mysql group by 执行原理及千万级别count 查询优化
大家好,我是蓝胖子,前段时间mysql经常碰到慢查询报警,我们线上的慢sql阈值是1s,出现报警的表数据有 7000多万,经常出现报警的是一个group by的count查询,于是便开始着手优化这块,遂有此篇,记录下自己优化过程中的心得。
优化慢sql前,肯定是要懂sql的查询逻辑,所以我先介绍下group by 语句的执行逻辑。
group by 执行逻辑
环境准备
拿下面这张表举例,这是一张记录文件夹id和用户id关联关系的表。其中dir_id代表文件夹id,uid代表用户id,还有个唯一索引是uniq_dir_id。
create table t_dir_user
(
id bigint unsigned auto_increment
primary key,
dir_id bigint default 0 not null,
uid bigint default 0 not null,
constraint uniq_dir_id
unique (dir_id, uid)
)
表一共有7000多万的数据。下面开始介绍使用group by 语句时sql执行的原理。
没有用到索引的情况
先说下结论,group by后面的列如果不能使用上索引,那么则会产生临时表且很可能产生文件排序的情况。
group by 语句有分 使用到索引和没有使用到索引的情况,先看看没有使用到索引的情况。假如我想查询在一些文件夹范围内,用户关注的文件夹数量。那我可以写出下面这样的sql。
explain select count(1), uid
from t_dir_user
where dir_id in (1803620,4368250,2890924,2033475,3038030)
group by uid;
使用explain分析时,会发现这个查询是使用到索引的,且Extra 那一栏会出现下面的信息。
Using index condition; Using temporary; Using filesort
上述信息代表了查询是使用到了索引来做where条件查询,并且使用到了临时表和文件排序。
注意📢📢 ❗️ 临时表和文件排序这两个操作都是性能不佳的操作,写sql时应尽量避免。
现在来对这种情况做更加具体的分析,在上述例子中,mysql相当于建立了一张临时表,具体是内存的临时表还是磁盘的临时表要看临时表数据量大小,内存放不下会放到磁盘上。
临时表一列存放需要分组的值,上述案例中就是 uid,一列存放统计出来的count值,mysql会一遍扫描uniq_dir_id索引,一边向这个临时表中写入数据或更新count值,当索引扫描完成后,再将填满数据的临时表做下排序然后返回给客户端。注意这个排序的行为,如果需要排序的数据量很大则会产生文件排序,否则则是内存排序。
使用到索引的情况
再来看看group by 后跟的列能使用到索引的情况。
先说下结论,使用到索引的时候,mysql会使用内置的聚合函数来进行操作,而不是创建临时表。并且节省了排序这一步,这种方式会更高效。
还是拿上面t_dir_user 这张表举例,这次我们要查一定文件夹范围内,一个文件夹与多少个用户关联。我们可以这样写sql,
explain select count(1), dir_id
from t_dir_user
where dir_id in (1803620,4368250,2890924,2033475,3038030)
group by dir_id;
此时explain分析后你会发现,虽然使用的是相同的索引,但是Extra这一栏的信息已经变了,Extra信息如下,
Using index condition; Using aggregate; Using index
Using aggregate 这条sql会使用mysql内置的聚合函数进行分组聚合的操作。
我们来具体分析下,因为group by此次是按dir_id文件夹id进行分组的,而dir_id刚好可以用上dir_id和uid建立的联合索引uniq_dir_id,并且索引是有序的,这样mysql在扫描索引的时候,就是一个文件夹id的索引数据扫描完成后,再次去扫描下一个文件夹id的索引数据,扫描的同时会对该文件夹id的count值进行累加。 这样一个文件夹的索引数据扫描完成后刚好就能知道这个文件夹id关联的uid的count值,并将这个值发送给客户端。
所以,整个过程其实是一边扫描索引对特定文件夹id的count值进行累加,一边将累加后的结果返回给客户端的过程。
注意📢📢,mysql返回给客户端的结果并不是全部查询出来后才返回给客户端,而是可以边查边返回的。
整个过程是没有用上临时表的。这样的查询会更加高效。
使用索引的情况下如何优化千万级count group by查询
在了解完group by语句的执行逻辑后,我对线上的sql进行了分析,发现线上的sql的group by列是属于已经使用了索引的情况。那为啥还会慢呢?

因为即使是使用了索引,group by的过程还是会有扫描索引和进行累加的过程,由于扫描的数据量太大了,最终导致了sql整体耗时还是很慢,超过了1s的阈值。
既然如此,那就换一种优化思路,这也是对大数据量的聚合统计的一种常用手段。 业务大部分时候都是读多写少的,可以建立一张新表专门用于记录对应的文件夹管理的用户数,每次关联关系发生变化时,同时再更新下这张统计表的数量即可。而业务在查询数量时,则直接查统计表中的数据。 这种优化非常适合大数据量的统计。
除此以外,甚至还可以使用elasticsearch 这类型数据库存数据,在这个案例里,相当于就把t_dir_user整张表的数据同步到elasticsearch中,并且做mysql到elasticsearch集群数据的实时同步机制,这样以后在查询对应文件夹的关联人数时,可以直接在elasticsearch进行查询。elasticsearch会对每个字段建立倒排索引。由于倒排索引中会存储该索引的记录条数,在这个案例中就是dir_id对应的记录条数,所以在用elasticsearch进行dir_id的分组count查询时是相当快的。
我们线上已经有elasticsearch同步部分mysql表的机制了,基于此,我选择了方案2,直接在之前同步表中新增了t_dir_user这张表,并且修改了业务查询文件夹下关联人数的逻辑,改由直接查询elasticsearch。
其实,你可以发现由于elasticsearch的倒排索引内直接记录了数量信息,这个和由mysql建立新的统计表记录数量,原理其实是一致的,就是将高频的读count查询改由低频的更新操作。
相关文章:
mysql group by 执行原理及千万级别count 查询优化
大家好,我是蓝胖子,前段时间mysql经常碰到慢查询报警,我们线上的慢sql阈值是1s,出现报警的表数据有 7000多万,经常出现报警的是一个group by的count查询,于是便开始着手优化这块,遂有此篇,记录下…...

Linux的几个常用基本指令
目录 1. ls 指令2.pwd命令3.cd 指令4. touch指令5.mkdir指令6.rmdir指令 && rm 指令7.man指令8.cp指令9.mv指令10.cat指令 1. ls 指令 语法: ls [选项][目录或文件] 功能:对于目录,该命令列出该目录下的所有子目录与文件。对于文件&…...
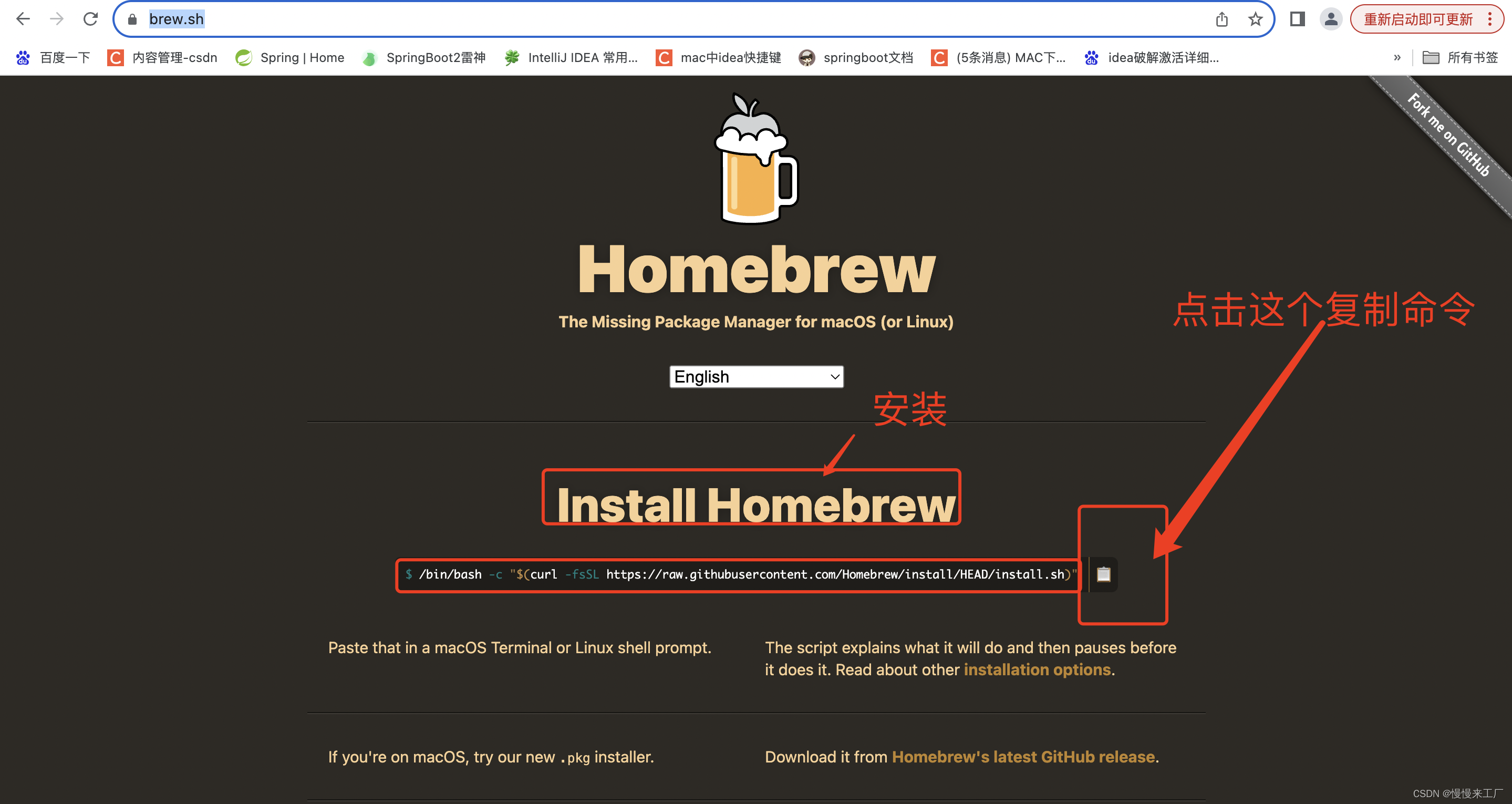
mac中安装Homebrew
1、Homebrew是什么? 软件安装管理工具 2、先检查电脑中是否已经安装了Homebrew 打开终端输入:brew 提示命令没有找到,说明电脑没有安装Homebrew 如果提示上述图片说明Homebrew已经安装成功 3、安装Homebrew 进入https://brew.sh/ 复制的命…...
)
Vue23的计算属性(computed)
Vue2&3的计算属性(computed) Vue2的计算属性 原理:data中的属性通过计算得到新的属性,称为计算属性(computed)。computed 具有 getter 和 setter 属性 getter 属性在使用时分别有两次调用:…...

vue3中祖孙组件之间的通信provide和inject
一、在vue3中新增的祖孙之间通信的方式 provide和inject是Vue中的两个相关功能,它们一起提供了一种祖孙组件之间共享数据的方式。父组件可以使用provide来提供数据,而子孙组件可以使用inject来接收这些数据。 二、使用 父组件中部分代码 <script&g…...

月影下的时光机:Python中的日期、时间、农历、节气和时区探秘
前言 在现代软件开发中,对日期、时间和时区的准确处理至关重要。无论是全球化应用的开发,还是与时序数据相关的任务,都需要强大而灵活的工具。Python作为一门流行的编程语言,提供了丰富的标准库和第三方库,使得处理日…...

【Bazel】Bazel 学习笔记
本文简单记录下 Bazel 使用过程中的一些知识点。 目录 文章目录 目录Bazel 目录结构BUILD 构建规则常用构建规则 Bazel 命令bazel buildbazel query Mac 安装 Bazel Bazel 是谷歌推出的一个开源的构建工具,工作原理与 make、maven 或 gradle 等其他构建工具类似。但…...
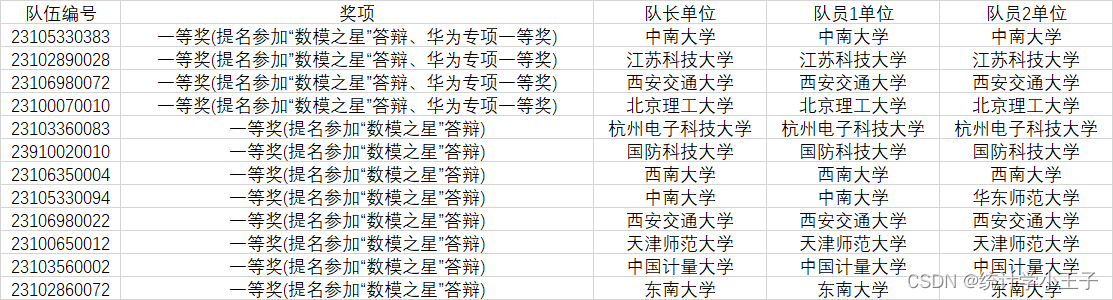
2023年“华为杯”第二十届中国研究生数学建模成绩数据分析(末尾有吃席群)
目录 0引言1、数据大盘1.1 官方数据1.2 分赛题统计数据1.2.1 A-F 获奖数1.2.2 A-F 获奖率 2、分学校统计获奖情况(数模之星没有统计)3、 数模之星4、吃席群5、写在最后的话 0引言 2023年华为杯成绩于2023年9月22-26日顺利举行,来自国际和全国…...

Linux文件和文件夹命令详解
1.Linux文件类型详解 常见的Linux文件类型: 普通文件(Regular File):(例如文本文件、二进制文件、图片、视频和压缩文件等;) 普通文件是最常见的文件类型,存储了实际的数据…...

MIKE水动力笔记20_由dfs2网格文件提取dfs1断面序列文件
本文目录 前言Step 1 MIKE Zero工具箱Step 2 提取dfs1 前言 在MIKE中,dfs2是一个一个小格格的网格面的时间序列文件,dfs1是一条由多个点组成的线的时间序列文件。 如下两图: 本博文内容主要讲如何从dfs2网格文件中提取dfs1断面序列文件。 …...
微服务nacos实战入门
注册中心 在微服务架构中,注册中心是最核心的基础服务之一 主要涉及到三大角色: 服务提供者 ---生产者 服务消费者 服务发现与注册 它们之间的关系大致如下: 1.各个微服务在启动时,将自己的网络地址等信息注册到注册中心&#x…...

PyCharm 远程连接服务器并使用服务器的 Jupyter 环境
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

HBase中的数据表是如何用CHAT进行分区的?
问CHA:HBase中的数据表是如何进行分区的? CHAT回复: 在HBase中,数据表是水平分区的。每一个分区被称为一个region。当一个region达到给定的大小限制时,它会被分裂成两个新的region。 因此,随着数据量的增…...
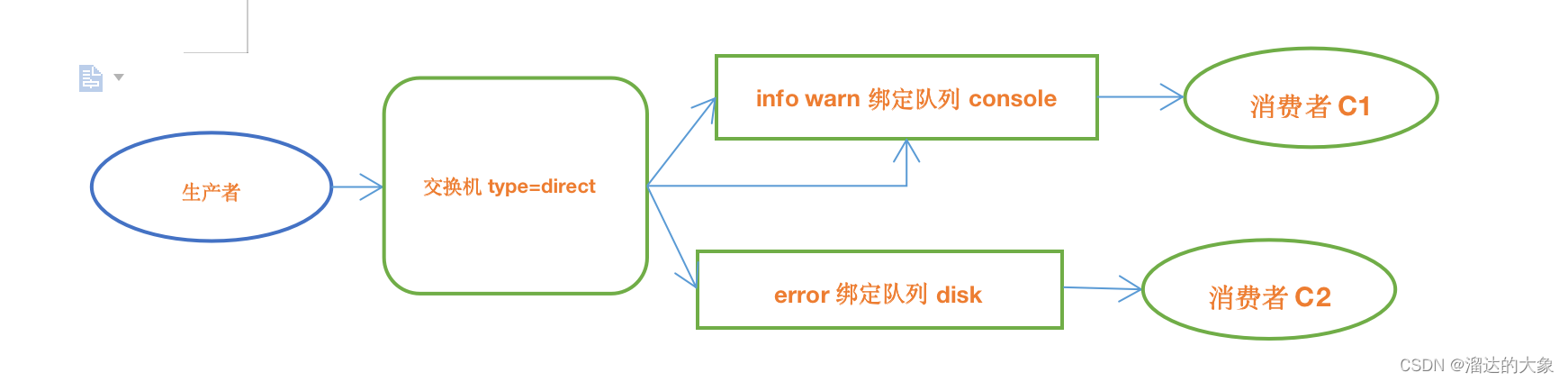
rabbitMQ的direct模式的生产者与消费者使用案例
消费者C1的RoutingKey 规则按照info warn 两种RoutingKey匹配 绑定队列console package com.esint.rabbitmq.work03;import com.esint.rabbitmq.RabbitMQUtils; import com.rabbitmq.client.Channel; import com.rabbitmq.client.DeliverCallback;/*** 消费者01的消息接受*/ p…...

分布式应用服务拆分
需求落地分布式应用服务 将需求转化为分布式应用服务的过程可以按照以下步骤进行: 理解需求:首先,你需要仔细阅读和理解业务需求。与相关的利益相关者(如业务分析师、产品经理等)进行沟通,确保你对需求的理…...
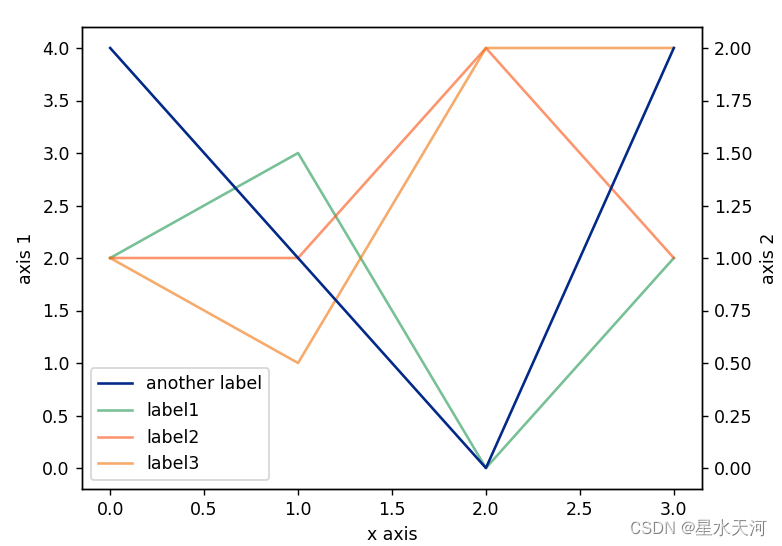
matplotlib 绘制双纵坐标轴图像
效果图: 代码: 由于使用了两组y axis,如果直接使用ax.legend绘制图例,会得到两个图例。而下面的代码将两个图例合并显示。 import matplotlib.pyplot as plt import numpy as npdata np.random.randint(low0,high5,size(3,4)) …...
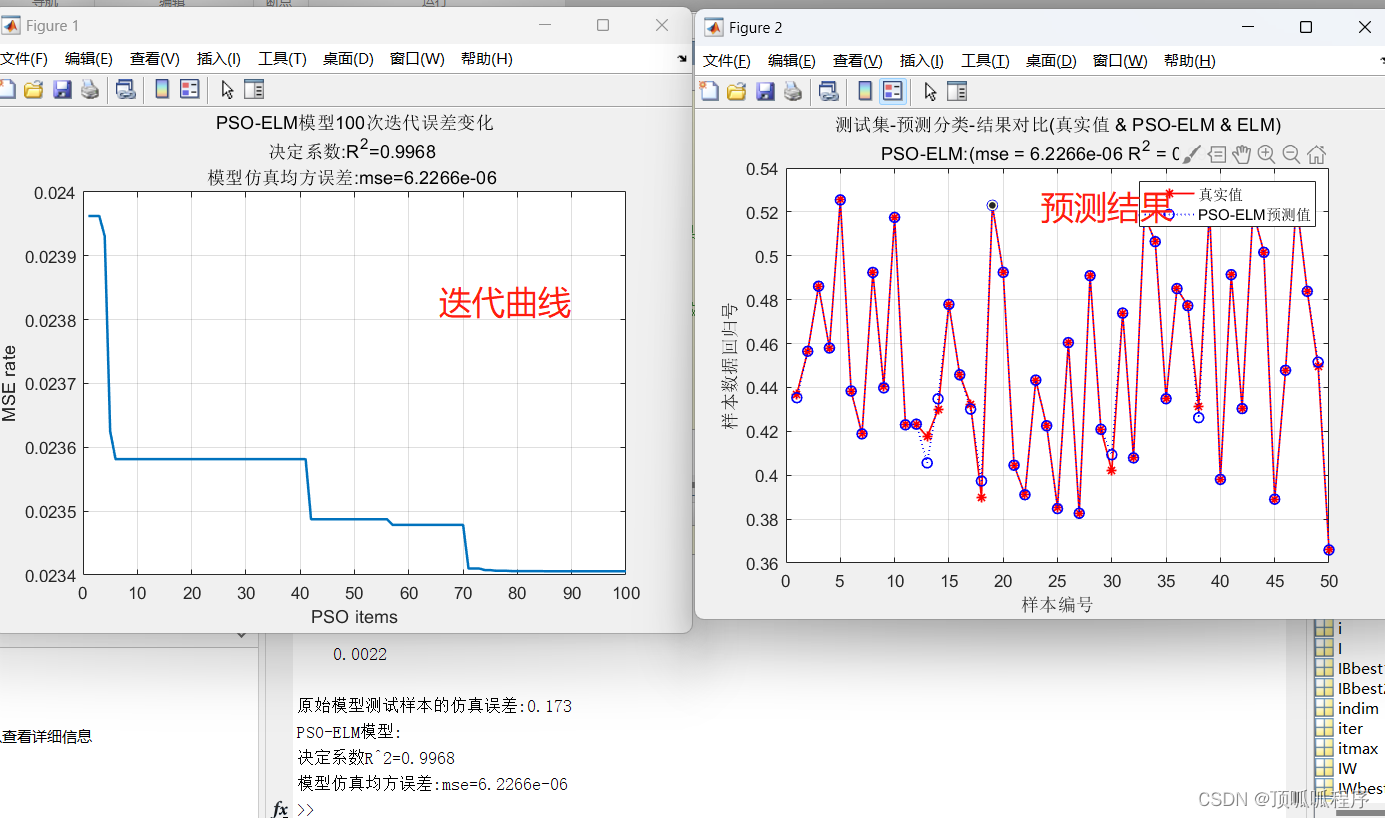
74基于matlab的PSO-ELM的多输入,单输出结果预测,输出训练集和测试机预测结果及误差。
基于matlab的PSO-ELM的多输入,单输出结果预测,输出训练集和测试机预测结果及误差,适应度值。数据可更换自己的,程序已调通,可直接运行。 74matlabPSO-ELM多输入单输出 (xiaohongshu.com)...

shell之head命令
head命令 head命令是UNIX和Linux环境中常用的命令,用于在标准输出上显示文件的开头内容。 具体来说,head命令默认会显示给定文件开头的10行内容。如果指定了多个文件名,head命令会逐个显示每个文件的开头内容,并在每个文件显示的…...
)
网络安全之了解安全托管服务(MSS)
数字化已深入千行百业。数字化将给各行各业带来巨大的变化,现实世界和虚拟世界也将联系得更加紧密。随着云计算、大数据等新技术结合企业级业务的落地,数字时代的安全面临着前所未有的新挑战。近年来,网络安全问题日益严重,在企业…...
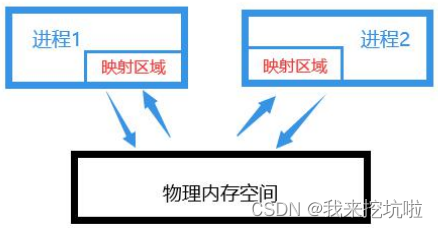
linux进程间通信之共享内存(mmap,shm_open)
共享内存,顾名思义就是允许两个不相关的进程访问同一个逻辑内存,共享内存是两个正在运行的进 程之间共享和传递数据的一种非常有效的方式。不同进程之间共享的内存通常为同一段物理内存。进程可以将同一段物理内存连接到他们自己的地址空间中,…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...