百度爬虫的工作原理解析
百度作为中国最大的搜索引擎,其工作原理备受关注。本文将深入探讨百度爬虫的工作原理,介绍其基本流程以及关键技术,帮助读者更好地理解搜索引擎背后的技术核心。

百度爬虫是百度搜索引擎的重要基石,它们被广泛用于收集互联网上的网页信息。这些爬虫程序通过跟踪网页链接,不断地深入互联网的各个角落,尽可能地收集和索引互联网上的网页信息。在收集网页信息的过程中,百度爬虫会根据特定的规则和算法对网页进行评估和分类,以确保它们的内容质量和相关性。
这些被收集的网页信息会被存储为索引数据,这些数据是百度搜索引擎进行快速检索的关键。当用户在百度中进行搜索时,百度搜索引擎会根据用户的查询关键词和相关算法,快速检索其索引数据库中的数据,并返回最相关、最有用的搜索结果。因此,百度爬虫的工作效率和质量直接影响到用户搜索体验的质量。
URL抓取
URL抓取是指从已知的种子URL(统一资源定位符)开始,通过搜索引擎的爬虫程序递归地访问和解析网页内容,以发现和抓取尽可能多的链接和页面信息。在这个过程中,百度爬虫会利用先进的算法和程序,对页面进行深入的分析和挖掘。
具体来说,百度爬虫会根据一定的规则和策略,对种子URL进行访问和解析。在解析过程中,它会识别和提取出页面中的链接信息,并根据这些链接信息递归地发现和访问更多的网页。同时,百度爬虫还会对页面的质量、重要性和更新频率等因素进行评估,以选择性地抓取更高质量的页面。
在URL抓取过程中,百度爬虫还采用了许多先进的技术和算法,如网页排序算法、去重算法、过滤算法等,以确保抓取到的数据具有高质量、全面性和实时性。此外,百度爬虫还具备处理各种复杂网页结构和内容的的能力,如动态加载内容、AJAX请求等,以便更准确地获取页面信息。

百度爬虫的URL抓取技术是一种高度智能化的网页数据获取方法,它能够快速、准确地发现和抓取网页中的链接和内容信息,为搜索引擎的索引和检索提供了重要的支持和保障。
页面解析
一旦百度爬虫成功抓取到网页的内容,它会采用先进的HTML解析技术,对页面进行深入的剖析和提取。这种技术能够精准地识别和提取出页面的各种元素,如标题、正文内容、链接、图片等,同时将它们归纳整理成有逻辑结构的数据形式。这种结构化的数据形式可以更好地被搜索引擎理解和使用,从而使用户在搜索结果中获得更准确、更有价值的信息。
索引存储
经过解析的页面内容被迅速发送到设在全球各地的分布式索引服务器上,由百度大规模的索引服务器集群进行信息处理和分析。这些索引服务器会对页面的关键词、链接以及其他重要特征进行精细的处理和深入分析,以构建一个高效且精准的索引数据结构,非常有利于后面的搜索和排序操作。
更新与重访
在互联网世界中,信息的更新和变化是时刻都在发生的。为了确保用户能够获得最新、最准确的信息,百度爬虫承担起了定期更新和重新访问已经抓取过的网页的任务。这种定期的更新与重访机制,是百度爬虫为了保持搜索结果的新鲜度和准确性而采取的重要措施。
具体来说,百度爬虫会制定一个合理的计划,定期对已经收录的网页进行重新访问。这就像是一个定期检查身体的状态,以确保一切都在良好的运行中。在重访的过程中,百度爬虫会对网页的内容进行细致的检查,认真分析其中的变化。如果发现页面有所更新或变化,百度爬虫就会重新对该页面进行抓取,并立即更新其索引信息。
这种实时的更新与重访机制,使得百度搜索能够时刻保持其内容的最新性和准确性。用户在使用百度搜索时,可以快速找到自己需要的信息,并且放心地使用。这也进一步巩固了百度作为全球最大的中文搜索引擎的地位,为广大用户提供了更加优质、便捷的搜索服务。
非HTML网页和多媒体内容处理
百度爬虫不仅能够处理常规的HTML页面,对于其他类型的网页内容,如PDF、Word文档、图片、视频等,它同样能够进行有效的处理。通过引入先进的文本和图像识别技术,百度爬虫可以对这些非HTML内容进行精准的解析和索引。这不仅提高了搜索结果的质量和多样性,同时也为搜索用户提供了更全面、更准确的信息。

具体而言,百度爬虫利用了光学字符识别(OCR)技术对PDF和图片中的文字进行识别,以及利用自然语言处理(NLP)技术对Word文档中的文本进行分析和理解。对于视频内容,百度爬虫则通过视频识别技术提取视频中的关键信息,并对其进行文本化处理,以便于搜索和索引。
这些技术的引入,使得百度爬虫能够更好地理解和索引非HTML网页和多媒体内容,从而提高了搜索结果的质量和多样性。同时,这也为搜索用户提供了更全面、更准确的信息,帮助他们更好地了解和解决问题。
反作弊与安全措施
为了提供高质量和安全的搜索结果,百度爬虫采用了多种技术手段来鉴别和过滤垃圾信息、恶意网页、钓鱼网站等。这些技术包括先进的人工智能算法、机器学习模型、网络安全技术等,旨在提供用户可信赖的搜索服务。
百度爬虫不断升级反作弊策略,通过分析网站的内容、结构、链接等特征,以及使用户行为分析等手段,精准识别欺诈网站、恶意跳转等恶意行为。同时,百度爬虫还会对搜索结果进行实时监控,一旦发现异常情况,会立即启动应急预案,及时清理垃圾信息,确保用户获取准确、可靠的搜索结果。
百度爬虫的安全措施不仅限于技术层面,还注重管理与制度方面的建设。例如,建立严格的信息审核机制,对所有收录的网站进行内容真实性和合法性的审核,以保证搜索结果的质量和安全性。此外,百度爬虫还建立了庞大的诚信网站联盟,鼓励优质网站加入,共同维护良好的网络生态。
在人工智能算法方面,百度爬虫开发了多种深度学习模型,用于特征提取、网页分类、链接分析等任务。这些模型能够学习并模拟人类专家的判断过程,实现对网页的精准分类和打分。同时,百度爬虫还采用联邦学习等前沿技术,保护网站数据隐私,提高模型泛化能力。
在机器学习方面,百度爬虫利用无监督学习模型对网页进行聚类分析,识别出相似或相关的网页,从而判断哪些网页可能存在欺诈行为。此外,百度爬虫还利用有监督学习模型对用户行为进行分析,预测用户可能的查询意图,优化搜索结果排序。
在网络安全技术方面,百度爬虫采用先进的防火墙技术、入侵检测系统等手段保护网站安全。同时,百度爬虫还建立了完善的安全应急响应机制,确保在发生安全事件时能够迅速应对,保障用户信息安全。
百度爬虫在反作弊与安全措施方面投入了大量资源和技术力量,旨在提供高质量和安全的搜索结果。这些措施不仅包括先进的人工智能算法、机器学习模型和网络安全技术等高科技手段,还注重管理与制度方面的建设。通过全方位的努力,百度爬虫为用户提供可信赖的搜索服务。
结论
百度爬虫,作为百度搜索引擎的核心组成部分,发挥着至关重要的作用。它承担着收集、解析和索引互联网信息的重任,对海量网页信息的组织、分类和存储具有决定性的影响。通过高效地抓取网页URL、解析页面内容、建立索引、存储与更新以及处理多媒体信息,百度爬虫在提升搜索引擎的效率和准确性方面发挥了关键作用。同时,为了应对恶意网页和作弊行为,百度爬虫还采取了相应的反作弊与安全措施,确保搜索结果的公正性和准确性。

通过对百度爬虫工作原理的深入理解,我们可以更好地把握搜索引擎背后的技术运作机制。这种理解有助于我们更好地利用搜索引擎,提升信息获取的效率和准确性。同时,对于从事网络开发和优化的人员来说,了解搜索引擎的工作原理也能为他们的职业发展提供重要的技术支持和指导。
在互联网时代,信息量巨大且更新迅速,搜索引擎作为人们获取信息的主要途径之一,其技术运作出色与否显得尤为重要。百度作为中国最大的搜索引擎服务商,其爬虫技术的不断升级和完善对于提升用户体验、满足用户需求具有举足轻重的地位。因此,对百度爬虫工作原理的理解和学习,对于我们日常生活和工作都具有重要的意义。
相关文章:
百度爬虫的工作原理解析
百度作为中国最大的搜索引擎,其工作原理备受关注。本文将深入探讨百度爬虫的工作原理,介绍其基本流程以及关键技术,帮助读者更好地理解搜索引擎背后的技术核心。 百度爬虫是百度搜索引擎的重要基石,它们被广泛用于收集互联网上的网…...

Linux入门必备指令
Linux学习之路起始篇——Linux基本指令 文章目录 Linux学习之路起始篇——Linux基本指令**一、ls指令****二、pwd命令****三、cd命令****四、touch指令****五、mkdir命令****六、rm命令****七、man 命令****八、cp命令****九、mv命令****10、cat 指令****十一、tac命令** 前言&…...
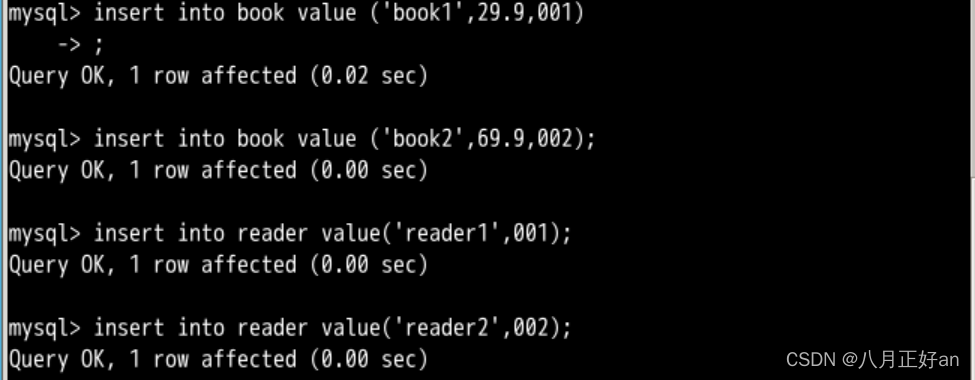
linux系统环境下mysql安装和基本命令学习
此篇文章为蓝桥云课--MySQL的学习记录 块引用部分为自己的实验部分,其余部分是课程自带的知识,链接如下: MySQL 基础课程_MySQL - 蓝桥云课 本课程为 SQL 基本语法及 MySQL 基本操作的实验,理论内容较少,动手实践多&am…...
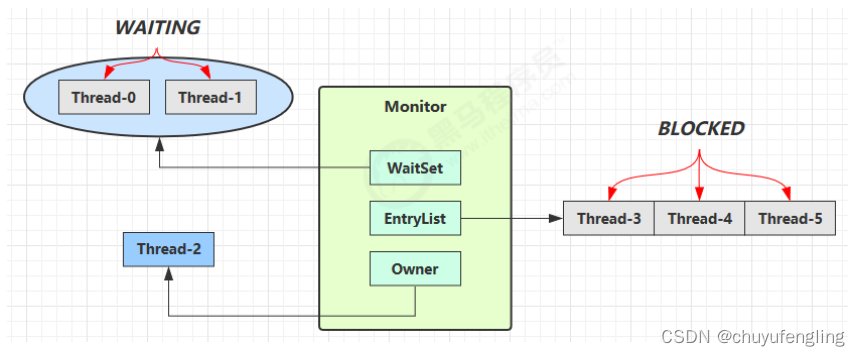
Monitor 原理
每个 Java 对象都可以关联一个 Monitor 对象,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的 Mark Word 中就被设置指向 Monitor 对象的指针。 Monitor组成内容 EntryList(入口列表) 当一个线…...

Java核心知识点整理大全7-笔记
目录 4.1.9. JAVA 锁 4.1.9.1. 乐观锁 4.1.9.2. 悲观锁 4.1.9.3. 自旋锁 4.1.9.4. Synchronized 同步锁 Synchronized 作用范围 Synchronized 核心组件 Synchronized 实现 4.1.9.5. ReentrantLock Lock 接口的主要方法 非公平锁 公平锁 ReentrantLock 与 synchronized …...

Flink Operator 使用指南 之 全局配置
背景 在上一个章节中已经介绍了基本的Flink-Operator安装,但是在实际的数据中台的项目中,用户可能希望看到Flink Operator的运行日志情况,当然这可以通过修改Flink-Operator POD的文件实现卷挂载的形势将日志输出到宿主机器的指定目录下,但是这种办法对数据中台的产品不是…...
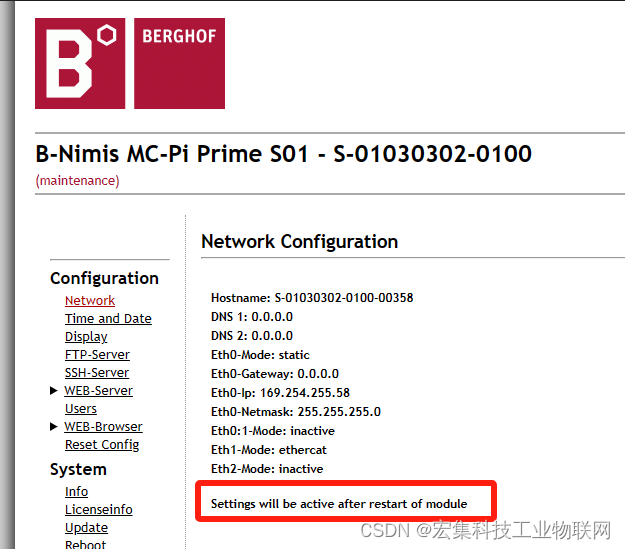
手把手教你通过CODESYS V3进行PLC编程(一)
教程背景 宏集MC系列模块化控制器是基于Raspberry Pi的高性能4核控制器,运动控制循环时间最快可达500微秒,实现了计算能力和成本之间的最佳平衡,适用于多轴运动控制和CNC控制。 教程目的 本系列教程将使用宏集MC系列控制器,详细…...

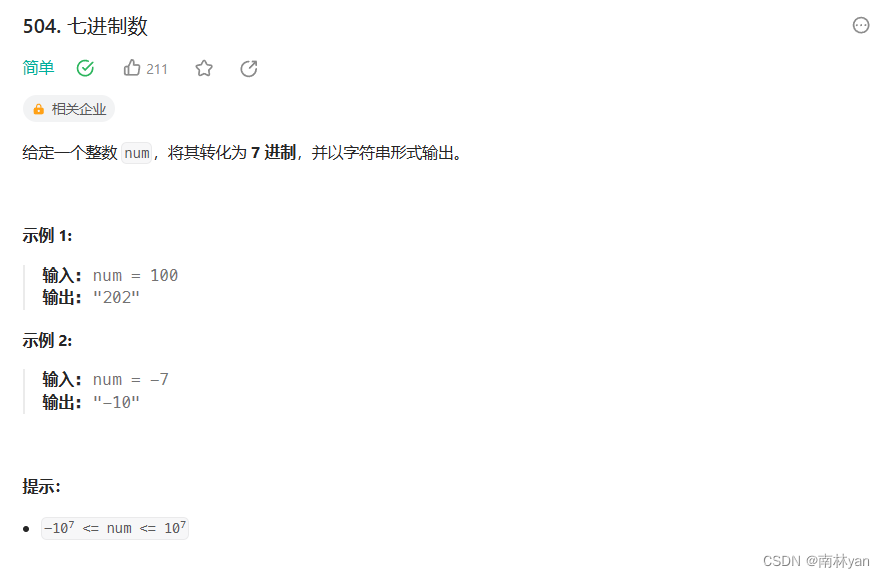
《算法通关村—进制转换问题处理模板》
《算法通关村—进制转换问题处理模板》 先来一个题热热身 504. 七进制数 给定一个整数 num,将其转化为 7 进制,并以字符串形式输出。 示例 1: 输入: num 100 输出: "202"示例 2: 输入: num -7 输出: "-10"提示: …...

python接口自动化测试之接口数据依赖
一般在做自动化测试时,经常会对一整套业务流程进行一组接口上的测试,这时候接口之间经常会有数据依赖,那又该如何继续呢? 那么有如下思路: 抽取之前接口的返回值存储到全局变量字典中。初始化接口请求时,…...

s28.CentOS、Ubuntu、Rocky Linux系统初始化脚本v6版本
CentOS、Ubuntu、Rocky系统初始化脚本 Shell脚本源码地址: Gitee:https://gitee.com/raymond9/shell Github:https://github.com/raymond999999/shell 可以去上面的Gitee或Github仓库代码拉取脚本。 版本功能v6版更新内容1.由于CentOS 6…...

go同步锁 sync mutex
goroutine http://127.0.0.1:3999/concurrency/11 go tour 到此 就结束了. 继续 学习 可以 从 以下网站 文档 https://golang.org/doc/ https://golang.org/doc/code https://golang.org/doc/codewalk/functions/ 博客 https://go.dev/blog/ wiki 服务器教程 服务器…...

使用项目自动生成的dokcerfile第一次构建时把加载aps5.0失败无法找到加载的文件
第一次构建初始化项目自带的dockerfile,内容如下: #See https://aka.ms/containerfastmode to understand how Visual Studio uses this Dockerfile to build your images for faster debugging.#FROM mcr.microsoft.com/dotnet/aspnet:5.0-buster-slim AS base #WORKDIR /a…...

ACREL DC energy meter Application in Indonesia
安科瑞 华楠 Abstract: This article introduces the application of Acrel DC meters in base station in Indonesia.The device is measuring current,voltage and energy together with hall current sensor. 1.Project Overview This company is located in Indonesia a…...
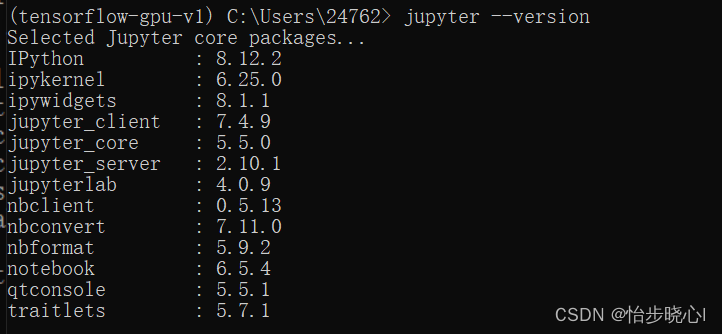
报错!Jupyter notebook 500 : Internal Server Error
Jupyter notebook 报错 500 : Internal Server Error 问题背景 tensorflow-gpu环境,为跑特定代码专门开了一个环境,使用conda安装了Jupyter notebook,能够在浏览器打开Jupyter notebook,但是notebook打开ipynb会报错。 问题分析…...

2023.11.21使用<button>元素来触发form表单和数据提交
2023.11.21使用<button>元素来触发form表单和数据提交 除了使用<input>中的submit方式进行form表单和数据提交,还可以使用button方式,两种方式视使用场景,各有优点。 方法一:可以将<button>放…...
leetcode:504. 七进制数
一、题目: 链接: 504. 七进制数 - 力扣(LeetCode) 函数原型: char* convertToBase7(int num) 二、思路 本题要将十进制数转换为二进制数,只要将十进制num数模7再除7,直到num等于0 每次将模7的结…...

centos安装指定版本docker
centos7安装指定版本的docker 官方文档 https://docs.docker.com/engine/install/centos/ 1、卸载旧版本 $ sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine2、设…...
PPT幻灯片里的图片,批量提取
之前分享过如何将PPT文件导出成图片,今天继续分享PPT技巧,如何提取出PPT文件里面的图片。 首先,我们将PPT文件的后缀名,修改为rar,将文件改为压缩包文件 然后我们将压缩包文件进行解压 最好是以文件夹的形式解压出来…...

《Fine-Grained Image Analysis with Deep Learning: A Survey》阅读笔记
论文标题 《Fine-Grained Image Analysis with Deep Learning: A Survey》 作者 魏秀参,南京理工大学 初读 摘要 与上篇综述相同: 细粒度图像分析(FGIA)的任务是分析从属类别的视觉对象。 细粒度性质引起的类间小变化和类内…...

【网络安全】伪装IP网络攻击的识别方法
随着互联网的普及和数字化进程的加速,网络攻击事件屡见不鲜。其中,伪装IP的网络攻击是一种较为常见的攻击方式。为了保护网络安全,我们需要了解如何识别和防范这种攻击。 一、伪装IP网络攻击的概念 伪装IP网络攻击是指攻击者通过篡改、伪造I…...

5分钟掌握拼多多数据采集:Scrapy-Pinduoduo爬虫实战指南
5分钟掌握拼多多数据采集:Scrapy-Pinduoduo爬虫实战指南 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 想要获取拼多多平台的热销商品信息和用户评…...

电动汽车充电站控制系统的Intel处理器实践与优化
1. 电动汽车充电站的技术架构解析电动汽车充电站作为新型能源基础设施的核心节点,其技术实现远比传统加油站复杂。一个完整的充电站系统通常包含三个层级:电力转换模块(AC/DC)、控制管理系统(CMS)和云端服务…...
)
ChatGPT Discord机器人开发全链路拆解(含Rate Limit绕过策略与上下文记忆优化)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Discord机器人开发全链路概览 构建一个能调用 ChatGPT 能力的 Discord 机器人,需跨越 API 集成、身份认证、消息路由与状态管理四大核心层。该链路并非单向调用,而是一…...

CH32F103C8T6 vs STM32F103C8T6:程序下载生态深度对比与国产替代实战
CH32F103C8T6与STM32F103C8T6程序下载生态全维度对比与国产化迁移指南 在嵌入式开发领域,MCU的程序下载方式往往决定了开发效率的上限。当工程师从熟悉的STM32平台转向国产CH32时,最直接的"水土不服"往往就发生在烧录环节——同样的SWD接口为何…...

AI智能体商业化实战:x402支付技能包集成指南
1. 项目概述:为AI智能体插上商业化的翅膀最近在折腾AI智能体(Agent)的落地应用,发现了一个挺有意思的痛点:怎么让这些能写代码、能处理任务的AI,真正地“赚到钱”?或者说,我们开发者…...

jdk1.8.0_05 在 SpringBootTest Debug模式下奔溃
之前好好的项目,最近换了之前的电脑,但是在使用SpringBootTest 启动debug模式时,虚拟机就会奔溃,通过修改如果把 junit5 import org.junit.jupiter.api.Test; 修改为 junit4 ,就不奔溃了 import org.junit.Test; 但是这样的话就得在测试类上加上 @RunWith(SpringRunn…...

VSCode跨IDE代码搜索工具:原理、配置与高效开发实践
1. 项目概述:一个为多IDE开发者量身定制的代码搜索利器如果你和我一样,日常开发需要在 Visual Studio Code 和 JetBrains 系列 IDE(如 IntelliJ IDEA、PyCharm、WebStorm 等)之间频繁切换,那你一定对“代码搜索”这件事…...

RAG:解锁大语言模型新能力,告别幻觉与知识陈旧!
本文深入解析了检索增强生成(RAG)架构,旨在解决传统大语言模型因知识局限而产生的幻觉、陈旧等问题。RAG通过在生成答案前检索外部知识库,提升回答的准确性和时效性。文章详细介绍了RAG的架构类型(如无微调、检索器微调…...

Swagger Skills:让OpenAPI文档活起来,实现自动化契约测试与场景编排
1. 项目概述:一个为Swagger API文档注入“技能”的利器如果你是一名后端开发者,或者经常需要与API打交道,那么Swagger(现在更常被称为OpenAPI)对你来说一定不陌生。它通过一个标准的YAML或JSON文件,清晰地描…...

清华PPT模板:5分钟打造专业学术演示的终极方案
清华PPT模板:5分钟打造专业学术演示的终极方案 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为每一次学术汇报、论文答辩或教学课件而烦恼吗?THU-PPT-Theme清华PPT模板库为你…...