Spring Cloud学习(十)【Elasticsearch搜索功能 分布式搜索引擎02】
文章目录
- DSL查询文档
- DSL查询分类
- 全文检索查询
- 精准查询
- 地理坐标查询
- 组合查询
- 相关性算分
- Function Score Query
- 复合查询 Boolean Query
- 搜索结果处理
- 排序
- 分页
- 高亮
- RestClient查询文档
- 快速入门
- match查询
- 精确查询
- 复合查询
- 排序、分页、高亮
- 黑马旅游案例
DSL查询文档
DSL查询分类
DSL Query的分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range
- term
- 地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询的基本语法如下:

查询DSL的基本语法是什么?
- GET /索引库名/_search
- { “query”: { “查询类型”: { “FIELD”: “TEXT”}}}
全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索:
match 查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:

multi_match:与 match 查询类似,只不过允许同时查询多个字段,语法:

match 和 multi_match 的区别是什么?
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
精确查询常见的有 term 查询和 range 查询。语法如下:

精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
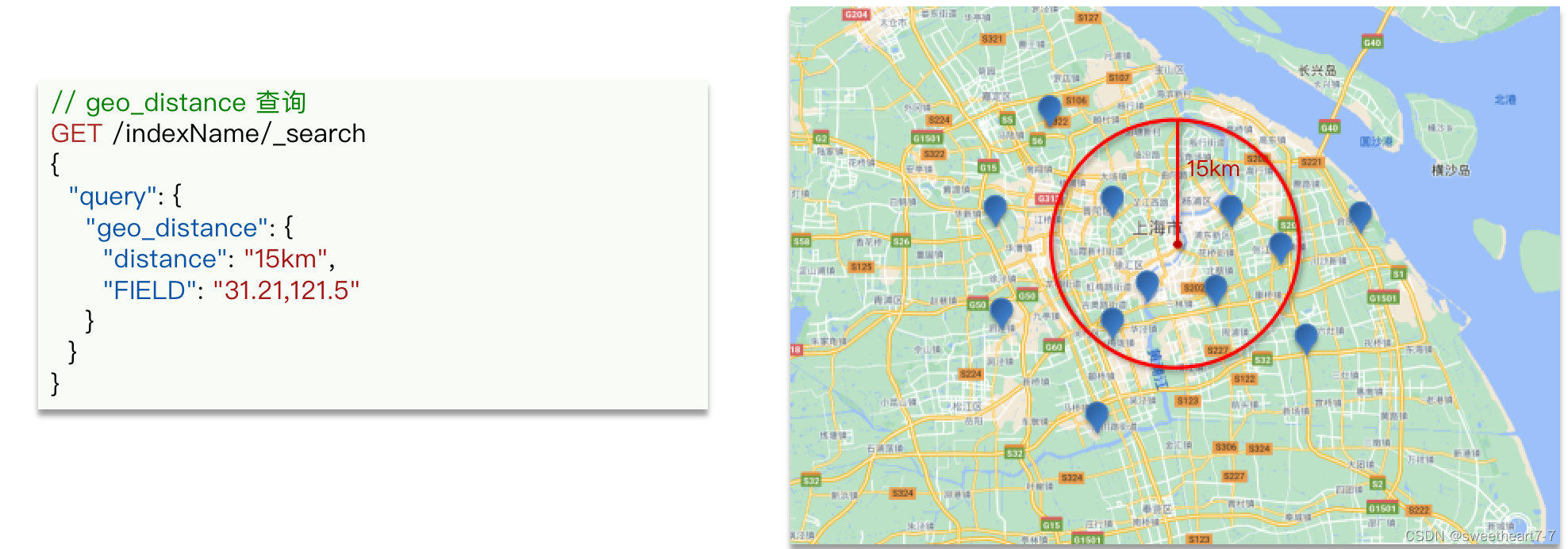
地理坐标查询
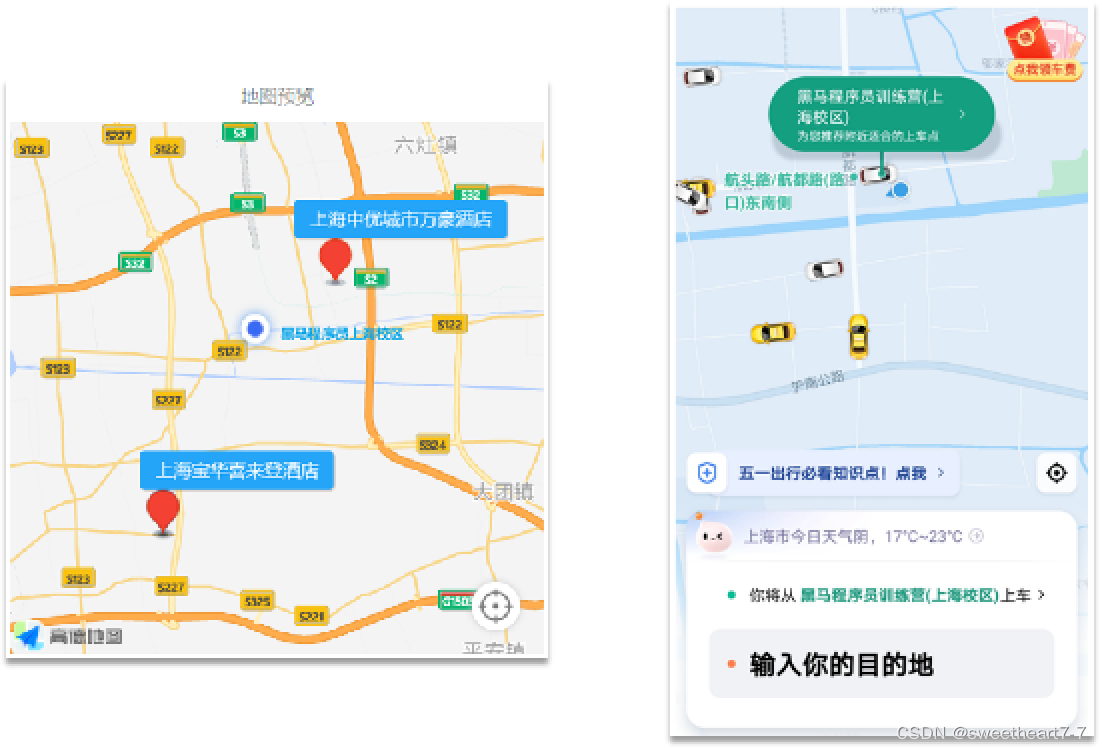
根据经纬度查询。常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
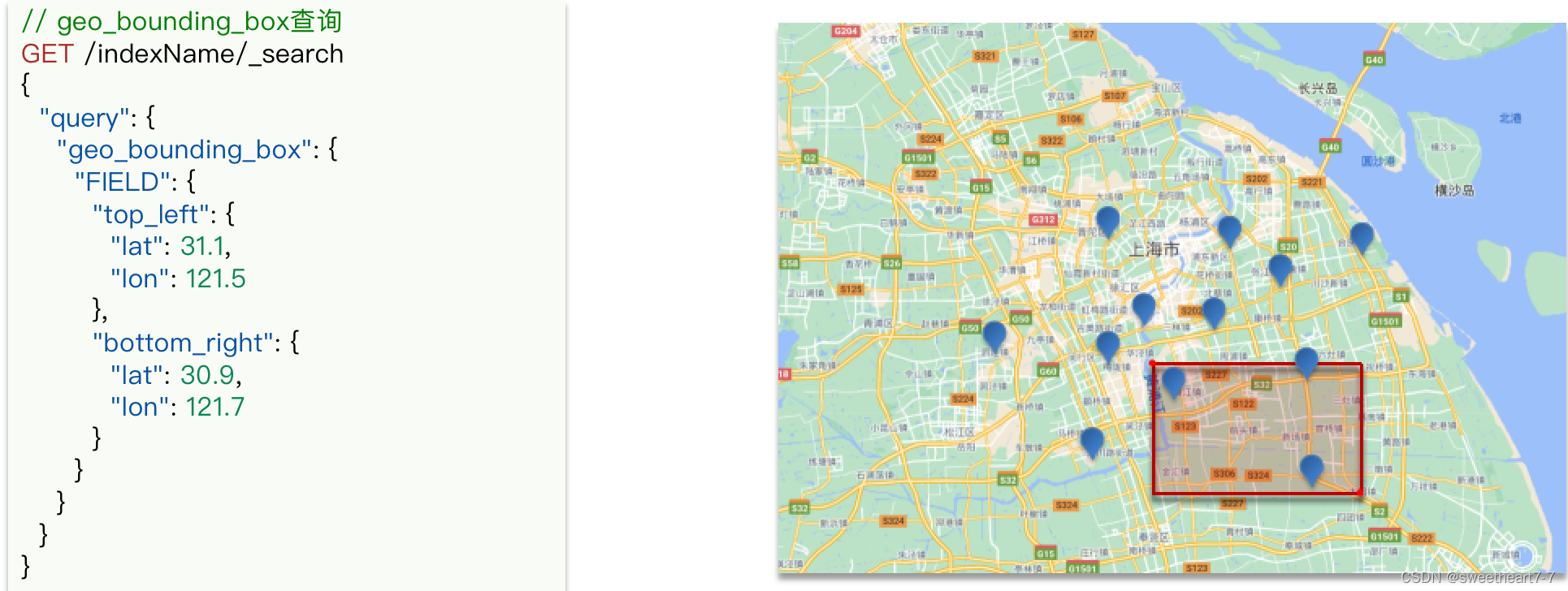
根据经纬度查询,官方文档。例如:
- geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档
根据经纬度查询,官方文档。例如:
- geo_distance:查询到指定中心点小于某个距离值的所有文档
组合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
相关性算分
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
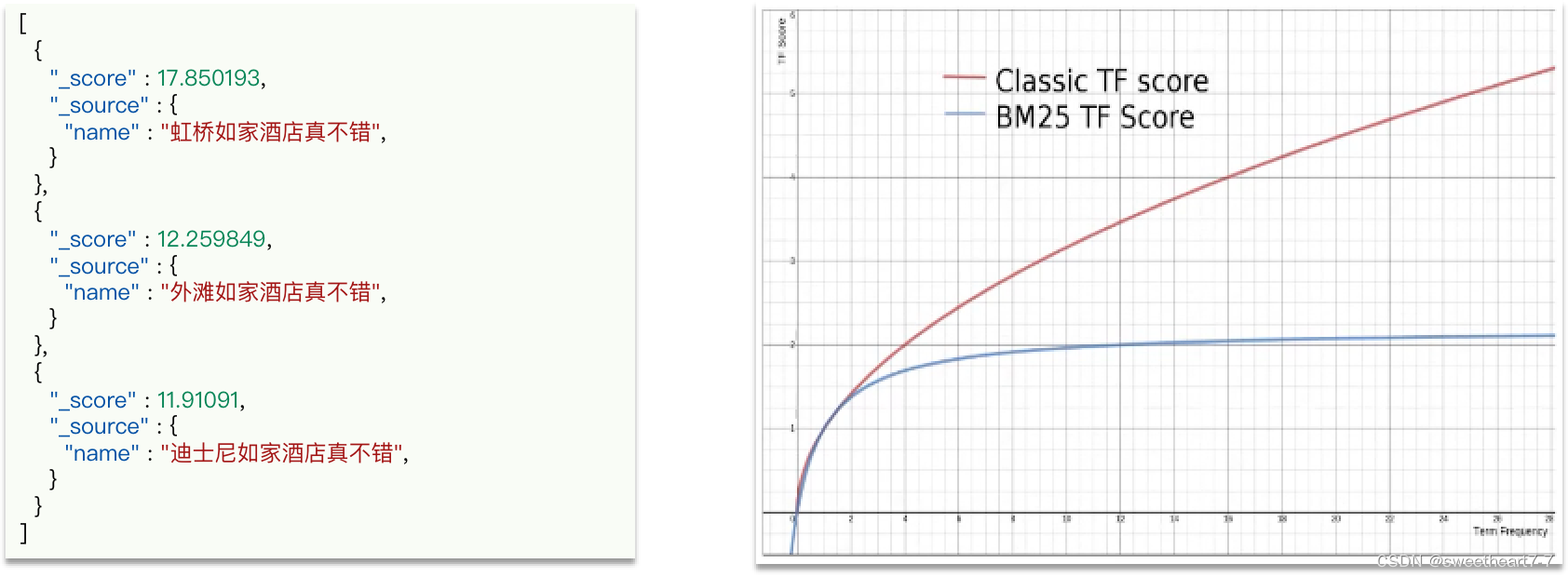

elasticsearch中的相关性打分算法是什么?
- TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
- BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平
Function Score Query
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。
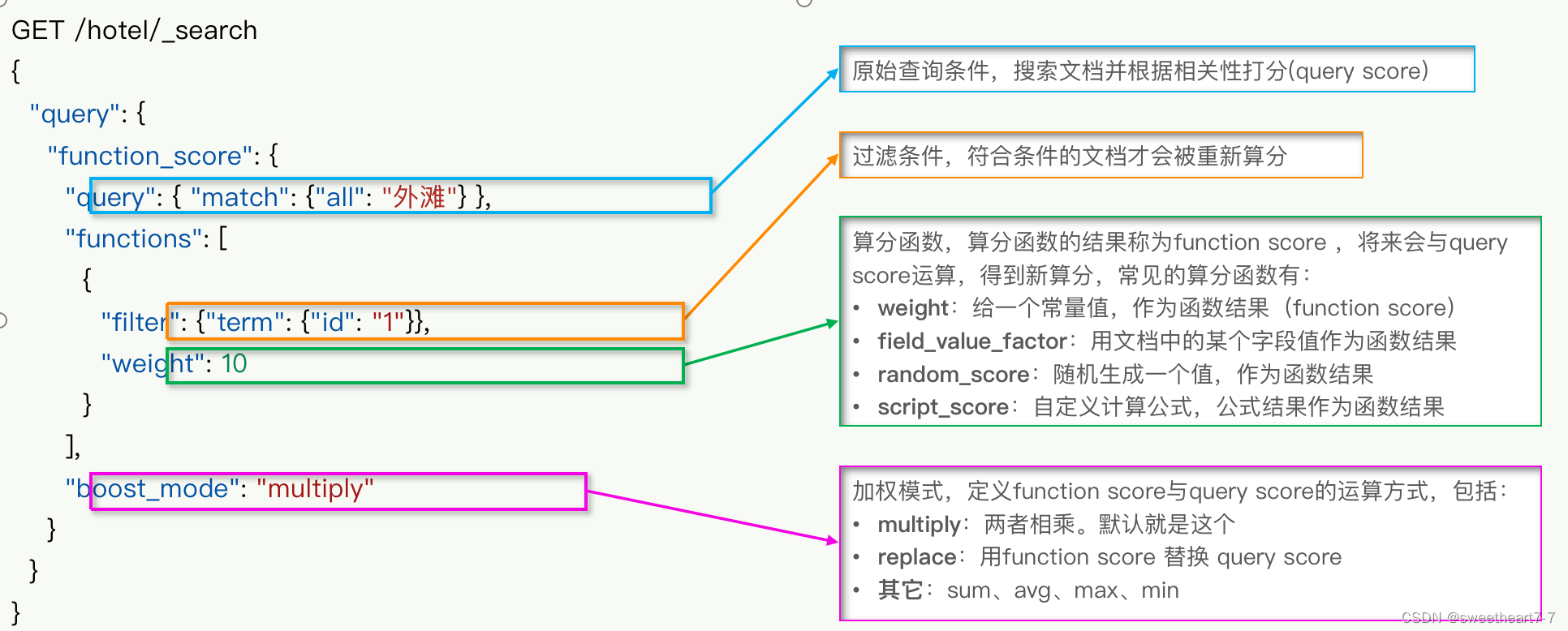
案例: 给“如家”这个品牌的酒店排名靠前一些
把这个问题翻译一下,function score需要的三要素:
- 哪些文档需要算分加权?
- 品牌为如家的酒店
- 算分函数是什么?
- weight就可以
- 加权模式是什么?
- 求和

function score query定义的三要素是什么?
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
复合查询 Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
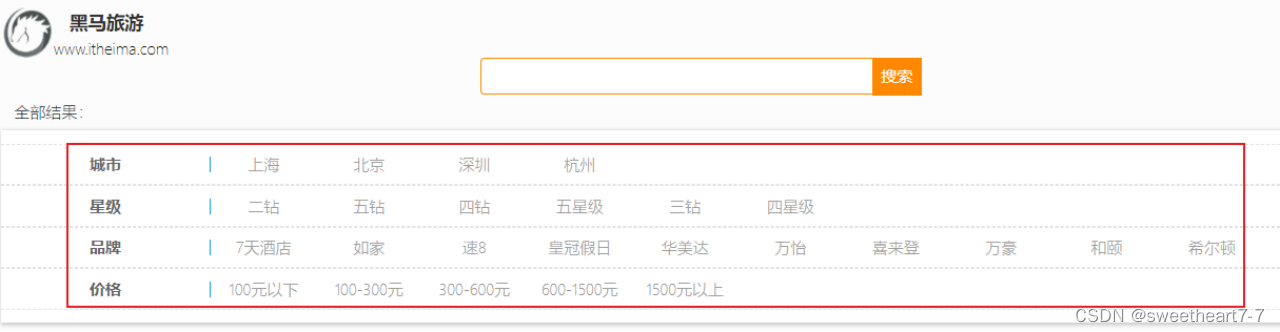

利用bool查询实现功能
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围 10km 范围内的酒店。

bool查询有几种逻辑关系?
- must:必须匹配的条件,可以理解为“与”
- should:选择性匹配的条件,可以理解为“或”
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
搜索结果处理
排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。

分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:

深度分页问题
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from = 990,size =10的数据:
- 首先在每个数据分片上都排序并查询前1000条文档。
- 然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档
- 最后从这1000条中,选取从990开始的10条文档
如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上限是10000
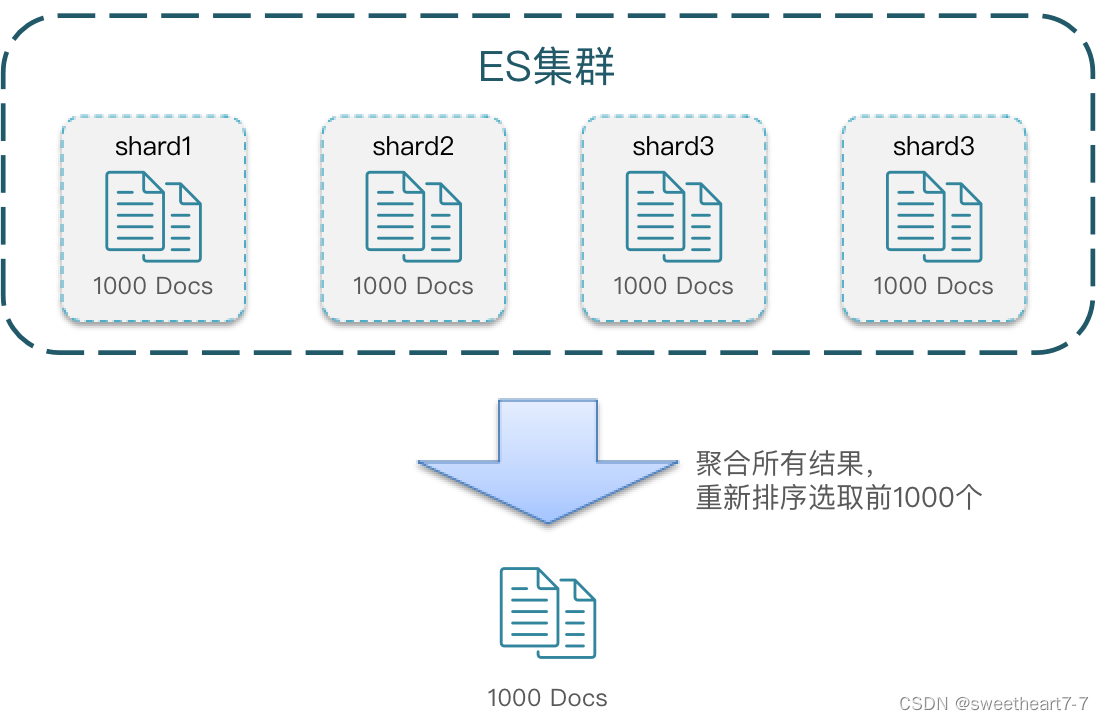
针对深度分页,ES提供了两种解决方案,官方文档:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
from + size:
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
after search:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
scroll:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
高亮
高亮:就是在搜索结果中把搜索关键字突出显示。
原理是这样的:
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式
语法:

搜索结果处理整体语法:
GET /hotel/_search
{"query": {"match": {"name": "如家"}},"from": 0, // 分页开始的位置"size": 20, // 期望获取的文档总数"sort": [ { "price": "asc" }, // 普通排序{"_geo_distance" : { // 距离排序"location" : "31.040699,121.618075", "order" : "asc","unit" : "km"}}],"highlight": {"fields": { // 高亮字段"name": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
RestClient查询文档
快速入门
我们通过 match_all 来演示下基本的 API ,先看请求 DSL 的组织:
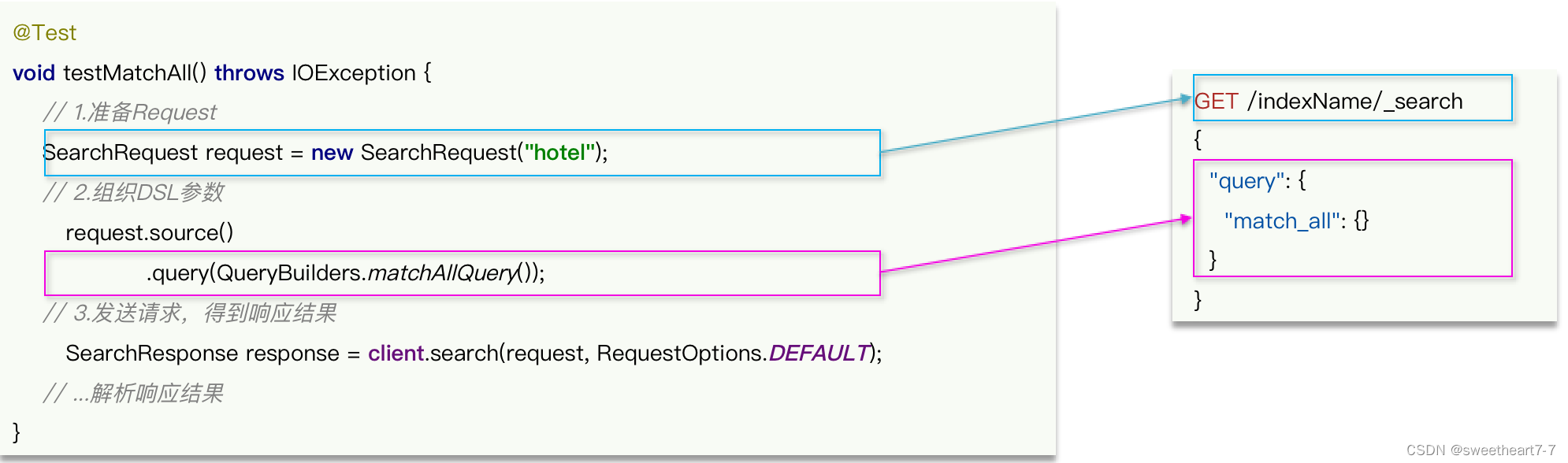
我们通过 match_all 来演示下基本的 API,再看结果的解析:
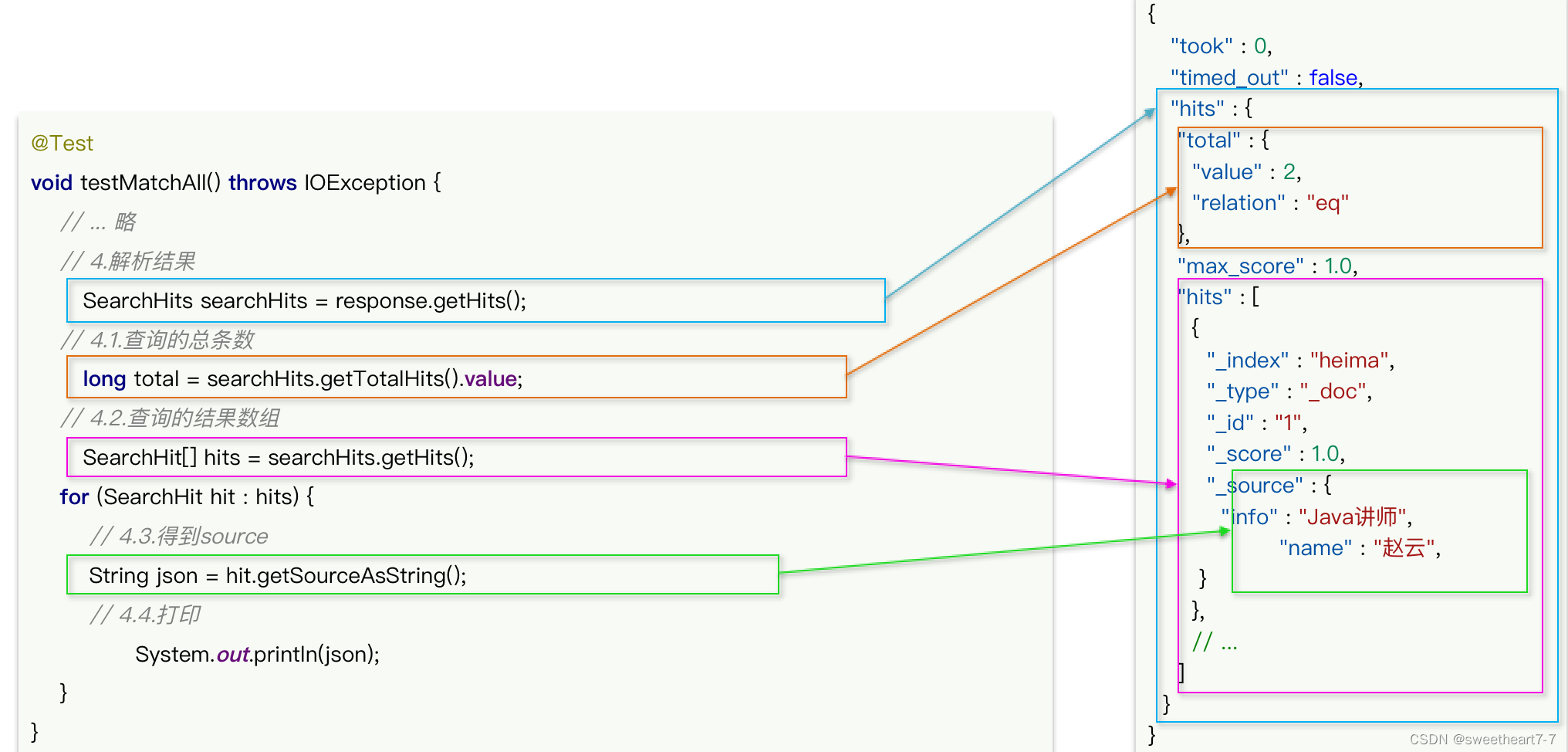
@Test
void testMatchAll() throws IOException {// 1. 准备RequestSearchRequest request = new SearchRequest("hotel");// 2. 准备DSLrequest.source().query(QueryBuilders.matchAllQuery());// 3. 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析响应SearchHits searchHits = response.getHits();// 4.1 获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2 文档数组SearchHit[] hits = searchHits.getHits();// 4.3 遍历for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc = " + hotelDoc);}System.out.println(response);
}
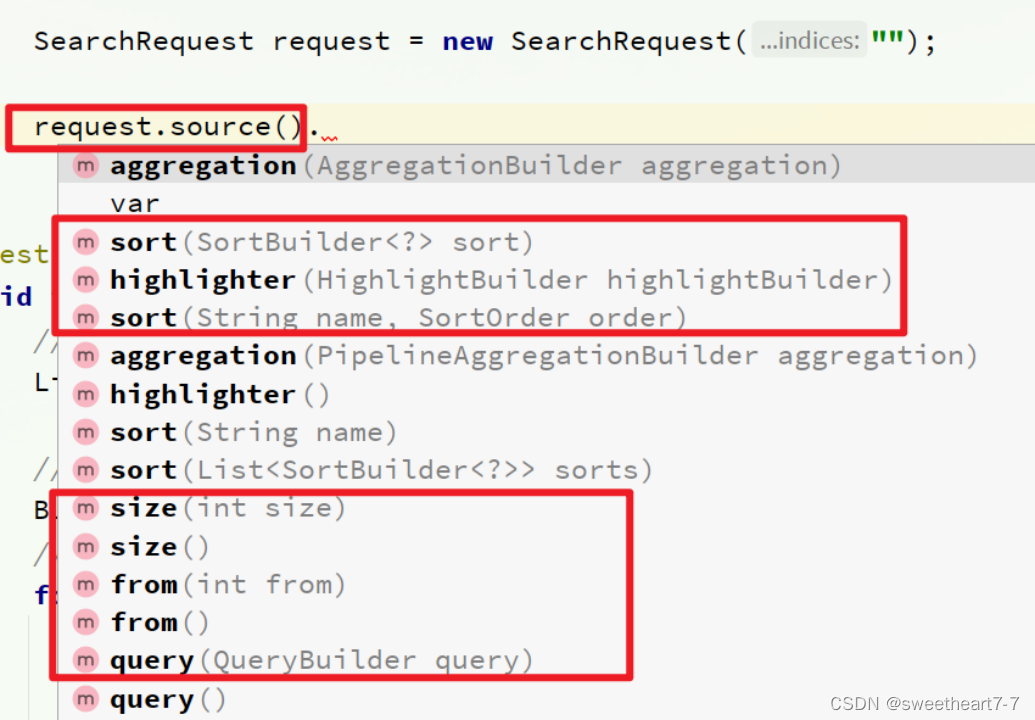
RestAPI 中其中构建 DSL 是通过 HighLevelRestClient 中的 resource() 来实现的,其中包含了查询、排序、分页、高亮等所有功能:
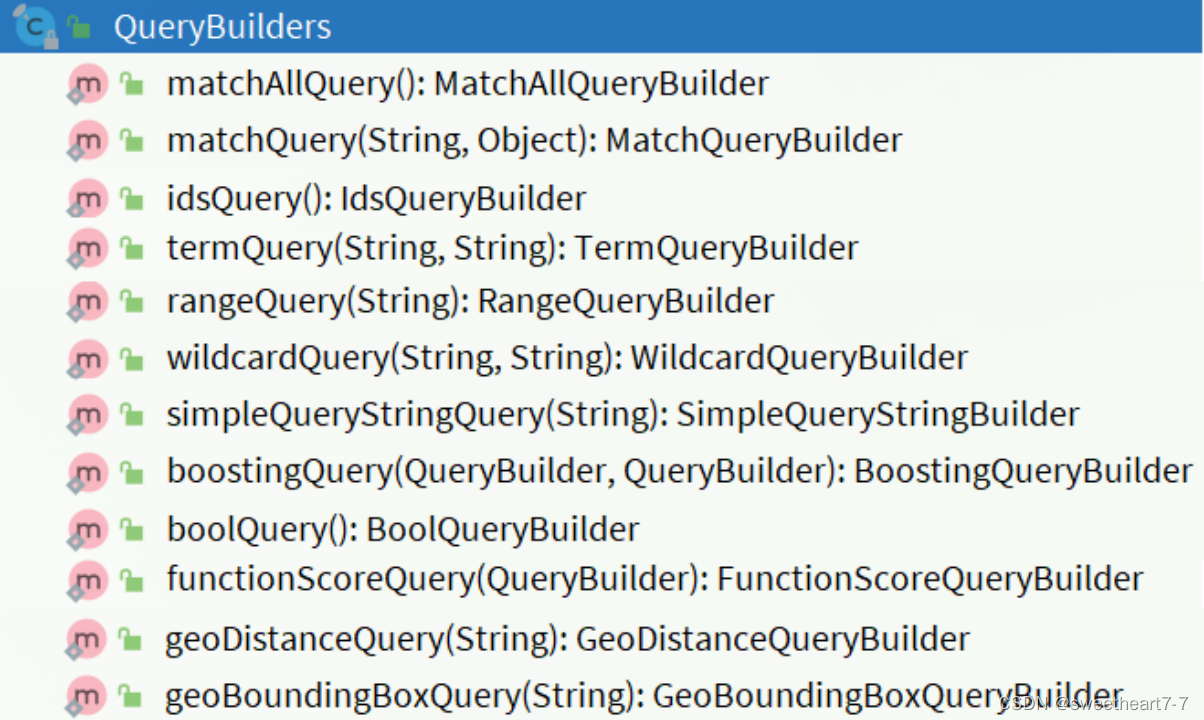
RestAPI 中其中构建查询条件的核心部分是由一个名为 QueryBuilders 的工具类提供的,其中包含了各种查询方法:
查询的基本步骤是:
- 创建SearchRequest对象
- 准备Request.source(),也就是DSL。
QueryBuilders来构建查询条件
传入Request.source() 的 query() 方法 - 发送请求,得到结果
- 解析结果(参考 JSON 结果,从外到内,逐层解析)
match查询
全文检索查询
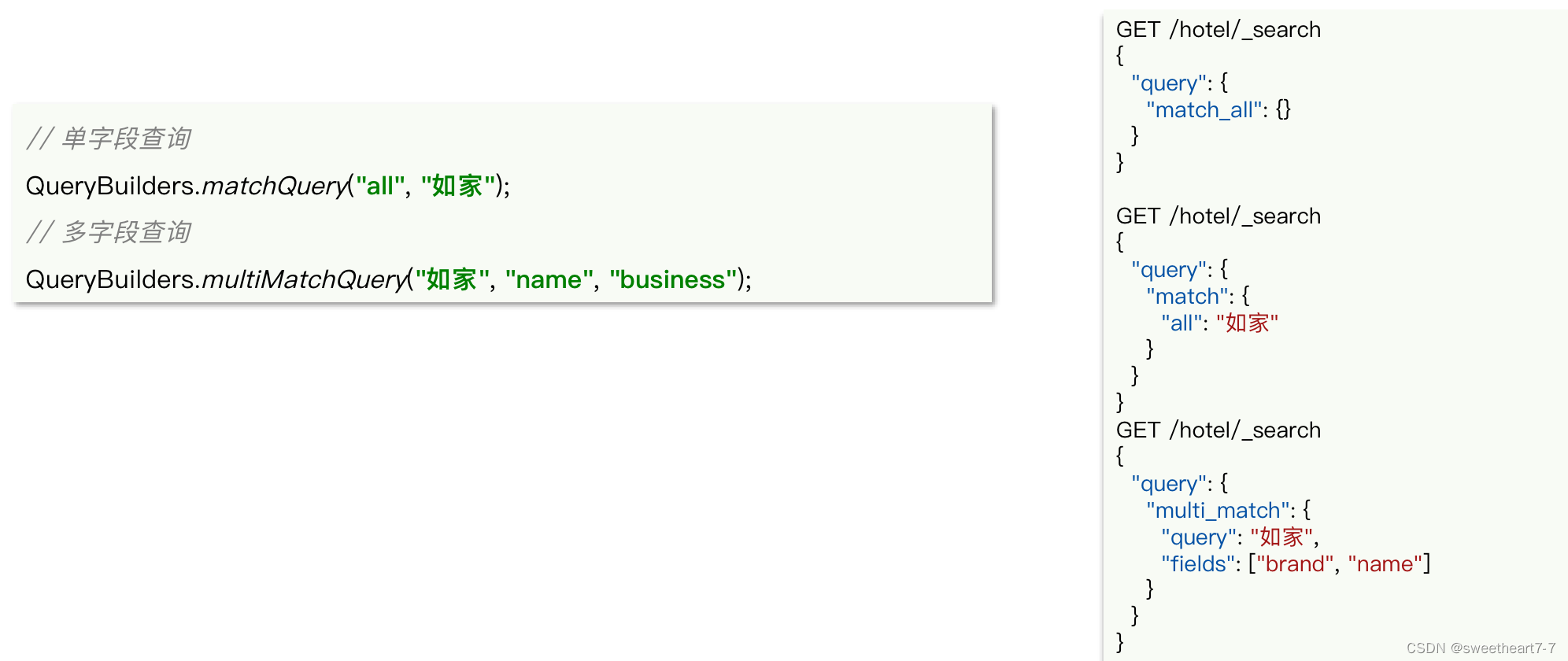
全文检索的 match 和 multi_match 查询与 match_all 的API基本一致。差别是查询条件,也就是 query 的部分。
同样是利用 QueryBuilders 提供的方法:
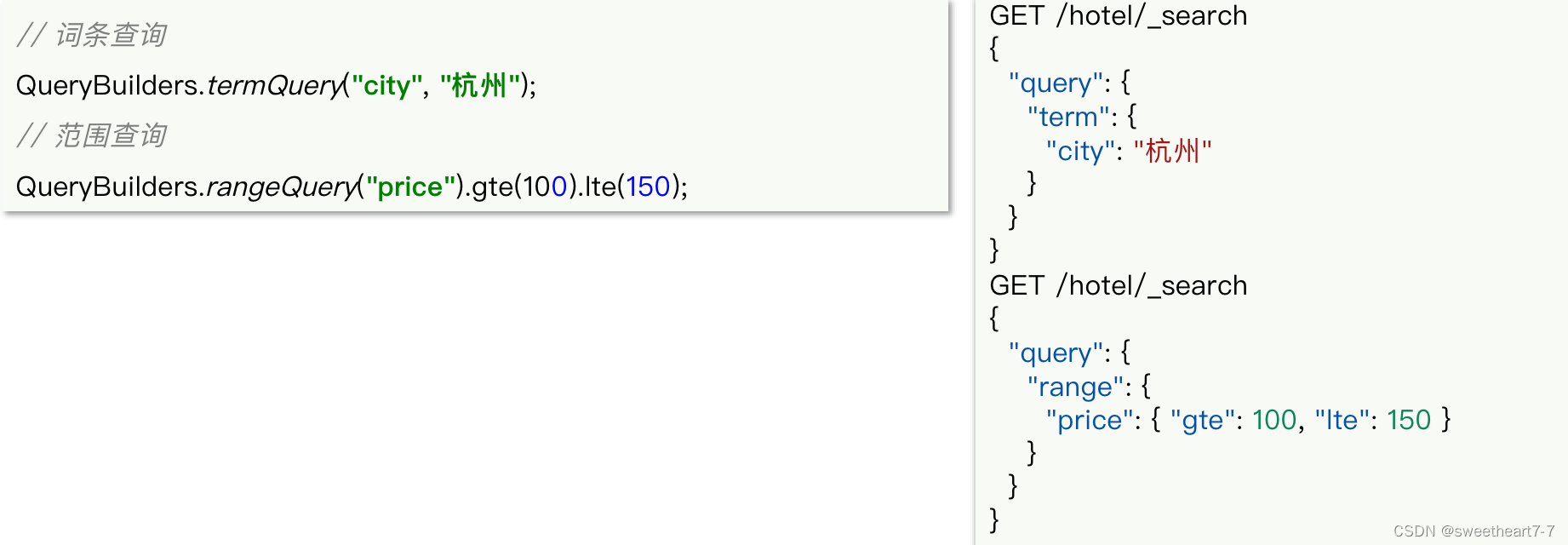
精确查询
精确查询常见的有term查询和range查询,同样利用QueryBuilders实现:
复合查询
复合查询-boolean query
精确查询常见的有 term 查询和 range 查询,同样利用 QueryBuilders 实现:
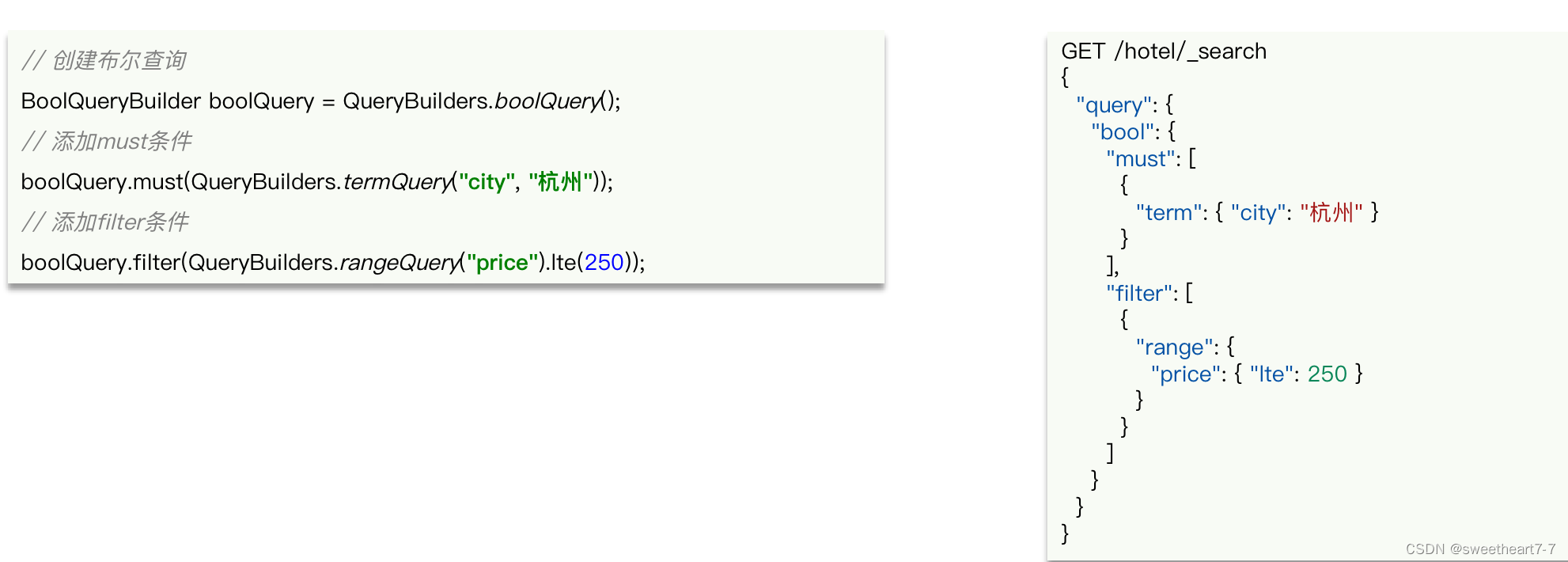
要构建查询条件,只要记住一个类:QueryBuilders
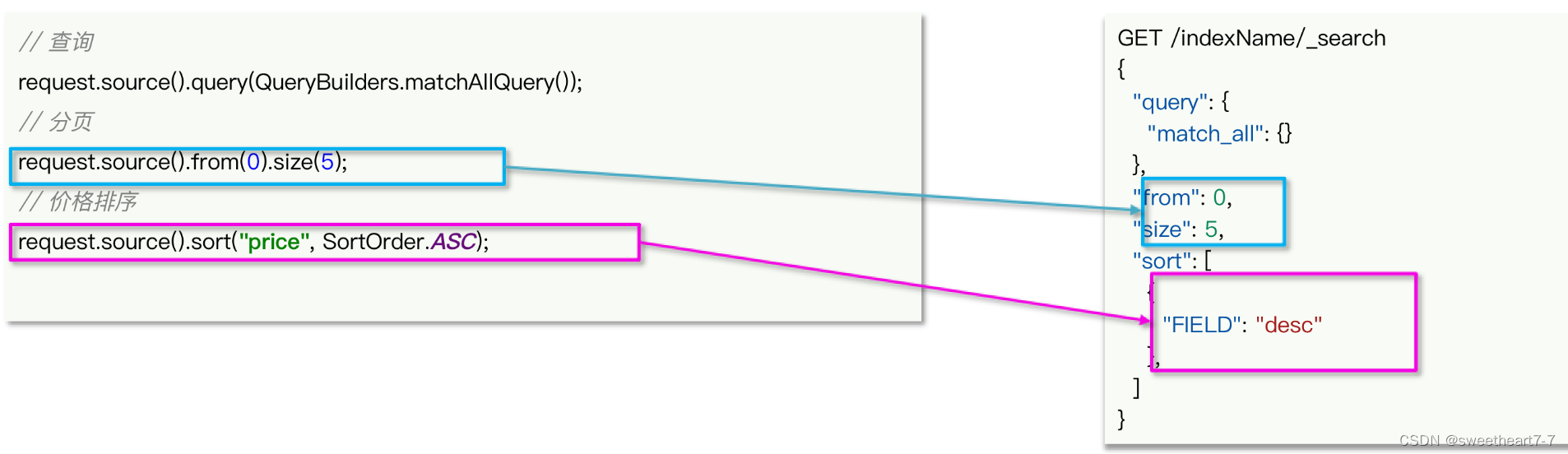
排序、分页、高亮
排序、分页
搜索结果的排序和分页是与query同级的参数,对应的API如下:
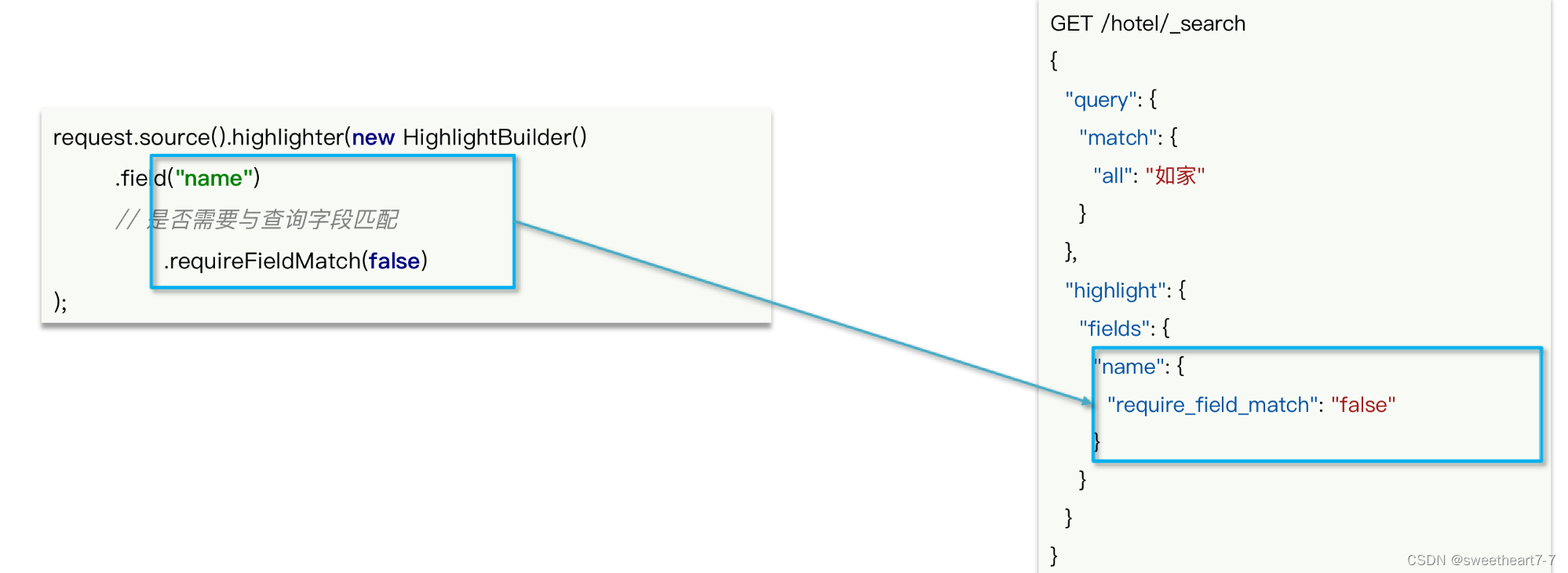
高亮
高亮API包括请求DSL构建和结果解析两部分。我们先看请求的DSL构建:
高亮的结果处理相对比较麻烦:
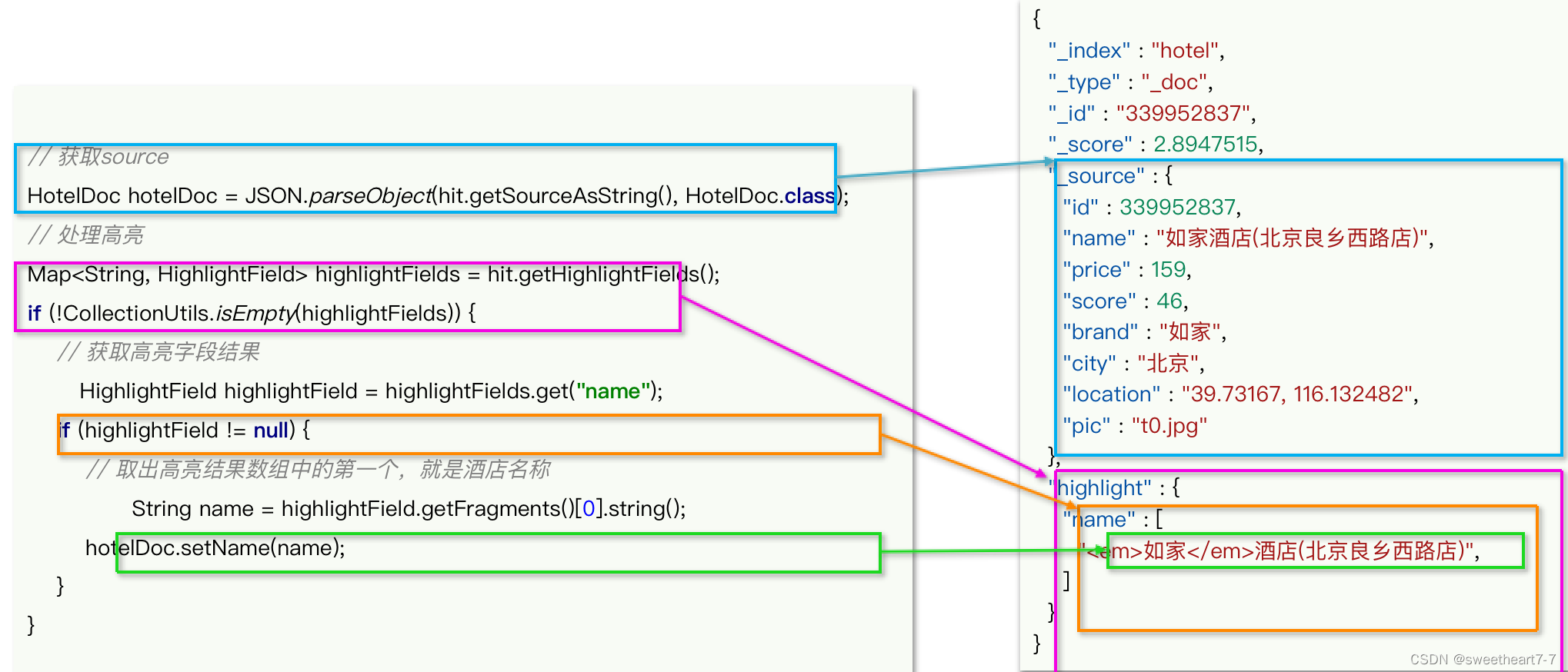
- 所有搜索DSL的构建,记住一个API:SearchRequest的source()方法。
- 高亮结果解析是参考JSON结果,逐层解析
// 4. 解析响应
SearchHits searchHits = response.getHits();
// 4.1 获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2 文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3 遍历
for (SearchHit hit : hits) {// 获取文档 sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 获取高亮结果Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(!CollectionUtils.isEmpty(highlightFields)){// 根据字段名称获取高亮结果HighlightField highlightField = highlightFields.get("name");if(highlightField != null){// 获取高亮值String name = highlightField.getFragments()[0].string();// 覆盖非高亮结果hotelDoc.setName(name);}}System.out.println("hotelDoc = " + hotelDoc);
}
黑马旅游案例
案例1:实现黑马旅游的酒店搜索功能,完成关键字搜索和分页
我们课前提供的hotel-demo项目中,自带了前端页面,启动后可以看到:
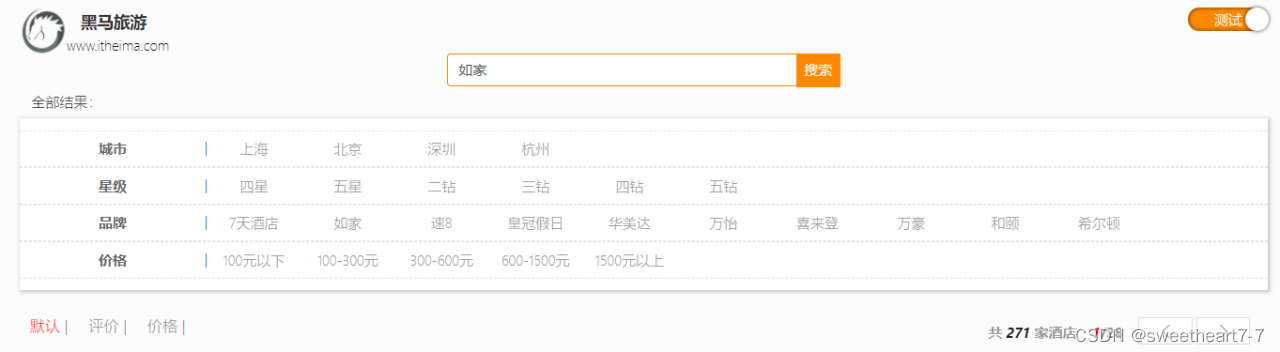
先实现其中的关键字搜索功能,实现步骤如下:
- 定义实体类,接收前端请求
- 定义controller接口,接收页面请求,调用IHotelService的search方法
- 定义IHotelService中的search方法,利用match查询实现根据关键字搜索酒店信息
步骤1:定义类,接收前端请求参数

步骤2:定义controller接口,接收前端请求
定义一个HotelController,声明查询接口,满足下列要求:
- 请求方式:Post
- 请求路径:/hotel/list
- 请求参数:对象,类型为RequestParam
- 返回值:PageResult,包含两个属性
Long total:总条数
List hotels:酒店数据
步骤3:在IHotelService中定义一个方法,实现搜索功能
- 在IHotelService中定义一个方法,声明如下:

- 在HotelService中实现该方法,满足下列要求:
利用match查询,根据参数中的key搜索all字段,查询酒店信息并返回
利用参数中的page、size实现分页
案例2:添加品牌、城市、星级、价格等过滤功能
需求效果如图:
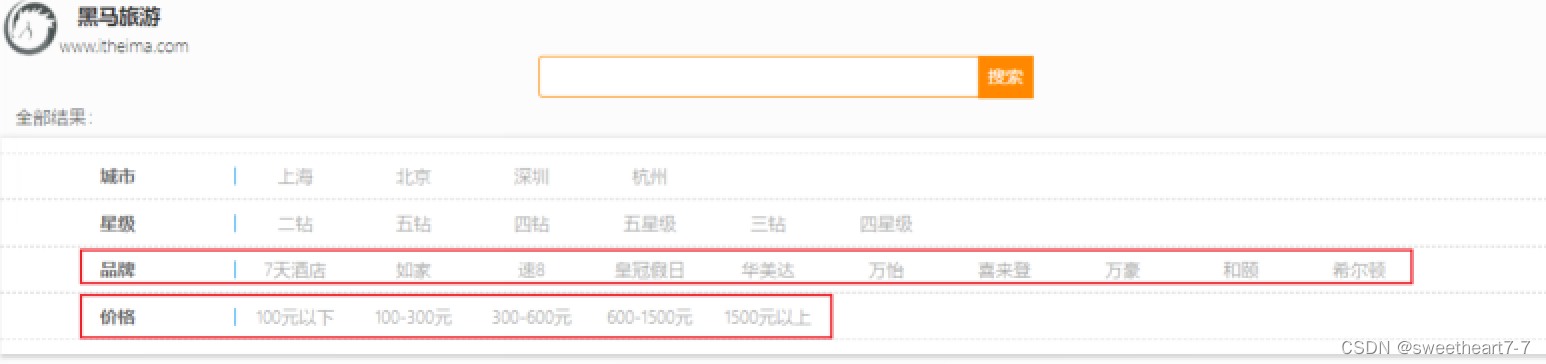
步骤:
- 修改RequestParams类,添加brand、city、starName、minPrice、maxPrice等参数
- 修改search方法的实现,在关键字搜索时,如果brand等参数存在,对其做过滤
步骤一:拓展IUserService的search方法的参数列表
修改RequestParams类,接收所有参数:

步骤二:修改search方法,在match查询基础上添加过滤条件
过滤条件包括:
- city精确匹配
- brand精确匹配
- starName精确匹配
- price范围过滤
注意事项:
- 多个条件之间是AND关系,组合多条件用BooleanQuery
- 参数存在才需要过滤,做好非空判断
案例3:我附近的酒店
前端页面点击定位后,会将你所在的位置发送到后台:
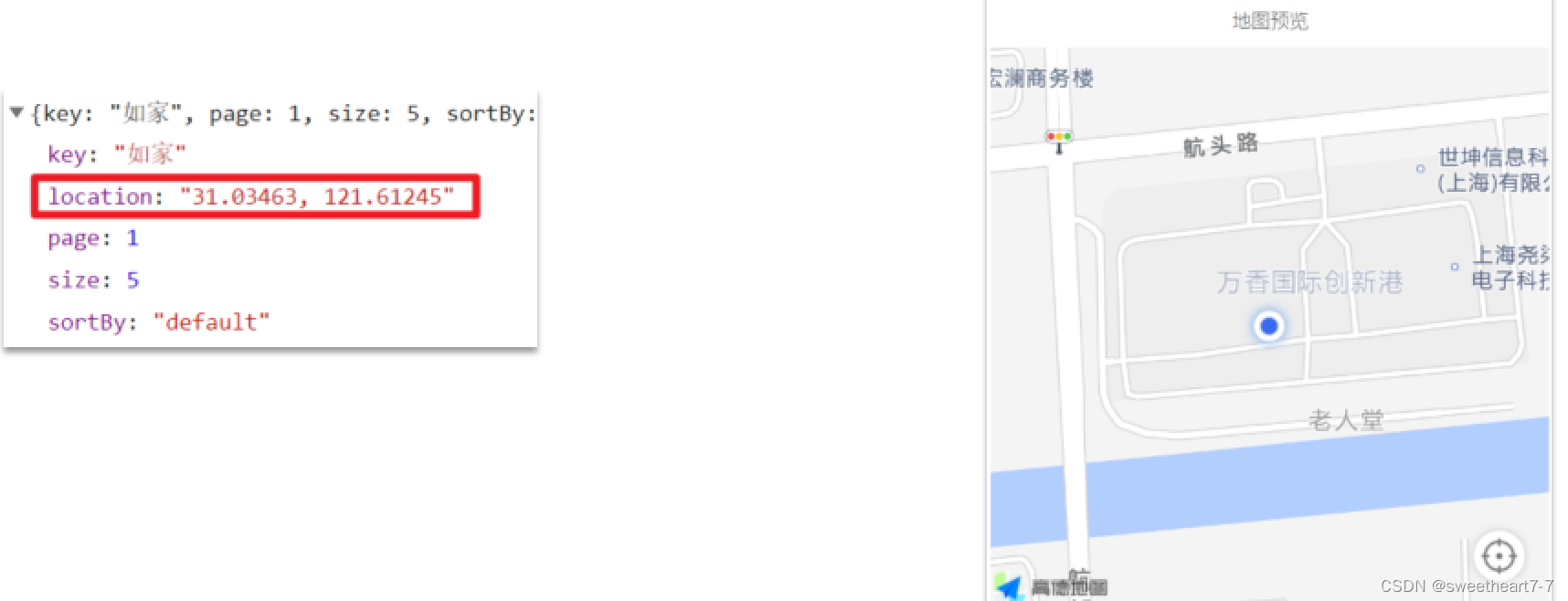
我们要根据这个坐标,将酒店结果按照到这个点的距离升序排序。
实现思路如下:
- 修改RequestParams参数,接收location字段
- 修改search方法业务逻辑,如果location有值,添加根据geo_distance排序的功能
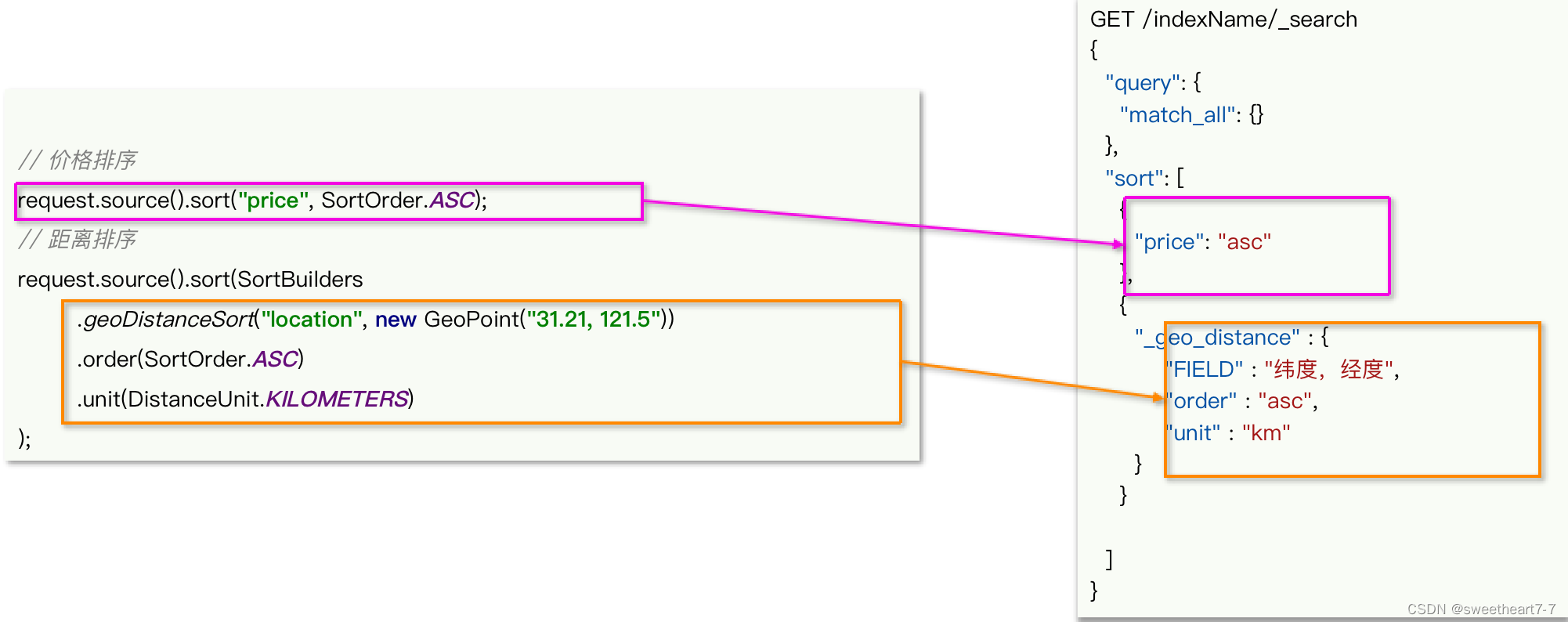
距离排序
距离排序与普通字段排序有所差异,API如下:
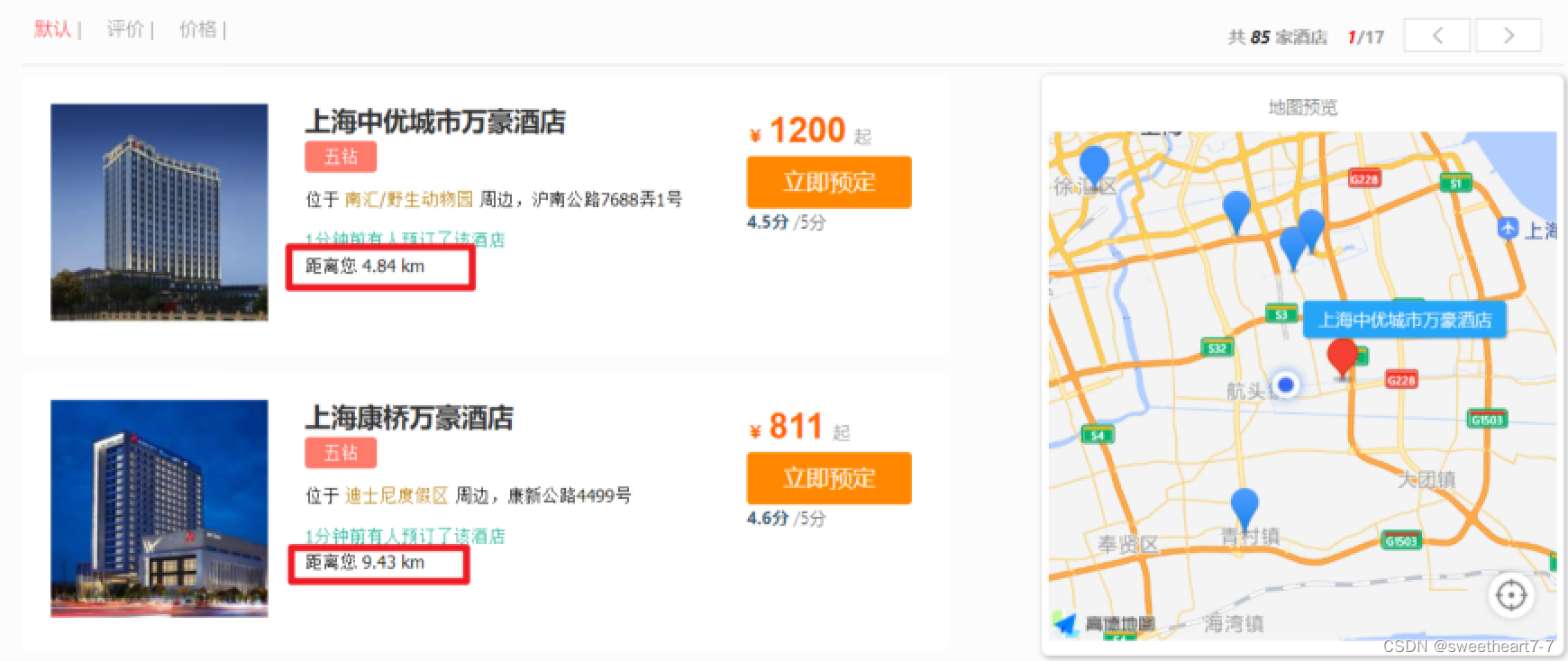
按照距离排序后,还需要显示具体的距离值:
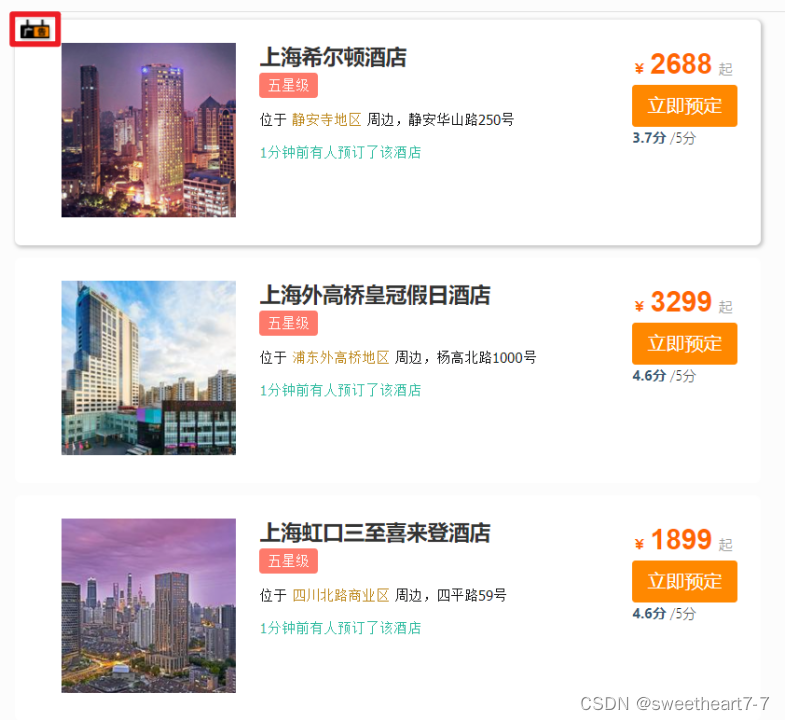
案例4:让指定的酒店在搜索结果中排名置顶
我们给需要置顶的酒店文档添加一个标记。然后利用function score给带有标记的文档增加权重。
实现步骤分析:
- 给HotelDoc类添加isAD字段,Boolean类型
- 挑选几个你喜欢的酒店,给它的文档数据添加isAD字段,值为true
- 修改search方法,添加function score功能,给isAD值为true的酒店增加权重
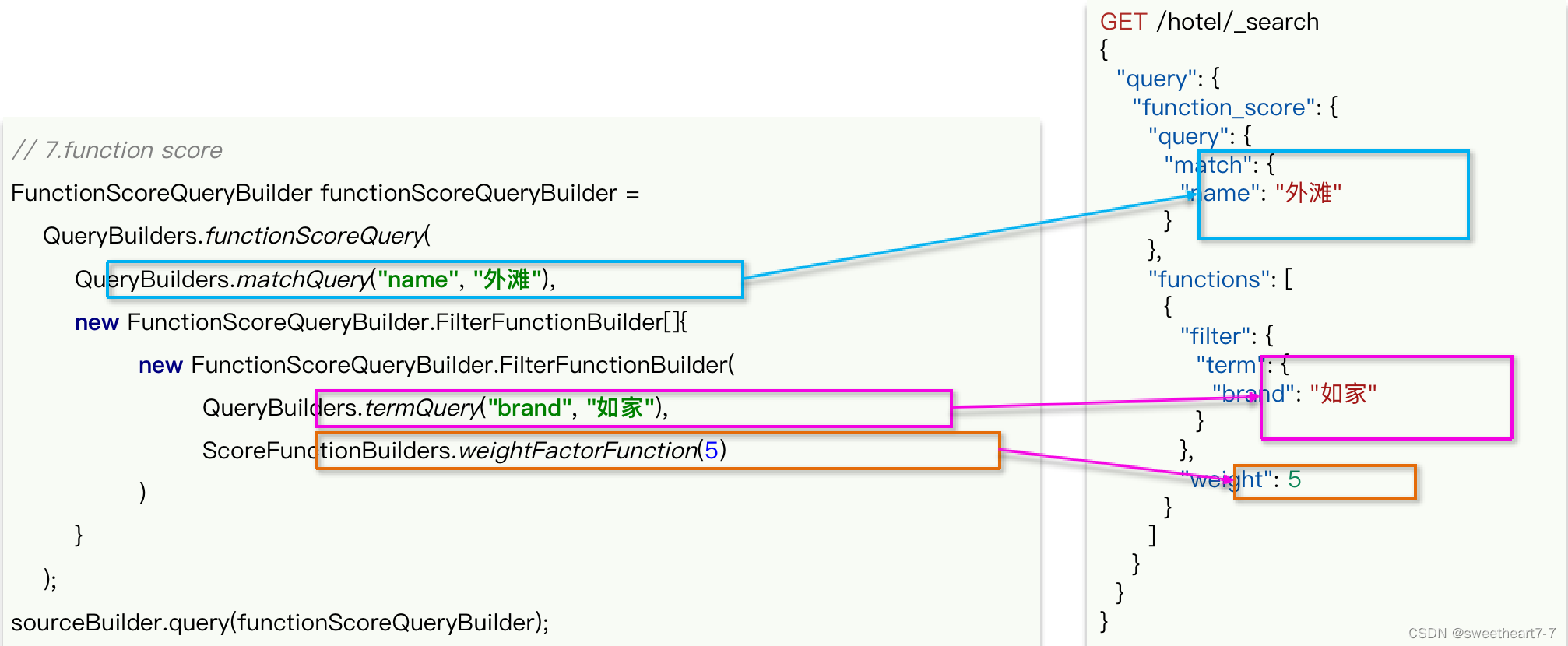
组合查询-function score
Function Score查询可以控制文档的相关性算分,使用方式如下:
给黑马旅游添加排序功能
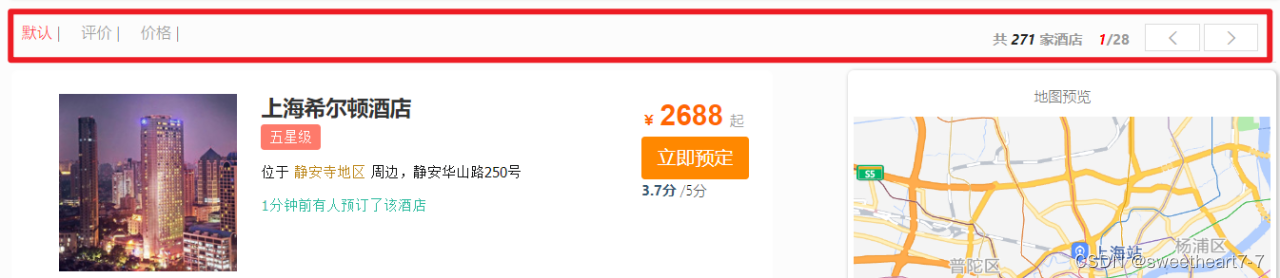
前端会传递sortBy参数,就是排序方式,我们需要判断sortBy值是什么:
- default:相关度算分排序,这个不用管,es的默认排序策略
- score:根据酒店的score字段排序,也就是用户评价,降序
- price:根据酒店的price字段排序,就是价格,升序
给黑马旅游添加搜索关键字高亮效果
前端已经给<em>标签写好CSS样式了。我们只需要负责服务端高亮即可。
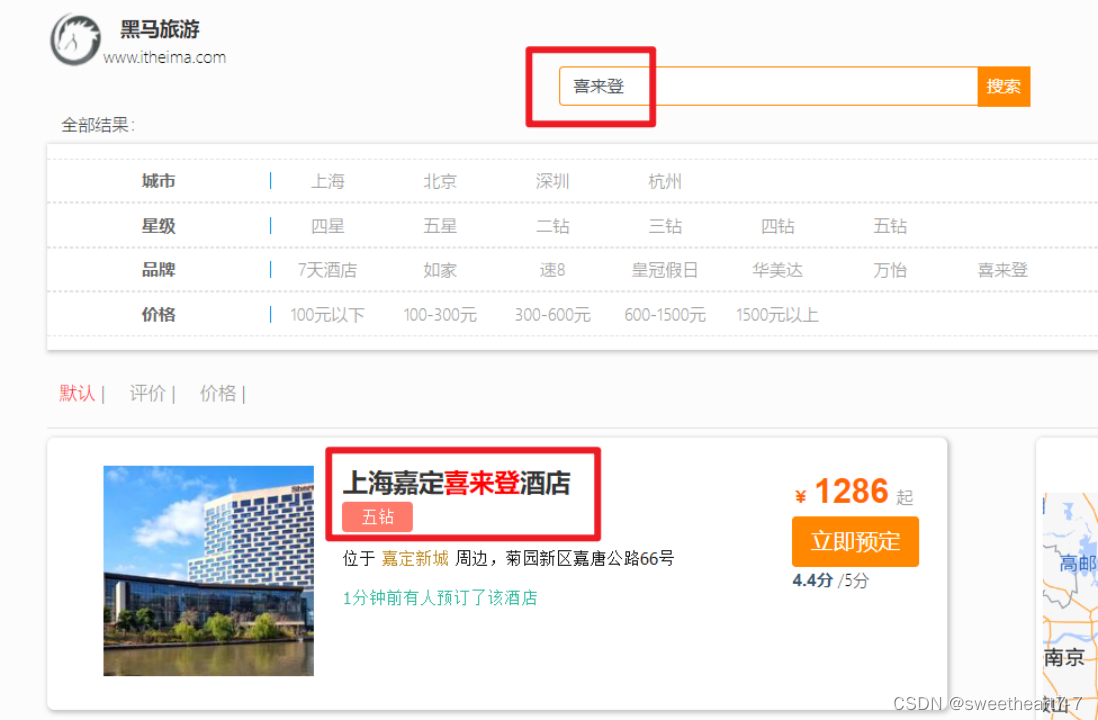
RequestParams
@Data
public class RequestParams {private String key;private Integer page;private Integer size;private String sortBy;private String city;private String brand;private String starName;private Integer minPrice;private Integer maxPrice;private String location;
}
PageResult.java
@Data
public class PageResult {private Long total;private List<HotelDoc> hotels;public PageResult(Long total, List<HotelDoc> hotels) {this.total = total;this.hotels = hotels;}public PageResult() {}
}
HotelService.java
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowiredprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {// 1. 准备 RequestSearchRequest request = new SearchRequest("hotel");// 2. 准备 DSL// 2.1 querybuildBasicQuery(params, request);// 2.2 分页int page = params.getPage();int size = params.getSize();request.source().from((page - 1) * size).size(size);// 2.3 排序String location = params.getLocation();if (location != null && !"".equals(location)){request.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint(location)).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));}// 3. 发送请求,得到响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析响应return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}private void buildBasicQuery(RequestParams params, SearchRequest request) {// 1. 构建BooleanQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 关键字搜索String key = params.getKey();if(key == null || "".equals(key)){boolQuery.must(QueryBuilders.matchAllQuery());}else{boolQuery.must(QueryBuilders.matchQuery("all", key));}// 条件过滤// 城市条件if (params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));}// 品牌条件if (params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));}// 星级条件if (params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName", params.getBrand()));}// 价格if (params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}// 2. 算分控制FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(// 原始查询,相关性算分查询boolQuery,// function score 的数组new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{// 其中的一个 function score 元素new FunctionScoreQueryBuilder.FilterFunctionBuilder(// 过滤条件QueryBuilders.termQuery("isAD", true),// 算分函数ScoreFunctionBuilders.weightFactorFunction(10))});request.source().query(functionScoreQuery);}private PageResult handleResponse(SearchResponse response){// 4. 解析响应SearchHits searchHits = response.getHits();// 4.1 获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2 文档数组SearchHit[] hits = searchHits.getHits();// 4.3 遍历ArrayList<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {// 获取文档 sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 获取排序值Object[] sortValues = hit.getSortValues();if (sortValues.length > 0){Object sortValue = sortValues[0];hotelDoc.setDistance(sortValue);}hotels.add(hotelDoc);}// 封装返回return new PageResult(total, hotels);}
}
相关文章:
Spring Cloud学习(十)【Elasticsearch搜索功能 分布式搜索引擎02】
文章目录 DSL查询文档DSL查询分类全文检索查询精准查询地理坐标查询组合查询相关性算分Function Score Query复合查询 Boolean Query 搜索结果处理排序分页高亮 RestClient查询文档快速入门match查询精确查询复合查询排序、分页、高亮 黑马旅游案例 DSL查询文档 DSL查询分类 …...
大数据HCIE成神之路之数学(3)——概率论
概率论 1.1 概率论内容介绍1.1.1 概率论介绍1.1.2 实验介绍 1.2 概率论内容实现1.2.1 均值实现1.2.2 方差实现1.2.3 标准差实现1.2.4 协方差实现1.2.5 相关系数1.2.6 二项分布实现1.2.7 泊松分布实现1.2.8 正态分布1.2.9 指数分布1.2.10 中心极限定理的验证 1.1 概率论内容介绍…...
【论文解读】FFHQ-UV:用于3D面部重建的归一化面部UV纹理数据集
【论文解读】FFHQ-UV 论文地址:https://arxiv.org/pdf/2211.13874.pdf 0. 摘要 我们提出了一个大规模的面部UV纹理数据集,其中包含超过50,000张高质量的纹理UV贴图,这些贴图具有均匀的照明、中性的表情和清洁的面部区域,这些都是…...
)
simple foc 移植odriver foc的 anti-cogging(抗齿槽算法)
文章目录 ESP32 simple foc 移植odriver anti-cogging.1.硬件,在淘宝买的。esp32 simple foc(最新). 下电阻三采样。2. 效果,见视频https://www.bilibili.com/video/BV1xg4y1X7Yr/?vd_source4fd70d693021f289fb2d339c6c0407193.代码添加(生成…...
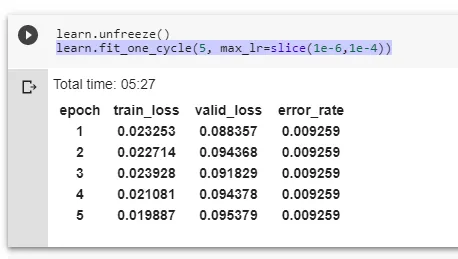
基于深度学习的恶意软件检测
恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。 恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网…...
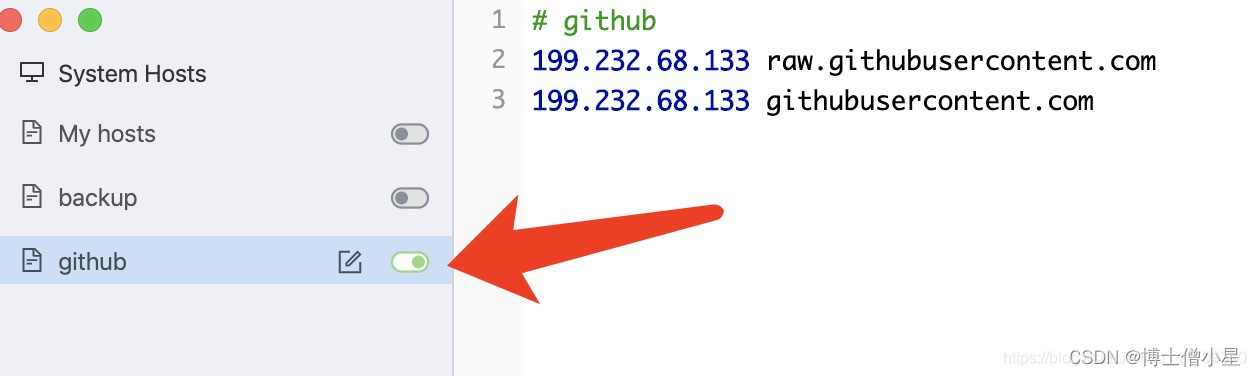
环境配置|GitHub——解决Github无法显示图片以及README无法显示图片
一、问题背景 最近在整理之前写过的实验、项目,打算把这些东西写成blog,并把工程文件整理上传到Github上。但在上传README文件的时候,发现github无法显示README中的图片,如下图所示: 在README中该图片路径为࿱…...
试用 12 -- 年终再总结)
AIGC(生成式AI)试用 12 -- 年终再总结
上次使用年终总结为题测试了CSDN创作助手和文心一言的表现,随着不断对总结给出更细节的提示。AIGC(生成式AI)试用 11 -- 年终总结-CSDN博客 总结年终总结生活/工作年终总结IT开发/运维年终总结 AIGC都能就新给出的主题修饰给出相应的关点&am…...

Linux下 tar 命令详解
一、tar 命令概述 Tar(Tape ARchive,磁带归档的缩写,LCTT 译注:最初设计用于将文件打包到磁带上,现在我们大都使用它来实现备份某个分区或者某些重要的目录)。 tar 是类 Unix 系统中广泛使用的命令&#x…...

SQL单表复杂查询where、group by、order by、limit
1.1SQL查询代码如下: select job as 工作类别,count(job) as 人数 from tb_emp where entrydate <2015-01-01 group by job having count(job) > 2 order by count(job) limit 1,1where entrydate <‘2015-01-01’ 表示查询日期小于2015-01-01的记录…...
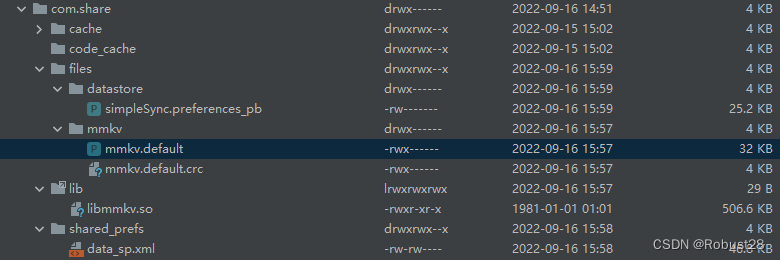
安卓中轻量级数据存储方案分析探讨
轻量级数据存储功能通常用于保存应用的一些常用配置信息,并不适合需要存储大量数据和频繁改变数据的场景。应用的数据保存在文件中,这些文件可以持久化地存储在设备上。需要注意的是,应用访问的实例包含文件所有数据,这些数据会一…...

数据结构【DS】栈的应用
描述一下如何实现括号匹配? 初始时栈为空。 从左往右遍历算术表达式中的每个括号元素: ①当遍历到左括号时,将其压入栈顶。 ②当遍历到右括号时,将栈顶元素出栈,并判断出栈的左括号与当前遍历的右括号是否匹配&…...

大数据数仓建模基础理论【维度表、事实表、数仓分层及示例】
文章目录 什么是数仓仓库建模?ER 模型三范式 维度建模事实表事实表类型 维度表维度表类型 数仓分层ODS 源数据层ODS 层表示例 DWD 明细数据层DWD 层表示例 DIM 公共维度层DIM 层表示例 DWS 数据汇总层DWS 层表数据 ADS 数据应用层ADS 层接口示例 数仓分层的优势 什么…...
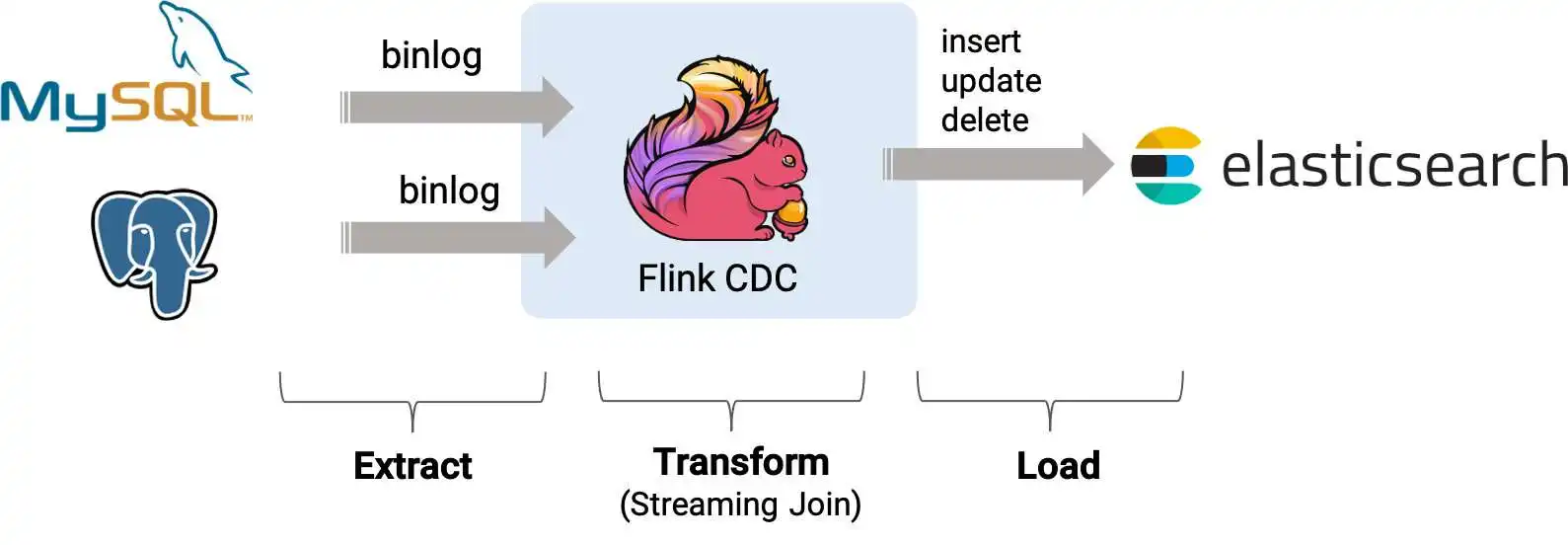
FlinkCDC数据实时同步Mysql到ES
考大家一个问题,如果想要把数据库的数据同步到别的地方,比如es,mongodb,大家会采用哪些方案呢? ::: 定时扫描同步? 实时日志同步? 定时同步是一个很好的方案,比较简单,但是如果对实时要求比较高的话,定…...

【Feign】 基于 Feign 远程调用、 自定义配置、性能优化、实现 Feign 最佳实践
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 SpringCloud MybatisPlus JVM 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Feign 一、 基于 Feign 远程调用1.1 RestTemplate方式…...
——基础入门3、基础入门4)
小迪安全笔记(3)——基础入门3、基础入门4
文章目录 一、抓包&封包&协议&APP&小程序&PC应用&web应用二、30余种加密编码进制&web&数据库&系统&代理 一、抓包&封包&协议&APP&小程序&PC应用&web应用 APP&小程序&PC抓包HTTP/S数据——Charles、F…...

SOME/IP 协议介绍(六)接口设计的兼容性规则
接口设计的兼容性规则(信息性) 对于所有序列化格式而言,向较新的服务接口的迁移有一定的限制。使用一组兼容性规则,SOME / IP允许服务接口的演进。可以以非破坏性的方式进行以下添加和增强: • 向服务中添加新方法 …...

吴恩达《机器学习》8-5->8-6:特征与直观理解I、样本与值观理解II
8.5、特征与直观理解I 一、神经网络的学习特性 神经网络通过学习可以得出自身的一系列特征。相对于普通的逻辑回归,在使用原始特征 x1,x2,...,xn 时受到一定的限制。虽然可以使用一些二项式项来组合这些特征,但仍然受到原始特征的限制。在神经网…...
『亚马逊云科技产品测评』活动征文|借助AWS EC2搭建服务器群组运维系统Zabbix+spug
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。 本文基于以下软硬件工具: aws ec2 frp-0.52.3 zabbix 6…...

文件转换,简简单单,pdf转word,不要去找收费的了,自己学了之后免费转,之后就复制粘贴就ok了
先上一个链接pdf转word文件转换 接口层 PostMapping("pdfToWord")public String pdfToWord(RequestParam("file") MultipartFile file) throws IOException {String fileName FileExchangeUtil.pdfToWord(file.getInputStream(),file.getName());return…...

Jmeter——循环控制器中实现Counter计数器的次数重置
近期在使用Jmeter编写个辅助测试的脚本,用到了多个Loop Controller和Counter。 当时想的思路就是三个可变的数量值,使用循环实现;但第三个可变值的数量次数,是基于第二次循环中得到的结果才能确认最终次数,每次的结果…...

如何通过SPT-AKI Profile Editor存档编辑器轻松掌控你的塔科夫离线体验
如何通过SPT-AKI Profile Editor存档编辑器轻松掌控你的塔科夫离线体验 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirr…...

解锁WeMod完整功能的终极指南:Wand-Enhancer让你的游戏体验升级
解锁WeMod完整功能的终极指南:Wand-Enhancer让你的游戏体验升级 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经因为WeMod的Pro会…...

ChatGPT企业版安全合规全解析:如何在72小时内完成GDPR/等保2.0双认证接入?
更多请点击: https://intelliparadigm.com 第一章:ChatGPT企业版核心架构与合规定位 ChatGPT企业版并非简单叠加访问权限的SaaS服务,而是基于隔离部署、数据主权保障与策略可编程性构建的合规优先架构。其底层采用多租户物理隔离的专用基础设…...

机器学习在轨道预测中的应用:两阶段模型实现精度与效率的平衡
1. 项目概述与核心挑战在低地球轨道(LEO)上,成千上万的卫星和空间碎片正以每秒数公里的速度高速飞行。精确预测它们未来的位置——轨道预测——是确保航天器安全、避免碰撞以及进行有效空间交通管理的基石。传统上,这项工作依赖于…...

工业云脑:04 边缘计算:本地处理 vs 云端
04 边缘计算:本地处理 vs 云端 数据从传感器冒出来,像车间里刚下线的零件儿,怎么“嚼”最香?全扔云上?还是本地先咬一口?来,慢慢扒。 边缘计算的价值,不在于算得多,而在于算得近、算得快。 你想想,以前工厂数据全往云端塞,千里迢迢,延迟高、带宽贵、网一抖就卡。边…...

FuSa RTX RTOS多核支持与AMP架构解析
1. FuSa RTX RTOS多核支持解析 在嵌入式安全关键系统开发领域,多核处理器架构已成为提升性能的主流选择。作为Arm FuSa RTS(功能安全运行时系统)的核心组件,FuSa RTX RTOS的多核支持能力自然成为开发者关注的焦点。本文将深入剖析…...

如何快速掌握茉莉花插件:Zotero中文文献管理的完整实践指南
如何快速掌握茉莉花插件:Zotero中文文献管理的完整实践指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zot…...

Grafana k6性能工程实践:从压测工具到CI/CD原生可观测性基础设施
1. 这不是又一个“压测脚本包装器”,而是性能工程的基础设施重构Grafana k6——这个名字刚出现时,我第一反应是:又一个基于Node.js封装的轻量级压测工具?毕竟JMeter、Locust、Artillery都走过类似路径。但真正把它跑通第一个真实业…...

从哈密顿量到李代数:对称性识别与结构常数计算实践
1. 从哈密顿量到李代数:物理学家工具箱里的对称性语言在理论物理和数学物理的日常工作中,我们常常面对一个核心问题:如何从一堆看似复杂的运动方程或一个写出来的哈密顿量中,快速识别出系统隐藏的“灵魂”?这个灵魂&am…...

从文本到流程:NLP与LLM驱动的业务流程模型自动提取技术
1. 项目概述与核心价值在业务流程管理(BPM)的日常工作中,我们经常遇到一个经典难题:业务部门或客户给出一大段文字描述,比如一份操作手册、一封需求邮件或一次会议纪要,我们需要从中梳理出清晰、可执行的业…...