深入了解百度爬虫工作原理

在当今数字化时代,互联网已经成为人们获取信息的主要渠道之一。而搜索引擎作为互联网上最重要的工具之一,扮演着连接用户与海量信息的桥梁角色。然而,我们是否曾经好奇过当我们在搜索引擎中输入关键词并点击搜索按钮后,究竟是如何能够迅速地找到相关结果呢?
百度作为中国最大的搜索引擎之一,其背后隐藏着一个庞大而复杂的系统,其中核心组成部分就是百度爬虫。百度爬虫是一种自动化程序,通过不断地抓取、解析和索引互联网上的网页,为用户提供高质量的搜索结果。它背后的工作原理涉及到多个技术领域的交叉与融合,包括网络通信、数据挖掘、算法优化等等。
目录
- 讲在前面
- 什么是爬虫
- 百度爬虫的作用
- 爬虫的基本原理
- URL抓取与调度
- 页面下载与解析
- 数据存储与索引
- 百度爬虫的工作流程
- 种子URL的选择
- 抓取与解析页面
- 抓取策略与规则
- Robots.txt协议
- 网页质量评估
- 反爬虫机制
讲在前面
什么是爬虫
在当今信息爆炸的时代,互联网成为了人们获取各种信息的主要途径。然而,互联网上的信息分布在各种网站和页面之中,要手动访问和收集这些信息无疑是一项耗时且繁琐的任务。为了解决这个问题,爬虫技术应运而生。

- 爬虫的定义
- 爬虫(Crawler),又称网络蜘蛛(Spider)或网络机器人(Bot),是一种自动化程序,用于在互联网上获取和抓取信息。
- 爬虫通过模拟浏览器的行为,自动访问网页并提取所需的数据。它可以遍历整个互联网,从而实现大规模的数据采集和处理。
- 爬虫的作用
- 数据采集与分析:爬虫可以帮助人们从互联网上获取大量的数据,用于分析、研究和决策。
- 搜索引擎索引:搜索引擎通过爬虫抓取网页内容,建立索引,以便用户可以快速找到他们需要的信息。
- 网络监测与安全:爬虫可以用于监测网络上的信息、追踪恶意行为并提供安全保护。
- 数据挖掘与推荐:通过分析爬虫获取的数据,可以进行数据挖掘和个性化推荐等应用。
- 爬虫的种类
- 通用爬虫:用于整个互联网的信息抓取,如搜索引擎的爬虫。
- 垂直爬虫:针对特定领域或网站的信息抓取,例如新闻网站、电商网站等。
- 增量式爬虫:仅抓取更新的页面或有修改的页面,以提高效率和节省资源。
百度爬虫的作用
百度爬虫作为百度搜索引擎的核心组成部分,在整个搜索服务过程中扮演着重要的角色。它的主要作用是收集、索引和更新互联网上的网页信息,以便用户能够通过输入关键词获取相关的搜索结果。
百度爬虫通过不断抓取互联网上的网页,并将这些网页存储在巨大的索引库中。这个过程是一个持续进行的任务,以确保索引库中的数据能够及时更新。通过广泛收集网页信息,百度爬虫为搜索引擎提供了丰富的搜索资源,使得用户能够找到他们所需的相关内容。
- 网页抓取:百度爬虫通过自动化程序扫描互联网上的网页,发现新的网页并抓取其中的内容。这样可以确保搜索引擎的索引库中包含最新的网页信息。
- 数据解析:百度爬虫对抓取的网页进行解析,提取其中的文本、图片、链接等信息。通过解析网页,百度爬虫能够理解网页的结构和内容,为后续的索引和检索做准备。
- 网页索引:百度爬虫将抓取和解析得到的网页数据存储在索引库中。索引库是一个巨大的数据库,其中存储了大量网页的关键词、标题、摘要等信息,以及指向每个网页的链接。
- 网页排名:百度爬虫通过分析网页的质量、相关度和用户反馈等因素,为每个网页赋予一个权重值。这个权重值在搜索结果中决定了网页的排名位置,从而影响了用户在搜索时所看到的结果顺序。
爬虫的基本原理
URL抓取与调度
URL抓取与调度是百度爬虫工作原理中的关键步骤,它负责确定哪些网页需要被爬取,并按照一定的规则和策略进行调度和管理。
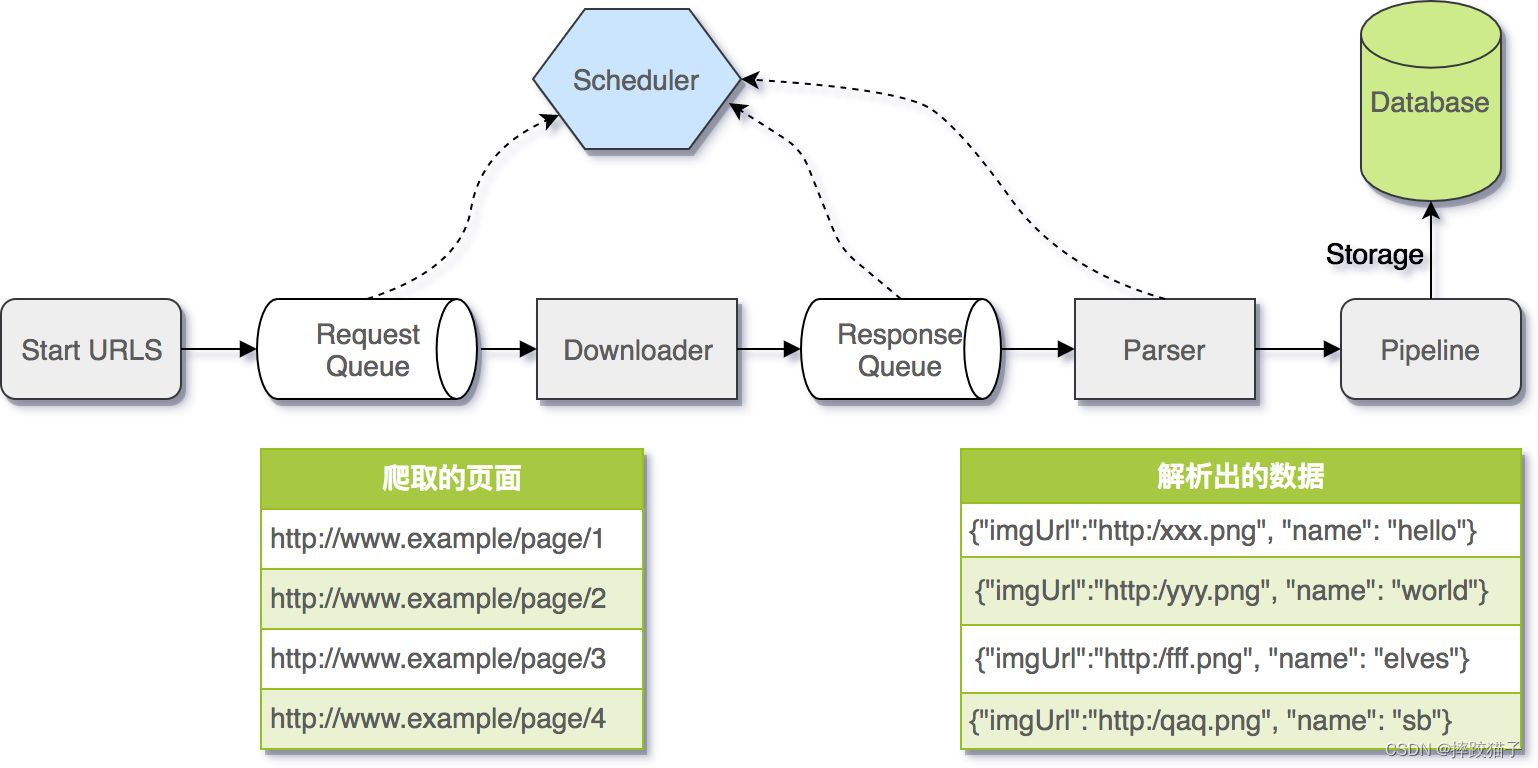
百度爬虫开始抓取工作时,需要先确定一些起始的种子URL。这些种子URL可以是事先设定的一些重要网站,也可以是用户输入的搜索关键词。百度爬虫会从这些种子URL开始,逐步扩展到其他相关网页。
百度爬虫使用一个URL队列来存储待抓取的网页链接。在抓取过程中,百度爬虫会不断从队列中取出URL进行处理。当一个URL被抓取后,它所包含的链接也会被添加到队列中,以便进一步抓取。
为了避免重复抓取相同的网页,百度爬虫需要进行URL去重操作。这通常通过对已经抓取的URL和队列中的URL进行比较,排除重复的链接。URL去重是保证爬虫效率和准确性的重要步骤。
为了提高抓取效率,百度爬虫还会采用一些策略,如多线程抓取、增量抓取和并行抓取等。这些策略可以帮助爬虫同时处理多个URL,并在保证抓取质量的前提下提高抓取速度。
页面下载与解析
- 页面下载
页面下载是指从互联网上获取网页内容并保存至本地存储设备的过程。百度爬虫首先根据抓取策略选择需要下载的网页,在下载过程中,爬虫会模拟浏览器的行为发送HTTP请求到目标网站的服务器,获取网页的响应。通过网络协议,爬虫将网页内容下载到本地,并进行存储以供后续处理。
- 页面解析
页面解析是指对下载的网页内容进行解析,提取出其中的有用信息。百度爬虫使用解析技术来理解网页的结构和内容,以便进行后续的索引和检索。解析过程包括以下几个步骤:
- HTML解析:百度爬虫使用HTML解析器对网页的HTML代码进行解析,识别出网页的各个元素,如标题、正文、链接等。
- 文本提取:通过解析HTML结构,爬虫可以提取出网页中的文本内容,包括段落、标题、标签等。文本提取是后续建立索引和进行关键词匹配的基础。
- 链接提取:爬虫还会解析网页中的链接,提取出其他页面的URL,以便进行进一步的抓取。通过链接提取,爬虫可以不断扩展抓取范围,建立更全面的索引。
页面下载与解析是百度爬虫工作过程中必不可少的环节。通过下载网页并解析其中的内容,百度爬虫能够获取网页的信息,并进一步进行索引、排名等操作,为用户提供准确、有价值的搜索结果。
数据存储与索引
在百度爬虫的工作中,数据存储与索引是非常重要的环节,通过高效的数据存储和索引机制来管理大规模的网页数据。
- 数据存储
数据存储是指将从互联网上下载的网页数据保存在合适的存储设备中。百度爬虫需要处理大量的网页数据,因此需要一个高效的存储系统来存储这些数据。通常,百度爬虫使用分布式存储系统,将数据分布在多个节点上,以提高存储容量和读写性能。
- 索引建立
索引建立是指将抓取到的网页数据进行整理和组织,以便用户进行快速检索。百度爬虫通过建立索引,将网页的关键信息以及对应的URL进行记录和归类。索引的建立可以分为以下几个步骤:
- 关键词提取:百度爬虫会对网页的文本内容进行分词和提取关键词。这样可以建立一个关键词库,记录每个关键词出现的频率和位置。
- 倒排索引:倒排索引是一种常用的索引结构,它将关键词作为索引的键,将对应的网页URL列表作为值。这样,用户在搜索时只需查询关键词,就可以快速找到相关的网页。
- 索引更新:由于互联网上的网页内容是动态变化的,爬虫需要及时更新索引。当新的网页被抓取并解析后,爬虫会将其加入到索引库中,保证索引的及时性和准确性。
百度爬虫的工作流程
种子URL的选择
在选择种子URL时,百度爬虫通常会结合多种策略来提高抓取的效果和覆盖范围。同时,为了保证抓取的合法性和合规性,百度爬虫会遵守相关的抓取规则和政策,避免抓取禁止访问或敏感内容的网页。
种子URL是指作为起始点的初始网页URL。它们是百度爬虫开始抓取过程的入口点,决定了抓取的起始位置和范围。选择合适的种子URL对于爬虫的效率和抓取结果都有重要影响。
百度爬虫选择种子URL的策略可以根据不同的需求和场景进行调整,常见的策略有:
- 首页链接:选择网站的首页链接作为种子URL是一种常见的策略。首页通常包含了网站的核心内容和导航链接,抓取首页可以较全面地覆盖网站的主要信息。
- 热门页面:选择网站上热门的、受欢迎的页面作为种子URL也是一种常用策略。这些页面通常包含了重要的内容和高质量的链接,抓取这些页面可以提高爬虫的抓取效果。
- 主题相关页面:根据用户指定的主题或关键词,选择与之相关的页面作为种子URL。这样可以更加精准地抓取与特定主题相关的网页。
- 历史数据:在一些情况下,可以选择已有的历史数据中的URL作为种子URL。这些URL可能是之前抓取过的、已经验证有效的网页,可以作为起始点进行新一轮的抓取。
抓取与解析页面
在百度爬虫的工作中,抓取和解析页面是核心环节之一。通过抓取和解析页面,百度爬虫能够获取目标网页的内容,并从中提取有用的信息。这些信息可以用于建立索引、计算网页的权重和相关性等,为用户提供准确和有用的搜索结果。
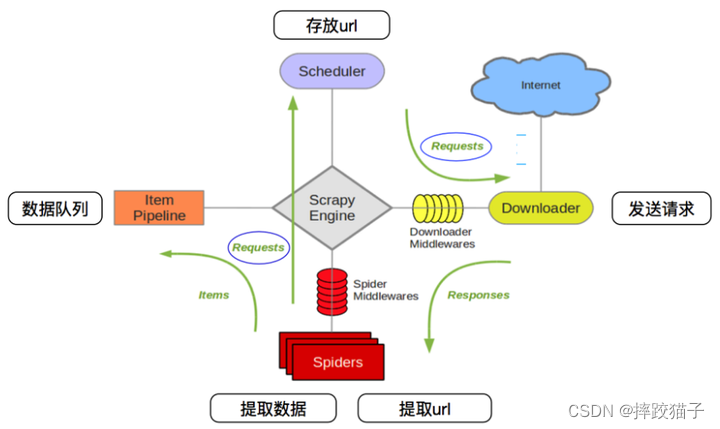
- 页面抓取
页面抓取是指通过网络请求获取目标网页的过程。百度爬虫会按照事先设定的规则和策略,通过HTTP或HTTPS协议向目标网址发送请求,获取网页的源代码。常见的页面抓取方式包括使用HTTP库发送GET或POST请求、模拟浏览器行为进行爬取等。
- 页面解析
页面解析是将抓取到的网页源代码进行处理和提取有用信息的过程。百度爬虫需要从网页中提取出关键信息,例如标题、正文内容、链接等。常见的页面解析方式包括:
- 正则表达式:使用正则表达式匹配和提取特定的文本模式。例如,使用正则表达式提取HTML标签中的内容。
- XPath:使用XPath语法进行HTML/XML文档的解析。XPath通过路径表达式定位和选择节点,可以方便地提取所需数据。
- CSS选择器:使用CSS选择器语法进行HTML文档的解析。通过选择器选择特定的HTML元素,提取相应的数据。
- 数据处理
在抓取和解析页面的过程中,百度爬虫还需要进行一些数据处理的步骤。例如:
- 数据清洗:对抓取到的数据进行清洗和格式化,去除不必要的标签、空格或特殊字符。
- 数据存储:将解析得到的数据保存到合适的格式中,例如文本文件、数据库或分布式存储系统。
- 错误处理:处理抓取过程中可能出现的错误,例如网络连接失败、页面不存在等情况。
抓取策略与规则
Robots.txt协议
在百度爬虫的工作中,Robots.txt协议扮演着重要的角色。
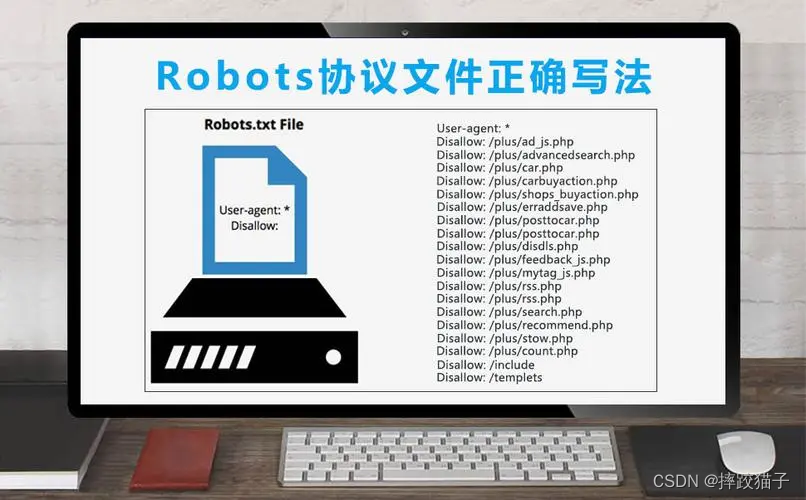
- 作用
Robots.txt是一种位于网站根目录下的文本文件,用于指导搜索引擎爬虫访问网站时应该遵守的规则。通过Robots.txt文件,网站管理员可以告诉搜索引擎爬虫哪些页面可以抓取,哪些页面不应该被抓取,以及抓取频率的限制等信息。Robots.txt协议有效地帮助网站管理者控制搜索引擎对其网站内容的抓取和索引行为。
- 实际应用
在百度爬虫的工作中,会遵循网站的Robots.txt文件中的规则来确定哪些页面可以抓取,哪些页面不应该被抓取。百度爬虫会定期访问网站的Robots.txt文件,并根据其中的规则来调整抓取的行为,以确保遵守网站所有者的指示。
- Robots.txt规则
Robots.txt文件包含了一些常用的指令和规则,例如:
- User-agent: 指定了该规则适用的搜索引擎爬虫代理,比如"*"表示适用于所有爬虫,"Baiduspider"表示只适用于百度爬虫。
- Disallow: 指定了不允许抓取的URL路径,例如"/admin/"表示不允许抓取网站的管理员页面。
- Allow: 指定了允许抓取的URL路径,优先级高于Disallow规则。
- Crawl-delay: 指定了爬虫抓取的延迟时间,用于控制爬虫的访问频率。
网页质量评估
在百度搜索引擎中,网页质量评估用于确定哪些网页应该排名更高,确定其在搜索结果中的排名和展示优先级。
内容质量是网页质量评估的核心指标之一。百度搜索引擎会评估网页的内容是否原创、丰富、有用,并与搜索用户的查询意图匹配。
用户体验也是网页质量评估的重要参考因素。百度搜索引擎会考虑网页的加载速度、页面布局、广告数量等因素,以评估用户在访问该网页时的体验质量。以下是一些用户体验评估的关键因素:
链接质量也是网页质量评估的重要考虑因素之一。百度搜索引擎会评估网页的链接质量,包括外部链接和内部链接。
在网页质量评估中,百度搜索引擎还会考虑网页的信任度和安全性。
反爬虫机制

在互联网信息爬取的过程中,网站所有者可能会采取一些反爬虫机制来限制搜索引擎爬虫和其他自动化程序对其网站内容的访问。
- IP限制与封锁
网站可能会对频繁访问的IP地址进行限制或封锁,以防止爬虫程序对网站进行大规模的数据抓取。
- 用户行为分析
一些网站会通过分析用户的访问行为来识别是否为爬虫程序的访问,如访问频率、点击模式等。
- 图像验证码
一些网站在特定情况下可能会强制要求用户输入图像验证码,以确认访问者是人类而非爬虫程序。
- 数据加载方式
一些网站可能会使用JavaScript等技术来动态加载页面内容, ers可能会对这种页面结构难以处理。
相关文章:
深入了解百度爬虫工作原理
在当今数字化时代,互联网已经成为人们获取信息的主要渠道之一。而搜索引擎作为互联网上最重要的工具之一,扮演着连接用户与海量信息的桥梁角色。然而,我们是否曾经好奇过当我们在搜索引擎中输入关键词并点击搜索按钮后,究竟是如何…...

【C语言基础】分享近期学习到的volatile关键字、__NOP__()函数以及# #if 1 #endif
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...

docker容器自启动
场景 当服务器关机重启后,docker容器每次都要去docker start 容器id 怎么可以下次让它自启动呢? 解决 先 # docker ps -a 查到之前启动过的容器id # docker update --restartalways 容器id重启后,reboot,就不用再单独去启动容…...

【C++】:模板的使用
目录 1、泛型编程 2、函数模板 2.1、函数模板概念 2.2、函数模板格式 2.3、函数模板的原理 2.4、函数模板的实例化 2.6、模板参数的匹配原则 3、类模板 3.1、 类模板的定义格式 3.2、 类模板的实例化 4、非类型模板参数 5、模板的特化 5.1、函数模板特化 5.2、类模…...

Springboot框架中使用 Redis + Lua 脚本进行限流功能
Springboot框架中使用 Redis Lua 脚本进行限流功能 限流是一种用于控制系统资源利用率或确保服务质量的策略。在Web应用中,限流通常用于控制接口请求的频率,防止过多的请求导致系统负载过大或者防止恶意攻击。 什么是限流? 限流是一种通过…...
 人名分类器实战项目(对比RNN、LSTM、GRU模型))
【nlp】2.5(cpu version) 人名分类器实战项目(对比RNN、LSTM、GRU模型)
人名分类器实战项目 0 项目说明1 案例介绍2 案例步骤2.1 导入必备的工具包2.2 数据预处理2.2.1 获取常用的字符数量2.2.2 国家名种类数和个数2.2.3 读数据到python环境中2.2.4 构建数据源NameClassDataset2.2.5 构建迭代器遍历数据2.3 构建RNN及其变体模型2.3.1 构建RNN模型2.3…...
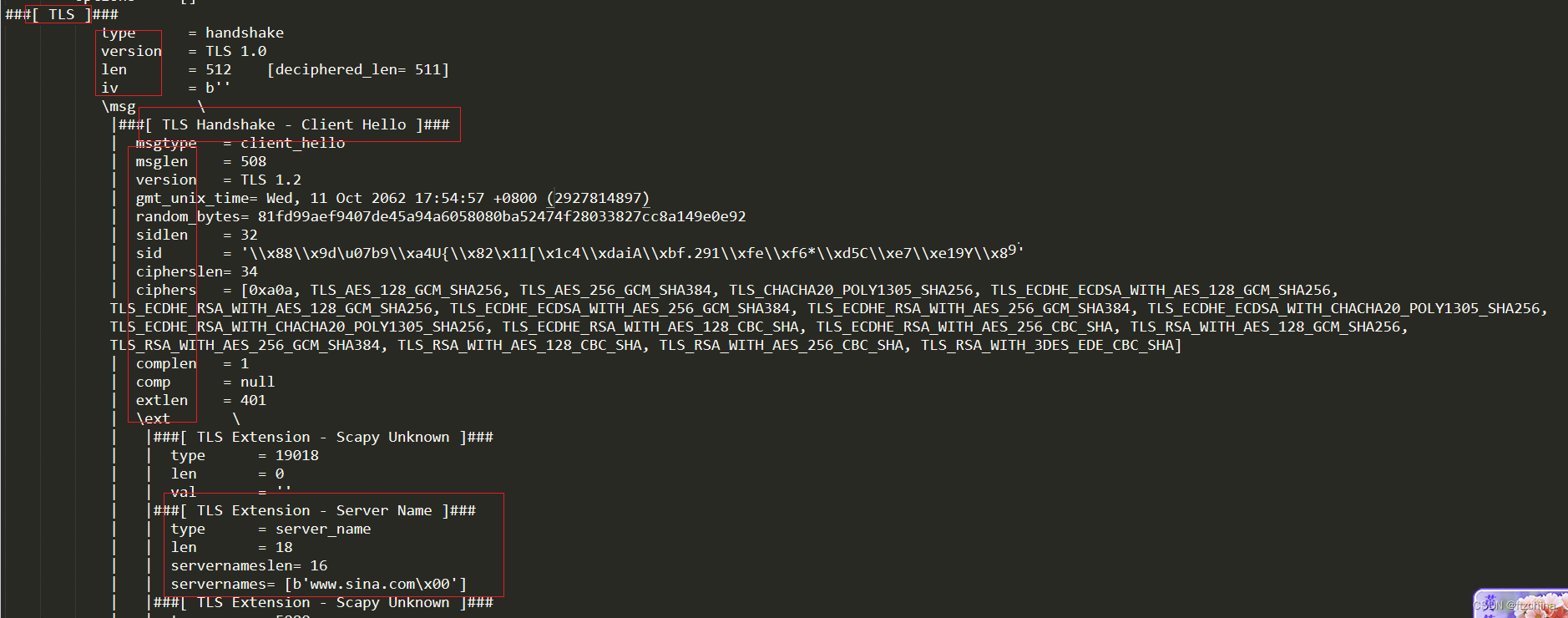
记录基于scapy构造ClientHello报文的尝试
最近有个需求就是用scapy构造https的client hello报文,由用户指定servername构造对应的报文。网上对于此的资料甚少,有的也是怎么去解析https报文,但是对于如果构造基本上没有找到相关的资料。 一直觉得最好的老师就是Python的help功能和dir功…...

程序设计实践学习笔记
第1题 题目描述 创建一个返回四舍五入到最接近整数的分数之和的函数。在矩阵中有每行的第一个数字表示分子,第二个数子表示分母,挑战者需要将该分数的结果进行四舍五入并将矩阵中所有分数结果总和进行返回。 输入输出格式 输入格式 数字 N 表示的是矩阵的行数。…...
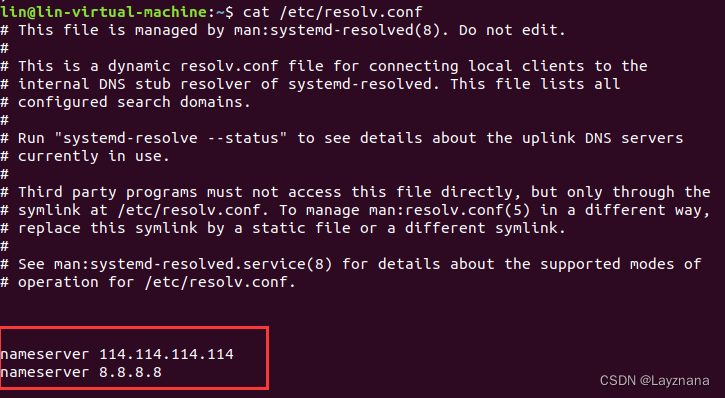
Ubuntu中apt-get update显示域名解析失败
第一步 检查主机->虚拟机能否ping成功 ping 红色框中的IPv4地址 能通,表示虚拟机ip配置成功;否则,需要先配置虚拟机ip 第二步 检查是否能ping成功百度网址 ping www.baidu.com 若不成功,可能原因 虚拟机没联网,打开火狐浏览器…...

go学习之简单项目
项目 文章目录 项目1.项目开发流程图2.家庭收支记账软件项目2)项目代码实现3)具体功能实现 3.客户信息管理系统1)项目需求说明2)界面设计3)项目框架图4)流程5)完成显示客户列表的功能6ÿ…...

代码随想录二刷 | 数组 | 总结篇
代码随想录二刷 | 数组 | 总结篇 基础知识二分查找移除元素有序数组的平方长度最小的数组最小覆盖子串螺旋数组 基础知识 定义:数组是存放在连续内存空间上的相同类型数据的集合 特点: 数组下标从 0 开始数组内存空间的地址是连…...

go test 命令详解
文章目录 1.简介2.test flag3.test/binary flags4.常用选项5.示例参考文献 1.简介 go test 是 Go 用来执行测试函数(test function)、基准函数(benchmark function)和示例函数(example function)的命令。 …...
【Mysql学习笔记】1 - Mysql入门
一、Mysql5.7安装配置 下载后会得到zip 安装文件解压的路径最好不要有中文和空格这里我解压到 D:\hspmysql\mysql-5.7.19-winx64 目录下 【根据自己的情况来指定目录,尽量选择空间大的盘】 添加环境变量 : 电脑-属性-高级系统设置-环境变量,在Path 环境变量增加mysq…...
sentinel 网关
网关简介 大家都都知道在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用。 这样的架构,会存在…...

常见面试题-MySQL的Explain执行计划
了解 Explain 执行计划吗? 答: explain 语句可以帮助我们查看查询语句的具体执行计划。 explain 查出来的各列含义如下: id:在一个大的查询语句中,每个 select 关键字都对应一个唯一的 id select_type:…...
SpringBoot静态资源配置
项目中 SSM中配置 第一种:配置文件中 <mvc:resources mapping"/js/**" location"/js/"/> <mvc:resources mapping"/css/**" location"/css/"/> <mvc:resources mapping"/html/**" location&q…...

Java拼图
第一步是创建项目 项目名自拟 第二部创建个包名 来规范class 然后是创建类 创建一个代码类 和一个运行类 代码如下: package heima;import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyEvent; import jav…...

Linux 怎样通过win 远程桌面连接链接Linux后台服务器的可视化图形界面
目的概述:因不想后台直接操作(操作不便),所以想到能否基于xrdp协议服务利用 win自带的远程桌面服务,链接到后台,类似于vnc的使用方式,涉及操作系统版本:win11 、 CentOS 7.4 、CentO…...

Java 实现随机图形
要求 定义4个类,MyShape、MyLine、MyRectangle和MyOval,其中MyShape是其他三个类的父类。MyShape为抽象类,包括图形位置的四个坐标;一个无参的构造方法,将所有的坐标设置为0;一个带参的构造函数࿰…...

java 读写文件的代码。
java 读写文件的代码。 import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStr…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

如何快速实现U盘文件自动备份:USBCopyer终极指南
如何快速实现U盘文件自动备份:USBCopyer终极指南 【免费下载链接】USBCopyer 😉 用于在插上U盘后自动按需复制该U盘的文件。”备份&偷U盘文件的神器”(写作USBCopyer,读作USBCopier) 项目地址: https://gitcode.…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...