【OpenGauss源码学习 —— 列存储(ColumnTableSample)】
执行算子(ColumnTableSample)
- 概述
- ColumnTableSample 类
- ColumnTableSample::ColumnTableSample 构造函数
- ColumnTableSample::~ColumnTableSample 析构函数
- ExecCStoreScan 函数
- ColumnTableSample::scanVecSample 函数
- ColumnTableSample::getMaxOffset 函数
- ColumnTableSample::scanBatch 函数
- ColumnTableSample::getBatchBySamples 函数
- ColumnTableSample::resetVecSampleScan 函数
- BaseTableSample::system_nextsampletuple 函数
- 案例
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及相关学习资料。
概述
在先前的学习中,我们在【 OpenGauss源码学习 —— 列存储(CopyTo)】一文中也学习过 CStore::CStoreScan 成员函数,该函数实现了列式存储表的扫描过程,通过加载压缩单元描述符(CUDesc)、进行粗略检查(RoughCheck)、填充数据批量(FillVecBatch)等步骤完成扫描操作。那么 CStore::CStoreScan 和 ExecCStoreScan 函数之间有什么联系吗?
CStore::CStoreScan 和 ExecCStoreScan 函数的区别主要在于它们所属的上下文和调用方式。这两个函数都用于执行列式存储表的扫描,但可能在不同的软件层次上。CStore::CStoreScan:属于 CStore 类,表明它可能是类的成员函数;而 ExecCStoreScan 函数属于执行器(Executor)或执行计划节点,表明它可能在查询执行计划的上下文中调用。总的来说,CStore::CStoreScan 可能更关联于存储引擎的具体实现,而 ExecCStoreScan 则更可能属于查询执行计划的执行器的一部分。
ColumnTableSample 类
ColumnTableSample 类是用于在列式存储表中执行采样扫描的实现。其功能包括维护偏移标识、当前列存储单元标识以及元组标识向量等状态信息,提供方法用于重置采样扫描状态、获取采样数据的批量行数,执行批量和向量化的采样扫描操作,并获取采样中的最大偏移值。该类的设计旨在有效地支持列式存储表的采样查询和分析需求。函数源码如下所示:(路径:src/include/executor/nodeSamplescan.h)
/* ColumnTableSample 类是 BaseTableSample 的子类,用于进行列存储表的抽样扫描。*/
class ColumnTableSample : public BaseTableSample {
private:uint16* offsetIds; // 存储列的偏移标识数组uint32 currentCuId; // 当前的列单元(CU)标识int batchRowCount; // 批次中的行数VectorBatch* tids; // 存储样本行的标识符public:ColumnTableSample(CStoreScanState* scanstate); // 构造函数,接受 CStoreScanState 参数进行初始化virtual ~ColumnTableSample(); // 虚析构函数,用于释放资源void resetVecSampleScan(); // 重置抽样扫描的矢量void getBatchBySamples(VectorBatch* vbout); // 根据样本获取批次数据ScanValid scanBatch(VectorBatch* batch); // 扫描并填充批次数据void scanVecSample(VectorBatch* batch); // 扫描抽样矢量数据void getMaxOffset(); // 获取最大的偏移值
};
ColumnTableSample::ColumnTableSample 构造函数
ColumnTableSample::ColumnTableSample 函数是 ColumnTableSample 类的构造函数,用于初始化样本扫描参数。在函数中进行了以下操作:
- 为 offsetIds 分配了内存,并将其初始化为 0。
- 创建了一个新的 VectorBatch 对象,用于构造 tids 以获取样本的 VectorBatch。
函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** 描述: 初始化 CStoreScanState 的样本扫描参数。** 参数:* @in scanstate: CStoreScanState 信息** 返回: void*/
ColumnTableSample::ColumnTableSample(CStoreScanState* scanstate): BaseTableSample(scanstate), currentCuId(0), batchRowCount(0)
{// 为 offsetIds 分配内存,并初始化为0offsetIds = (uint16*)palloc0(sizeof(uint16) * BatchMaxSize);errno_t rc = memset_s(offsetIds, sizeof(uint16) * BatchMaxSize, 0, sizeof(uint16) * BatchMaxSize);securec_check(rc, "", "");/* 创建新的 VectorBatch 以构造 tids 以获取样本 VectorBatch。*/TupleDesc tupdesc = CreateTemplateTupleDesc(1, false);TupleDescInitEntry(tupdesc, (AttrNumber)1, "tids", INT8OID, -1, 0);tids = New(CurrentMemoryContext) VectorBatch(CurrentMemoryContext, tupdesc);
}
ColumnTableSample::~ColumnTableSample 析构函数
ColumnTableSample::~ColumnTableSample 是 ColumnTableSample 类的析构函数,用于释放在构造函数中分配的资源。在函数中进行了以下操作:
- 释放 offsetIds 分配的内存。
- 删除 tids 对象,释放相关资源。
函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
ColumnTableSample::~ColumnTableSample()
{// 释放 offsetIds 分配的内存if (offsetIds) {pfree_ext(offsetIds);offsetIds = NULL;}// 释放 tids 对象if (tids) {delete tids;tids = NULL;}
}
下面,我将按照函数的调用关系来依次介绍 ColumnTableSample 类相关成员函数,函数调用关系如下图所示:
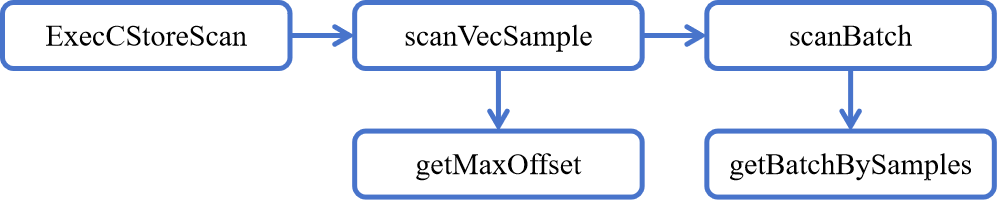
ExecCStoreScan 函数
ExecCStoreScan 函数用于执行列存储表的扫描操作,返回下一个符合条件的向量批次。函数包括了设置运行时键、处理函数返回集合、运行列存储扫描或样本扫描、检查扫描是否结束等关键步骤。函数的目的是执行列存储表的顺序扫描,返回下一个符合条件的向量批次。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 执行列存储表的扫描操作,返回下一个符合条件的向量批次。** Parameters:* @in node: CStoreScanState 信息** Returns: VectorBatch 包含下一个符合条件的元组。*/
VectorBatch* ExecCStoreScan(CStoreScanState* node)
{VectorBatch* p_out_batch = NULL; // 输出向量批次VectorBatch* p_scan_batch = NULL; // 扫描到的向量批次// 如果有运行时键且尚未设置,进行设置if (node->m_ScanRunTimeKeysNum && !node->m_ScanRunTimeKeysReady) {ExecCStoreScanEvalRuntimeKeys(node->ps.ps_ExprContext, node->m_pScanRunTimeKeys, node->m_ScanRunTimeKeysNum);node->m_ScanRunTimeKeysReady = true;}p_out_batch = node->m_pCurrentBatch;p_scan_batch = node->m_pScanBatch;// 更新列存储扫描计时标志node->m_CStore->SetTiming(node);ExprDoneCond done = ExprSingleResult;// 处理函数返回集合的情况if (node->ps.ps_TupFromTlist) {Assert(node->ps.ps_ProjInfo);p_out_batch = ExecVecProject(node->ps.ps_ProjInfo, true, &done);if (p_out_batch->m_rows > 0) {return p_out_batch;}node->ps.ps_TupFromTlist = false;}restart:// 重置向量批次和表达式上下文p_scan_batch->Reset(true);p_out_batch->Reset(true);node->ps.ps_ProjInfo->pi_exprContext->current_row = 0;// 运行列存储扫描或样本扫描if (!node->isSampleScan) {node->m_CStore->RunScan(node, p_scan_batch);} else {((ColumnTableSample*)node->sampleScanInfo.tsm_state)->scanVecSample(p_scan_batch);}// 检查扫描是否结束且批次为空if (node->m_CStore->IsEndScan() && p_scan_batch->m_rows == 0) {// 如果有数据,扫描增量存储表ScanDeltaStore(node, p_scan_batch, NULL);if (p_scan_batch->m_rows == 0)return p_out_batch;}// 修复扫描到的向量批次的行数p_scan_batch->FixRowCount();// 应用条件和投影操作p_out_batch = ApplyProjectionAndFilter(node, p_scan_batch, &done);if (done != ExprEndResult) {// 如果表达式计算结果不是结束状态node->ps.ps_TupFromTlist = (done == ExprMultipleResult);}// 处理停止查询标志if (unlikely(executorEarlyStop()))return NULL;// 如果输出批次为空,重新开始扫描if (BatchIsNull(p_out_batch)) {CHECK_FOR_INTERRUPTS();goto restart;}return p_out_batch;
}
其中,可以看到,在代码 ExecCStoreScan 中调用了 CStore::RunScan 函数:
// 运行列存储扫描或样本扫描
if (!node->isSampleScan) {node->m_CStore->RunScan(node, p_scan_batch);
} else {((ColumnTableSample*)node->sampleScanInfo.tsm_state)->scanVecSample(p_scan_batch);
}
ColumnTableSample::scanVecSample 函数
ColumnTableSample::scanVecSample 函数是一个用于获取列存储表样本的函数。函数通过状态机的方式,依次执行获取最大块数(GETMAXBLOCK)、获取块号(GETBLOCKNO)、获取最大偏移量(GETMAXOFFSET)、获取偏移量(GETOFFSET)、获取数据(GETDATA)的操作。在每个阶段,根据不同的条件和状态执行相应的操作,最终将样本数据存储在输出的 VectorBatch 中。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 获取列存储表的样本 VectoBatch。** Parameters:* @in pOutBatch: 返回 VectorBatch 的数值** Returns: void*/
void ColumnTableSample::scanVecSample(VectorBatch* pOutBatch)
{/* 如果扫描已完成或者百分比值为0,则返回NULL。*/if ((finished == true) || (vecsampleScanState->sampleScanInfo.sampleType == BERNOULLI_SAMPLE && percent[0] == 0) || (vecsampleScanState->sampleScanInfo.sampleType == SYSTEM_SAMPLE && percent[0] == 0) || (vecsampleScanState->sampleScanInfo.sampleType == HYBRID_SAMPLE && percent[BERNOULLI_SAMPLE] == 0 && percent[SYSTEM_SAMPLE] == 0)) {return;}for (;;) {CHECK_FOR_INTERRUPTS();switch (runState) {case GETMAXBLOCK: {/* 获取最大CU数目。 */totalBlockNum = CStoreRelGetCUNumByNow((CStoreScanDesc)vecsampleScanState);runState = GETBLOCKNO;elog(DEBUG2,"获取关系:%s 在 %s 上的 %u 个CUs。",NameStr(vecsampleScanState->ss_currentRelation->rd_rel->relname),g_instance.attr.attr_common.PGXCNodeName,totalBlockNum);break;}case GETBLOCKNO: {/* 获取随机或序列化的CUId作为当前块。 */(this->*nextSampleBlock_function)();if (!BlockNumberIsValid(currentBlock)) {/* 所有块已经扫描完成。 */finished = true;return;}currentCuId = currentBlock + FirstCUID + 1;runState = GETMAXOFFSET;break;}case GETMAXOFFSET: {getMaxOffset();if (InvalidOffsetNumber == curBlockMaxoffset) {runState = GETBLOCKNO;} else {runState = GETOFFSET;}elog(DEBUG2,"获取关系:%s 在 %s 上的 CUNo: %u 中的 %d 个元组。",NameStr(vecsampleScanState->ss_currentRelation->rd_rel->relname),g_instance.attr.attr_common.PGXCNodeName,currentBlock,curBlockMaxoffset);break;}case GETOFFSET: {(this->*nextSampleTuple_function)();runState = GETDATA;break;}case GETDATA: {// 调用 scanBatch 函数获取有效的批次ScanValid scanState = scanBatch(pOutBatch);switch (scanState) {// 如果存在有效数据,继续获取下一行数据case VALIDDATA: {runState = GETOFFSET;return;}// 如果没有更多数据,转到获取下一个块的状态case NEXTDATA: {runState = GETOFFSET;break;}// 如果块中的数据已经全部扫描完毕,需要获取下一个块case INVALIDOFFSET: {runState = GETBLOCKNO;// 如果上一个批次已经填满,返回上一个批次并获取新的块和批次if (batchRowCount > 0) {batchRowCount = 0;return;}break;}// 处理其他情况default: {break;}}break;}default: {break;}}}
}
ColumnTableSample::getMaxOffset 函数
ColumnTableSample::getMaxOffset 函数是用于获取当前块的最大偏移量的函数。在列存储数据库系统中,数据通常以列为单位进行组织,一个列可以被分成多个块,每个块包含一定数量的行。偏移量是指在一个块中某一行的相对位置。函数首先根据当前块号和列标识符获取列存储描述符 CUDesc。然后,通过检查快照规则和元组状态,确定当前块的最大偏移量。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 获取当前块的最大偏移量。** Parameters: 无** Returns: void*/
void ColumnTableSample::getMaxOffset()
{CUDesc cu_desc;int fstColIdx = 0;Assert(BlockNumberIsValid(currentBlock));curBlockMaxoffset = InvalidOffsetNumber;/* 如果第一列已经被删除,我们应该更改第一列的索引。 */if (vecsampleScanState->ss_currentRelation->rd_att->attrs[0]->attisdropped) {fstColIdx = CStoreGetfstColIdx(vecsampleScanState->ss_currentRelation);}/** 根据 currentCuId 获取列的 CUDesc。*/if (vecsampleScanState->m_CStore->GetCUDesc(fstColIdx, currentCuId, &cu_desc, GetActiveSnapshot()) != true) {return;}/** 我们尽力保持对行关系获取元组的规则:* 1). 忽略已死亡的元组* 2). 忽略最近死亡的元组* 3). 忽略其他事务中正在插入中的元组* 4). 忽略我们事务中正在删除中的元组* 5). 忽略其他事务中正在删除中的元组* SnapshotNow 可以满足规则 1) 2) 3) 4),因此在这里使用它。*/vecsampleScanState->m_CStore->GetCUDeleteMaskIfNeed(currentCuId, GetActiveSnapshot());/* 如果在此 CU 单元中所有元组都已删除,则快速退出此循环。 */if (vecsampleScanState->m_CStore->IsTheWholeCuDeleted(cu_desc.row_count)) {return;}curBlockMaxoffset = cu_desc.row_count;
}
ColumnTableSample::scanBatch 函数
ColumnTableSample::scanBatch 函数是用于通过元组 ID 扫描每个偏移量,获取样本的 VectorBatch 的函数。函数会检查当前块的偏移量是否为无效值,如果是,则判断是否有剩余的批次需要处理,如果有,则调用 getBatchBySamples 处理批次。接着,函数检查当前偏移量对应的行是否为无效行,如果不是,则将其添加到当前批次的 offsetIds 数组中。当批次的元组数量达到 BatchMaxSize 时,调用 getBatchBySamples 处理批次,然后清空 offsetIds 数组。最后,函数根据处理的结果返回相应的标志。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 扫描每个偏移量,并通过元组ID获取样本的 VectorBatch。** Parameters:* @in pOutBatch: 返回 VectorBatch 的数值** Returns: ScanValid(用于标识元组是否有效的标志)*/
ScanValid ColumnTableSample::scanBatch(VectorBatch* pOutBatch)
{Assert(BlockNumberIsValid(currentBlock));/* 当前块已经被读取。*/if (currentOffset == InvalidOffsetNumber) {if (batchRowCount > 0) {/** 如果到达这里,意味着我们已经用尽了这个 CU 上的元组,* 现在是时候移到下一个 CU。*/getBatchBySamples(pOutBatch);errno_t rc = memset_s(offsetIds, sizeof(uint16) * BatchMaxSize, 0, sizeof(uint16) * BatchMaxSize);securec_check(rc, "", "");}return INVALIDOFFSET;}if (!vecsampleScanState->m_CStore->IsDeadRow(currentCuId, (uint32)currentOffset)) {elog(DEBUG2,"获取一个元组 [currentCuId: %u, currentOffset: %u] for 关系: %s 在 %s 上.",currentCuId,currentOffset,NameStr(vecsampleScanState->ss_currentRelation->rd_rel->relname),g_instance.attr.attr_common.PGXCNodeName);/* 从 CU 中获取当前行,并填充到向量中,直到完成一个批次。 */offsetIds[batchRowCount++] = currentOffset;if (batchRowCount >= BatchMaxSize) {getBatchBySamples(pOutBatch);batchRowCount = 0;errno_t rc = memset_s(offsetIds, sizeof(uint16) * BatchMaxSize, 0, sizeof(uint16) * BatchMaxSize);securec_check(rc, "", "");return VALIDDATA;}}return NEXTDATA;
}
ColumnTableSample::getBatchBySamples 函数
ColumnTableSample::getBatchBySamples 函数是根据 tids(CuId+offsetId)获取样本的 VectorBatch 的函数。函数首先重置了 tids 的状态,然后通过当前 CU 的 CuId 和 offsetIds 构建了 tids 的 VectorBatch 。接着,函数通过 tids 扫描了 VectorBatch,并将结果存储在输出参数 vbout 中。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 根据 tids(CuId+offsetId)获取样本的 VectorBatch。** Parameters:* @in state: CStoreScanState 信息* @in cuId: 当前 CU 的 CuId* @in maxOffset: 当前 CU 的最大 Offset* @in offsetIds: 当前 CU 的随机 offsetIds* @in tids: 通过 cuId 和 offsetIds 构建 tids 的 VectorBatch* @in vbout: 返回 VectorBatch 的数值** Returns: void*/
void ColumnTableSample::getBatchBySamples(VectorBatch* vbout)
{ScalarVector* vec = tids->m_arr;tids->Reset();/* 用 CuId 和 offsetId 填充 tids 的 VectorBatch。 */for (int j = 0; j < batchRowCount; j++) {/* 我们可以确定这不是死行。 */vec->m_vals[j] = 0;ItemPointer itemPtr = (ItemPointer)&vec->m_vals[j];/* 注意,itemPtr->offset 从 1 开始。 */ItemPointerSet(itemPtr, currentCuId, offsetIds[j]);}vec->m_rows = batchRowCount;tids->m_rows = vec->m_rows;/* 通过 tids 扫描 VectorBatch。 */if (!BatchIsNull(tids)) {CStoreIndexScanState* indexScanState = makeNode(CStoreIndexScanState);indexScanState->m_indexOutAttrNo = 0;vecsampleScanState->m_CStore->ScanByTids(indexScanState, tids, vbout);vecsampleScanState->m_CStore->ResetLateRead();}
}
ColumnTableSample::resetVecSampleScan 函数
ColumnTableSample::resetVecSampleScan 函数是用于重置 VectoBatch 样本扫描参数的函数。在函数中,将 currentCuId 和 batchRowCount 设置为初始值,然后调用 resetSampleScan 函数重置表样本的通用参数。接着,如果存在 tids 对象,将其重置;同时,如果存在 offsetIds 数组,使用 memset_s 函数将其清零。这个函数主要用于准备进行下一轮 VectoBatch 样本扫描时的初始状态。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 重置 VectoBatch 样本扫描参数。** Parameters: 无** Returns: void*/
void ColumnTableSample::resetVecSampleScan()
{currentCuId = 0;batchRowCount = 0;/* 重置表样本的通用参数。 */(((ColumnTableSample*)vecsampleScanState->sampleScanInfo.tsm_state)->resetSampleScan)();if (tids) {tids->Reset();}if (offsetIds) {errno_t rc = memset_s(offsetIds, sizeof(uint16) * BatchMaxSize, 0, sizeof(uint16) * BatchMaxSize);securec_check(rc, "", "");}
}
BaseTableSample::system_nextsampletuple 函数
BaseTableSample::system_nextsampletuple 函数是用于获取下一个顺序偏移量的函数。函数首先记录当前偏移量,然后将其递增到页面上的下一个可能的偏移量。如果当前偏移量为无效值,则将其设置为第一个偏移量。接着,如果递增后的偏移量超过了当前块的最大偏移量,将其重新设置为无效值。最后,更新对象的当前偏移量。这个函数通常在对数据进行顺序扫描时使用,确保按顺序逐个获取数据行的偏移量。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeSamplescan.cpp)
/** Description: 获取顺序下一个偏移量。* Parameters: 无* Returns: void*/
void BaseTableSample::system_nextsampletuple()
{// 记录当前偏移量OffsetNumber tupoffset = currentOffset;/* 向页面上的下一个可能的偏移量前进 */if (tupoffset == InvalidOffsetNumber) {tupoffset = FirstOffsetNumber;} else {tupoffset++;}// 如果偏移量超过当前块的最大偏移量,则将其设置为无效值if (tupoffset > curBlockMaxoffset) {tupoffset = InvalidOffsetNumber;}// 更新当前偏移量currentOffset = tupoffset;
}
案例
下面我们还是以一个案例来调试一下代码吧,首先执行以下 sql 语句:
-- 创建表
CREATE TABLE column_store_table (id INT,name VARCHAR(50),age INT,salary DECIMAL(10, 2),email VARCHAR(100)
)WITH (ORIENTATION = COLUMN);-- 插入数据
INSERT INTO column_store_table VALUES(1, 'John', 30, 50000.00, 'john@example.com'),(2, 'Alice', 28, 60000.50, NULL),(3, 'Bob', NULL, NULL, 'bob@example.com');-- 执行列存查询操作
select * from column_store_table where id > 1;
1. 在 ExecCStoreScan 函数中打上断点。
函数调用关系如下所示:
#0 ExecCStoreScan (node=0x7f15ae082060) at veccstore.cpp:314
#1 0x000000000173425f in VectorEngine (node=0x7f15ae082060) at vecexecutor.cpp:171
#2 0x0000000001687fd5 in ExecVecToRow (state=0x7f15adeea060) at vectortorow.cpp:149
#3 0x000000000159a439 in ExecProcNodeByType (node=0x7f15adeea060) at execProcnode.cpp:677
#4 0x000000000159a8dd in ExecProcNode (node=0x7f15adeea060) at execProcnode.cpp:769
#5 0x0000000001595232 in ExecutePlan (estate=0x7f15b335c060, planstate=0x7f15adeea060, operation=CMD_SELECT, sendTuples=true, numberTuples=0,direction=ForwardScanDirection, dest=0x7f15b3355d60) at execMain.cpp:2124
#6 0x0000000001591d6a in standard_ExecutorRun (queryDesc=0x7f15b3368c60, direction=ForwardScanDirection, count=0) at execMain.cpp:608
#7 0x000000000139a5d4 in explain_ExecutorRun (queryDesc=0x7f15b3368c60, direction=ForwardScanDirection, count=0) at auto_explain.cpp:116
#8 0x000000000159188f in ExecutorRun (queryDesc=0x7f15b3368c60, direction=ForwardScanDirection, count=0) at execMain.cpp:484
#9 0x000000000147298f in PortalRunSelect (portal=0x7f15adedc060, forward=true, count=0, dest=0x7f15b3355d60) at pquery.cpp:1396
#10 0x0000000001471b5c in PortalRun (portal=0x7f15adedc060, count=9223372036854775807, isTopLevel=true, dest=0x7f15b3355d60, altdest=0x7f15b3355d60,completionTag=0x7f15abf27f90 "") at pquery.cpp:1134
---Type <return> to continue, or q <return> to quit---
相关调试信息如下所示:
(gdb) p *node
$1 = {<ScanState> = {ps = {type = T_CStoreScanState, plan = 0x7f15b9b1a0a0, state = 0x7f15b335c060, instrument = 0x0, targetlist = 0x7f15b9b242d0,qual = 0x7f15b9b25530, lefttree = 0x0, righttree = 0x0, initPlan = 0x0, subPlan = 0x0, chgParam = 0x0, hbktScanSlot = {currSlot = 0},ps_ResultTupleSlot = 0x7f15b9b24b98, ps_ExprContext = 0x7f15ae082288, ps_ProjInfo = 0x7f15b9b27e50, ps_TupFromTlist = false, vectorized = true,nodeContext = 0x7f15adee0060, earlyFreed = false, stubType = 0 '\000', jitted_vectarget = 0x0, plan_issues = 0x0, recursive_reset = false,qual_is_inited = false, ps_rownum = 0}, ss_currentRelation = 0x7f15adff8390, ss_currentScanDesc = 0x0, ss_ScanTupleSlot = 0x7f15b9b24d08,ss_ReScan = false, ss_currentPartition = 0x0, isPartTbl = false, currentSlot = 0, partScanDirection = NoMovementScanDirection, partitions = 0x0,lockMode = 0, runTimeParamPredicates = 0x0, runTimePredicatesReady = false, is_scan_end = false, ss_scanaccessor = 0x0, part_id = 0, startPartitionId = 0,endPartitionId = 0, rangeScanInRedis = {isRangeScanInRedis = 0 '\000', sliceTotal = 0 '\000', sliceIndex = 0 '\000'}, isSampleScan = false,sampleScanInfo = {args = 0x0, repeatable = 0x0, sampleType = SYSTEM_SAMPLE, tsm_state = 0x0}, ScanNextMtd = 0x0}, ss_currentDeltaRelation = 0x7f15adffb050,ss_partition_parent = 0x0, ss_currentDeltaScanDesc = 0x7f15b8289060, ss_deltaScan = false, ss_deltaScanEnd = false, m_pScanBatch = 0x7f15b305b3d0,m_pCurrentBatch = 0x7f15b9b25b20, m_pScanRunTimeKeys = 0x0, m_ScanRunTimeKeysNum = 0, m_ScanRunTimeKeysReady = false, m_CStore = 0x7f15b31f54f0,csss_ScanKeys = 0x7f15b31f50c8, csss_NumScanKeys = 1, m_fSimpleMap = true, m_fUseColumnRef = false, jitted_vecqual = 0x0, m_isReplicaTable = false}(gdb) p *p_out_batch
$2 = {<BaseObject> = {<No data fields>}, m_rows = 0, m_cols = 5, m_checkSel = false, m_sel = 0x7f15b9b25b88, m_arr = 0x7f15b2ddbdb0, m_sysColumns = 0x0,m_pCompressBuf = 0x0}(gdb) p *p_scan_batch
$3 = {<BaseObject> = {<No data fields>}, m_rows = 0, m_cols = 5, m_checkSel = false, m_sel = 0x7f15b305b438, m_arr = 0x7f15b9b27c30, m_sysColumns = 0x0,m_pCompressBuf = 0x0}
在这里,执行 select * from column_store_table where id > 1; 后 ExecCStoreScan 函数会调用 CStore::RunScan 对列存表进行扫描。这里,我们可以使用如下 SQL 来限制表扫描的范围:SELECT * FROM column_store_table TABLESAMPLE SYSTEM (10);
2. 执行样本表扫描。
执行 SELECT * FROM column_store_table TABLESAMPLE SYSTEM (10); 后,可以看到ExecCStoreScan 函数会调用 ColumnTableSample::scanVecSample 函数进行样本表扫描。
│354 if (!node->isSampleScan) { ││355 node->m_CStore->RunScan(node, p_scan_batch); ││356 } else { ││357 /* ││358 * Sample scan for column table. ││359 */ │>│360 (((ColumnTableSample*)node->sampleScanInfo.tsm_state)->scanVecSample)(p_scan_batch); ││361 } │
相关调试信息如下所示:
(gdb) p * pOutBatch
$1 = {<BaseObject> = {<No data fields>}, m_rows = 0, m_cols = 5, m_checkSel = false, m_sel = 0x7f15b305c1c8, m_arr = 0x7f15b2dd3db0, m_sysColumns = 0x0,m_pCompressBuf = 0x0}
(gdb) p totalBlockNum
$2 = 2
(gdb) p blockindex
$3 = 2
(gdb) p p_scan_batch->m_rows
$4 = 0
这里由于 TABLESAMPLE SYSTEM (10) 表示从表中随机抽取约 10% 的行,所以当执行到如下判断时就会直接 return。
if (!BlockNumberIsValid(currentBlock)) {/* 所有块已经扫描完成。 */finished = true;return;
}
为了调试 ColumnTableSample::getMaxOffset 函数,我们这里修改 SQL 语句如下:SELECT * FROM column_store_table TABLESAMPLE SYSTEM (60);
3. 步入 getMaxOffset 函数。
相关调试信息如下所示:
(gdb) p curBlockMaxoffset
$1 = 0
(gdb) p cu_desc.row_count
$2 = 1
(gdb) p curBlockMaxoffset
$3 = 1
ColumnTableSample::getMaxOffset 函数的目的是获取当前块(Column Unit,CU)的最大偏移量。在列存储数据库系统中,数据通常以列为单位进行组织,一个列可以被分成多个块,每个块包含一定数量的行。偏移量是指在一个块中某一行的相对位置。
举个具体例子:假设有一个列存储表 sample_table 包含以下数据:
id | name | value
---|-------|-------
1 | John | 10
2 | Alice | 20
3 | Bob | 15
假设该表按照 value 列进行列存储,每个 Column Unit(CU)包含 2 行数据。现在,我们来模拟一下 ColumnTableSample::getMaxOffset 函数的执行:
- 获取列存储描述符: 假设当前块的 CuId 为 1,即第一个 CU。通过 CuId 获取列存储描述符,该描述符包含有关该列的元数据信息,例如每个 CU 中的行数。
- 检查行是否被删除:假设当前块的第一行数据被删除,但其他行有效。函数检查列存储描述符,并确定第一行已被删除。
- 确定最大偏移量:由于第一行已被删除,最大偏移量将是第二行,因此最大偏移量为 2。
这样,在进行后续的列存储扫描时,系统将从第二行开始扫描,忽略已被删除的第一行,从而避免不必要的数据读取和处理。这种方式有助于提高查询性能,特别是当表中包含大量被删除或不需要的数据时。
4. 进入 GETDATA 状态。
相关调试信息如下所示:
(gdb) p scanState
$1 = NEXTDATA
返回 NEXTDATA 状态,这通常表示当前块中的数据已经全部扫描完毕,需要获取下一个块的数据。使用 (this->*nextSampleTuple_function)() 调用 BaseTableSample::system_nextsampletuple 函数获取下一个顺序偏移量的函数。
相关调试信息如下所示:
(gdb) p currentOffset
$1 = 1
(gdb) p curBlockMaxoffset
$2 = 1
(gdb) p tupoffset
$30 = 2
# 执行 if (tupoffset > curBlockMaxoffset) 后
(gdb) p tupoffset
$4 = 0
# 返回下一个符合条件的向量批次
(gdb) p *p_out_batch
$5 = {<BaseObject> = {<No data fields>}, m_rows = 1, m_cols = 5, m_checkSel = false, m_sel = 0x7f15b30505a0, m_arr = 0x7f15b9b27d58, m_sysColumns = 0x0,m_pCompressBuf = 0x0}
相关文章:
【OpenGauss源码学习 —— 列存储(ColumnTableSample)】
执行算子(ColumnTableSample) 概述ColumnTableSample 类ColumnTableSample::ColumnTableSample 构造函数ColumnTableSample::~ColumnTableSample 析构函数ExecCStoreScan 函数ColumnTableSample::scanVecSample 函数ColumnTableSample::getMaxOffset 函数…...
【开源】基于JAVA的校园二手交易系统
项目编号: S 009 ,文末获取源码。 \color{red}{项目编号:S009,文末获取源码。} 项目编号:S009,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 二手商品档案管理模…...
)
C 语言结构体(struct)
C 语言结构体(struct) 在本教程中,您将学习C语言编程中的结构类型。您将借助示例学习定义和使用结构。 在C语言编程中,有时需要存储实体的多个属性。 实体不必仅具有一种类型的所有信息。 它可以具有不同数据类型的不同属性。 C 数组允许定义可存储相…...

Linux:zip包的压缩与解压
压缩文件: zip命令 语法: zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][-b <工作目录>][-ll][-n <字尾字符串>][-t <日期时间>][-<压缩效率>][压缩文件][文件...][-i <范本样式>][-x <范本样式>] 补充说明:zi…...

Linux 时区设置
对于服务器来说,linux的时区影响着运行之上的数据库和后端程序的时区 应该和数据库和后端及其他程序的时区保持一致 其他相关时区的设置 pgsql时区设置: php时区设置: 1.显示当前的时间和时区 date结果类似下面,图中显示的是ut…...
Linux本地WBO创作白板部署与远程访问
文章目录 前言1. 部署WBO白板2. 本地访问WBO白板3. Linux 安装cpolar4. 配置WBO公网访问地址5. 公网远程访问WBO白板6. 固定WBO白板公网地址 前言 WBO在线协作白板是一个自由和开源的在线协作白板,允许多个用户同时在一个虚拟的大型白板上画图。该白板对所有线上用…...
leetcode刷题日记:205. Isomorphic Strings(同构字符串)
205. Isomorphic Strings(同构字符串) 对于同构字符串来说也就是对于字符串s与字符串t,对于 s [ i ] s[i] s[i]可以映射到 t [ i ] t[i] t[i],同时对于任意 s [ k ] s [ i ] s[k]s[i] s[k]s[i]都有 s [ k ] s[k] s[k]映射到 t [ k ] t[k] t[k],则 t [ k ] t [ i …...
Autox.js和Auto.js4.1.1手机编辑器不好用我自己写了一个编辑器
功能有 撤销 重做 格式化 跳转关键词 下面展示一些 内联代码片。 "ui"; ui.layout( <drawer id"drawer"><vertical><appbar><toolbar id"toolbar"title""h"20"/></appbar><horizontal b…...

docker logs 如何使用grep检索
无法使用docker logs <container> | grep xxx 这是因为管道仅对stdout有效,如果容器将日志记录到stderr,这种情况就会发生,这时可以尝试这样写 docker logs <container id> 2>&1 | grep xxx...
)
【教3妹学编辑-mysql】详解join(内连接、外连接、交叉连接等)
内连接、外连接、交叉连接、笛卡尔积 内连接(inner join):取得两张表中满足存在连接匹配关系的记录。外连接(outer join):不只取得两张表中满足存在连接匹配关系的记录,还包括某张表(或两张表)中不满足 匹配关系的记录。交叉连接(cross join):显示两张表所有记录一…...
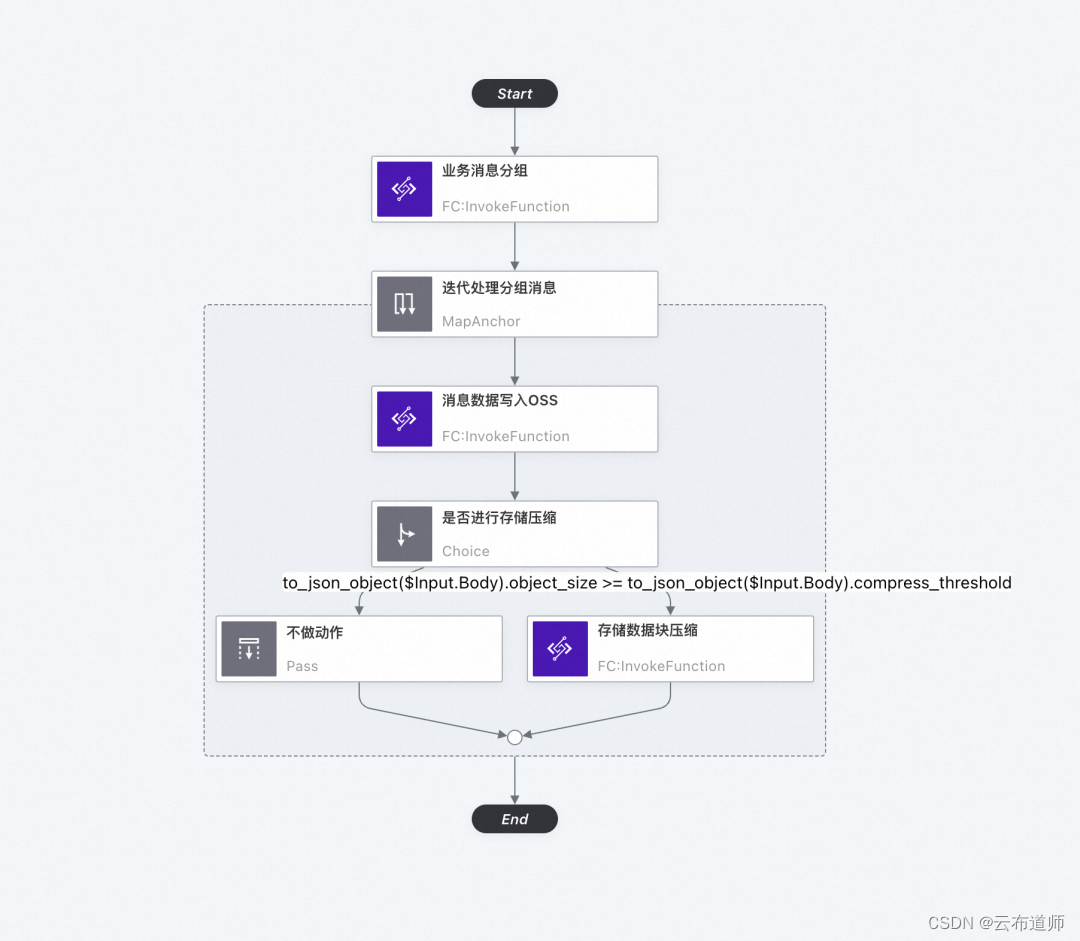
云工作流 CloudFlow 重磅发布,流程式开发让云上应用构建更简单
云布道师 为了让企业和开发者更快速、便捷地进行云上开发,阿里云重磅发布云工作流(CloudFlow),它是一款强大的面向开发者的流程编排开发工具,全托管、高并发、高可用,帮助用户简化和自动化复杂的云上业务流…...

基于单片机GPS轨迹定位和里程统计系统
**单片机设计介绍, 基于单片机GPS轨迹定位和里程统计系统 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 一个基于单片机、GPS和里程计的轨迹定位和里程统计系统可以被设计成能够在移动的交通工具中精确定位车辆的位置…...

go 适配器模式
适配器模式用于转换一种接口适配另一种接口。 实际使用中Adaptee一般为接口,并且使用工厂函数生成实例。 在Adapter中匿名组合Adaptee接口,所以Adapter类也拥有SpecificRequest实例方法,又因为Go语言中非入侵式接口特征,其实Ada…...
蓝桥杯物联网_STM32L071_1_CubMxkeil5基础配置
CubMx配置: project工程中添加.h和.c文件: keil5配置: 运行: 代码提示与解决中文乱码:...
如果文件已经存在与git本地库中,配置gitignore能否将其从git库中删除
想把项目的前后台代码放到同一个git仓库管理,由于未设置.gitignore,就使用vscode做stage操作(相当于git add . 命令 其中【.】点表示全部文件),观察将要入库的文件发现,node_modules、target、.idea、log等…...

枚举 小蓝的漆房
题目 思路 核心思想是枚举 首先利用set记录每一种颜色 然后依次从set取出一种颜色作为targetColor,遍历房子 如果当前房子的颜色和targetColor不相同,就以当前房子为起点,往后长度为k的区间都涂成targetColor,并且需要的天数递增…...

【设计模式】行为型设计模式
行为型设计模式 文章目录 行为型设计模式一、概述二、责任链模式(Chain of Responsibility Pattern)三、命令模式(Command Pattern)四、解释器模式(Interpreter Pattern)五、迭代器模式(Iterato…...

Docker部署FLASK Unicorn并配置Nginx
1. 安装相关依赖 flask3.0.0 pymysql1.1.0 #我自己需要的 flask_cors4.0.0 gunicorn21.2.0 gevent23.9.12. 配置Gunicorn 新建gunicorn.conf.py bind 0.0.0.0:5418 # 绑定的IP地址和端口 workers 8 # 同时执行的进程数,推荐为当前CPU个数*21 worker_class&qu…...
pytorch的backward()的底层实现逻辑
自动微分是一种计算张量(tensors)的梯度(gradients)的技术,它在深度学习中非常有用。自动微分的基本思想是: 自动微分会记录数据(张量)和所有执行的操作(以及产生的新张…...
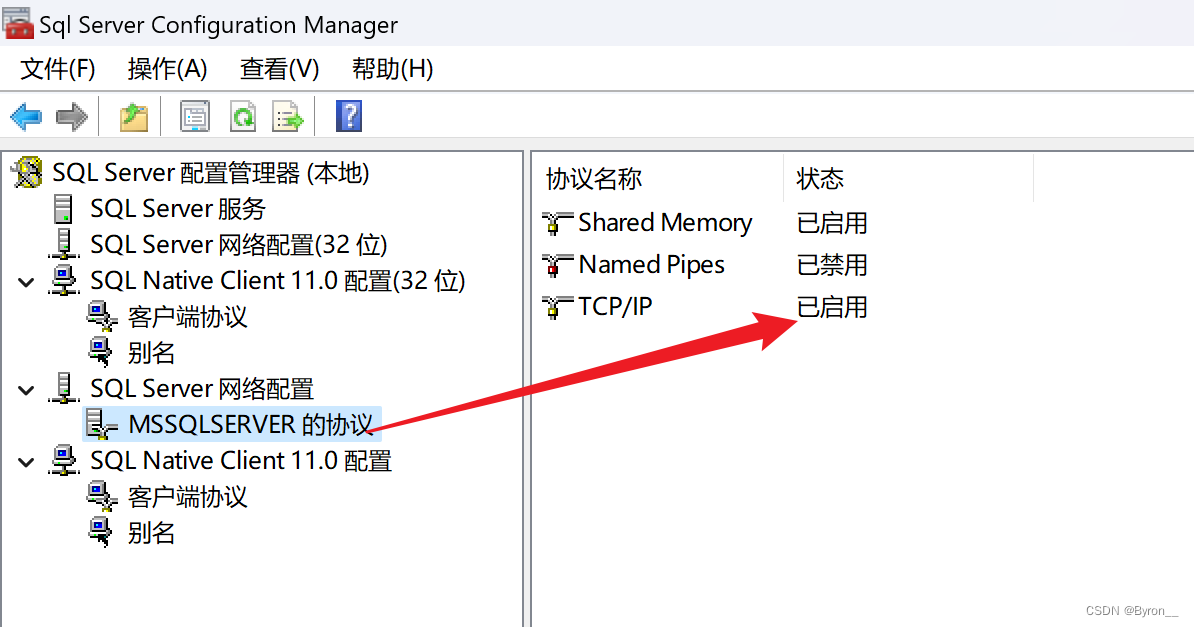
SqlServer_idea连接问题
问题描述: sqlServer安装之后可以使用navicat进行连接idea使用账户密码进行登录连接失败 问题解决: 先使用sqlServer管理工具进行登录 使用window认证连接修改账户密码 启用该登录名 这时idea还是无法连接,还需要如下配置 打开sqlserve…...

CANN/ops-cv最近邻上采样算子
UpsampleNearest 【免费下载链接】ops-cv 本项目是CANN提供的图像处理、目标检测相关的算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-cv 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DTAtlas A3 训练系列产品/Atlas A3 …...

大语言模型赋能人文社科研究:混合量化设计框架与实践指南
1. 项目概述:当“文科”遇见“大模型”“大语言模型赋能人文社科研究”这个标题,乍一听可能有点“跨界”的意味。在很多人印象里,人文社科研究——无论是历史学、社会学、文学还是哲学——其核心是思辨、诠释与批判,是“文科生”在…...
TokenTracker:基于事件监听的以太坊代币转账实时追踪工具实战
1. 项目概述与核心价值最近在搞一个涉及链上数据分析的小项目,需要实时追踪特定代币的链上转账记录。一开始想着直接用区块浏览器的API,但试了几个发现要么有频率限制,要么数据不够实时,要么就是没法按我想要的粒度(比…...

CANN ops-fft算子开发快速入门
算子开发快速入门:基于ops-fft仓 【免费下载链接】ops-fft ops-fft 是 CANN (Compute Architecture for Neural Networks)算子库中提供 FFT 类计算的基础算子库,采用模块化设计,支持灵活的算子开发和管理。 项目地址…...

CANN/catlass aclnn接口算子接入示例
basic_matmul_aclnn example 【免费下载链接】catlass 本项目是CANN的算子模板库,提供NPU上高性能矩阵乘及其相关融合类算子模板样例。 项目地址: https://gitcode.com/cann/catlass aclnn接口是CANN软件栈一直沿用的接口,msOpGen工具是CANN提供可…...

基于Signal协议自建去中心化安全通信服务:Signal-Bastion部署指南
1. 项目概述:构建一个去中心化的安全通信堡垒最近在折腾一个挺有意思的项目,叫 Signal-Bastion。这名字一听就很有感觉,“Bastion”是堡垒、要塞的意思,而“Signal”则指向了那个以安全著称的即时通讯应用。所以,这个项…...

在昇腾训练平台上适配Hunyuan3D 2.0 模型的推理
在昇腾训练平台上适配Hunyuan3D 2.0 模型的推理 【免费下载链接】cann-recipes-embodied-intelligence 本项目针对具身智能业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-embodied-intelligence …...

CANN / cann-recipes-infer: NPU DeepSeek-V3.2-Exp Ascend C 融合算子优化
NPU DeepSeek-V3.2-Exp Ascend C 融合算子优化 【免费下载链接】cann-recipes-infer 本项目针对LLM与多模态模型推理业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-infer 面向 DeepSeek-V3.2-Exp…...

CANN/ops-cv算子跨平台迁移指导
算子跨平台迁移指导 【免费下载链接】ops-cv 本项目是CANN提供的图像处理、目标检测相关的算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-cv 本指南介绍算子在多平台间迁移的适配要点与方案。以算子从Atlas A2系列迁移至Ascend …...

CANN/HCOMM通信域配置
HcclCommConfig 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 功能说明 初始化具有特定配置的通信域时,此数据类…...