万字长文 - Python 日志记录器logging 百科全书 - 高级配置之 日志分层

万字长文 - Python 日志记录器logging 百科全书 - 高级配置之 日志分层
前言
在 Python 的logging模块中,它不仅提供了基础的日志功能,还拥有一系列高级配置选项来满足复杂应用的日志管理需求。
说到logging 模块的高级配置,必须提及日志分层、logging.config配置、日志异步操作等关键功能。它们每一项都为开发者提供了强大的调试和监控环境,对于构建可维护和高效的日志系统至关重要。
在接下来的三篇logging高级配置 文章中,我将为读者朋友们介绍 Python logging 模块中的三个高级配置的具体应用:日志分层、logging.config 以及 日志异步操作,探讨它们如何优化日志处理流程,并提升应用的整体性能。
本文将首先聚焦于 logging 模块中的日志分层概念,解析其如何使开发者能够构建具有层级结构的日志记录系统,并高效地管理和过滤日志信息。
知识点📖📖
| 模块 | 释义 |
|---|---|
logging | Python 的日志记录工具,标准库 |
logging.getLogger | 获取日志记录器实例 |
导入模块
import logging
import logging.handlers文章脉络:
- 点击直达:万字长文 - Python 日志记录器logging 百科全书 之 基础配置
- 点击直达:Python 日志记录器logging 百科全书 之 日志回滚
- 点击直达:万字长文 - Python 日志记录器logging 百科全书 之 日志过滤
- 点击直达:万字长文 - Python 日志记录器logging 百科全书 - 高级配置之 日志分层
理解日志分层
日志分层在管理复杂应用的日志中发挥着重要作用。
作用
日志分层在复杂应用程序中提供了高度的组织性和灵活性,允许针对不同模块或组件进行细致的日志管理,从而优化调试、维护效率,并增强整体日志系统的性能和可读性。
将 Python 的 logging 模块中的日志分层类比为 Python 中的类继承(父类和子类关系),这样可以有助于理解日志记录器(logger)之间的继承和行为传播机制。
-
继承:在类的继承中,子类继承父类的属性和方法。类似地,在日志分层中,子记录器会继承父记录器的配置,如日志级别和关联的处理器(handlers)。
-
重写和自定义:就像子类可以重写或扩展父类的方法和属性,子记录器也可以有自己的日志级别和处理器,甚至可以完全覆盖父记录器的设置。
-
层级关系:正如类可以有多层继承关系,日志记录器也可以形成层级结构,允许复杂和细致的控制。
-
传播行为:在类继承中,子类的行为可以反映父类的特征,而在日志分层中,日志消息的传播(默认情况下)会从子记录器向上到父记录器,除非显式地将
propagate属性设置为False。
需要注意的是,这只是一个比喻,实际的实现细节和概念上仍有区别。例如,类继承是面向对象编程中的一个核心概念,涉及到更广泛的编程模式,而日志分层主要是关于信息传递和处理的策略。
简单总结如下:
| 特性 | 主要作用与实现方式 | 备注 |
|---|---|---|
| 组织性 | 为每个模块或组件设置独立的子记录器 | 日志分层核心优势,提供清晰的日志结构 |
| 继承和覆盖 | 子记录器继承父记录器的配置,可根据需要覆盖 | 日志分层核心优势,提高配置灵活性 |
| 灵活性 | 为不同模块设置不同的日志级别 | 多日志处理器可实现,但日志分层的优势是更加结构化和直观 |
| 性能优化 | 控制哪些消息被记录,减少不必要的日志输出 | 多日志处理器可实现,但日志分层的优势是更加结构化和直观 |
| 问题追踪 | 快速定位大型应用中的问题所在模块 | 日志记录自带buff,但日志分层的优势在于它使得定位问题变得更加容易 |
疑惑
在学习了前面的 万字长文 - Python 日志记录器logging 百科全书 之 日志过滤 和 初步了解到日志分层的作用之后,可能会有读者朋友们有疑问:
?既然能够通过单个记录器和多处理器满足复杂日志需求的情况下,为什么还需要使用分层的日志记录器方法???
以下是我在深入了解日志分层 的作用之后的回答:
- 单个日志记录器配合多个处理器:在这种情况下,我们可以根据日志的类型(如错误、警告、信息等)将日志定向到不同的处理器(如文件、控制台等)。这种方法在应用结构相对简单,或者当日志需求主要围绕不同类型的日志处理时很有效。
- 使用分层多个日志记录器和处理器:这种方法允许按模块或组件分别记录日志。每个模块或组件可以有其自定义的日志级别和处理器。这种方式适用于更复杂的应用程序,其中不同部分可能有不同的日志需求。
分层日志在大型和复杂的应用程序中提供了更好的组织性和灵活性,使得对不同模块或组件的日志管理更加精细和高效。
应用场景
日志分层的应用场景主要体现在大型、多模块的应用程序和微服务架构中,以及多团队协作的开发项目里,它帮助各个模块独立地控制日志记录,简化问题追踪和调试,提高维护效率。
- 大型应用程序:在大型应用程序(如电子商务平台、企业级软件等)中,应用通常分为多个模块或组件。每个组件可以有自己的日志记录器,这些记录器可以根据组件的具体需求进行配置。
- 多团队开发:在多团队协作的项目中,每个团队可能负责应用的不同部分。日志分层允许每个团队为其负责的部分单独配置日志。
- 微服务架构:在微服务架构中,每个微服务可以配置自己的日志记录器。这样可以确保每个服务的日志信息都是独立和清晰的。
- 调试和维护:在应用程序的维护和调试过程中,可以针对出现问题的特定模块调整日志级别,从而获取更详细的日志信息。
- 统一基础配置:在一个复杂的应用中,各个组件可能有不同的日志需求。使用分层结构,可以在顶层记录器上定义通用的日志策略,然后根据需要为特定子记录器定制日志行为。这种方式使得日志系统更易于维护和更新。
日志分层的要点
命名规范和核心概念
以下内容来自官方文档:
getLogger() 返回对具有指定名称的记录器实例的引用(如果已提供),或者如果没有则返回 root 。名称是以句点分隔的层次结构。多次调用 getLogger()具有相同的名称将返回对同一记录器对象的引用。在分层列表中较低的记录器是列表中较高的记录器的子项。例如,给定一个名为 foo 的记录器,名称为 foo.bar 、 和 foo.bam 的记录器都是 foo 子项。
记录器具有 有效等级 的概念。如果未在记录器上显式设置级别,则使用其父记录器的级别作为其有效级别。如果父记录器没有明确的级别设置,则检查 其 父级。依此类推,搜索所有上级元素,直到找到明确设置的级别。根记录器始终具有明确的级别配置(默认情况下为 WARNING )。在决定是否处理事件时,记录器的有效级别用于确定事件是否传递给记录器相关的处理器。
子记录器将消息传播到与其父级记录器关联的处理器。因此,不必为应用程序使用的所有记录器定义和配置处理器。一般为顶级记录器配置处理器,再根据需要创建子记录器就足够了。(但是,你可以通过将记录器的 propagate 属性设置为 False 来关闭传播。)
我提炼如下,简要说明了关于日志分层中的日志记录器行为和层次结构的核心概念:
-
记录器实例引用:使用
getLogger()函数可以获取具有特定名称的记录器实例。如果使用相同的名称多次调用getLogger(),将返回同一个记录器对象的引用。 -
命名规范:记录器(logger)的名称通常遵循点号分隔的层级结构,类似于 Python 包和模块的命名方式。例如,
'foo.database'表示foo下的database子模块的记录器。 -
层级关系:记录器的层级结构通过命名来实现。在这个层级中,一个记录器可以是另一个记录器的子项。例如,如果有一个名为
'foo'的记录器,那么'foo.bar'和'foo.bar.baz'就是它的子记录器。 -
有效级别:如果调用
getLogger()时不提供名称,将返回根记录器。根记录器是所有记录器的最顶层父记录器,它的默认级别为WARNING。 -
消息传播:子记录器的日志消息会传播到其父记录器的处理器,除非设置了
propagate属性为False。通常只需为顶级记录器配置处理器,子记录器可以继承这些处理器。
这种层级结构和命名规范为大型和复杂的应用程序提供了一种高效和灵活的日志管理方式。通过恰当地命名和配置记录器,可以轻松地管理应用程序的不同部分所生成的日志,确保日志信息的清晰和有序。
命名不规范的问题
在 Python 的 logging 模块中,如果顶级日志记录器的命名与子记录器的命名不遵循统一的层级结构,会出现以下几个问题:
- 继承失效:日志记录器之间的层级关系是通过它们的命名来确定的。如果顶级记录器和子记录器的命名不遵循统一的层级前缀,子记录器将无法正确继承顶级记录器的配置(如处理器、级别等)。这意味着我们需要为每个子记录器单独配置处理器和其他设置,增加了配置复杂性。
- 日志传播问题:通常,日志消息会从子记录器传播到父记录器。如果子记录器的命名不遵循正确的层级结构,这种传播可能无法发生,导致日志消息不会被预期的父记录器(和其关联的处理器)处理。
- 可维护性和可读性降低:在大型项目中,清晰和一致的日志记录器命名极为重要。不遵循统一的命名规范会使代码难以理解和维护,特别是在涉及多个开发者和模块的情况下。
为了避免这些问题,所以需要使用一致的层级命名约定。例如,顶级日志记录器命名为 'foo',那么子记录器应该以 'foo.' 作为前缀,如 'foo.bar'、'foo.baz' 等,以确保正确的继承和日志消息传播。
什么时候使用 propagate
可能会有读者朋友们有疑问:
?既然设置
logger.propagate = False,那为什么还需要使用日志分层呢? 一开就使用 非日志封层的logger不是更合适吗?
其实要回答这个疑问,就应该重新审视日志分层的作用和应用场景,以及为什么即使在某些情况下禁用了传播,日志分层仍然是有价值的。
使用 logger.propagate = False 的情况,
-
避免重复日志记录:当在不希望某个子记录器(logger)的日志被其父记录器也处理时。例如,当已经为子记录器配置了特定的处理器(handler)并且不希望同样的日志消息再次由更高级别的记录器处理,这时设置
propagate = False可以防止日志消息向上传播。 -
特定日志处理:当我们希望对某个模块或组件的日志进行特殊处理,与应用程序的其他部分区别开来。例如,我们可能有一个记录安全相关日志的记录器,我们不希望这些日志被常规的应用程序日志处理器处理。
-
独立日志流:在构建库或框架时,可能希望库的日志独立于使用该库的应用程序的日志系统。在这种情况下,可以为库设置一个专用的记录器,并设置
propagate = False,以防止库的日志消息污染或干扰主应用程序的日志。 -
性能考虑:在一些性能敏感的应用中,防止不必要的日志传播可以减少一些处理开销,特别是当有大量的日志消息和复杂的日志处理器配置时。
即使在上面的这些情况下,分层结构依然有助于维护清晰的组织架构。我们可以为特定的模块创建专用的子记录器,给予它独立的处理器和格式化器,而不必在每个模块中创建和配置新的独立记录器。
示例代码
这里是一份能用的伪代码,用于帮助读者朋友们更好的理解
日志分层的具体应用。
代码:
# -*- coding: utf-8 -*-import logging
import logging.handlers
import sysimport requests# 全局基础配置, 日志格式化配置
formatter = logging.Formatter('%(levelname)-7s - %(asctime)s - %(name)s - %(message)s')class RemoteLogHandler(logging.Handler):"""自定义远程处理器"""def __init__(self, remote_url, logger):super().__init__()self.remote_url = remote_urlself.error_logger = loggerself.setFormatter(formatter)def emit(self, record):# 发送日志记录到远程服务器log_entry = self.format(record) # 格式化日志记录try:response = requests.post(self.remote_url, data=log_entry)response.raise_for_status()except Exception as e:record.msg = f"Original message: {record.msg}, Failed to send log to remote: {str(e)}"print('error_logger 等级是 ', self.error_logger.level)self.error_logger.handle(record)def setup_logger(*handlers, name, level=logging.INFO):"""用于设置特定记录器的函数,支持多个处理器.Args:*handlers(logging.Handler): 日志处理器name(str): 日志记录器名称level(int): 日志等级Returns:日志记录器."""logger = logging.getLogger(name)logger.setLevel(level)for handler in handlers:handler.setFormatter(formatter)logger.addHandler(handler)return loggerdef setup_file_handler(filename, level=logging.DEBUG):"""setup file handlerArgs:filename(str): 日志文件的名称level(int): 日志处理器的级别, 默认为logging.DEBUGReturns:"""file_handler = logging.FileHandler(filename=filename, delay=True)file_handler.setLevel(level=level)file_handler.setFormatter(formatter)return file_handlerdef setup_stream_handler(stream=sys.stdout, level=logging.INFO):stream_handler = logging.StreamHandler(stream=stream)stream_handler.setLevel(level=level)stream_handler.setFormatter(formatter)return stream_handlerdef create_remote_log_handler(url, logger, level=logging.INFO):remote_handler = RemoteLogHandler(url, logger)remote_handler.setLevel(level=level)remote_handler.setFormatter(formatter)return remote_handlerif __name__ == '__main__':# 顶层日志记录器# 处理器配置, 文件处理器 和 控制台处理器file_handler_global = setup_file_handler(filename='ecommerce_global.log')stream_handler_global = setup_stream_handler(stream=sys.stdout)global_logger = setup_logger(file_handler_global, stream_handler_global, name='ecommerce', level=logging.DEBUG)# 创建错误记录器和处理器error_file_handler = setup_file_handler(filename='error.log', level=logging.ERROR)error_logger = setup_logger(error_file_handler, name='error', level=logging.WARNING)# 实例化RemoteLogHandlerremote_handler_global = create_remote_log_handler(url='http://127.0.0.1:5000/submit_log', logger=error_logger, level=logging.ERROR)# 订单处理系统记录器和处理器order_file_handler = setup_file_handler('orders.log', level=logging.WARNING)order_logger = setup_logger(order_file_handler, remote_handler_global, name='ecommerce.orders', level=logging.INFO)# 支付系统记录器和处理器payment_file_handler = setup_file_handler(filename='payments.log', level=logging.ERROR)payment_logger = setup_logger(payment_file_handler, remote_handler_global, name='ecommerce.payments', level=logging.WARNING)## 测试打印日志global_logger.info('Global logger configured')order_logger.warning('Order logger configured')payment_logger.error('Payment logger configured')运行效果
如果程序没有出错的话,可以看到会创建orders.log, payments.log和 ecommerce_global.log 三份日志文件,内容分别如下所示:
- 可以看到
ecommerce_global.log文件,打印的日志是包含orders.log和payments.log的。

使用propagate
添加以下两行代码,
- 设置子记录器的日志消息不传播到父记录器
order_logger.propagate = False
payment_logger.propagate = False
再次运行结果如下:
- 可以看到没有重复日志记录啦。

代码释义
这份代码是一个复杂的日志系统的实现,适用于需要将日志信息记录到不同位置(如文件、控制台、远程服务器)的应用程序。展示了如何在 Python 中使用 logging 模块来创建一个分层且灵活的日志处理架构。
-
自定义远程日志处理器 (
RemoteLogHandler):- 定义了一个自定义的日志处理器,用于将日志消息发送到远程服务器。
- 如果发送失败,它会使用另一个配置的日志记录器(
error_logger)来处理这些日志消息。
-
灵活的日志配置函数:
- 提供了多个辅助函数(
setup_logger,setup_file_handler,setup_stream_handler,create_remote_log_handler),使得创建和配置日志记录器和处理器更加灵活和简洁。
- 提供了多个辅助函数(
-
分层日志记录器:
- 创建了多个日志记录器,每个记录器代表应用程序的不同部分(如全局、订单处理系统、支付系统)。
- 每个记录器可以有自己的处理器和日志级别。
日志分层的体现
-
不同功能的日志记录器:
global_logger用于全局日志记录。order_logger专门用于订单处理系统的日志。payment_logger专门用于支付系统的日志。
-
层级命名:
- 日志记录器的命名体现了应用程序的层级结构。例如,
ecommerce.orders和ecommerce.payments表示这些记录器是ecommerce的子模块。
- 日志记录器的命名体现了应用程序的层级结构。例如,
-
日志传播:
- 在这个例子中,如果
propagate属性没有被设置为False,那么日志消息会从子记录器传播到父记录器。这意味着order_logger和payment_logger的日志也可能被global_logger所处理,除非显式地关闭了传播。
- 在这个例子中,如果
实际应用
这个日志系统适用于大型或模块化的应用程序,其中需要对不同部分的日志进行精细控制。通过这种方法,我们可以确保不同部分的日志被适当地记录和处理,同时保持日志系统的整洁和可维护性。这对于故障排查、性能监控和安全分析等方面非常有用。
总体来说,这个代码示例展示了一个结构化的日志系统,它既灵活又能够适应不同的日志需求,非常适合复杂的应用场景。
总结🎈🎈
本文详细介绍了 Python logging 模块中的日志分层功能,强调了其在构建复杂应用程序中的重要性。以下是文章的主要要点总结:
- 日志分层的作用与优势:
- 提高组织性:允许开发者为不同模块或组件设置独立的子记录器。
- 继承与覆盖:子记录器可以继承父记录器的配置,同时具备自定义设置的能力。
- 易于问题追踪:通过层级结构,方便快速定位问题所在模块。
- 命名规范与层级关系:
- 通过点号分隔的命名规范,确保记录器之间的层级关系清晰明确。
- 层级结构提供了继承和消息传播的机制,简化了配置并增加了灵活性。
- 传播行为与性能优化:
- 默认情况下,子记录器的日志会传播到父记录器,可通过设置
propagate属性进行控制。 - 正确使用日志分层可以减少不必要的日志输出,从而优化性能。
- 默认情况下,子记录器的日志会传播到父记录器,可通过设置
- 应用场景:
- 日志分层特别适用于大型、多模块应用程序和微服务架构。
- 有助于多团队协作的项目中的日志管理和维护。
- 实用代码示例:
- 文章通过实际代码展示了如何设置和使用分层日志记录器。
- 包括自定义处理器和日志记录器的配置方法,增强了文章的实用性和可操作性。
总体来说,这篇文章为理解和应用 Python 的 logging 模块提供了深入的指导,特别是在构建需要细粒度日志管理的复杂应用时。文章的结构清晰,通过逐步深入的方式,使得读者朋友容易跟进和理解。
后话
本次分享到此结束,
see you~~🏹🏹
相关文章:
万字长文 - Python 日志记录器logging 百科全书 - 高级配置之 日志分层
万字长文 - Python 日志记录器logging 百科全书 - 高级配置之 日志分层 前言 在 Python 的logging模块中,它不仅提供了基础的日志功能,还拥有一系列高级配置选项来满足复杂应用的日志管理需求。 说到logging 模块的高级配置,必须提及日志分…...
工作记录---为什么双11当天不能申请退款?(有趣~)
为什么? 服务降级了 服务降级: 当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。 分布式系统的降级…...

ElasticSearch在Windows上的下载与安装
Elasticsearch是一个开源的分布式搜索和分析引擎,它可以帮助我们快速地搜索、分析和处理大量数据。Elasticsearch能够快速地处理结构化和非结构化数据,支持全文检索、地理位置搜索、自动补全、聚合分析等功能,能够承载各种类型的应用…...

软件测试/测试开发/人工智能丨基于Spark的分布式造数工具:加速大规模测试数据构建
随着软件开发规模的扩大,测试数据的构建变得越来越复杂,传统的造数方法难以应对大规模数据需求。本文将介绍如何使用Apache Spark构建分布式造数工具,以提升测试数据构建的效率和规模。 为什么选择Spark? 分布式计算:…...
ClickHouse的 MaterializeMySQL引擎
1 概述 MySQL 的用户群体很大,为了能够增强数据的实时性,很多解决方案会利用 binlog 将数据写入到 ClickHouse。为了能够监听 binlog 事件,我们需要用到类似 canal 这样的第三方中间件,这无疑增加了系统的复杂度。 ClickHouse 20.…...
Ubuntu 22.04安装Rust编译环境并且测试
我参考的博客是《Rust使用国内Crates 源、 rustup源 |字节跳动新的 Rust 镜像源以及安装rust》 lsb_release -r看到操作系统版本是22.04,uname -r看到内核版本是uname -r。 sudo apt install -y gcc先安装gcc,要是结果给我的一样的话,那么就是安装好了…...
制作Go程序的Docker容器(以及容器和主机的网络问题)
今天突然遇到需要将 Go 程序制作成 Docker 的需求,所以进行了一些研究。方法很简单,但是官方文档和教程有些需要注意的地方,所以写本文进行记录。 源程序 首先介绍一下示例程序,示例程序是一个 HTTP 服务器,会显示si…...

mysql清除数据痕迹_MySQL使用痕迹清理~/.mysql_history - milantgh
mysql会给出我们最近执行的SQL命令和脚本;同linux command保存在~/.bash_history一样,你用mysql连接MySQL server的所有操作也会被记录到~/.mysql_history文件中,这样就会有很大的安全风险了,如添加MySQL用户的sql也同样会被明文记…...
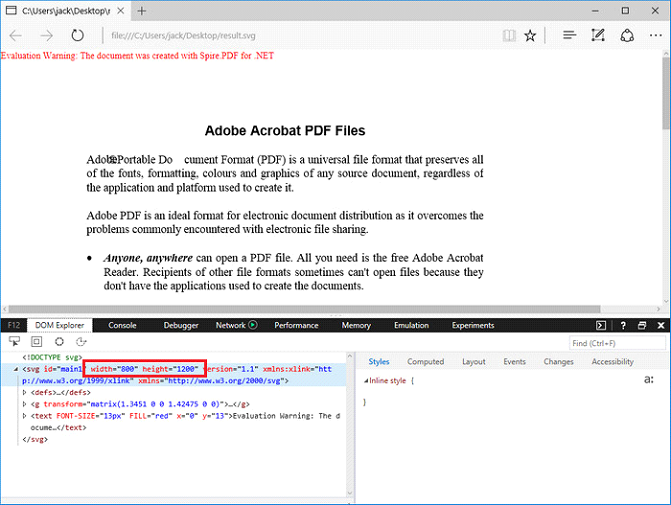
PDF控件Spire.PDF for .NET【转换】演示:自定义宽度、高度将 PDF 转 SVG
我们在上一篇文章中演示了如何将 PDF 页面转换为 SVG 文件格式。本指南向您展示如何使用最新版本的 Spire.PDF 以及 C# 和 VB.NET 指定输出文件的宽度和高度。 Spire.Doc 是一款专门对 Word 文档进行操作的 类库。在于帮助开发人员无需安装 Microsoft Word情况下,轻…...

01背包 P1507 NASA的食物计划
P1507 NASA的食物计划 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 普通01背包状态表示:f(i, j)表示前i件物品放入一个容量为j的背包可以获得的最大价值。 本题类似,f(i, j, k)表示前i件物品放入一个限制为j,且另一个限制为k的背包中可以…...

平衡二叉树c语言版
一、定义二叉树结点结构体 /*** 定义平衡二叉树结点 */ struct avlbinarytree { //数据域NodeData* data;///树高int h;struct avlbinarytree* left;struct avlbinarytree* right; }; typedef struct avlbinarytree AVLNode; 二、声明函数的操作 /*** 创建结点 */ AV…...
初始环境配置
目录 一、JDK1、简介2、配置步骤 二、Redis1、简介2、配置步骤 三、MySQL1、简介2、配置步骤 四、Git1、简介2、配置步骤 五、NodeJS1、简介2、配置步骤 六、Maven1、简介2、配置步骤 七、Tomcat1、简介2、配置步骤 一、JDK 1、简介 JDK 是 Oracle 提供的 Java 开发工具包&…...

记GitLab服务器迁移后SSH访问无法生效的问题解决过程
公司IT心血来潮对GitLab服务器进行安全升级,升级后无法启动。。。只得启用备用服务器,具体的备份机制不祥,只知道原数据都在,但文件系统是否完全一样不清楚。切换为备用服务器后使用SSH下载代码死活不成功,反复提示需要…...

【NGINX--2】高性能负载均衡
1、HTTP 负载均衡 将负载分发到两台或多台 HTTP 服务器。 在 NGINX 的 HTTP 模块内使用 upstream 代码块对 HTTP 服务器实施负载均衡: upstream backend {server 10.10.12.45:80 weight1;server app.example.com:80 weight2;server spare.example.com:80 backup; …...
Android studio run 手机或者模拟器安装失败,但是生成了debug.apk
错误信息如下:Error Installation did not succeed. The application could not be installed:List of apks 出现中文乱码; 我首先尝试了打包,能正常安装,再次尝试了debug的安装包,也正常安装࿱…...

【面试经典150 | 数学】加一
文章目录 写在前面Tag题目来源解题思路方法一:加一 其他语言python3 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主,并附带一些对于本题涉及到的数据结…...

Rust unix domain socket
先用起来再说 use std::io::prelude::*; use std::os::unix::net::UnixStream;fn main() {let mut stream: UnixStream;let mut buffer vec![0u8; 4096];match UnixStream::connect("/tmp/hello.world.serv") {Ok(handle) > {stream handle;match stream.write_…...
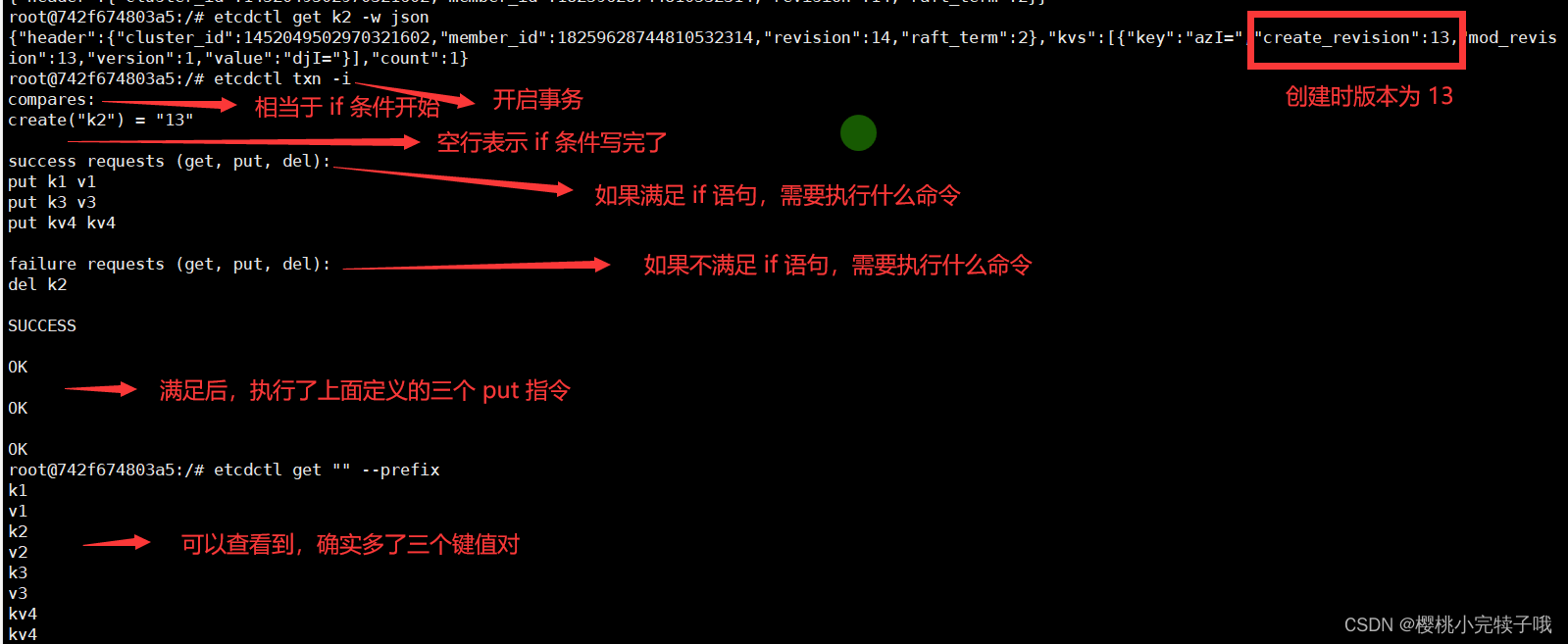
初识分布式键值对存储etcd
欢迎大家到我的博客浏览。胤凯 (oyto.github.io)大家好,今天我带大家来学习一下 etcd。 一、什么是 etcd etcd 是一个开源的分布式键值存储系统,主要用于构建分布式系统中那点服务发现、配置管理、分布式锁等场景。它采用 Raft 一致性算法来确保所有节…...

docker swarm集群部署
文章目录 前言一、安装docker1.1 解压1.2 配置docker 存储目录和dns1.3 添加docker.service文件1.4 docker 启动验证 二、docker swarm 集群配置2.1 关闭selinux2.2 设置主机名称并加入/etc/hosts2.3 修改各个服务器名称(uname -a 进行验证)2.4 初始化sw…...

MySQL进阶_9.事务基础知识
文章目录 第一节、数据库事务概述1.1、基本概念1.2、事务的ACID特性 第二节、如何使用事务 第一节、数据库事务概述 1.1、基本概念 事务 一组逻辑操作单元,使数据从一种状态变换到另一种状态。事务处理的原则 保证所有事务都作为 一个工作单元 来执行,…...

LaTeX公式一键转Word:告别繁琐复制,提升学术写作效率
LaTeX公式一键转Word:告别繁琐复制,提升学术写作效率 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为将网页上的数…...

从脚本运维到AI自治运维,全链路可观测性重构,SITS 2026标准下9类典型故障自动根因定位率突破91.7%
更多请点击: https://intelliparadigm.com 第一章:AI原生DevOps:SITS 2026开发运维一体化新范式 AI原生DevOps并非传统CI/CD管道的简单增强,而是以大模型驱动的智能体(Agent)为核心,重构软件交…...

英文论文降AI教程:从97%到8%,2026实测的4种文本结构级优化方法
大家最近都在为英文降aigc率发愁吧,作为研三党,我太懂这种痛了,之前我自己写英文初稿,写完直接拿去查重,结果turnitin检测ai率飙到了89%,当时看着报告整个人都懵了。 怎么给英文降ai?对于非母语…...

写了三年CRUD我觉得自己废了,直到产品经理说了一句话
2024年秋天,我在工位上改一个按钮的颜色。从#1890FF改成#4096FF,产品经理说原来的颜色「太老气了」。改完之后,我盯着屏幕发了十分钟的呆。不是因为这个需求有多难,而是我突然意识到,这是我今天写的第四个CSS微调了。上…...
Transmission密码安全加固:从配置文件到命令行实战
1. Transmission密码安全加固的必要性 最近在帮朋友排查一个奇怪的网络问题时,意外发现他路由器上的Transmission客户端竟然还在使用默认密码。这让我惊出一身冷汗——这相当于把家门钥匙插在门锁上啊!作为一款广泛使用的BT客户端,Transmiss…...

Void Memory:为AI智能体构建持久记忆的轻量级解决方案
1. 项目概述:为AI智能体构建持久记忆的“记忆锚”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手并肩作战,一定对那个令人沮丧的瞬间不陌生:你花了半小时向它详细解释了一个复杂项目的架构、你的编码偏好、刚刚踩过的坑…...

Groundhog:基于Git仓库的开发者时间自动追踪工具
1. 项目概述:一个面向开发者的时间管理利器如果你是一名开发者,或者你的工作与代码、项目、任务紧密相关,那么你一定对“时间都去哪儿了”这个问题深有感触。我们每天在各种编辑器、终端、浏览器标签页之间切换,处理着功能开发、B…...

别再傻傻切片了!PyTorch Tensor高级索引实战:用index_select、masked_select和gather提升数据处理效率
别再傻傻切片了!PyTorch Tensor高级索引实战:用index_select、masked_select和gather提升数据处理效率 在深度学习项目的日常开发中,数据处理环节往往占据了开发者大量的时间和精力。许多PyTorch用户习惯性地使用基础切片操作来处理Tensor数据…...

网盘直链下载助手完整教程:告别限速,解锁九大网盘真实下载链接
网盘直链下载助手完整教程:告别限速,解锁九大网盘真实下载链接 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / …...

OpenHarmony.Avalonia 归档事件对中国自主软件生态的影响--信任的坍塌与生态的异化
026年5月8日,中国开源技术社区发生了一起具有里程碑意义的争议性事件:由开发者“布布”(Bubu)主导的 OpenHarmony-NET/OpenHarmony.Avalonia 项目正式宣告停止更新并进入归档状态。这一决定不仅标志着一个由民间力量驱动的底层基础…...