Elasticsearch总结笔记
文章目录
- 简介
- 类型
- 增删改查操作
- 索引原理
简介
- 底层使用的lucene引擎,lucene引擎直接使用相对复杂,有一定的学习成本,同样是使用Java编写,Elasticsearch使用的rest风格的进行交互,而数据呢则是以JSON的方式进行传输。
- 学习Elasticsearch要求使用的JDK版本在8以上。Elasticsearch主要用于检索,尤其是其全文检索的能力,以及自带乐观锁以及友好的集群,让它越来越受欢迎。
- 使用Elasticsearch首先要指定是如何定位数据。即三要素进行定位,index索引,type类型,id主键(
_index,_type,_id) - PUT,DELETE,POST,GET(使用的方法都是
大写,大括号在请求下一行)4种REST请求方式即完成增删改查,当然在ES中改其实是先把旧的移除,重新创建一个新的文档,PUT也可以更新,但是是整体更新,POST则是可以内容追加,不过也是一个新的文档。 - 1.映射(
Mapping)
描述数据在每个字段内如何存储
2.分析(Analysis)
全文是如何处理使之可以被搜索的
3.领域特定查询语言(Query DSL)
Elasticsearch 中强大灵活的查询语言
类型
ES的基本类型有:(和关系型SQL区别不需要设置字段的长度)
字符串:text,keyword
数字类型:integer,long
浮点类型"float,double,
布尔类型:boolean,
时间类型:date
在ES中默认只有text类型可以分词,分词使用英文引擎,按照单词分词,如果是中文进行查询的话,则是将数据变成单字分词
增删改查操作
查:
GET /索引名(即数据库)/_doc/_id(记录id值)
增(覆盖式)
PUT /索引名(即数据库)/_doc/_id(记录id值)
{_id:''
}
改:(增量式)
POST /索引名(即数据库)/_doc/_id(记录id值)
{要修改的字段
}
删除
DELETE /索引名(即数据库)/_doc/_id(记录id值)
批量操作
POST /索引名(即数据库)/_doc/_bulk
{批量的文档(需注意每行文档记录不能换行)
}
高级查询:(Query DSL)
1.查询所有
GET /索引名(即数据库)/_search
{"query":{"match_all":{}}
}
2.term条件查询
GET /索引名(即数据库)/_search
{"query":{"term":{}}
}
3.range范围查询
GET /索引名(即数据库)/_search
{"query":{"range":{"字段":{"gt":"值","lte":"值"}}}
}
3.前缀查询
GET /索引名(即数据库)/_search
{"query":{"prefix":{"字段":"值"}}
}
4.通配符查询
*是通配(可以匹配多个长度的),?是占位(匹配固定长度,如goo?,可匹配good,但不能god,匹配的字符长度是固定的)
GET /索引名/_search
{"query": {"wildcard": {"字段": {"value": "值* "}}}
}
5.ids查询
GET /索引名/_search
{"query": {"ids": {"values": id数组}}
}
6.模糊查询[fuzzy]
GET /products/_search
{"query": {"fuzzy": {"字段":"值"}}
}
模糊查询[fuzzy],切记使用有以下规则
fuzzy 关键字: ⽤来模糊查询含有指定关键字的⽂档
注意: fuzzy 模糊查询 最⼤模糊错误 必须在0-2之间
搜索关键词⻓度为 2 不允许存在模糊
搜索关键词⻓度为3-5 允许⼀次模糊
搜索关键词⻓度⼤于5 允许最⼤2模糊
7.布尔查询
这个其实就是基本类似于关系性SQL中的:exist,not exist 等语法
bool 关键字: ⽤来组合多个条件实现复杂查询
must: 相当于&& 同时成⽴
should: 相当于|| 成⽴⼀个就⾏
must_not: 相当于! 不能满⾜任何⼀个
GET /索引名/_search
{"query": {"bool": {"must": [{"term":{要求的条件JSON}}]}}
}
8.多字段查询[multi_match]
GET /索引名/_search
{"query": {"multi_match": {"query": "值","fields":字段数组}}
}
注意: 字段类型分词,将查询条件分词之后进⾏查询改字段 如果该字段不分词就会
将查询条件作为整体进⾏查询
9.默认字段分词查询[query_string]
GET /索引名/_search
{"query": {"query_string": {"default_field": "查询字段","query": "值"}}
}
注意: 查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
10.⾼亮查询[highlight]
highlight 关键字: 可以让符合条件的⽂档中的关键词⾼亮
GET /索引名/_search
{"query": {"term": {"字段": {"value": "值"}}},"highlight": {"fields": {"*":{}}}
}
⾃定义⾼亮html标签: 可以在highlight中使⽤ pre_tags 和 post_tags
GET /索引名/_search
{"query": {"term": {"字段": {"value": "值"}}},"highlight": {"post_tags": ["</span>"],"pre_tags": ["<span style='color:red'>"],"fields": {"*":{}}}
}
多字段⾼亮 使⽤ require_field_match 开启多个字段⾼亮
GET /索引名/_search
{"query": {"term": {"字段": {"value": "值"}}},"highlight": {"require_field_match": "false","post_tags": ["</span>"],"pre_tags": ["<span style='color:red'>"],"fields": {"*":{}}}
}
11.分页查询
利用from,和size,起始页同样是0开始,0即第一页
返回指定条数[size]
size 关键字: 指定查询结果中返回指定条数。 默认返回值10条
分⻚查询[form]
from 关键字: ⽤来指定起始返回位置,和size关键字连⽤可实现分⻚效
果
GET /索引/_search
{"query": {"match_all": {}},"size": 5,"from": 0
}
指定字段排序[sort]
GET /索引名/_search
{"query": {"match_all": {}},"sort": [{"字段": {"order": "desc"}}]
}
12.返回指定字段[_source]
_source 关键字: 是⼀个数组,在数组中⽤来指定展示那些字段
GET /索引名/_search
{"query": {"match_all": {}},"_source": 要展示的指定字段数组
}
索引原理
倒排索引(Inverted Index) 也叫反向索引,有反向索引必有正向索引。
通俗地来讲, 正向索引是通过key找value,反向索引则是通过value找key。
ES底层在检索时底层使⽤的就是倒排索引。
在ES中除了text类型分词,其他类型不分词,因此根据不同字段创建索引。就将文档的内容根据text字段内容先进行一个默认分词,然后将每个分词有默认的,id映射,当我们查询的时候,ES会将我们搜索条件进行分词,再用搜索的分词条件和我们数据的分词内容进行一定的算法匹配,然后找到id,再关联回我们的文档数据,形成一个命中记录集合,并根据匹配算法的匹配程度给文档打分,并返回整一个结果集
本质是使用了空间换时间的实现,搜索来了只要拿搜索关键词和我们的分词关键词比较即可,所以会很快。
注意: Elasticsearch : Elasticsearch分别为每个字段都建⽴了⼀个倒排索引。因此查询
时查询字段的term, term,就能知道⽂档ID,就能快速找到⽂档。
相关文章:

Elasticsearch总结笔记
文章目录简介类型增删改查操作索引原理简介 底层使用的lucene引擎,lucene引擎直接使用相对复杂,有一定的学习成本,同样是使用Java编写,Elasticsearch使用的rest风格的进行交互,而数据呢则是以JSON的方式进行传输。学习…...
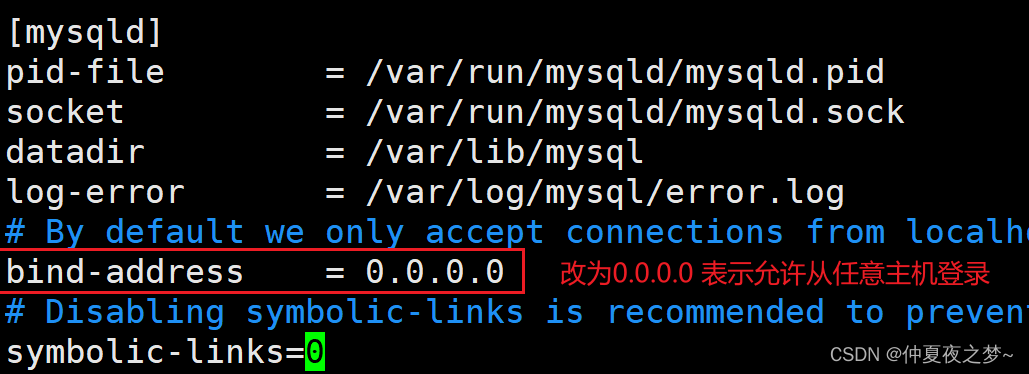
Ubuntu 安装指定版本 Mysql,并设置远程连接(以安装mysql 5.5 为例)
目录 一、安装Mysql 1、卸载Mysql(可跳过) 2、安装mysql 软件源 3、安装mysql 5.5 4、验证测试 二、设置远程登录 1、允许使用root账号远程连接 2、Mysql 允许远程登录 一、安装Mysql 1、卸载Mysql(可跳过) 如果之前安装…...

NumPy:Python中的强大数学工具
NumPy:Python中的强大数学工具 文章目录NumPy:Python中的强大数学工具一、NumPy简介二、创建数组三、数组尺寸四、数组运算五、数组切片六、数组连接七、数据存取八、数组形态变换九、数组排序与搜索十、矩阵与线性代数运算一、NumPy简介 当谈到数据科学…...
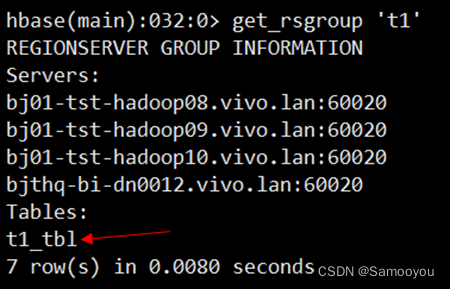
Hbase资源隔离操作指南
1.检查集群的环境配置 1.1 HBase版本号确认> 5.11.0 引入rsgroup的Patch: [HBASE-6721] RegionServer Group based Assignment - ASF JIRA RegionServer Group based Assignment 社区支持版本:2.0.0 引入rsgroup的CDH版本 5.11.0 https://www.…...

TPS2012B泰克Tektronix隔离通道示波器
简 述: 复杂环境中开发和测试你的设计,进行浮动或差 分测量;100MHz,2通道 主要特点和优点 100 MHz和200 MHz带宽 高达2 GS/s的实时采样率 2条或4条全面隔离和浮动通道,外加隔离外部触 发 在安装两块电池时可以连续…...

9.4 PIM-DM
实验目的 熟悉PIM-DM的应用场景掌握PIM-DM的配置方法 实验拓扑 实验拓扑如图9-28所示: 图9-28:PIM-DM 实验步骤 (1)IP地址的配置 MCS1的配置如图9-29所示: 图9-29:配置MCS1的IP地址 R1的配置 <Huawe…...

程序员推荐的良心网站合集!
今天来给大家推荐几个程序员必看的国外良心网站合集。 IBM developer 技术性很强的博客网站,网站自带真实示例代码和架构解决方案,大家可以在上面找到适合自己的语言方向开始学习交流。 https://developer.ibm.com/ infoq 技术论坛社区,内…...

信息安全概论之《密码编码学与网络安全----原理与实践(第八版)》
前言:在信息安全概论课程的学习中,参考了《密码编码学与网络安全----原理与实践(第八版)》一书。以下内容为以课件为主要参考,课本内容与网络资源为辅助参考,学习该课程后作出的总结。 一、信息安全概述 1…...

跬智信息全新推出云原生数据底座玄武,助力国产化数据服务再次升级
2月28日,跬智信息(Kyligence)宣布全新推出国产化云原生数据底座开源项目玄武(XUANWU),以助力企业加速数据平台上云,并实现国产化升级。玄武(XUANWU)是在容器化技术上形成…...
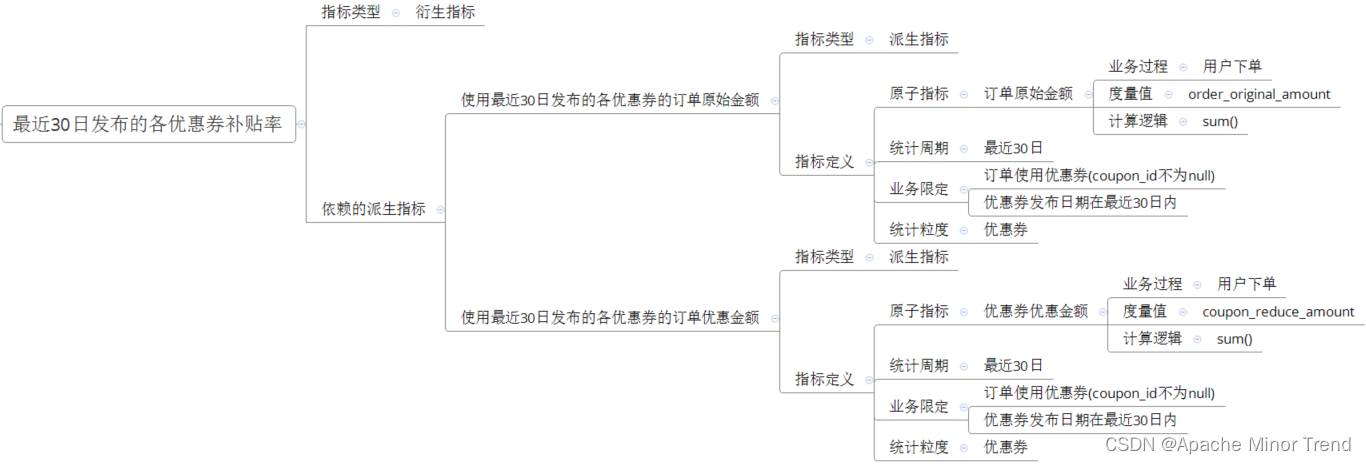
【离线数仓-9-数据仓库开发DWS层设计要点-DWS层汇总表以及数据装载】
离线数仓-9-数据仓库开发DWS层设计要点-DWS层汇总表以及数据装载离线数仓-9-数据仓库开发DWS层设计要点-DWS层汇总表以及数据装载一、交易域用户商品粒度订单最近1日/N日汇总表1.交易域用户商品粒度订单最近1日汇总表2.交易域用户商品粒度订单最近N日汇总表二、交易域优惠券粒度…...

我的十年编程路 序
算起来,从决定并从事编程开始,已十年有余了。 这十年是怎么算的呢? 我的本科是从2009年至2013年,现在回想起来,应该是从2012年下半年,也就是大四还未正式开始的时候决定从事Android开发。参加了培训班&am…...

xs 180
选择题(共180题,合计180.0分) 1. 你被任命为某项目的敏捷教练,为了更好的交付产品,你与团队召开会议,讨论项目过程中团队应该如何做到有效沟通。最有可能确定项目过程中主要以下列哪种方式沟通? A 团队成员在各自的办公室自行办公&#…...
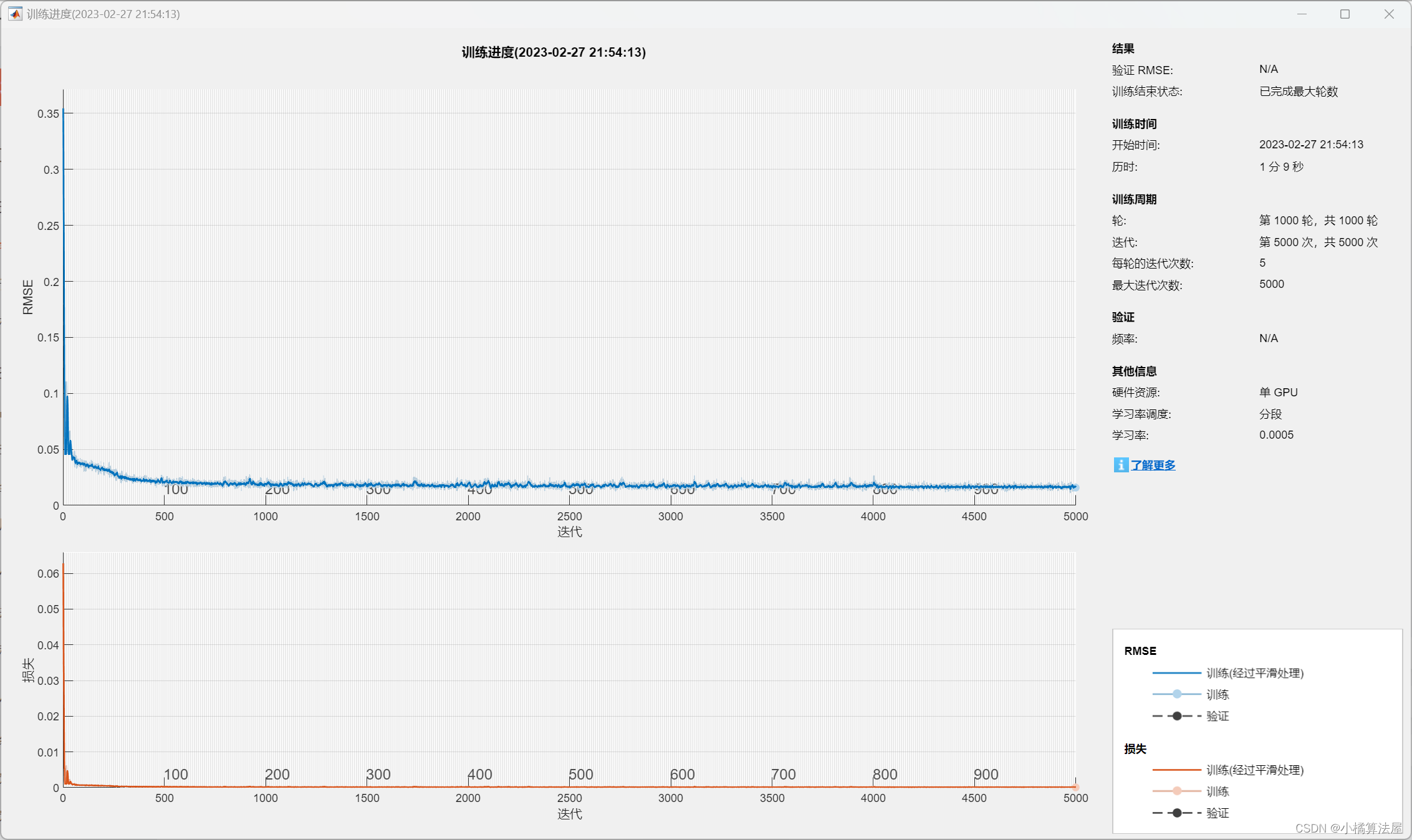
时间序列分析 | BiLSTM双向长短期记忆神经网络时间序列预测(Matlab完整程序)
时间序列分析 | BiLSTM双向长短期记忆神经网络时间序列预测(Matlab完整程序) 目录 时间序列分析 | BiLSTM双向长短期记忆神经网络时间序列预测(Matlab完整程序)预测结果评价指标基本介绍完整程序参考资料预测结果 评价指标 训练集数据的R2为:0.99302 测试集数据的R2为&…...

0101基础-认证授权-springsecurity
文章目录1 基础概念1.1 认证1.2 会话1.3 jwt1.4 授权2 授权的数据模型3 RBAC3.1 基于角色的访问控制3.2 基于资源的访问控制4 名词解析4.1 SSO4.2 CAS4.3 联合登陆4.4 多端登录:同一账号不同终端登录4.5 OAuth1 基础概念 1.1 认证 认证是为了保护系统的隐私数据和…...

一文简单了解THD布局要求
一、什么是THD? THD指总谐波失真。谐波失真是指输出信号比输入信号多出的谐波成分。谐波失真是系统不完全线性造成的。所有附加谐波电平之和称为总谐波失真。总谐波失真与频率有关。一般说来,1000Hz频率处的总谐波失真最小,因此不少产品均以…...
[C++]多态
🥁作者: 华丞臧 📕专栏:【C】 各位读者老爷如果觉得博主写的不错,请诸位多多支持(点赞收藏关注)。如果有错误的地方,欢迎在评论区指出。 推荐一款刷题网站 👉LeetCode 文章目录一、多态…...

中国版ChatGPT高潮即将到来,解密ChatGPT底层网络架构
2022年11月30日人工智能研究实验室OpenAI发布全新聊天机器人ChatGPT,在中国用户无法访问的前提下,上线仅两个月月活用户就突破了1亿。ChatGPT如同重磅炸弹,一时间火遍全球。面对这一万亿级市场机遇,在国内,无论是资本方…...

PingCAP 唐刘:一个咨询顾问对 TiDB Chat2Query Demo 提出的脑洞
导读 近日,TiDB Cloud 发布了 Chat2Query 功能,在 TiDB Cloud 上通过自然语言提问,即可生成相应的 SQL,通过 TiDB Cloud 对上传的任意数据集进行分析。Gartner 也在一份有关 ChatGPT 对数据分析影响研究的报告中提及了 PingCAP 的…...

力扣-销售分析III
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1084. 销售分析III二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其他总结…...

U-Boot 之七 详解 Driver Model 架构、配置、命令、初始化流程
U-Boot 在 2014 年 4 月参考 Linux Kernel 的驱动模型设计并引入了自己的 Driver Model(官方简称 DM) 驱动架构。这个驱动模型(DM)为驱动的定义和访问接口提供了统一的方法,提高了驱动之间的兼容性以及访问的标准性。 …...

科研人狂喜!AI生成的位图可以转矢量图了
今天给大家分享我最近挖到的宝藏科研工具:MedPeer「图片创作」——国内领先的垂直领域AI科研绘图工具,刚好解决我们科研人最头疼的几个痛点。尤其是它的人工绘图转换服务,简直是帮我解决了大麻烦,必须给大家捋捋明白。我们科研人绘…...
)
Mac小白必看:手把手教你找回丢失的Recovery HD分区(附diskutil命令详解)
Mac用户必备技能:深度解析Recovery HD分区修复与diskutil实战指南 当你按下CommandR却只看到闪烁的问号图标时,那种手足无措的感觉我深有体会。Recovery HD分区就像是Mac的急救箱,藏着系统恢复、磁盘修复和时间机器备份等关键工具。但很多用户…...

Android HWASan 详解:硬件标记原理、Clang 启用与排障实践
Android HWASan 详解:硬件标记原理、Clang 启用与排障实践 HWASan(Hardware-assisted AddressSanitizer)是面向 AArch64 的一类 Native(C/C)内存错误检测机制:利用指针与内存区域上的 短标签(T…...

MyBatis 二级缓存脏读真实原因
很多同学熟悉 MyBatis 一级缓存、二级缓存基础用法,但多表联查、跨Mapper更新场景下的缓存脏读漏洞,90%的人都会踩坑。 本文结合完整实战案例,用大白话拆解:脏读如何产生、一级缓存二级缓存双重隐患、Namespace隔离缺陷࿰…...

性价比好的深圳除甲醛公司
深圳作为高密度开发城市,常年保持稳定的新房交付、写字楼翻新与商铺装修需求,装修带来的甲醛残留问题,始终是业主和企业管理者关注的室内安全重点。目前深圳本地已有大量除甲醛服务机构,消费者可根据自身需求筛选适配的服务主体。…...

反射式红外光电管ITR9909:从基础测试到智能车竞赛应用实战
1. ITR9909反射式红外光电管基础入门 第一次拿到ITR9909这个小家伙时,我差点被它朴素的外表骗了。这个直径不到5mm的黑色塑料封装器件,看起来就像普通的三极管,但它的能力可不容小觑。作为智能车竞赛的老玩家,我发现它在信标检测…...

WarcraftHelper:让魔兽争霸3在现代电脑重获新生的终极解决方案
WarcraftHelper:让魔兽争霸3在现代电脑重获新生的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Windows …...

自建S3兼容对象存储:Shebe部署、集成与运维全指南
1. 项目概述:一个面向开发者的开源文件存储与分发解决方案最近在折腾个人项目,需要处理用户上传的图片、文档,还要能快速分发到前端展示。自己搭存储服务吧,从对象存储到CDN,配置起来一堆事儿,用第三方云服…...

在飞腾FT-2000/4与麒麟V10上源码编译VLC:从依赖解析到播放验证的完整实践
1. 环境准备与依赖解析 在飞腾FT-2000/4处理器和麒麟V10系统上编译VLC,首先需要搭建合适的开发环境。我实测发现,麒麟V10自带的软件源有时无法满足所有依赖需求,需要手动补充配置。建议先执行以下基础命令更新系统: sudo yum up…...

Simulink仿真报错‘积分器发散’?别慌,试试把ode45换成ode3并固定步长
Simulink仿真中积分器发散问题的深度解析与实战解决方案 当你在Simulink中进行控制系统仿真时,突然弹出一条令人不安的错误信息——"Derivative not finite"或"singularity",这往往意味着你的仿真遇到了积分器发散问题。这种报错不…...