Elasticsearch备份与还原:使用elasticdump
在数据管理的世界里,备份和还原数据是重中之重的日常工作,特别是对于Elasticsearch这样的强大而复杂的搜索引擎。备份不仅可以用于灾难恢复,还可以在数据迁移、测试或者升级等场景中发挥重要作用。
在本博客中,我们将会重点介绍如何使用一个非常实用的工具——elasticdump——来对Elasticsearch数据进行备份和还原。我们会覆盖单索引备份还原,全部索引备份还原以及特定前缀索引的备份还原。
注:我的使用场景是从A集群同步数据到B集群迁移
Elasticdump 简介
Elasticdump是一个开源工具,它可以用于对Elasticsearch索引的数据和映射(mapping)进行导入、导出操作。Elasticdump工作在命令行接口,通过简单直观的指令集操作Elasticsearch的索引数据。
安装 Elasticdump
Elasticdump是一个基于Node.js的工具,因此首先你需要确保你的系统中安装有Node.js。然后,你可以使用以下npm命令安装Elasticdump:
npm install -g elasticdump
单索引备份与还原
下面,我们首先介绍如何对单个索引进行备份和还原:
备份单个索引
为了备份一个特定的索引,我们可以使用以下命令:
elasticdump \--input=http://localhost:9200/INDEX \--output=/path/to/output/INDEX.json \--type=data
这个命令将会将索引INDEX的数据导出到指定路径下的INDEX.json文件。
对于有账号密码的Elasticsearch实例,则可以使用以下脚本:
elasticdump \--input=http://user:passwd@localhost:9200/INDEX \--output=/path/to/output/INDEX.json \--type=data
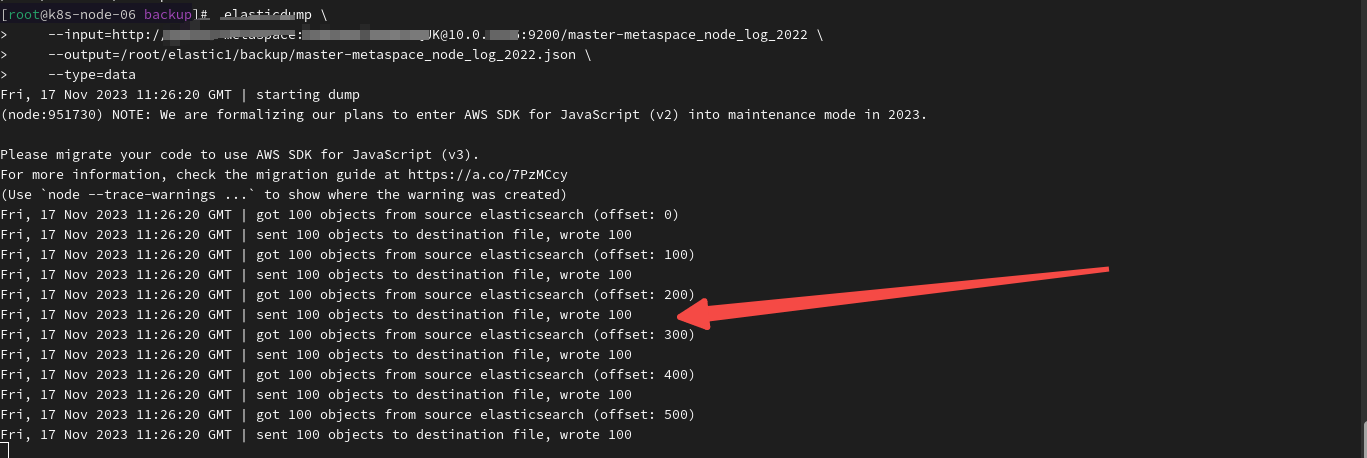
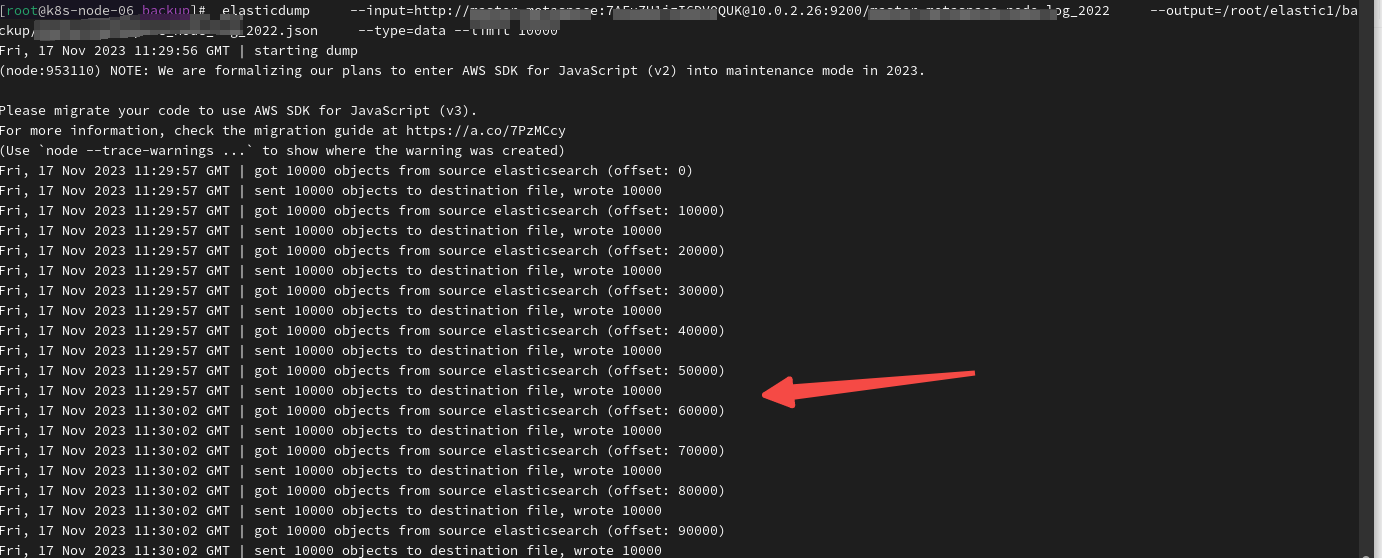
默认的速率是100条,可以通过limit 修改默认的导出数量:
elasticdump \--input=http://user:passwd@localhost:9200/INDEX \--output=/path/to/output/INDEX.json \--type=data --limit 10000
还原单个索引
相反,如果我们想从之前创建的备份中还原单个索引,可以使用以下命令:
elasticdump \--input=/path/to/output/INDEX.json \--output=http://localhost:9200/INDEX \--type=data --limit 10000
这将会将INDEX.json文件中的数据导入到Elasticsearch中的指定索引。
带账号密码的elasticsearch实例:
elasticdump \--input=/path/to/output/INDEX.json \--output=http://user:passwd@localhost:9200/INDEX \--type=data --limit 10000
所有索引备份与还原
备份所有索引
备份Elasticsearch中的所有索引可能需要一些额外的脚本,因为Elasticdump没有直接的方式来备份所有索引。以下是一个简单的bash脚本示例,用于备份所有索引:
#!/bin/bash
for index in $(curl -s http://localhost:9200/_cat/indices?h=index)
doelasticdump \--input=http://localhost:9200/${index} \--output=/path/to/output/${index}.json \--type=data
done
还原所有索引
还原所有索引通常涉及到遍历包含备份数据的文件,并将它们导入到相应的Elasticsearch索引中。这是一个简单的bash脚本示例,用于还原在一个文件夹中的所有索引备份:
#!/bin/bash
BACKUP_DIR="/path/to/backup/directory"
for backup_file in $(ls ${BACKUP_DIR}/*.json); doindex_name=$(basename ${backup_file} .json)elasticdump \--input=${backup_file} \--output=http://localhost:9200/${index_name} \--type=data
done
在这个脚本中,我们假设备份文件的名字与索引的名字相对应,备份文件的扩展名为.json,通过移除.json,我们获取了原始的索引名以便于还原。
匹配前缀索引备份与还原
匹配前缀索引备份
有时我们可能需要备份名称有共同前缀的多个索引。下面是一个通过前缀备份多个索引的bash脚本示例:
#!/bin/bash
PREFIX="INDEX"
for index in $(curl -s http://localhost:9200/_cat/indices?h=index | grep ^${PREFIX})
doelasticdump \--input=http://localhost:9200/${index} \--output=/path/to/output/${index}.json \--type=data
done
带账号密码的备份脚本:
#!/bin/bash# Elasticsearch的主机和认证信息
ELASTIC_HOST="xxxx:9200"
ELASTIC_USER="xxxx"
ELASTIC_PASS="xxxxx"# 要备份的索引的前缀
INDEX_PREFIX="xxxx"# 输出的备份目录
BACKUP_DIR="/root/elastic1/back2"# 获取所有以master开头的索引
INDICES=$(curl --silent --user $ELASTIC_USER:$ELASTIC_PASS \--request GET "http://$ELASTIC_HOST/_cat/indices/$INDEX_PREFIX*" | \awk '{ print $3 }')# 检查备份目录是否存在,如果不存在就创建它
mkdir -p "$BACKUP_DIR"# 逐个备份索引
for INDEX in $INDICES; doelasticdump \--input=http://$ELASTIC_USER:$ELASTIC_PASS@$ELASTIC_HOST/$INDEX \--output=$BACKUP_DIR/$INDEX.json \--type=data --limit 10000
done还原符合特定前缀的索引
如果只希望还原带有特定前缀的索引,您可以使用以下bash脚本作为参考:
#!/bin/bash
PREFIX="your_prefix_here"
BACKUP_DIR="/path/to/backup/directory"
for backup_file in $(ls ${BACKUP_DIR}/${PREFIX}*.json); doindex_name=$(basename ${backup_file} .json)elasticdump \--input=${backup_file} \--output=http://localhost:9200/${index_name} \--type=data
done
带密码的可以参考以下脚本(未实践,chatgpt生成,但是基本一眼扫过没有多大问题)
#!/bin/bash# 源 Elasticsearch 的主机和认证信息
SOURCE_ELASTIC_HOST="xxxx:9200"
SOURCE_ELASTIC_USER="xxxx"
SOURCE_ELASTIC_PASS="xxxxx"# 目标 Elasticsearch 的主机和认证信息
RESTORE_ELASTIC_HOST="yyyy:9200"
RESTORE_ELASTIC_USER="yyyy"
RESTORE_ELASTIC_PASS="yyyyy"# 要备份的索引的前缀 - 对于恢复来说不需要改变
INDEX_PREFIX="xxxx"# 输入的备份目录 - 同时用于备份和恢复
BACKUP_DIR="/root/elastic1/back2"# 获取所有以 INDEX_PREFIX 开头的索引备份文件
BACKUP_FILES=$(ls $BACKUP_DIR | grep "$INDEX_PREFIX")# 检查备份目录是否存在,并且是否有备份文件
if [ -z "$BACKUP_FILES" ]; thenecho "没有发现匹配前缀的备份文件, 请检查你的备份目录."exit 1
fi# 逐个恢复备份文件到新实例
for FILE in $BACKUP_FILES; doINDEX_NAME=$(basename $FILE .json)elasticdump \--input=$BACKUP_DIR/$FILE \--output=http://$RESTORE_ELASTIC_USER:$RESTORE_ELASTIC_PASS@$RESTORE_ELASTIC_HOST/$INDEX_NAME \--type=data --limit 10000# 可选: 如果你还想恢复 mapping 和 settings, 添加如下命令:# elasticdump \# --input=$BACKUP_DIR/$INDEX_NAME-mapping.json \# --output=http://$RESTORE_ELASTIC_USER:$RESTORE_ELASTIC_PASS@$RESTORE_ELASTIC_HOST/$INDEX_NAME \# --type=mapping# elasticdump \# --input=$BACKUP_DIR/$INDEX_NAME-settings.json \# --output=http://$RESTORE_ELASTIC_USER:$RESTORE_ELASTIC_PASS@$RESTORE_ELASTIC_HOST/$INDEX_NAME \# --type=settings
doneecho "恢复完成."
与还原所有索引的脚本类似,但这里通过限定文件路径 ${BACKUP_DIR}/${PREFIX}*.json 只选取带有特定前缀的备份文件。
值得注意的是,进行大规模数据还原时,可能会因为Elasticsearch集群的性能限制、配置或者网络条件等因素影响执行效率。建议优化Elasticsearch配置,并可能需要调整批次大小或者并发数来适应你的环境。
在还原环境之前,最好确保Elasticsearch集群处于健康状态并有足够的资源来处理数据恢复过程。这些脚本是简化版本,视具体环境可能需要进一步的优化和调整。请注意,在生产环境下执行脚本前务必进行充分测试。
其他备份实现方式
Elasticdump是实现Elasticsearch备份与还原的一种方式,但并不是唯一方式。以下列举了其他的一些方法:
- 使用Elasticsearch自带的Snapshot and Restore功能,可以创建索引的快照并存储在文件系统或者支持的云存储服务中;
- 使用Curator工具管理索引生命周期,包括创建和删除快照;
- 第三方服务和插件如Elastic Cloud的备份功能或者开源插件如Cerebro。
确保在实施任何备份策略之前,都应该先在非生产环境下进行测试,以保证恢复过程中数据的完整性和准确性。
通过Elasticdump,我们可以灵活高效地进行Elasticsearch的数据备份和还原,但始终记得选择适合自己业务场景和数据规模的备份方案。
值的注意的
- 以上备份还原主要实现了data的部分,mapping 和 settings正常来说也最好能备份一下!
- **multielasticdump **之前也尝试过,可以使用一下!
- 有没有增量同步的方式?貌似也可以通过logstash 这样的去做?还有企业版的ccr(Cross-Cluster Replication)?还有**INFINI **企业版的也可以?
- –limit 的添加可以增加一下备份还原的速度的!
注:以上博客基本chatgpt生成,大部分脚本代码没有问题,有问题的应该略微调试一下就可以了
相关文章:
Elasticsearch备份与还原:使用elasticdump
在数据管理的世界里,备份和还原数据是重中之重的日常工作,特别是对于Elasticsearch这样的强大而复杂的搜索引擎。备份不仅可以用于灾难恢复,还可以在数据迁移、测试或者升级等场景中发挥重要作用。 在本博客中,我们将会重点介绍如…...

给大伙讲个笑话:阿里云服务器开了安全组防火墙还是无法访问到服务
铺垫: 某天我在阿里云上买了一个服务器,买完我就通过MobaXterm进行了ssh(这个软件是会保存登录信息的) 故事开始: 过了n天之后我想用这个服务器来部署流媒体服务,咔咔两下就部署好了流媒体服务器&#x…...

js:react使用zustand实现状态管理
文档 https://www.npmjs.com/package/zustandhttps://github.com/pmndrs/zustandhttps://docs.pmnd.rs/zustand/getting-started/introduction 安装 npm install zustand示例 定义store store/index.js import { create } from "zustand";export const useCount…...
vue3+vite+SQL.js 读取db3文件数据
前言:好久没写博客了,最近一直在忙,没时间梳理。最近遇到一个需求是读取本地SQLite文件,还是花费了点时间才实现,没怎么看到vite方面写这个的文章,现在分享出来完整流程。 1.pnpm下载SQL.js(什么都可以下)…...
微信小程序 限制字数文本域框组件封装
微信小程序 限制字数文本域框 介绍:展示类组件 导入 在app.json或index.json中引入组件 "usingComponents": {"text-field":"/pages/components/text-field/index"}代码使用 <text-field maxlength"500" bindtabsIt…...
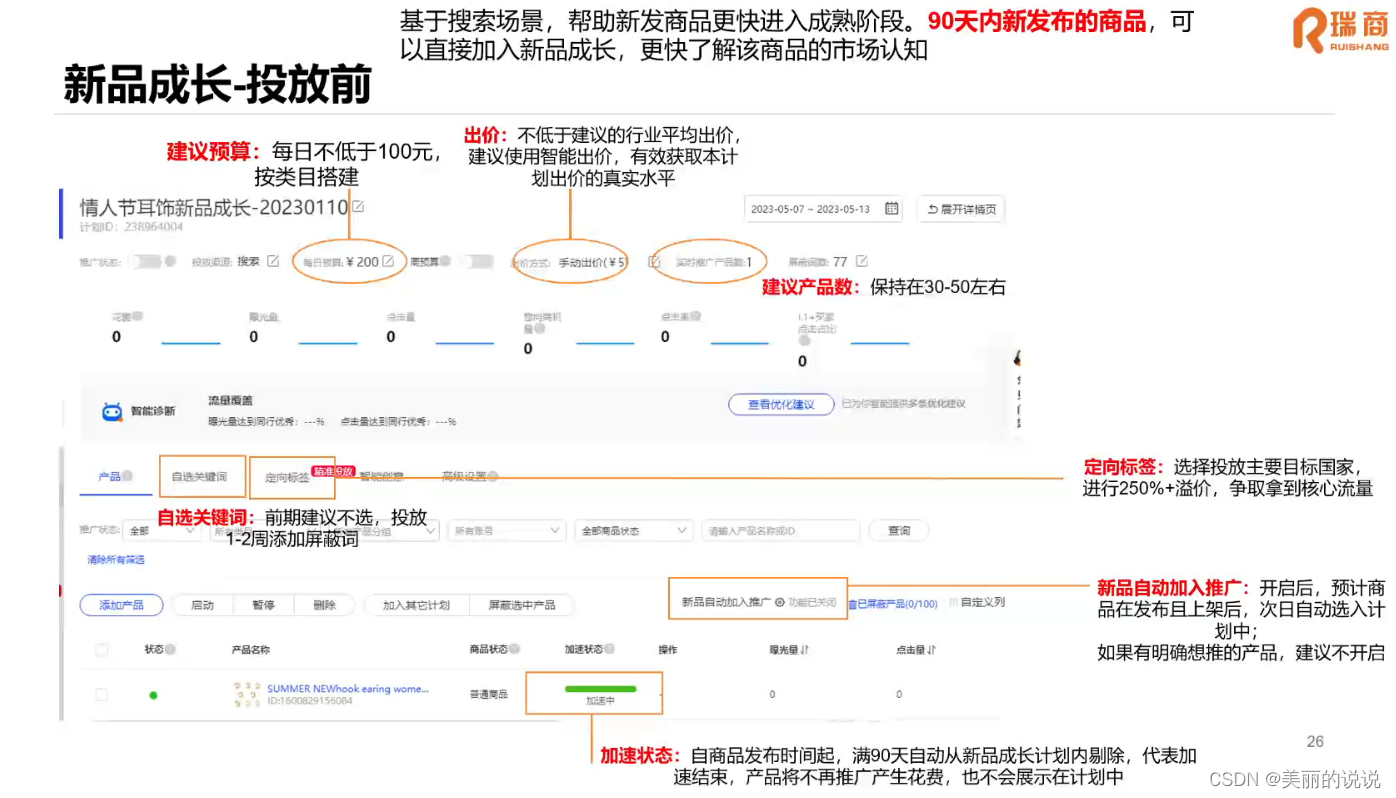
阿里国际站(直通车)
1.国际站流量 2.直通车即P4P(pay for performance点击付费) 2.1直通的含义:按点击付费,通过自助设置多维度展示产品信息,获得大量曝光吸引潜在买家。 注意:中国大陆和尼日利尼地区点击不扣费。 2.2扣费规…...

C# GC机制
在C#中,垃圾回收(Garbage Collection,简称GC)是CLR(公共语言运行时)的一个重要部分,用于自动管理内存。它会自动释放不再使用的对象所占用的内存,避免内存泄漏,减少程序员…...
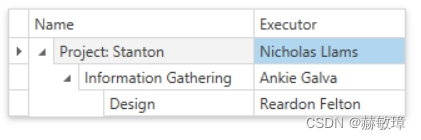
wpf devexpress在未束缚模式中生成Tree
TreeListControl 可以在未束缚模式中没有数据源时操作,这个教程示范如何在没有数据源时创建tree 在XAML生成tree 创建ProjectObject类实现数据对象显示在TreeListControl: public class ProjectObject {public string Name { get; set; }public string Executor {…...

Python利器:os与chardet读取多编码文件
在数据处理中会遇到读取位于不同位置的文件,每个文件所在的层级不同,而且每个文件的编码类型各不相同,那么如何高效地读取文件呢? 在读取文件时首先需要获取文件的位置信息,然后根据文件的编码类型来读取文件。本文将使用os获取文件路径,使用chardet得到文件编码类型。 …...

微服务和注册中心
微服务和注册中心是紧密相关的概念,可以说注册中心是微服务架构中必不可少的一部分。 在微服务架构中,系统被拆分成了若干个独立的服务,因此服务之间需要进行通信和协作。为了实现服务的发现和调用,需要一个中心化的注册中心来进…...
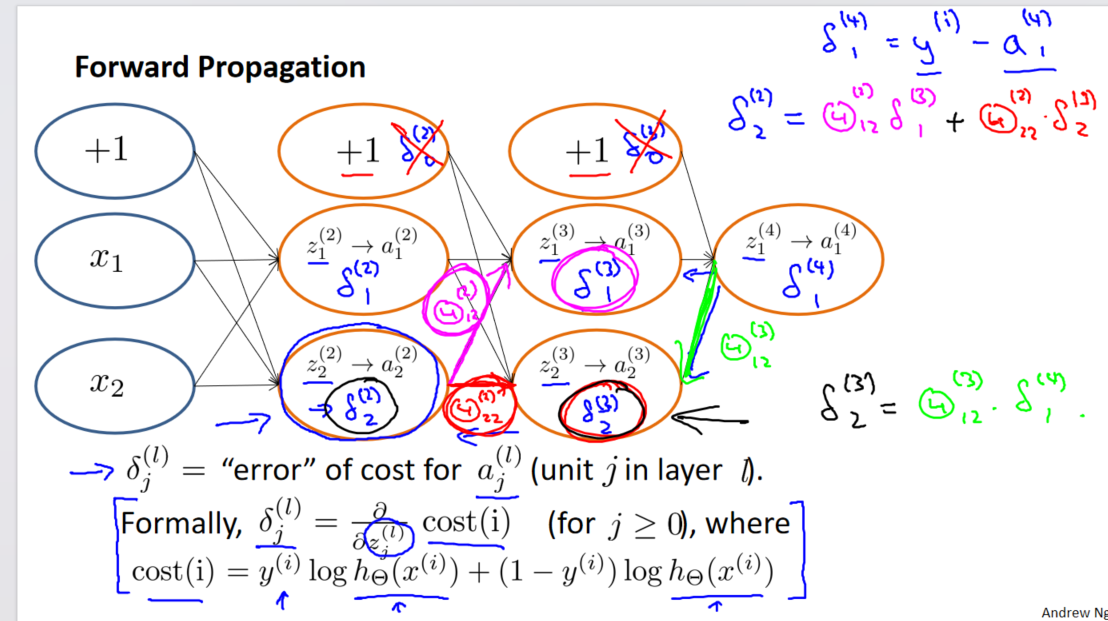
吴恩达《机器学习》9-1-9-3:反向传播算法、反向传播算法的直观理解
一、正向传播的基础 在正向传播中,从神经网络的输入层开始,通过一层一层的计算,最终得到输出层的预测结果。这是一种前向的计算过程,即从输入到输出的传播。 二、反向传播算法概述 反向传播算法是为了计算代价函数相对于模型参数…...
Java 算法篇-链表的经典算法:判断回文链表、判断环链表与寻找环入口节点(“龟兔赛跑“算法实现)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 链表的创建 2.0 判断回文链表说明 2.1 快慢指针方法 2.2 使用递归方式实现反转链表方法 2.3 实现判断回文链表 - 使用快慢指针与反转链表方法 3.0 判断环链表说明…...

【JS】Chapter13-构造函数数据常用函数
站在巨人的肩膀上 黑马程序员前端JavaScript入门到精通全套视频教程,javascript核心进阶ES6语法、API、js高级等基础知识和实战教程 (十三)构造函数&数据常用函数 1. 深入对象 1.1 创建对象三种方式 利用对象字面量创建对象const o {…...

06-流媒体-YUV数据在SDL控件显示
整体方案: 采集端:摄像头采集(YUV)->编码(YUV转H264)->写封装(H264转FLV)->RTMP推流 客户端:RTMP拉流->解封装(FLV转H264)…...

对象和数据结构
文章目录 前言一、从链式调用说起二、数据抽象三、数据、对象的反对称性四、得墨忒尔律五、数据传送对象总结 前言 代码整洁之道读书随笔,第六章 一、从链式调用说起 面向对象语言中常用的一种调用形式,链式调用,是一种较受推崇的编码风格&…...
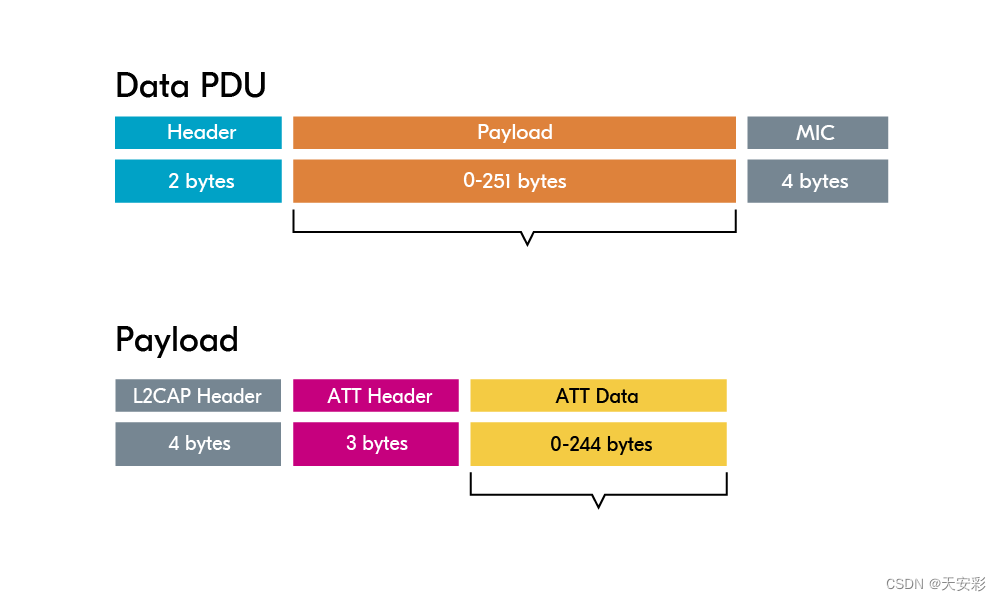
ESP32-BLE基础知识
一、存储模式 两种存储模式: 大端存储:低地址存高字节,如将0x1234存成[0x12,0x34]。小端存储:低地址存低字节,如将0x1234存成[0x34,0x12]。 一般来说,我们看到的一些字符串形式的数字都是大端存储形式&a…...
vscode终端npm install报错
报错如下: npm WARN read-shrinkwrap This version of npm is compatible with lockfileVersion1, but package-lock.json was generated for lockfileVersion2. Ill try to do my best with it! npm ERR! code EPERM npm ERR! syscall open npm ERR! errno -4048…...

雪花算法的使用
雪花算法的使用(工具类utils) import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component;// 雪花算法 Component public class SnowflakeUtils { // Generated ID: 1724603634882318341; // Generated ID: 1724603…...
-metrics)
flink源码分析之功能组件(一)-metrics
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metric,future。其中kubeclient上一个系列介绍过,本系列不在介绍。 本文介绍flink metrics组件,metric…...
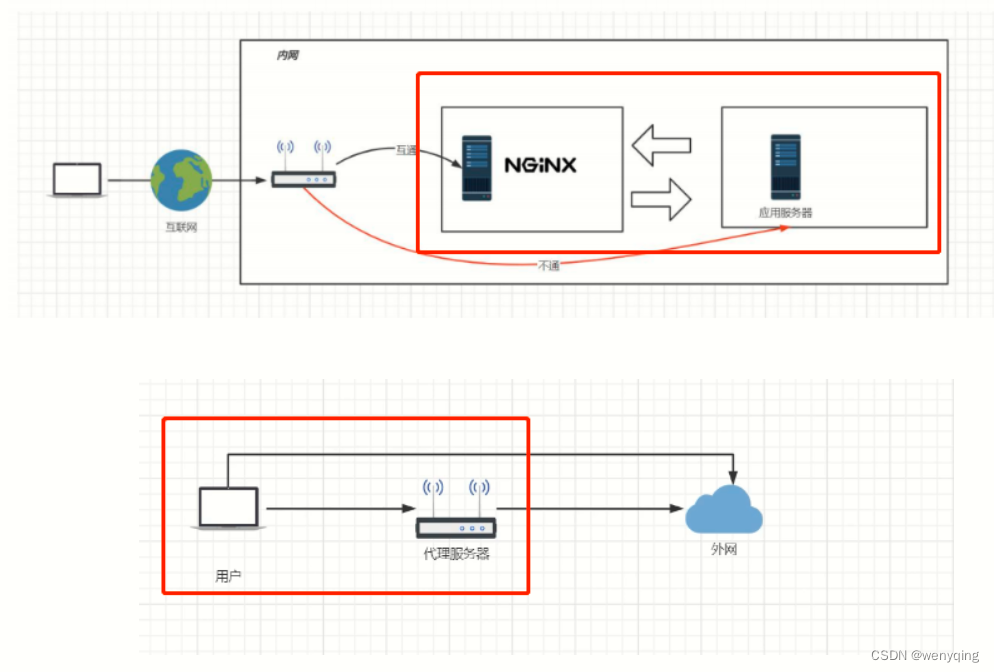
Nginx反向代理和负载均衡
1.反向代理 反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一…...
)
保姆级教程:用HWSD世界土壤数据库为SWAT模型快速搭建土壤库(附SPAW软件计算避坑指南)
从HWSD到SWAT:零基础构建高精度土壤数据库的完整指南 水文模型研究者常面临一个棘手问题:如何将全球土壤数据转化为模型可用的参数?HWSD(Harmonized World Soil Database)作为国际权威土壤数据库,与SWAT模…...

使用curl命令直接调试taotoken大模型api接口的详细方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型API接口的详细方法 对于需要在无SDK环境下进行底层调试、自动化脚本编写或快速验证接口的开发…...

Sora 2生成3分钟以上视频总卡顿、跳帧?:5步精准定位帧间语义断裂点并修复
更多请点击: https://codechina.net 第一章:Sora 2生成3分钟以上视频总卡顿、跳帧?:5步精准定位帧间语义断裂点并修复 长时序视频生成中,Sora 2 在输出超过180秒内容时频繁出现视觉跳变、运动不连贯及语义突兀中断&am…...

Nginx慢速HTTP攻击防护:超时配置与内核级加固实战
1. 这不是误报:当Nginx日志里反复出现“client timed out”时,你面对的已是真实攻击面“检测到目标主机可能存在缓慢的HTTP拒绝服务攻击”——这条告警在安全扫描报告里出现时,很多运维同学第一反应是:又一个误报。毕竟Nginx跑得稳…...
 深度解析:从架构原理到自动化实战)
Android Debug Bridge (adb) 深度解析:从架构原理到自动化实战
1. 项目概述:从“黑盒”到“白盒”的调试桥梁如果你是一名移动应用开发者、测试工程师,或者是一名热衷于折腾手机、平板的极客,那么“adb”这个词对你来说一定不陌生。它就像一把万能钥匙,静静地躺在你的开发工具目录里࿰…...

魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题
魔兽争霸3现代化修复指南:3步解决经典游戏兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还记得那个曾经风靡全球的《魔…...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

中兴光猫工厂模式解锁神器:zteOnu让你的网络管理权限瞬间升级
中兴光猫工厂模式解锁神器:zteOnu让你的网络管理权限瞬间升级 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾经想过,家里的中兴光猫其实隐藏着更多高级…...

TPU加速GAN训练:从Colab实操到混合精度调优
1. 项目概述:为什么在Kaggle/Colab上用TPU训GAN不是“炫技”,而是刚需你有没有试过在笔记本电脑上跑一个DCGAN,等了47分钟,loss曲线刚抖两下,风扇就发出濒死的哀鸣?或者在普通GPU上训StyleGAN2,…...

ncmdump终极指南:3步快速解密网易云音乐NCM格式,重获音乐掌控权
ncmdump终极指南:3步快速解密网易云音乐NCM格式,重获音乐掌控权 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐的NCM加密格式而烦恼?精心收藏的音乐只能在特定平台播放&…...