深度学习YOLO安检管制物品识别与检测 - python opencv 计算机竞赛
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 卷积神经网络
- 4 Yolov5
- 5 模型训练
- 6 实现效果
- 7 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习YOLO安检管制误判识别与检测 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
军事信息化建设一直是各国的研究热点,但我国的武器存在着种类繁多、信息散落等问题,这不利于国防工作提取有效信息,大大妨碍了我军信息化建设的步伐。同时,我军武器常以文字、二维图片和实体武器等传统方式进行展示,交互性差且无法满足更多军迷了解武器性能、近距离观赏或把玩武器的迫切需求。本文将改进后的Yolov5算法应用到武器识别中,将武器图片中的武器快速识别出来,提取武器的相关信息,并将其放入三维的武器展现系统中进行展示,以期让人们了解和掌握各种武器,有利于推动军事信息化建设。
2 实现效果
检测展示

3 卷积神经网络
简介
卷积神经网络 (CNN)
是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。

相关代码实现
cnn卷积神经网络的编写如下,编写卷积层、池化层和全连接层的代码
conv1_1 = tf.layers.conv2d(x, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_1')
conv1_2 = tf.layers.conv2d(conv1_1, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_2')
pool1 = tf.layers.max_pooling2d(conv1_2, (2, 2), (2, 2), name='pool1')
conv2_1 = tf.layers.conv2d(pool1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_1')
conv2_2 = tf.layers.conv2d(conv2_1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_2')
pool2 = tf.layers.max_pooling2d(conv2_2, (2, 2), (2, 2), name='pool2')
conv3_1 = tf.layers.conv2d(pool2, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_1')
conv3_2 = tf.layers.conv2d(conv3_1, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_2')
pool3 = tf.layers.max_pooling2d(conv3_2, (2, 2), (2, 2), name='pool3')
conv4_1 = tf.layers.conv2d(pool3, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_1')
conv4_2 = tf.layers.conv2d(conv4_1, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_2')
pool4 = tf.layers.max_pooling2d(conv4_2, (2, 2), (2, 2), name='pool4')flatten = tf.layers.flatten(pool4)
fc1 = tf.layers.dense(flatten, 512, tf.nn.relu)
fc1_dropout = tf.nn.dropout(fc1, keep_prob=keep_prob)
fc2 = tf.layers.dense(fc1, 256, tf.nn.relu)
fc2_dropout = tf.nn.dropout(fc2, keep_prob=keep_prob)
fc3 = tf.layers.dense(fc2, 2, None)
4 Yolov5
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行火焰识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region
proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种
one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO
一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
YOLOv5有4个版本性能如图所示:

网络架构图

YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
Mosaic数据增强
:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错

基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。


FPN+PAN的结构

这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-
Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255②==>20×20×255③==>10×10×255

-
相关代码
class Detect(nn.Module):stride = None # strides computed during build onnx_dynamic = False # ONNX export parameterdef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].deviceif check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')else:yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()anchor_grid = (self.anchors[i].clone() * self.stride[i]) \.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()return grid, anchor_grid
5 模型训练
训练效果如下
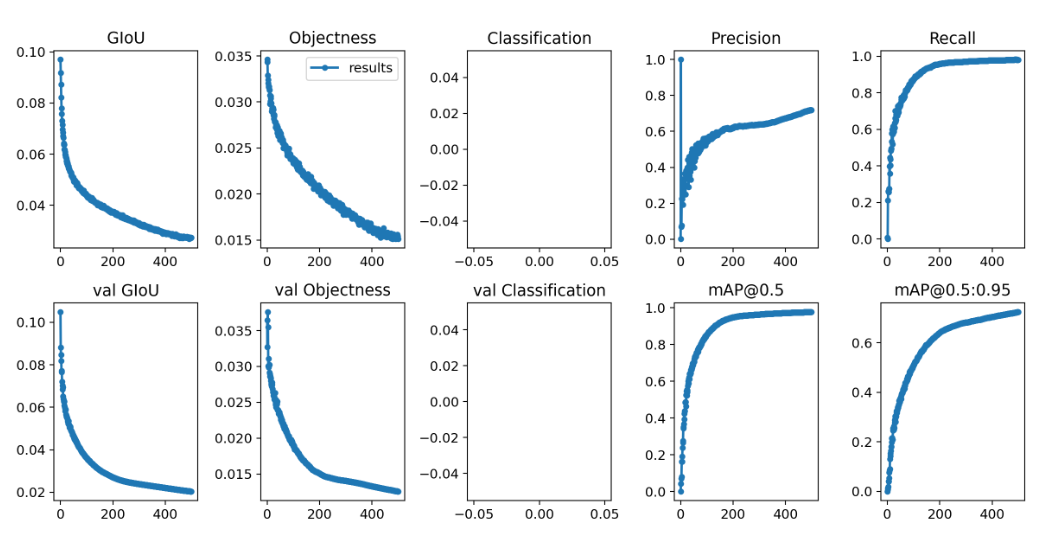
相关代码
#部分代码
def train(hyp, opt, device, tb_writer=None):print(f'Hyperparameters {hyp}')log_dir = tb_writer.log_dir if tb_writer else 'runs/evolve' # run directorywdir = str(Path(log_dir) / 'weights') + os.sep # weights directoryos.makedirs(wdir, exist_ok=True)last = wdir + 'last.pt'best = wdir + 'best.pt'results_file = log_dir + os.sep + 'results.txt'epochs, batch_size, total_batch_size, weights, rank = \opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.local_rank# TODO: Use DDP logging. Only the first process is allowed to log.# Save run settingswith open(Path(log_dir) / 'hyp.yaml', 'w') as f:yaml.dump(hyp, f, sort_keys=False)with open(Path(log_dir) / 'opt.yaml', 'w') as f:yaml.dump(vars(opt), f, sort_keys=False)# Configurecuda = device.type != 'cpu'init_seeds(2 + rank)with open(opt.data) as f:data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dicttrain_path = data_dict['train']test_path = data_dict['val']nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, namesassert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check# Remove previous resultsif rank in [-1, 0]:for f in glob.glob('*_batch*.jpg') + glob.glob(results_file):os.remove(f)# Create modelmodel = Model(opt.cfg, nc=nc).to(device)# Image sizesgs = int(max(model.stride)) # grid size (max stride)imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples# Optimizernbs = 64 # nominal batch size# default DDP implementation is slow for accumulation according to: https://pytorch.org/docs/stable/notes/ddp.html# all-reduce operation is carried out during loss.backward().# Thus, there would be redundant all-reduce communications in a accumulation procedure,# which means, the result is still right but the training speed gets slower.# TODO: If acceleration is needed, there is an implementation of allreduce_post_accumulation# in https://github.com/NVIDIA/DeepLearningExamples/blob/master/PyTorch/LanguageModeling/BERT/run_pretraining.pyaccumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizinghyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decaypg0, pg1, pg2 = [], [], [] # optimizer parameter groupsfor k, v in model.named_parameters():if v.requires_grad:if '.bias' in k:pg2.append(v) # biaseselif '.weight' in k and '.bn' not in k:pg1.append(v) # apply weight decayelse:pg0.append(v) # all elseif opt.adam:optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentumelse:optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decayoptimizer.add_param_group({'params': pg2}) # add pg2 (biases)print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))del pg0, pg1,
6 实现效果

7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
深度学习YOLO安检管制物品识别与检测 - python opencv 计算机竞赛
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络4 Yolov55 模型训练6 实现效果7 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习YOLO安检管制误判识别与检测 ** 该项目较为新颖,适合作为竞赛课题方向&…...

vite+react+typescript 遇到的问题
1.找不到模块“vite”。你的意思是要将 “moduleResolution” 选项设置为 “node”,还是要将别名添加到 “paths” 选项中 tsconfig.json 中 compilerOptions:{“moduleResolution”: node} 2.未知的编译器选项“allowImportingTsExtensions” 该选项用于控制是否…...
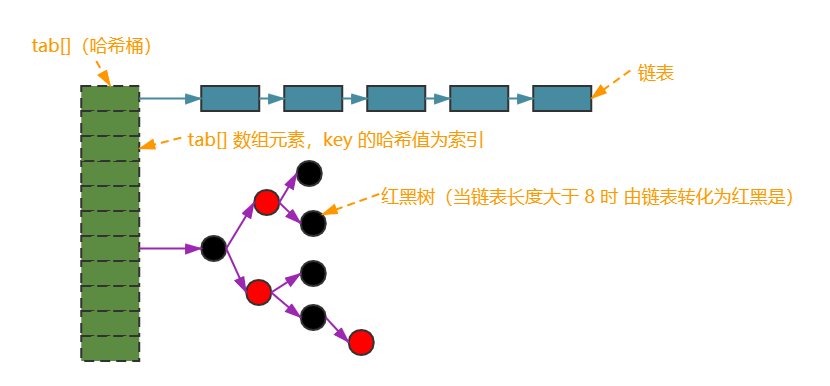
数据结构及八种常用数据结构简介
data-structure 数据结构是一种存在某种关系的元素的集合。“数据” 是指元素;“结构” 是指元素之间存在的关系,分为 “逻辑结构” 和 “物理结构(又称存储结构)”。 常用的数据结构有 数组(array)、栈&…...
)
阿里云配置ssl(Apache)
阿里云申请证书,有个专门的免费的申请方式与普通证书是平级的功能; 访问服务器,判断apache是不是开启ssl功能,如果没有安装就安装它 [rootcentos ~]# rpm -qa | grep mod_ssl //什么没显示说明没装 yum install mod_ssl openssl …...

阿里云linux升级新版本npm、nodejs
在阿里云服务器上编译部署NextJS工程发现 alibaba linux默认yum install npm安装的版本太低, 使用以下方式升级node、npm新版本。 1、卸载现有版本 yum remove nodejs npm -y2、安装新版本 sudo yum install https://rpm.nodesource.com/pub_21.x/nodistro/repo/nodesource-…...

如何在el-tree懒加载并且包含下级的情况下进行数据回显-02
上一篇文章如何在el-tree懒加载并且包含下级的情况下进行数据回显-01对于el-tree懒加载,包含下级的情况下,对于回显提出两种方案,第一种方案有一些难题无法解决,我们重点来说说第二种方案。 第二种方案是使用这个变量对其是否全选…...

Pytorch 网络冻结的三种方法区别:detach、requires_grad、with_no_grad
1、requires_grad requires_gradTrue # 要求计算梯度; requires_gradFalse # 不要求计算梯度;在pytorch中,tensor有一个 requires_grad参数,如果设置为True,那么它会追踪对于该张量的所有操作。在完成计算时可以通过调…...

如何定位el-tree中的树节点当父元素滚动时如何定位子元素
使用到的方法 Element 接口的 scrollIntoView() 方法会滚动元素的父容器,使被调用 scrollIntoView() 的元素对用户可见。 参数 alignToTop可选 一个布尔值: 如果为 true,元素的顶端将和其所在滚动区的可视区域的顶端对齐。相应的 scrollIntoV…...
【WiFI问题自助】解决WiFi能连上但是没有网的问题
WiFi能连上但是没有网的问题 背景:wifi能连上,但是没有网 解决 遇事不决,先重启啊!怎么重启?拔掉电源再插上!拔掉网线再插上! 直接ok了。 思考记录 今天WiFi又上不了网了,昨天报…...

论文阅读:JINA EMBEDDINGS: A Novel Set of High-Performance Sentence Embedding Models
Abstract JINA EMBEDINGS构成了一组高性能的句子嵌入模型,擅长将文本输入转换为数字表示,捕捉文本的语义。这些模型在密集检索和语义文本相似性等应用中表现出色。文章详细介绍了JINA EMBEDINGS的开发,从创建高质量的成对(pairwi…...

计数排序.
一.定义: 计数排序(Counting Sort)是一种非比较性质的排序算法,其时间复杂度为O(nk)(其中n为待排序的元素个数,k为不同值的个数)。这意味着在数据值范围不大并且离散分布的情况下,规…...

flink中配置Rockdb的重要配置项
背景 由于我们在flink中使用了状态比较大,无法完全把状态数据存放到tm的堆内存中,所以我们选择了把状态存放到rockdb上,也就是使用rockdb作为状态后端存储,本文就是简单记录下使用rockdb状态后端存储的几个重要的配置项 使用rockdb状态后端…...

代码随想录二刷 | 数组 | 有序数组的平方
代码随想录二刷 | 数组 | 有序数组的平方 题目描述题目分析 & 代码实现暴力排序双指针法 题目描述 977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 …...

基于单片机C51全自动洗衣机仿真设计
**单片机设计介绍, 基于单片机C51全自动洗衣机仿真设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机C51的全自动洗衣机仿真设计是一个复杂的项目,它涉及到硬件和软件的设计和实现。以下是对这…...

「Verilog学习笔记」实现3-8译码器①
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 ① 本题要求根据38译码器的功能表实现该电路,同时要求采用基础逻辑门实现,那么就需要将功能表转换为逻辑表达式。 timescale 1ns/1nsmodule d…...

Centos(Linux)服务器安装Dotnet8 及 常见问题解决
1. 下载dotnet8 sdk 下载 .NET 8.0 SDK (v8.0.100) - Linux x64 Binaries 拿到 dotnet-sdk-8.0.100-linux-x64.tar.gz 文件 2. 把文件上传到 /usr/local/software 目录 mkdir -p /usr/local/software/dotnet8 把文件拷贝过去 mv dotnet-sdk-8.0.100-linux-x64.tar.gz /usr/loc…...
最强人工智能ChatGPT引领AIGC发展
从公众号转载,关注微信公众号掌握更多技术动态 --------------------------------------------------------------- ——AI不会淘汰所有人,但会淘汰不懂AI的人 一、最强人工智能GPT-4 Turbo 在前不久的OpenAI开发者大会,正值Chatgpt3.5发布一…...

10.Oracle的同义词与序列
oracle11g的同义词与序列 一、Oracle同义词:1、同义词的基本使用2、同义词的相关权限3、同义词的作用范围 二、Oracle序列:1、序列的基本操作2、序列的相关权限 一、Oracle同义词: 同义词是一个数据库对象的别名,它允许用户通过不…...

【周报2023-11-10】
周报2023-11-10 本周的主要工作下周工作计划 本周的主要工作 本周的主要工作就有三个 第一个是进行对我们目前的高企项目的完善情况第二个是对于高企项目的接口对接情况以及细节的把控第三个为新的小程序项目做准备工作 首先第一个高企项目的完善情况得话主要是页面上 对于原…...

搜维尔科技:业内普遍选择Varjo头显作为医疗VR/AR/XR解决方案
Varjo 的人眼分辨率混合现实和虚拟现实头显将医疗专业人员的注意力和情感投入提升到更高水平。借助逼真的 XR/VR,医疗和保健人员可以为最具挑战性的现实场景做好准备! 在虚拟、增强和混合现实中进行最高水平的训练和表现 以逼真的 3D 方式可视化医疗数据…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...