HDFS、MapReduce原理--学习笔记
1.Hadoop框架
1.1框架与Hadoop架构简介
(1)广义解释
从广义上来说,随着大数据开发技术的快速发展与逐步成熟,在行业里,Hadoop可以泛指为:Hadoop生态圈。
也就是说,Hadoop指的是大数据生态圈整体。
(2)狭义解释
从狭义上来说,Hadoop是指Hadoop这个开源框架,它的核心组件有:
a)HDFS(分布式文件系统):解决海量数据存储;
b)MapReduce(分布式计算):解决海量数据计算;
c)YARN(作业资源调度):解决资源任务调度。
为什么大数据框架Hadoop需要引入分布式技术呢?
分布式指的是:多台计算机(或服务器)完成不同事情。
比如,多台电脑完成不同工作,类似于:一个餐厅厨房有3个人,一个人买菜、一个人切菜、一个人炒菜,效率提高了
从广义上来说,Hadoop指的是Hadoop大数据生态圈;而从狭义上而言,Hadoop是指Hadoop开源框架。
2.HDFS组件
2.1HDFS简介
HDFS(Hadoop Distribute File System)指的是:Hadoop分布式文件系统,是Hadoop核心组件之一,用于提供分布式存储服务。
HDFS分布式文件系统的基础架构是怎样的呢?包含三个角色:
(1)NameNode主节点
HDFS系统的主角色,是一个独立的进程。
a)负责管理HDFS整个文件系统;
b)负责管理DataNode。
(2)DataNode从节点
HDFS系统的从角色,是一个独立进程。
a)主要负责数据的存储,即存入数据和取出数据。
(3)Secondary NameNode辅助节点
NameNode的辅助,是一个独立进程。
a)主要帮助NameNode完成元数据整理工作(打杂)。[Hive]
(1)数据信息存储在了HDFS分布式文件系统中
(2)使用DataGrip客户端编写HQL程序
(3)MySQL存储元数据,且映射存储在HDFS中的数据信息
由于单机存储性能有限,此时,采用更多数量的服务器提供分布式存储,可以实现1+1>2的效果。
2.2 管理数据资源
1,分块管理
当有了HDFS分布式文件存储系统,就可以来存储数据文件了。
那么,当把大小不一的数据文件存储到各台服务器中,会遇到什么麻烦呢?
(1)在hdfs-site.xml文件中配置[了解]
要如何设置默认文件上传到HDFS中拥有的副本数量呢?路径名:
/export/server/hadoop/etc/hadoop/hdfs-site.xml
# 在文件中的<configuration>标签内做设定.
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
HDFS在使用分块管理数据的同时,还对数据块进行了备份处理,并实现了三副本机制。
2.3edits与fsimage
我们知道,在HDFS中,文件是被划分了一堆堆的block块
那么,如果文件很大且很多,而HDFS又是如何记录及整理文件和block块的关系呢?
实际上,NameNode主节点就会负责处理这些问题。
在NameNode主节点中,有:
(1)edits:负责记录文件、块信息,有很多edits
(2)fsimage:会将多个edits合并为fsimage
(1)edits
edits是一个流水账文件,记录了HDFS中的每一次操作,以及本次操作影响的文件及对应的block信息。
(2)fsimage
为了操作便捷,会将全部的edits,都合并为最终结果,此时,就得到了一个fsimage文件。
通常地,edits用于记录每一次操作,多个或所有edits文件合并成fsimage。
2.4查看元数据文件
了解了edits和fsimage后,则会有个问题产生:edits和fsimage存放在哪呢?
(1)NameNode存放路径:
edits和fsimage路径: /export/data/hadoop/dfs/name/current
(2)DataNode存放路径
edits和fsimage路径: /export/data/hadoop/dfs/data/current
在HDFS基础架构的不同角色中,对于元数据的处理遵循:
(1)NameNode:元数据管理维护
(2)SecondaryNameNode:元数据合并
(1)NameNode:元数据管理维护
NameNode基于edits和FSImage的配合,会完成整个文件系统数据文件的管理:
a)每次对HDFS的操作,均被edits文件记录
b)edits达到大小上限后,会开启新的edits记录
c)定期进行edits的合并操作
如当前没有fsimage文件,会将全部edits合并为第一个fsimage;
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage;
d)重复123流程。
(2)SecondaryNameNode:元数据合并
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage),然后合并完成后,定期提供给NameNode使用。
对于元数据的合并,是一个定时过程,只要有一个达到条件就执行。基于:
dfs.namenode.checkpoint.period,默认3600(秒)即1小时
dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
检查是否达到条件,默认60秒检查一次,基于:
dfs.namenode.checkpoint.check.period,默认60(秒),来决定
2.5元数据存储原理
HDFS的基础架构为:
(1)NameNode主节点
用于管理HDFS元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息….)。
(2)DataNode从节点
用于真正存储数据块。
(3)Secondary NameNode辅助节点
用于辅助NameNode,并分担其工作量。
元数据在NameNode、Secondary NameNode之间是怎么来存储的呢?
(1)NameNode
1)NameNode第一次启动时,先把最新的fsimage文件中内容加载到内存中,同时会把
edits文件中内容也加载到内存中;
2)客户端发起指令(增删改查等操作),NameNode接收到客户端指令把每次产生的新的指令操作先放到内存中;
3)然后把刚才内存中新的指令操作写入到edits_inprogress文件中;
4)edits_inprogress文件中数据到了一定阈值的时候,把文件中历史操作记录写入到序列化的edits备份文件中(同时更新文件名);
5)NameNode就在上述2-4步中循环操作...
(2)Secondary NameNode
1)当Secondary NameNode检测到自己距离上一次检查点(checkpoint)已经1小时或者事务数达到100w,就触发Secondary NameNode询问NameNode是否对edits文件和fsimage文件进行合并操作;
2)NameNode告知可以进行合并;
3)Secondary NameNode将NameNode上积累的所有edits和一个最新的fsimage下载/拉取到本地,并加载到内存进行合并(这个过程称检查点checkpoint);
4)Secondary NameNode把刚才合并后的fsimage.checkpoint文件拷贝给NameNode;
5)NameNode把拷贝过来的最新的fsimage.checkpoint文件,重命名为fsimage,覆盖原来的文件。
一般地,edits、fsimage存储的文本内容都进行了序列化和反序列化操作,因此内容基本乱码。
2.6HDFS存储原理
副本机制
当使用HDFS分布式文件系统存储数据时,遵循三个原理机制:(1)副本机制
(2)负载均衡机制
(3)心跳机制
副本机制指的是:为了保证数据安全和效率,每个block块会默认切割为128MB(134217728字节),且block块信息会存储多个副本,默认是3个。
而当存储多个副本,满足条件:
(1)第一副本保存在客户端所在服务器;
(2)第二副本保存在和第一副本不同机架服务器上;
(3)第三副本保存在和第二副本相同机架的不同服务器中。
Rack是机架名称,Node是服务器名称。机架与服务器之间满足:
(1)一个机架上,可以安装多台服务器
(2)一个服务器中,运行一个DataNode服务
block如何选择写入副本的DataNode呢?
a)第一个副本选择本地机架,距离近,上传速度快;
b)第二个副本选择远程机架的随机节点,保证数据的可靠性;
c)第三个副本选择第二个副本所在机架的随机节点,而不是其他机架,是同时兼顾可靠性+效率的。
当备份第2、3个副本时,通常存放在一个机架中,遵循就近原则。
2.7负载均衡机制
负载均衡就是一种计算机网络技术,用来在计算机集群、网络连接、CPU、磁盘或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间,同时避免过载的目的。
通俗地说,负载均衡就是给各个服务器node分配的任务尽可能均匀一些,不至于谁特别闲,谁又特别忙。
负载均衡机制是NameNode为了保证不同的DataNode中block块信息大体一致,而分配存储任务时,会优先保存在存储容量比较大的DataNode上。
一般地,集群往往需要通过负载均衡,来对外提供服务。而HDFS存储数据时,也遵循负载均衡机制。
在负载均衡机制下,节点的磁盘利用率会尽可能的均等。
比如,在集群环境中,不同服务器存储的block信息效果。
虽然HDFS存储数据时,遵循负载均衡,但这种均衡属于相对均衡,即尽可能均等分配。
2.8心跳机制
心跳机制就是每隔几分钟发送一个固定信息给服务端,服务端收到后回复一个固定信息。如果服务端几分钟内,没有收到客户端信息,则视客户端已断开。发包方可以是
客户端,也可以是服务端,具体看哪边实现更方便、合理。
(1)DataNode每隔3秒钟向NameNode汇报自己的状态信息;
(2)如果某个时刻,DataNode连续10次不汇报了,NameNode会认为DataNode有可能宕机了;
(3)NameNode就会每5分钟(300000毫秒)继续发送一次确认消息,连续2次没有收到回复,就认定DataNode此时一定宕机了。
2.9HDFS读写数据
HDFS写入数据流程
在HDFS写入数据时,有几个注意事项:
(1)数据包
每次读取64kb大小的数据,称之为一个packet数据包。然后将packet数据包写入一个队列中,反复多次读完文件的全部数据,且都会写入到队列(data queue)中;
(2)记录信息
NameNode会对文件进行一系列检查,比如是否有同名文件、路径对不对等,并记录新文件的信息到元数据中,以及记录文件写入的数据块信息
(3)保存副本
NameNode会管理对应的DataNode,确认数据是否已经被保存在block块中。当检测到至少保存了一个副本的数据,则认为数据已保存成功。
写入流程:
1)客户端给NameNode,发起写入数据的请求;
2)NameNode接收到客户端请求后,开始校验(是否有权限、路径是否存在、文件是否
存在等),如果校验成功,就告知客户端可以准备写入数据;
3)客户端收到可以写入的消息后,开始把文件数据分割成默认128MB大小的block块,并且把block块数据拆分成64kb的packet数据包,然后放入传输队列;
4)客户端携带block块信息,再次向NameNode发送请求,获取能够存储block块的DataNode列表;
5)NameNode查看当前距离上传位置较近且不忙的DataNode,放入列表中,返回给客户端;
6)客户端连接DataNode,开始发送packet数据包,第一个DataNode接收完后,就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个DataNode开始复制刚才接收到的数据包给DataNode2,接收后也复制给DataNode3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道;
7)其他packet数据包,根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块传输完成(存储了block信息的DataNode需要把已经存储的块信息定期的同步给NameNode);
8)其他block块数据存储,反复多次执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(NameNode把该文件的元数据也要保存);
9)最后客户端和NameNode互相确认,文件数据已经保存完成。
2.10HDFS读取数据流程
在HDFS读取数据时,有几个注意事项:
NameNode会对文件进行一系列检查,比如如文件是否存在,是否有权限获取等。
读取流程:
1)客户端给NameNode发送读取文件请求;
2)NameNode接收到请求,然后进行一系列校验(路径是否存在、文件是否存在、是否有权限等),如果没有问题,就告知可以开始读取;
3)客户端需要再次和NameNode确认当前文件在哪些DataNode中存储;
4)NameNode查看当前距离下载位置较近且不忙的DataNode,放入列表中返回给客户端;
5)客户端找到最近的DataNode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包),放到内存缓冲区中;
6)接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据);
7)最后从内存缓冲区把数据通过流写入到目标文件中。
3,归档模式
,为什么要归档呢?
在存入数据文件到HDFS时,会发现每个小文件单独存放到HDFS都会占用一个block块,那么HDFS就需要依次存储每个小文件的元数据信息,浪费资源。当然,归档后也更加便于集中管理!
当要对一些数据文件进行归档时,语法:
hadoop archive -archiveName 归档名称.har -p 原始文件的目录 归档文件的存储目录
归档后文件结尾为.har。
若要查看归档后的目录或文件信息,可以使用命令:
# 查看文件或目录列表信息
hdfs dfs -ls 目录或文件名
# 查看文件内容
hdfs dfs -cat 文件名
# 查看归档内的单个文件内容
hdfs dfs -cat har:///xxx/归档名称.har/文件名hadoop archive -archiveName test.har -p
/itheima/code /arch
3.1垃圾桶机制
垃圾桶模式,类似于Windows系统的回收站
(1)未设定垃圾桶模式时
删除数据则无法恢复,直接永久删除了
(2)设定垃圾桶模式后
已删除的文件或不会立刻消失,而是会存放在HDFS
的/user/root/.Trash/Current/目录下
此时,可以去垃圾桶里把文件进行恢复,并继续使用
当设定垃圾桶模式时,有两种常见方式:
(1)直接在Shell中使用vi命令修改
这个方式设定垃圾桶模式有个缺陷: 先关闭Hadoop服务,比如在node1中执行
stop-all.sh,而后再启动服务
(2)使用第3方终端软件修改,比如NotePad++
修改模式后,保存文件即可生效.
/export/server/hadoop-3.3.0/etc/hadoop
# 找到core-site.xml
修改core-site.xml文件,记得必须先在文件的标签下添加
<!-- 设置垃圾桶模式 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
当设定为垃圾桶模式后,可以执行命令:
# 删除hdfs中的某文件
hdfs dfs -rm 文件名
# 恢复已删除的文件
hdfs dfs -mv /user/root/.Trash/Current/路径及文件名 指定恢复到的目录名
当未设定垃圾桶模式时,删除文件则直接被丢失了。[注意]
还需注意的是:在Web页面上点击按钮删除文件时,是永久删除(会跳过回收站,直接删除)。
当在HDFS中,从垃圾桶中恢复数据,执行的是mv移动命令
4,MapReduce组件
MapReduce简介
MapReduce表示分布式计算,顾名思义,即以分布式技术完成数据的统计,得到需要的结果。
MapReduce也是Hadoop核心组件之一,用于提供分布式计算服务。
a)Map阶段并行处理输入的数据;
b)Reduce阶段对Map结果进行汇总处理。
在大数据开发技术下的分布式计算引擎,常见模式有
(1)分散 -> 汇总模式
MapReduce
(2)中心调度 -> 步骤执行模式
Spark、Flink
4.1统计词频
1)先要进入到mapreduce所在目录,命令:
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
2)接着,执行案例程序命令:
hadoop jar hadoop-mapreduce-examples-3.3.0.jar 案例名 数据文件路径名 生成结果路径名
4.2WordCount原理
值得注意的是,MapReduce的核心思想:分而治之。
所谓分而治之,就是把一个复杂的问题按一定的 分解方法分为规模较小的若干部分,然后逐个解决,分别找出各部分的解,再把各部分的解组成整个问题的结果。在这期间:
(1)Map:负责【分】,即把复杂的任务分解为若干个“简单的任务”来并行处理;
(2)Reduce:负责【合】,即对map阶段的结果进行全局汇总处理。
a. Map功能接口提供了【分散】的功能, 由服务器分布式对数据进行处理;
b. Reduce功能接口提供了【汇总(聚合)】的功能,将分布式的处理结果汇总统计。[分析]
此时,我们就来简单分析一下,WordCount案例是如何通过MapReduce完成分布式计算的?
假定有4台服务器用来执行MapReduce任务,其中,3台服务器执行Map,1台服务器执行Reduce。
对于MapReduce执行任务的流程,要多思考加多动手实践,才能出真知
4.3MapReduce阶段任务
MapReduce计算会依次走3个阶段任务:
阶段1:Map阶段
阶段2:Shuffle阶段
阶段3:Reduce阶段 [wordcount]
MapReduce在Map阶段的基本流程:
第1步:是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size等于Block size[128MB]。每一个切片由一个MapTask处理(当然,也可以通过参数单独修改split大小);
第2步:是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容;
第3步:是调用Mapper类中的map()方法。把上阶段中每解析出来的一个,都调用一次map()方法,而每次调用map()方法都会输出零个或多个键值对;
第4步:是按照一定的规则,对第3步输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。且默认只有一个Reducer任务;
第5步:是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第6步,那么进入第6步;如果没有,直接输出到文件中;
第6步:是对数据进行局部聚合处理,也就是combiner(规约、组合)处理。键相等的键值对会调用一次reduce方法。经过这一步,数据量会减少。当然,本步骤默认是没有的。
阶段2:Shuffle阶段[数据小块 -> 合并且排序后结果]
shuffle阶段是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段之间。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。依次进行
Collect(收集) -> Spill(溢出) -> Merge(合并) -> Copy(复制) ->
Merge(合并) -> Sort(排序)
1
Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是
key/value,Partition分区信息等;Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序;Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件;Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上;Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作;Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
阶段3:Reduce阶段[各部分结果 -> 合并总结果]
MapReduce在Reduce阶段的基本流程:
第1步:是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出;第2步:是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序;
第3步:是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。当要把数据进行收集且排序处理的阶段,一般是指Shuffle阶段
注意:MapReduce是Hadoop中的分布式计算组件,一般以【分散->汇总(聚合)模式】执行计算任务。

相关文章:
HDFS、MapReduce原理--学习笔记
1.Hadoop框架 1.1框架与Hadoop架构简介 (1)广义解释 从广义上来说,随着大数据开发技术的快速发展与逐步成熟,在行业里,Hadoop可以泛指为:Hadoop生态圈。 也就是说,Hadoop指的是大数据生态圈整…...

PC端使子组件的弹框关闭
子组件 <template><el-dialog title"新增部门" :visible"showDialog" close"close"> </el-dialog> </template> <script> export default {props: {showDialog: {type: Boolean,default: false,},},data() {retu…...
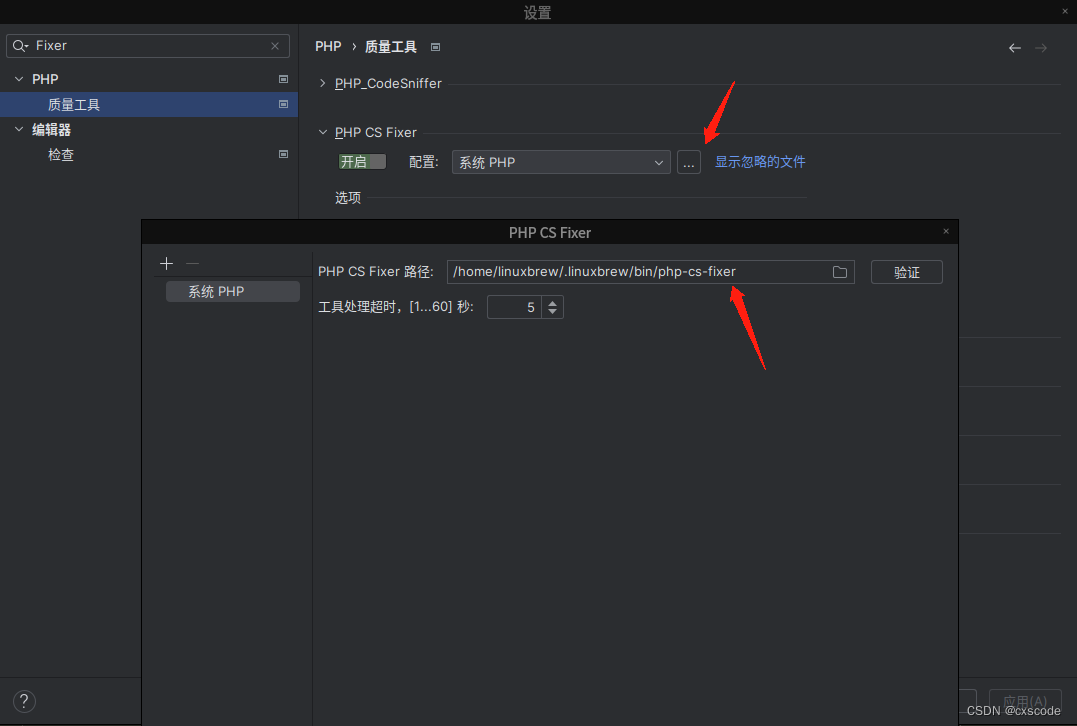
PHPStorm PHP-CS-Fixer
我用的是brew安装: brew install php-cs-fixer phpstorm配置: setting搜索fixer 指定安装php-cs-fixer的目录: https://github.com/PHP-CS-Fixer/PHP-CS-Fixer/blob/master/doc/installation.rst 图文详解PHPStorm实现自动执行代码格式化-…...

SpringBoot中日志的使用log4j
SpringBoot中日志的使用log4j 项目中日志系统是必不可少的,目前比较流行的日志框架有 log4j、logback 等,这两个框架的作者是同一个 人,Logback 旨在作为流行的 log4j 项目的后续版本,从而恢复 log4j 离开的位置。 另外 slf4j(…...

迭代器与生成器
章节目录: 一、迭代器1.1 相关概述1.2 基本使用1.3 自定义迭代器 二、生成器2.1 相关概述2.2 基本使用2.3 三种应用场景 三、yield 和 class 定义的迭代器对比四、结束语 一、迭代器 1.1 相关概述 迭代是 Python 最强大的功能之一,是访问集合元素的一种…...
适用于 Windows 的 10 个最佳视频转换器:快速转换高清视频
您是否遇到过由于格式不兼容而无法在您的设备上播放视频或电影的情况?您想随意播放从您的相机、GoPro 导入的视频,还是以最合适的格式将它们上传到媒体网站?您的房间里是否有一堆 DVD 光盘,想将它们转换为数字格式以便于播放&…...

分布式锁的概念、应用场景、实现方式和优缺点对比
一:什么是分布式锁 分布式锁是一种用于协调分布式系统中多个节点对共享资源的访问的机制。在分布式系统中,由于多个节点的并发执行,可能会导致对共享资源的竞争,而分布式锁的目的就是确保在任何时刻,只有一个节点能够持…...

Linux:常见指令
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》 文章目录 前言一、常见指令ls指令pwd指令cd指令touch指令mkdir指令rmdir指令rm指令man指令cp指令mv指令cat指令tac指令echo指令more指令less指令head指令tail指令date显示Cal指令find指令gr…...

大数据基础设施搭建 - ZooKeeper
文章目录 一、上传压缩包二、解压压缩包三、本机安装3.1 修改配置文件3.1.1 创建ZooKeeper数据存储目录3.1.2 修改配置文件名3.1.2 修改配置文件内容 3.3 启动/停止服务端3.4 测试(1)启动客户端(2)测试客户端操作 四、集群安装4.1…...

网站优化工具Google Optimize
Google Optimize 是一款由Google提供的网站优化工具。Google Optimize旨在帮助网站管理员通过对网页内容、设计和布局进行测试和优化,来提升用户体验和网站的转化率。 Google Optimize 提供了 A/B 测试和多变量测试功能,使网站管理员能够比较和评估不同…...

PostgreSQL创建分区表,并插入大量数据
创建分区表,按日期范围分区 CREATE TABLE sales (id serial,sale_date DATE, amount NUMERIC, PRIMARY KEY(id, sale_date) ) PARTITION BY RANGE (sale_date); 创建分区 CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM (2019-0…...

NewStarCTF2023 Reverse Week3 EzDLL WP
分析 这里调用了z3h.dll中的encrypt函数。 用ida64载入z3h.dll 直接搜索encrypt 找到了一个XTEA加密。接着回去找key和密文。 发现key 这里用了个调试状态来判断是否正确,v71,要v7=1才会输出Right,即程序要处于飞调试状态。 可…...
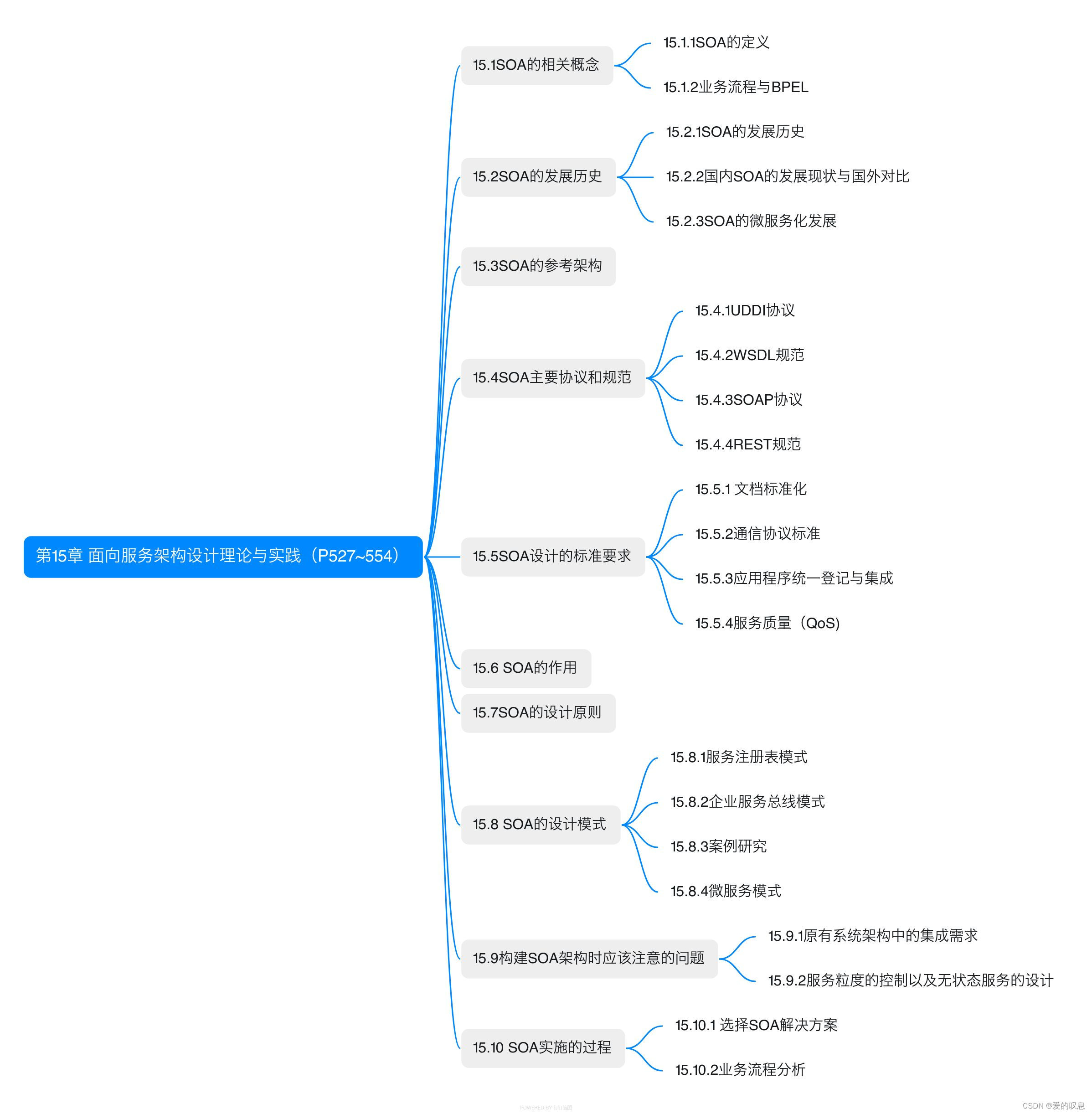
软考-高级-系统架构设计师教程(清华第2版)【第15章 面向服务架构设计理论与实践(P527~554)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第15章 面向服务架构设计理论与实践(P527~554)-思维导图】 课本里章节里所有蓝色字体的思维导图...
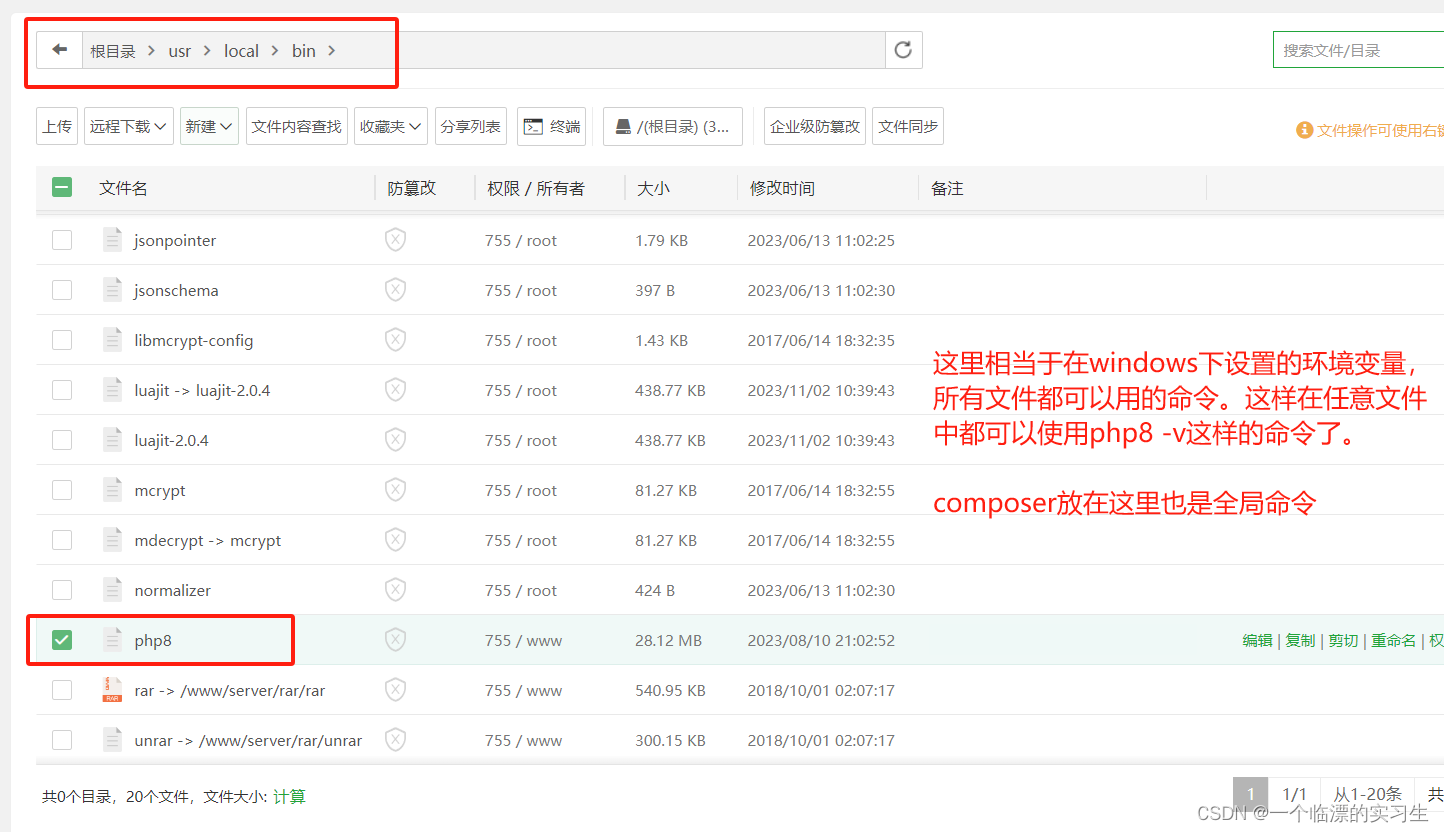
php-cli
//运行index.php ./php index.php//启动php内置服务器 ./php -S 0.0.0.0:8080//启动内置服务在后台运行,日志输出到本目录下的server.log nohup ./php -S 0.0.0.0:8080 -t . > server.log 2>&1 &# 查找 PHP 进程 ps aux | grep "php -S 0.0.0.0:…...
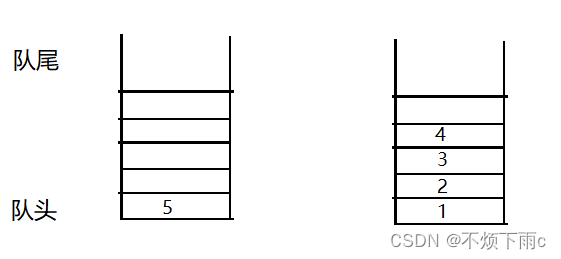
[C/C++] 数据结构 LeetCode:用队列实现栈
题目描述: 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元…...

ESP32网络开发实例-物联网声污染监测系统
物联网声污染监测系统 文章目录 物联网声污染监测系统1、KY-038 声音传感器模块2、软件准备3、硬件准备4、代码实现在本文中,我们将使用 ESP32、声音模块和 Blynk 应用程序创建一个基于物联网的声音污染监测系统。 我们将使用 KY-038 麦克风传感器以分贝为单位检测声音并在 OL…...

Unexpected error from cudaGetDeviceCount 错误解决
Unexpected error from cudaGetDeviceCount 错误解决 0. 背景1. 解决方法 0. 背景 新配置了1台服务器,有4张4090显卡。 在 wsl-ubuntu 里执行 python -c “import torch;print(torch.cuda.is_available());” 命令时,会报以下错误。 /root/miniconda3…...

目标检测—YOLO系列(二 ) 全面解读复现YOLOv1 PyTorch
精读论文 前言 从这篇开始,我们将进入YOLO的学习。YOLO是目前比较流行的目标检测算法,速度快且结构简单,其他的目标检测算法如RCNN系列,以后有时间的话再介绍。 本文主要介绍的是YOLOV1,这是由以Joseph Redmon为首的…...
使用C#插件Quartz.Net定时执行CMD任务工具2
目录 创建简易控制台定时任务步骤完整程序 创建简易控制台定时任务 创建winform的可以看:https://blog.csdn.net/wayhb/article/details/134279205 步骤 创建控制台程序 使用vs2019新建项目,控制台程序,使用.net4.7.2项目右键(…...

Java实现两数之和-算法
题意 给出一个数组和一个目标值,让你在该数组中找出和为目标值的两个数,并且这两个数在数组中的下标不同。 示例 输入: nums [2,7,11,15], target 9 输出: [0,1] 解释: 因为 nums[0] nums[1] 9 ,返回 […...

深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构
深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

将deepseek v4 pro集成到codex桌面APP中使用
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...

OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS
OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重获新…...

如何快速配置虚拟显示器:面向初学者的完整指南
如何快速配置虚拟显示器:面向初学者的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否在为游戏串流画质不佳而烦恼?或者需要为无显示器主机…...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...