国科大数据挖掘期末复习——聚类分析
聚类分析
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生 成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
聚类属于无监督学习(unsupervised learning),也就意味着它不依赖于预先定义的类和训练样本。所以聚类是通过观察学习,而不是通过例子学习。
数据挖掘对聚类的典型要求如下:
- 可伸缩性
- 处理不同类型属性的能力
- 发现任意形状的聚类
- 用于决定输入参数的领域知识最小化
- 处理“噪声”数据的能力
- 对于输入记录的顺序不敏感
- 高维度
- 基于约束的聚类
- 可解释性和可用性
聚类分析中的数据类型
- 数据矩阵(Data matrix):用p个变量来表现n个对象,(n 个对象*p 个属性)的矩阵

- 相异度矩阵(dissimilarity matrix):存储n个对象两两之间的近似性,表现形式是一个 n*n 维的矩阵。d(i,j)是对象i和对象j之间的相异性的量化表示,通常它是一个非负的数值,当对象 i 和 j 越相似,其值越接近 0;两个对象越不同,其值越大。

区间标度(Interval-Scaled)变量
为了实现度量值的标准化,一种方法是将原来的度量值转 换为无单位的值。给定一个变量 f 的度量值,可以进行如下的变换:

这里的 x1f,…,xnf 是 f 的 n 个度量值,mf 是 f 的平均值
对数据进行标准化的处理之后,下面要计算对象间的相异度,而对象间的相异度是基于对象间的距离来计算的。
欧几里得距离(Euclidean distance):

曼哈顿距离(Manhattan distance):

以上两种距离度量方法均满足:
- d(i,j)>=0,距离是一个非负的数值
- d(i,i)=0,一个对象与自身的距离是0
- d(i,j)=d(j,i),距离函数具有对称性
- d(i,j)<=d(i,h)+d(h,j),从对象i到对象j的直接距离不会大于途径任何其他对象的距离。
**明考斯基距离(Minkowski distance)**是欧几里得距离和曼哈顿距离的概化:

q=1就是曼哈顿距离,q=2就是欧几里得距离
二元变量(binary variable)
一个二元变量只有两个状态:0 或 1,0 表示该变量为空,1 表示该变量存在。
如何计算二元变量的相似度呢?
如果假设所有的二元变量有相同的权重,我们得到一个两行两列的可能性表。在表中,a 是对象 i 和 j 值都为 1 的变量的数目,b 是在对象 i 中值为 1,在对象 j 中值为 0 的变量的数目,c 是 在对象 i 中值为 0,在对象 j 中值为 1 的变量的数目,d 是在对象 i 和 j 中值都为 0 的变量的数目。变量的总数是 p=a+b+c+d

对称的二元变量和不对称的二元变量之间的区别是什么?
如果它的两个状态有相同的权重, 那么该二元变量是对称的,也就是两个取值 0 或 1 没有优先权。如果两个状态的输出不是同样重要,那么该二元变量是不对称的。例
对称的二元变量距离测量:

非对称二元变量的距离测量:



d(jack,mary)=(0+1)/(2+0+1)=0.33
d(jack,jim)=(1+1)/(1+1+1)=0.67
d(jim,mary)=(1+2)/(1+1+2)=0.75
这意味着jim和mary不可能有相似的疾病,因为他们有着最高的相异度,在这三个病人中,jack和mary最可能有类似疾病。
标称变量
标称变量是二元变量的推广,它可以具有多于两个的状态值。
如何计算标称变量所描述的对象之间的相异度?

这里的p是全部变量的数目,m是匹配数目(i和j取值相同的变量数目)
序数型变量
一个离散的序数型变量类似于标称变量,除了序数型变量的 M 个状态是以有意义的序列排序的。一个序数型变量的值可以映射为排序。
如何计算序数型变量所描述的对象之间的相异度?

- 用对应的rif将xif替换,rif∈{1,…,Mf}
- 将每个变量的值域映射到 [0 .0, 1.0]上,以便每个变量都有相同的权重。
- 计算得出结果即可
比例标度型变量
如何计算用比例标度型变量描述的对象之间的相异度?
-
采用与处理区间标度变量同样的方法。但是,这种作法通常不是一个好的选择,因为刻度 可能被扭曲了。
-
对比例标度型变量进行对数变换

- 将 xif 看作连续的序数型数据,将其值作为区间标度的值来对待
后两种方法比较有效
混合型的变量
在许多真实的数据库中,对象是被混合类型的变量描述的。一般来说,一个数据库可能包含上 面列出的全部六种类型(区间标度变量, 对称二元变量,不对称二元变量,标称变量,序数型变量,比例标度型变量)。
那么,我们怎样计算用混合类型变量描述的对象之间的相异度?
是将所有的变量一起处理,只进行一次聚类分析。一种技术将不同类型的变 量组合在单个相异度矩阵中,把所有有意义的变量转换到共同的值域区间[0.0, 1.0]上。



待解
主要聚类方法的分类
-
划分方法(partitioning methods):
给定一个 n 个对象或元组的数据库,一个划分方法构建数据的 k 个划分,每个划分表示一个聚类,并且 k<=n。也就是说,它将数据划分为 k 个组,同时满足如下的 要求:
(1)每个组至少包含一个对象;
(2)每个对象必须属于且只属于一个组。
- k-means算法:每个簇用该簇中对象的平均 值来表示
- k-medoids算法:每个簇用接近聚类中心的一个对象来表示
-
层次的方法(hierarchical methods):层次的方法对给定数据集合进行层次的分解。根据层次的分解 如何形成,层次的方法可以被分为凝聚的或分裂的方法。凝聚的方法,也称为自底向上的方法,一 开始将每个对象作为单独的一个组,然后继续地合并相近的对象或组,直到所有的组合并为一个(层 次的最上层),或者达到一个终止条件。分裂的方法,也称为自顶向下的方法,一开始将所有的对 象置于一个簇中。在迭代的每一步中,一个簇被分裂为更小的簇,直到最终每个对象在单独的一个 簇中,或者达到一个终止条件。
-
基于密度的方法:绝大多数划分方法基于对象之间的距离进行聚类。这样的方法只能发现球状的簇, 而在发现任意形状的簇上遇到了困难。随之提出了基于密度的另一类聚类方法,其主要思想是:只 要临近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类。也就是说,对给定类中的 每个数据点,在一个给定范围的区域中必须包含至少某个数目的点。这样的方法可以用来过滤“噪 音”数据,发现任意形状的簇。
-
基于网格的方法:基于网格的方法把对象空间量化为有限数目的单元,形成了 一个网格结构。所有的聚类操作都在这个网格结构(即量化的空间)上进行。这种方法的主要优点 是它的处理速度很快,其处理时间独立于数据对象的数目,只与量化空间中每一维的单元数目有关。
-
基于模型的方法:基于模型的方法为每个簇假定了一个模型,寻找数据对给定模型的最佳匹配。一个基于模型的算法可能通过构建反映数据点空间分布的密度函数来定位聚类。它也基于标准的统计数字自动决定聚类的数目,考虑“噪音”数据和孤立点,从而产生健壮的 聚类方法。
划分方法(partitioning methos)
k-means算法
输入:簇的数目k和包含n个对象的数据库
输出:k个簇,使平方误差最小
- 任意选择k个对象作为初始的簇中心
- repeat
- 根据与每个中心的距离,将每个对象赋给“最近”的簇
- 重新计算每个簇的平均值(质心,平均点)
- until 不再发生变化

缺点:
- 只有在簇的平均值被定义在情况下才能使用
- 需要提前指定k的值
- 无法处理有噪声的数据和异常值
- 不适合于发现非凸面形状的簇,或者大小差别很大的簇
k-methods算法
此方法修改了k-means算法对异常值的敏感性。不采用簇中对象的平均值作为参 照点,可以选用簇中位置最中心的对象,即 medoid。这样划分方法仍然是基于最小化所有对象与其 参照点之间的相异度之和的原则来执行的。
- 为每个簇随意选择一个代表对象
- 剩余的对象根据其与代表对象的距离分配给最近的一个簇
- 用非代表对象(距离中心最近的点)来替代代表对象,以改进聚类的质量

层次方法(Hierarchical Methods)
一个层次的聚类方法将数据对象组成一棵聚类的树。根据层次分解是自底向上,还是自顶向下形成,层次的聚类方法可以进一步分为凝聚(agglomerative)和分裂(divisive)层次聚类。
一个纯粹的层次聚类方法的聚类质量受限于如下特点:一旦一个合并或分裂被执行,就不能修正。
-
凝聚的层次聚类:这种自底向上的策略首先将每个对象作为一个簇,然后合并这些原子簇 为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足。绝大多数层 次聚类方法属于这一类,它们只是在簇间相似度的定义上有所不同。
- 使用单链路和不相似矩阵
- 逐个合并差异度最小的节点


-
分裂的层次聚类:这种自顶向下的策略与凝聚的层次聚类不同,它首先将所有对象置于一 个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终结条 件,例如达到了某个希望的簇数目,或者两个最近的簇之间的距离超过了某个阈值。
- 恰恰与凝聚相反,逐渐分裂


BIRCH
它克服了凝聚聚类方法的两个困难:
- 可伸缩性
- 不能撤销先前所做的工作
BIRCH 使用聚类特征来概括一个簇,使用聚类特征树(CF-树)来表示聚类的层次结构。
考虑一个n个d维的数据对象或点的簇。簇的聚类特征(Clustering Feature,CF)是一个3 维向量,汇总了对象簇的信息,定义如下:



CF-树是一个高度平衡的树,它存储了层次聚类的聚类特征。
- 树中的非叶结点都有后代或“子女”
- 非叶结点存储了其子女的CF的总和
- CF-树有两个参数
- 分支因子B:定义了非叶结点的子女最大数目
- 阈值T:存储在树的叶结点中的子簇的最大直径

BIRCH采用了一种多阶段聚类技术:数据集的单遍扫描产生一个基本好的聚类,而一或多遍的额外扫描可以进一步地改进聚类质量。主要有两个阶段:
- BIRCH扫描数据库,建立一棵存放于内存的初始CF-树,它可以被看做数据的多层压缩,试图保留数据的内在聚类结构。
- 对象被插入到最近的叶条目(子簇)
- 如果插入后,存储在叶结点中的子簇的直径大于阈值,则该叶节点和可能的其他结点被分裂。
- BIRCH采用某个(选定的)聚类算法对CF树的叶结点进行聚类,把稀疏的簇当做离群点删除,而把稠密的簇合并为更大的簇。
CURE
CURE 采用了一种新的层 次聚类算法,该算法选择了位于基于质心和基于代表对象方法之间的中间策略。它不用单个质心或 对象来代表一个簇,而是选择了数据空间中固定数目的具有代表性的点。
- 多个具有代表性的点允许CURE发现任意形状的簇
- 对异常值不太敏感
- 对于大规模的数据库,请进行采样和分区
CURE算法核心:
- 从源数据对象中抽取一个随机样本 S
- 将样本 S 划分为一组分块
- 对每个划分局部地聚类
- 通过随机取样剔除孤立点。如果一个簇增长得太慢,就去掉它
- 对局部的簇进行聚类。落在每个新形成的簇中的代表点根据用户定义的一个收缩因子 a 收缩或向 簇中心移动。这些点描述和捕捉到了簇的形状
- 用相应的簇标签来标记数据
基于密度的方法(Density-Based Clustering Methods)
为了发现任意形状的聚类结果,提出了基于密度的聚类方法。这类方法将簇看作是数据空间中 由低密度区域分割开的高密度对象区域。
主要特点:
- 发现任意形状的团簇
- 消除噪声
- 需要密度参数作为终止条件
- 复杂度为O(n2)
两个参数:
- ε–邻域
- 最小数目 MinPts
如果一个对象的ε–邻域至少包含最小数目 MinPts 的对象,那么该对象称为核心对象。
给定一个对象集合 D,如果 p 是在 q 的ε–邻域内,而 q 是一个核心对象,我们说对象 p 从对象 q 出发是直接密度可达的

如果存在一个对象链 p1,p2,…,pn,p1=q, pn=p,对 pi∈ D,1≤i≤n,pi+1 是从 pi 关于ε和 MinPts 直接密度可达的,则对象 p 是从对象 q 关于ε和 MinPts 密度可达的(density-reachable)。

如果对象集合 D 中存在一个对象 o,使得对象 p 和 q 是从 o 关于ε和 MinPts 密度可达的,那么 对象 p 和 q 是关于ε和 MinPts 密度相连的(density-connected)

DBSCAN算法
输入:
- D:一个包含n个对象的数据集
- ε:半径参数
- MinPts:邻域密度阈值
输出:基于密度的簇集合


基于网格的方法(Grid-Based Clustering Method)
基于网格的聚类方法采用一个多分辨率的网格数据结构。它将空间量化为有限数目的单元,这些单元形成了网格结构,所有的聚类操作都在网格上进行。这种方法的主要优点是处理速度快,其处理时间独立于数据对象的数目,仅依赖于量化空间中每一维上的单元数目。
- STING:它利用了存储在网格单元中的统计信息
- WaveCluster:它用一种小波转换方法来聚类对象
- CLIQUE:它是在高维数据空间中基于网格和密度的聚类方法。
STING(STatistical INformation Grid)
- 空间区域被划分为矩形单元格
- 高层的每个单元被划分为多个低一层的单元
- 关于每个网格单元属性的统计信息被预先计算和存储
- count
- 平均值
- 标准偏差
- 最小值
- 最大值
- 分布类型(正态、均匀和无等)

- 一个高层单元的分布类型可以基于它对应的低层单元多数的分布类 型,用一个阈值过滤过程来计算。如果低层单元的分布彼此不同,阈值检验失败,高层单元的分布 类型被置为 none
统计查询方法:
- 使用自顶向下的方法来回答空间数据查询
- 从一个预先选择的图层开始,通常是使用少量的单元格
- 对于当前级别中的每个单元格,计算置信区间
- 从而进一步的考虑中删除无关的单元格
- 完成检查当前层后,继续进入相关单元格的下一个较低层
- 重复此过程,直到到达最底层为止
特点:
- STING 在构建一个父亲单元时没有考虑孩子单元和其相邻单 元之间的关系,结果簇的形状是(isothetic),即所有的聚类边界或者是水平的,或者是竖直的,没有斜的分界线。
- 该方法的效率很高:STING 扫描数据库一次来计 算单元的统计信息,因此产生聚类的时间复杂度是 O(n),n 是对象的数目。在层次结构建立后, 查询处理时间是 O(g),这里 g 是最底层网格单元的数目,通常远远小于 n。
- STING 聚类的质量取决于网格结构的最底层的粒度。如果粒度比较细,处理的代价会显著增加;但是,如果网格结构最底层的粒度太粗,将会降低聚类分析的质量。
- 基于网格的计算是独立于查询的
- 网格结构有利于并行处理和增量更新
孤立点分析(Outlier Analysis)
孤立点是什么?
经常存在一些数据对象,它们不符合数据的一般模型。这样的数据对象被 称为孤立点,它们与数据的其它部分不同或不一致。孤立点可能是度量或执行错误所导致的。孤立点本身可能是非常重要的。
目测方法:

基于统计的孤立点检测
统计的方法对给定的数据集合假设了一个分布或概率模型(例如一个正态分布),然后根据模 型采用不一致性检验(discordancy test)来确定孤立点。该检验要求数据集参数(例如假设的数据分布),分布参数(例如平均值和方差),和预期的孤立点的数目。
不一致性检测依赖于:
- 数据分布
- 两个假设
- 分布参数(如平均值,方差)
- 预期异常值的数量
缺点:
- 是绝大多数检验是针对单个属性的,而许多数据挖掘问题要求在多维空间中发现孤立点。
- 统计学方法要求关于数据集合参数的知识,例如数据分布。但是在许多情况下,数据分布可能是未知的
- 需要输入参数
基于距离的孤立点检测
如果至少数据集合 S 中对象的 p 部分与对象 o 的距离大于 d, 对象 o 是一个基于距离的带参数 p 和 d 的孤立点,即 DB(p,d)。换句话说,不依赖于统计检验,我 们可以将基于距离的孤立点看作是那些没有足够邻居的对象,这里的邻居是基于距给定对象的距离 来定义的。与基于统计的方法相比,基于距离的孤立点探测归纳了多个标准分布的不一致性检验的 思想。基于距离的孤立点探测避免了过多的计算,而大量的计算正是使观察到的分布适合某个标准分布,及选择不一致性检验所需要的。

基于索引的算法:
给定一个数据集合,基于索引的算法采用多维索引结构,例如 R 树或 k-d 树, 来查找每个对象 o 在半径 d 范围内的邻居。设 M 是一个孤立点的 d 邻域内的最大对象数目。因此, 一旦对象 o 的 M+1 个邻居被发现,o 就不是 孤立点。
这个算法在最坏情况下的复杂度为 O(k*n2 ), 这里 k 是维数,n 是数据集合中对象的数目。
缺点:复杂度估算只考虑了搜索时间,即使建造索引的任务本身就是计算密集的。
基于单元的算法:
为了避免 O(n2 )的计算复杂度,为驻留内存的数据集合开发了基于单元 的算法。它的复杂度是 O(ck +n),这里 c 是依赖于单元数目的常数,k 是维数。
- 把数据空间划分为单元格,边长等于d/2k1/2
- 每个单元有两层围绕着
- 第一层的厚度是一个单元
- 而第二层 的厚度是2k1/2-1
异常值检测:
- 如果计算第一层>M,则该单元格中没有异常值
- 如果第二层<=M,所有对象都是异常值
- 否则,请检查单元格中的每个对象
基于偏差的孤立点检测
它通过检查一组对象的主要特征来确定孤立点。与给出的描述偏离的对象 被认为是孤立点。
序列异常技术:模仿了人类从一系列推测类似的对象中识别异常对象的方式
- 该算法从集合中选择了一个子集合的序列来分析。对每个子集合,它确定其与序列中前一个子集合的相异度差异。
相关文章:
国科大数据挖掘期末复习——聚类分析
聚类分析 将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生 成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。 聚类属于无监督学习(unsupervised learning&…...

【经验之谈·高频PCB电路设计常见的66个问题】
文章目录 1、如何选择PCB 板材?2、如何避免高频干扰?3、在高速设计中,如何解决信号的完整性问题?4、差分布线方式是如何实现的?5、对于只有一个输出端的时钟信号线,如何实现差分布线?6、接收端差…...
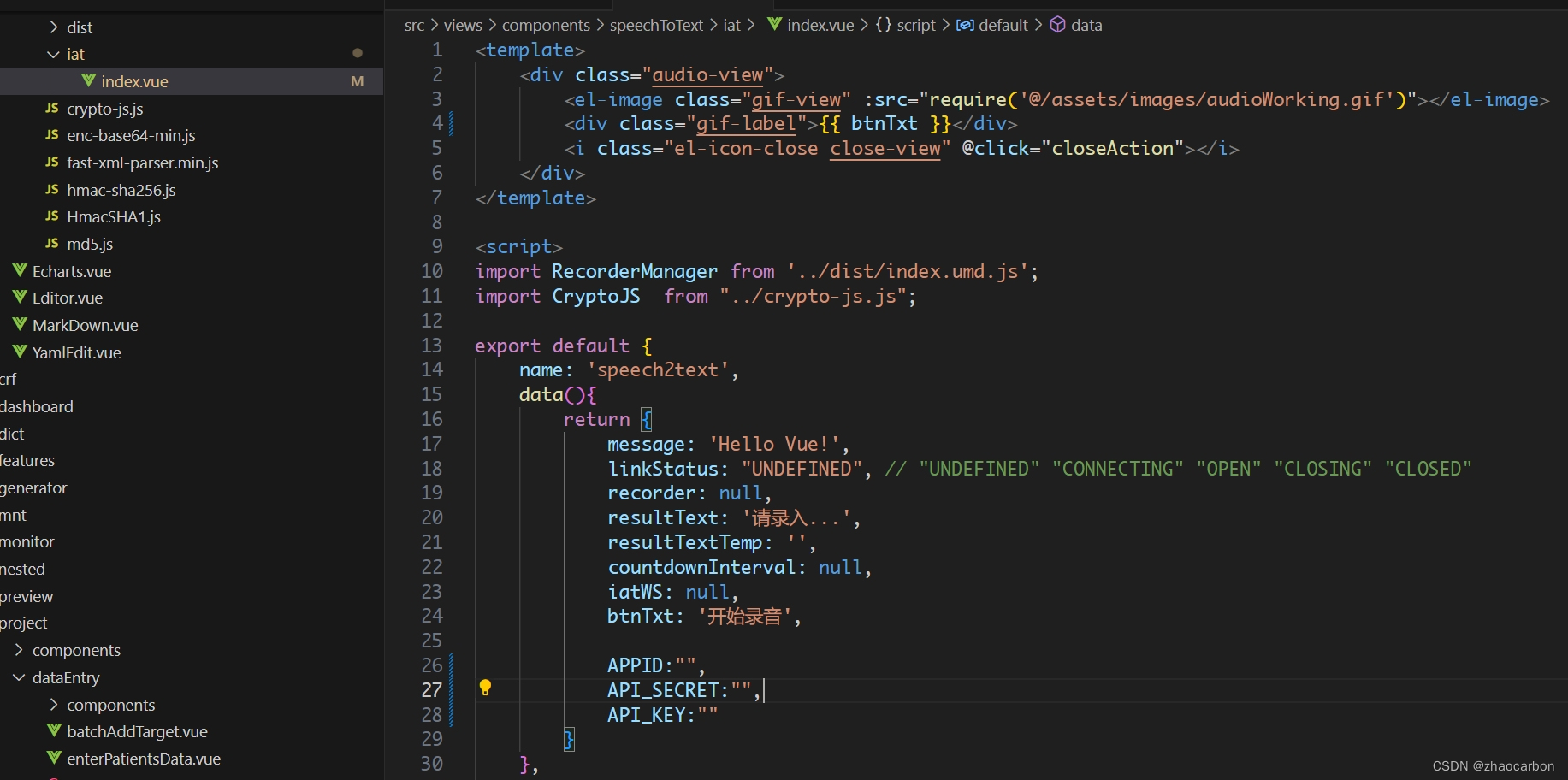
科大讯飞 vue.js 语音听写流式实现 全网首发
组件下载 还是最近的需求,页面表单输入元素过多,需要实现语音识别来由用户通过朗读的方式向表单中填写数据,尽量快的、高效的完成表单数据采集及输入。 国内科大讯飞在语音识别方面的建树还是有目共睹,于是还是选择了科大讯飞的平…...
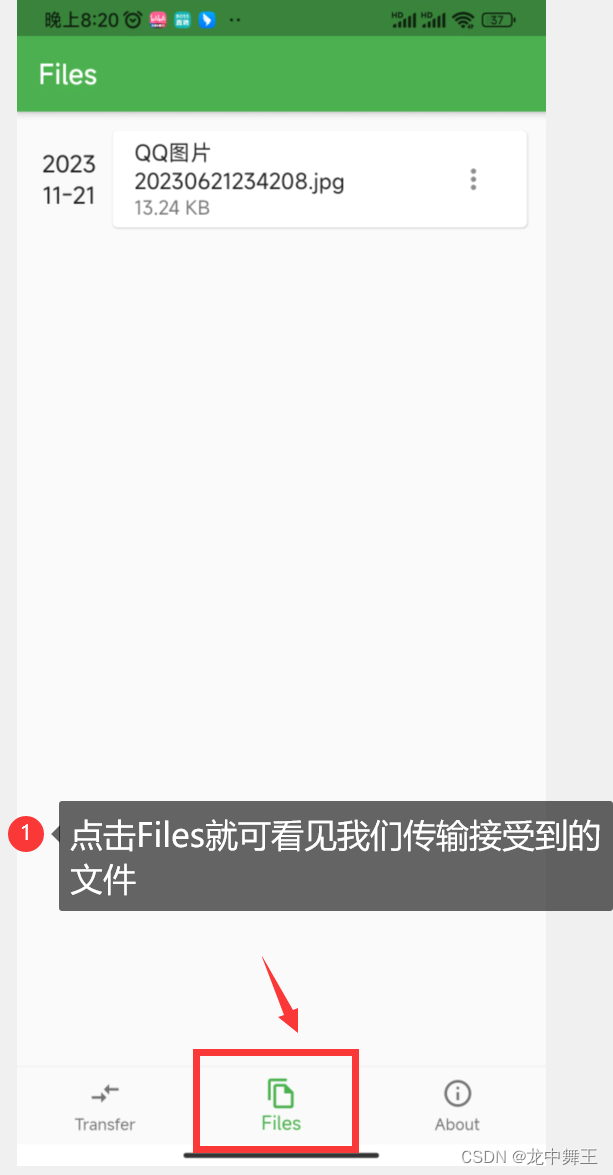
局域网文件共享神器:Landrop
文章目录 前言解决方案Landrop软件界面手机打开效果 软件操作 前言 平常为了方便传文件,我们都是使用微信或者QQ等聊天软件,互传文件。这样传输有两个问题: 必须登录微信或者QQ聊天软件。手机传电脑还有网页版微信,电脑传手机比…...
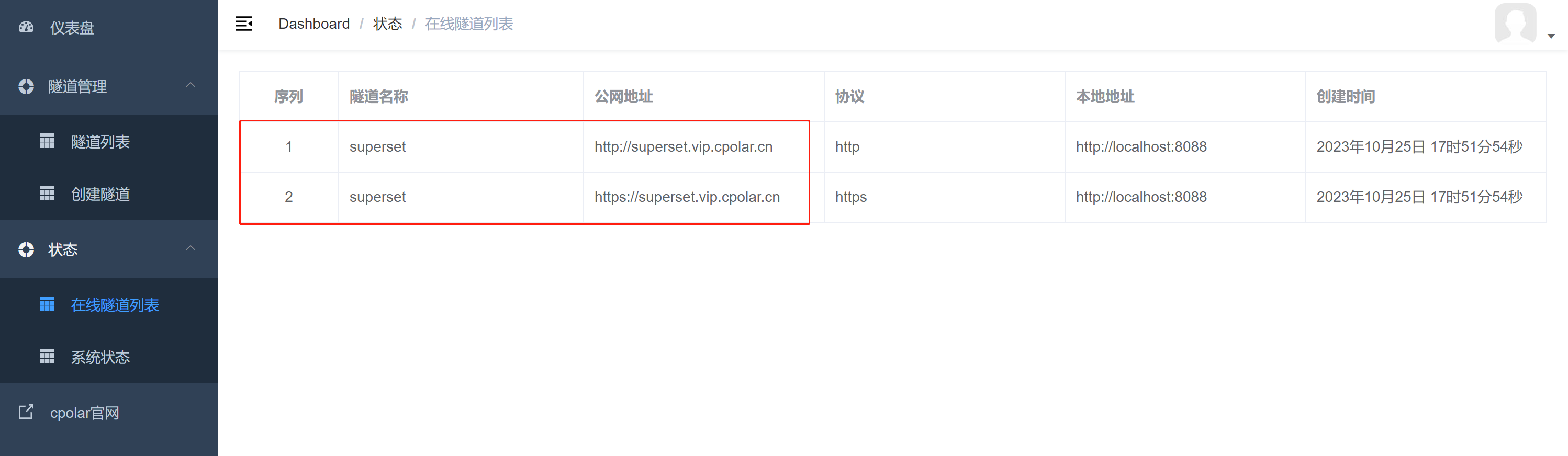
如何使用Docker部署Apache+Superset数据平台并远程访问?
大数据可视化BI分析工具Apache Superset实现公网远程访问 文章目录 大数据可视化BI分析工具Apache Superset实现公网远程访问前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网…...
【阿里云】图像识别 摄像模块 语音模块
USB 摄像头模块测试及配置 一、首先将 USB 摄像头插入到 Orange Pi 开发板的 USB 接口中二、然后通过 lsmod 命令可以看到内核自动加载了下面的模块三、通过 v4l2-ctl 命令可以看到 USB 摄像头的设备节点信息为 /dev/video0四、使用 fswebcam 测试 USB 摄像头五、使用 motion …...
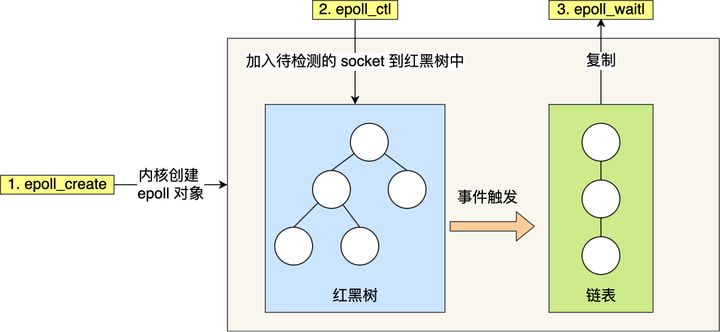
一文读懂 Linux 网络 IO 模型
文章目录 1.从一个问题说起2.多进程模型3.多线程模型4.I/O 多路复用5.select、poll、epoll 的区别?5.1 select5.2 poll5.3 epoll5.4 两种事件触发模式 参考文献 1.从一个问题说起 互联网发展历史上,曾经有一个著名的问题:C10K 问题。 C 是 …...

Arduino库之U8g2lib
某些图片、表格在手机竖屏状态下会显示不全,横屏显示即可。最好是用平板或电脑看。大部分内容摘自官网。 简介 U8g2 U8glib是用于单色显示屏的图形库,它可以用于51、Arduino、ARM控制显示屏,目前作者olikraus已经更新到version2了࿰…...

fiddler 手机抓包
前置步骤参考:手把手教你如何配置fiddler、并开启手机代理抓包、最详细_fiddler抓socks5_赴梦、的博客-CSDN博客 后续: 问:fiddler 证书已安装 在 iphone, 访问网站,报错, 此链接非私人链接 gpt: 如果你在使用 Fiddl…...

基于知识问答的上下文学习中的代码风格11.20
基于知识问答的上下文学习中的代码风格 摘要1 引言2 相关工作3 方法3.1 概述3.2 元函数设计3.3 推理 4 实验4.1 实验设置4.2 实施细节4.3 主要结果 摘要 现有的基于知识的问题分类方法通常依赖于复杂的训练技术和模型框架,在实际应用中存在诸多局限性。最近&#x…...

opencv-形态学处理
通过阈值化分割可以得到二值图,但往往会出现图像中物体形态不完整,变的残缺,可以通过形态学处理,使其变得丰满,或者去除掉多余的像素。常用的形态学处理算法包括:腐蚀,膨胀,开运算&a…...

手把手设计C语言版循环队列(力扣622:设计循环队列)
文章目录 前言描述分析力扣AC代码 力扣: 622.设计循环队列 前言 队列会出现“假溢出”现象,即队列的空间有限,队列是在头和尾进行操作的,当元素个数已经达到最大个数时,队尾已经在空间的最后面了,但是对头…...

数据仓库及ETL的理论基础
数据仓库(Data Warehouse)是一个用于存储和管理大量结构化数据的系统,旨在支持企业的决策制定过程。它是一个集成的、主题导向的、时间变化的、非易失性的数据集合,用于支持企业的决策制定过程。数据仓库的设计目标是提供高性能的…...
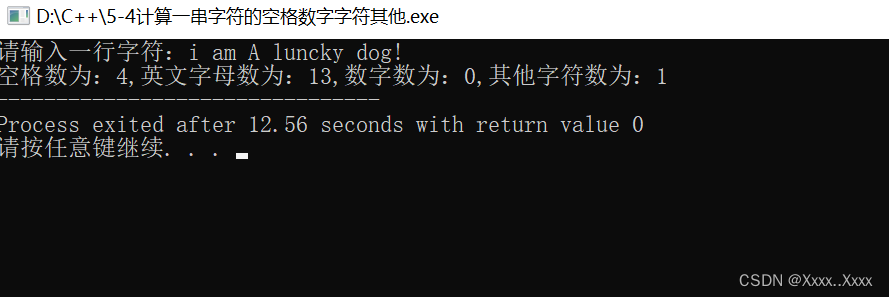
5-4计算一串字符的空格数字字符其他
#include<stdio.h> int main(){char c;int space0;//空格int letters0;//英文字母int numbers0;//数字int others0;//其他字符printf("请输入一行字符:");while((cgetchar())!\n)//获取字符的内容,到\n停止{if(c>a&&c<z|…...

leetcode面试经典150题——30 长度最小的子数组
题目:长度最小的子数组 描述: 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组&a…...

学习计划计划执行记录
11.21--写下学习目标 游戏行业通识学习: 求知鱼游戏学院的个人空间-求知鱼游戏学院个人主页-哔哩哔哩视频 (bilibili.com) (28 封私信 / 80 条消息) 游鲨游戏圈 - 知乎 (zhihu.com) 书籍学习: 软技能2:软件开发者职业生涯指南 面经学习…...
【紫光同创PCIE教程】——使用WinDriver驱动紫光PCIE
本原创教程由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注www.meyesemi.com) 紫光的logos系列的PGL50H/PGL100H、logos-2全系列都集成gen24的PCIE硬核,且官方也提供了例程。 紫光的PCIE用起来还是挺方便的…...

MT8735/MTK8735安卓核心板规格参数介绍
MT8735核心板是一款高性能的64位Cortex-A53四核处理器,设计用于在4G智能设备上运行安卓操作系统。这款多功能核心板支持LTE-FDD/LTE-TDD/WCDMA/TD-SCDMA/EVDO/CDMA/GSM等多种网络标准,同时还具备WiFi 802.11a/b/g/n和BT4.0LE等无线通信功能。此外&#x…...
NSSCTF web刷题记录6
文章目录 [HZNUCTF 2023 final]eznode[MoeCTF 2021]地狱通讯-改[红明谷CTF 2022] Smarty Calculator方法一 CVE-2021-26120方法二 CVE-2021-29454方法三 写马蚁剑连接 [HZNUCTF 2023 final]eznode 考点:vm2沙箱逃逸、原型链污染 打开题目,提示找找源码 …...
米哈游大数据云原生实践
云布道师 近年来,容器、微服务、Kubernetes 等各项云原生技术的日渐成熟,越来越多的公司开始选择拥抱云原生,并将企业应用部署运行在云原生之上。随着米哈游业务的高速发展,大数据离线数据存储量和计算任务量增长迅速,…...

保姆级教程:用ArcGIS Pro的克里金插值和栅格计算器,搞定水源涵养量评估
从零到精通:ArcGIS Pro水源涵养量评估全流程实战指南 当你第一次在学术论文中看到"水源涵养量评估"这个专业术语时,是否感到无从下手?作为生态规划的基础性工作,准确评估水源涵养能力不仅关系到学术研究的严谨性&#x…...

终极Windows热键冲突检测指南:3步快速定位占用程序
终极Windows热键冲突检测指南:3步快速定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经按…...

长期项目使用Taotoken按Token计费带来的成本可控性体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken按Token计费带来的成本可控性体验 在中长期AI应用项目的开发与维护过程中,成本管理是一个贯穿始终…...

基于Spring Boot的餐厅订餐系统的设计与实现毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的餐厅订餐系统以解决传统餐饮服务模式中存在的信息传递效率低下、订单处理流程繁琐以及顾客体验不均衡等问题。随着移动…...

Arm Neoverse V3AE调试寄存器DBGWCR0_EL1与DBGBVR1_EL1详解
1. Arm Neoverse V3AE调试寄存器深度解析 在Arm架构的调试系统中,调试寄存器扮演着至关重要的角色。作为一位长期从事Arm架构底层开发的工程师,我经常需要与DBGWCR0_EL1和DBGBVR1_EL1这类调试寄存器打交道。这些寄存器不仅仅是简单的控制位集合ÿ…...

为什么你的游戏总是卡顿?OpenSpeedy带你突破帧率限制的技术奥秘
为什么你的游戏总是卡顿?OpenSpeedy带你突破帧率限制的技术奥秘 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾经在游戏关键时刻遭遇卡顿,眼…...

DeepSeek-R1-Distill-Qwen-1.5B部署避坑指南:常见问题与优化方案
DeepSeek-R1-Distill-Qwen-1.5B部署避坑指南:常见问题与优化方案 1. 模型特性与部署优势 1.1 为什么选择DeepSeek-R1-Distill-Qwen-1.5B DeepSeek-R1-Distill-Qwen-1.5B是一款经过知识蒸馏优化的轻量级语言模型,具有以下突出特点: 小体积…...

AI技能封装Unikraft:用自然语言操作单内核,降低云原生开发门槛
1. 项目概述:当AI助手遇上Unikraft单内核最近在折腾AI编程助手和云原生基础设施,发现了一个挺有意思的项目:guillempuche/ai-skill-unikraft。简单来说,这是一个为AI助手(比如Cursor、Claude Code、GitHub Copilot&…...

学术写作技能精进:从逻辑架构到高效发表的完整指南
1. 项目概述:学术写作技能的精进之道“muhammad1438/academic-writer-skills”这个项目标题,乍一看像是一个GitHub仓库名,指向一套关于学术写作技能的集合。对于任何一位在学术圈、科研领域深耕,或者正在为学位论文、期刊投稿、研…...

Phi-4多模态模型:轻量架构与高效推理实践
1. 项目背景与核心价值在人工智能领域,多模态模型正逐渐成为解决复杂现实问题的关键技术路径。Phi-4-reasoning-vision-15B这个命名本身就揭示了它的三大核心特性:基于Phi架构的第四代优化、强化推理能力(reasoning)以及视觉模态&…...