卷积神经网络(CNN)天气识别
文章目录
- 前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 我的环境:
- 2. 导入数据
- 3. 查看数据
- 二、数据预处理
- 1. 加载数据
- 2. 可视化数据
- 3. 再次检查数据
- 4. 配置数据集
- 三、构建CNN网络
- 四、编译
- 五、训练模型
- 六、模型评估
前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")
2. 导入数据
import matplotlib.pyplot as plt
import os,PIL# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)from tensorflow import keras
from tensorflow.keras import layers,modelsimport pathlib
data_dir = "weather_photos/"
data_dir = pathlib.Path(data_dir)
3. 查看数据
数据集一共分为cloudy、rain、shine、sunrise四类,分别存放于weather_photos文件夹中以各自名字命名的子文件夹中。
image_count = len(list(data_dir.glob('*/*.jpg')))print("图片总数为:",image_count)
roses = list(data_dir.glob('sunrise/*.jpg'))
PIL.Image.open(str(roses[0]))

二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 1125 files belonging to 4 classes.
Using 900 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 1125 files belonging to 4 classes.
Using 225 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
['cloudy', 'rain', 'shine', 'sunrise']
2. 可视化数据
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")

3. 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(32, 180, 180, 3)
(32,)
Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。Label_batch是形状(32,)的张量,这些标签对应32张图片
4. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入,fashion_mnist 数据集中的图片,形状是 (28, 28, 1)即灰度图像。我们需要在声明第一层时将形状赋值给参数input_shape。
num_classes = 4model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3 layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.3), layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(num_classes) # 输出层,输出预期结果
])model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 178, 178, 16) 448
_________________________________________________________________
average_pooling2d (AveragePo (None, 89, 89, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 87, 87, 32) 4640
_________________________________________________________________
average_pooling2d_1 (Average (None, 43, 43, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 41, 41, 64) 18496
_________________________________________________________________
dropout (Dropout) (None, 41, 41, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 107584) 0
_________________________________________________________________
dense (Dense) (None, 128) 13770880
_________________________________________________________________
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 13,795,109
Trainable params: 13,795,109
Non-trainable params: 0
_________________________________________________________________
四、编译
- 在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
五、训练模型
epochs = 10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
Epoch 1/10
29/29 [==============================] - 6s 58ms/step - loss: 1.5865 - accuracy: 0.4463 - val_loss: 0.5837 - val_accuracy: 0.7689
Epoch 2/10
29/29 [==============================] - 0s 12ms/step - loss: 0.5289 - accuracy: 0.8295 - val_loss: 0.5405 - val_accuracy: 0.8133
Epoch 3/10
29/29 [==============================] - 0s 12ms/step - loss: 0.2930 - accuracy: 0.8967 - val_loss: 0.5364 - val_accuracy: 0.8000
Epoch 4/10
29/29 [==============================] - 0s 12ms/step - loss: 0.2742 - accuracy: 0.9074 - val_loss: 0.4034 - val_accuracy: 0.8267
Epoch 5/10
29/29 [==============================] - 0s 11ms/step - loss: 0.1952 - accuracy: 0.9383 - val_loss: 0.3874 - val_accuracy: 0.8844
Epoch 6/10
29/29 [==============================] - 0s 11ms/step - loss: 0.1592 - accuracy: 0.9468 - val_loss: 0.3680 - val_accuracy: 0.8756
Epoch 7/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0836 - accuracy: 0.9755 - val_loss: 0.3429 - val_accuracy: 0.8756
Epoch 8/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0943 - accuracy: 0.9692 - val_loss: 0.3836 - val_accuracy: 0.9067
Epoch 9/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0344 - accuracy: 0.9909 - val_loss: 0.3578 - val_accuracy: 0.9067
Epoch 10/10
29/29 [==============================] - 0s 11ms/step - loss: 0.0950 - accuracy: 0.9708 - val_loss: 0.4710 - val_accuracy: 0.8356
六、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

相关文章:
卷积神经网络(CNN)天气识别
文章目录 前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)我的环境: 2. 导入数据3. 查看数据 二、数据预处理1. 加载数据2. 可视化数据3. 再次检查数据4. 配置数据集 三、构建CNN网络四、编译五、训练模型六、模型评估 前期工作 1. 设置GP…...
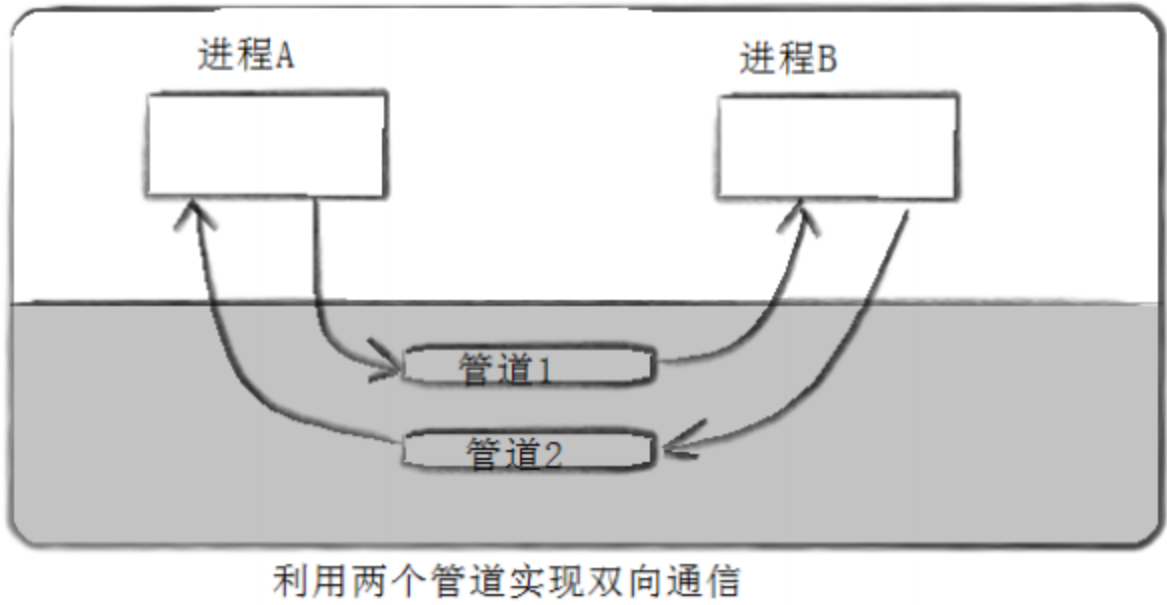
Linux进程间通信之匿名管道
文章目录 为什么要有进程间通信pipe函数共享管道原理管道特点管道的四种情况 管道的应用场景(进程池)ProcessPool.ccTask.hpp 为什么要有进程间通信 数据传输:一个进程需要将它的数据发送给另一个进程 资源共享:多个进程之间共享…...

【PTA题目】6-19 使用函数输出指定范围内的Fibonacci数 分数 20
6-19 使用函数输出指定范围内的Fibonacci数 分数 20 全屏浏览题目 切换布局 作者 C课程组 单位 浙江大学 本题要求实现一个计算Fibonacci数的简单函数,并利用其实现另一个函数,输出两正整数m和n(0<m≤n≤10000)之间的所有F…...

运行ps显示msvcp140.dll丢失怎么恢复?msvcp140.dll快速解决的4个不同方法
msvcp140.dll无法继续执行代码的主要原因有以下几点 系统缺失:msvcp140.dll是Visual Studio 2015编译的程序默认的库文件,如果系统中没有这个库文件,那么在运行相关程序时就会出现找不到msvcp140.dll的错误提示。 文件损坏:如果…...

Java多线程(3)
Java多线程(3) 深入剖析Java线程的生命周期,探秘JVM的线程状态! 线程的生命周期 Java 线程的生命周期主要包括五个阶段:新建、就绪、运行、阻塞和销毁。 **新建(New):**线程对象通过 new 关键字创建&…...

Java线程周期
Java线程的生命周期包含以下状态: 新建(New):当一个线程被创建但还没有被启动时,它的状态是新建。就绪(Runnable):当线程已经被启动并且没有任何阻止它立即运行的条件时,…...
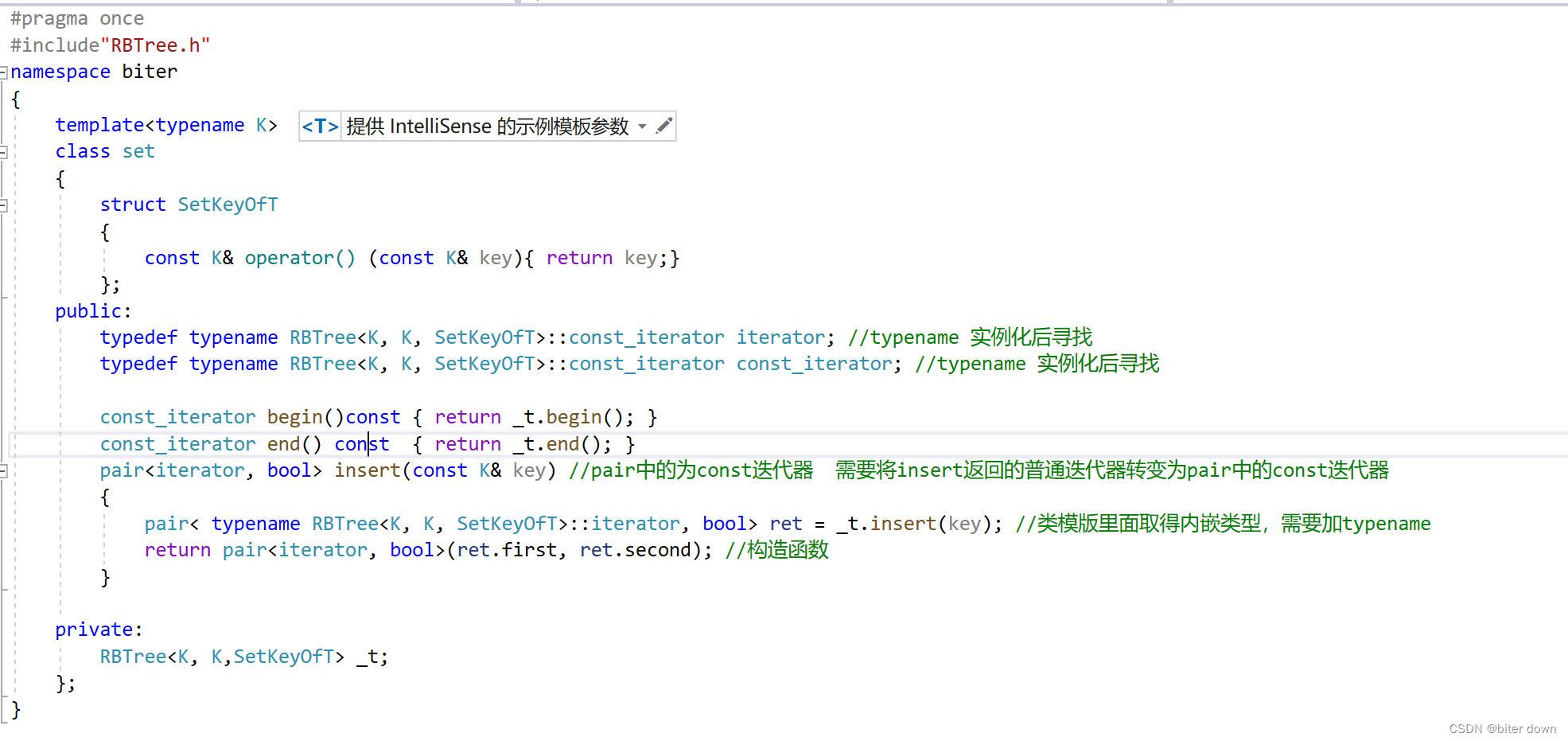
map与set的封装
目录 红黑树的结点 与 红黑树的迭代器 红黑树的实现: 迭代器: 编辑 红黑树的查找: 红黑树的插入: 编辑 检查红色结点:编辑红黑树的左旋 编辑红黑树的右旋 编辑红黑树的双旋 Map的封装 编辑set的…...
mac无法向移动硬盘拷贝文件怎么解决?不能读取移动硬盘文件怎么解决
有时候我们在使用mac的时候,会遇到一些问题,比如无法向移动硬盘拷贝文件或者不能读取移动硬盘文件。这些问题会给我们的工作和生活带来不便,所以我们需要找到原因和解决办法。本文将为你介绍mac无法向移动硬盘拷贝文件怎么回事,以…...

基于Netty实现的简单聊天服务组件
目录 基于Netty实现的简单聊天服务组件效果展示技术选型:功能分析聊天服务基础设施配置(基于Netty)定义组件基础的配置(ChatProperties)定义聊天服务类(ChatServer)定义聊天服务配置初始化类&am…...

视频封面:从视频中提取封面,轻松制作吸引人的视频
在当今的数字时代,视频已成为人们获取信息、娱乐和交流的重要方式。一个吸引人的视频封面往往能抓住眼球,提高点击率和观看率。今天将介绍如何从视频中提取封面,轻松制作吸引人的视频封面。 一、准备素材选择合适的视频片段 首先࿰…...
CICD 持续集成与持续交付——gitlab
部署 虚拟机最小需求:4G内存 4核cpu 下载:https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/ 安装依赖性 [rootcicd1 ~]# yum install -y curl policycoreutils-python openssh-server perl[rootcicd1 ~]# yum install -y gitlab-ce-15.9.3-ce.0…...

Linux - 驱动开发 - RNG框架
说明 公司SOC上有一个新思的真随机数(TRNG)模块,Linux平台上需要提供接口给外部使用。早期方式是提供一个独立的TRNG驱动,实现比较简单的,但是使用方式不open,为了加入Linux生态环境,对接linux…...
qsort使用举例和qsort函数的模拟实现
qsort使用举例 qsort是C语言中的一个标准库函数,用于对数组或者其他数据结构中的元素进行排序。它的原型如下: void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); 我们可以去官网搜来看一看:…...

AttributeError: module ‘gradio‘ has no attribute ‘ClearButton‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
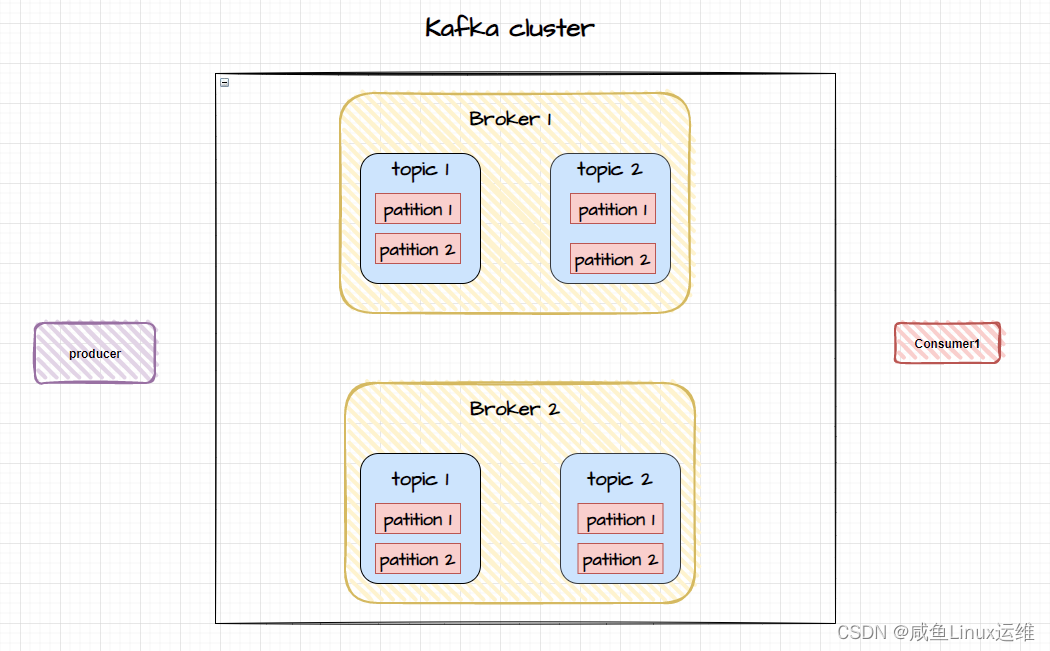
Kafka 集群如何实现数据同步?
哈喽大家好,我是咸鱼 最近这段时间比较忙,将近一周没更新文章,再不更新我那为数不多的粉丝量就要库库往下掉了 T﹏T 刚好最近在学 Kafka,于是决定写篇跟 Kafka 相关的文章(文中有不对的地方欢迎大家指出)…...
一本了解生成式人工智能
上周,发了一篇关于大语言模型图数据库技术相结合的文章,引起了很多朋友的兴趣。当然了,这项技术本身就让俺们很兴奋,比如我就是从事图研发的,当然会非常关注它在图领域的应用与相互促就啦。 纵观人类文明历史ÿ…...
)
git 相关指令总结(持续更新中......)
文章目录 一、git clone 相关指令1.1 clone 指定分支的代码 一、git clone 相关指令 1.1 clone 指定分支的代码 git clone -b 分支名 仓库地址...
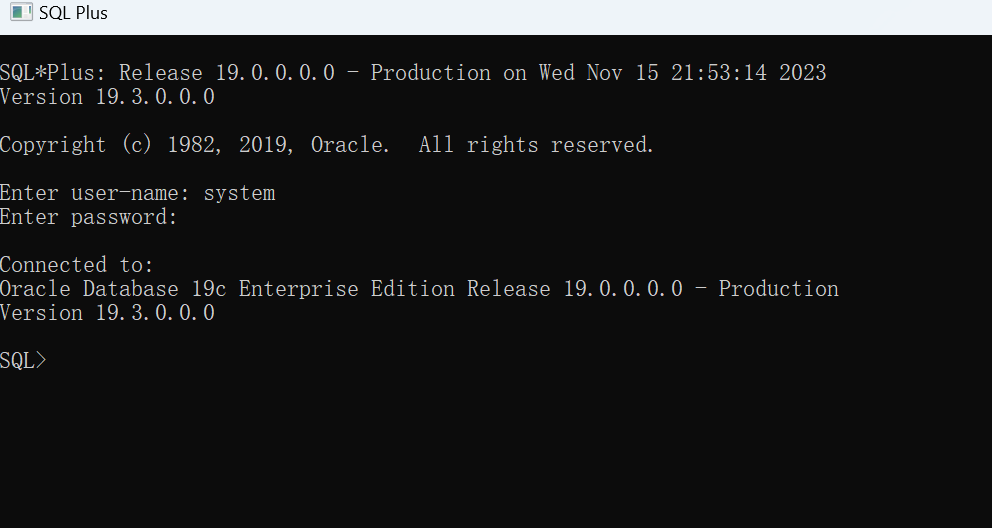
windows 安装 Oracle Database 19c
目录 什么是 Oracle 数据库 下载 Oracle 数据库 解压文件 运行安装程序 测试连接 什么是 Oracle 数据库 Oracle数据库是由美国Oracle Corporation(甲骨文公司)开发和提供的一种关系型数据库管理系统,它是一种强大的关系型数据库管理系统…...

【数据结构】图的存储结构(邻接矩阵)
一.邻接矩阵 1.图的特点 任何两个顶点之间都可能存在边,无法通过存储位置表示这种任意的逻辑关系。 图无法采用顺序存储结构。 2.如何存储图? 将顶点与边分开存储。 3.邻接矩阵(数组表示法) 基本思想: 用一个一维数…...

kubernetes--Pod控制器详解
目录 一、Pod控制器及其功用: 二、pod控制器的多种类型: 1、ReplicaSet: 1.1 ReplicaSet主要三个组件组成: 2、Deployment: 3、DaemonSet: 4、StatefulSet: 5、Job: 6、Cronjob: …...
)
保姆级教程:在Ubuntu 22.04上搞定水星MW310UH无线网卡驱动(含安全启动关闭指南)
水星MW310UH无线网卡在Ubuntu 22.04的完整驱动指南当你刚拿到水星MW310UH无线网卡,满心欢喜地插入Ubuntu 22.04系统,却发现系统毫无反应时,那种挫败感我深有体会。作为一款性价比极高的USB无线网卡,MW310UH在Windows下即插即用&am…...

JavaScript语言精粹第三章解读 | 吃透JS对象核心!告别90%日常开发对象Bug
前言 最近重读《JavaScript语言精粹》,复盘JS对象基础的时候,我真的发现了自己多年的编码陋习。 写了好几年前端,每天都在和对象打交道:接口回参解析、页面状态存储、配置项封装,全是{},看似简单到不值一…...

如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南
如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circ…...

2026 最新版网络安全全岗位详解,入行择业一看就懂
全网最全!网络安全全岗位解析(2026版) 摘要:随着数字化转型加速,网络安全已成为企业、政务、互联网大厂的核心刚需,人才缺口持续扩大,2026年国内网络安全人才缺口已突破327万,全球缺…...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...

JMeter中稳定获取与传递Token的三种实战方案
1. 为什么token获取总在JMeter脚本里“掉链子”做接口测试的同行应该都踩过这个坑:明明API文档写得清清楚楚,Postman里一调一个准,可一到JMeter里,登录接口返回了token,后续请求却始终401——Header里token字段空着、变…...

项目文档:基于Multisim的汽车尾灯顺序控制电路模块化设计与仿真
摘要:本设计并实现了一种基于模块化思想的汽车尾灯顺序控制电路。该系统采用分模块设计方法,将整体电路划分为左移模块、右移模块和闪烁模块三个独立功能单元,通过模块化组合实现汽车转向灯的流水显示效果。项目简介本项目旨在设计一套完整的…...

STM32中断优先级到底怎么分?用医生叫号系统讲透NVIC抢占与响应优先级
STM32中断优先级到底怎么分?用医生叫号系统讲透NVIC抢占与响应优先级 在嵌入式系统开发中,实时响应能力往往是衡量系统性能的关键指标。想象一下,当您正在全神贯注地编写代码时,突然手机来电、微信消息和邮件通知同时响起——您会…...

终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具
终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

VS Code 提交变 yarn 执行?解析 Git Hook 劫持真相
1. 这不是 Git 报错,是 VS Code 被“劫持”了提交流程你点下 CtrlEnter(或点击 VS Code 源代码管理面板的对勾图标)准备提交代码,结果弹出一个半透明终端窗口,第一行赫然写着:Git: yarn run v1.22.19紧接着…...