基于Pytorch的从零开始的目标检测
引言
目标检测是计算机视觉中一个非常流行的任务,在这个任务中,给定一个图像,你预测图像中物体的包围盒(通常是矩形的) ,并且识别物体的类型。在这个图像中可能有多个对象,而且现在有各种先进的技术和框架来解决这个问题,例如 Faster-RCNN 和 YOLOv3。
本文讨论将讨论图像中只有一个感兴趣的对象的情况。这里的重点更多是关于如何读取图像及其边界框、调整大小和正确执行增强,而不是模型本身。目标是很好地掌握对象检测背后的基本思想,你可以对其进行扩展以更好地理解更复杂的技术。
本文中的所有代码都在下面的链接中:https://jovian.ai/aakanksha-ns/road-signs-bounding-box-prediction
问题陈述
给定一个由路标组成的图像,预测路标周围的包围盒,并识别路标的类型。这些路标包括以下四种:
· 红绿灯
· 停止
· 车速限制
· 人行横道
这就是所谓的多任务学习问题,因为它涉及执行两个任务: 1)回归找到包围盒坐标,2)分类识别道路标志的类型

数据集
我使用了来自 Kaggle 的道路标志检测数据集,链接如下:https://www.kaggle.com/andrewmvd/road-sign-detection
它由877张图像组成。这是一个相当不平衡的数据集,大多数图像属于限速类,但由于我们更关注边界框预测,因此可以忽略不平衡。
加载数据
每个图像的注释都存储在单独的 XML 文件中。我按照以下步骤创建了训练数据集:
· 遍历训练目录以获得所有.xml 文件的列表。
· 使用xml.etree.ElementTree解析.xml文件。
· 创建一个由文件路径、宽度、高度、边界框坐标( xmin 、 xmax 、 ymin 、 ymax )和每个图像的类组成的字典,并将字典附加到列表中。
· 使用图像统计数据字典列表创建一个 Pandas 数据库。
def filelist(root, file_type):"""Returns a fully-qualified list of filenames under root directory"""return [os.path.join(directory_path, f) for directory_path, directory_name, files in os.walk(root) for f in files if f.endswith(file_type)]def generate_train_df (anno_path):annotations = filelist(anno_path, '.xml')anno_list = []for anno_path in annotations:root = ET.parse(anno_path).getroot()anno = {}anno['filename'] = Path(str(images_path) + '/'+ root.find("./filename").text)anno['width'] = root.find("./size/width").textanno['height'] = root.find("./size/height").textanno['class'] = root.find("./object/name").textanno['xmin'] = int(root.find("./object/bndbox/xmin").text)anno['ymin'] = int(root.find("./object/bndbox/ymin").text)anno['xmax'] = int(root.find("./object/bndbox/xmax").text)anno['ymax'] = int(root.find("./object/bndbox/ymax").text)anno_list.append(anno)return pd.DataFrame(anno_list)· 标签编码类列
#label encode target
class_dict = {'speedlimit': 0, 'stop': 1, 'crosswalk': 2, 'trafficlight': 3}
df_train['class'] = df_train['class'].apply(lambda x: class_dict[x])调整图像和边界框的大小
由于训练一个计算机视觉模型需要的图像是相同的大小,我们需要调整我们的图像和他们相应的包围盒。调整图像的大小很简单,但是调整包围盒的大小有点棘手,因为每个包围盒都与图像及其尺寸相关。
下面是调整包围盒大小的工作原理:
· 将边界框转换为与其对应的图像大小相同的图像(称为掩码)。这个掩码只有 0 表示背景,1 表示边界框覆盖的区域。
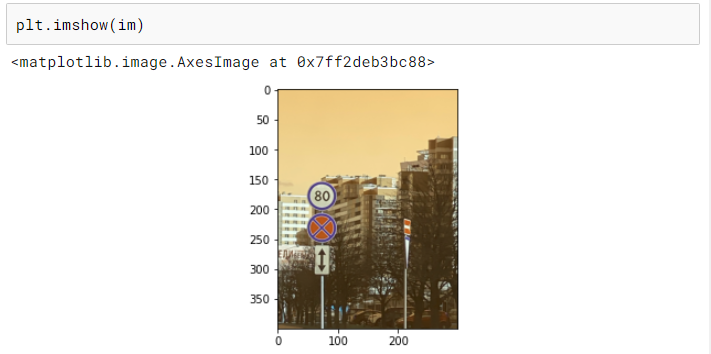
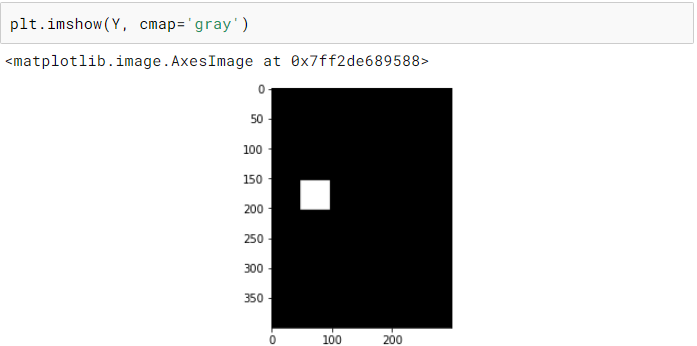
· 将掩码调整到所需的尺寸。
· 从调整完大小的掩码中提取边界框坐标。
def create_mask(bb, x):"""Creates a mask for the bounding box of same shape as image"""rows,cols,*_ = x.shapeY = np.zeros((rows, cols))bb = bb.astype(np.int)Y[bb[0]:bb[2], bb[1]:bb[3]] = 1.return Ydef mask_to_bb(Y):"""Convert mask Y to a bounding box, assumes 0 as background nonzero object"""cols, rows = np.nonzero(Y)if len(cols)==0: return np.zeros(4, dtype=np.float32)top_row = np.min(rows)left_col = np.min(cols)bottom_row = np.max(rows)right_col = np.max(cols)return np.array([left_col, top_row, right_col, bottom_row], dtype=np.float32)def create_bb_array(x):"""Generates bounding box array from a train_df row"""return np.array([x[5],x[4],x[7],x[6]])def resize_image_bb(read_path,write_path,bb,sz):"""Resize an image and its bounding box and write image to new path"""im = read_image(read_path)im_resized = cv2.resize(im, (int(1.49*sz), sz))Y_resized = cv2.resize(create_mask(bb, im), (int(1.49*sz), sz))new_path = str(write_path/read_path.parts[-1])cv2.imwrite(new_path, cv2.cvtColor(im_resized, cv2.COLOR_RGB2BGR))return new_path, mask_to_bb(Y_resized)#Populating Training DF with new paths and bounding boxes
new_paths = []
new_bbs = []
train_path_resized = Path('./road_signs/images_resized')
for index, row in df_train.iterrows():new_path,new_bb = resize_image_bb(row['filename'], train_path_resized, create_bb_array(row.values),300)new_paths.append(new_path)new_bbs.append(new_bb)
df_train['new_path'] = new_paths
df_train['new_bb'] = new_bbs数据增强
数据增强是一种通过使用现有图像的不同变体创建新的训练图像来更好地概括我们的模型的技术。我们当前的训练集中只有 800 张图像,因此数据增强对于确保我们的模型不会过拟合非常重要。
对于这个问题,我使用了翻转、旋转、中心裁剪和随机裁剪。
这里唯一需要记住的是确保包围盒也以与图像相同的方式进行转换。
# modified from fast.ai
def crop(im, r, c, target_r, target_c): return im[r:r+target_r, c:c+target_c]# random crop to the original size
def random_crop(x, r_pix=8):""" Returns a random crop"""r, c,*_ = x.shapec_pix = round(r_pix*c/r)rand_r = random.uniform(0, 1)rand_c = random.uniform(0, 1)start_r = np.floor(2*rand_r*r_pix).astype(int)start_c = np.floor(2*rand_c*c_pix).astype(int)return crop(x, start_r, start_c, r-2*r_pix, c-2*c_pix)def center_crop(x, r_pix=8):r, c,*_ = x.shapec_pix = round(r_pix*c/r)return crop(x, r_pix, c_pix, r-2*r_pix, c-2*c_pix)def rotate_cv(im, deg, y=False, mode=cv2.BORDER_REFLECT, interpolation=cv2.INTER_AREA):""" Rotates an image by deg degrees"""r,c,*_ = im.shapeM = cv2.getRotationMatrix2D((c/2,r/2),deg,1)if y:return cv2.warpAffine(im, M,(c,r), borderMode=cv2.BORDER_CONSTANT)return cv2.warpAffine(im,M,(c,r), borderMode=mode, flags=cv2.WARP_FILL_OUTLIERS+interpolation)def random_cropXY(x, Y, r_pix=8):""" Returns a random crop"""r, c,*_ = x.shapec_pix = round(r_pix*c/r)rand_r = random.uniform(0, 1)rand_c = random.uniform(0, 1)start_r = np.floor(2*rand_r*r_pix).astype(int)start_c = np.floor(2*rand_c*c_pix).astype(int)xx = crop(x, start_r, start_c, r-2*r_pix, c-2*c_pix)YY = crop(Y, start_r, start_c, r-2*r_pix, c-2*c_pix)return xx, YYdef transformsXY(path, bb, transforms):x = cv2.imread(str(path)).astype(np.float32)x = cv2.cvtColor(x, cv2.COLOR_BGR2RGB)/255Y = create_mask(bb, x)if transforms:rdeg = (np.random.random()-.50)*20x = rotate_cv(x, rdeg)Y = rotate_cv(Y, rdeg, y=True)if np.random.random() > 0.5: x = np.fliplr(x).copy()Y = np.fliplr(Y).copy()x, Y = random_cropXY(x, Y)else:x, Y = center_crop(x), center_crop(Y)return x, mask_to_bb(Y)def create_corner_rect(bb, color='red'):bb = np.array(bb, dtype=np.float32)return plt.Rectangle((bb[1], bb[0]), bb[3]-bb[1], bb[2]-bb[0], color=color,fill=False, lw=3)def show_corner_bb(im, bb):plt.imshow(im)plt.gca().add_patch(create_corner_rect(bb))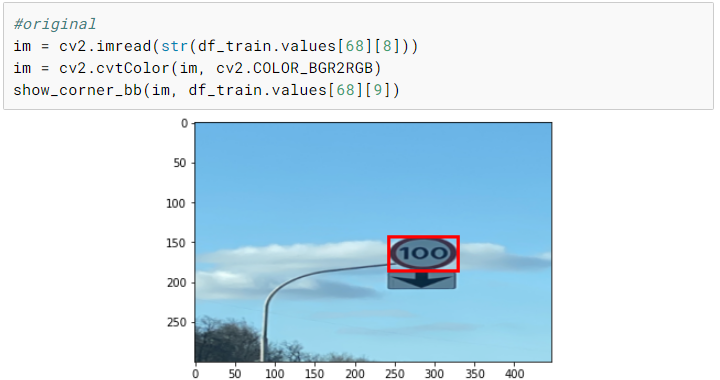
PyTorch 数据集
现在我们已经有了数据增强,我们可以进行训练验证拆分并创建我们的 PyTorch 数据集。我们使用 ImageNet 统计数据对图像进行标准化,因为我们使用的是预训练的 ResNet 模型并在训练时在我们的数据集中应用数据增强。
X_train, X_val, y_train, y_val = train_test_split(X, Y, test_size=0.2, random_state=42)def normalize(im):"""Normalizes images with Imagenet stats."""imagenet_stats = np.array([[0.485, 0.456, 0.406], [0.229, 0.224, 0.225]])return (im - imagenet_stats[0])/imagenet_stats[1]class RoadDataset(Dataset):def __init__(self, paths, bb, y, transforms=False):self.transforms = transformsself.paths = paths.valuesself.bb = bb.valuesself.y = y.valuesdef __len__(self):return len(self.paths)def __getitem__(self, idx):path = self.paths[idx]y_class = self.y[idx]x, y_bb = transformsXY(path, self.bb[idx], self.transforms)x = normalize(x)x = np.rollaxis(x, 2)return x, y_class, y_bbtrain_ds = RoadDataset(X_train['new_path'],X_train['new_bb'] ,y_train, transforms=True)
valid_ds = RoadDataset(X_val['new_path'],X_val['new_bb'],y_val)batch_size = 64
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size=batch_size)PyTorch 模型
对于这个模型,我使用了一个非常简单的预先训练的 resNet-34模型。由于我们有两个任务要完成,这里有两个最后的层: 包围盒回归器和图像分类器。
class BB_model(nn.Module):def __init__(self):super(BB_model, self).__init__()resnet = models.resnet34(pretrained=True)layers = list(resnet.children())[:8]self.features1 = nn.Sequential(*layers[:6])self.features2 = nn.Sequential(*layers[6:])self.classifier = nn.Sequential(nn.BatchNorm1d(512), nn.Linear(512, 4))self.bb = nn.Sequential(nn.BatchNorm1d(512), nn.Linear(512, 4))def forward(self, x):x = self.features1(x)x = self.features2(x)x = F.relu(x)x = nn.AdaptiveAvgPool2d((1,1))(x)x = x.view(x.shape[0], -1)return self.classifier(x), self.bb(x)训练
对于损失,我们需要同时考虑分类损失和边界框回归损失,因此我们使用交叉熵和 L1 损失(真实值和预测坐标之间的所有绝对差之和)的组合。我已经将 L1 损失缩放了 1000 倍,因为分类和回归损失都在相似的范围内。除此之外,它是一个标准的 PyTorch 训练循环(使用 GPU):
def update_optimizer(optimizer, lr):for i, param_group in enumerate(optimizer.param_groups):param_group["lr"] = lrdef train_epocs(model, optimizer, train_dl, val_dl, epochs=10,C=1000):idx = 0for i in range(epochs):model.train()total = 0sum_loss = 0for x, y_class, y_bb in train_dl:batch = y_class.shape[0]x = x.cuda().float()y_class = y_class.cuda()y_bb = y_bb.cuda().float()out_class, out_bb = model(x)loss_class = F.cross_entropy(out_class, y_class, reduction="sum")loss_bb = F.l1_loss(out_bb, y_bb, reduction="none").sum(1)loss_bb = loss_bb.sum()loss = loss_class + loss_bb/Coptimizer.zero_grad()loss.backward()optimizer.step()idx += 1total += batchsum_loss += loss.item()train_loss = sum_loss/totalval_loss, val_acc = val_metrics(model, valid_dl, C)print("train_loss %.3f val_loss %.3f val_acc %.3f" % (train_loss, val_loss, val_acc))return sum_loss/totaldef val_metrics(model, valid_dl, C=1000):model.eval()total = 0sum_loss = 0correct = 0 for x, y_class, y_bb in valid_dl:batch = y_class.shape[0]x = x.cuda().float()y_class = y_class.cuda()y_bb = y_bb.cuda().float()out_class, out_bb = model(x)loss_class = F.cross_entropy(out_class, y_class, reduction="sum")loss_bb = F.l1_loss(out_bb, y_bb, reduction="none").sum(1)loss_bb = loss_bb.sum()loss = loss_class + loss_bb/C_, pred = torch.max(out_class, 1)correct += pred.eq(y_class).sum().item()sum_loss += loss.item()total += batchreturn sum_loss/total, correct/totalmodel = BB_model().cuda()
parameters = filter(lambda p: p.requires_grad, model.parameters())
optimizer = torch.optim.Adam(parameters, lr=0.006)train_epocs(model, optimizer, train_dl, valid_dl, epochs=15)测试
现在我们已经完成了训练,我们可以选择一个随机图像并在上面测试我们的模型。尽管我们只有相当少量的训练图像,但是我们最终在测试图像上得到了一个相当不错的预测。
使用手机拍摄真实照片并测试模型将是一项有趣的练习。另一个有趣的实验是不执行任何数据增强并训练模型并比较两个模型。
# resizing test image
im = read_image('./road_signs/images_resized/road789.png')
im = cv2.resize(im, (int(1.49*300), 300))
cv2.imwrite('./road_signs/road_signs_test/road789.jpg', cv2.cvtColor(im, cv2.COLOR_RGB2BGR))# test Dataset
test_ds = RoadDataset(pd.DataFrame([{'path':'./road_signs/road_signs_test/road789.jpg'}])['path'],pd.DataFrame([{'bb':np.array([0,0,0,0])}])['bb'],pd.DataFrame([{'y':[0]}])['y'])
x, y_class, y_bb = test_ds[0]xx = torch.FloatTensor(x[None,])
xx.shape# prediction
out_class, out_bb = model(xx.cuda())
out_class, out_bb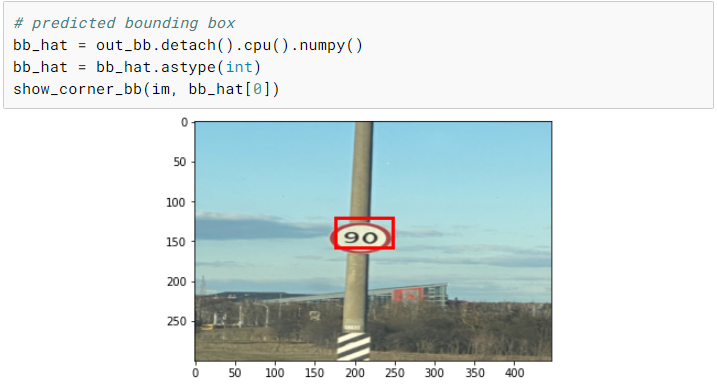
总结
现在我们已经介绍了目标检测的基本原理,并从头开始实现它,您可以将这些想法扩展到多对象情况,并尝试更复杂的模型,如 RCNN 和 YOLO!
相关文章:
基于Pytorch的从零开始的目标检测
引言 目标检测是计算机视觉中一个非常流行的任务,在这个任务中,给定一个图像,你预测图像中物体的包围盒(通常是矩形的) ,并且识别物体的类型。在这个图像中可能有多个对象,而且现在有各种先进的技术和框架来解决这个问…...
interview review
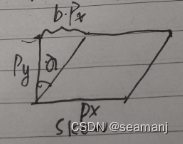
M: intrinsic matrix [ f x s c x 0 f y c y 0 0 1 ] \begin{bmatrix}f_x & s & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1\end{bmatrix} fx00sfy0cxcy1 ( c x , c y ) (c_x, c_y) (cx,cy): camera center in pixels ( f x , f y …...

layui表头多出一列(已解决)
问题描述 :layui表头多出来一列,但是表体没有内容,很影响美观。 好像是原本的表格有滚轮,我操作放大之后滚轮没有了,但是滚轮自带的表头样式还在, 之后手动把这个样式隐藏掉了,代码如下…...

LeetCode解法汇总307. 区域和检索 - 数组可修改
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个数…...
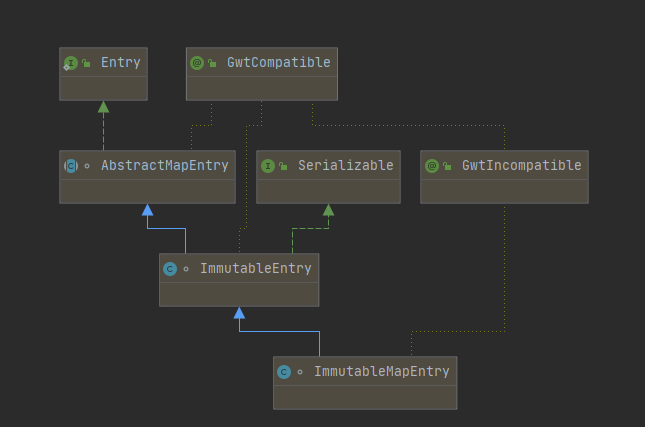
Java源码分析:Guava之不可变集合ImmutableMap的源码分析
原创/朱季谦 一、案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样—— public static final Map<String,String> dayMap new HashMap<>(); static {dayMap.put("Monday&q…...
详解自动化测试之 Selenium
目录 1. 什么是自动化 2.自动化测试的分类 3. selenium(web 自动化测试工具) 1)选择 selenium 的原因 2)环境部署 3)什么是驱动? 4. 一个简单的自动化例子 5.selenium 常用方法 5.1 查找页面元素&…...
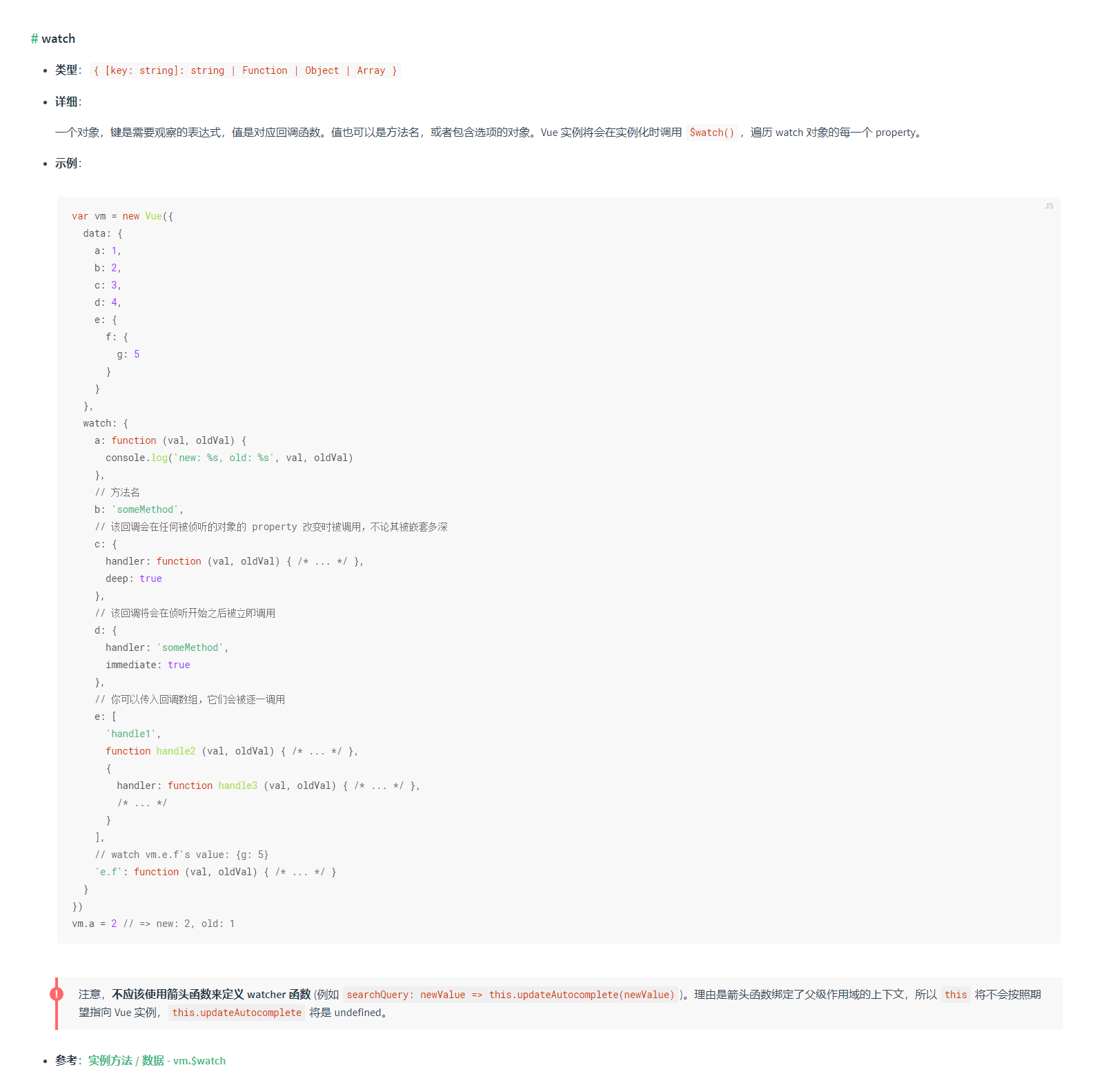
vue监听对象属性值变化
一、官方文档 二、实现方法 方法一、直接根据watch来监听 export default {data() {return {object: {username: ,password: }}},watch: {object.username(newVal, oldVal) {console.log(newVal, oldVal)}} }方法二:利用watch和computed来实现监听 利用computed定…...
)
Unicode编码的emoji表情如何在前端页面展示(未完成)
Unicode编码的emoji表情如何在前端页面展示 一、首先几个定义解决办法 一、首先几个定义 U1F601 和 0x1F601 表示同一个 Unicode 代码点,即笑脸 Emoji 的代码点。它们之间的区别在于表示方式和数据类型。 1.U1F601 是一种常见的表示方式,也称为 “U” 标…...
基于SSM的设备配件管理和设备检修系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
鸿蒙开发|鸿蒙系统项目开发前的准备工作
文章目录 鸿蒙项目开发的基本流程介绍鸿蒙项目开发和其他项目有什么不同成为华为开发者-注册和实名认证1.登录官方网站 鸿蒙项目开发的基本流程介绍 直接上图,简单易懂! 整个项目的开发通过4个模块进行:开发准备、开发应用、运行调试测试和发…...
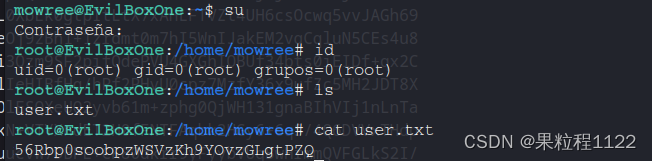
Evil靶场
Evil 1.主机发现 使用命令探测存活主机,80.139是kali的地址,所以靶机地址就是80.134 fping -gaq 192.168.80.0/242.端口扫描 开放80,22端口 nmap -Pn -sV -p- -A 192.168.80.1343.信息收集 访问web界面 路径扫描 gobuster dir -u http…...

第77题. 组合
原题链接:第77题. 组合 全代码: class Solution { private:vector<vector<int>> result; // 存放符合条件结果的集合vector<int> path; // 用来存放符合条件结果void backtracking(int n, int k, int startIndex) {if (path.size() …...

读书笔记:彼得·德鲁克《认识管理》第21章 企业与政府
一、章节内容概述 企业社会责任最重要的维度之一是政企关系。无论对于企业的顺利运作,还是对于政府的顺利运作,政企关系都至关重要。然而,重商主义典范和宪政主义典范这两种传统理论越来越不适应社会现实,越来越失效。虽然当前尚…...

C/C++疫情集中隔离 2021年12月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C疫情集中隔离 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C疫情集中隔离 2021年12月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 A同学12月初从国外回来,按照防疫要…...

052-第三代软件开发-系统监测
第三代软件开发-系统监测 文章目录 第三代软件开发-系统监测项目介绍系统监测 关键字: Qt、 Qml、 cpu、 内存、memory 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object Language)和 C 的强大功…...

向量矩阵范数pytorch
向量矩阵范数pytorch 矩阵按照某个维度求和(dim就是shape数组的下标)1. torch1.1 Tensors一些常用函数 一些安装问题cd进不去不去目录PyTorch里面_表示重写内容 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值 范数是向量或…...
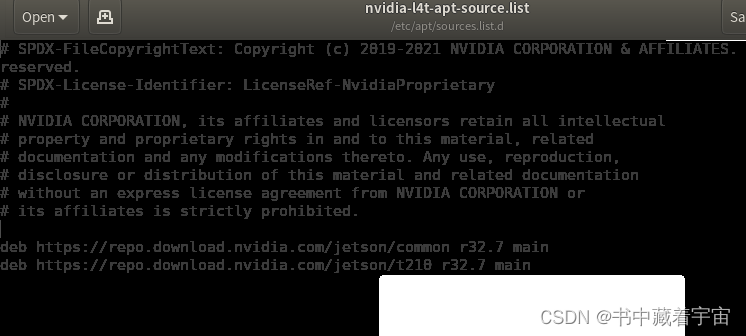
NVIDIA Jetson OTA升级
从 JetPack 4.4 开始,可以使用包管理工具升级到下一个 JetPack 版本。请按照以下步骤执行升级。 1,小版本升级 (如,从 JetPack 4.4 升级到 JetPack 4.4.1) 第一步: sudo apt update 第二步: apt list --upgradable 第三步: sudo apt upgrade更新完之后重新启动即可 …...

【算法】算法题-20231118
这里写目录标题 一、16.17. 连续数列二、合并两个有序数组(力扣88)三、存在重复元素(217)四、有效的字母异位词(242) 一、16.17. 连续数列 简单 给定一个整数数组,找出总和最大的连续数列&…...
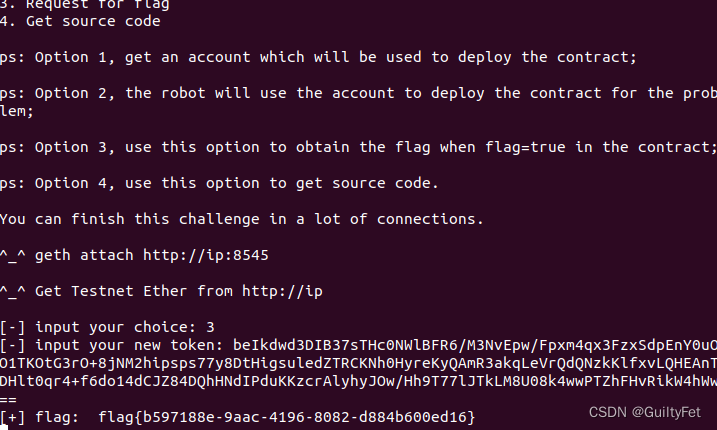
某60区块链安全之整数溢出漏洞实战学习记录
区块链安全 文章目录 区块链安全整数溢出漏洞实战实验目的实验环境实验工具实验原理攻击过程分析合约源代码漏洞EXP利用 整数溢出漏洞实战 实验目的 学会使用python3的web3模块 学会以太坊整数溢出漏洞分析及利用 实验环境 Ubuntu18.04操作机 实验工具 python3 实验原理…...
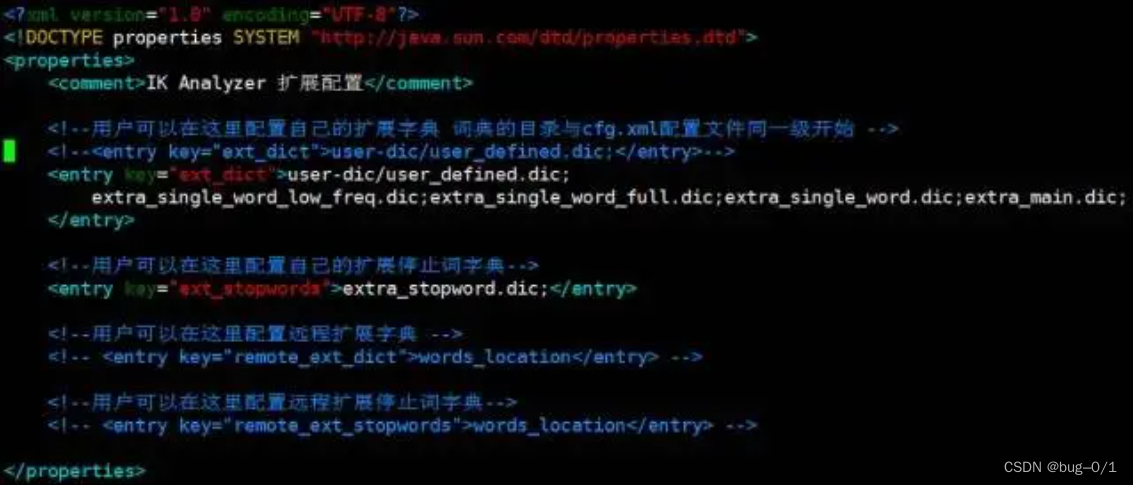
图数据库Neo4J 中文分词查询及全文检索(建立全文索引)
Neo4j的全文索引是基于Lucene实现的,但是Lucene默认情况下只提供了基于英文的分词器,下篇文章我们在讨论中文分词器(IK)的引用,本篇默认基于英文分词来做。我们前边文章就举例说明过,比如我要搜索苹果公司&…...

modelsim crack过程中显示dll文件找不到解决方法
把这几个文件放到modelsim/win64目录下,按照教程点击patch64生成license时会报错,如下找不到文件 - mgls.dll找不到文件 - mgls64.dll这个时候关闭杀毒软件进入你的 D:\modeltech64_10.5\win64 文件夹。在文件夹上方的地址栏(显示路径的地方&…...

Gemma-3-12b-it实战教程:对接企业微信/钉钉机器人实现图文消息自动解析
Gemma-3-12b-it实战教程:对接企业微信/钉钉机器人实现图文消息自动解析 1. 引言:当多模态AI遇上企业协作 想象一下这个场景:你的同事在企业微信群里发了一张复杂的业务流程图,问“这个流程的第三步有什么风险?”或者…...

数据迁移技术指南:Obsidian跨平台笔记整合解决方案
数据迁移技术指南:Obsidian跨平台笔记整合解决方案 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-importer …...

Qwen3.5-4B-Claude-Opus企业实操:数据治理元数据血缘关系推理补全工具
Qwen3.5-4B-Claude-Opus企业实操:数据治理元数据血缘关系推理补全工具 1. 平台概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B架构的推理蒸馏模型,专门针对企业级数据治理场景中的元数据血缘关系分析任务进行了优化。该模…...
:为什么92%的团队还在用Pandas硬扛TB级脏数据?)
Polars 2.0清洗架构解密(含完整数据流拓扑图):为什么92%的团队还在用Pandas硬扛TB级脏数据?
第一章:Polars 2.0清洗架构解密:从设计哲学到性能跃迁Polars 2.0 的清洗架构并非简单功能叠加,而是以“零拷贝流式处理”与“惰性执行图优化”为双核驱动的范式重构。其设计哲学根植于两个核心信条:数据不应在内存中被无谓复制&am…...

AR.js终极指南:在Web浏览器中实现高效增强现实的完整解决方案
AR.js终极指南:在Web浏览器中实现高效增强现实的完整解决方案 【免费下载链接】AR.js Image tracking, Location Based AR, Marker tracking. All on the Web. 项目地址: https://gitcode.com/gh_mirrors/arj/AR.js AR.js是一个轻量级JavaScript库࿰…...

终极指南:nanoGPT如何让每个人都能训练自己的AI语言模型?
终极指南:nanoGPT如何让每个人都能训练自己的AI语言模型? 【免费下载链接】nanoGPT The simplest, fastest repository for training/finetuning medium-sized GPTs. 项目地址: https://gitcode.com/GitHub_Trending/na/nanoGPT 想要训练自己的AI…...

Qwen3-0.6B-FP8效果展示:中英混合输入、长上下文保持、多轮记忆实测
Qwen3-0.6B-FP8效果展示:中英混合输入、长上下文保持、多轮记忆实测 1. 开篇:小模型,大能耐 你可能听过很多关于大语言模型的讨论,动辄几十亿、上百亿参数,部署起来对硬件要求极高。但今天我想跟你聊点不一样的——一…...
)
从漏极、栅极到源极开关:手把手教你选对单端电荷泵拓扑(基于噪声与速度权衡)
从漏极、栅极到源极开关:单端电荷泵拓扑的噪声与速度权衡实战指南 在锁相环(PLL)设计中,电荷泵的性能往往成为整个系统相位噪声和杂散特性的瓶颈。特别是当设计目标同时包含低带内相位噪声和高开关速度时,单端电荷泵的拓扑选择就变得尤为关键…...

macOS Unlocker V3.0:在Windows和Linux上免费运行macOS虚拟机的终极解决方案 [特殊字符]
macOS Unlocker V3.0:在Windows和Linux上免费运行macOS虚拟机的终极解决方案 🚀 【免费下载链接】unlocker 项目地址: https://gitcode.com/gh_mirrors/unlo/unlocker macOS Unlocker V3.0是一款革命性的开源工具,让您能够在Windows或…...