Spring Cloud学习(九)【Elasticsearch 分布式搜索引擎01】
文章目录
- 初识 elasticsearch
- 了解 ES
- 倒排索引
- ES 的一些概念
- 安装es、kibana
- 安装elasticsearch
- 部署kibana
- 分词器
- 安装IK分词器
- ik分词器-拓展词库
- 索引库操作
- mapping 映射属性
- 索引库的 CRUD
- 文档操作
- 添加文档
- 查看、删除文档
- 修改文档
- Dynamic Mapping
- RestClient 操作索引库
- 什么是RestClient
- 创建索引库
- 删除索引库
- 判断索引库是否存在
- RestClient操作文档
- 新增文档
- 查询文档
- 修改文档
- 删除文档
- 批量导入文档
初识 elasticsearch
了解 ES
Elasticsearch 是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch 结合 kibana、Logstash、Beats,也就是 elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch 是 elastic stack 的核心,负责存储、搜索、分析数据。
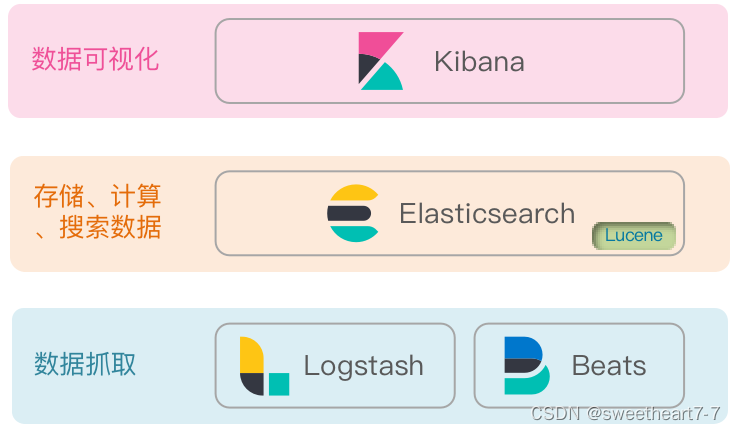
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
Lucene的缺点:
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
2004年Shay Banon基于Lucene开发了Compass
2010年Shay Banon 重写了Compass,取名为Elasticsearch。
官网地址: https://www.elastic.co/cn/
目前最新的版本是:7.12.1
相比与lucene,elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
搜索引擎技术排名:
- Elasticsearch:开源的分布式搜索引擎
- Splunk:商业项目
- Solr:Apache的开源搜索引擎
什么是 elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是 elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是 Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
倒排索引
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:
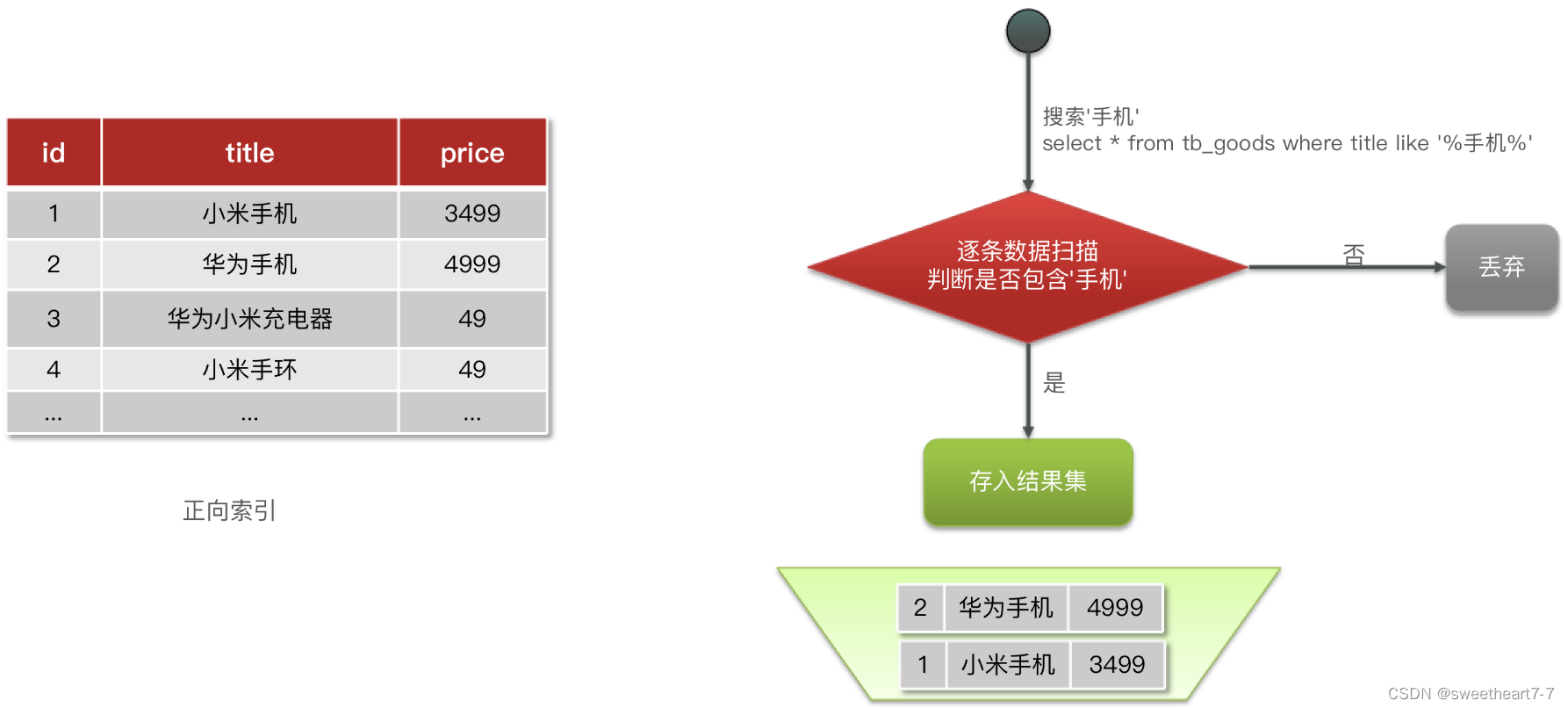
正向索引和倒排索引
elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
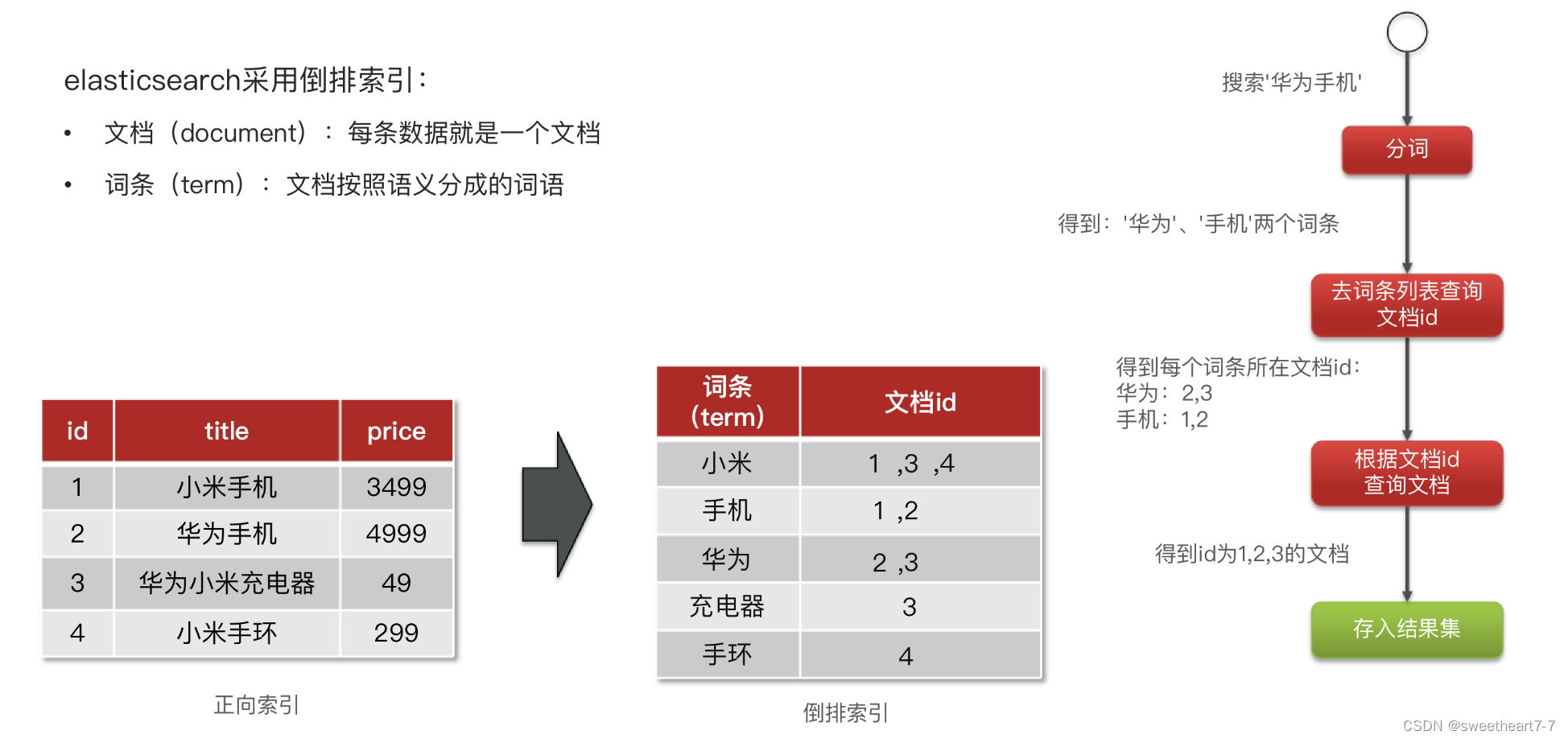
posting list
倒排索引中包含两部分内容:
- 词条词典(Term Dictionary):记录所有词条,以及词条与倒排列表(Posting List)之间的关系,会给词条创建索引,提高查询和插入效率
- 倒排列表(Posting List):记录词条所在的文档id、词条出现频率 、词条在文档中的位置等信息
- 文档id:用于快速获取文档
- 词条频率(TF):文档在词条出现的次数,用于评分
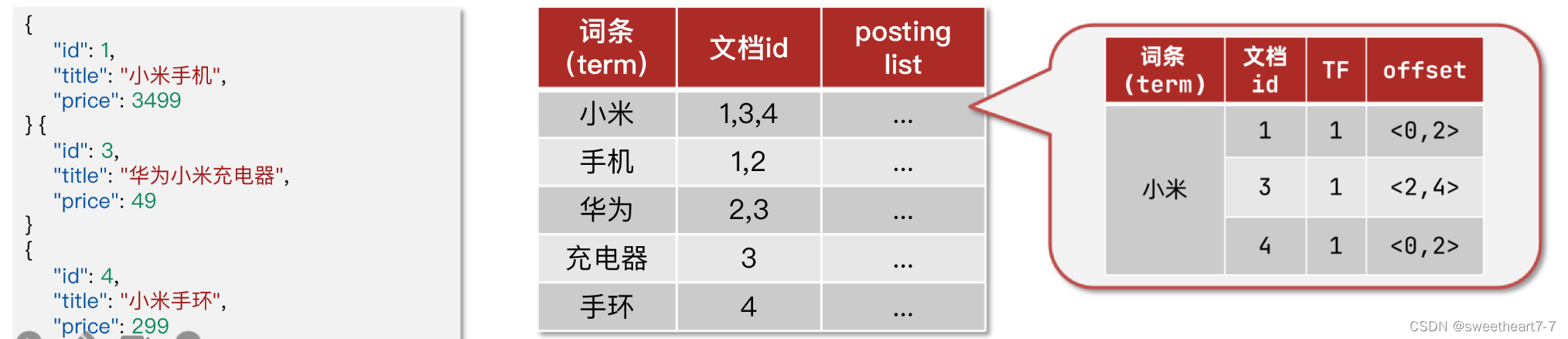
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
ES 的一些概念
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中。

索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束

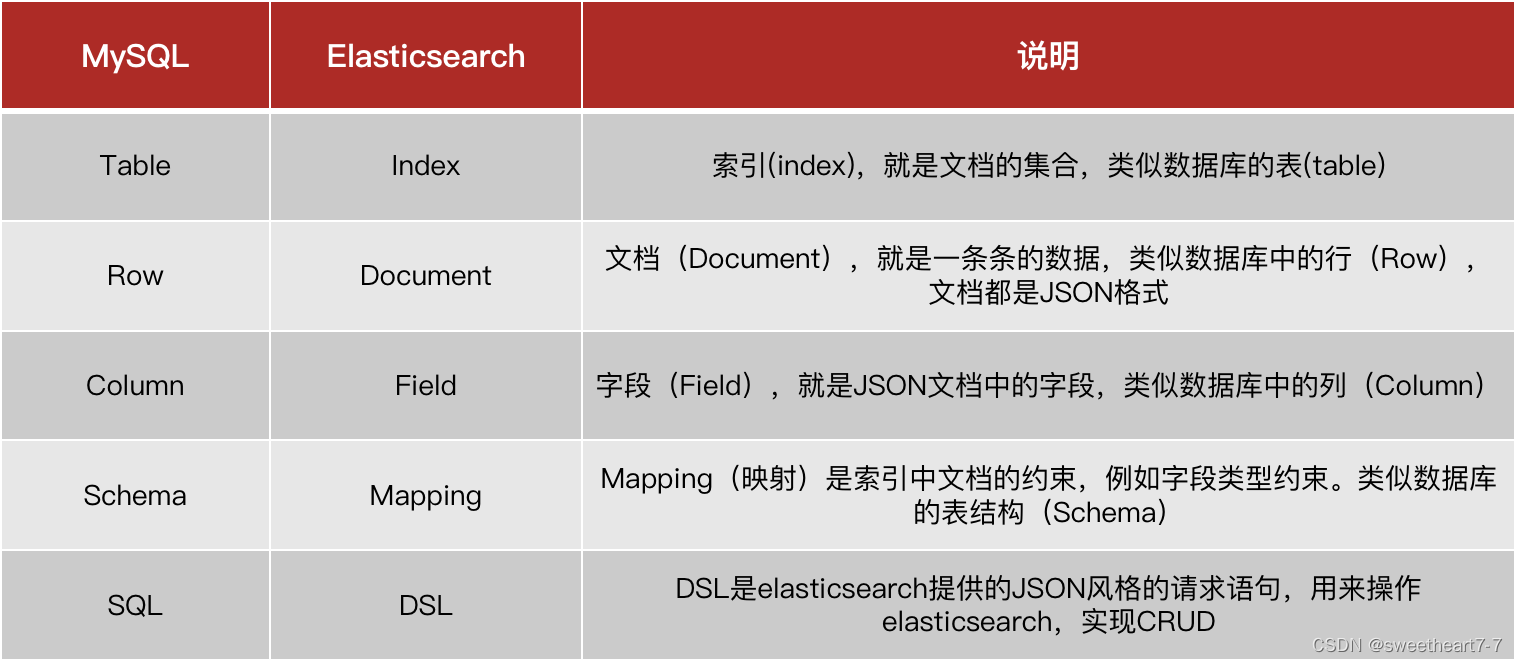
概念对比
架构
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
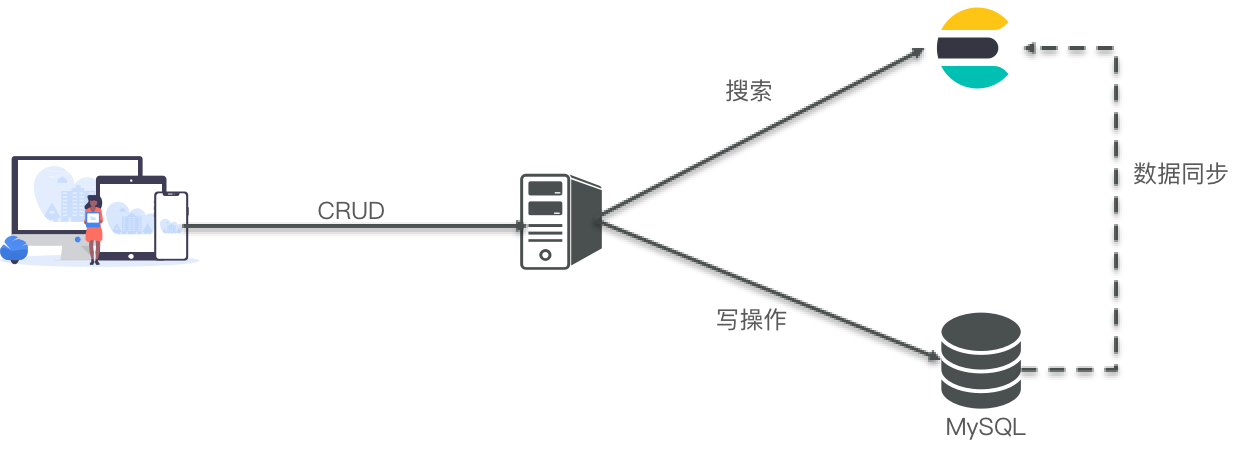
文档:一条数据就是一个文档,es中是Json格式
字段:Json文档中的字段
索引:同类型文档的集合
映射:索引中文档的约束,比如字段名称、类型
elasticsearch与数据库的关系:
- 数据库负责事务类型操作
- elasticsearch 负责海量数据的搜索、分析、计算
安装es、kibana
安装elasticsearch
部署单点es
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
加载镜像
通过 docker pull 命令拉取
elasticsearch
docker pull elasticsearch:7.16.2
arm linux
docker pull arm64v8/elasticsearch:7.16.2
kibana
docker pull kibana:7.16.2
运行
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.16.2
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
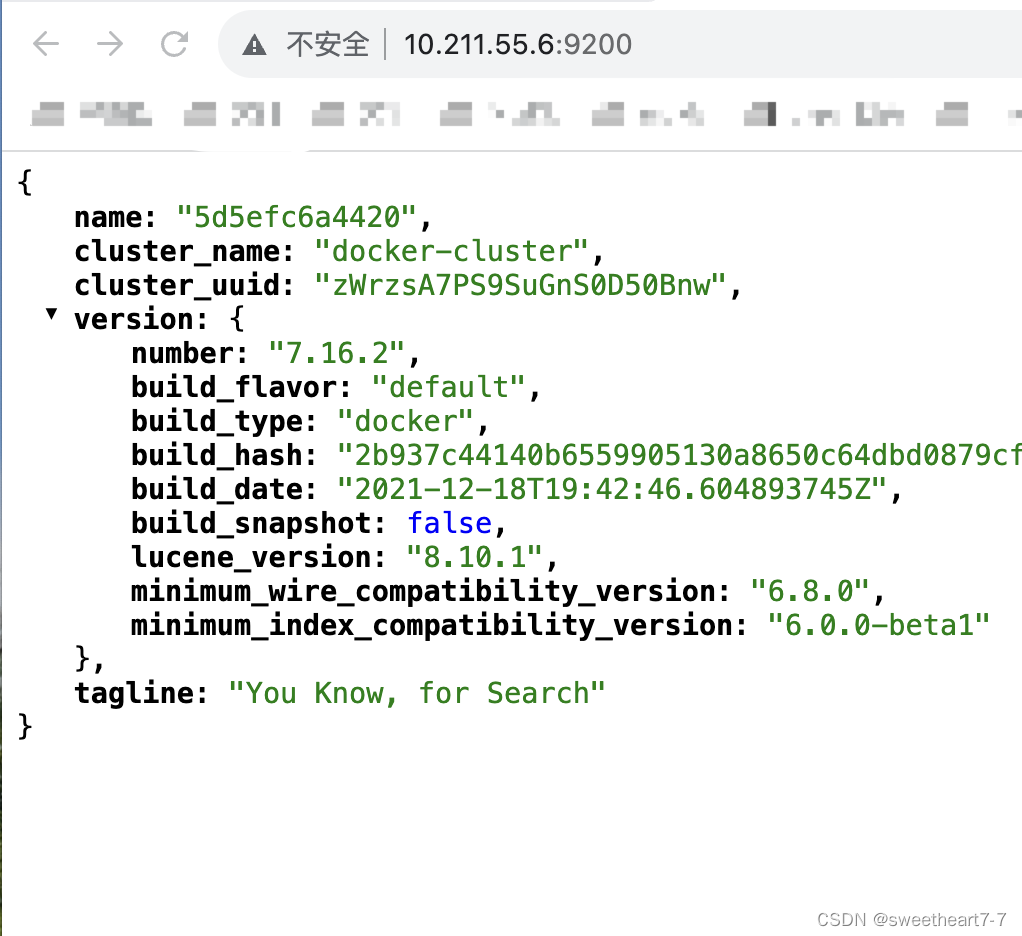
在浏览器中输入:http://10.211.55.6:9200 即可看到elasticsearch的响应结果:
部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
- 部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.16.2
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
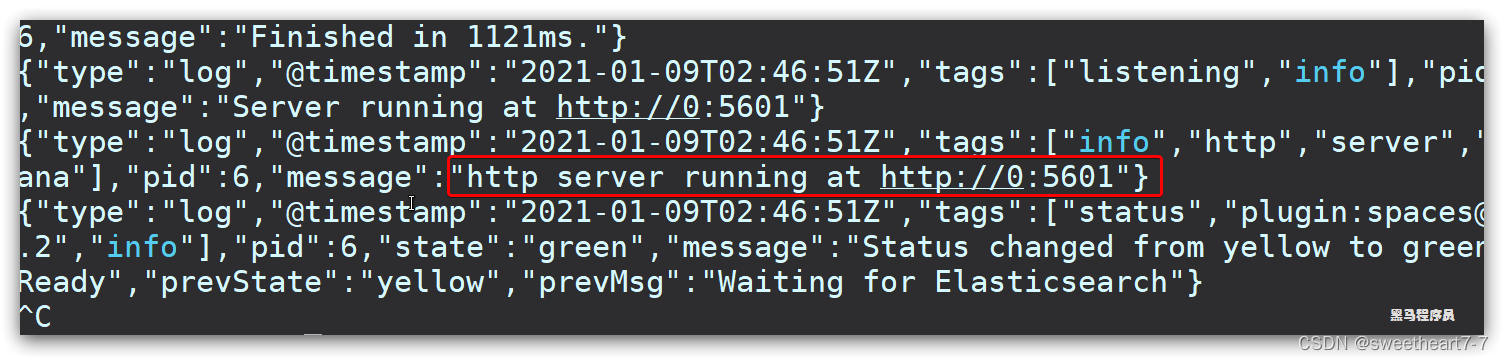
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
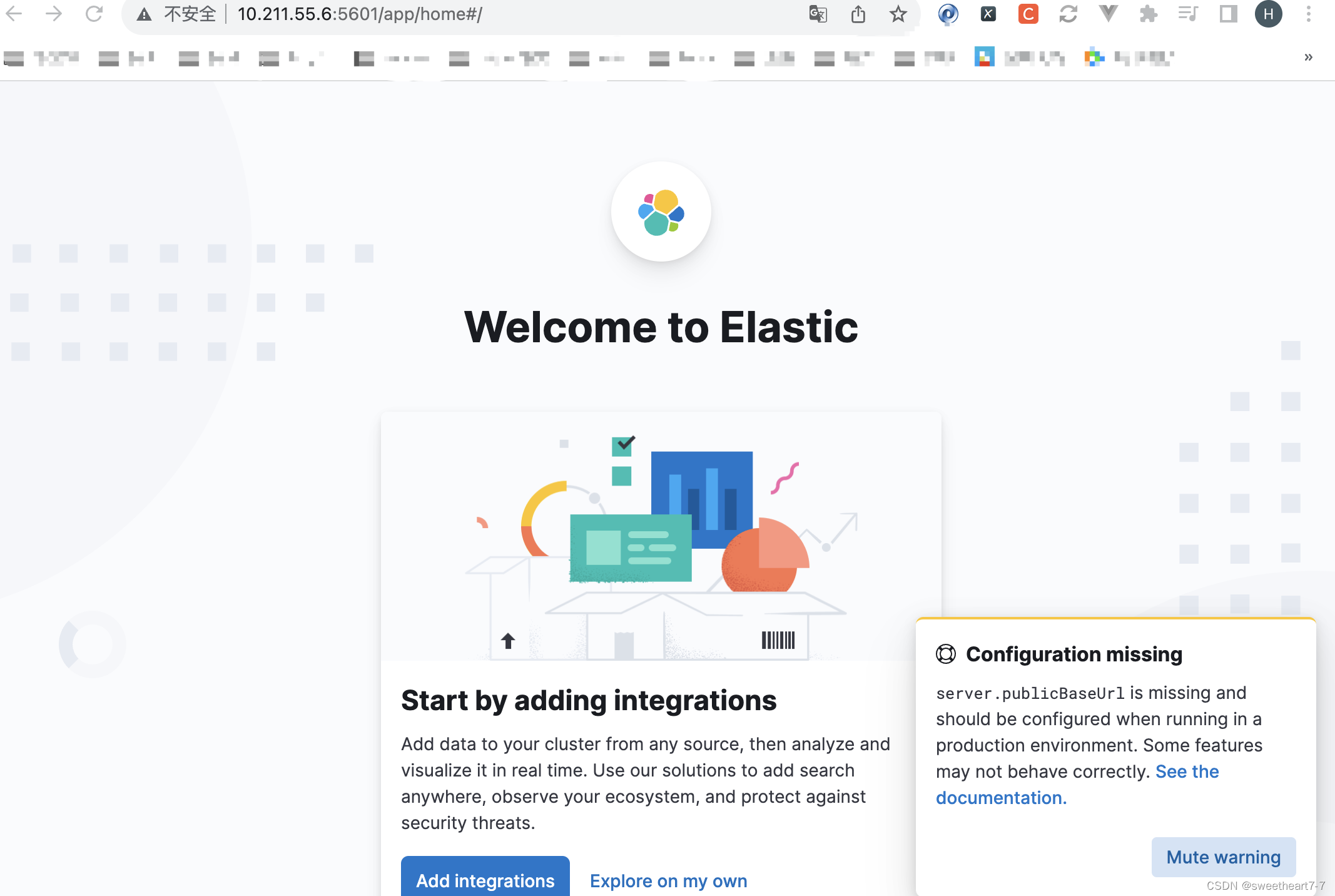
此时,在浏览器输入地址访问:http://10.211.55.6:5601,即可看到结果
- DevTools
kibana 中提供了一个DevTools界面:

这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
POST /_analyze
{"text": "java学习中,勿扰?程序员", "analyzer": "standard"
}
语法说明:
- POST:请求方式
- /_analyze:请求路径,这里省略了http://10.211.55.6/:9200,有kibana帮我们补充
- 请求参数,json风格:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
安装IK分词器
处理中文分词,一般会使用IK分词器。https://github.com/medcl/elasticsearch-analysis-ik
在线安装ik插件
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
离线安装ik插件
1)查看数据卷目录
安装插件需要知道 elasticsearch 的 plugins 目录位置,而我们用了数据卷挂载,因此需要查看 elasticsearch 的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
显示结果:
[{"CreatedAt": "2023-11-17T15:52:19+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
2)解压缩分词器安装包
把ik分词器解压缩,重命名为ik
3)上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data
4)重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
5)测试
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
POST /_analyze
{"text": "java学习中,勿扰?程序员", "analyzer": "ik_max_word"
}
结果
{"tokens" : [{"token" : "java","start_offset" : 0,"end_offset" : 4,"type" : "ENGLISH","position" : 0},{"token" : "学习","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 1},{"token" : "中","start_offset" : 6,"end_offset" : 7,"type" : "CN_CHAR","position" : 2},{"token" : "勿扰","start_offset" : 8,"end_offset" : 10,"type" : "CN_WORD","position" : 3},{"token" : "程序员","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4},{"token" : "程序","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 5},{"token" : "员","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 6}]
}
ik分词器-拓展词库
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的 config 目录中的IkAnalyzer.cfg.xml 文件:

然后在名为 ext.dic 的文件中,添加想要拓展的词语即可:

要禁用某些敏感词条,只需要修改一个ik分词器 目录中的 config 目录中的IkAnalyzer.cfg.xml 文件:

然后在名为 stopword.dic 的文件中,添加想要拓展的词语即可:

分词器的作用是什么?
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
索引库操作
mapping 映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段

mapping常见属性有哪些?
- type:数据类型
- index:是否索引
- analyzer:分词器
- properties:子字段
type常见的有哪些?
- 字符串:text、keyword
- 数字:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
索引库的 CRUD
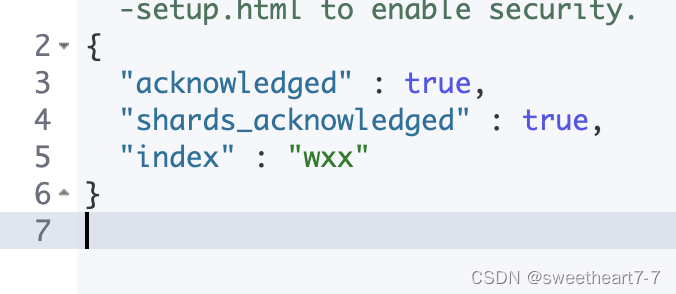
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

# 创建索引库
PUT /wxx
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
查看索引库语法:
GET /索引库名
示例:
GET /wxx
删除索引库的语法:
DELETE /索引库名
示例:
DELETE /wxx
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例:
PUT /wxx/_mapping
{"properties": {"age":{"type": "integer"}}
}
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
文档操作
添加文档
新增文档的 DSL 语法如下:

查看、删除文档
查看文档语法:
GET /索引库名/_doc/文档id
示例:
GET /wxx/_doc/文档id
删除索引库的语法:
DELETE /索引库名/_doc/文档id
示例:
DELETE /wxx/_doc/文档id
修改文档
方式一:全量修改,会删除旧文档,添加新文档

方式二:增量修改,修改指定字段值

文档操作有哪些?
- 创建文档:POST /索引库名/_doc/文档id { json文档 }
- 查询文档:GET /索引库名/_doc/文档id
- 删除文档:DELETE /索引库名/_doc/文档id
- 修改文档:
- 全量修改:PUT /索引库名/_doc/文档id { json文档 }
- 增量修改:POST /索引库名/_update/文档id { “doc”: {字段}}
Dynamic Mapping
当我们向ES中插入文档时,如果文档中字段没有对应的mapping,ES会帮助我们字段设置mapping,规则如下:
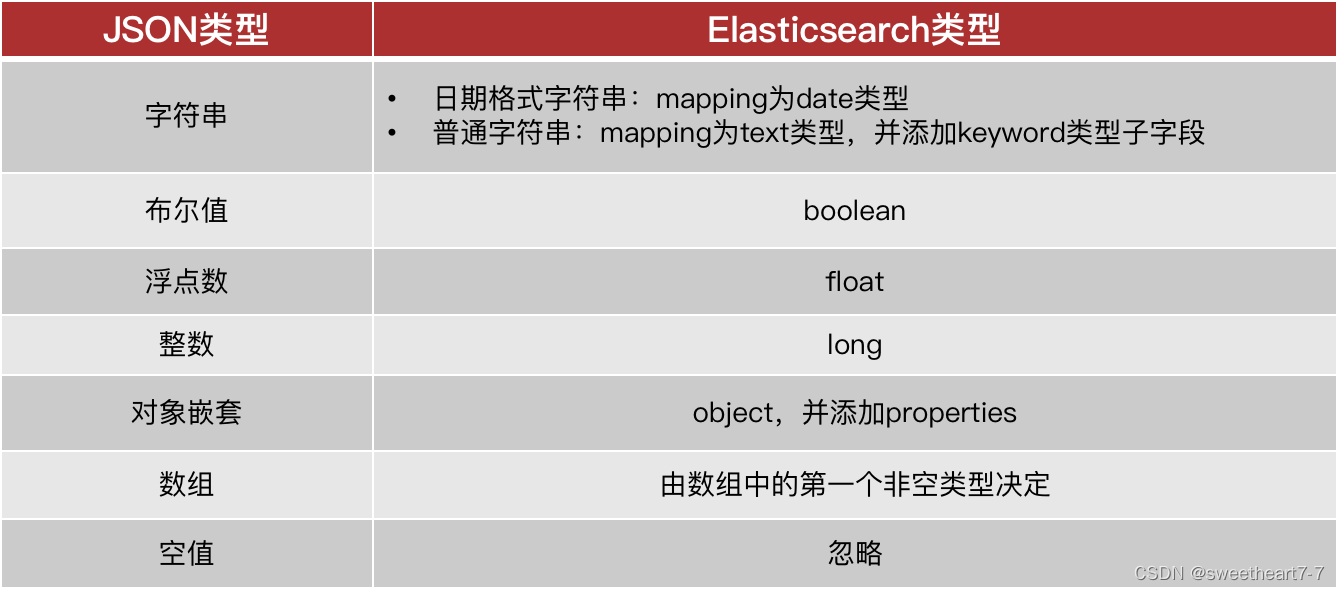
我们插入一条新的数据,其中包含4个没有mapping的字段:
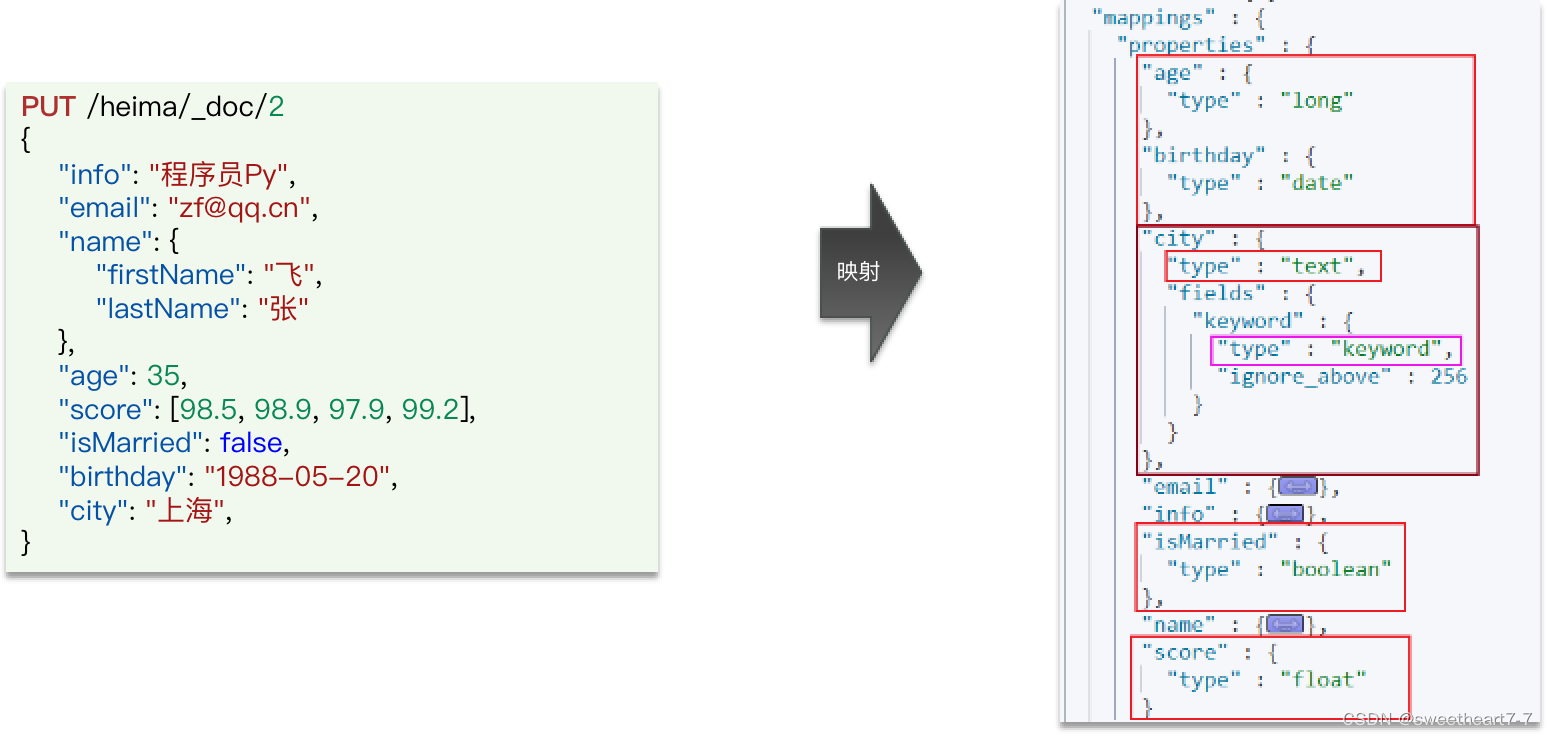
- 插入文档时,es会检查文档中的字段是否有mapping,如果没有则按照默认mapping规则来创建索引。
- 如果默认mapping规则不符合你的需求,一定要自己设置字段mapping
RestClient 操作索引库
什么是RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html

利用JavaRestClient实现创建、删除索引库,判断索引库是否存在
根据课前资料提供的酒店数据创建索引库,索引库名为hotel,mapping属性根据数据库结构定义。
基本步骤如下:
- 导入课前资料Demo
- 分析数据结构,定义mapping属性
- 初始化JavaRestClient
- 利用JavaRestClient创建索引库
- 利用JavaRestClient删除索引库
- 利用JavaRestClient判断索引库是否存在
DROP TABLE IF EXISTS `tb_hotel`;
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称',`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址',`price` int(10) NOT NULL COMMENT '酒店价格',`score` int(2) NOT NULL COMMENT '酒店评分',`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌',`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市',`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻',`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商圈',`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度',`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度',`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店图片',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Compact;
步骤1:导入课前资料Demo
首先导入课前资料提供的数据库数据:

然后导入课前资料提供的项目:

步骤2:分析数据结构
mapping要考虑的问题:
字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?
ES中支持两种地理坐标数据类型:
- geo_point:由纬度(latitude)和经度(longitude)确定的一个点。例如:“32.8752345, 120.2981576”
- geo_shape:有多个geo_point组成的复杂几何图形。例如一条直线,“LINESTRING (-77.03653 38.897676, -77.009051 38.889939)”
字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段。示例:

步骤3:初始化JavaRestClient
- 引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
- 因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.16.2</elasticsearch.version>
</properties>
- 初始化RestHighLevelClient:
this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://10.211.55.6:9200")
));
创建索引库
步骤4:创建索引库
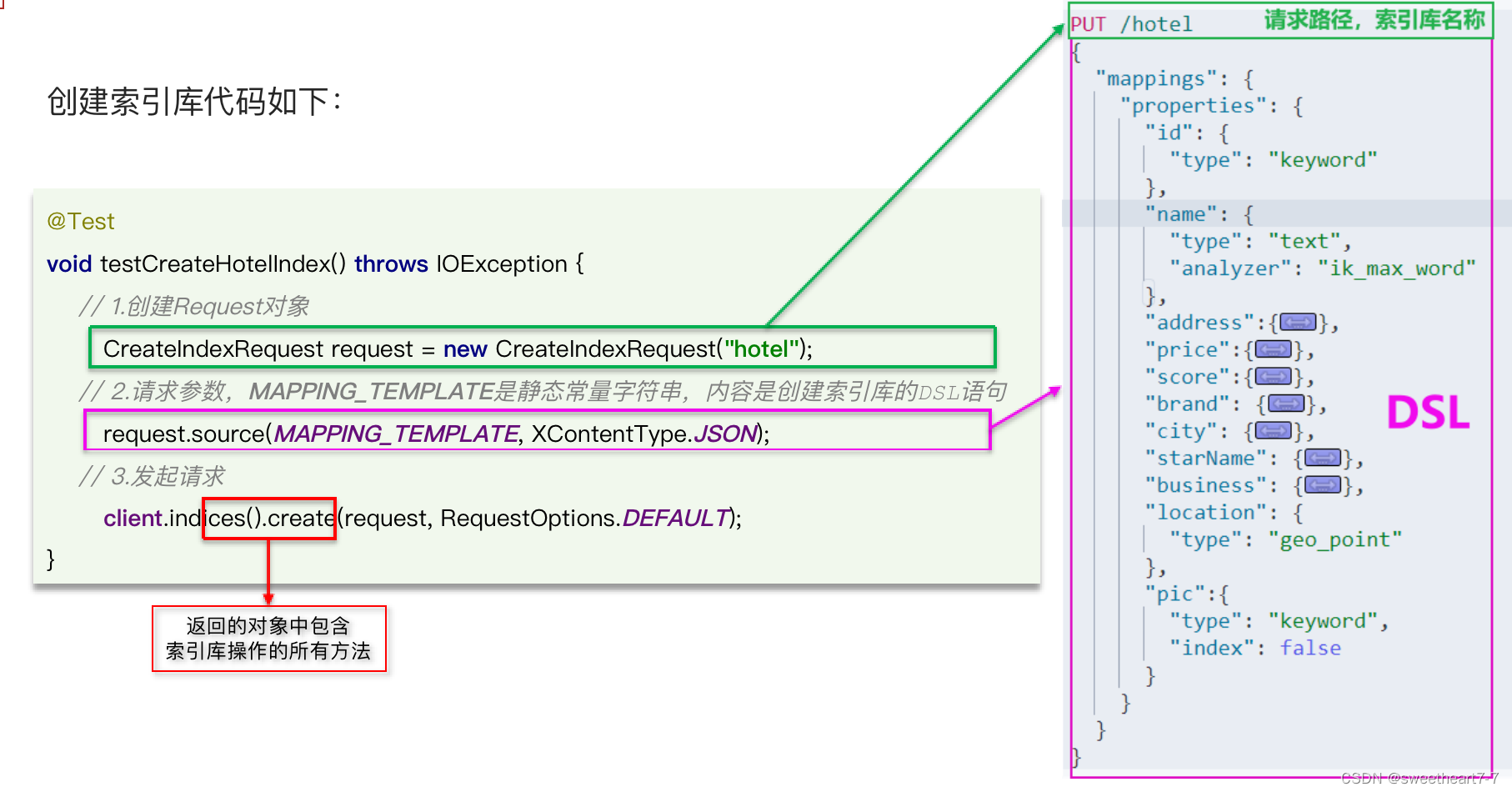
@Test
void testCreateHotelIndex() throws IOException {// 1. 创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2. 准备请求参数:DSL语句request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);// 3. 发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
# 酒店的mapping
PUT /hotel
{"mappings": {"properties": {"all": {"type": "text","analyzer": "ik_max_word"},"id": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword","copy_to": "all"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"business": {"type": "keyword","copy_to": "all"},"location": {"type": "geo_point"},"pic": {"type": "keyword","index": false}}}
}
删除索引库
步骤5:删除索引库、判断索引库是否存在
删除索引库代码如下:

判断索引库是否存在
判断索引库是否存在

索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
RestClient操作文档
利用JavaRestClient实现文档的CRUD
去数据库查询酒店数据,导入到hotel索引库,实现酒店数据的CRUD。
基本步骤如下:
- 初始化JavaRestClient
- 利用JavaRestClient新增酒店数据
- 利用JavaRestClient根据id查询酒店数据
- 利用JavaRestClient删除酒店数据
- 利用JavaRestClient修改酒店数据
新增文档
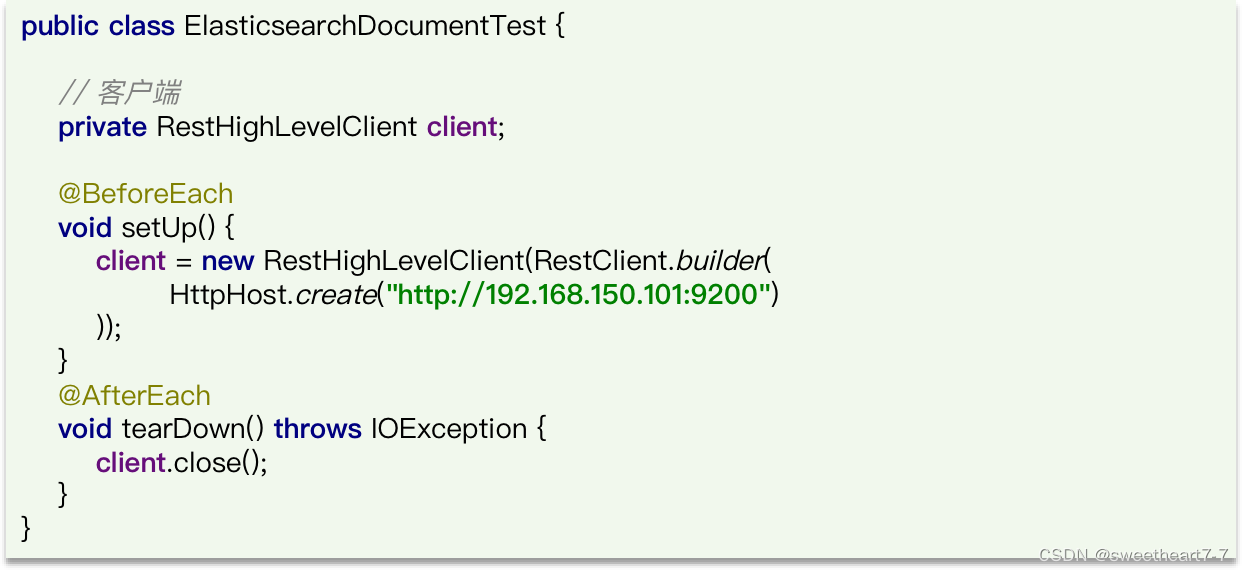
步骤1:初始化JavaRestClient
新建一个测试类,实现文档相关操作,并且完成JavaRestClient的初始化
步骤2:添加酒店数据到索引库
先查询酒店数据,然后给这条数据创建倒排索引,即可完成添加:

@SpringBootTest
public class HotelDocumentTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient client;@Testvoid testInit(){System.out.println(client);}@Testvoid testAddDocument() throws IOException {// 根据 id 查询酒店数据Hotel hotel = hotelService.getById(38665L);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1. 准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2. 准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3. 发送请求client.index(request, RequestOptions.DEFAULT);}@BeforeEachvoid setUp(){this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://10.211.55.6:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}
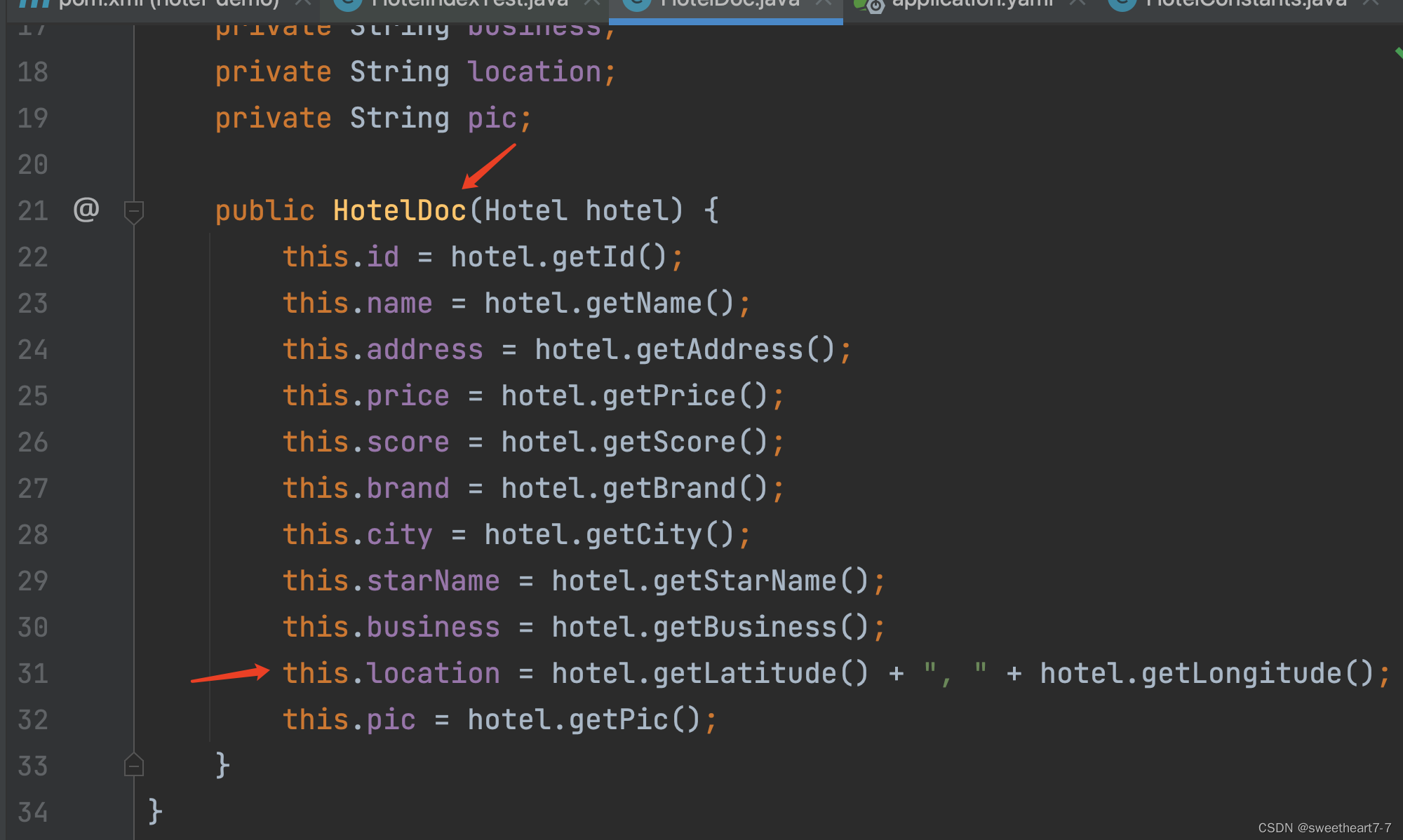
运行后查看是否添加成功
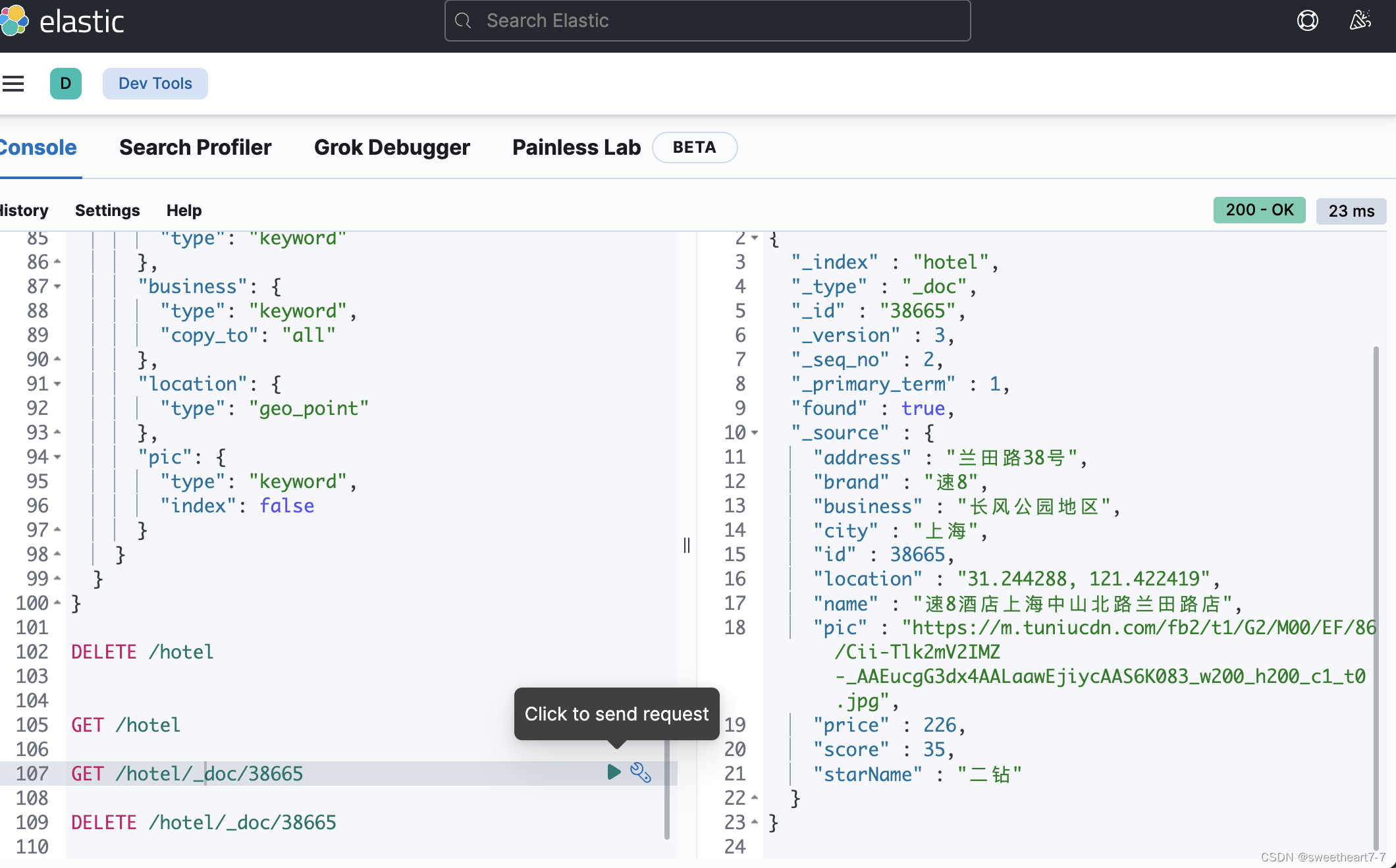
查询文档
步骤3:根据id查询酒店数据
根据id查询到的文档数据是json,需要反序列化为java对象:

修改文档
步骤4:根据id修改酒店数据
修改文档数据有两种方式:
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档
方式二:局部更新。只更新部分字段,我们演示方式二

删除文档
步骤5:根据id删除文档数据
删除文档代码如下:

文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete
- 准备参数(Index和Update时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete
- 解析结果(Get时需要)
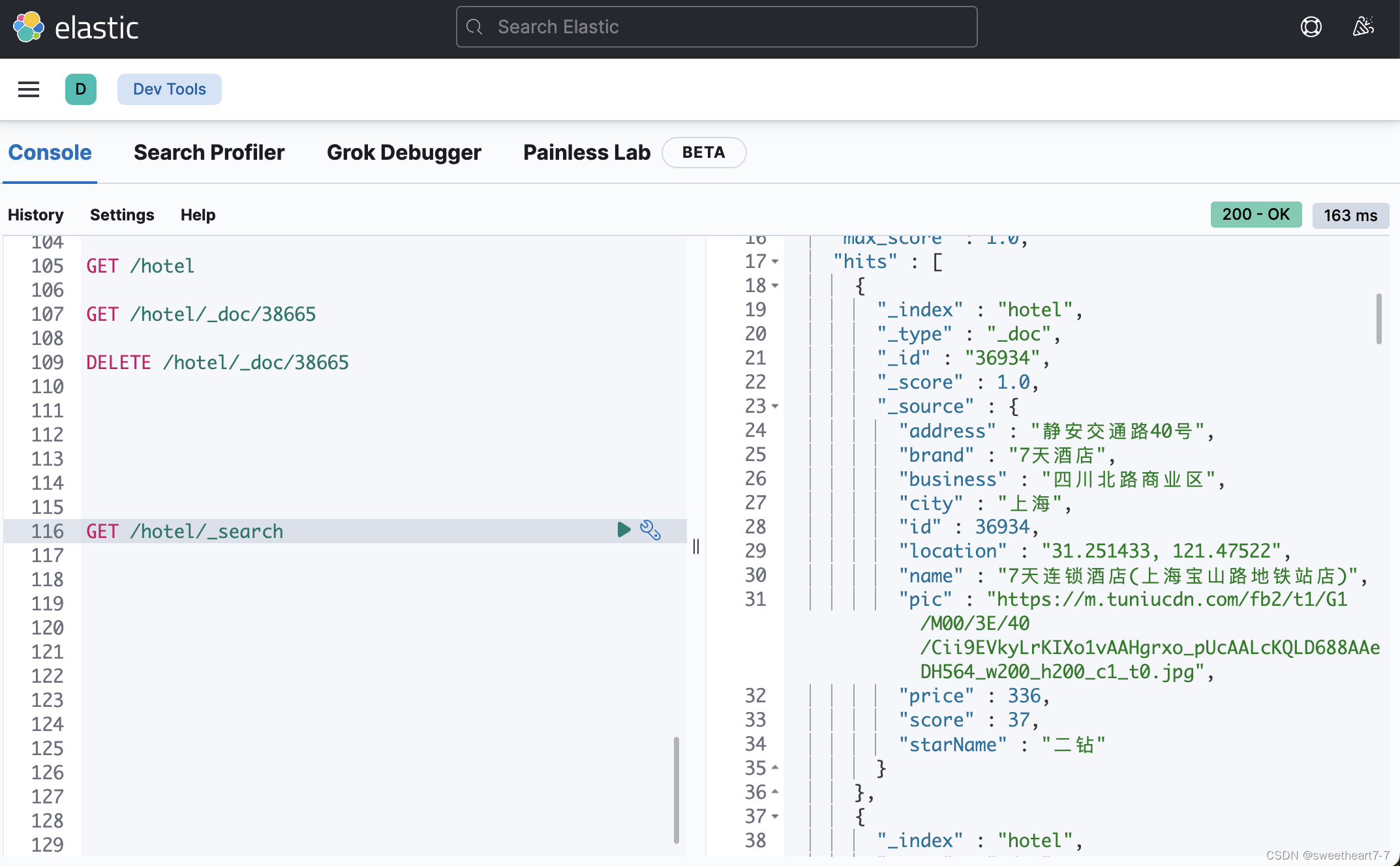
批量导入文档
利用JavaRestClient批量导入酒店数据到ES
需求:批量查询酒店数据,然后批量导入索引库中
思路:
- 利用mybatis-plus查询酒店数据
- 将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
- 利用JavaRestClient中的Bulk批处理,实现批量新增文档,示例代码如下

@Testvoid testBulkRequest() throws IOException {// 批量查询酒店数据List<Hotel> hotels = hotelService.list();// 1. 创建 RequestBulkRequest request = new BulkRequest();// 2. 准备参数,添加多个新增的Requestfor (Hotel hotel : hotels) {// 转换为文档类型 HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);// 创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3. 发送请求client.bulk(request, RequestOptions.DEFAULT);}
相关文章:
Spring Cloud学习(九)【Elasticsearch 分布式搜索引擎01】
文章目录 初识 elasticsearch了解 ES倒排索引ES 的一些概念安装es、kibana安装elasticsearch部署kibana 分词器安装IK分词器ik分词器-拓展词库 索引库操作mapping 映射属性索引库的 CRUD 文档操作添加文档查看、删除文档修改文档Dynamic Mapping RestClient 操作索引库什么是Re…...
jvm 内存结构 ^_^
1. 程序计数器 2. 虚拟机栈 3. 本地方法栈 4. 堆 5. 方法区 程序计数器 定义: Program Counter Register 程序计数器(寄存器) 作用,是记住下一条jvm指令的执行地址 特点: 是线程私有的 不会存在内存溢出 虚拟机栈…...

SQL基础理论篇(八):视图
文章目录 简介创建视图修改视图删除视图总结参考文献 简介 视图,即VIEW,是SQL中的一个重要概念,它其实是一种虚拟表(非实体数据表,本身不存储数据)。 视图类似于编程中的函数,也可以理解成是一个访问数据的接口。 从…...
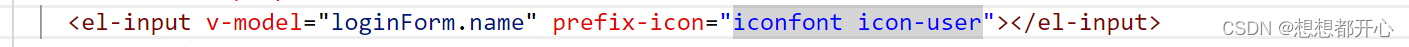
element-ui中怎样使用iconfont的图标
1 登录 https://www.iconfont.cn/ 2 搜索合适的图 这里可以找到这个图所在的图库。这样就可以一次查找到对应的所有同款图标 3 选择同款加入购物车 4 将购物车的icon加入项目,注意是新建项目,除非你是确定需要前面已经加过的icon 5 下载icon 选择fon…...

记一次struct2漏洞获取服务器
文章目录 一、漏洞原因二、漏洞成果三、漏洞利用0x01 struts2漏洞获取shell0x02 todesk配置文件获取连接0x03 orcal数据库连接0x04 web网站 sso管理权限0x05 tomcat网站0x06 获取路由器权限0x07 远程桌面四、总结五、免责声明一、漏洞原因 由于网站使用struct2框架,未及时进行…...
ChatGPT API 学习
参考:从零开始的 ChatGPT API 使用指南,只需三步! - 知乎 (zhihu.com) ChatGPT API 是一种由 OpenAI 提供的 API,它可以用最简单的方式把 ChatGPT 的聊天能力接入到各种应用程序或服务中。 自然语言语音识别(Natural Language S…...

nginx中将指定文件夹设置为虚拟目录
记得目录后面要加个斜杠“/"。 话说,我们系统有照相机和摄像头,可以产生照片和视频。通过nginx将照片和视频所在文件夹映射为虚拟目录,外部即可访问。 如何映射(或曰,转发)呢?这样写&…...

78基于matlab的BiLSTM分类算法,输出迭代曲线,测试集和训练集分类结果和混淆矩阵
基于matlab的BiLSTM分类算法,输出迭代曲线,测试集和训练集分类结果和混淆矩阵,程序有详细注释,数据可更换自己的,程序已调通,可直接运行。...

苹果MAC安装绿盾出现问题,安装时没有出现填服务器地址的页面,现在更改不了也卸载不了绿盾 怎么处理?
环境: Mac mini M1 Mac os 11.0 绿盾v6.5 问题描述: 苹果MAC安装绿盾出现问题,安装时没有出现填服务器地址的页面,现在更改不了也卸载不了绿盾 怎么处理? 解决方案: 大部分企业是Windows和Mac终端混合使用,在进行文档加密管理时通常会遇到不兼容的现象,而为了统一…...

MySQL优化-查询优化
MySQL查询优化是指通过调整查询语句、优化表结构、使用索引等方式,提高查询性能的过程。以下是MySQL查询优化的几种方法: 1. 尽量避免使用SELECT* SELECT *会查询表中的所有列,包括不需要的列,这会消耗大量的计算资源和时间。而…...

Ubuntu18.04安装Moveit框架
简介 Moveit是一个由一系列移动操作的功能包组成的集成化开发平台,提供友好的GUI,是目前ROS社区中使用度排名前三的功能包,Moveit包含以下三大核心功能,并集成了大量的优秀算法接口: 运动学:KDL,Trac-IK,IKFast...路径规划:OMPL,CHMOP,SBPL..碰撞检测:FCL,PCD... 一、更新功…...

MongoDB——文档增删改查命令使用
MongoDB 文档增删改查 命令操作描述db.collection.insert() db.collection.insert()将单个文档或多个文档插入到集合中db.collection.insertOne()插入文档,3.2 版中的新功能db.collection.insertMany()插入多个文档,3.2 版中的新功能db.collection.update更新或替…...
【日常总结】Swagger-ui 导入 showdoc (优雅升级Swagger 2 升至 3.0)
一、场景 环境: 二、存在问题 三、解决方案 四、实战 - Swagger 2 升至 3.0 (Open API 3.0) Stage 1:引入Maven依赖 Stage 2:Swagger 配置类 Stage 3:访问 Swagger 3.0 Stage 4:获取 js…...
OpenCV C++ 图像 批处理 (批量调整尺寸、批量重命名)
文章目录 图像 批处理(调整尺寸、重命名)图像 批处理(调整尺寸、重命名) 拿着棋盘格,对着相机变换不同的方角度,采集十张以上(以10~20张为宜);或者棋盘格放到桌上,拿着相机从不同角度一通拍摄。 以棋盘格,第一个内焦点为坐标原点,便于计算世界坐标系下三维坐标; …...
RT-DETR手把手教程,注意力机制如何添加在网络的不同位置进行创新优化
💡💡💡本文独家改进:本文首先复现了将EMA引入到RT-DETR中,并跟不同模块进行结合创新;1)Rep C3结合;2)直接作为注意力机制放在网络不同位置;3)高效…...

qt treeview 删除节点
Qt 中,要删除 QTreeView 中的节点,可以通过操作其模型(QAbstractItemModel)来实现。以下是一个简单的示例,展示如何从 QTreeView 中删除节点。 假设你有一个 QTreeView,它使用了 QStandardItemModel 作为模…...
【单词】【2019】
...

Java自动化驱动浏览器搜索稻香
下载最新的Chrome浏览器 查看chrome版本,在浏览器地址栏输入:chrome://version/ 下载对应的浏览器驱动,将其放到一个目录中,我放到了D:/chromedriver-win64 导入对应的依赖【注意:不要导入最新的版本,最…...
、WebSocket、消息队列)
php聊天室通讯系统常用的接口对接函数 curl、file_get_contents()、WebSocket、消息队列
方法有: 1、HTTP请求,可以通过PHP的curl库或者file_get_contents()函数发送HTTP请求来与聊天室接口进行通信; 2、WebSocket协议,可以使用PHP的WebSocket库或者第三方库来与聊天室接口进行对接; 3、使用这些SDK或者包装…...

SQL基础理论篇(九):存储过程
文章目录 简介存储过程的形式定义一个存储过程使用delimiter定义语句结束符存储过程中的三种参数类型流控制语句 存储过程的优缺点参考文献 简介 存储过程Stored Procedure,SQL中的另一个重要应用。 前面说的视图,只能勉强跟编程中的函数相似ÿ…...

CANN/ops-nn erfinv算子API文档
aclnnErfinv&aclnnInplaceErfinv 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950…...

3步搭建个人游戏串流服务器:Sunshine让你在任何设备畅玩3A大作
3步搭建个人游戏串流服务器:Sunshine让你在任何设备畅玩3A大作 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾希望用轻薄笔记本流畅运行最新的3A游戏大作&…...

我做了一个 Agent Skill,一句话生成一镜到底城市宣传片
上周,我制作了一个 skill ,用这个 skill 可以一键直出符合生成 seedance2.0 视频生成模型的城市宣传片分镜提示词,这个 skill 可以让你在 15 秒的视频当中,做出一镜到底效果的城市宣传片。我为什么制作这么一个 skill 呢ÿ…...
联邦学习与Transformer融合:破解数据孤岛下的视觉与安全AI落地难题
1. 引言:当AI前沿技术遇见现实世界的“硬骨头”如果你和我一样,长期混迹在AI研究和工业落地的交叉地带,就会发现一个有趣的现象:每年都有大量炫酷的新模型、新范式在顶会上涌现,但真正能走出论文,在计算机视…...

如何搭建个人游戏云:Sunshine串流服务器完全指南
如何搭建个人游戏云:Sunshine串流服务器完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,专为Moonlight…...

CANN学习中心CMake配置详解
CMake 配置详解 【免费下载链接】cann-learning-hub CANN 学习中心仓,支持在线互动运行、边学边练,提供教程、示例与优化方案,一站式助力昇腾开发者快速上手。 项目地址: https://gitcode.com/cann/cann-learning-hub CMakePresets.js…...

LangChain Tool + Agent 最小可运行示例解析
下面给出一个代码示例: 展示如何使用 LangChain 通义千问(Qwen),通过 ReAct Agent 安全地调用自定义工具完成数学计算任务。 示例代码取自《AI Agent智能体开发实践》第8章。 # -*- coding: utf-8 -*- """ Creat…...

激光三角法测距
激光三角测距原理详述 激光三角测距法作为低成本的激光雷达设计方案,可获得高精度、高性价比的应用效果,并成为室内服务机器人导航的首选方案,本文将对激光雷达核心组件进行介绍并重点阐述基于激光三角测距法的激光雷达原理。 激光雷达四大核…...

Video Speed Controller:如何优雅应对现代视频网站的复杂DOM架构
Video Speed Controller:如何优雅应对现代视频网站的复杂DOM架构 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 作为一名前端开发者,你一定有过这样的…...

量子误差缓解技术:IC-ZNE原理与应用解析
1. 量子误差缓解技术概述量子计算作为下一代计算范式,其核心优势在于利用量子叠加和纠缠等特性解决经典计算机难以处理的复杂问题。然而,当前量子硬件普遍存在噪声干扰问题,这直接影响了计算结果的可靠性。误差缓解技术(Error Mit…...