spider 网页爬虫中的 AWS 实例数据获取问题及解决方案

前言
AAWS实例数据对于自动化任务、监控、日志记录和资源管理非常重要。开发人员和运维人员可以通过AWS提供的API和控制台访问和管理这些数据,以便更好地管理和维护他们在AWS云上运行的实例。然而,在使用 spider 框架进行网页爬取时,我们常常会面临一些技术挑战,特别是当我们尝试获取 AWS 实例数据时。本文将探讨在 spider 网页爬虫中可能遇到的 AWS 实例数据获取问题,并提供解决方案,以确保爬虫的顺利运行。
报错示例
使用 spider 框架进行网页爬取时,可能会遇到如下的错误信息:
2017-05-31 22:00:38 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2017-05-31 22:00:38 [scrapy] INFO: Optional features available: ssl, http11, boto
2017-05-31 22:00:38 [scrapy] INFO: Overridden settings: {}
2017-05-31 22:00:38 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2017-05-31 22:00:38 [boto] DEBUG: Retrieving credentials from metadata server.
2017-05-31 22:00:39 [boto] ERROR: Caught exception reading instance data
Traceback (most recent call last):File "/usr/lib/python2.7/dist-packages/boto/utils.py", line 210, in retry_urlr = opener.open(req, timeout=timeout)File "/usr/lib/python2.7/urllib2.py", line 429, in openresponse = this._open(req, data)File "/usr/lib/python2.7/urllib2.py", line 447, in _open'_open', req)File "/usr/lib/python2.7/urllib2.py", line 407, in _call_chainresult = func(*args)File "/usr/lib/python2.7/urllib2.py", line 1228, in http_openreturn this.do_open(httplib.HTTPConnection, req)File "/usr/lib/python2.7/urllib2.py", line 1198, in do_openraise URLError(err)
URLError: <urlopen error timed out>
2017-05-31 22:00:39 [boto] ERROR: Unable to read instance data, giving up
2017-05-31 22:00:39 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2017-05-31 22:00:39 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2017-05-31 22:00:39 [scrapy] INFO: Enabled item pi这个问题的出现主要是由于 spider 框架在使用 Boto 库获取 AWS 实例数据时,出现了错误。具体来说,由于网络问题导致超时, spider 无法获取 AWS 实例数据,从而无法进行后续的网页爬取操作。
解决方案
对于这个问题,我们可以采取以下的解决方案:
1. 检查网络连接
首先,我们需要检查本地的网络连接是否正常。如果本地的网络连接存在问题,那么 spider 在获取 AWS 实例数据时,就可能出现超时或者无法获取数据的情况。因此,我们需要确保本地的网络连接是正常的。
2. 调整超时时间
如果网络连接没有问题,那么我们需要考虑调整 spider 的超时时间。在 spider 中,可以通过修改 settings.py 文件中的 DOWNLOAD_TIMEOUT 和 HTTP_TIMEOUT 参数,来调整超时时间。一般来说,我们应该将这两个参数的值设置得较大,以防止 spider 在获取 AWS 实例数据时,由于网络问题,导致超时。
在 spider 的 settings.py 文件中,可以添加如下配置:
DOWNLOAD_TIMEOUT = 60 # 设置下载超时时间为60秒
HTTP_TIMEOUT = 60 # 设置HTTP请求超时时间为60秒这样可以确保 spider 在获取数据时有足够的时间来完成操作。
3. 使用代理服务器
如果网络连接和超时时间都没有问题,那么我们需要考虑使用代理服务器。通过使用代理服务器,我们可以避免直接访问 AWS 实例数据,从而避免出现超时的情况。在 spider 中,可以通过修改 settings.py 文件中的 HTTP_PROXY 参数,来设置代理服务器的地址和端口。
在 spider 的 settings.py 文件中,可以添加如下配置:
import requests# 代理服务器的信息
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"# 构建代理服务器的URL
HTTP_PROXY = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"# 构建请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36"
}# 创建代理服务器的Session
session = requests.Session()
session.proxies = {"http": HTTP_PROXY,"https": HTTP_PROXY
}# 发送请求
url = "https://example.com" # 替换为你要访问的目标网址
response = session.get(url, headers=headers)# 处理响应数据
if response.status_code == 200:print("成功访问网站")# 进一步处理网页内容# ...
else:print("访问网站失败")请将 your_proxy_server 替换为实际的代理服务器地址,port 替换为代理服务器的端口号。使用代理服务器可以帮助解决网络访问问题,但要确保代理服务器稳定可用。
4. 检查 AWS 实例状态
如果以上的方法都无法解决问题,那么我们需要检查 AWS 实例的状态。如果 AWS 实例的状态异常,那么 spider 在获取 AWS 实例数据时,就可能出现错误。因此,我们需要确保 AWS 实例的状态是正常的。
可以登录到 AWS 管理控制台,检查实例的运行状态、网络配置和安全组设置等是否正确。确保实例能够正常访问互联网。
总结
以上就是对这个问题的解决方案。在实际操作中,我们可以根据具体的情况,选择适合自己的解决方案。同时,我们还需要注意,这些解决方案可能会带来一些副作用,所以在爬取过程中我们需要随时进行观察,监测错误。
相关文章:
spider 网页爬虫中的 AWS 实例数据获取问题及解决方案
前言 AAWS实例数据对于自动化任务、监控、日志记录和资源管理非常重要。开发人员和运维人员可以通过AWS提供的API和控制台访问和管理这些数据,以便更好地管理和维护他们在AWS云上运行的实例。然而,在使用 spider 框架进行网页爬取时,我们常常…...

flink的window和windowAll的区别
背景 在flink的窗口函数运用中,window和windowAll方法总是会引起混淆,特别是结合上GlobalWindow的组合时,更是如此,本文就来梳理下他们的区别和常见用法 window和windowAll的区别 window是KeyStream数据流的方法,其…...
【机器学习】特征工程:特征选择、数据降维、PCA
各位同学好,今天我和大家分享一下python机器学习中的特征选择和数据降维。内容有: (1)过滤选择;(2)数据降维PCA;(3)sklearn实现 那我们开始吧。 一个数据集中…...

短视频账号矩阵系统saas管理私信回复管理系统
一、短视频矩阵号系统源码开发层面如何来解决? 1.短视频矩阵号系统源码搭建中,首先开发者需要保证api接口的稳定性 ,保证权限应用场景满足官方平台的开发预期。api---待发布、用户管理与授权绑定、私信回复与评论管理等是非常重要的权限接口。…...
利用ETLCloud自动化流程实现业务系统数据快速同步至数仓
现代企业有不少都完成了数字化的转型,而还未转型的企业或商铺也有进行数字化转型的趋势,由此可见,数据已经成为企业决策的重要依据。企业需要先获取数据,将业务系统数据同步至数仓进行整合,然后再进行数据分析。为了更…...

学习c#的第十六天
目录 C# 正则表达式 定义正则表达式 字符转义 字符类 定位点 分组构造 Lookaround 概览 数量词 反向引用构造 替换构造 替代 正则表达式选项 其他构造 Regex 类 代码示例 实例 1 实例 2 实例 3 C# 正则表达式 正则表达式 是一种匹配输入文本的模式。.Net 框…...

【论文阅读笔记】Deep learning for time series classification: a review
【论文阅读笔记】Deep learning for time series classification: a review 摘要 在这篇文章中,作者通过对TSC的最新DNN架构进行实证研究,探讨了深度学习算法在TSC中的当前最新性能。文章提供了对DNNs在TSC的统一分类体系下在各种时间序列领域中的最成功…...
如何将vscode和Linux远程链接:
如何将vscode和Linux远程链接: Remote - SSH - 远程登录Linux 安装Remote - SSH 我们下载完后,就会出现这些图标 这里点一下号 查看一下我们的主机名,并复制 输入ssh 用户名主机名 这里是要将ssh这个文件要放在主机下的哪个路径下ÿ…...
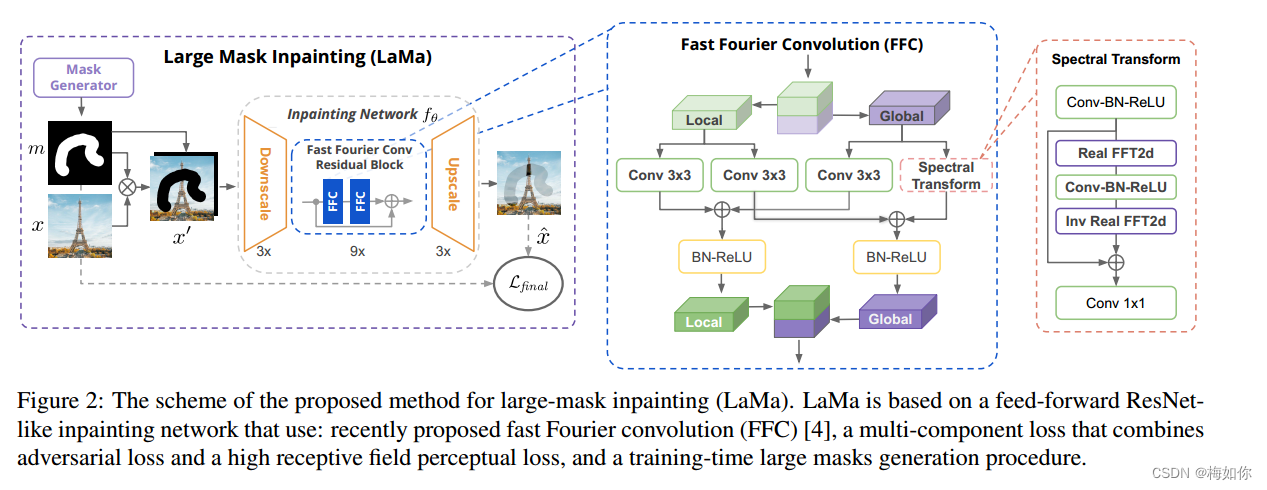
快速傅立叶卷积(FFC)
论文 LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions https://github.com/advimman/lama 1.Introduce 解决图像绘制问题——缺失部分的真实填充——既需要“理解”自然图像的大尺度结构,又需要进行图像合成。 通常的做法是在一个大型自…...
)
藏头诗(C语言)
本题要求编写一个解密藏头诗的程序。 注:在 2022 年 7 月 14 日 16 点 50 分以后,该题数据修改为 UTF-8 编码。 输入格式: 输入为一首中文藏头诗,一共四句,每句一行。注意:一个汉字占三个字节。 输出格…...
适合您的智能手机的 7 款优秀手机数据恢复软件分享
如今,我们做什么都用手机;从拍照到录音,甚至作为 MP3 播放器,我们已经对手机变得非常依恋。这导致我们在手机上留下了很多珍贵的回忆。 不幸的是,我们有可能会丢失手机上的部分甚至全部数据。幸运的是,这不…...

uniapp APP下载流文件execl 并用WPS打开
使用plus.downloader.createDownload 方法将新建下载任务 HTML5 API Reference export default function plusDownload(config){if(!config){console.error("Argument should not be null");return;}const urlrequest.baseUrlconfig.url;let token uni.getStorage…...

【Python】 Python 操作PDF文档
Python 操作PDF文档 1、PDF (便携式文件格式,Portable Document Format)是由Adobe Systems在1993年用于文件交换所发展出的文件格式。 PDF主要由三项技术组成:衍生自PostScript;字型嵌入系统;资料压缩及传…...

vue3-响应式核心
🌈个人主页:前端青山 🔥系列专栏:Vue篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来vue篇专栏内容:vue3-响应式核心 响应式核心 目录 响应式核心 3.1ref() 3.2computed () 3.3 reactive() 3.4 …...

人工智能的广泛应用与影响
目录 前言1 智能手机与个人助手2 医疗保健3 自动驾驶技术4 金融领域5 教育与学习6 智能家居与物联网7 娱乐与媒体8 环境保护结语 前言 人工智能(Artificial Intelligence,AI)是当今科技领域的璀璨明星,它不仅在技术创新方面掀起了…...
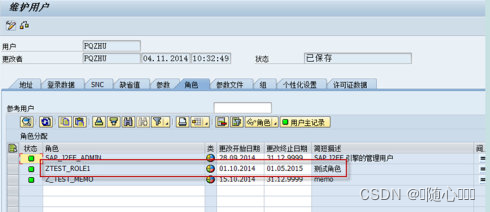
SAP创建权限对象、角色、并分配角色
一、SU20:维护权限字段 二、SU21创建权限对象,分配权限字段: 三、SU24关联程序和自建权限对象(标准tcode会默认存在标准权限对象) 四、PFCG创建角色 五、SU01给用户分配角色 一、su20:维护权限字段 X点新建: 填入…...

[uni-app]记录APP端跳转页面自动滚动到底部的bug
文章目录 bug描述原因分析: 处理方案 bug描述 1.点击的A页面, 跳转到了B页面, 第一次页面正常显示 2.从B页面返回A页面 3.A页面不进行任何操作,再次点击A页面进入B页面 4.B页面自动滚动到底部. 原因 看一段A页面代码 let that thisthis.defaultScrollTop uni.getStorageSy…...

应用软件安全编程--23避免使用不安全的操作模式
块密码又称为分组加密, 一次加密明文中的一个块。将明文按一定的位长分组,明文组经过加密运 算得到密文组,密文组经过解密运算(加密运算的逆运算),还原成明文组。这种加密算法共有四种操作 模式用于描述如何重复地应用密码的单块操作来安全的…...

国产高云FPGA:纯verilog实现视频图像缩放,提供6套Gowin工程源码和技术支持
目录 1、前言免责声明 2、相关方案推荐国产高云FPGA相关方案推荐国产高云FPGA基础教程 3、设计思路框架视频源选择OV5640摄像头配置及采集动态彩条跨时钟FIFO图像缩放模块详解设计框图代码框图2种插值算法的整合与选择 Video Frame Buffer 图像缓存DDR3 Memory Interface 4、Go…...

python操作windows窗口,python库pygetwindow使用详解
文章目录 一、pygetwindow模块简介二、pygetwindow常用方法1、常用方法2、window常用方法 一、pygetwindow模块简介 pygetwindow是一个Python第三方库,用于获取、管理和操作窗口。它提供了一些方法和属性,使得在Python程序中可以轻松地执行各种窗口操作…...
)
告别YAML诅咒:用LLM自动生成可验证CD流水线(附奇点大会开源Schema v2.1)
更多请点击: https://intelliparadigm.com 第一章:AI原生持续交付:2026奇点智能技术大会部署流水线优化 在2026奇点智能技术大会上,AI原生持续交付(AI-Native CI/CD)成为核心实践范式——它不再将AI模型视…...

Agent才不会“赢家通吃“,证据来了……
Claude Code已经赢成这样了, 顺带又做了CMA, 定义下一代企业级Agent infra。 Claude Code『同款』infra, 谁不想用。 谁又不想卖可复用的工具呢。 这样下去, 做Agent infra须有爆款Agent证明自己吗? 肯定很多人反对&am…...

PIDtoolbox完全指南:3步掌握无人机黑盒日志分析的终极免费工具
PIDtoolbox完全指南:3步掌握无人机黑盒日志分析的终极免费工具 【免费下载链接】PIDtoolbox PIDtoolbox is a set of graphical tools for analyzing blackbox log data 项目地址: https://gitcode.com/gh_mirrors/pi/PIDtoolbox 你是否曾面对无人机的飞行日…...

抖音批量下载终极指南:5分钟学会免费下载无水印视频
抖音批量下载终极指南:5分钟学会免费下载无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

GitHubCopilot与Gemini3.1Pro协同开发实战
在 2026 年,AI 编程工具的差异已经从“谁能写代码”转向“谁能把代码写对、写稳、写得可维护”。很多团队开始采用“双引擎协作”:GitHub Copilot 负责快速生成与代码补全,而 Gemini 3.1 Pro 负责更强的推理、架构级建议、测试策略与长上下文…...

5分钟掌握LayerDivider:AI图像分层工具终极指南
5分钟掌握LayerDivider:AI图像分层工具终极指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对复杂的插画作品,花…...

终极指南:3分钟免费完成OFD转PDF,彻底解决电子发票打印难题
终极指南:3分钟免费完成OFD转PDF,彻底解决电子发票打印难题 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 你是否曾因收到OFD格式的电子发票而无法在手机或普通电脑上打开&am…...

3分钟快速解密QMC加密音乐:QMCDecoder完整使用指南
3分钟快速解密QMC加密音乐:QMCDecoder完整使用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否遇到过QQ音乐下载的歌曲只能在特定播放器里播放&#…...

从Max Pressure到PressLight:一个交通信号控制算法的演进史与实战效果对比
从Max Pressure到PressLight:交通信号控制算法的技术革命与实战解析 引言:城市交通信号控制的进化之路 每当我们在早高峰被堵在十字路口时,很少有人会想到红绿灯背后隐藏着怎样的智能决策系统。现代城市交通信号控制已经从简单的定时控制发展…...
)
2026AI医疗急救系统落地实战手册(附卫健委备案模板+边缘算力配置清单)
更多请点击: https://intelliparadigm.com 第一章:2026AI医疗急救系统的战略定位与政策演进全景 2026AI医疗急救系统已超越技术工具范畴,成为国家公共卫生韧性建设的核心基础设施。其战略定位聚焦于“黄金10分钟”智能响应闭环——通过边缘端…...