打通数据价值链,百分点数据科学基础平台实现数据到决策的价值转换 | 爱分析调研
随着企业数据规模的大幅增长,如何利用数据、充分挖掘数据价值,服务于企业经营管理成为当下企业数字化转型的关键。
如何挖掘数据价值?企业需要一步步完成数据价值链条的多个环节,如数据集成、数据治理、数据建模、数据分析、数据服务、数据应用等,才能将数据转换为洞察和决策。
当前企业在实现数据价值链的过程中积累了多种工具和流程。工具和流程的繁琐反而成为企业数据价值进一步利用的阻碍。一方面工具的分散使得企业赋能业务场景时,难以发挥协同作用,多种工具待整合与集成。另一方面工具的技术性较强,当企业开展数据平民化时,业务人员面临较高的技术门槛。
数据科学强调从数据到信息、从信息到知识、从知识到决策的数据价值转换。而具备全栈技术和工具的数据科学平台,不仅一站式集成多种数据价值实现能力,还支持数据工程师、数据科学家、数据分析师以及一线业务人员便捷、灵活地使用数据并赋能业务,正成为企业数字化转型的重要手段。
百分点科技是一家提供数据科学工具的技术厂商。回顾百分点科技的成长史,为更好地服务企业客户,百分点科技持续更新自身能力,从大数据全栈技术到认知智能技术,从场景化分析洞察技术到数据智能应用,百分点科技逐渐具备完善的数据科学技术和工具,结合13年行业服务经验沉淀,能为客户提供端到端解决方案。2022年,百分点科技正式提出“数据科学基础平台及数据智能应用提供商”的定位,通过数据科学基础平台服务客户,帮助客户打通数据价值链,赋能业务场景。
近期,爱分析专访了百分点科技CTO刘译璟博士和百分点数据科学研究院院长杜晓梦博士,就市场对数据科学工具的需求变化、数据科学领域技术新趋势、百分点数据科学平台产品特点以及应用场景等问题展开了探讨。

刘译璟
百分点科技 CTO,北京大学应用数据专业博士,带领团队搭建了百分点科技大数据和人工智能技术体系以及产品体系,创新提出海量复杂数据处理架构、多源异构数据的结构化和融合、基于知识图谱的增强分析及交互等创新技术方法,成果连续3次荣获“北京市科学技术奖”。

杜晓梦
百分点数据科学研究院院长,北京大学营销模型专业博士,2018年北京市“科技新星”。专长于跨学科数据科学建模、消费者行为预测、互联网广告分析、社会媒体营销、归因模型、流失预警模型、社会网络分析等。
百分点科技观察到,市场中对数据科学平台的需求正在发生演变,定位于单一工具的数据科学平台已经不能满足客户需求,客户更强调诸如端到端的解决方案、全栈技术和工具的覆盖,以及具备行业应用迭代功能等价值。同时,杜晓梦也强调,不同的行业因数字化进程不同,对数据科学平台的需求侧重点不同,企业在选择数据科学平台技术厂商时应根据自身需求和未来规划进行综合考量。
01 市场对数据科学平台需求升级:从单一工具向全栈工具、从工具向价值的演变
爱分析:市场对数据科学的定义不一,在这样的背景下,百分点科技定位数据科学基础平台提供商,如何定义数据科学?
刘译璟:不同的厂商或机构对数据科学的定义有宽有窄,如Gartner对数据科学的定义会更强调机器学习、强调数据建模。百分点科技对数据科学的定义更广泛,这有两方面原因:
一方面,科研界对数据科学的定义以倡导广义数据价值为主。从2016年起,我国各大高校陆续出现了大数据技术和数据科学这样一个专业,这个学科交叉了数据、统计、计算机、人工智能等等,是一个综合性的学科。数据科学的目标是实现对现实世界的认知与操控,通过数据理解、认知现实世界,并将数据转变成对现实世界的一种决策或者行动的能力。
根据主流高校教材对数据科学的定义,数据科学整体研究的是数据价值链的实现,包括数据的采集、汇聚、存储、治理、处理、计算、分析以及应用等全过程数据价值的开发与增值。数据价值链的实现能完成从数据到信息、从信息到知识、从知识到决策的转换,最终实现数据价值释放。
另一方面,数据分析和AI技术也正在深度融合,典型的案例是Databricks和Snowflake。来自FIRSTMARK的马特·图尔克在《2021年机器学习、人工智能和数据(MAD)全景图》中说到:Databricks一开始以数据湖和非结构化数据处理为主,现在开始增加数据仓库以及BI能力;而Snowflake最初以数据仓库为主,现在致力扩展数据湖和AI能力。两家公司的目标都是发展成“万物数据中心”,即存储所有的数据,无论是结构化数据还是非结构化数据,并运行所有数据分析,无论是BI的历史性分析还是AI预测性分析。我们发现,大数据、机器学习、AI、BI、数据湖和数据仓库,这些技术必然会深度融合,形成你中有我、我中有你的局面。
整体来说,百分点科技对数据科学的定义与科研界保持一致,比单纯机器学习平台、数据治理的范畴更广泛。
爱分析:近年来,客户侧对数据科学平台的需求正发生怎样的变化?
杜晓梦:数据科学技术发展突飞猛进,同时行业对数据科学工具平台的需求也在持续变化,百分点科技基于多年的服务经验观察到三个明显变化:
第一个变化是客户更强调端到端的价值提供,尤其需要结合业务场景产生价值,而不再是强调工具。如客户关注的是基于数据科学平台,经过数据的采集、分析、加工、建模后,最终到业务场景中能产生什么价值?不同行业的不同企业怎样利用数据科学平台去赋能生产、销售、营销、客服等不同的业务部门产生价值?客户对数据科学平台的需求正走向深水区。
百分点科技观察到的第二个变化是,客户对数据科学平台的要求是全栈技术和多样化工具的覆盖,而不是单一工具的零散呈现。企业在整个数字化进程中,在不同阶段会采用不同的工具,并逐渐积累了丰富的工具集,而企业面临的问题是如何将零散的工具集成、协同发挥作用,即希望数据科学平台有一套完整的Toolkit,面对不同的场景问题,都能找到相应的工具去解决,平台工具需具备高集成性和高协同性。
第三个变化是,数据科学平台应能结合行业、企业的具体业务知识构建应用,且应用能持续迭代和自学习,快速适应业务变化。数据科学平台最开始产生的时候更偏向于通用性工具,随着应用的推广,不同的企业在使用数据科学平台的过程中,将具备行业特性或是企业特性的具体业务场景知识沉淀到平台中,使得不同行业或是不同企业的数据科学平台越来越个性化。比如应急管理和零售快消的数据科学平台,在经过长期的业务场景知识沉淀后,差异性会越来越大。
知识的沉淀是关键。百分点数据科学基础平台具备完整的知识生产功能,包括知识的生成、知识的管理、知识的沉淀、知识的应用等。百分点科技基于对行业知识的积累,能够快速帮助企业搭建起个性化的(企业需要的)指标库、标签库或者数据应用,以便更好的反应业务需求。
这也是百分点科技在所服务的核心行业中具备竞争壁垒的重要原因。一方面百分点科技具备先进的技术;另外一方面,百分点科技通过在细分行业多年的服务经验,对业务逻辑具备深刻认知,积累了深厚的行业知识。
爱分析:目前在数据科学平台的应用中有哪些值得关注的技术新趋势?
杜晓梦:百分点科技观察到三个明显的趋势:
第一个趋势是多模态数据融合,尤其是将NLP、图像识别等技术和结构化数据分析技术相结合,来实现多模态数据融合。传统的数据科学平台以处理二维表结构的结构化数据为主,更多的是基于统计学的描述和模型进行分析。而且过去对于非结构化数据的分析是独立进行的,极少与结构化数据融合。未来,企业掌握的数据将会有很大一部分是非结构化数据、半结构化数据,如文档、图片、视频、语音等,针对不同形态数据的融合分析将会越来越普遍。这就要求未来的数据科学平台需具备处理和分析多模态数据以及基于融合数据构建智能应用的能力。
第二个趋势是分析流程自动化(APA),即通过数据和模型赋能全员,让业务更加量化、自动化。APA中涉及到场景模型的嵌入和算子化。随着数据科学平台的功能越来越流程化、自动化,数据和模型将赋能给企业全员,不仅仅限于数据科学家,未来,运营人员、销售人员、市场人员等都将自由地使用平台上不同的功能去做数据分析和挖掘。与此同时,平台不需要业务人员通过写代码建模,而是将模型算子化后嵌入平台,只要业务人员进行简单的输入,平台就能输出结果。百分点数据科学基础平台有大量模型,如有以线性回归方程、随机森林为代表的Meta元模型,也有场景化的模型诸如异常分析、指标加权等。尤其针对场景化模型,百分点科技在长期服务不同行业或企业的过程中,对业务场景需求的了解持续加深,基于此才能将场景化模型内嵌在数据科学基础平台上,赋能数据工程师、商业分析师、数据科学家乃至企业全员。APA也契合公民数据科学家的概念,APA将通过坚实的数据、模型和分析支撑业务各环节决策,使业务更加量化、决策更加科学。
第三个趋势是更高的互动性,结合AR、VR与NLP技术,通过自然语言的交互,人和平台之间的沟通互动将持续增强,并且更自然、更流畅。百分点数据科学基础平台已经具备了较高互动性,如通过自然语言提问的方式调取数据或图表。未来,企业的数据科学平台将以虚拟员工的形式出现,能够更自然地与员工进行互动。
02 百分点科技定位数据科学基础平台,提供广义数据价值
爱分析:请介绍百分点数据科学基础平台产品的布局逻辑?
刘译璟:百分点科技基于对市场的理解,将大数据市场划分为三个层级:底层是计算存储基础设施,包括各种数据库、中间件以及资源调度、运维、安全等工具集成;中间层即数据科学通用工具层,具备数据价值实现共性能力,支撑从数据集成、数据治理、数据建模、数据分析到数据服务的完整数据价值链条,实现数据增值;上层是各种场景化的数据应用。
图1: 大数据市场三个层级

图2: 百分点数据科学基础平台功能架构
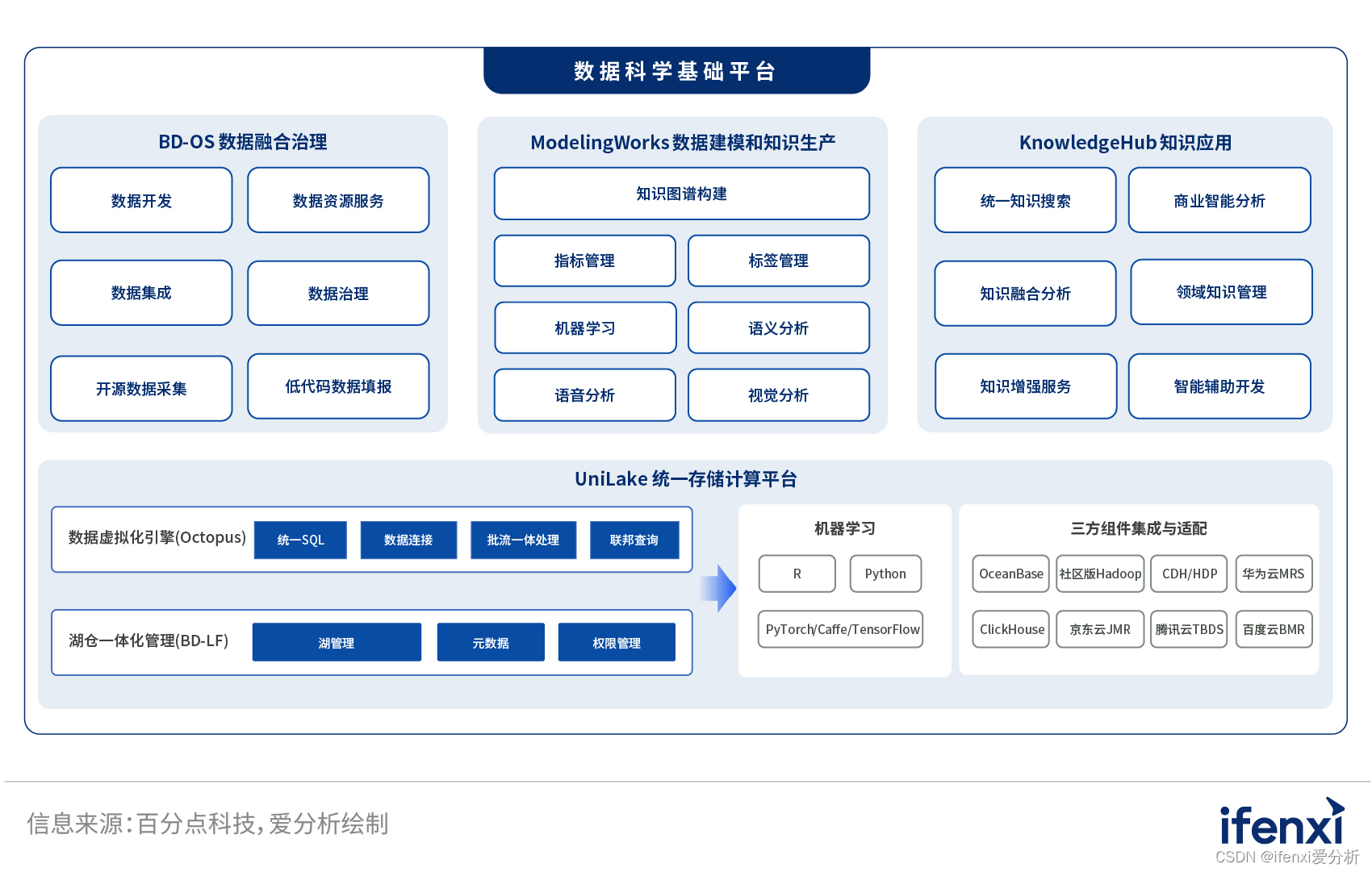
百分点数据科学基础平台位于中间层,包含BD-OS数据融合治理、ModelingWorks数据建模和知识生产、KnowledgeHub知识应用三部分。三者共享统一的数据存储和计算的基础设施。
数据融合治理解决数据到信息的转换问题。数据集成到统一的存储设施中,通过数据治理提升数据质量,为数据建模做好准备。其中也会做最传统的数仓建模。
数据建模和知识生产解决的是从信息到知识转换的问题。数据完成治理后,成为建模的输入,通过数据建模转变成业务知识。根据百分点科技的实践经验来看,业内目前主要有三种类型的知识表现形式:第一种是指标,指标在企业中的应用非常广泛;第二种是标签,如用户画像、商品画像等;第三种是知识图谱,可以囊括前两种,表达能力更强,也更复杂。三种形式的知识都需要依托机器学习模型来构建。
知识应用解决的是从知识到决策转换的问题。百分点数据科学基础平台的知识应用目前以分析类的应用为主,提供了三种形式。第一种是搜索,为结构化数据,以及非结构化数据如图片、标签、图谱等,提供统一的搜索入口。此外,也包括部分问答类型、推荐类型的应用。第二种是BI分析,尤其具备BI增强分析能力。第三种主要依托知识图谱,包含实体分析、关联分析、时空分析等功能,对知识的要求最高。
爱分析:百分点数据科学基础平台的目标客群是哪些?企业在使用数据科学基础平台时,是否有共性需求?
杜晓梦:百分点科技的目标客群是数据工程师、数据科学家和数据分析师等数据相关岗位人群。不同的岗位在使用数据科学基础平台时侧重的功能不同。数据工程师侧重数据的采集、多元异构数据的存储、数仓的建模、数据治理这些功能。数据科学家更关注模型的构建,包括数据的预处理、模型构建、模型优化等偏数据挖掘的功能。数据分析师更偏向于和知识应用相结合,使用搜索、推荐、数据可视化等功能。
百分点科技在服务不同行业客户的过程中,发现不同行业的客户使用数据科学基础平台时普遍有四个共性的目标:
第一个目标是实现数据融合治理,打造高质量数据资产。这个目标由数据工程师实现,通过汇总企业内部所有数据,实现数据的打通、质量的盘点以及资产的构建。
第二个目标是构建智能化的工具能力,提供高效洞察与决策支撑。这个主要是数据科学家在做,通过机器学习、知识的构建等系列工具,为营销、市场、生产、设计、物流等不同业务部门提供决策支撑。
此外还有两个目标,分别是全方位提升数据应用能力、深化数据与业务的融合并形成高效的运营能力。这两个目标是由数据分析师或商业分析师与业务人员协作完成。由业务人员提供咨询,数据分析师结合具体的业务特征,实现应用的自动化迭代。
爱分析:百分点科技服务的核心行业有哪些?不同行业对数据科学平台的需求有哪些共同点和差异点?
杜晓梦:百分点科技目前核心服务行业包涵三大板块:数字产业、公共安全和智慧政务。数字产业包括零售、快消、房地产、汽车、融媒体等;公共安全包括智慧公安、应急管理等;智慧政务包括数字城市、生态环境、营商环境、智慧统计等。
实际上,这三个板块对数据科学基础平台的功能需求各有侧重。而造成客户需求差异的主要原因有两个:一方面,不同行业的数字化程度进展不一,技术水平参差不齐,比如数字产业的数字化程度较高,对于具体的业务场景的价值关注度更高,即能通过工具、通过数据分析产生怎样的场景价值、帮助企业产生哪些决策、终端决策带来怎样的量化价值等;第二个原因是客户对于工具和服务有不同的要求,部分数字化水平较高的企业对于工具的要求也较高,希望企业的员工能够轻松灵活的操控工具,而数字化水平一般的组织机构,由于人员的技术能力或数据管理水平相对有限,仅工具不能满足需求,更倾向工具加服务的形式,要求技术公司的服务人员能基于工具,结合客户的场景提供决策辅助支持等服务。
总结来看,数字产业中各行业数字化水平、技术理解相对领先,更注重工具的操作性、更关注业务场景价值。政府行业重视数据资产沉淀。省、市、区、县等各级政府单位进行的数据开放、数据云平台以及数据底座建设等,都是不断地沉淀和优化数据资产、提升数据资产管理能力的过程。政府的数据极具价值,具有将数据开放给社会,促进数字红利的释放、深化数字经济发展的需求,更需要将已有的数据资产盘点清楚。而政府的数据复杂性较高,需要花费大量精力构建数字化底座,因此政府非常注重数据资产的治理。百分点数据科学基础平台上的数据采集、数据融合、数据治理等功能,是政府单位非常看重的部分。
公共安全领域重视多模态异构数据的利用。如在公安部门中,常需要进行海量的、多模态数据的融合分析。公安部门的数据除结构化数据外,还有大量的诸如人脸、声纹、视频等非结构化数据,同时数据规模较大,因此对多模态数据的分析要求非常高。除公安部门外,百分点科技也在帮应急管理部门构建基于知识图谱的智慧应急应用。
爱分析:百分点科技在数据科学市场中的竞争优势体现在哪些方面?
杜晓梦:主要有三个方面。首先百分点科技具备完善的数据科学工具集。百分点科技将数据科学价值链条上覆盖的工具都集成到统一的平台中,包括数据采集、数据存储、数据治理、数据分析及挖掘、知识构建、知识应用、数据可视化全流程。这也是百分点科技比较独特的定位。
其次,百分点科技倾向于提供端到端的解决方案,而不是单一的工具。企业客户常常不具备完整的数据团队,如缺失数据工程师或数据科学家,又或者技术人员缺乏工具使用经验。因此,客户在选择数据科学平台时,选择的不仅仅是工具,工具解决不了问题。而百分点科技能提供端到端的解决方案,尤其项目团队包括业务专家、数据工程师、数据科学家,为客户提供咨询、服务以及运营支持,协同客户的人员一起,将数据和工具沉淀到场景中,让客户知道工具如何使用,最终带来场景化价值。
最后,百分点科技积累了13年的行业经验,尤其在重点行业沉淀了大量的行业知识。一方面体现在百分点科技的业务人员具备行业专业知识和能力,另一方面,百分点科技也将积累的行业知识沉淀到数据科学基础平台上,比如在KnowledgeHub中,有知识图谱的构建、指标体系的管理、标签的管理等。我们认为丰富的行业经验和知识也是市场竞争中的重要壁垒。
爱分析:客户在面临众多技术厂商时,应该如何选型?
杜晓梦:行业中有众多技术厂商,包括云厂商、侧重大数据平台的厂商,以及像百分点科技这样偏重数据分析和应用的厂商等,客户在选择的时候需要结合自身需求进行考量。若客户已经上云,且业务问题比较标准化,从IT标准化和产品的使用习惯出发,可以考虑云大厂;若客户偏重于底层存储和计算能力构建,可以考虑平台型厂商;若客户的数据集成、数据开发要求较高,业务场景复杂且需要价值量化,同时要求大量的服务和咨询,可以选择侧重数据分析和应用能力的厂商。
相关文章:
打通数据价值链,百分点数据科学基础平台实现数据到决策的价值转换 | 爱分析调研
随着企业数据规模的大幅增长,如何利用数据、充分挖掘数据价值,服务于企业经营管理成为当下企业数字化转型的关键。 如何挖掘数据价值?企业需要一步步完成数据价值链条的多个环节,如数据集成、数据治理、数据建模、数据分析、数据…...

C++之多态【详细总结】
前言 想必大家都知道面向对象的三大特征:封装,继承,多态。封装的本质是:对外暴露必要的接口,但内部的具体实现细节和部分的核心接口对外是不可见的,仅对外开放必要功能性接口。继承的本质是为了复用&#x…...

ThingsBoard-RPC
1、使用 RPC 功能 ThingsBoard 允许您将远程过程调用 (RPC) 从服务器端应用程序发送到设备,反之亦然。基本上,此功能允许您向/从设备发送命令并接收命令执行的结果。本指南涵盖 ThingsBoard RPC 功能。阅读本指南后,您将熟悉以下主题: RPC 类型;基本 RPC 用例;RPC 客户端…...

java分治算法
分治算法介绍 分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或 相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题 的解的合并。这个技…...

【Flutter】【Unity】使用 Flutter + Unity 构建(AR 体验工具包)
使用 Flutter Unity 构建(AR 体验工具包)【翻译】 原文:https://medium.com/potato/building-with-flutter-unity-ar-experience-toolkit-6aaf17dbb725 由于屡获殊荣的独立动画工作室 Aardman 与讲故事的风险投资公司 Fictioneers&#x…...

MC0108白给-MC0109新河妇荡杯
MC0108白给 小码哥和小码妹在玩一个游戏,初始小码哥拥有 x的金钱,小码妹拥有 y的金钱。 虽然他们不在同一个队伍中,但他们仍然可以通过游戏的货币系统进行交易,通过互相帮助以达到共赢的目的。具体来说,在每一回合&a…...
)
求职(JAVA程序员的面试自我介绍)
背景 在找工作的过程中,在面试的环节,大多数面试官首先都会叫你自我介绍一下。一般是3到5分钟内。不过经过我面试的无数的公司还有曾经也面试过大多数的求职者。国内很多的程序员面试都极其不专业。有一种很随心所欲的感觉。所以经常遇到求职者吐槽遇到了…...

金三银四季节前端面试题复习来了
vue3和vue2的区别有哪些 Diff算法的改进Tree Sharing优化主要的API双向绑定改为es6的proxy原生支持tscomposition API移除令人头疼的this 说说CSS选择器以及这些选择器的优先级 !important 内联样式(1000) ID选择器(0100) 类选…...

【C/C++基础练习题】简单语法使用练习题
🍉内容专栏:【C/C要打好基础啊】 🍉本文内容:简单语法使用练习题(复习之前写过的实验报告) 🍉本文作者:Melon西西 🍉发布时间 :2023.2.10 目录 1、输入三个数…...

堆排序
章节目录:一、相关概述1.1 基本介绍1.2 排序思想二、基本应用2.1 步骤说明2.2 代码示例三、结束语一、相关概述 1.1 基本介绍 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序。它的最坏最好平均时间复杂度均为 O(nlogn)&#x…...
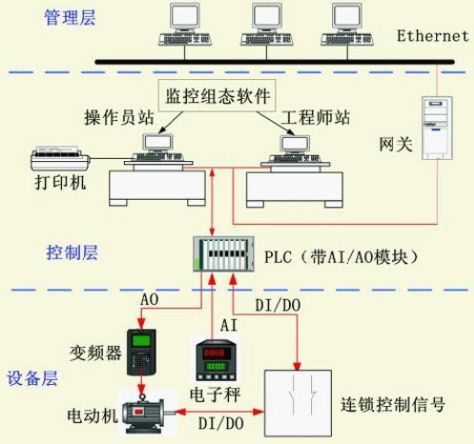
PLC是什么?PLC相关知识小科普
欢迎各位来到东用知识小课堂1.PLC是什么:●PLC就是可编程控制器,它应用于工业环境,必须具有很强的抗干扰能力、广泛的适应能力和应用范围。●PLC是“数字运算操作的电子系统”,也是一种计算机,它是“专为在工业环境下应…...

BERT简介
BERT: BERT预训练模型训练步骤: 使用Masked LM方式将语料库中的某一部分的词语掩盖住,模型通过上下文预测被掩盖的信息,从而训练出初步的语言模型在语料库中选出连续的上下语句,并使用Tranformer模块识别语句的连续性通…...
 | 部署Nova)
OpenStack云平台搭建(5) | 部署Nova
目录 1、登录数据库配置 2、安装nova 3、计算节点上安装nova 4、在controller节点上 nova组件是用来建虚拟机的(功能:负责响应虚拟机创建请求、调度、销毁云主机) nova主要组成: (1).nova api service------安装在controlle…...

【重要】2023年上半年有三AI新课程规划出炉,讲师持续招募中!
2023年正式起航,想必大家都已经完全投入到了工作状态中,有三AI平台今年将在已有内容的基础上,继续进行新课程开发,本次我们来介绍今年上半年的课程计划,以及新讲师招募计划。2023年新上线课程我们平台的课程当前分为两…...
【正点原子FPGA连载】第八章UART串口中断实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第八章UART串口中…...
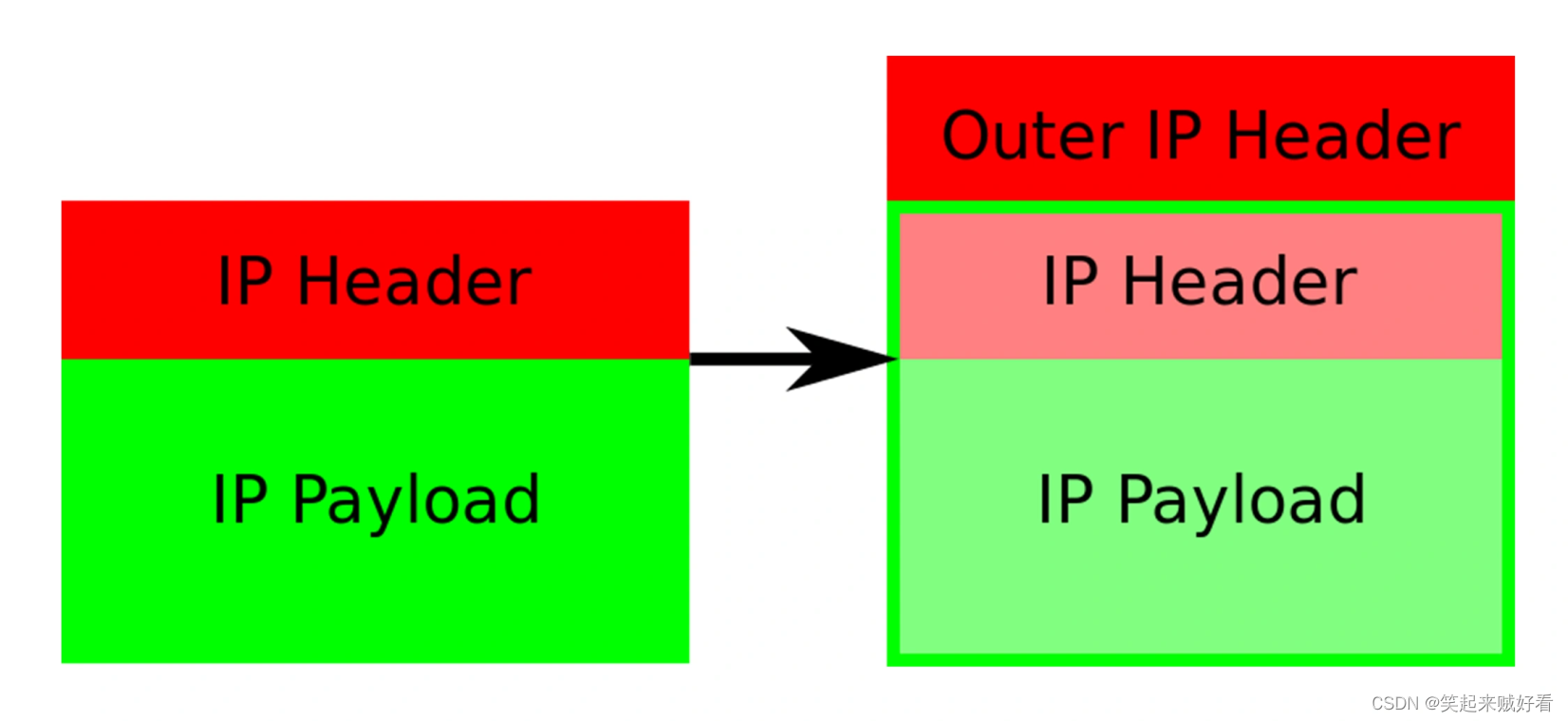
【云原生】解读Kubernetes三层网络方案
在上一篇文章中,我以网桥类型的 Flannel 插件为例,为你讲解了 Kubernetes 里容器网络和 CNI 插件的主要工作原理。不过,除了这种模式之外,还有一种纯三层(Pure Layer 3)网络方案非常值得你注意。其中的典型…...
elasticsearch8.3.2搭建部署
Elasticsearch8.3.2搭建部署详细步骤 0.过往文章 ES-6文章: Elasticsearch6.6.0部署、原理和使用介绍: https://blog.csdn.net/wt334502157/article/details/119515730 ES-7文章: Elasticsearch7.6.1部署、原理和使用介绍: https://blog.csdn.net/wt…...
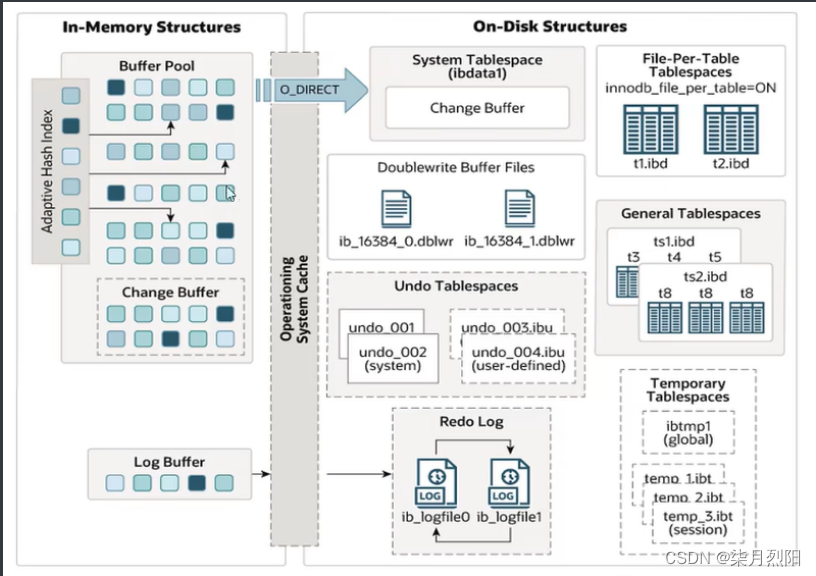
MySQL_InnoDB引擎
InnoDB引擎 逻辑存储结构 表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。 段,分为数据段(Leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollba…...
json-server使用
文章目录json-server使用简介安装json-server启动json-server操作创建数据库查询数据增加数据删除数据修改数据putpatch配置静态资源静态资源首页资源json-server使用 简介 github地址 安装json-server npm install -g json-server启动json-server json-server --watch db…...
)
实现mint操作(参考pancake)
区块链发展越来越好,nft已经火了很久,今天写一下如何用js、web3js、调用合约,实现mint nft。简单的调用://引入一些依赖 (根据需要,有一些是其他功能的) import useActiveWeb3React from ./web3…...

Illustrator批量替换实战指南:用ReplaceItems释放设计效率
Illustrator批量替换实战指南:用ReplaceItems释放设计效率 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是不是经常在Illustrator中遇到这样的场景:需要…...

Oracle RAC实战:5分钟搞懂SCAN IP和VIP的区别与配置技巧
Oracle RAC实战:SCAN IP与VIP的深度解析与高效配置指南 引言 在Oracle RAC(Real Application Clusters)环境中,高可用性和负载均衡是核心诉求。SCAN IP和VIP作为两大关键技术组件,常常让刚接触RAC的DBA感到困惑。它们虽…...

npm install 背后的依赖管理机制:为什么你的node_modules这么大?
npm install 背后的依赖管理机制:为什么你的node_modules这么大? 每次运行 npm install 后,看着飞速增长的 node_modules 文件夹,你是否曾好奇过这个"黑洞"究竟是如何形成的?今天我们就来揭开Node.js依赖管理…...
)
Java响应式编程实战:用Reactor 3.x处理高并发请求(附完整代码示例)
Java响应式编程实战:用Reactor 3.x处理高并发请求(附完整代码示例) 在当今高并发的互联网应用中,传统的同步阻塞式编程模型往往成为性能瓶颈。想象一下,当你的电商系统在秒杀活动中面临每秒数万次的请求时,…...

高效安全备份QQ空间历史说说:GetQzonehistory全方位使用指南
高效安全备份QQ空间历史说说:GetQzonehistory全方位使用指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 功能价值:为什么选择GetQzonehistory? …...

B2B企业获客技术瓶颈:矩阵跃动龙虾机器人+GEO,精准捕捉采购端搜索流量
在数字化转型深度渗透、AI技术全面重构行业逻辑的当下,B2B行业的获客模式已从传统粗放式的展会、电话陌拜,转向精细化、智能化、数据化的精准获客赛道。不同于C端流量的泛化传播,B2B采购决策链路长、决策人群集中(采购负责人、技术…...

用74ls10和74ls20与非门搭建四人表决器:从真值表到电路图的完整设计流程
用74LS10和74LS20与非门搭建四人表决器:从真值表到电路图的完整设计流程 在数字电路设计中,表决器是一个经典的教学案例,它不仅能帮助理解组合逻辑电路的基本原理,还能锻炼从理论到实践的完整设计能力。本文将手把手带你用74LS10…...
大模型Transformer架构学习
基础知识: 损失函数:梯度下降单次训练过程过拟合数据增强:增加训练数据,对原始数据加噪,翻转,旋转 正则化:防止该函数过分变化,让损失函数加上该参数,调整损失函数时会抑…...

如何在Java中使用Thread创建线程
在Java中使用Thread类创建线程是一种常见而直接的方式。你可以继承Thread类并重写其run()定义线程执行的任务的方法。当调用线程对象时start()JVM将为该线程分配资源并自动执行该方法run()方法中的代码。继承Thread类,重写run方法创建线程的第一步是定义一个类继承T…...
)
Python实战:温度转换小工具开发(附GESP考试真题解析)
Python实战:温度转换小工具开发与GESP考试技巧精讲 温度转换是编程入门阶段的经典案例,也是GESP考试中常见的题型。本文将从零开始构建一个功能完整的温度转换工具,同时深入解析GESP考试中可能遇到的类似题型,帮助初学者掌握Pytho…...