ClickHouse 语法优化规则
ClickHouse 的 SQL 优化规则是基于RBO(Rule Based Optimization),下面是一些优化规则
1 准备测试用表
1)上传官方的数据集
将visits_v1.tar和hits_v1.tar上传到虚拟机,解压到clickhouse数据路径下
// 解压到clickhouse数据路径
sudo tar -xvf hits_v1.tar -C /var/lib/clickhouse
sudo tar -xvf visits_v1.tar -C /var/lib/clickhouse//修改所属用户
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/data/datasets
sudo chown -R clickhouse:clickhouse /var/lib/clickhouse/metadata/datasets
2)重启clickhouse-server
sudo clickhouse restart
3)执行查询
clickhouse-client --query "SELECT COUNT(*) FROM datasets.hits_v1"
clickhouse-client --query "SELECT COUNT(*) FROM datasets.visits_v1"
注意:官方的tar包,包含了建库、建表语句、数据内容,这种方式不需要手动建库、建表,最方便。
hits_v1表有130多个字段,880多万条数据
visits_v1表有180多个字段,160多万条数据
2 COUNT 优化
在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则会直接使用 system.tables 的 total_rows,例如:
EXPLAIN SELECT count()FROM datasets.hits_v1;Union
Expression (Projection)
Expression (Before ORDER BY and SELECT)
MergingAggregated
ReadNothing (Optimized trivial count)
注意 Optimized trivial count ,这是对 count 的优化。
如果 count 具体的列字段,则不会使用此项优化:
EXPLAIN SELECT count(CounterID) FROM datasets.hits_v1;Union
Expression (Projection)
Expression (Before ORDER BY and SELECT)
Aggregating
Expression (Before GROUP BY)
ReadFromStorage (Read from MergeTree)
3 消除子查询重复字段
下面语句子查询中有两个重复的 id 字段,会被去重:
EXPLAIN SYNTAX SELECT
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM
hits_v1 AS a
LEFT JOIN (
SELECT
UserID,
UserID as HaHa,
VisitID
FROM visits_v1) AS b
USING (UserID)
limit 3;//返回优化语句:
SELECT
UserID,
VisitID,
URL,
b.UserID
FROM hits_v1 AS a
ALL LEFT JOIN
(
SELECT
UserID,
VisitID
FROM visits_v1
) AS b USING (UserID)
LIMIT 3
4 谓词下推
当group by有having子句,但是没有with cube、with rollup 或者with totals修饰的时候,having过滤会下推到where提前过滤。例如下面的查询,HAVING name变成了WHERE name,在group by之前过滤:
EXPLAIN SYNTAX SELECT UserID FROM hits_v1 GROUP BY UserID HAVING UserID = '8585742290196126178';//返回优化语句
SELECT UserID
FROM hits_v1
WHERE UserID = \'8585742290196126178\'
GROUP BY UserID
子查询也支持谓词下推:
EXPLAIN SYNTAX
SELECT *
FROM
(
SELECT UserID
FROM visits_v1
)
WHERE UserID = '8585742290196126178'//返回优化后的语句
SELECT UserID
FROM
(
SELECT UserID
FROM visits_v1
WHERE UserID = \'8585742290196126178\'
)
WHERE UserID = \'8585742290196126178\'再来一个复杂例子:
//返回优化后的语句
SELECT UserID
FROM
(
SELECT UserID
FROM (
SELECT UserID
FROM visits_v1
WHERE UserID = \'8585742290196126178\')
WHERE UserID = \'8585742290196126178\'
UNION ALL
SELECT UserID
FROM (
SELECT UserID
FROM visits_v1
WHERE UserID = \'8585742290196126178\')
WHERE UserID = \'8585742290196126178\'
)
WHERE UserID = \'8585742290196126178\'
5 聚合计算外推
聚合函数内的计算,会外推,例如:
EXPLAIN SYNTAX
SELECT sum(UserID * 2)
FROM visits_v1//返回优化后的语句
SELECT sum(UserID) * 2
FROM visits_v1
6 聚合函数消除
如果对聚合键,也就是 group by key 使用 min、max、any 聚合函数,则将函数消除,例如:
EXPLAIN SYNTAX
SELECTsum(UserID * 2),max(VisitID),max(UserID)
FROM visits_v1
GROUP BY UserID//返回优化后的语句
SELECT sum(UserID) * 2,max(VisitID),
UserID
FROM visits_v1
GROUP BY UserID
7 删除重复的 order by key
例如下面的语句,重复的聚合键 id 字段会被去重:
EXPLAIN SYNTAX
SELECT *
FROM visits_v1
ORDER BY
UserID ASC,
UserID ASC,
VisitID ASC,
VisitID ASC//返回优化后的语句:
select
……
FROM visits_v1
ORDER BY
UserID ASC,
VisitID ASC
8 删除重复的 limit by key
例如下面的语句,重复声明的 name 字段会被去重:
EXPLAIN SYNTAX
SELECT *
FROM visits_v1
LIMIT 3 BY
VisitID,
VisitID
LIMIT 10//返回优化后的语句:
select
……
FROM visits_v1
LIMIT 3 BY VisitID
LIMIT 10
9 删除重复的 USING Key
例如下面的语句,重复的关联键 id 字段会被去重:
EXPLAIN SYNTAX
SELECT
a.UserID,
a.UserID,
b.VisitID,
a.URL,
b.UserID
FROM hits_v1 AS a
LEFT JOIN visits_v1 AS b USING (UserID, UserID)//返回优化后的语句:
SELECT
UserID,
UserID,
VisitID,
URL,
b.UserID
FROM hits_v1 AS a
ALL LEFT JOIN visits_v1 AS b USING (UserID)
10 标量替换
如果子查询只返回一行数据,在被引用的时候用标量替换,例如下面语句中的 total_disk_usage 字段:
EXPLAIN SYNTAX
WITH (
SELECT sum(bytes)
FROM system.parts
WHERE active) AS total_disk_usage
SELECT(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10;//返回优化后的语句:
WITH CAST(0, \'UInt64\') AS total_disk_usage
SELECT (sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10
11 三元运算优化
如果开启了 optimize_if_chain_to_multiif 参数,三元运算符会被替换成 multiIf 函数,例如:
EXPLAIN SYNTAX
SELECT number = 1 ? 'hello' : (number = 2 ? 'world' : 'atguigu')
FROM numbers(10)
settings optimize_if_chain_to_multiif = 1;// 返回优化后的语句:
SELECT multiIf(number = 1, \'hello\', number = 2, \'world\', \'atguigu\')
FROM numbers(10)
SETTINGS optimize_if_chain_to_multiif = 1
相关文章:

ClickHouse 语法优化规则
ClickHouse 的 SQL 优化规则是基于RBO(Rule Based Optimization),下面是一些优化规则 1 准备测试用表 1)上传官方的数据集 将visits_v1.tar和hits_v1.tar上传到虚拟机,解压到clickhouse数据路径下 // 解压到clickhouse数据路径 sudo tar -xvf…...

3-运行第一个docker image-hello world
CentOS7.9下安装完成docker后,我们开始部署第一个docker image-hello world 1.以root用户登录CentOS7.9服务器,拉取centos7 images 命令: docker pull hello-world [root@centos79 ~]# docker pull hello-world Using default tag: latest latest: Pulling from library…...
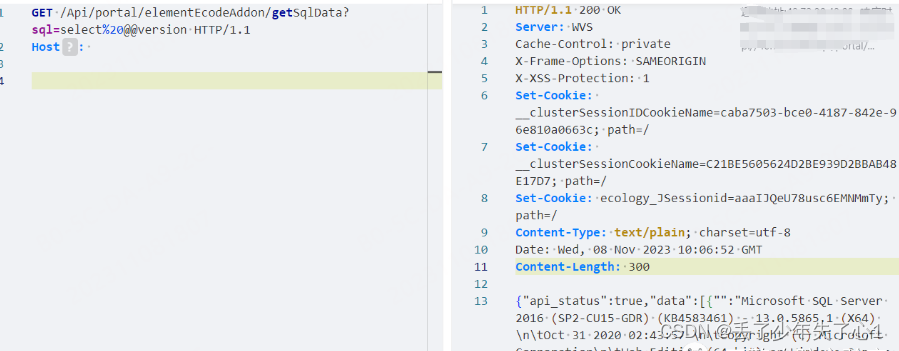
【漏洞复现】泛微e-Weaver SQL注入
漏洞描述 泛微e-Weaver(FANWEI e-Weaver)是一款广泛应用于企业数字化转型领域的集成协同管理平台。作为中国知名的企业级软件解决方案提供商,泛微软件(广州)股份有限公司开发和推广了e-Weaver平台。 泛微e-Weaver旨在…...
「git 系列」git 如何存储代码的?
这里写自定义目录标题 git 文件存储位置git 数据模型示例分析分析前准备命令哈希值 具体示例 不同版本的提交,git 做了什么工作?snapshot vs delta-based vs backup参考资料 git 文件存储位置 想要了解如何存储,首先需要知道存储位置。 当我…...
IDEA 集成 Docker 插件一键部署 SpringBoot 应用
目录 前言IDEA 安装 Docker 插件配置 Docker 远程服务器编写 DockerFileSpringBoot 部署配置SpringBoot 项目部署结语 前言 随着容器化技术的崛起,Docker成为了现代软件开发的关键工具。在Java开发中,Spring Boot是一款备受青睐的框架,然而&…...
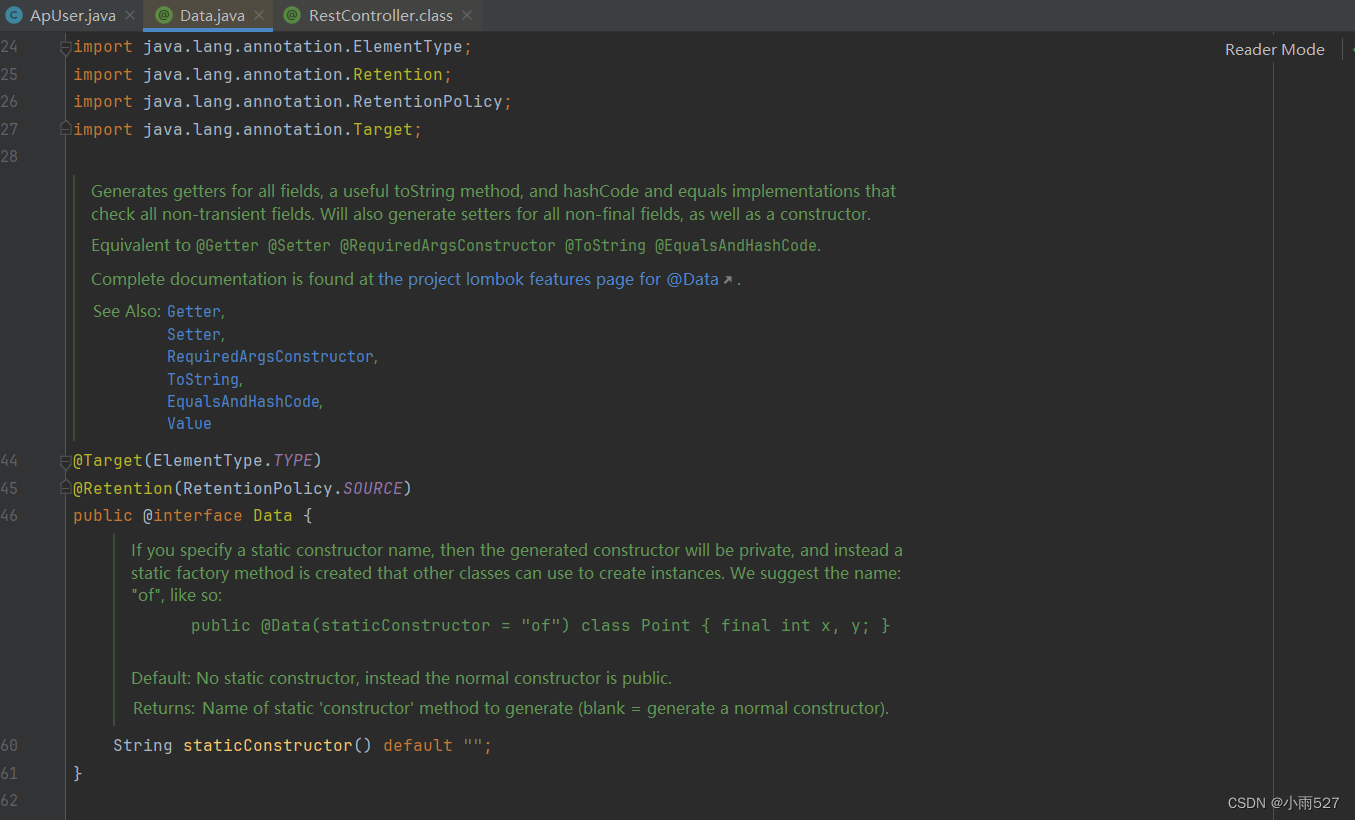
IDEA无法查看源码是.class,而不是.java解决方案?
问题:在idea中,ctrl鼠标左键进入源码,但是有时候会出现无法查看反编译的源码,如图! 而我们需要的是方法1: mvn dependency:resolve -Dclassifiersources 注意:需要该模块的目录下,不是该文件目…...

机器视觉系统选型-定光照强度
同一个外形结构的光源,光照强度受如下影响: 单颗灯珠的亮度灯珠排列的数量和密度漫射板/防护板的材质(透明、半透明、全漫射) 在合理范围内提升光照强度,可降低对相机曝光时长的要求 外形结构尺寸相同的两款光源&am…...
ChatGLM3-6B:新一代开源双语对话语言模型,流畅对话与低部署门槛再升级
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…...

StoneDB顺利通过中科院软件所 2023 开源之夏 结项审核
近日,中科院软件所-开源软件供应链点亮计划-开源之夏2023的结项名单正式出炉,经过三个月的项目开发和一个多月的严格审核,共产生 418个成功结项项目!其中,StoneDB 作为本次参与开源社区,社区入选的两个项目…...
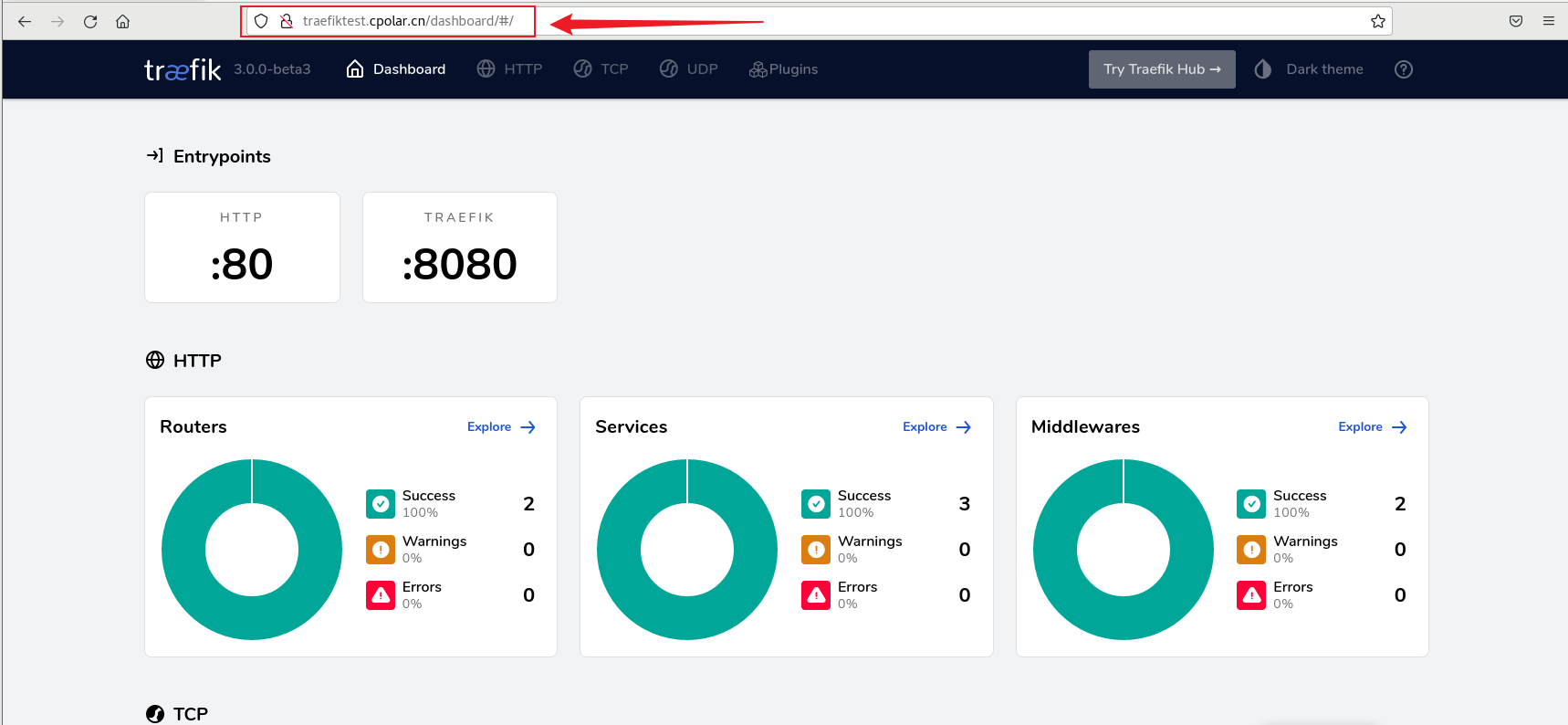
Linux本地docker一键部署traefik+内网穿透工具实现远程访问Web UI管理界面
文章目录 前言1. Docker 部署 Trfɪk2. 本地访问traefik测试3. Linux 安装cpolar4. 配置Traefik公网访问地址5. 公网远程访问Traefik6. 固定Traefik公网地址 前言 Trfɪk 是一个云原生的新型的 HTTP 反向代理、负载均衡软件,能轻易的部署微服务。它支持多种后端 (D…...

SpringCloud FeignClient声明式服务调用采坑记录(A调用服务B/C,B/C重启后必须重启A后才能成功调用配置项)
SpringCloud FeignClient声明式服务调用(A调用服务B/C,B/C重启后必须重启A后才能成功调用配置项采坑记录) 1. 报错(info级别的警告信息)2. 原因:使用了默认了cache负载均衡,或者禁用了ribbonLoa…...

安装银河麒麟linux系统docker(docker-compose)环境,注意事项(一定能解决,有环境资源)
1:安装docker环境必须使用麒麟的版本如下 2:使用docker-compse up -d启动容器遇到的文件 故障1:如果运行docker-compose up 报“Cannot create redo log files because data files are corrupt or the database was not shut down cleanly a…...
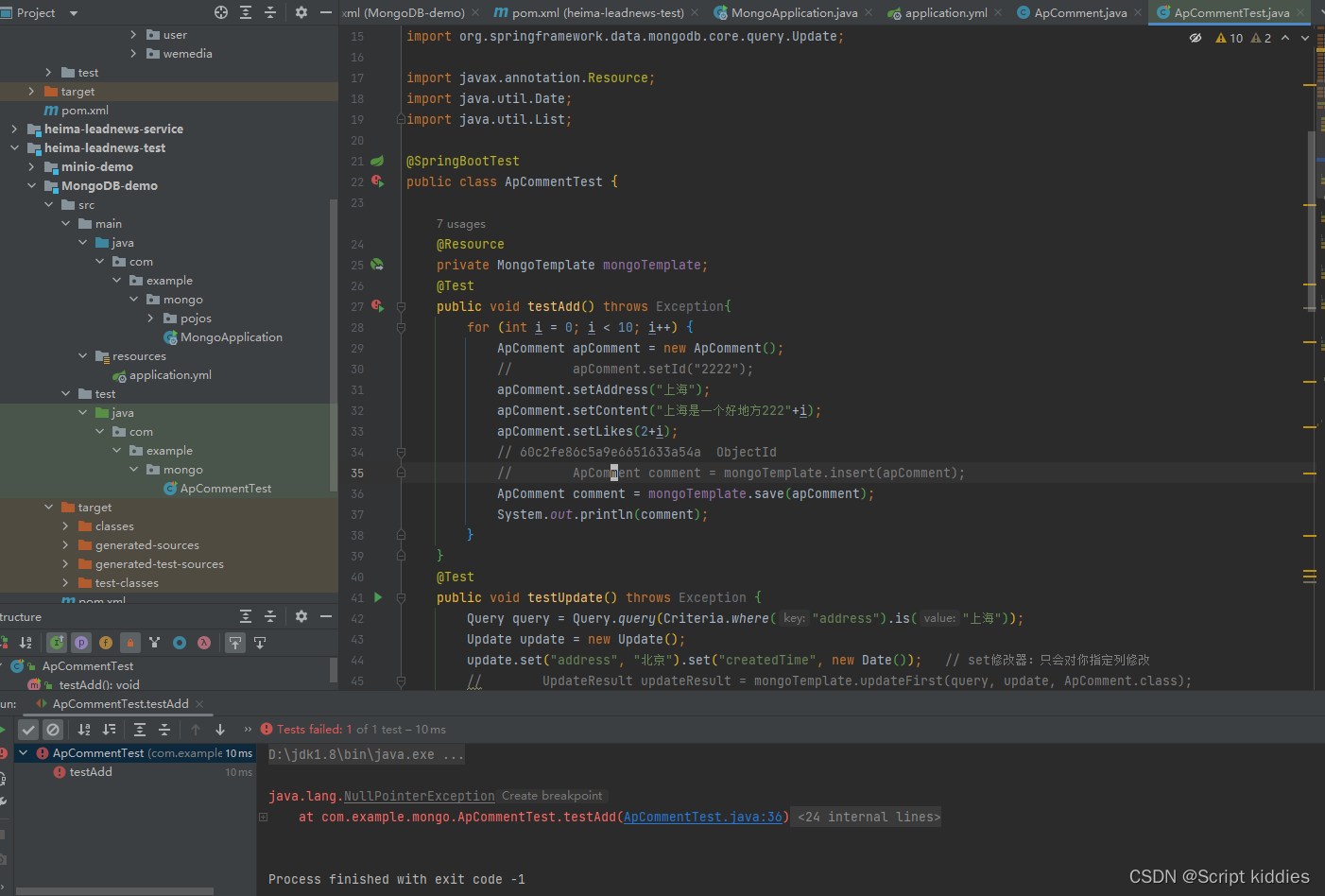
BUG:编写springboot单元测试,自动注入实体类报空指针异常
原因:修饰测试方法的Test注解导入错误 造成错误的原因是 import org.junit.Test;正确的应该是 import org.junit.jupiter.api.Test前者是Junit4,后者是Junit5 junit4的使用似乎要在测试类除了添加SpringbootTest还要添加RunWith(SpringRunner.class) 同时要注意spring-boot-s…...

深度解析 InterpretML:打开机器学习模型的黑箱
深度解析 InterpretML:打开机器学习模型的黑箱 机器学习模型的高性能往往伴随着模型的复杂性,这使得模型的决策过程变得不透明,难以理解。在这个背景下,可解释性机器学习成为了一个备受关注的领域。本文将介绍 InterpretML&#…...

数据结构初阶leetcodeOJ题(二)
目录 第一题 思路: 第二题 思路 第三题 描述 示例1 思路 总结:这种类似的题,都是用快慢指针,相差一定的距离然后输出慢指针。 第一题 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val…...
若依框架数据源切换为pg库
一 切换数据源 在ruoyi-admin项目里引入pg数据库驱动 <dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.18</version> </dependency>修改配置文件里的数据源为pg spring:d…...
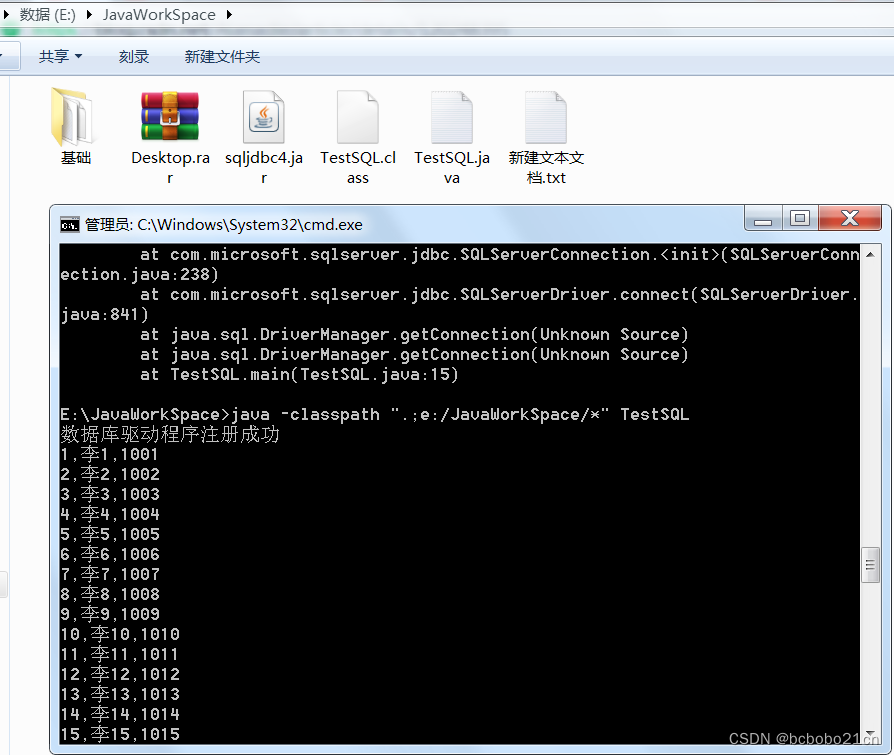
java 访问sqlserver 和 此驱动程序不支持jre1.8错误
sqlserver数据如下; TestSQL.java; import java.sql.*;public class TestSQL {public static void main(String[] args) throws ClassNotFoundException, SQLException {String driverName "com.microsoft.sqlserver.jdbc.SQLServerDriver";…...

C/C++字符判断 2021年12月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C字符判断 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C字符判断 2021年12月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 对于给定的字符,如果该字符是大小写字母或…...

Kotlin语言实现单击任意TextVIew切换一个新页面,并且实现颜色变换
<LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:orientation"vertical"android:layout_height"match_parent"><!-- 这里放置你的其他视图组件 -->&…...
Flume学习笔记(4)—— Flume数据流监控
前置知识: Flume学习笔记(1)—— Flume入门-CSDN博客 Flume学习笔记(2)—— Flume进阶-CSDN博客 Flume 数据流监控 Ganglia 的安装与部署 Ganglia 由 gmond、gmetad 和 gweb 三部分组成。 gmond(Ganglia …...

基于Proteus与51单片机的智能交通灯系统仿真设计
1. 智能交通灯系统设计概述 红绿灯控制系统是城市交通管理的基础设施,传统固定时长的红绿灯已经无法满足现代交通需求。使用51单片机和Proteus仿真软件搭建智能交通灯系统,不仅能帮助理解嵌入式系统开发流程,还能为实际硬件开发打下基础。这个…...

UI-TARS-desktop作品集:从简单指令到复杂工作流,看AI如何帮你干活
UI-TARS-desktop作品集:从简单指令到复杂工作流,看AI如何帮你干活 1. 引言:当AI成为你的数字同事 想象一下,你每天上班要处理一堆重复性的电脑操作:打开邮箱、下载附件、整理数据、生成报告、发送邮件……这些工作繁…...

LFM2.5-1.2B-Thinking多模态扩展展示:结合视觉模型的图文理解能力
LFM2.5-1.2B-Thinking多模态扩展展示:结合视觉模型的图文理解能力 1. 多模态能力惊艳亮相 LFM2.5-1.2B-Thinking最近在多模态领域展现出了令人惊喜的表现。这个原本专注于文本推理的模型,通过与视觉模型的结合,实现了从纯文本到图文理解的跨…...

用Python脚本让Crazyflie 2.X无人机动起来:手把手教你写第一个自主飞行程序
用Python脚本让Crazyflie 2.X无人机动起来:从零编写自主飞行程序 当第一次看到Crazyflie这个巴掌大的无人机在桌面上悬停时,我意识到微小型飞行器的编程控制远比想象中更有趣。与传统无人机不同,Crazyflie 2.X系列通过Python脚本就能实现毫米…...
)
避坑指南:用Sora做商品视频时90%人会踩的3个坑(附解决方案)
避坑指南:用Sora做商品视频时90%人会踩的3个坑(附解决方案) 当你第一次尝试用Sora生成商品推广视频时,大概率会经历这样的心路历程:输入产品图后兴奋地等待成片→看到结果后皱眉发现人物比例像巨人→调整参数重试又遇…...

零基础上手DownKyi:B站视频下载工具的高效使用指南
零基础上手DownKyi:B站视频下载工具的高效使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

零基础玩转RetinaFace:一键部署人脸检测,合影/监控都能精准识别
零基础玩转RetinaFace:一键部署人脸检测,合影/监控都能精准识别 1. 为什么选择RetinaFace人脸检测 在当今数字时代,人脸检测技术已经成为众多应用的基础功能。无论是社交媒体上的自动标记、安防监控系统的人脸识别,还是手机相册…...

HY-Motion 1.0应用案例:为AR试衣间生成‘转身→抬手→比划’交互动作流
HY-Motion 1.0应用案例:为AR试衣间生成转身→抬手→比划交互动作流 1. 项目背景与需求 AR试衣间正在改变传统购物体验,但如何让虚拟服装在用户身上自然流动,一直是个技术难题。传统方案要么动作生硬不连贯,要么需要复杂的动作捕…...

HG-ha/MTools行业实践:短视频工作室AI配音+自动字幕+封面图生成闭环
HG-ha/MTools行业实践:短视频工作室AI配音自动字幕封面图生成闭环 你是不是也遇到过这样的场景?作为短视频工作室的创作者,每天都要面对海量的视频素材。一条1分钟的视频,从剪辑、配音、加字幕到制作封面,前前后后可能…...
)
游戏开发必备:Unity中三维坐标系转换的5种实战技巧(附代码)
Unity三维坐标系转换实战指南:从原理到代码实现 在游戏开发中,三维物体的旋转和坐标系转换是构建沉浸式体验的核心技术。无论是角色转向、镜头跟随还是物理模拟,开发者都需要精准控制物体在三维空间中的方位。Unity作为主流游戏引擎ÿ…...