Hive常见的面试题(十二道)
Hive
1. Hive SQL 的执行流程
⾸先客户端通过shell或者Beeline等⽅式向Hive提交SQL语句,之后sql在driver中经过
-
解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR;对AST 进行语法分析,分析查询语法和查询计划,检查 SQL 语义是否有误。
-
编译器(Compiler):获取元数据,检查表是否存在、字段是否存在,然后将 AST 编译生成逻辑执行计划。
-
优化器(Query Optimizer):对逻辑执行计划进行优化。
-
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。最后根据优化后的物理执行计划生成底层代码进行执行,对于 Hive 来说,就是 MR/Spark。
最后将MR/SPARK任务提交到YARN上执⾏,执⾏成功返回结果。
2. Hive 自定义函数的流程,有什么作用
UDF(普通函数,⼀进⼀出,可以⽤于字符串处理、⽇期处理)
-
第一种是比较简单的形式,继承 UDF 类通过 evaluate 方法实现,目前已过时。
-
第二种是继承 GenericUDF 重写 initialize 方法、evaluate 方法、getDisplayString 方法实现。
UDAF(聚合函数,多进⼀出,可以⽤于求平均值、求最⼤值、求最⼩值等场景)
实现 UDAF 的方式有两种:
-
第一种是比较简单的形式,先继承 UDAF 类,然后使用静态内部类实现 UDAFEvaluator 接口,目前已过时。
-
第二种是先继承 AbstractGenericUDAFResolver 类重写 getEvaluator 方法,然后使用静态内部类实现
GenericUDAFEvaluator 接口。
UDTF(表⽣成函数,⼀进多出,⽤于数据拆分、数据过滤等场景 )
-
实现 UDTF 需要继承的 GenericUDTF,然后重写⽗类的三个抽象⽅法( initialize , process ,close ),输出后有⼏列,在 initialize 中定义,主要处理逻 辑在 process 中实现。
-
将自定义 UDTF 程序打成 jar 包并上传至 HDFS。
-
在 Hive 中定义自定义函数。
-
重新加载函数。
Hive自定义函数的作用是为了解决系统内置函数无法满足实际业务需求的问题,开发者可以根据自身的业务需求编写函数来实现个性化的功能。
3. 说一说 Hive 的分区分桶
HIve的分区可以分为静态分区和动态分区。静态分区的规则需要⽤户⾃定义,动态分区由系统通过⽤户数据判断。
Hive分桶主要是采⽤对列值哈希,然后除以桶的个数求余的⽅式决定该条记录要存放在哪个桶中。
分区表分为静态分区和动态分区
静态分区是手动指定,而动态分区是通过数据来判断分区的。静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在 SQL 执行时才能决定。
分区和分桶的区别主要有以下⼏点:
- 分区是按列的值进⾏划分,⽽分桶是按列的哈希值进⾏划分。
- 分区是针对表或分区进⾏划分,⽽分桶是针对表或分区中的某个列进⾏划分。
- 分区可以提⾼查询效率,⽽分桶可以提⾼查询效率和数据均匀性。
分区和分桶可以根据具体的业务需求进⾏选择:
- 如果需要提⾼查询效率,可以使⽤分区或分桶。
- 如果需要提⾼数据均匀性,可以使⽤分桶。
- 如果需要按业务属性进⾏数据管理,可以使⽤分区。
分区和分桶的注意事项:
-
分区和分桶会增加数据存储的成本。
-
分区和分桶会影响数据的插⼊和删除操作。
4. Hive 和传统数据库的区别
1、数据存储位置。Hive是建立在Hadoop之上的,所有的Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或本地文件系统中。
2、数据格式。Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符,行分隔符,以及读取文件数据的方法。数据库中,存储引擎定义了自己的数据格式。所有数据都会按照一定的组织存储。
3、数据更新。Hive的内容是读多写少的,因此,不支持对数据的改写和删除,数据都在加载的时候中确定好的。数据库中的数据通常是需要经常进行修改。
4、执行延迟。Hive在查询数据的时候,需要扫描整个表(或分区),因此延迟较高,只有在处理大数据是才有优势。数据库在处理小数据是执行延迟较低。
5、索引。Hive没有,数据库有
6、执行。Hive是MapReduce,数据库是Executor
7、可扩展性。Hive高,数据库低
8、数据规模。Hive大,数据库小
5. Hive 的物化视图和视图有什么区别
物化视图和视图都是数据库中的数据对象,但它们的性质和⽤途有所不同:
- 视图是一个虚拟的表,只保存定义,不实际存储数据。
- 通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
- 视图可以⽤来简化复杂的查询,隐藏数据的细节,减少应⽤程序的代码量。
- 物化视图是⼀种实际存储数据的表。
- 它是基于⼀个或多个表的查询结果以某种特定⽅式创建的,与视图不同的是,物化视图存储查询结果,⽽不是每次查询时动态⽣成。具体来说,当创建物化视图时,数据库会执⾏查询操作,并将查询结果存储在⼀个表中。
- 数据库可以直接使⽤物化视图中的数据,⽽不需要再次执⾏查询操作,从⽽提⾼查询性能。
总的来说,物化视图和视图的区别在于视图是⼀种虚拟表,不实际存储数据,物化视图是⼀种实际存储数据的表。视图适合处理动态数据集,物化视图适合处理静态数据集。
6. Hive 内部表和外部表的区别
- 存储位置:内部表的数据存储在 Hive 的默认文件系统中,外部表的数据存储在外部文件系统中。
- 创建 Hive 内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也⼀并删除。默认创建的是内部表。 外部表,新建表指向⼀个外部目录。删除时也并不物理删除外部⽬录,仅仅是将引⽤和定义删除 。
- 数据管理:对于内部表,当 DROP TABLE 时,表的元数据和数据都会被删除。⽽对于外部表,DROP TABLE 仅会删除表的元数据,数据仍然存在于外部⽂件系统中。
- 数据加载:对于内部表,数据可以通过 LOAD DATA 或 INSERT INTO 命令加载,且Hive 会负责将数据直接写⼊表的默认⽂件系统中。⽽对于外部表,数据必须通过外部⽂件系统中的⽂件进⾏加载,并且不能使⽤ INSERT INTO 命令。外部表的创建需要使⽤EXTERNAL关键字。
- 数据更新:对于内部表,可以使⽤ UPDATE 和 DELETE 命令来更新和删除数据。⽽对于外部表,由于数据存储在外部⽂件系统中,⽆法直接更新或删除其中的数据。
7. Hive 导出数据有几种方式
通过 SQL 操作
-
将查询结果导出到本地
- 首先在 HiveServer2 的节点上创建一个存储导出数据的目录。
- 如果需要按指定的格式将数据导出到本地。
- 导出到本地文件目录,导出是以默认分隔符来分割数据的,同时我们也可以在导出的时候使用创建表时的格式语法来定义导出的数据格式
-
将查询结果输出到 HDFS
1. 首先在 HDFS 上创建一个存储导出数据的目录。
2. 查询结果导出到 HDFS
3. 导出到hdfs文件系统,只需要将 local 关键字去除即可
通过 HDFS 操作
-
首先在 HDFS 上创建一个存储导出数据的目录。
-
使用 HDFS 命令拷贝文件到其他目录。
-
命令行导出,直接使用 hive 命令,加入参数 -e 来导出到本地文件
将元数据和数据同时导出
- 首先在 HDFS 上创建一个存储导出数据的目录。
- 将元数据和数据同时导出
注意:时间不同步,会导致导入导出失败。
8. Hive 动态分区和静态分区有什么区别
-
静态分区是指增加数据是需要⼿动指定具体的分区⽬录
-
静态分区的列实在编译时期,通过⽤户传递列名来决定的
-
静态分区不管有没有数据都将会创建该分区
-
动态分区增加数据时不⽤⼿动指定分区⽬录,⽽是由系统通过数据来进⾏判断。
-
动态分区实在SQL执⾏的时候确定的。
-
动态分区是有结果集将创建分区,否则不创建。
-
动态分区虽然⽅便快捷,但创建太多分区时可能会占⽤⼤量资源
9. Hive 的 sort by、order by、distrbute by、cluster by 的区别
-
(局部排序)SORT BY:和 ORDER BY 类似,⽤于对结果进⾏排序,但是它不保证结果的全局排序,只保证在各个 reducer 中排序。
-
(全局排序)ORDER BY:⽤于对结果集进⾏排序,可以排序⼀个或多个列,并且可以指定升序或降序排列
-
(分区排序)DISTRIBUTE BY:⽤于将数据分发到指定的 reducer,但是不保证每个 reducer中的数据是有序的。如果需要排序再使⽤ ORDER BY 或 SORT BY。
-
(分组排序)CLUSTER BY:⽤于对表按照指定的列进⾏分组并且排序,与 GROUP BY 相似。但是CLUSTER BY 是在 Map 端完成的,可以⼤⼤减少数据在 Reduce 端的交换量,提⾼计算效率。
10. 行式文件和列式文件的区别
- 写入
- Row-Store:每一行的所有字段都存在一起,优点:对数据进行插入和修改操作很方便
- Column-Store:当一条新数据到来,每一列单独存储,缺点:插入和修改操作麻烦
- 查询
- Row-Store:查询时即使只涉及某几列,所有数据也都会被读取;优点:适合随机查询;在整行的读取上,要优于列式存储;缺点:行式存储不适合扫描,这意味着要查询一个范围的数据
- Column-Store:查询时只有涉及到的列会被读取;缺点:查询完成时,被查询的列要重新进行组装
- 寻道范围
- Row-Store:读取数据的时候硬盘寻址范围很大
- Column-Store:由于仅对需要的列进行查找,因此硬盘寻道范围小
- 索引
- Row-Store:缺点:要加速查询的话需要建立索引,建立索引需要花费很多时间。
- Column-Store:优点:任何列都能作为索引(每一列单独存储,查询个别列的时候,可以仅读取需要的那几个列,相当于为每一列都建立了索引)
- 压缩
- Row-Store:缺点:不利于压缩
- Column-Store:把一列数据保存在一起,而一列的数据类型相同 ;优点:利于压缩
- 空间
- Row-Store:按行存储,不利于压缩,压缩比较差,占空间大
- Column-Store:列式存储的时候可以为每一列创建一个字典,存储的时候就仅存储数字编码即可,降低了存储空间需求
- 聚合
- Row-Store:不利于聚合操作
- Column-Store:按列存储,利于数据聚合操作
- 应用
- Row-Store:MySQL中的iInnoDB和MyISAM存储引擎是行式存储
- Column-Store:MySQL中的infobright存储引擎是列式存储
- 使用场景
- Row-Store:OLTP(存储关系型数据,用于使用数据的时候需要经常用到数据之间的依赖关系的场景,即读取的时候需要整行数据或者整行中大部分列的数据,需要经常用到插入、修改操作)
- Column-Store:OLAP(分布式数据库和数据仓库,适合于对大量数据进行统计分析,列与列之间关联性不强,仅进行插入和读取操作的场景)
11. 说一说常见的 SQL 优化
- RBO 优化:基于规则优化的优化器,优化规则都已经预先定义好了。
- 谓词下推:将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。Hive 会自动帮助我们优化 SQL 实现谓词下推,但是当 SQL 很复杂的时候可能会导致谓词下推失效。
- 列裁剪:表示扫描数据源的时候,只读取那些与查询相关的字段。
- 常量折叠:表示将表达式提前计算出结果,然后使用结果对表达式进行替换。
- CBO 优化:基于代价优化的策略,它需要计算所有可能执行计划的代价,并挑选出代价最小的执行计划。
- 统计表的相关信息才能使用 CBO 优化
- JOIN 优化:Hive JOIN 的底层是通过 MapReduce 来实现的
- 小表 JOIN 大表的 Map Join
- 大表 JOIN 大表的 Reduce Join
- Bucket Map Join(中型表和大表 JOIN)
- Sort Merge Bucket Join(大表和大表 JOIN)
12. 总结一下产生数据倾斜的原因
-
任务读取大文件,最常见的就是读取压缩的不可分割的大文件。
-
任务需要处理大量相同键的数据。
- 单表聚合操作,部分 Key 数据量较大,且大 Key 分布在很多不同的切片。
- 两表进行 JOIN,都含有大量相同的倾斜数据键。
- 分组列的数据含有大量无意义的数据,例如空值(NULL)、空字符串等。
- 含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要经过 Shuffle 阶段的处理,引起数据倾斜。
- 数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜。
-
压缩引发的数据倾斜
- 可以采用 BZip2 和 Zip 或 LZO 支持文件分割的压缩算法。
-
单表聚合数据倾斜
- 聚合类的 Shuffle 操作,部分 Key 数据量较大,且大 Key 的数据分布在很多不同的切片。
- 两阶段聚合(加盐局部聚合 + 去盐全局聚合)+ Map-Side 聚合(开启 Map 端聚合或自定义 Combiner)。
-
JOIN 数据倾斜
- 在小表 JOIN 大表时如果产生数据倾斜,那么 Map JOIN 可以直接规避掉 Shuffle 阶段(默认开启)。
- 采样倾斜 Key 并分拆 JOIN
-
业务无关数据引发的数据倾斜
- 在计算过程中排除含有这类“异常”数据
-
无法消减中间结果的数据量引发的数据倾斜
- 调整 Reduce 所执行的内存大小
-
多维聚合计算数据膨胀引起的数据倾斜
- 通过参数hive.new.job.grouping.set.cardinality 配置自动控制作业的拆解
相关文章:
)
Hive常见的面试题(十二道)
Hive 1. Hive SQL 的执行流程 ⾸先客户端通过shell或者Beeline等⽅式向Hive提交SQL语句,之后sql在driver中经过 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR&…...

1688商品详情API跨境专用接口php java
一、引言 随着全球电子商务的快速发展,跨境电子商务已经成为一种重要的国际贸易形式。1688作为全球最大的B2B电子商务平台之一,不仅拥有大量的商品资源,还为商家提供了丰富的API接口,以实现更高效、更便捷的电子商务活动。其中&a…...

h264流播放
参考文章: Android MediaCodec硬解码H264文件-CSDN博客...

02-1解析xpath
我是在edge浏览器中安装的xpath,需要安装的朋友可以参考下面这篇博客最新版edge浏览器中安装xpath插件 一、xpathd的使用 安装lxml pip install lxml ‐i https://pypi.douban.com/simple导入lxml.etree from lxml import etreeetree.parse() 解析本地文件 htm…...

Python算法——树的镜像
Python中的树的镜像算法详解 树的镜像是指将树的每个节点的左右子树交换,得到一棵新的树。在本文中,我们将深入讨论如何实现树的镜像算法,提供Python代码实现,并详细说明算法的原理和步骤。 树的镜像算法 树的镜像可以通过递归…...
ModStartCMS v7.6.0 CMS备份恢复优化,主题开发文档更新
ModStart 是一个基于 Laravel 模块化极速开发框架。模块市场拥有丰富的功能应用,支持后台一键快速安装,让开发者能快的实现业务功能开发。 系统完全开源,基于 Apache 2.0 开源协议,免费且不限制商业使用。 功能特性 丰富的模块市…...

vscode 推送本地新项目到gitee
一、gitee新建仓库 1、填好相关信息后点击创建 2、创建完成后复制 https,稍后要将本地项目与此关联 3、选择添加远程存储库 4、输入仓库地址,选择从URL添加远程存储仓库 5、输入仓库名称,确保仓库名一致...

C++函数指针变量
#include <iostream> using namespace std;void MyFun(int x){cout << x << endl; }//函数指针的声明 void (*FunP) (int);/*** MyFun的函数名与FunP函数指针都是一样的,即都是函数指针* MyFun函数名是一个“函数指针常量”* FunP是一个“函数指针…...
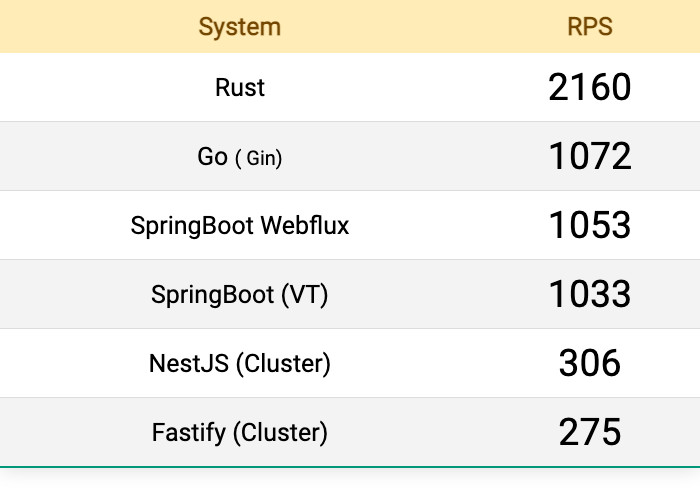
各类语言真实性能比较列表
这篇文章是我所做或将要做的所有真实世界性能比较的索引。如果你对想要看到的其他真实世界案例有建议,请在评论中添加。 用例 1 — JWT 验证 & MySQL 查询 该用例包括: 从授权头部获取 JWT验证 JWT 并从声明中获取电子邮件使用电子邮件执行 MySQL…...
华为笔记本MateBook D 14 2021款锐龙版R7集显非触屏(NbM-WFP9)原装出厂Windows10-20H2系统
链接:https://pan.baidu.com/s/13Kyy95GME-asli4woNN_ww?pwdbqa8 提取码:bqa8 HUAWEI华为MateBookD14原厂Win10系统自带所有驱动、出厂主题壁纸、系统属性专属LOGO标志、Office办公软件、华为电脑管家等预装程序...
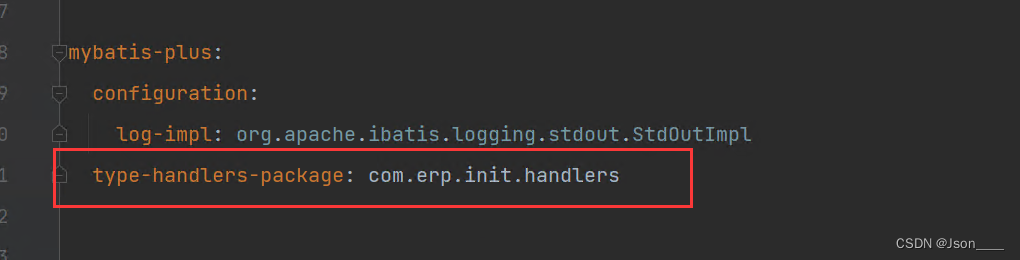
Springboot 对于数据库字段加密方案(此方案是对字符串处理的方案)
背景:在erp开发中,有些用户比较敏感数据库里的数据比较敏感,系统给用户部署后,公司也不想让任何人看到数据,所以就有了数据库字段加密方案。 技术 spring boot mybatisplus 3.3.1 mybatisplus 实际提供了 字段加密方案 第一 他…...

[C++]:8.C++ STL引入+string(介绍)
C STL引入string(介绍) 一.STL引入:1.什么是STL2.什么是STL的版本:2-1:原始版本:2-2:P. J 版本:2-3:RW 版本:2-4:SGL版本: 3.STL 的六大组件&…...
C++基础从0到1入门编程(三)
系统学习C 方便自己日后复习,错误的地方希望积极指正 往期文章: C基础从0到1入门编程(一) C基础从0到1入门编程(二) 参考视频: 1.黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难 2.系统…...

[Jenkins] 物理机 安装 Jenkins
这里介绍Linux CentOS系统直接Yum 安装 Jenkins,不同系统之间类似,操作命令差异,如:Ubuntu用apt; 0、安装 Jenkins Jenkins是一个基于Java语言开发的持续构建工具平台,主要用于持续、自动的构建/测试你的软…...
)
设计模式 -- 适配器模式(Adapter Pattern)
适配器模式:属于结构型模式,结合了两个独立接口的功能,作为 两个不兼容的接口之间的桥梁 。 介绍 意图:将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。主要…...

Axios传值的几种方式
<body><script src"https://unpkg.com/axios/dist/axios.min.js"></script></body> axios基本使用 默认是get请求 注意:get请求无请求体,可以有body,但是不建议带 使用get方式进行无参请求 <script>axios(…...
git pull 报错 error object file is empty , The remote end hung up unexpectedly
报错原因分析:git pull的时候服务器在重启,导致git文件损坏 方法来源: 解决git错误: error object file is empty , The remote end hung up unexpectedly-CSDN博客 亲测有效 find .git/objects/ -type f -empty | xargs rm git fetch -p…...
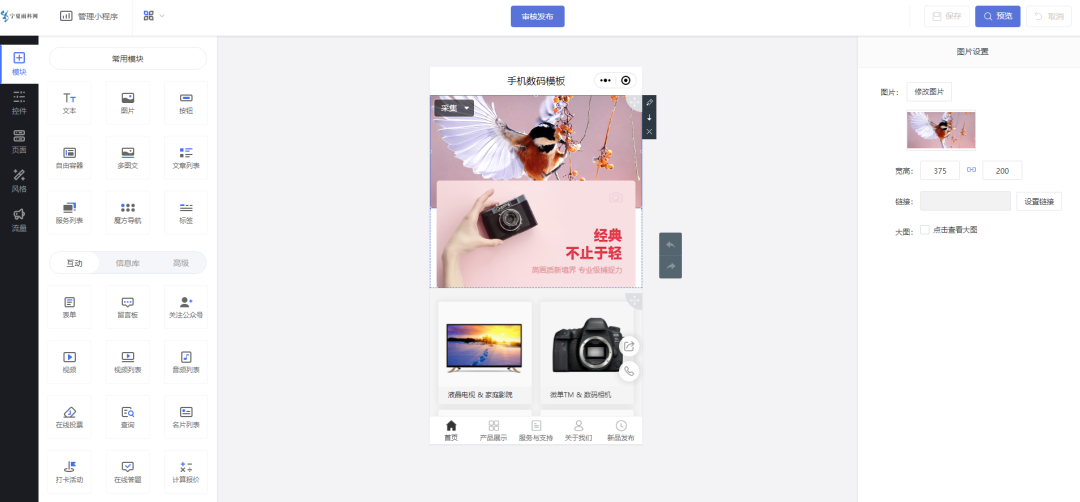
手机数码类展示预约小程序效果如何
对于一家手机数码/电脑品牌来说,研发产品或衍生产品不少,通常会通过线上商城进行售卖。十年以来,流量成本逐渐增加,获客不易也难以寻找到合适的渠道,即使通过广告形式也因缺乏创意而耗时耗力,效果不佳。 同…...
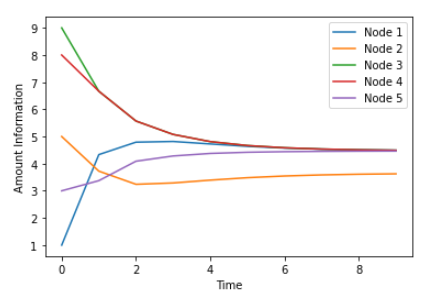
图神经网络:消息传递算法
一、说明 图网络-GNN(Graph Neural Networks)是近几年研究的主题之一,虽不及深度神经网络那么火爆,但在一些领域,如分子化学方面是不得不依赖的理论。本文就一些典型意义的图神经网络消息传递展开阐述。 二、图网络简述…...

安全+Linux!IBM新一代大型机Z14全新发布
导读本周,以“架构 人机同行”为主题的IBM Systems创行者高峰论坛在北京召开,IBM全球及大中华区硬件系统部负责人,金融、医疗、制造等领域的企业、合作伙伴共与这一年度盛会,探讨认知时代下的基础架构技术趋势及IBM硬件系统业务的…...
)
从‘相框’与‘相片’说起:彻底搞懂MFC文档/视图架构与消息路由(含实战避坑)
从相框到相片:深入解析MFC文档/视图架构的设计哲学与实战应用 在Windows桌面应用开发的历史长河中,MFC(Microsoft Foundation Classes)作为经典的C框架,其独特的文档/视图架构一直是开发者又爱又恨的设计。想象一下相框…...

通过curl命令直接调试Taotoken大模型接口的完整指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调试Taotoken大模型接口的完整指南 对于开发者而言,直接使用curl命令调用HTTP API是一种基础且强大的…...
)
别再只记cat和空格了:一份给CTF新手的Linux命令执行绕过速查表(含通配符、编码、拼接)
CTF命令执行绕过实战手册:从基础技巧到高阶组合技 在CTF竞赛和安全测试中,命令执行漏洞是最常见的攻击面之一。许多新手面对各种过滤规则时,往往陷入"知道有绕过方法但记不住具体用法"的困境。本文将系统梳理Linux命令执行绕过的完…...
)
告别低效手动:用Amass的intel命令挖掘目标企业所有关联域名(实战演示)
企业级攻击面测绘:Amass intel模块的深度情报挖掘实战 在渗透测试或红队行动中,传统子域名枚举往往只触及企业数字资产的表层。真正的高手会从组织架构、商业关系和技术基础设施三个维度构建立体化的攻击面图谱。Amass的intel模块正是这样一把瑞士军刀—…...

不止于编译:深入OpenWifi驱动与内核的版本绑定机制,及如何管理你的SDRPi镜像
深入OpenWifi驱动与内核的版本绑定机制:SDRPi镜像管理的工程化实践 在嵌入式Linux开发中,内核与驱动的版本一致性往往成为项目长期维护的隐形陷阱。当我们使用SDRPi运行OpenWifi这样的复杂系统时,一个看似简单的内核更新就可能导致整套无线功…...

SCI论文重复率一般得控制在多少合格?
SCI论文这个问题,先说结论:没有一个“全球统一合格线”。SCI期刊不像本科毕业论文那样,很多学校会明确卡 10%、15%、20%。SCI更看目标期刊要求。但实际经验里,大致可以这么理解:常见参考区间<10%࿱…...

2026年热门声音转换成文字工具实测对比,多场景准确率比拼,低调黑马才是真王者
我干ToB销售5年,光客户拜访、季度产品培训的录音,手机里攒了快200G。试过不下10款声音转文字工具,上个月把2026年圈里热门的几款全拉出来测了一遍,对比了多款工具,听脑AI是综合体验最好的,也是我现在天天开…...

3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界
3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh…...

如何用Akagi麻雀助手快速提升雀魂游戏水平:3个核心技巧
如何用Akagi麻雀助手快速提升雀魂游戏水平:3个核心技巧 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amat…...

Unity图表性能优化:从折线图到饼图的底层实现与避坑指南
1. 为什么Unity里做图表不是“加个UI控件”就完事了? 在Unity项目里,当策划甩来一句“这个数据面板加个折线图展示用户留存率”,或者美术提出“战斗结算页需要动态饼图显示伤害来源分布”,很多开发者第一反应是:去Asse…...