MySQL优化-查询优化
MySQL查询优化是指通过调整查询语句、优化表结构、使用索引等方式,提高查询性能的过程。以下是MySQL查询优化的几种方法:
1. 尽量避免使用SELECT*
SELECT *会查询表中的所有列,包括不需要的列,这会消耗大量的计算资源和时间。而且,如果使用了SELECT *,MySQL无法使用索引优化查询,因为MySQL无法确定要查询的列是哪些。这将导致MySQL必须对所有列进行扫描,这将使查询变得非常缓慢。
如果必须使用它,可以考虑以下几个优化策略:
- 明确指定要查询的列,而不是使用SELECT *。
- 只查询需要的列,避免查询不需要的列。
- 使用索引来优化查询,以避免对所有列进行扫描。
- 使用缓存来减少查询的开销。
假设有一个名为users的表,包含id、name、age、email等列。如果使用SELECT*查询这个表,会返回所有列的值,即使只需要其中的一部分。而如果只查询id和name列,可以使用:
SELECT id, name FROM users;
这样只会返回需要的列,免了冗余数据的产生,提高了查询效率。
2. 尽量避免使用LIKE ‘%value%’
LIKE ‘%value%’需要对所有数据进行扫描,这会消耗大量的计算资源和时间。如果数据量很大,这些操作可能会变得非常缓慢。
另一方面,如果使用了LIKE ‘%value%’,MySQL无法使用索引优化查询,因为MySQL不知道要匹配的字符串在哪个位置。这将导致MySQL必须对所有数据进行扫描,这将使查询变得非常缓慢。
因此,为了优化MySQL查询性能,我们应该尽量避免使用LIKE ‘%value%’。如果必须使用它,可以考虑以下几个优化策略:
- 尽可能缩小查询结果集的大小,以减少扫描的开销。
- 尽可能使用索引来优化查询,以避免MySQL无法使用索引优化查询。
- 尽可能使用前缀匹配,例如LIKE ‘value%’或LIKE ‘%value’,这样MySQL可以使用索引优化查询。
- 尽可能使用全文索引,例如使用MySQL的全文索引功能,以避免LIKE ‘%value%’导致的性能问题。
例如,对于一个文章表,应该使用LIKE 'value%'来提高搜索效率。
SELECT * FROM article WHERE title LIKE 'mysql%';
3. 尽量避免使用NOT IN和NOT EXISTS
一方面,NOT IN和NOT EXISTS需要对所有数据进行扫描,这会消耗大量的计算资源和时间。如果数据量很大,这些操作可能会变得非常缓慢。
另一方面,如果使用了NOT IN和NOT EXISTS,MySQL无法使用索引优化查询,因为MySQL无法确定要查询的数据是否在指定的列表或子查询中。这将导致MySQL必须对所有数据进行扫描,这将使查询变得非常缓慢。
因此,为了优化MySQL查询性能,我们应该尽量避免使用NOT IN和NOT EXISTS。如果必须使用它们,可以考虑以下几个优化策略:
-
尽可能使用IN和EXISTS,因为它们可以使用索引优化查询。
-
尽可能缩小查询结果集的大小,以减少扫描的开销。
-
尽可能使用JOIN操作,因为它可以使用索引优化查询,并且可以在查询结果集上执行其他操作。
-
尽可能使用子查询的内部表连接,因为它可以使用索引优化查询,并且可以在查询结果集上执行其他操作。
例如,对于一个订单表和一个产品表,可以使用LEFT JOIN来查询没有订单的产品。
SELECT p.product_id, p.product_name
FROM product p
LEFT JOIN order_detail od ON p.product_id = od.product_id
WHERE od.order_id IS NULL;
4. 尽量避免使用ORDER BY和GROUP BY
ORDER BY和GROUP BY会进行全表扫描,从而增加查询的时间和资源消耗。我们应该尽可能避免使用ORDER BY和GROUP BY。如果必须使用它们,可以考虑以下几个优化策略:
- 尽可能缩小查询结果集的大小,以减少排序和分组的开销。
- 尽可能使用索引来优化查询,以避免MySQL无法使用索引优化查询。
- 尽可能使用覆盖索引,以避免MySQL需要进行回表操作。
- 尽可能使用LIMIT来限制查询结果集的大小,以减少排序和分组的开销。
- 尽可能使用更快的排序算法,例如使用索引排序而不是文件排序。
假设我们有一个名为students的表,其中包含了学生的ID、姓名、年龄、成绩等信息。我们需要查询年龄大于18岁的学生的姓名和成绩,并按照成绩从高到低进行排序。可以使用以下SQL语句:
SELECT name, score FROM students WHERE age > 18 ORDER BY score DESC;
这个查询语句中,我们使用了WHERE来筛选出年龄大于18岁的学生,然后使用ORDER BY按照成绩从高到低进行排序。这个查询语句在数据量较小的情况下可能没有问题,但是在数据量较大的情况下也会导致查询性能下降,因为MySQL需要对所有符合条件的学生进行排序。
为了避免这个问题,我们可以尝试使用索引来加速查询。可以为age和score两个字段分别创建索引,如下所示:
CREATE INDEX idx_age ON students(age);
CREATE INDEX idx_score ON students(score);
然后修改查询语句,如下所示:
SELECT name, score FROM students USE INDEX (idx_score) WHERE age > 18 ORDER BY score DESC;
这个查询语句中,我们使用了USE INDEX来指定使用idx_score索引来加速查询避免了MySQL对所有符合条件的学生进行排序的问题。
需要注意的是,使用索引来加速查询也并不是适用于所有情况的。在某些情况下,使用索引可能会导致查询性能更差。因此,在进行优化时需要根据具体情况进行权衡和测试。
5. 尽量使用连接(JOIN)来代替子查询(Sub-Queries)
尽量使用连接(JOIN)来代替子查询(Sub-Queries)是一个常见的优化策略。这是因为子查询通常会比连接慢,而且在某些情况下,它们可能会导致性能问题。连接是一种将两个或多个表中的数据合并在一起的方式。而子查询是一种查询语句嵌套在另一个查询语句中的方式。在使用子查询时,MySQL需要先执行子查询,然后再将其结果作为参数传递给外部查询。这种操作会增加查询的复杂度和执行时间。
相比之下,连接通常更快,因为它可以在一次查询中将两个或多个表中的数据合并在一起。这种操作可以减少查询的复杂度和执行时间。
当需要查询多个表中的数据时,尽量使用连接而不是子查询。但是,对于一些特殊的情况,使用子查询可能会更加方便和有效。因此,在实际使用中,需要根据具体情况选择最适合的优化策略。
假设我们有两个表:学生表(students)和成绩表(scores)。学生表包含学生的ID和姓名,成绩表包含学生的ID和成绩。
现在我们需要查询所有成绩大于90分的学生的姓名。我们可以使用连接和子查询两种方式来实现这个查询。
使用子查询:
SELECT name
FROM students
WHERE id IN (SELECT student_id FROM scores WHERE score > 90);
使用连接:
SELECT students.name
FROM students
INNER JOIN scores ON students.id = scores.student_id
WHERE scores.score > 90;
这两种方式都可以得到正确的结果,但是使用连接的查询通常会比使用子查询的查询更快。因为连接可以在一次查询中将两个表中的数据合并在一起,而子查询需要先执行子查询,然后再将其结果作为参数传递给外部查询。所以在这个例子中,使用连接可以减少查询的复杂度和执行时间,从而提高查询的效率。
6. 尽量使用联合(UNION)来代替手动创建的临时表
当我们需要在查询中使用临时表时,MySQL会自动创建一个临时表来存储查询结果。这种方法虽然可以实现我们的查询需求,但是会增加系统的负担,降低查询的效率。
相比之下,使用UNION操作可以将多个查询的结果合并在一起,从而避免了手动创建临时表的过程。这种方法通常比手动创建临时表更高效,因为它可以减少系统的负担并提高查询的速度。
需要注意的是,UNION操作也有一些限制和注意事项。例如,UNION操作会去重,如果需要保留重复的行,则需要使用UNION ALL操作。此外,UNION操作的两个查询必须具有相同的列数和列类型,否则会出现错误。
总之,在MySQL优化中,使用UNION操作来代替手动创建临时表是一种有效的优化方法,可以提高查询的效率并减少系统的负担。
假设我们有两个表,分别是employees和customers,我们想要将这两个表中的数据合并起来,并统计每个部门的员工和客户数量。可以使用以下SQL语句:
SELECT department, COUNT(*) as count
FROM (SELECT departmentFROM employeesUNION ALLSELECT departmentFROM customers
) t
GROUP BY department;
这个SQL语句中,我们使用了UNION ALL操作将employees表和customers表中的department字段合并起来,然后再使用GROUP BY对department字段进行分组统计。这样可以避免手动创建临时表,提高查询性能。
7. 尽量使用索引
使用索引可以加速数据的查找,从而提高查询性能。关于索引以及其优化详见我的另一个博客:MySQL优化-索引优化。下面举一个例子来说明如何使用索引进行优化。
假设我们有一个名为users的表,其中包含了用户的ID、姓名、年龄等信息。我们需要查询年龄为21岁的用户,可以使用以下SQL语句:
SELECT * FROM users WHERE age = 21;
如果users表中的数据量非常大,那么这个查询可能会非常耗时。为了提高查询性能,我们可以在age字段上创建一个索引。可以使用以下SQL语句来创建索引:
CREATE INDEX idx_age ON users(age);
这个SQL语句中,我们使用了CREATE INDEX语句来创建一个名为idx_age的索引,它是基于age字段创建的。
创建索引后,我们再次执行查询语句,可以发现查询速度大大提高了。这是因为MySQL在查询时会使用索引来加速数据的查找,从而提高查询性能。
需要注意的是,索引并不是越多越好。过多的索引会增加数据插入、更新和删除的时间,同时也会占用更多的磁盘空间。因此,在创建索引时需要权衡索引的数量和性能需求,选择合适的索引策略。如果使用的是复合索引,还得考虑最左前缀匹配原则,否则索引起不到理想的效果。
8. 尽量避免在where 子句中的 “=” 左边进行内置函数、算术运算等其他表达式运算
因为MySQL无法将表达式的计算结果与索引中的值进行比较,而是需要对整个表进行扫描,从而导致查询效率低下。
下面举一个例子来说明这个问题。假设我们有一个名为users的表,其中包含了用户的ID、姓名、年龄等信息。我们需要查询年龄为21岁的用户,并且名字的长度为3。可以使用以下SQL语句:
SELECT * FROM users WHERE LENGTH(name) = 3 AND age = 21;
这个查询语句中,我们在WHERE子句中使用了LENGTH函数来计算名字的长度,这就会导致MySQL无法使用索引进行优化。为了避免这个问题,我们可以将LENGTH函数移到SELECT子句中,然后使用别名进行引用,如下所示:
SELECT *, LENGTH(name) AS name_length FROM users WHERE name_length = 3 AND age = 21;
这个查询语句中,我们在SELECT子句中使用了LENGTH函数来计算名字的长度,并使用别名name_length进行引用。然后在WHERE子句中使用了别名name_length来进行筛选,这样就可以避免在WHERE子句中进行函数运算,从而提高查询性能。
需要注意的是,这个优化方法并不是适用于所有情况的。在某些情况下,将函数移到SELECT子句中可能会导致查询性能更差。因此,在进行优化时需要根据具体情况进行权衡和测试。
9. 尽量避免在 where 子句中使用 != 或 <> 操作符
因为这两个操作符会使得查询条件不满足索引最左匹配原则,从而使得查询效率变慢。
举个例子,假设我们有一个名为 students 的表,其中包含了学生的ID、姓名、年龄、成绩等信息。我们需要查询成绩不等于 80 分的学生的姓名和成绩。如果使用 != 或 <> 操作符,查询语句如下:
SELECT name, score FROM students WHERE score != 80;
这个查询语句中,使用了 != 操作符来筛选出成绩不等于 80 分的学生。但是,由于 != 操作符无法使用索引进行优化,MySQL 将不得不扫描整个表来找到符合条件的记录,从而导致查询性能下降。
为了避免这个问题,我们可以使用其他操作符来代替 != 操作符,如下所示:
SELECT name, score FROM students WHERE score < 80 OR score > 80;
这个查询语句中, > 操作符来筛选出成绩不等于 80 分的学生。由于这些操作符可以使用索引进行优化,MySQL 可以快速定位符合条件的记录,从而提高查询性能。
需要注意的是,在某些情况下,使用 != 操作符可能是必要的,但是需要根据具体情况进行权衡和测试。
10. 尽量避免在 where 子句中使用or操作符
因为 OR 操作符会使得查询条件不满足索引最左匹配原则,从而使得查询效率变慢。
举个例子,假设我们有一个表格 students,其中包含了学生的信息,包括姓名和年龄两个字段。如果我们需要查询年龄等于 18 岁或者 20 岁的学生记录,我们可以使用以下 SQL 语句:
SELECT * FROM students WHERE age = 18 OR age = 20;
但是,这个查询语句会导致 MySQL 引擎无法使用 age 字段上的索引来加速查询,因为 OR 操作符会使得查询条件不满足索引最左匹配原则。为了避免这个问题,我们可以使用 IN 操作符来进行查询,例如:
SELECT * FROM students WHERE age IN (18, 20);
这个查询语句可以使用 age 字段上的索引来加速查询,从而提高查询效率。因此,在 MySQL 优化中,尽量避免在 where 子句中使用 OR 操作符是一个很好的实践。总结
查询优化是数据库优化中的一个重要方面,可以提高查询的效率和响应速度,从而提升数据库系统的整体性能。以下是一些查询优化的总结:
-
使用索引:索引可以加速查询的速度,因此需要在经常使用的字段上创建索引,避免在 where 子句中使用不等于避免在 where 子句中使用 or 操作符,避免在 where 子句中使用函数,避免在 where 子句中使用模糊查询。
-
避免全表扫描:尽量避免使用不带条件的 select 语句,因为这会导致数据库执行全表扫描,而且会消耗大量的系统资源。
-
优化 join 操作:join 操作是数据库中经常使用的操作,需要注意 join 的顺序,使用 inner join 代替其他类型的 join,避免在 join 子句中使用 or 操作符。
-
避免使用子查询:子查询可以导致性能问题,尽量避免使用子查询,可以使用 join 操作来代替子查询。
综上所述,以上大部分优化查询的方法都是为了避免全表扫描和尽可能利用索引。查询优化是数据库优化中的一个重要方面。为了提高数据库系统的整体性能,需要从多个方面来考虑和优化。
相关文章:

MySQL优化-查询优化
MySQL查询优化是指通过调整查询语句、优化表结构、使用索引等方式,提高查询性能的过程。以下是MySQL查询优化的几种方法: 1. 尽量避免使用SELECT* SELECT *会查询表中的所有列,包括不需要的列,这会消耗大量的计算资源和时间。而…...

Ubuntu18.04安装Moveit框架
简介 Moveit是一个由一系列移动操作的功能包组成的集成化开发平台,提供友好的GUI,是目前ROS社区中使用度排名前三的功能包,Moveit包含以下三大核心功能,并集成了大量的优秀算法接口: 运动学:KDL,Trac-IK,IKFast...路径规划:OMPL,CHMOP,SBPL..碰撞检测:FCL,PCD... 一、更新功…...

MongoDB——文档增删改查命令使用
MongoDB 文档增删改查 命令操作描述db.collection.insert() db.collection.insert()将单个文档或多个文档插入到集合中db.collection.insertOne()插入文档,3.2 版中的新功能db.collection.insertMany()插入多个文档,3.2 版中的新功能db.collection.update更新或替…...
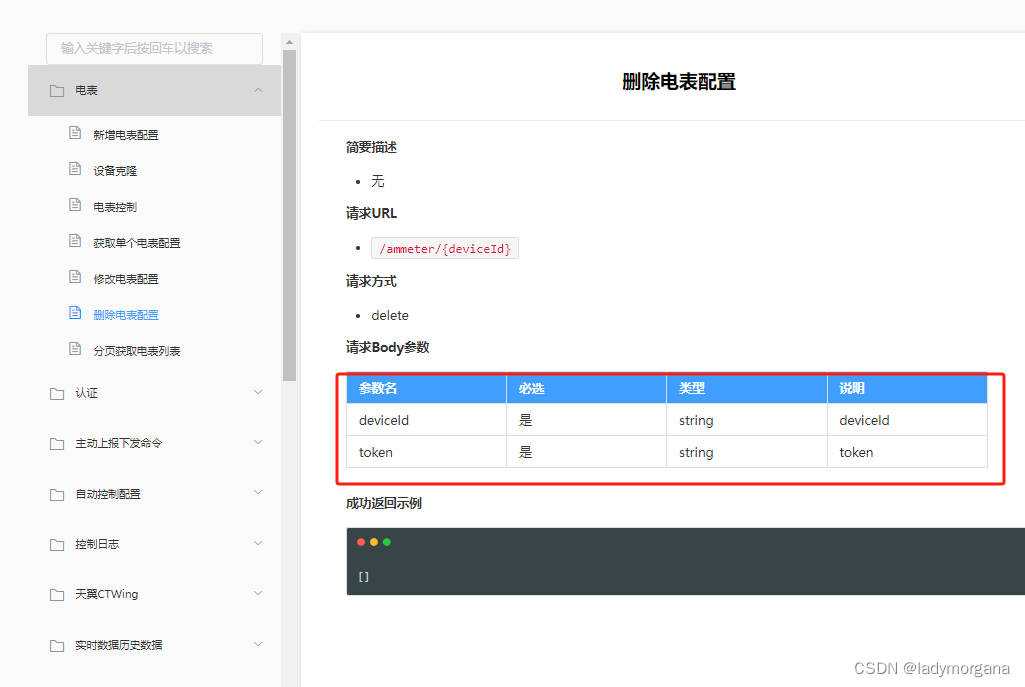
【日常总结】Swagger-ui 导入 showdoc (优雅升级Swagger 2 升至 3.0)
一、场景 环境: 二、存在问题 三、解决方案 四、实战 - Swagger 2 升至 3.0 (Open API 3.0) Stage 1:引入Maven依赖 Stage 2:Swagger 配置类 Stage 3:访问 Swagger 3.0 Stage 4:获取 js…...
OpenCV C++ 图像 批处理 (批量调整尺寸、批量重命名)
文章目录 图像 批处理(调整尺寸、重命名)图像 批处理(调整尺寸、重命名) 拿着棋盘格,对着相机变换不同的方角度,采集十张以上(以10~20张为宜);或者棋盘格放到桌上,拿着相机从不同角度一通拍摄。 以棋盘格,第一个内焦点为坐标原点,便于计算世界坐标系下三维坐标; …...
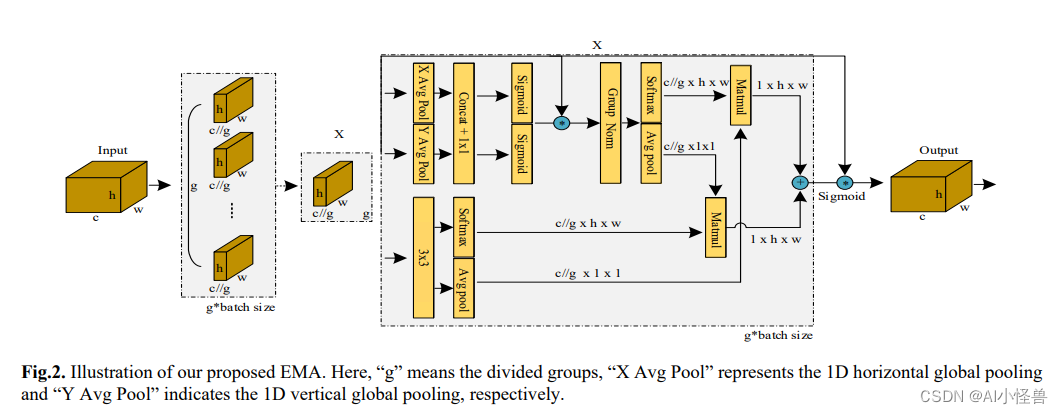
RT-DETR手把手教程,注意力机制如何添加在网络的不同位置进行创新优化
💡💡💡本文独家改进:本文首先复现了将EMA引入到RT-DETR中,并跟不同模块进行结合创新;1)Rep C3结合;2)直接作为注意力机制放在网络不同位置;3)高效…...

qt treeview 删除节点
Qt 中,要删除 QTreeView 中的节点,可以通过操作其模型(QAbstractItemModel)来实现。以下是一个简单的示例,展示如何从 QTreeView 中删除节点。 假设你有一个 QTreeView,它使用了 QStandardItemModel 作为模…...
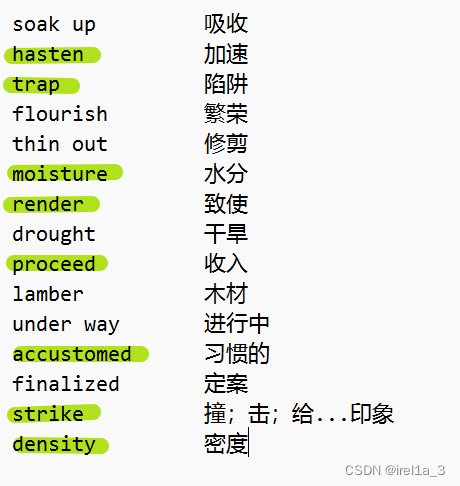
【单词】【2019】
...

Java自动化驱动浏览器搜索稻香
下载最新的Chrome浏览器 查看chrome版本,在浏览器地址栏输入:chrome://version/ 下载对应的浏览器驱动,将其放到一个目录中,我放到了D:/chromedriver-win64 导入对应的依赖【注意:不要导入最新的版本,最…...
、WebSocket、消息队列)
php聊天室通讯系统常用的接口对接函数 curl、file_get_contents()、WebSocket、消息队列
方法有: 1、HTTP请求,可以通过PHP的curl库或者file_get_contents()函数发送HTTP请求来与聊天室接口进行通信; 2、WebSocket协议,可以使用PHP的WebSocket库或者第三方库来与聊天室接口进行对接; 3、使用这些SDK或者包装…...

SQL基础理论篇(九):存储过程
文章目录 简介存储过程的形式定义一个存储过程使用delimiter定义语句结束符存储过程中的三种参数类型流控制语句 存储过程的优缺点参考文献 简介 存储过程Stored Procedure,SQL中的另一个重要应用。 前面说的视图,只能勉强跟编程中的函数相似ÿ…...

申银万国期货通过ZStack Cube信创超融合一体机打造金融信创平台
信创是数字中国建设的重要组成部分,也是数字经济发展的关键推动力量。作为云基础软件企业,云轴科技ZStack产品矩阵全面覆盖数据中心云基础设施,ZStack信创云首批通过可信云《一云多芯IaaS平台能力要求》先进级,是其中唯一兼容四种…...
SquareCTF-2023 Web Writeups
官方wp:CTFtime.org / Square CTF 2023 tasks and writeups sandbox Description: I “made” “a” “python” “sandbox” “”“” nc 184.72.87.9 8008 先nc连上看看,只允许一个单词,空格之后的直接无效了。 flag就在当…...

Docker-compose 安装mysql8
1、编写docker-compose.yml文件 version: 3.8 services:mysql:container_name: mysql8image: mysql:8.0.18restart: alwaysports:- 3306:3306privileged: truevolumes:- $PWD/log:/var/log/mysql- $PWD/conf/my.cnf:/etc/mysql/my.cnf- $PWD/data:/var/lib/mysqlenvironment:M…...

分布式锁实现对比
1、对比 tairzookeper性能高 低可靠性低 高 2、zookeper实现分布式锁 特点: Zookeeper能保证数据的强一致性,用户任何时候都可以相信集群中每个节点的数据都是相同的。 加锁 客户端在ZooKeeper一个特定的节点下创建临时顺序节点&…...
)
Ubuntu 系统上使用 QQ 邮箱的 SMTP 服务器发送邮件,msmtp(已验证)
安装 msmtp sudo apt-get update sudo apt-get install msmtp2 .配置 msmtp nano ~/.msmtprcdefaults auth on tls on tls_starttls on tls_trust_file /etc/ssl/certs/ca-certificates.crt logfile ~/.msmtp.logaccount qq host …...
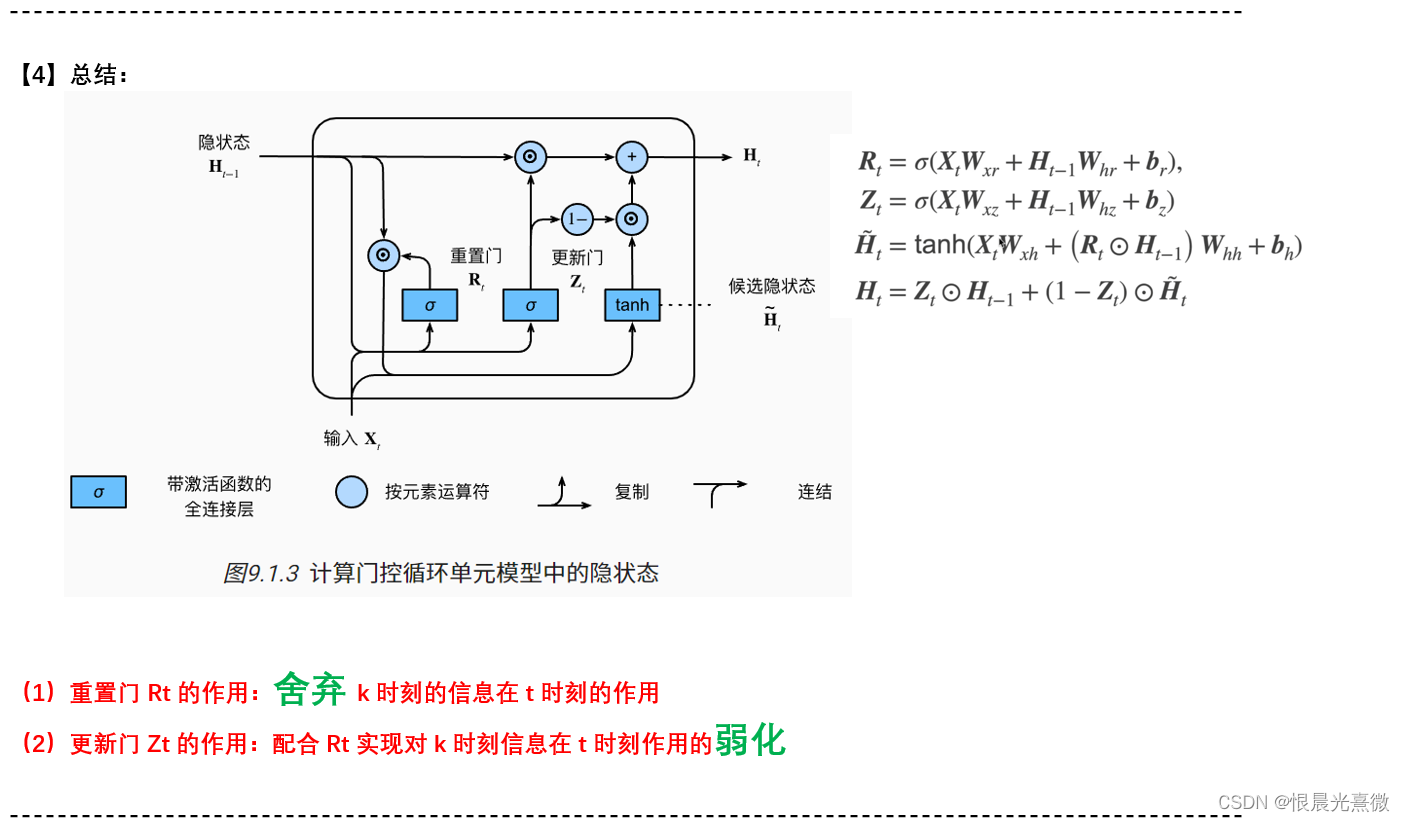
笔记54:门控循环单元 GRU
本地笔记地址:D:\work_file\DeepLearning_Learning\03_个人笔记\3.循环神经网络\第9章:动手学深度学习~现代循环神经网络 a a a a a a a...
数据仓库高级面试题
数仓高内聚低耦合是怎么做的 定义 高内聚:强调模块内部的相对独立性,要求模块内部的元素尽可能的完成一个功能,不混杂其他功能,从而使模块保持简洁,易于理解和管理。 低耦合:模块之间的耦合度要尽可能的…...
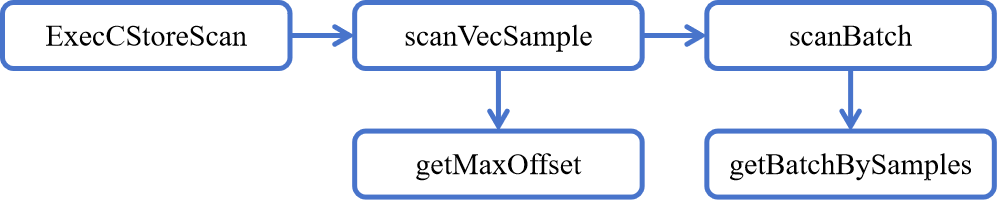
【OpenGauss源码学习 —— 列存储(ColumnTableSample)】
执行算子(ColumnTableSample) 概述ColumnTableSample 类ColumnTableSample::ColumnTableSample 构造函数ColumnTableSample::~ColumnTableSample 析构函数ExecCStoreScan 函数ColumnTableSample::scanVecSample 函数ColumnTableSample::getMaxOffset 函数…...
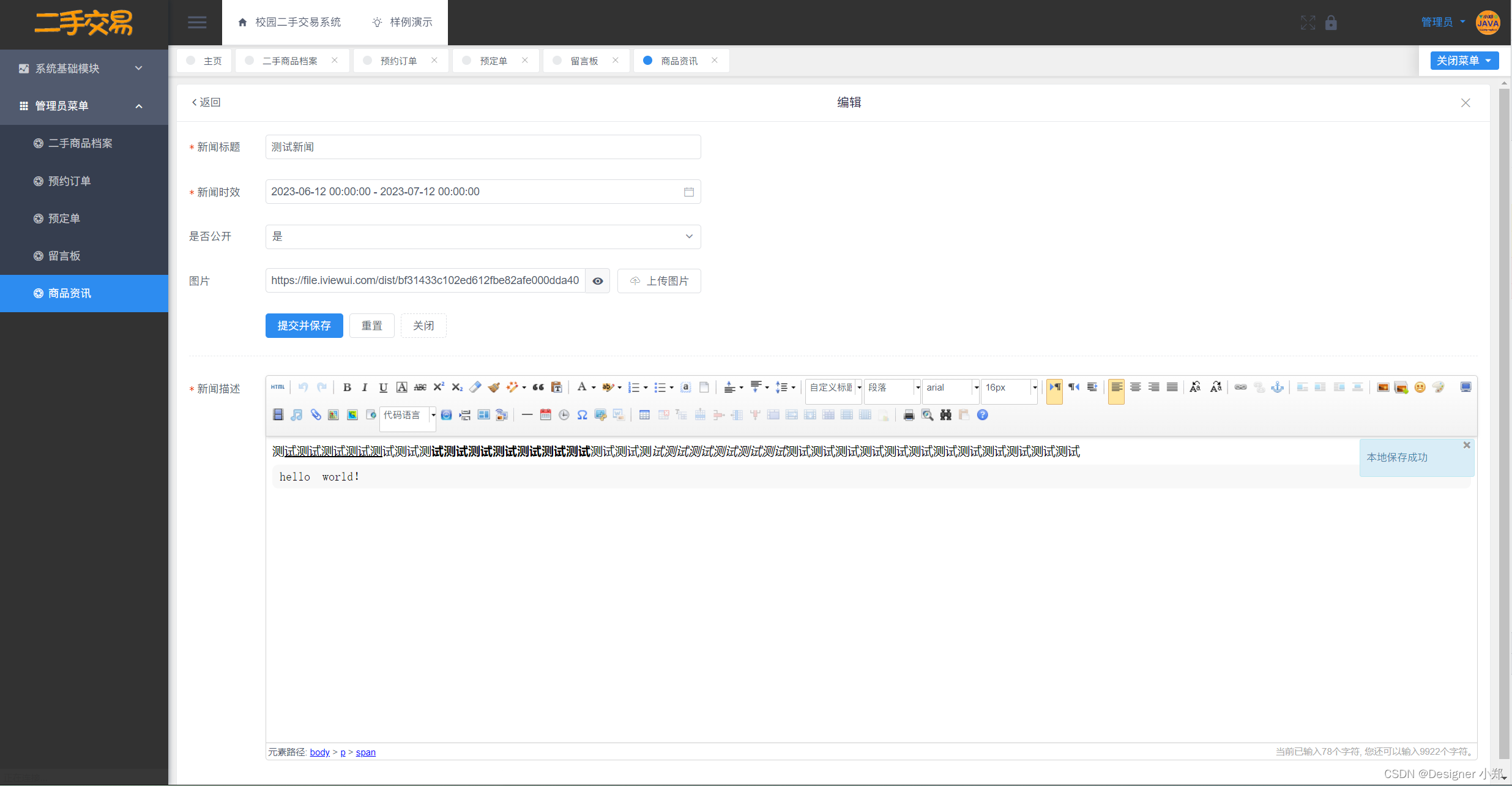
【开源】基于JAVA的校园二手交易系统
项目编号: S 009 ,文末获取源码。 \color{red}{项目编号:S009,文末获取源码。} 项目编号:S009,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 二手商品档案管理模…...

CANN/pto-isa库开发者规则与限制
This file lists some rules and limitations on the implementation of this library for pto-isa developers. 【免费下载链接】pto-isa Parallel Tile Operation (PTO) is a virtual instruction set architecture designed by Ascend CANN, focusing on tile-level operati…...

基于深度学习的YOLOV8目标检测+目标跟踪+车辆测速+车辆行人计数+交互式禁停区域识别+GUI
文章目录YOLOV8目标跟踪与测速(绘制进出线与禁停区域)使用后端运行参数修改可视化界面界面参数测速不准测速不准进出线与禁停区域禁停区域时间禁停区域时间YOLOV8目标跟踪与测速(绘制进出线与禁停区域) 使用 后端运行 python d…...

从开发者视角体验Taotoken文档中Python与Node示例的易用性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从开发者视角体验Taotoken文档中Python与Node示例的易用性 作为一名刚接触大模型API的开发者,我最近注册并尝试了Taoto…...

CANN/Ascend C按位与操作API
And 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/a…...
:混合检索——让召回更全面)
RAG 系列(十):混合检索——让召回更全面
向量检索的一个盲区 假设你的知识库里有一篇文档,内容包含这样一句话: “中文场景推荐使用 BAAI/bge-large-zh-v1.5,向量维度为 1024。” 用户问:“BAAI/bge-large-zh-v1.5 的向量维度是多少?” 你以为这是送分题——…...

Unity性能优化实战:用Magica Cloth的Virtual Deformer把高模裙子顶点数砍掉80%
Unity性能优化实战:Magica Cloth虚拟变形器实现高模裙子顶点数缩减80% 在角色表现力与性能消耗的天平上,技术美术常常需要做出艰难抉择。当项目中的女性角色穿着繁复的裙装时,传统布料模拟方案往往让移动设备GPU不堪重负。Magica Cloth的Virt…...

基于LSP为小众语言打造VSCode智能插件:从架构到实践
1. 项目概述:一个为VSCode量身定制的DLiteScript语言支持插件 如果你在VSCode里折腾过一些不那么“主流”的脚本语言,或者自己设计过领域特定语言,那你肯定遇到过这样的场景:编辑器对这门语言的支持几乎为零,没有语法…...

CursorBeam:开源光标高亮工具,提升演示与操作精准度
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的小工具,叫CursorBeam。乍一看名字,你可能会联想到光标或者光束,实际上,它是一个专门为开发者设计的、能实时高亮显示鼠标光标在屏幕上的精确位置和移动轨迹的开源工具。对…...

语音技能开发框架解析:从事件驱动到插件化实现
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫hermesnest/sister-skill。乍一看这个名字,可能会觉得有点抽象,甚至带点神秘色彩。但如果你对智能语音助手、家庭自动化或者个人AI助理这类话题感兴趣,那这个项目绝对值…...
功率线用共模电感WHACM07A40R101产品介绍)
苏州沃虎电子(VOOHU)功率线用共模电感WHACM07A40R101产品介绍
苏州沃虎电子科技有限公司(品牌:VOOHU)供应的 WHACM07A40R101 是一款高性能功率线用共模电感,采用紧凑的7.06.04.0mm封装,专为电源线电磁干扰(EMI)抑制设计。该产品具备大电流承载能力和优异的共…...