Pytorch 网络冻结的三种方法区别:detach、requires_grad、with_no_grad
1、requires_grad
requires_grad=True # 要求计算梯度;
requires_grad=False # 不要求计算梯度;
在pytorch中,tensor有一个 requires_grad参数,如果设置为True,那么它会追踪对于该张量的所有操作。在完成计算时可以通过调用backward()自动计算所有的梯度,并且,该张量的所有梯度会自动累加到张量的.grad属性;反之,如果设置为False,则不会记录这些操作过程,自然而然就不会进行计算梯度的工作 。 tensor的requires_grad的属性默认为False.
x = torch.tensor([1.0, 2.0])
x.requires_grad"""
结果:
False
"""
我们可以先看一下requires_grad参数设置分别为True和False时的情况。
# 设置好requires_grad的值为True
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y = torch.tensor([3.0, 4.0], requires_grad=False)
y1 = 2.0 * x + 2.0 * yprint(x, x.requires_grad)
print(y, y.requires_grad)
print(y1, y1.requires_grad)y1.backward(torch.tensor([1.0, 1.0]))
print(x.grad)
print(y.grad)"""
结果:
tensor([1., 2.], requires_grad=True) True
tensor([3., 4.]) False
tensor([ 8., 12.], grad_fn=<AddBackward0>) True
tensor([2., 2.])
None
"""
在上面的实验中,发现在计算中如果存在tensor张量x的requires_grad为True的情况,那么计算之后的结果y1的requires_grad也为True,且计算梯度时仅会计算x的梯度,因为前面设置了y张量的requires_grad为False,所以最后y张量的grad属性值为None。
关于张量tensor的梯度计算可以参考另一篇博客:Tensor及其梯度
所以在深度学习训练时,要冻结部分权值参数不进行参数更新的话,可以在优化器初始化之前将参数组进行筛选,将不想进行训练的参数的requires_grad设置为False。代码示例参考如下:
cnn = CNN() #构建网络for n,p in cnn.named_parameters():print(n,p.requires_grad)if n=="conv1.0.weight":p.requires_grad = Falseoptimizer = torch.optim.Adam(filter(lambda p: p.requires_grad,cnn.parameters()), lr=learning_rate)也可以把requires_grad属性置为 False这个操作放在optimizer之后,参数都不会进行更新。但是区别在于,先进行requires_grad属性置为False的操作,再optimizer初始化,不会将该层的参数放进优化器中更新,而先进行optimizer初始化,再进行requires_grad属性置为False的操作,会将所有的参数放进优化器中,但不更新该指定层参数,只更新剩下的参数。对比看来,optimizer中的参数量会相比前者会更大一点。
所以一般最好是将requires_grad属性置为 False这个操作放在optimizer之前。
注意事项:
1、requires_grad属性置为 False或者默认时,不能在对该tensor计算梯度,否则会进行报错。因为并没有追踪到任何计算历史,所以就不存在梯度的计算了。
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y = torch.tensor([3.0, 4.0], requires_grad=False)
y1 = 2.0 * x + 2.0 * y
# y1.backward(torch.tensor([1.0, 1.0]))
# print(x.grad)
y.backward(torch.tensor([1.0, 1.0]))"""
结果:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
"""
2、整数型的tensor并没有requires_grad这个属性,只有浮点类型的tensor可以计算梯度
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
d:\test.ipynb Cell 9 in <cell line: 2>()1 a = torch.tensor([1,2])
----> 2 b = torch.tensor([3,4], requires_grad=True)3 c = a+b4 print(a.requires_grad)RuntimeError: Only Tensors of floating point and complex dtype can require gradients
2、detach()
detach方法就是返回了一个新的张量,该张量与当前计算图完全分离,且该张量的计算将不会记录到梯度当中。
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y = torch.tensor([3.0, 4.0], requires_grad=True)
z = torch.tensor([3.0, 2.0], requires_grad=True)
x = x * 2
z1 = z.detach()
x1 = x.detach()
y1 = 2.0 * x1 + 2.0 * y + 3 * z1
y1.backward(torch.tensor([1.0, 1.0]))
print(x.requires_grad)
print(x.grad)
print(y.requires_grad)
print(y.grad)
print(z.requires_grad)
print(z.grad)
print(z1.requires_grad)
print(z1.grad)"""
结果:
True
None
True
tensor([2., 2.])
True
None
False
None
C:\Users\26973\AppData\Local\Temp\ipykernel_37516\3652236761.py:12: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.print(x.grad)
"""
从上面实验可以看到,使用detach()方法后,可以截断反向传播的梯度流,其作用有点类似于将requires_grad属性置为False的情况。
与requires_grad_()将requires_grad属性置为False不同的是 detach()函数会返回一个新的Tensor对象b , 并且新Tensor是与当前的计算图分离的,其requires_grad属性为False,反向传播时不会计算其梯度。 b与a共享数据的存储空间,二者指向同一块内存。
而requires_grad_()函数会改变Tensor的requires_grad属性并返回Tensor,修改requires_grad的操作是原位操作(in place)。其默认参数为requires_grad=True。requires_grad=True时,自动求导会记录对Tensor的操作,requires_grad_()的主要用途是告诉自动求导开始记录对Tensor的操作。
关于detach()返回的张量与原张量共享数据的存储空间,二者指向同一块内存可以由以下代码看出:
z1[0] = 5.0
print(z)
print(z1)"""
结果:
tensor([5., 2.], requires_grad=True)
tensor([5., 2.])
"""
当我们修改z1中的数据时,z中的数据也随之修改。
**总结:**当我们在计算到某一步时,不需要在记录某一个张量的梯度时,就可以使用detach()将其从追踪记录当中分离出来,这样一来该张量对应计算产生的梯度就不会被考虑了。比较常见的就是在GAN生成模型中,当训练一次生成器后,再训练判别器时,需要对生成器生成的fake进行损失计算,但是又不希望这部分损失对生成器进行权值的更新,这个时候需要冻结生成器那部分的权值,因此通常将生成器生成的fake张量使用fetch()进行阶段,再输入到判别器进行运算,这样最后使用loss.backward()时仅会对判别器部分的梯度进行计算
import torch
import numpy as npy = torch.tensor([3.0, 4.0], requires_grad=True)
z = torch.tensor([3.0, 2.0], requires_grad=True)
z1 = z.detach()
z2 = z1 + y
y1 = torch.sum(3 * z2)
y1.backward()
print(z2, z2.requires_grad)
print(y.grad)
print(z2.grad)
print(z1.grad)"""
结果:
tensor([6., 6.], grad_fn=<AddBackward0>) True
tensor([3., 3.])
None
None
"""
这里假设z是生成器生成的图片,z1表示的是使用detch()截断后的张量,y表示的判别器内部的一些运算张量,z2表示经过判别器后的结果,y1假设是计算loss的损失函数,我们可以看到,使用y1.backward() 后,不会对生成器生成的z产生任何的梯度,在优化器优化时自然而然不会对其进行优化。而对于后面的步骤仍然会跟踪记录其所有的计算过程,比如对于z1在判别器中进行运算仍然会记录其过程,并仅会对判别器内部的参数y进行梯度计算,从而进行优化。
(注:这里z2.grad之所以也为None,是因为z2节点不是叶子节点,它是由z1和y进行累加而来的,所以在z2处不会有grad属性,这部分可以看其给出的警告)
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
3、with_no_grad
torch.no_grad()是一个上下文管理器,用来禁止梯度的计算,通常用来网络推断中,它可以减少计算内存的使用量。
# 设置好requires_grad的值为True
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y1 = x ** 2with torch.no_grad(): # 这里使用了no_grad()包裹不需要被追踪的计算过程y2 = y1 * 2y3 = x ** 5y4 = y1 + y2 + y3print(y1, y1.requires_grad)
print(y2, y2.requires_grad)
print(y3, y3.requires_grad)
print(y4, y4.requires_grad)y4.backward(torch.ones(y4.shape)) # y1.backward() y2.backward()
print(x.grad)"""
结果:
tensor([1., 4.], grad_fn=<PowBackward0>) True
tensor([2., 8.]) False
tensor([ 1., 32.]) False
tensor([ 4., 44.], grad_fn=<AddBackward0>) True
tensor([2., 4.])
"""
可以看出,其实使用with torch.no_grad()这个后,被其包裹的所有运算都是不计算梯度的,其效果与detach()类似,所以使用下列代码的运行结果是一样的:
# 设置好requires_grad的值为True
import torchx = torch.tensor([1.0, 2.0], requires_grad=True)
y1 = x ** 2# with torch.no_grad(): # 这里使用了no_grad()包裹不需要被追踪的计算过程
y2 = y1 * 2
y3 = x ** 5
y2 = y2.detach()
y3 = y3.detach()y4 = y1 + y2 + y3print(y1, y1.requires_grad)
print(y2, y2.requires_grad)
print(y3, y3.requires_grad)
print(y4, y4.requires_grad)y4.backward(torch.ones(y4.shape)) # y1.backward() y2.backward()
print(x.grad)
"""
结果:
tensor([1., 4.], grad_fn=<PowBackward0>) True
tensor([2., 8.]) False
tensor([ 1., 32.]) False
tensor([ 4., 44.], grad_fn=<AddBackward0>) True
tensor([2., 4.])
"""
detach()是考虑将单个张量从追踪记录当中脱离出来;
而torch.no_grad()是一个warper,可以将多个计算步骤的张量计算脱离出去,本质上没啥区别。
4、总结:
- requires_grad:在最开始创建Tensor时候可以设置的属性,用于表明是否追踪当前Tensor的计算操作。后面也可以通过requires_grad_()方法设置该参数,但是只有叶子节点才可以设置该参数。
- detach()方法:则是用于将某一个Tensor从计算图中分离出来。返回的是一个内存共享的Tensor,一变都变。
- torch.no_grad():对所有包裹的计算操作进行分离。但是torch.no_grad()将会使用更少的内存,因为从包裹的开始,就表明不需要计算梯度了,因此就不需要保存中间结果。
相关文章:

Pytorch 网络冻结的三种方法区别:detach、requires_grad、with_no_grad
1、requires_grad requires_gradTrue # 要求计算梯度; requires_gradFalse # 不要求计算梯度;在pytorch中,tensor有一个 requires_grad参数,如果设置为True,那么它会追踪对于该张量的所有操作。在完成计算时可以通过调…...

如何定位el-tree中的树节点当父元素滚动时如何定位子元素
使用到的方法 Element 接口的 scrollIntoView() 方法会滚动元素的父容器,使被调用 scrollIntoView() 的元素对用户可见。 参数 alignToTop可选 一个布尔值: 如果为 true,元素的顶端将和其所在滚动区的可视区域的顶端对齐。相应的 scrollIntoV…...
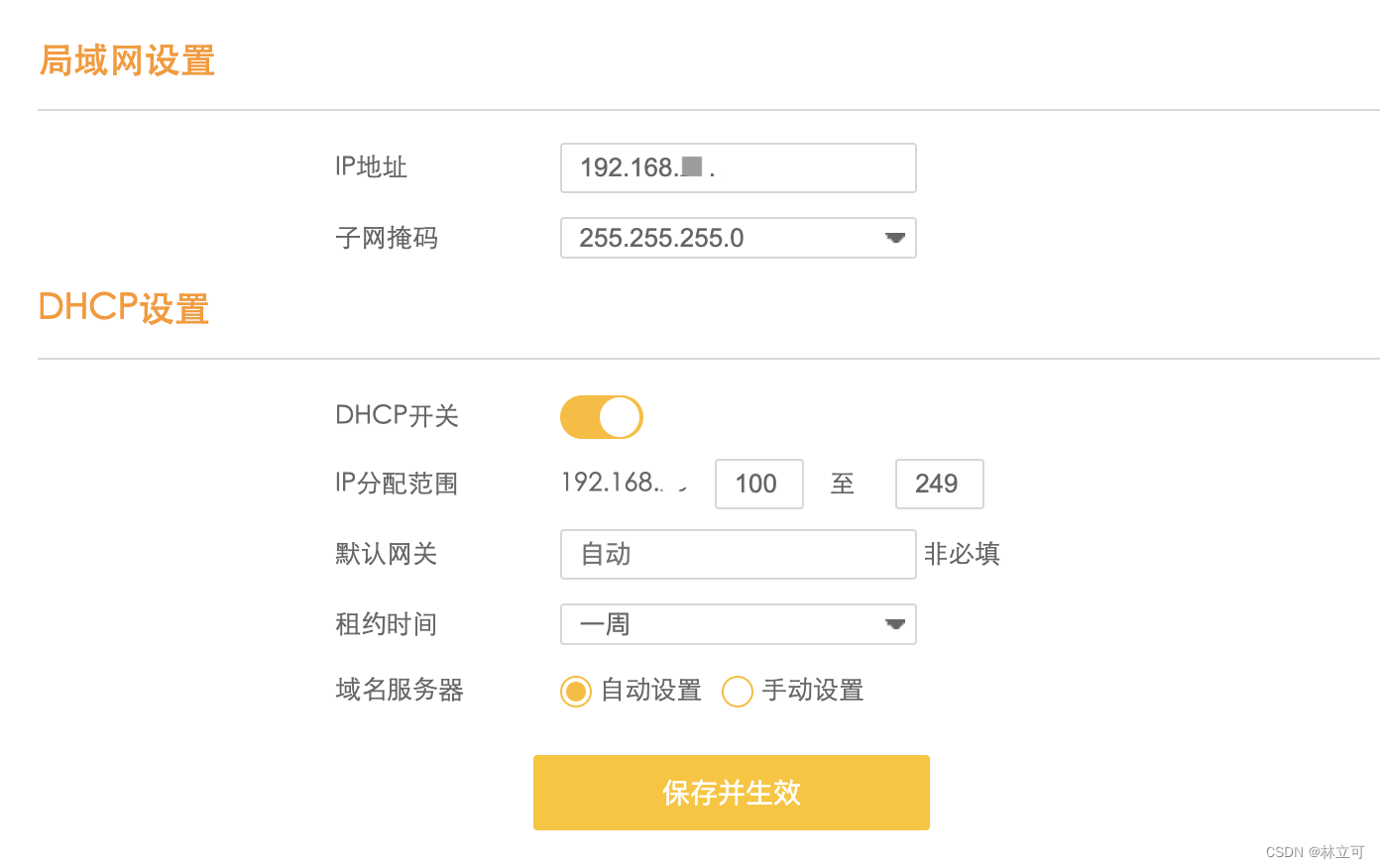
【WiFI问题自助】解决WiFi能连上但是没有网的问题
WiFi能连上但是没有网的问题 背景:wifi能连上,但是没有网 解决 遇事不决,先重启啊!怎么重启?拔掉电源再插上!拔掉网线再插上! 直接ok了。 思考记录 今天WiFi又上不了网了,昨天报…...

论文阅读:JINA EMBEDDINGS: A Novel Set of High-Performance Sentence Embedding Models
Abstract JINA EMBEDINGS构成了一组高性能的句子嵌入模型,擅长将文本输入转换为数字表示,捕捉文本的语义。这些模型在密集检索和语义文本相似性等应用中表现出色。文章详细介绍了JINA EMBEDINGS的开发,从创建高质量的成对(pairwi…...

计数排序.
一.定义: 计数排序(Counting Sort)是一种非比较性质的排序算法,其时间复杂度为O(nk)(其中n为待排序的元素个数,k为不同值的个数)。这意味着在数据值范围不大并且离散分布的情况下,规…...

flink中配置Rockdb的重要配置项
背景 由于我们在flink中使用了状态比较大,无法完全把状态数据存放到tm的堆内存中,所以我们选择了把状态存放到rockdb上,也就是使用rockdb作为状态后端存储,本文就是简单记录下使用rockdb状态后端存储的几个重要的配置项 使用rockdb状态后端…...

代码随想录二刷 | 数组 | 有序数组的平方
代码随想录二刷 | 数组 | 有序数组的平方 题目描述题目分析 & 代码实现暴力排序双指针法 题目描述 977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 …...

基于单片机C51全自动洗衣机仿真设计
**单片机设计介绍, 基于单片机C51全自动洗衣机仿真设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机C51的全自动洗衣机仿真设计是一个复杂的项目,它涉及到硬件和软件的设计和实现。以下是对这…...

「Verilog学习笔记」实现3-8译码器①
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 ① 本题要求根据38译码器的功能表实现该电路,同时要求采用基础逻辑门实现,那么就需要将功能表转换为逻辑表达式。 timescale 1ns/1nsmodule d…...

Centos(Linux)服务器安装Dotnet8 及 常见问题解决
1. 下载dotnet8 sdk 下载 .NET 8.0 SDK (v8.0.100) - Linux x64 Binaries 拿到 dotnet-sdk-8.0.100-linux-x64.tar.gz 文件 2. 把文件上传到 /usr/local/software 目录 mkdir -p /usr/local/software/dotnet8 把文件拷贝过去 mv dotnet-sdk-8.0.100-linux-x64.tar.gz /usr/loc…...
最强人工智能ChatGPT引领AIGC发展
从公众号转载,关注微信公众号掌握更多技术动态 --------------------------------------------------------------- ——AI不会淘汰所有人,但会淘汰不懂AI的人 一、最强人工智能GPT-4 Turbo 在前不久的OpenAI开发者大会,正值Chatgpt3.5发布一…...

10.Oracle的同义词与序列
oracle11g的同义词与序列 一、Oracle同义词:1、同义词的基本使用2、同义词的相关权限3、同义词的作用范围 二、Oracle序列:1、序列的基本操作2、序列的相关权限 一、Oracle同义词: 同义词是一个数据库对象的别名,它允许用户通过不…...

【周报2023-11-10】
周报2023-11-10 本周的主要工作下周工作计划 本周的主要工作 本周的主要工作就有三个 第一个是进行对我们目前的高企项目的完善情况第二个是对于高企项目的接口对接情况以及细节的把控第三个为新的小程序项目做准备工作 首先第一个高企项目的完善情况得话主要是页面上 对于原…...

搜维尔科技:业内普遍选择Varjo头显作为医疗VR/AR/XR解决方案
Varjo 的人眼分辨率混合现实和虚拟现实头显将医疗专业人员的注意力和情感投入提升到更高水平。借助逼真的 XR/VR,医疗和保健人员可以为最具挑战性的现实场景做好准备! 在虚拟、增强和混合现实中进行最高水平的训练和表现 以逼真的 3D 方式可视化医疗数据…...
数据结构02附录01:顺序表考研习题[C++]
图源:文心一言 考研笔记整理~🥝🥝 之前的博文链接在此:数据结构02:线性表[顺序表链表]_线性链表-CSDN博客~🥝🥝 本篇作为线性表的代码补充,每道题提供了优解和暴力解算法…...
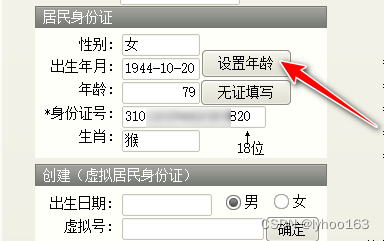
ClientDateSet:Cannot perform this operation on a closed dataset
一、问题表现 Delphi 三层DataSnap,使用AlphaControls控件优化界面,一窗口编辑时,出现下列错误提示: 编译通过,该窗口中,重新显示数据,下图: 相关代码: procedure…...

python中列表的基础解释
列表: 一种可以存放多种类型数据的数据结构 列表的创建: 1.用【】创建列表 #创建一个空列表 list1[] #创建一个非空列表 list2 [zhang,li,ying,1,2,3] #输出内容及类型 print(list1,type(list1)) print(list2,type(list2))结果: 2.使用list…...

『力扣刷题本』:链表分割
一、题目 现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。 二、思路解析 首先,让我们列出我们需要做的事情&…...
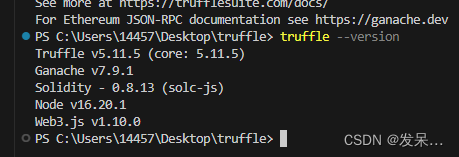
FISCOBCOS入门(十)Truffle测试helloworld智能合约
本文带你从零开始搭建truffle以及编写迁移脚本和测试文件,并对测试文件的代码进行解释,让你更深入的理解truffle测试智能合约的原理,制作不易,望一键三连 在windos终端内安装truffle npm install -g truffle 安装truffle时可能出现网络报错,多试几次即可 truffle --vers…...

Unity Text文本首行缩进两个字符的方法
Text文本首行缩进两个字符的方法比较简单。通过代码把"\u3000\u3000"加到文本字符串前面即可。 参考如下代码: TMPtext1.text "\u3000\u3000" "这是一段有首行缩进的文本内容。\n这是第二行"; 运行效果如下图所示: 虽…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...