打开文件 和 文件系统的文件产生关联
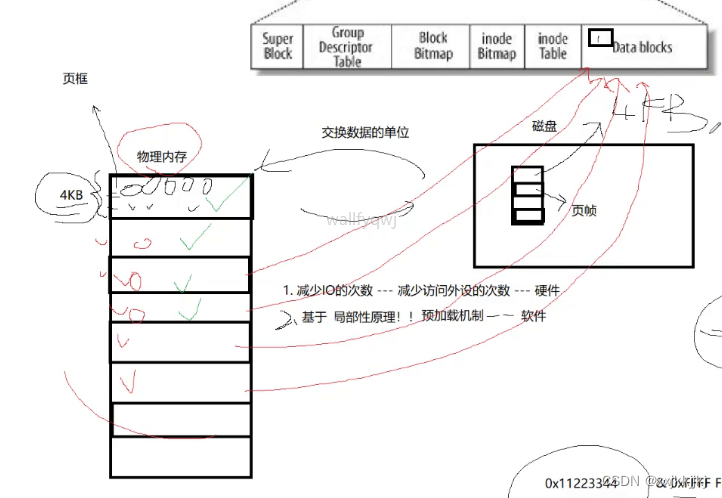
补充1:硬件级别磁盘和内存之间数据交互的基本单位
OS的内存管理
内存的本质是对数据临时存/取,把内存看成很大的缓冲区
物理内存和磁盘交互的单位是4KB,磁盘中未被打开的文件数据块也是4KB,所以磁盘中页帧也是4KB,内存中叫页框
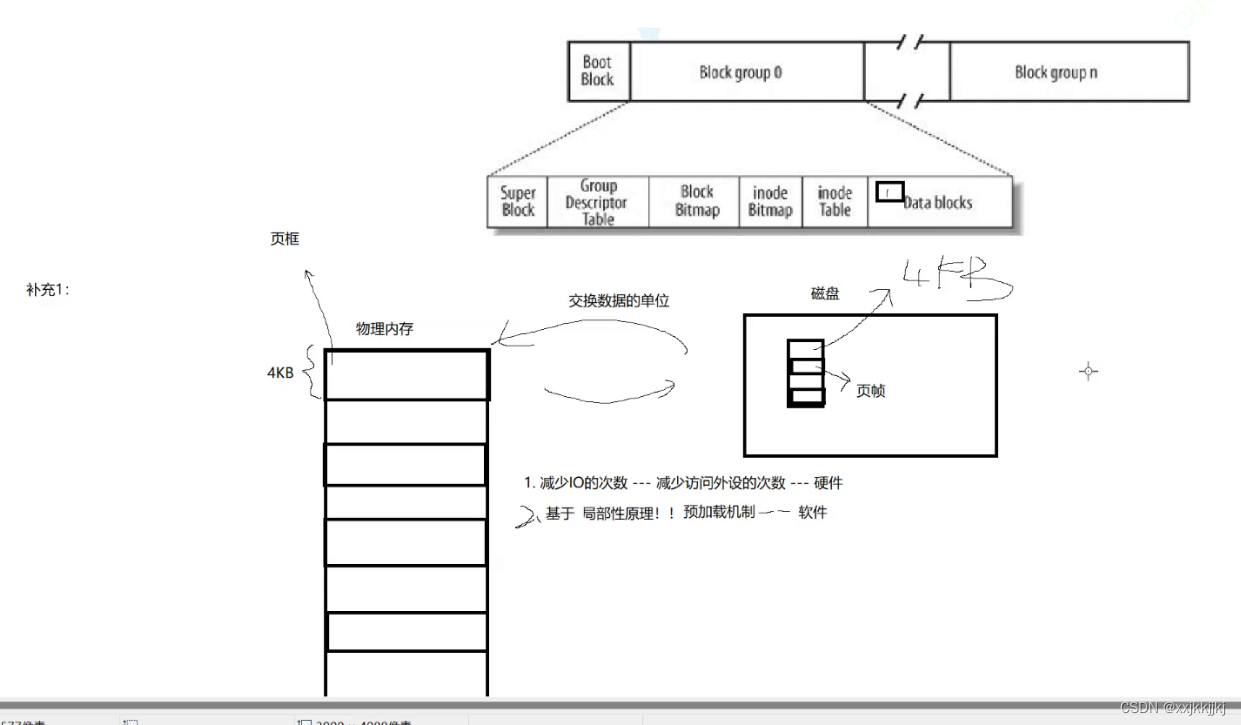
我这个文件可能没有4KB,就一个字节,但不好意思加载4KB
我这个文件4KB,想修改1字节,也得加载4KB
为什么它不是要多少加载多少,而是一个固定大小4KB呢?
1、和磁盘交互比较慢,一共4KB每次要1KB的效率不如一气直接4KB,因为磁盘只需要定位一次
2、如果4KB文件你只要100字节,你能保证你下一次不用这文件上下文的其他数据吗?反正拿100字节还是4KB效率差不多,因为估摸着你后面的字节大概率也要用
局部性原理:正在访问代码区域附近也大概率会有数据代码被访问
这是一种预加载机制
那系统中向文件写了100字节,实际上保存100字节需要4KB?把数据交换的物理内存也要花4KB?
是的,文件大小从中做了一些事情
不用担心浪费问题,文件特别大前面那些内容把4KB都写满了,只有最后一个块被浪费了,小文件的就更不用说了
补充2:操作系统如何管理内存
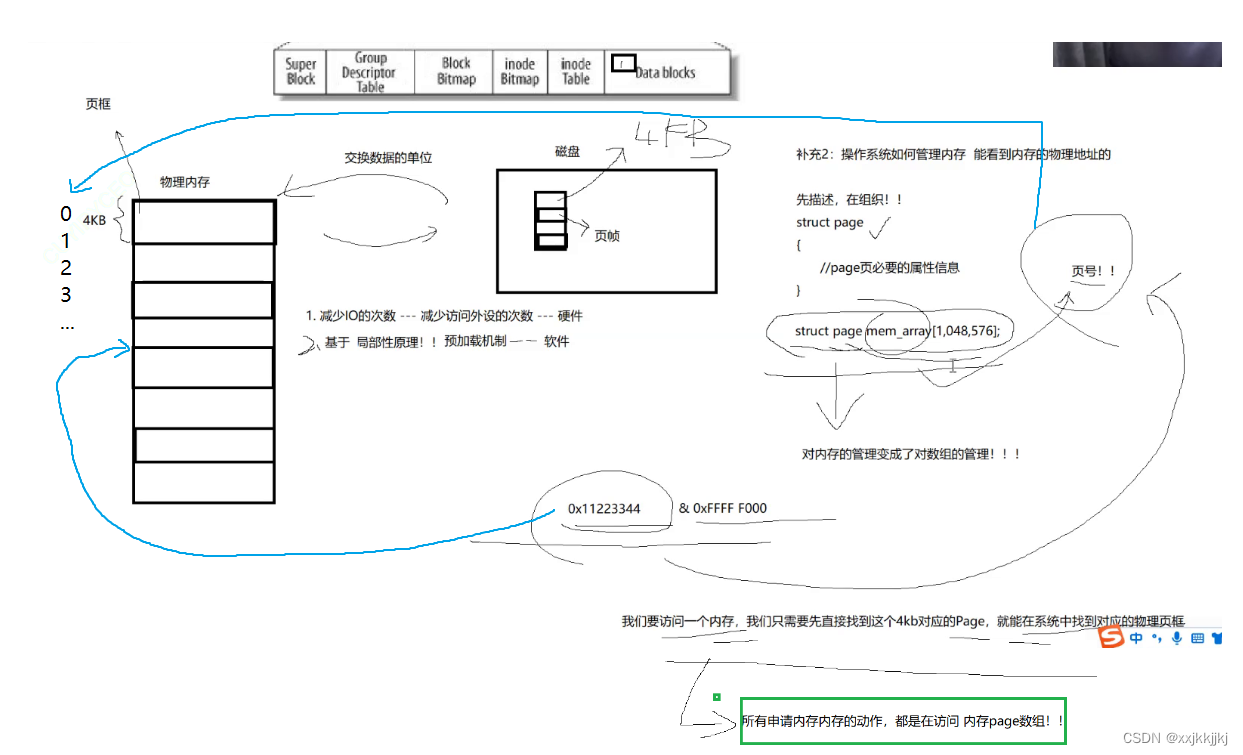
操作系统必须能看到内存的物理地址
操作系统如何管理内存呢?
内存已经是一个一个4KB大小,非常多
我怎么知道哪些4KB被用到了,那些没被用
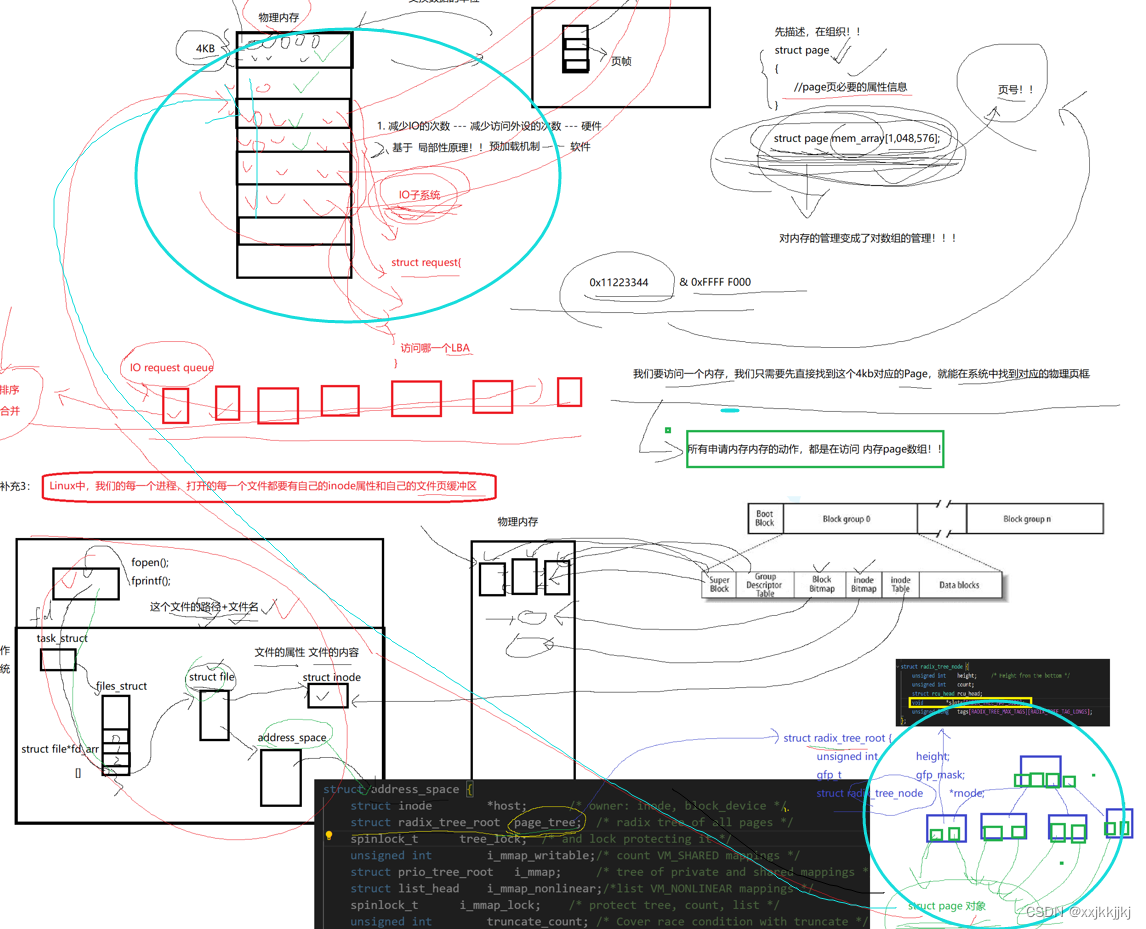
先描述,在组织!
struct page
{
//page页必要的属性信息
}
描述其中一个4KB
物理内存4G B 就有100多万的页

struct page mem_array[1048576];
对内存的管理变成了对数组的管理!!
数组天然是有下标的,所以每一个page天然有了页号的概念
如果此时任意一个地址0x11223344 & 0xFFFF F000,相当于求的是这个页的4KB对齐的起始地址
有了这个任意页的地址,应该就能通过找到对应的page数组对应的下标(不用&直接让11223344转10进制 然后 除以 4096就能找到对应下标了)(都拿到地址了还有啥找不到的),进行物理内存管理
结论:
所有申请内存的动作,都是在访问内存page数组,都是对这个数组增删查改
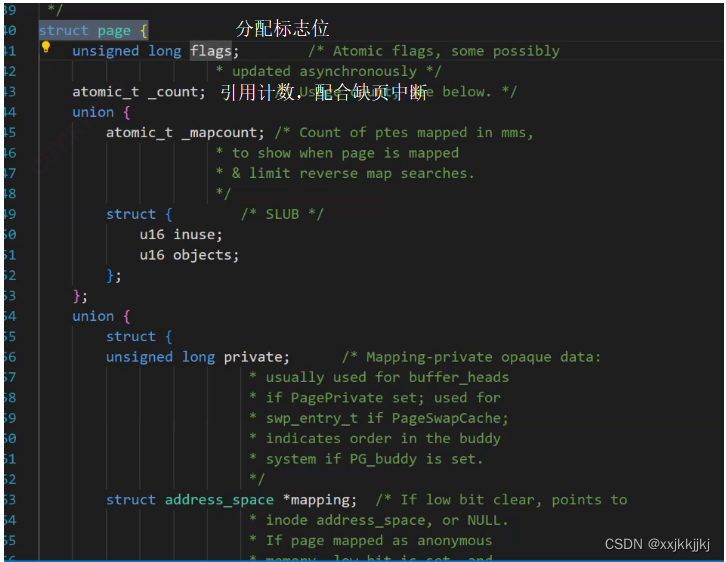
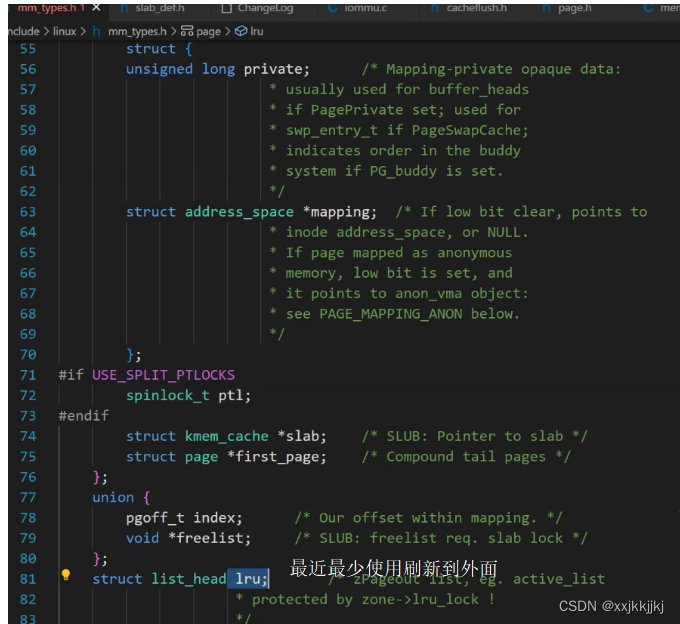
struct page mem_array[1048576] 一定像链表一样有对应的数据结构方法,调算法申请内存
补充3:Linux中,我们的每一个进程、打开的每一个文件都要有自己的inode属性和自己的文件页缓冲区(内核缓冲区)
在开机时,把文件系统中的管理属性已经预加载到内存中了,尤其是super block GDT等文件系统方面的信息
比如这个分区上面就是操作系统文件,都要读,所以OS提前预加载到内存中
每个分区可能用的不同文件系统,OS中存在把所有的super block用双链表链接起来,OS知道每个分区大概在哪,每个分区文件系统什么样
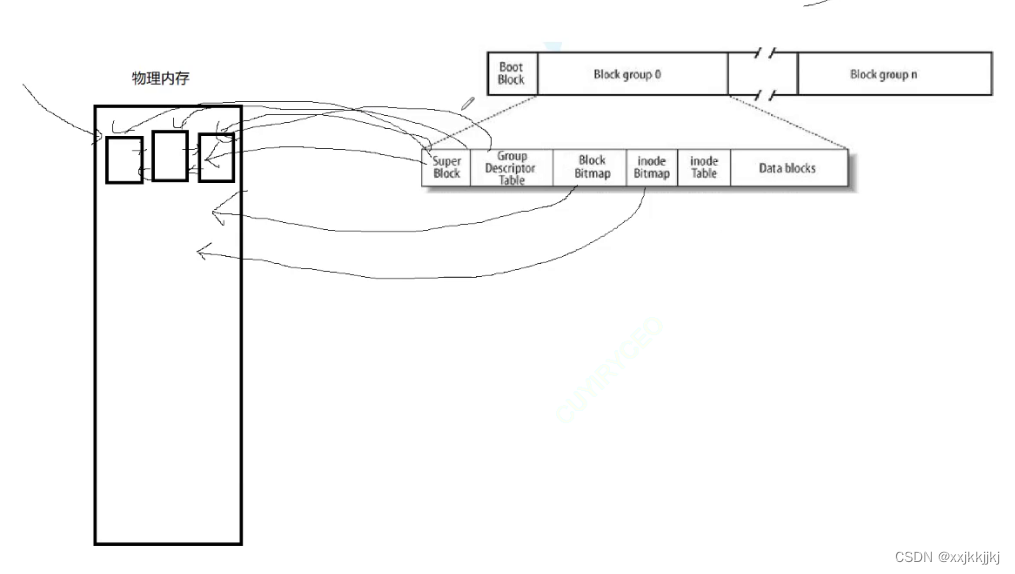
关于打开一个文件时,OS要做什么工作,理解内核文件级缓冲区概念
打开一个文件时,struct file只保存了少数的文件属性,OS要为struct file构建一个数据结构struct inode才会保存文件的大部分属性,当打开文件时,根据对应目录中的数据块文件名映射找到inode编号,在已经预加载到物理内存中 的inode bitmap确认文件存在,然后在inode table 把对应的inode属性填入struct inode里
struct file 通过指针要能找到对应的struct inode,文件属性也就有了
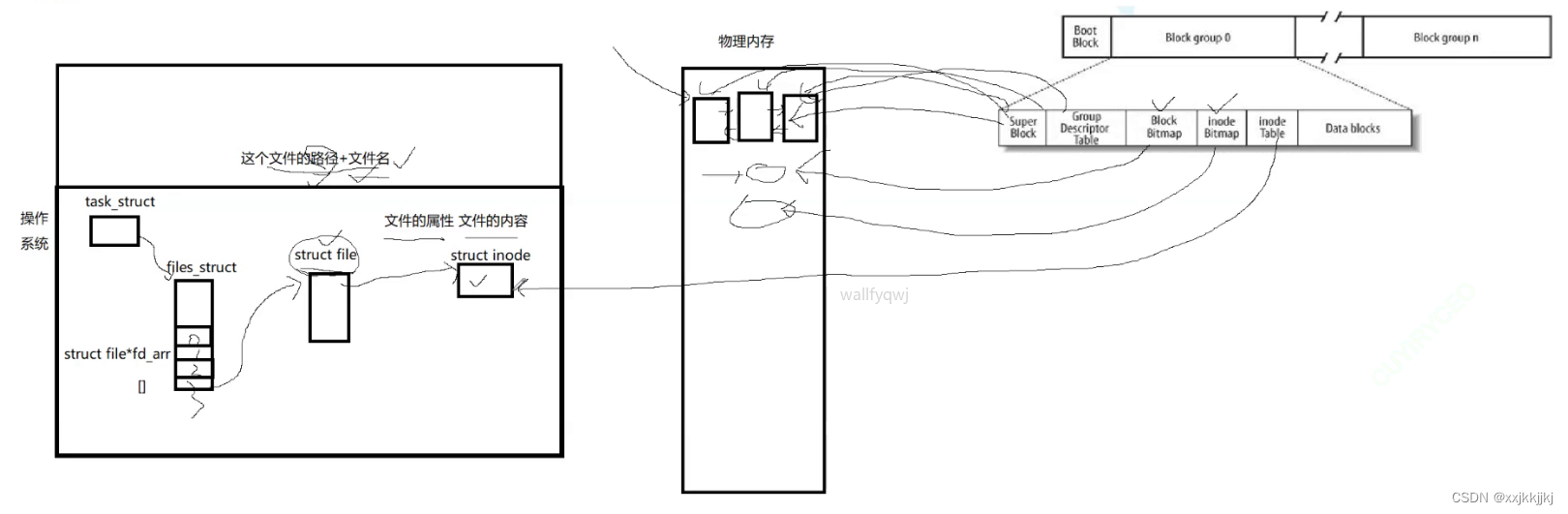
内核中的struct file 与struct inode指针
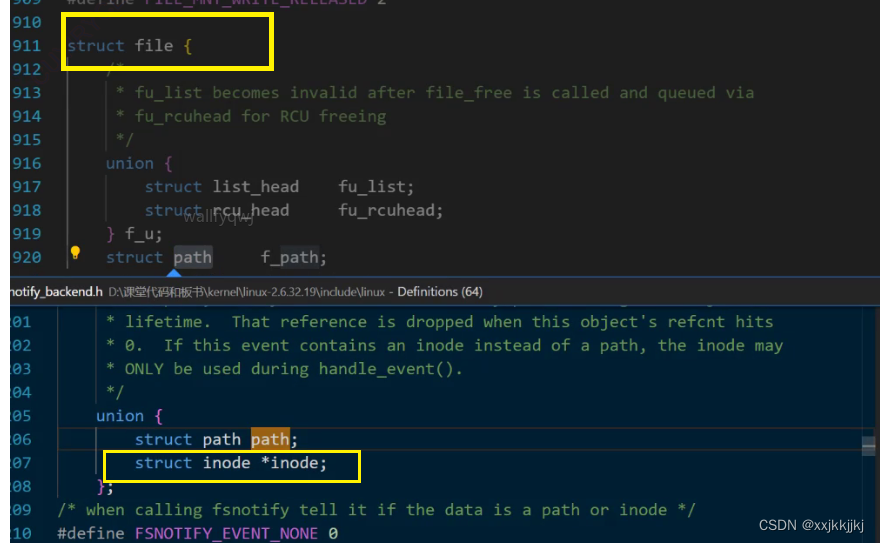
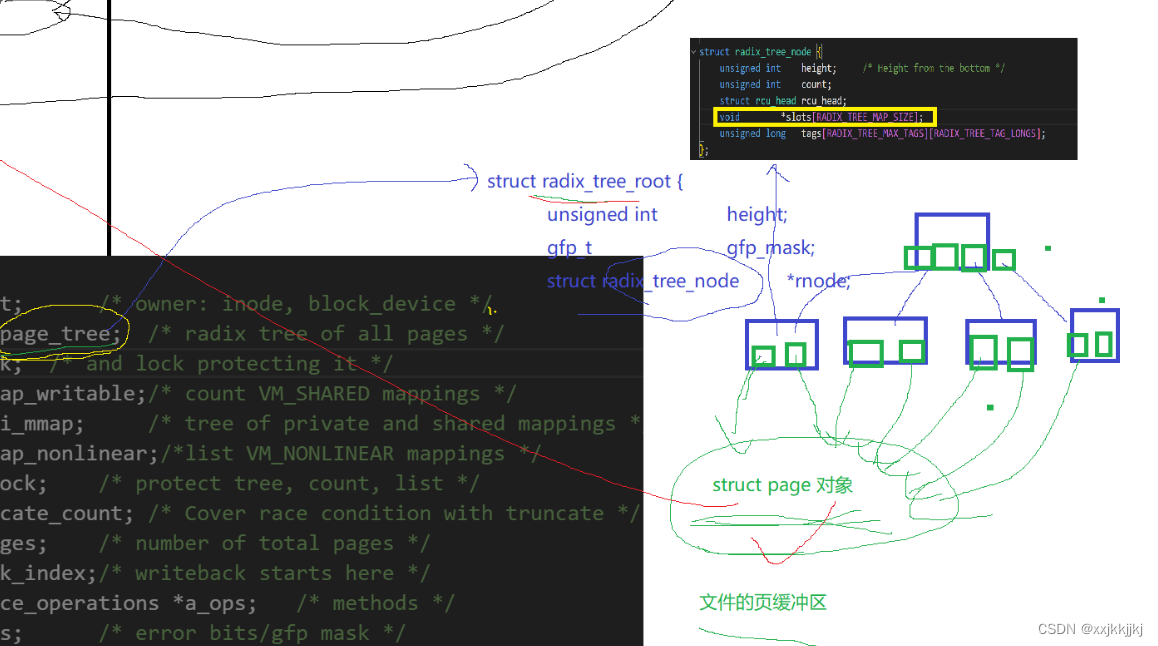
文件属性其实不难找,文件内容呢?
C语言提供缓冲区,通过fprintf把数据写到缓冲区,通过fd我这个进程找到对应文件struct file
最终又怎么把数据写到对应磁盘上呢?
struct file中存在 address_space结构指针,这个结构包含一颗树page_tree,可以想象成一颗多叉树,树的节点中保存了指针数组,在叶子节点中保存了一个一个的struct page对象,而一个struct page对应物理内存4KB大小页框,所以应用层数据按照顺序从用户级缓冲区-> fd -> struct file -> address_space -> page_tree->叶子结点中的struct page然后再往物理内存中4KB中写入,就写到物理内存中了
我们看待物理内存时,只要找到对应的page,就能把数据写到物理内存里了
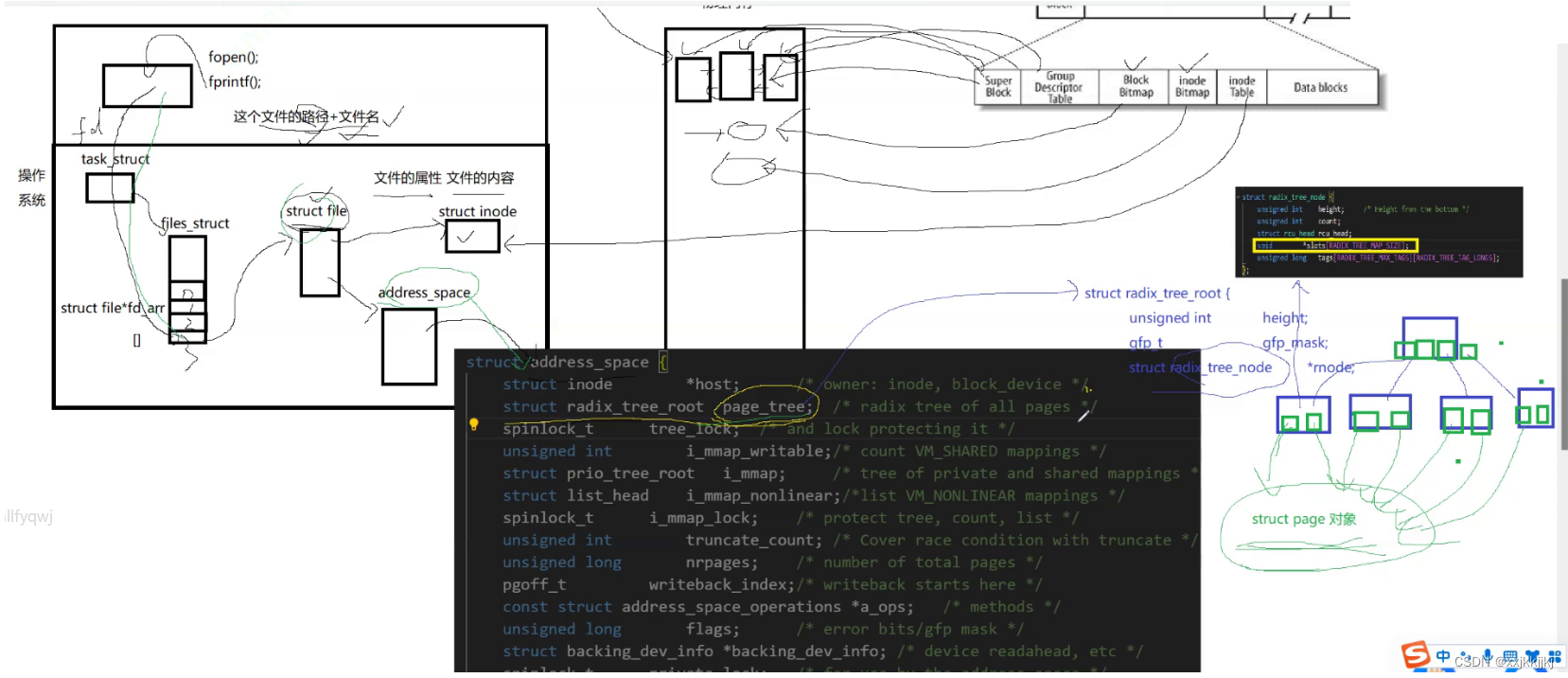
这颗树就叫文件的页缓冲区,此时我们把数据从应用层写到了由page管理的一个个内存中
补充4:
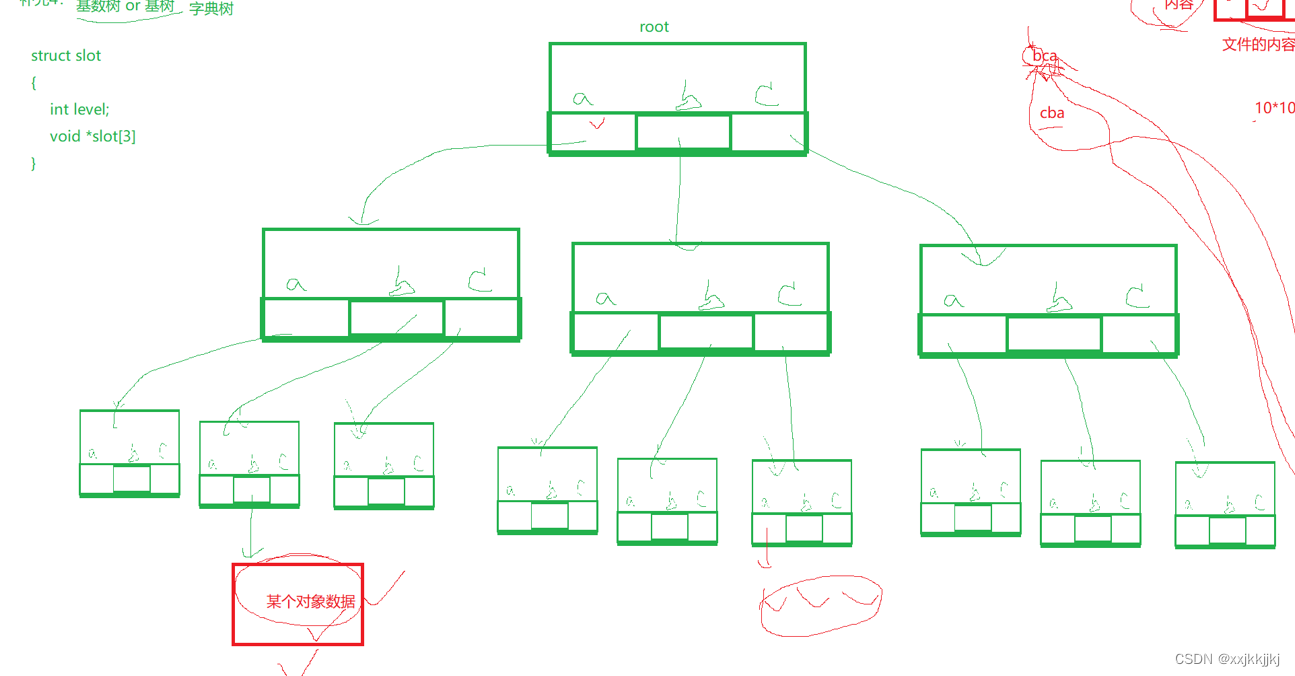
你说这玩意是个树,那是个什么树呢?
基数树 or 基树 本质是 字典树
数组有3个,那么这颗树就干上3层
void* slot[3]数组下标是数字,当我把他当成字母
每个数组又指向一个节点,就形成了这么一棵树
如果key是bca ,那么按照key的顺序就从根节点从上往下找
各种三个字母的组合就能根据这颗树找到某个底层叶子对象了
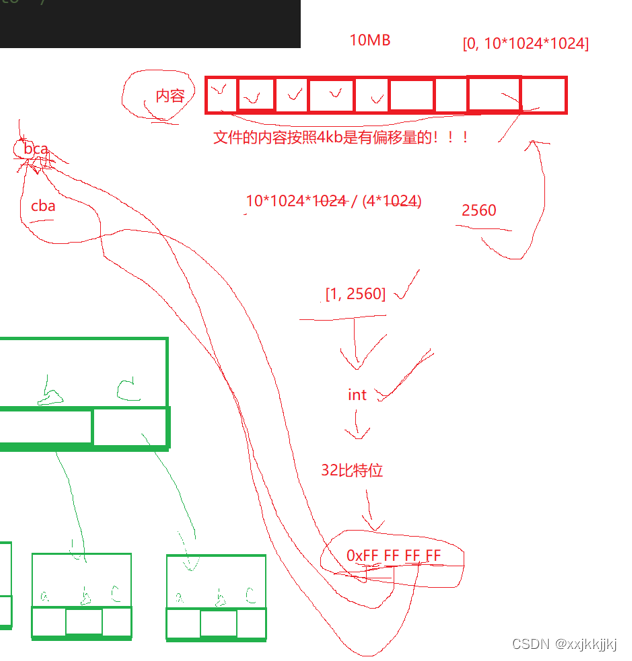
文件的内容是有偏移量的
假设文件大小10MB,也就是10x1024x1024字节
按照[0,1010241024]字节范围空间来看待
按照4KB来划分成一个一个的块
一共有多少个块呢?
1010241024/4*1024 = 2560个块
也就是说整个文件在磁盘上占2560个数据块
磁盘中每个块也就有了编号,从【1,2560】
每个数字乘以4096就是编号对应4KB在原始文件中的偏移量
所以把【1,2560】的编号按照Int来看待,有32bit位
假设0xFF FF FF FF 每八个bit看做一个字母Key = b,c ,a…
如果我们构建出这样的字典树,我们就可以拿着文件内容把文件内容的偏移量按照比特位分成特定的几个区域,八个bit为看成第一个字母b,后面依次类推,然后对应的字典树中就能找到整个文件中的偏移量和内存中page的映射关系
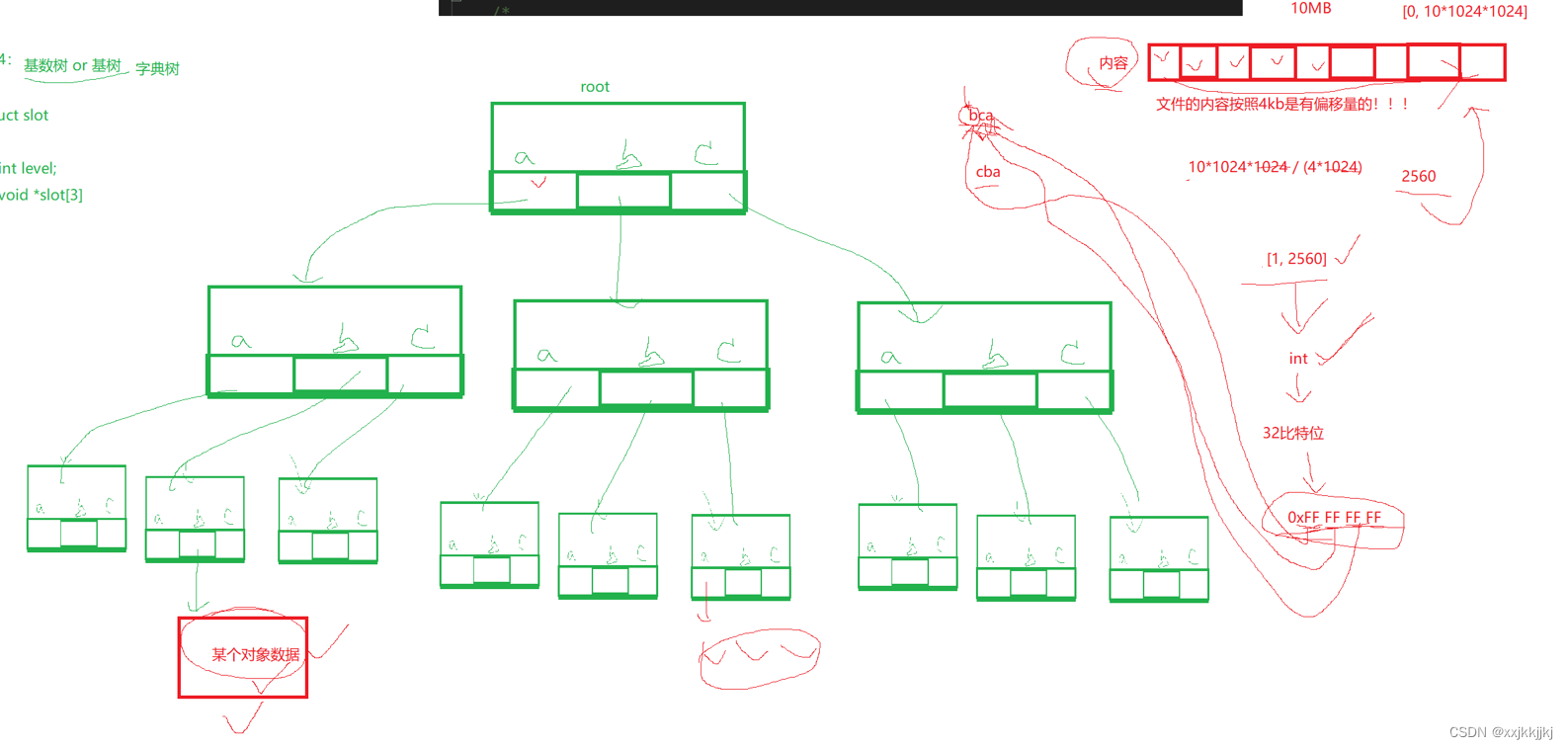
拿着文件的内容偏移量和内存的page建立映射关系,当我进行读写文件时,从开头读,结尾读,读写哪里,每一个读写都有偏移量,有偏移量找这颗树中偏移量对应的内存中某一个page,这样就能把数据保存到page里
其实最终想说的是文件写入把用户缓冲区的数据通过内核数据结构找到对应的Page对象把数据刷新到物理内存中了
接下来的工作就是OS要定期把数据刷到文件系统data blocks里面
此时数据已经写在物理内存中了,树里面的struct page就可以对应到物理内存中的page了
写完进程还管不管心数据刷到磁盘这个过程呢?
他就不关心了
所以这个数据刷新不刷新完全由OS决定,从这开始就往驱动层面走了
总结:
1、一个磁盘对应的文件它在访问之前部分对应文件系统中的属性已经加载内存了
2、进程打开文件时,本质就是把磁盘中的属性往struct inode 放
内容blocks通过struct file也能找到,以page的形式保存好
3、用户层写入时,通过fd-》 struct file-》 address-》 找到管理基树 找到物理内存中对应的page
然后把数据刷新到对应page页里,最后由OS调用IO子系统,把数据通过IO队列刷新到硬件上
相关文章:
打开文件 和 文件系统的文件产生关联
补充1:硬件级别磁盘和内存之间数据交互的基本单位 OS的内存管理 内存的本质是对数据临时存/取,把内存看成很大的缓冲区 物理内存和磁盘交互的单位是4KB,磁盘中未被打开的文件数据块也是4KB,所以磁盘中页帧也是4KB,内存…...
【Rust】快速教程——模块mod与跨文件
前言 道尊:没有办法,你的法力已经消失,我的法力所剩无几,除非咱们重新修行,在这个世界里取得更多法力之后,或许有办法下降。——《拔魔》 \;\\\;\\\; 目录 前言跨文件mod多文件mod 跨文件mod //my_mod.rs…...
crontab定时任务是否执行
centos查看 crontab 是否启动 systemctl status crond.service 查看cron服务的启动状态 systemctl start crond.service 启动cron服务[命令没有提示] systemctl stop crond.service 停止cron服务[命令没有提示] systemctl restart crond.service 重启cron服务[命令没有提示] s…...

MATLAB程序设计:牛顿迭代法
function xnewton(x0,e,N,fx) %输入x0,误差限e,迭代次数N和函数Fx k1; while k<Nif subs(diff(fx),x0)0disp("输出奇异标志");break;endx1x0-subs(fx,x0)/subs(diff(fx),x0);if abs(x1-x0)<ebreak;endx0x1;kk1; end if k<Ndisp(x1); elsedisp("迭代失败…...

B031-网络编程 Socket Http TomCat
目录 计算机网络网络编程相关术语IP地址ip的概念InerAdress的了解与测试 端口URLTCP、UDP和7层架构TCPUDPTCP与UDP的区别和联系TCP的3次握手七层架构 Socket编程服务端代码客户端代码 http协议概念Http报文 Tomcat模拟 计算机网络 见文档 网络编程相关术语 见文档 IP地址 …...

gRPC之metadata
1、metadata 服务间使用 Http 相互调用时,经常会设置一些业务自定义 header 如时间戳、trace信息等,gRPC使用 HTTP/2 协议自然也是支持的,gRPC 通过 google.golang.org/grpc/metadata 包内的 MD 类型提供相关的功能接口。 1.1 类型定义 /…...
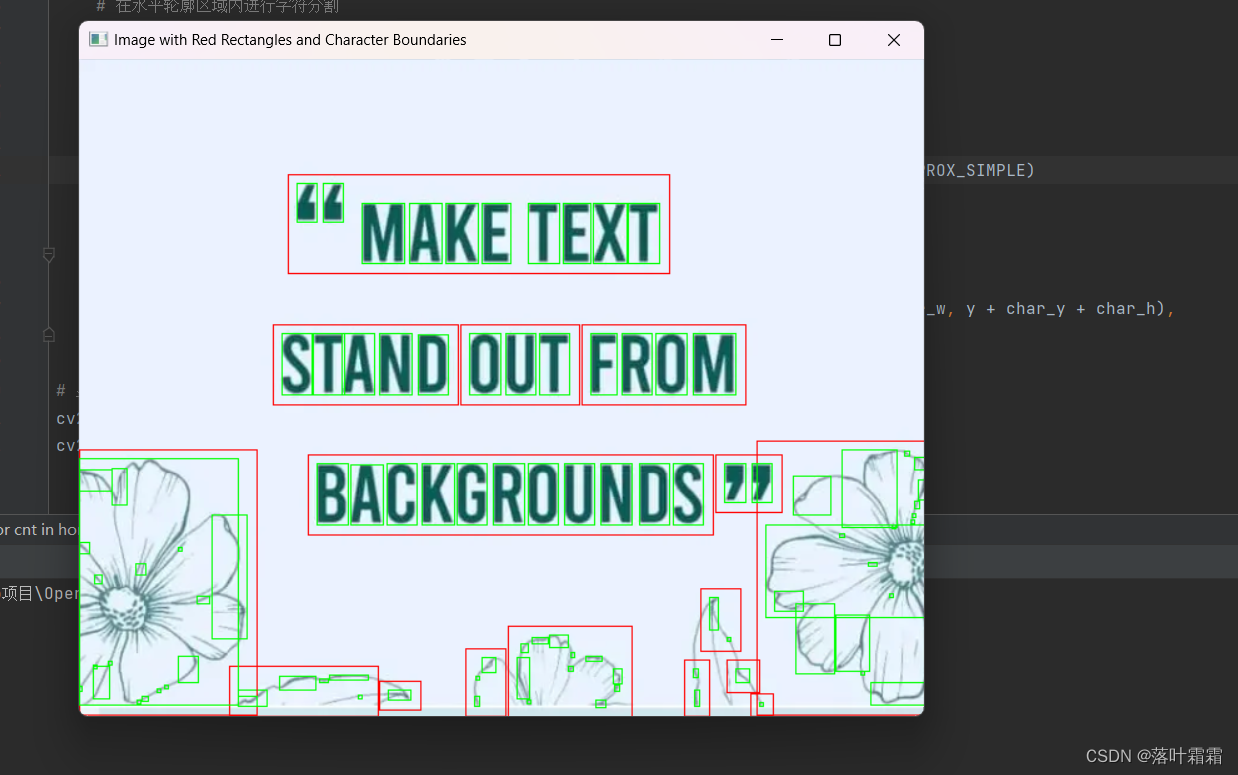
【OpenCV实现图像:OpenCV进行OCR字符分割】
文章目录 概要基本概念读入图像图像二值化小结 概要 在处理OCR(Optical Character Recognition,光学字符识别)时,利用传统的图像处理方法进行字符切分仍然是一种有效的途径。即便当前计算机视觉领域主导的是卷积神经网络…...

景联文科技入选量子位智库《中国AIGC数据标注产业全景报告》数据标注行业代表机构
量子位智库《中国AIGC数据标注产业全景报告》中指出,数据标注处于重新洗牌时期,更高质量、专业化的数据标注成为刚需。未来五年,国内AI基础数据服务将达到百亿规模,年复合增长率在27%左右。 基于数据基础设施建设、大模型/AI技术理…...
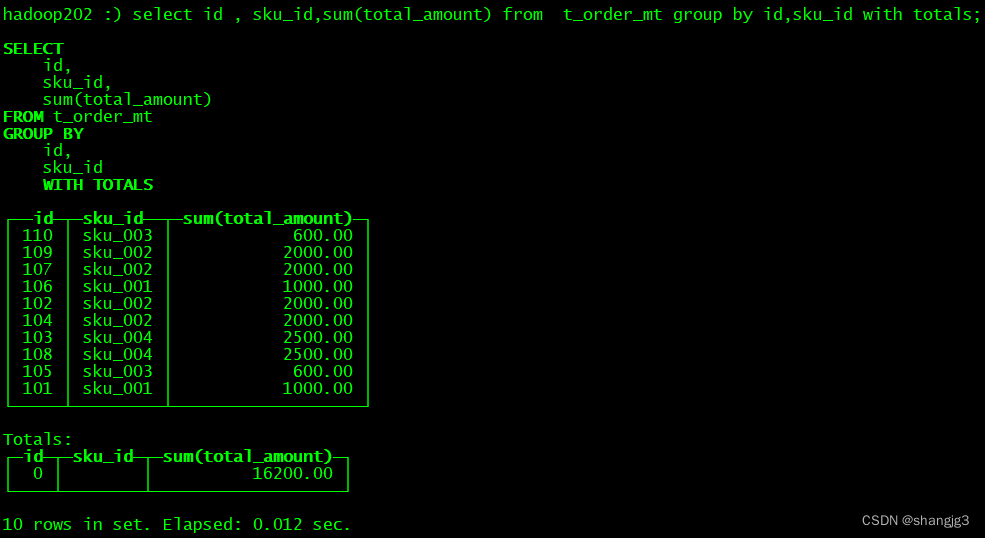
ClickHouse SQL操作
基本上来说传统关系型数据库(以MySQL为例)的SQL语句,ClickHouse基本都支持,这里不会从头讲解SQL语法只介绍ClickHouse与标准SQL(MySQL)不一致的地方。 1 Insert 基本与标准SQL(MySQL)…...
)
Ubuntu安装Python环境(使用VSCode)
想在Ubuntu上安装Python环境,选择了VSCode,而不想多装Anaconda等环境,最后参考了这篇博客: python入门开发:ubuntu下搭建python开发环境(vscode)...

QTcpSocket发送结构体的做法
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> QTcpSocket发送结构体其实很简单:使用QByteArray类对象进行封装发送,示例代码如下: /* 消息结构体 */ struct stMsg {int m_A…...
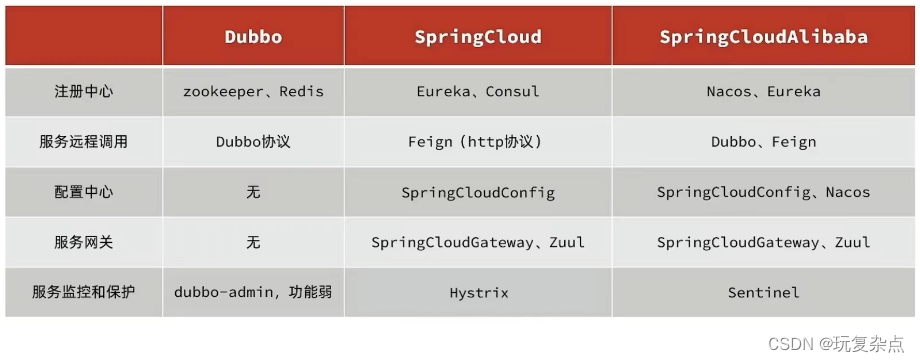
微服务学习 | Ribbon负载均衡、Nacos注册中心、微服务技术对比
Ribbon负载均衡 负载均衡流程 负载均衡策略 通过定义IRule实现可以修改负载均衡规则,有两种方式: 1. 代码方式:在服务消费者order-service中的OrderApplication类中,定义一个新的IRule: 2.配置文件方式: 在order-service的application.yml…...

【FPGA】zynq 单端口RAM 双端口RAM 读写冲突 写写冲突
RAMRAM读写分类RAM原理及实现RAM三种读写模式不变模式写优先读优先 单端口 RAM伪双端口 RAM真双端口 RAM读写冲突和写写冲突读写冲突写写冲突总结: RAM RAM 的英文全称是 Random Access Memory,即随机存取存储器,简称随机存储器,…...
【备忘】websocket学习之挖坑埋自己
背景故事 以前没有好好学习过websocket,只知道它有什么用途,也知道是个好东西,平时在工作中没用过,所以对它并不知所以然。如今要做个自己的项目,要在付款的时候实时播报声音。自己是个开发者,也不想用别人…...

大数据研发工程师面试
文章目录 面试1.AUC,ROC,准确率与召回率都是怎么计算的?2.数据清洗是如何清洗的,要做哪些清洗的工作?3.什么是数据的完整性?4.数仓是怎么设计的?5.linux查看进程的命令是什么,如何查看具体某一行的内容(查看第n至m行࿰…...
【星海出品】云存储 ceph
https://ceph.com/en/ ceph组件介绍 Monitor 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。 OSD OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有…...

[nlp] grad norm先降后升再降
grad norm先降后升再降正常嘛 在深度学习中,梯度的范数通常被用来衡量模型参数的更新程度,也就是模型的学习进度。在训练初期,由于模型参数的初始值比较随机,梯度的范数可能会比较大,这是正常现象。随着模型的训练&…...

云积天赫AI全域营销系统,为品牌营销注入新活力
AIGC(生成式人工智能)的出现,标志着人工智能已经进入了一个全新的时代,它与传统的人工智能不同,可以更好地理解品牌的需求,并提供更精准的答案。目前,AIGC已经深入到各个领域,其中营…...

Arthas在线修改Java代码
Arthas在线修改Java代码 jad --source-only com.example.demo.arthas.user.UserController > /tmp/UserController.javamc /tmp/UserController.java -d /tmpretransform /tmp/com/example/demo/arthas/user/UserController.class参考链接: arthas retransform...

mapbox支持的坐标系
mapbox 中只支持 web墨卡托坐标系,不支持经纬度坐标系。 栅格数据 基于经纬度坐标系的栅格数据没有办法渲染。矢量数据 矢量数据代码中会自动转换成墨卡托投影坐标系再渲染。 输出坐标时候还是经纬度。...

OBS Advanced Timer:全场景直播计时神器,让你的直播节奏掌控自如
OBS Advanced Timer:全场景直播计时神器,让你的直播节奏掌控自如 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 作为主播,你是否曾因手动计时失误导致直播环节超时ÿ…...

郭老师-我们为什么要爱国?
我们为什么要爱国? ——因为家在,根在,魂在“你可以不爱你的管家, 但必须爱你家的房子。”🌿 国家如屋,人民为主, 执政者不过管家—— 而这屋,是我们的命脉所系。🏠 一、…...

STM32F103红外小车避坑指南:从Proteus仿真失败到实物调试成功
STM32F103红外小车避坑指南:从Proteus仿真失败到实物调试成功 第一次尝试用STM32F103做红外循迹小车时,我花了整整三天时间在Proteus里调试仿真,结果连最基本的电机转动都实现不了。直到把电路搬到实物上,才发现仿真环境里那些看似…...

usearch的内存泄漏自动化测试:在CI中集成泄漏检测
usearch的内存泄漏自动化测试:在CI中集成泄漏检测 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolf…...

Qwen3.5-2B效果展示:对含中英混排、公式符号的PDF截图进行精准语义还原
Qwen3.5-2B效果展示:对含中英混排、公式符号的PDF截图进行精准语义还原 1. 模型概览 Qwen3.5-2B是通义千问团队推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型主打低功耗、低门槛部署特性&#x…...

Z-Image-GGUF模型Java后端集成指南:SpringBoot微服务实战
Z-Image-GGUF模型Java后端集成指南:SpringBoot微服务实战 最近在做一个内容创作平台的后台重构,产品经理提了个需求,想给用户加个“AI一键生成文章配图”的功能。团队评估了几个方案,最终决定用Z-Image-GGUF这个模型,…...

精通ComfyUI-BrushNet:专业图像修复全流程指南
精通ComfyUI-BrushNet:专业图像修复全流程指南 【免费下载链接】ComfyUI-BrushNet ComfyUI BrushNet nodes 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-BrushNet ComfyUI-BrushNet是一款功能强大的图像修复工具,通过节点式工作流实现专…...
)
别再为PDF表格头疼了!用Nougat+LangChain搞定RAG系统里的表格问答(附完整代码)
突破PDF表格解析瓶颈:Nougat与LangChain构建智能问答系统实战 每次打开满是表格的学术论文PDF时,你是否也经历过这样的挫败感?传统OCR工具要么把跨页表格拆得七零八落,要么将复杂的LaTeX公式识别成乱码,更别提准确关联…...

基于滑模变结构观测器的永磁同步电机失磁故障容错补偿控制
基于失磁故障容错补偿的永磁同步电机控制【提供参考资料】 一、算法简介 基于滑模变结构观测器,将状态电流观测值作为反馈量,利用滑模变结构等值控制原理,建立实时估计永磁磁链算式,从而进行补偿。 避免因失磁导致的转速下降&…...

Graphormer开源可部署意义:支撑国家AI for Science重大科技基础设施
Graphormer开源可部署意义:分子属性预测使用指南 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等分子基准测试中表现优…...