《多GPU大模型训练与微调手册》

全参数微调
Lora微调
PTuning微调
多GPU微调预备知识
1. 参数数据类型 torch.dtype
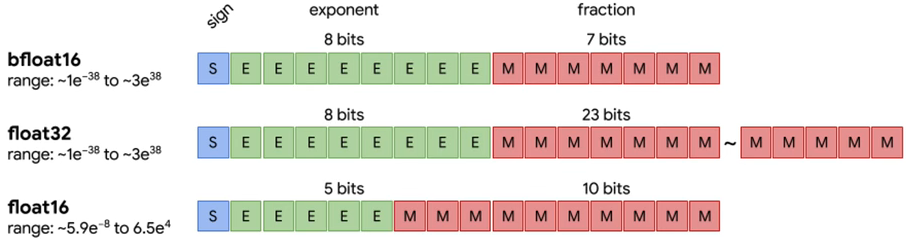
1.1 半精度 half-precision
-
torch.float16:fp16 就是 float16,1个 sign(符号位),5个 exponent bits(指数位),10个 mantissa bits(小数位) -
torch.bfloat16:bf 16 就是 brain float16,1个 :符号位,8个exponent bits(指数位),7个mantissa bits(小数位) -
区别:bf16 牺牲了精度(小数位),实现了比 fp16 更大的范围(多了三个指数位)。
1.2 全精度 single-precision
torch.float32:fp 32 就是 float32,1个 sign(符号位),8个 exponent bits(指数位),23个 mantissa bits(小数位)
2. 显卡环境
2.1 参数量与显存换算
例如,实验室是单机多卡:8卡A6000(40G)服务器 320G显存
① CUDA_VISIBLE_DEVICES 控制显卡可见性
通过CUDA_VISIBLE_DEVICES环境变量 控制哪些GPU可以被torch调用:
- 代码控制:
# 必须置于 import torch 之前,准确地说在 torch.cuda 的调用之前
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3,4,5,6,7'
import torch
torch.cuda.device_count()
# 8
- 命令行控制:
CUDA_VISIBLE_DEVICES=0,1 python train.py
② 推理换算
-
模型加载:
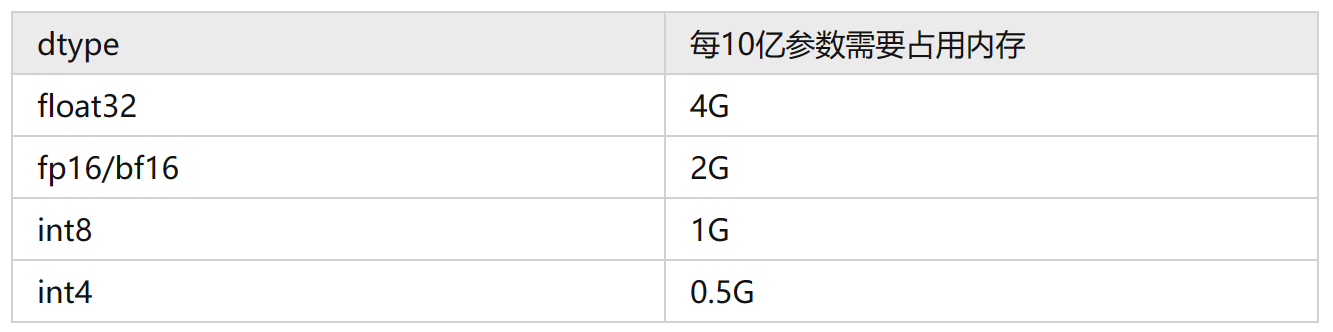
(1)目前模型的参数绝大多数都是float32类型, 每个参数占用4个字节。所以一个粗略的计算方法就是,每10亿个参数(1 billion=10亿),占用4G显存 (实际应该是10^9 * 4 / 1024 / 1024 / 1024 = 3.725G,为了方便可以记为4G),即1B Params= 4G VRAM。比如LLaMA的参数量为7000559616个Params,那么全精度加载这个模型参数需要的显存为:7000559616 * 4 /1024/1024/1024 = 26.08G。
(2)显存不够,可以用半精度的fp16/bf16来加载,这样每个参数只占2个字节,所需显存就降为一半,只需要13.04G。
(3)如果显存还不够,可以采用int8的精度,显存再降一半,仅需6.5G,但是模型效果会更差一些。
(4)如果显存还是不够,int4精度显存再降一半,仅需3.26G。int4就是最低精度了,再往下模型推理效果就很难保证了。
-
模型推理:注意上面只是加载模型到显存,模型运算时的一些临时变量也需要申请空间,比如你beam search的时候。所以真正做推理的时候记得留一些Buffer,不然就容易OOM。如果显存还不够,就只能采用
Memery Offload的技术,把部分显存的内容给挪到内存,但是这样会显著降低推理速度。
③ 训练换算
模型训练的时候显存使用包括如下几部分:
- 模型权重,计算方法和推理一样。
- 优化器:(1)如果你采用AdamW,每个参数需要占用8个字节,因为需要维护两个状态。也就说优化器使用显存是全精度(float32)模型权重的2倍。(2)如果采用bitsandbytes优化的AdamW,每个参数需要占用2个字节,也就是全精度(float32)模型权重的一半。(3)如果采用SGD,则优化器占用显存和全精度模型权重一样。
- 梯度:梯度占用显存和全精度(float32)模型权重一样。
- 计算图内部变量:有时候也叫Forward Activations。
如果模型想要训练,只看前3部分,需要的显存是至少推理的3-4倍。7B的全精度模型加载需要78G ~ 104G。 然后计算图内部变量这一部分只能在运行时候观测了,可以两个不同的batch的占用显存的差值大概估算出来。
优化的思路也就有了,目前市面上主流的一些计算加速的框架如DeepSpeed, Megatron等都在降低显存方面做了很多优化工作,比如量化,模型切分,混合精度计算,Memory Offload等等。
2.2 分布式架构
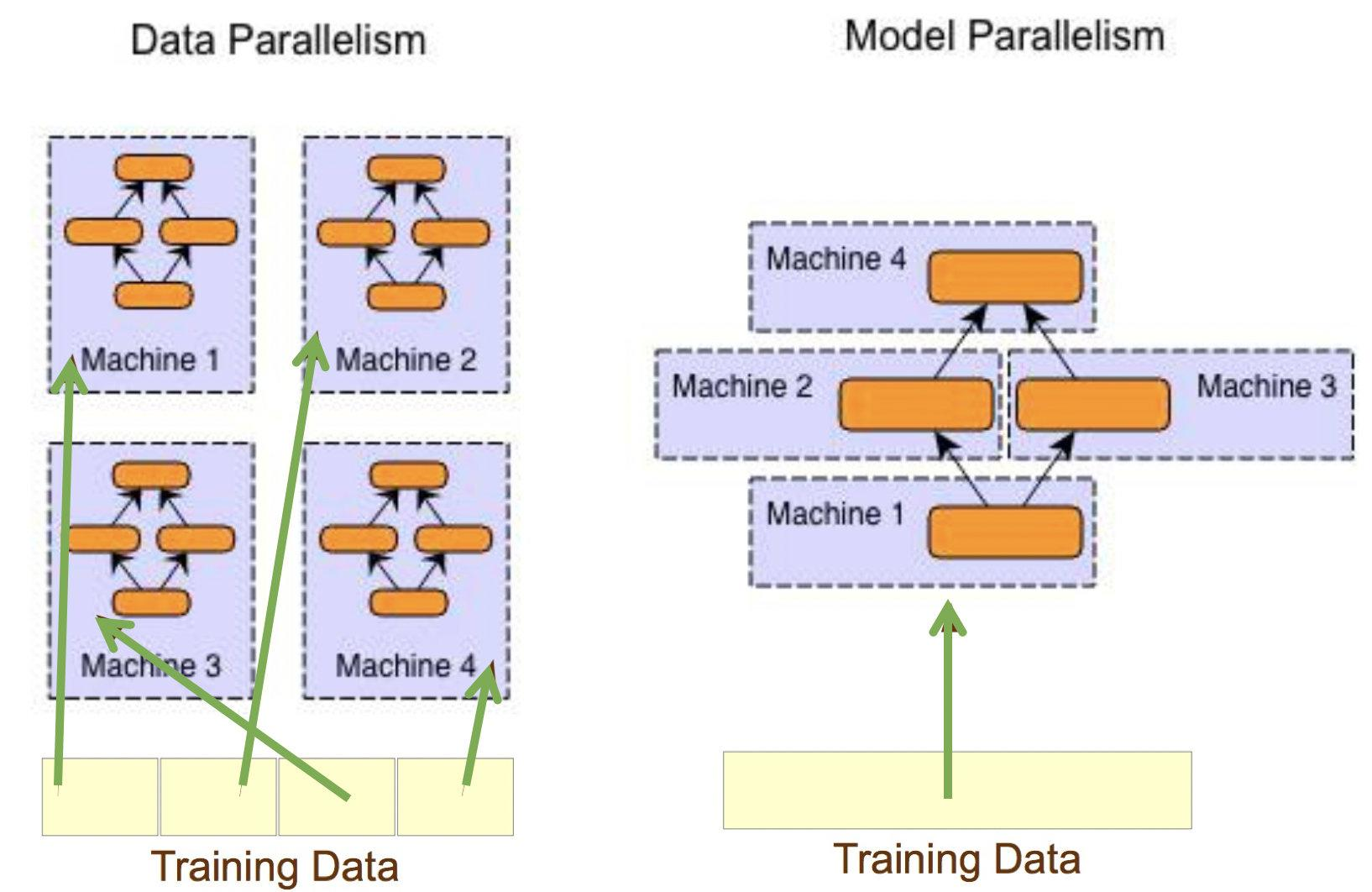
3种并行方式:
- 数据并行Data Paralleism:模型复制到不同GPU上,将
数据切分后,分配到不同的GPU上。 - 模型并行Model Paralleism:将
模型切分后,分配到不同的GPU上。分为张量并行和流水线并行。张量并行Tensor Paralleism:对模型参数 tensor 切分,分配到不同的GPU进行计算,在参数更新的时候再进行同步。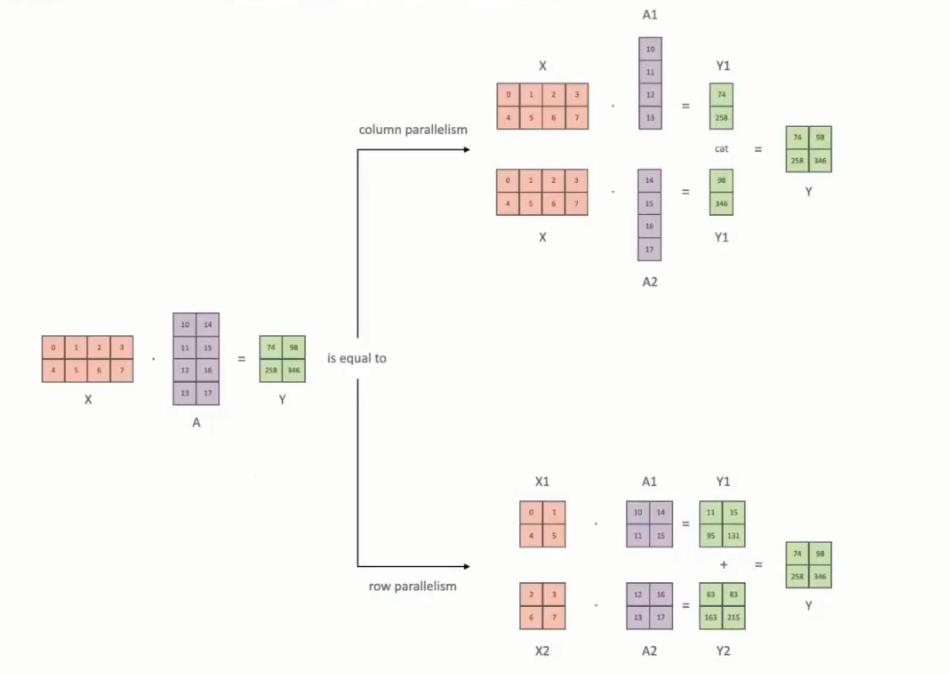
流水线并行Pipeline Paralleism:对模型按层layer切分,分配到不同的GPU上进行计算。
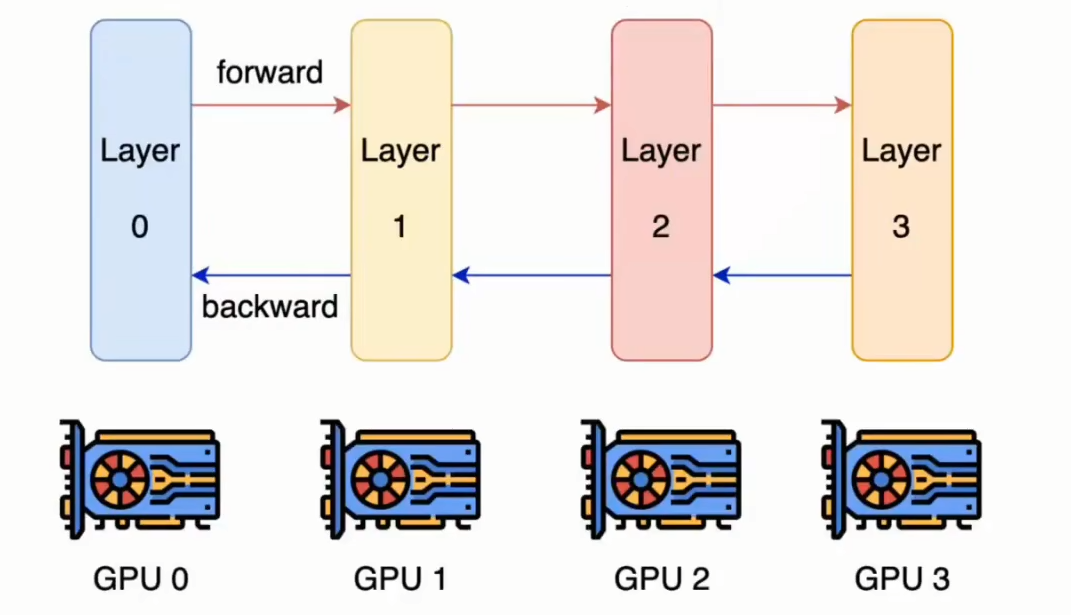
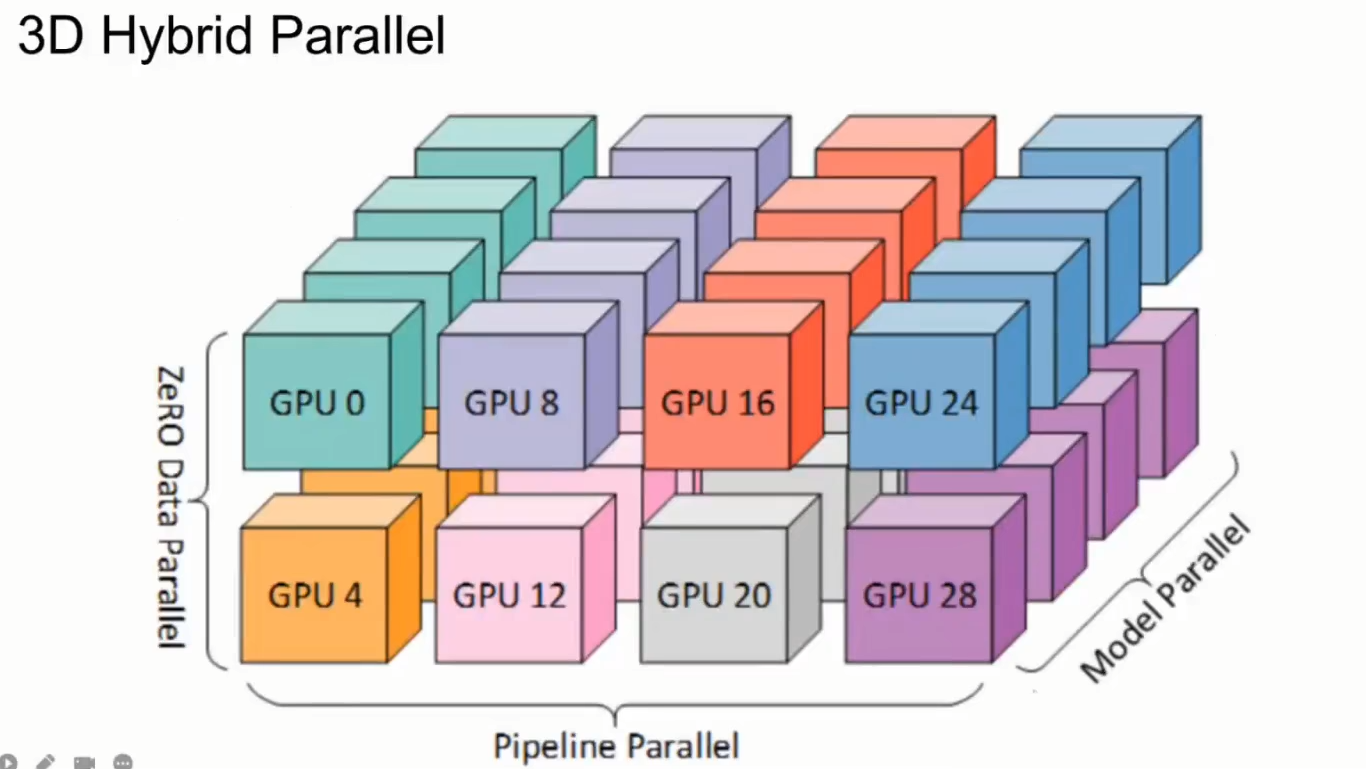
- 混合并行Hybrid Paralleism:同时进行数据并行、张量并行、流水线并行。
下面3个分布式框架都是基于 Pytorch 的并行框架:
DP(torch.nn.DataParallel):单机-单进程多线程进行实现的,它使用一个进程来计算模型权重,在每个batch处理期间将数据分发到每个GPU,每个GPU 分发到 batch_size/N 个数据,各个GPU的forward结果汇聚到master GPU上计算loss,计算梯度更新master GPU参数,将参数复制给其他GPU。(数据并行)DDP(torch.nn.DistributedDataParallel):可以单机/多机-多进程进行实现的,每个GPU对应的进程都有独立的优化器,执行自己的更新过程。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程(GPU)之间只传递梯度,这样网络通信就不再是瓶颈。(数据并行)FSDP(torch.distributed.fsdp.FullyShardedDataParallel):Pytorch最新的数据并行方案,在1.11版本引入的新特性,目的主要是用于训练大模型。我们都知道Pytorch DDP用起来简单方便,但是要求整个模型加载到一个GPU上,维护模型参数、梯度和优化器状态的每个 GPU 副本。FSDP则可以在数据并行的基础上,将模型参数和优化器分片分配到 GPU,这使得大模型的训练权重得以加载。(数据并行+模型并行)
这些在前面的博客已经讲过:
- 分布式并行训练(DP、DDP、DeepSpeed)
- pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
2.3 分布式工具
前面的分布式框架使用起来较为麻烦,因此分布式工具在底层对torch的分布式框架进行封装,实现更加方便的分布式训练和微调:
DerepSpeed(微软开发)Accelerate(Huggingface开发)
① DerepSpeed—Zero
DerepSpeed的原理是基于微软的研究:Zero(零冗余优化),研究哪些部分是占用存储空间的,并对这些占用存储的数据进行优化。
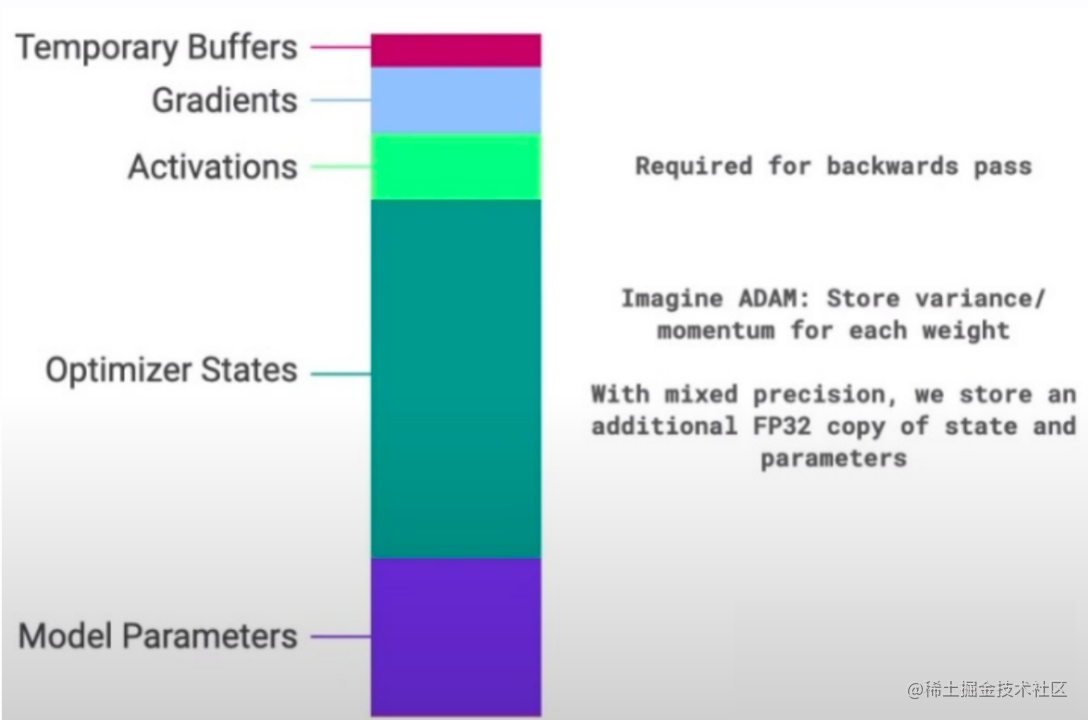
存储空间的消耗 Memory Consumption主要包含两部分:
- Model States(主):
模型参数Parameters、梯度Gradients、优化器Optimizer_State - Residual States(次):
前向传播激活值Activations、临时缓存区Temporal Buffers、内存碎片Unusable Fragmented Memory
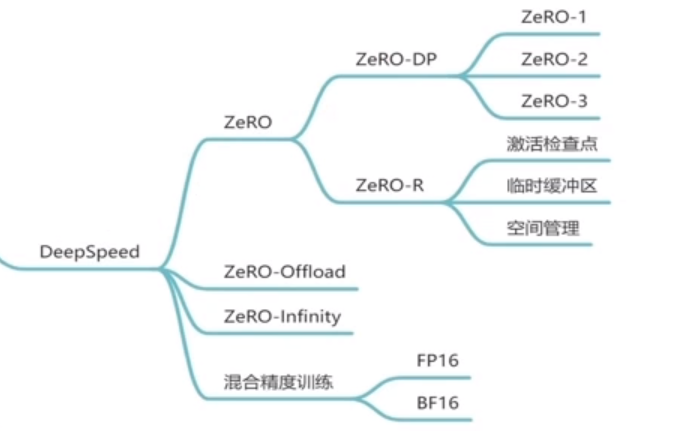
知道了什么东西会占存储,以及它们占了多大的存储之后,我们就可以来谈如何优化存储了。注意到,在整个训练中,有很多states并不会每时每刻都用到;因此提出了三种Zero优化方法:
-
Zero-DP(
优化Model States):作者采取三个方法优化内存,Pos、Pg、Pp。大体思路都是一样的,把每个模型的参数、梯度、优化器状态分别平均分给所有的gpu,当时计算需要用到其他gpu的内容时,通过GPU之间的通讯传输,以通讯换内存。其中前两个方法不增加通讯成本,第三个方法会增加GPU之间的通信成本。
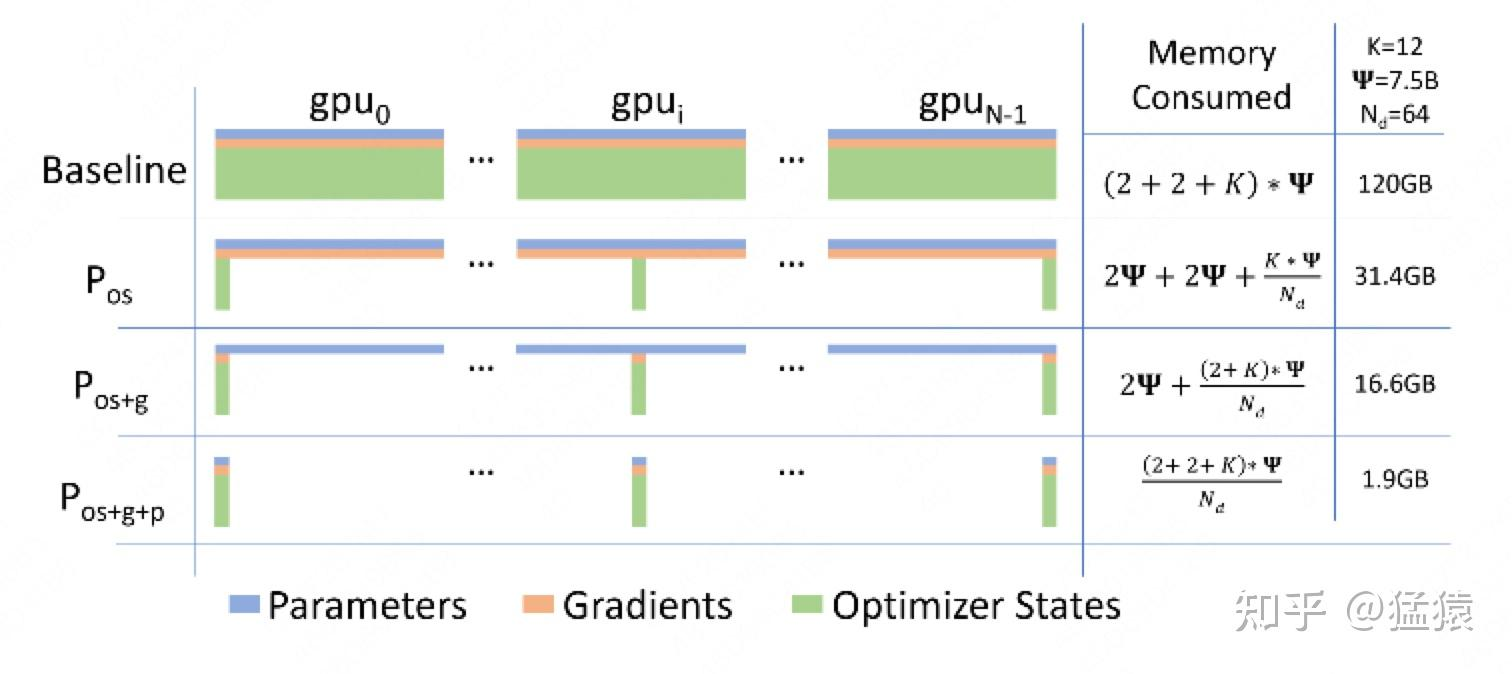
-
Zero-R(
优化Residual States):(1)激活函数:在前向传播计算完成激活函数之后,对把激活值丢弃,由于计算图还在,等到反向传播的时候,再次计算激活值,算力换内存。或者采取一个与cpu执行一个换入换出的操作。(2)临时缓冲区:模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行All Reduce啥的,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要创建临时数据,在固定缓冲区创建就好。(3)内存碎片:显存出现碎片的一大原因是时候gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁discarded activation复用了操作系统对内存的优化,不断内存整理。 -
混合精度训练:对于模型,我们肯定希望其参数越精准越好,也即我们用
fp32(单精度浮点数,存储占4byte)来表示参数W。但是在forward和backward的过程中,fp32的计算开销也是庞大的。那么能否在计算的过程中,引入fp16或bf16(半精度浮点数,存储占2byte),来减轻计算压力呢?于是,混合精度训练(float2hlaf)就产生了,它的步骤如下图:
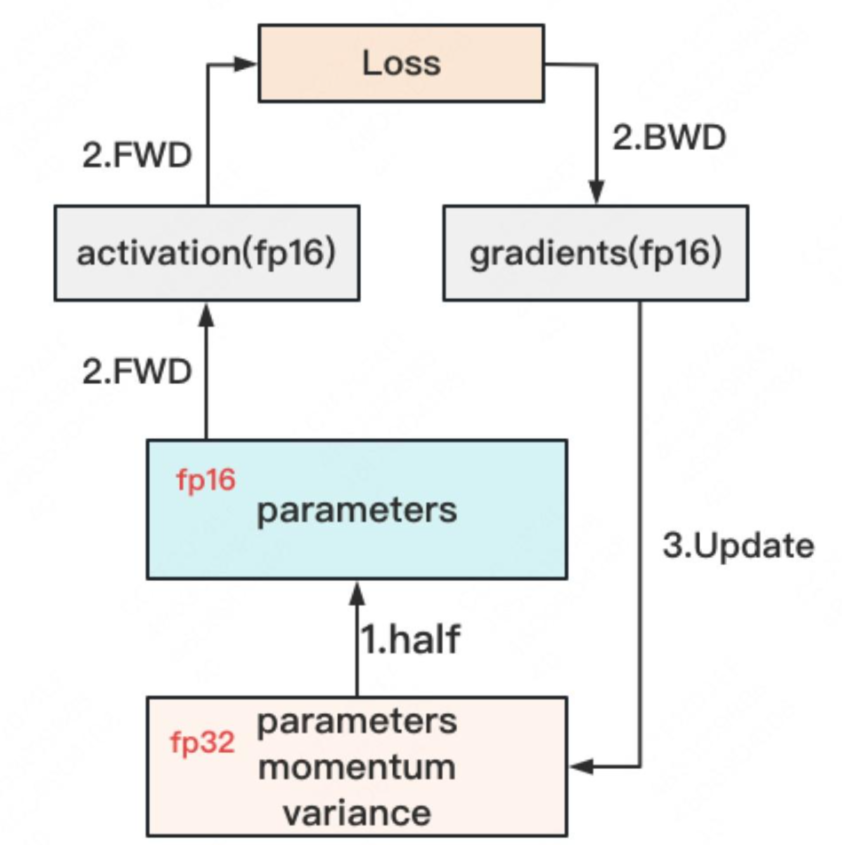
get fp32:存储一份fp32的Model States:parameter,momentum和variancefp32-to-fp16:在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter。fp16 computing:正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储。update fp32 model states:用fp16 gradients去更新fp32下的model states。
-
Zero-Offload:
GPU显存不够,CPU内存来凑。如下图,左边是正常的计算图,右侧是Zero-Offload的计算图。(⭕️表示state,正方形表示计算图,箭头表示数据流向、M表示模型参数,float2half表示32位转16位)其实就是forward和backward在GPU上计算,参数更新在CPU上。因为CPU与GPU通信数据开销很大,所以CPU和GPU传播的是gradient16,这样保证传播数据量最小。
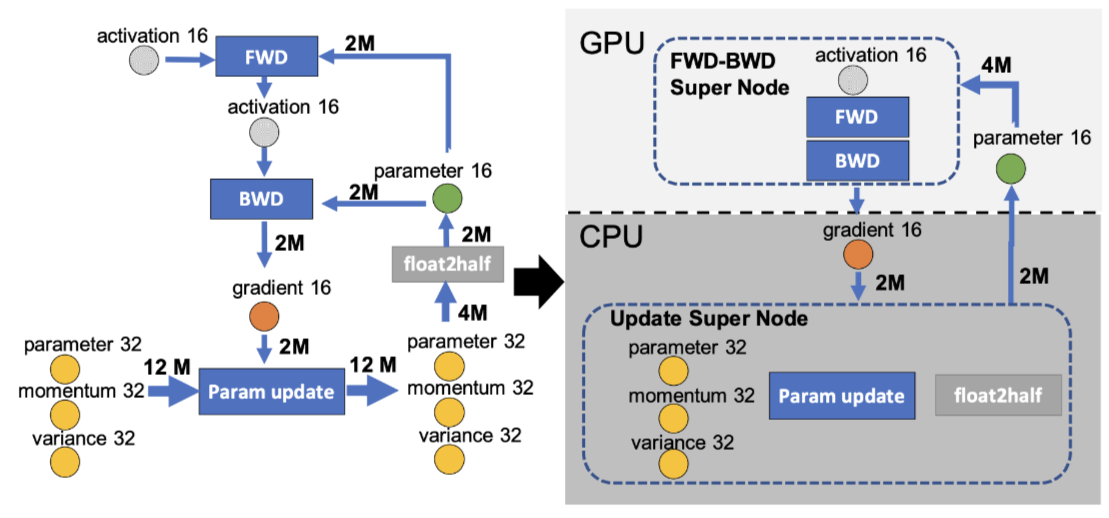
-
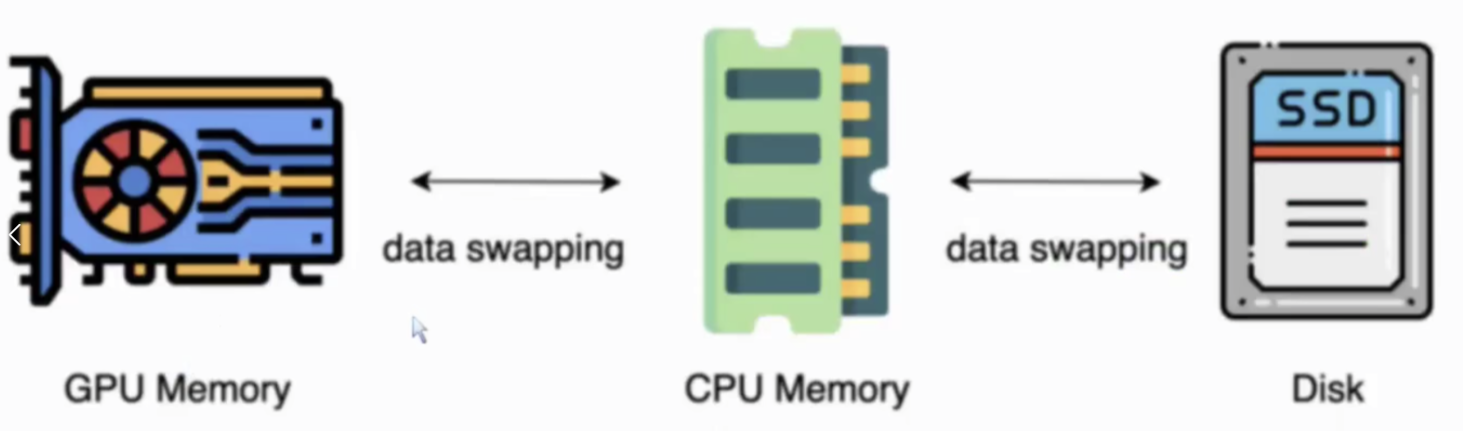
Zero-Infinity:
GPU内存不够,SSD外存来凑。
②Accelerate—Huggingface
相关文章:
《多GPU大模型训练与微调手册》
全参数微调 Lora微调 PTuning微调 多GPU微调预备知识 1. 参数数据类型 torch.dtype 1.1 半精度 half-precision torch.float16:fp16 就是 float16,1个 sign(符号位),5个 exponent bits(指数位),10个 ma…...
)
【C++】const与类(const修饰函数的三种位置)
目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const 目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const const基本介绍 const 是 C 中的修饰符,用于声明常量或表示不可修改的对象、函数或成员函数。 我们已经了解了const基本用法,我们先进行…...

深度学习在图像识别中的革命性应用
深度学习在图像识别中的革命性应用标志着计算机视觉领域的重大进步。以下是深度学习在图像识别方面的一些革命性应用: 1. **卷积神经网络(CNN)的崭新时代**: - CNN是深度学习在图像识别中的核心技术,通过卷积层、池化…...

R语言读文件“-“变成“.“
R语言读取文件时发生"-"变成"." 如果使用read.table函数,需要 check.namesFALSE data <- read.table("data.tsv", headerTRUE, row.names1, check.namesFALSE)怎样将"."还原为"-" 方法一:gsub函…...
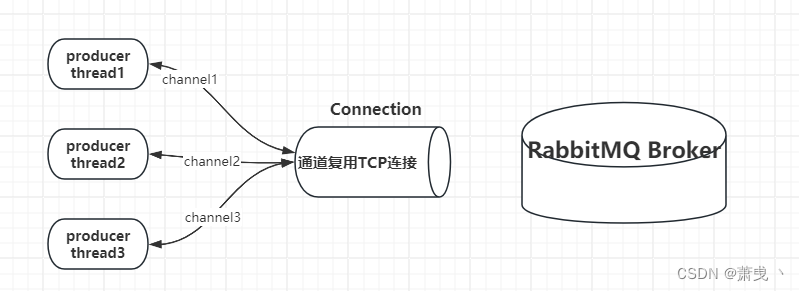
RabbitMQ 基础操作
概念 从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。 Queue 队列 Queue:队列,是RabbitMQ 的内部对象,用于存储消息。 RabbitMQ 中消息只能存储在队列中,这一点和Kafka相反。Kafka将消息存储在topic&am…...

自然语言处理:Transformer与GPT
Transformer和GPT(Generative Pre-trained Transformer)是深度学习和自然语言处理(NLP)领域的两个重要概念,它们之间存在密切的关系但也有明显的不同。 1 基本概念 1.1 Transformer基本概念 Transformer是一种深度学…...

Ps:裁剪工具 - 裁剪预设的应用
裁剪工具提供了两种类型的裁剪方式。 一种是仅按宽高比(比例)进行裁剪,常在对图像进行二次构图时采用。 另一种则按指定的图像尺寸(宽度值和高度值)及分辨率(宽 x 高 x 分辨率)进行裁剪。其实质…...

前端工程化-什么是构建工具
了解构建工具之前,我们首先要知道的是浏览器只认识html、css、js,而我们开发时用的vue,react框架都只是为了方便我们开发而使用的工具 使用构建工具的原因 vue或react的企业级项目里都会具备这些功能: 1.使用typescript语言&…...
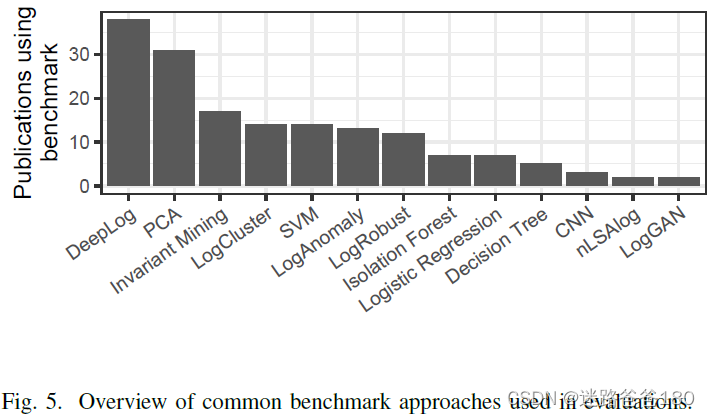
01-论文阅读-Deep learning for anomaly detection in log data: a survey
01-论文阅读-Deep learning for anomaly detection in log data: a survey 文章目录 01-论文阅读-Deep learning for anomaly detection in log data: a survey摘要I 介绍II 背景A 初步定义B 挑战 III 调查方法A 搜索策略B 审查的功能 IV 调查结果A 文献计量学B 深度学习技术C …...

图像处理02 matlab中NSCT的使用
06 matlab中NSCT的使用 最近在学习NSCT相关内容,奈何网上资源太少,简单看了些论文找了一些帖子才懂了一点点,在此分享给大家,希望有所帮助。 一.NSCT流程 首先我们先梳理一下NSCT变换的流程,只有清楚流程才更好的理清…...
提升办公效率,畅享多功能办公笔记软件Notion for Mac
在现代办公环境中,高效的笔记软件对于提高工作效率至关重要。而Notion for Mac作为一款全能的办公笔记软件,将成为你事业成功的得力助手。 Notion for Mac以其多功能和灵活性而脱颖而出。无论你是需要记录会议笔记、管理项目任务、制定流程指南…...
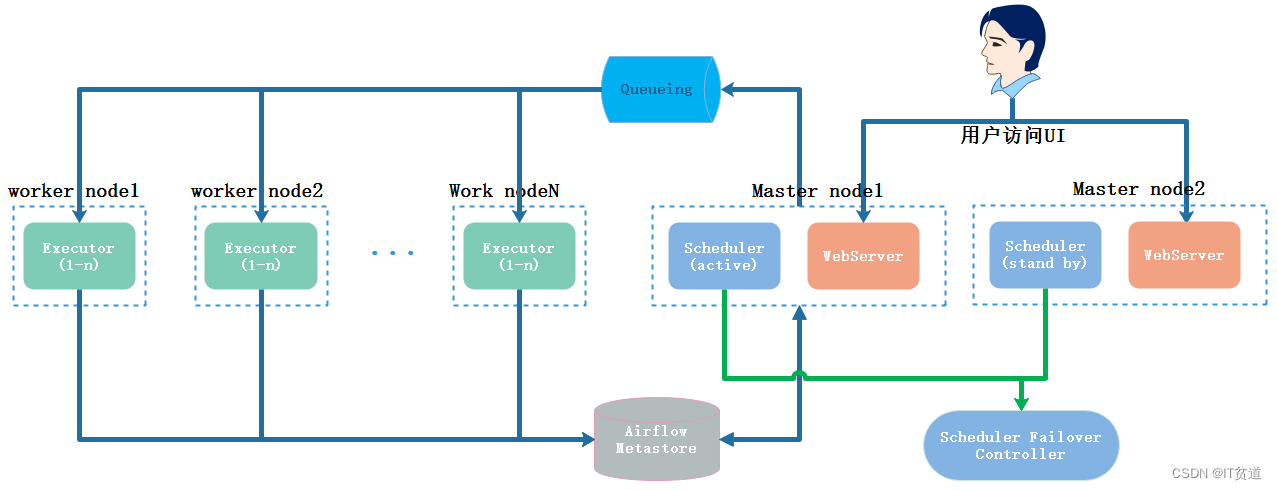
Apache Airflow (十三) :Airflow分布式集群搭建及使用-原因及
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...

# 聚类系列(一)——什么是聚类?
目前在做聚类方面的科研工作, 看了很多相关的论文, 也做了一些工作, 于是想出个聚类系列记录一下, 主要包括聚类的概念和相关定义、现有常用聚类算法、聚类相似性度量指标、聚类评价指标、 聚类的应用场景以及共享一些聚类的开源代码 下面正式进入该系列的第一个部分ÿ…...
Android DatePicker(日期选择器)、TimePicker(时间选择器)、CalendarView(日历视图)- 简单应用
示意图: layout布局文件:xml <?xml version"1.0" encoding"utf-8"?> <ScrollView xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"http://schemas.android.com/apk/res-auto"…...

linux环境搭建mysql5.7总结
以下安装方式,在阿里云与腾讯云服务器上都测试可用。 一、进入到opt目录下,执行: [rootmaster opt]# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz解压: [rootmaster opt]#…...
函数)
SQL Server Count()函数
SQL Server Count()函数 SQL Server COUNT() 是一个聚合函数,它返回在集合中找到的项目数。 COUNT() 函数语法: COUNT([ALL | DISTINCT ] expression)ALL 指示COUNT() 函数应用于所有值。ALL是默认值。返回非NULL值的数量(包括重复值&…...
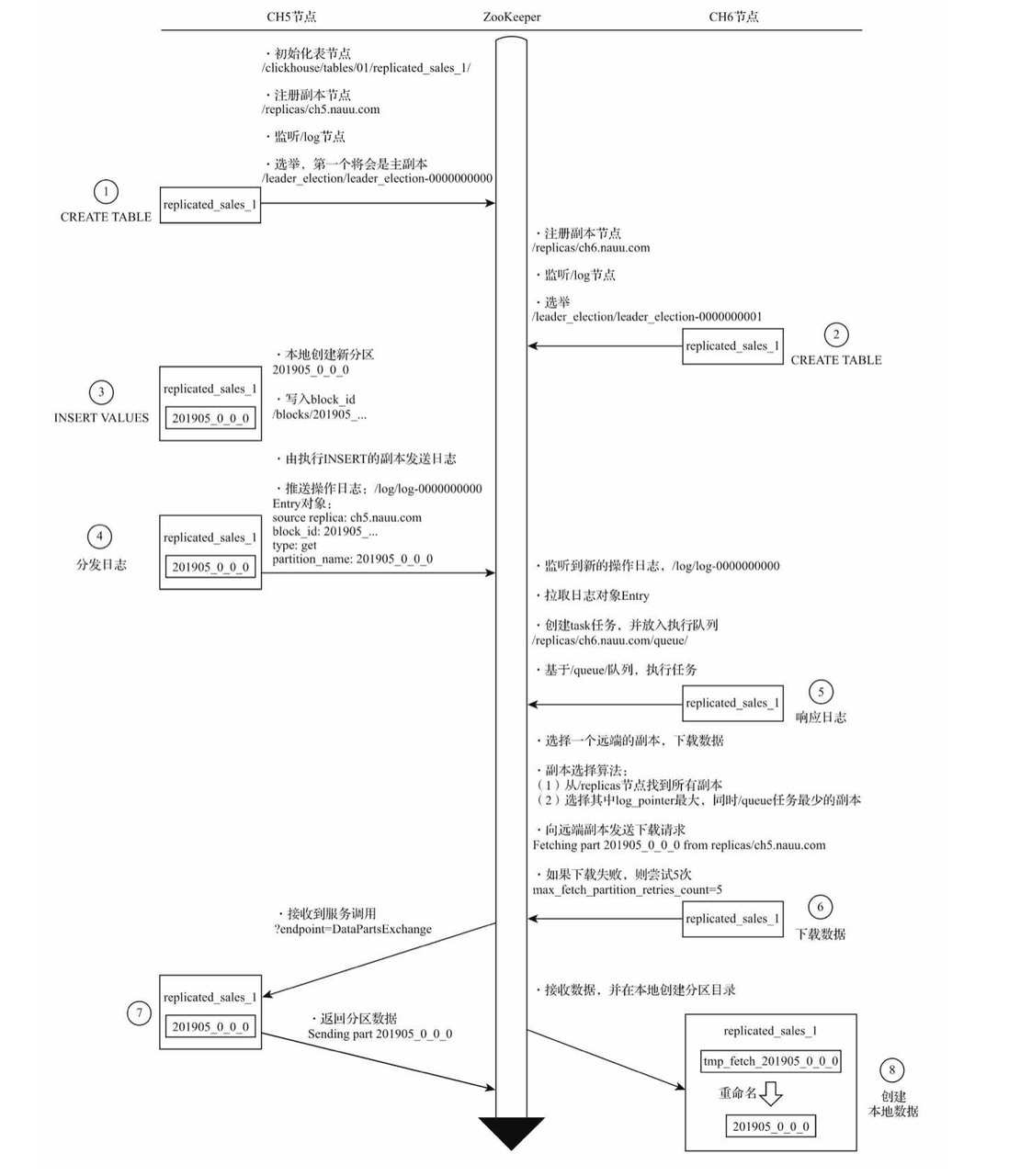
架构探索之路-第一站-clickhouse | 京东云技术团队
一、前言 架构, 软件开发中最熟悉不过的名词, 遍布在我们的日常开发工作中, 大到项目整体, 小到功能组件, 想要实现高性能、高扩展、高可用的目标都需要优秀架构理念辅助. 所以本人尝试编写架构系列文章, 去剖析市面上那些经典优秀的开源项目, 学习优秀的架构理念来积累架构设…...
易航网址引导系统 v1.9 源码:去除弹窗功能的易航网址引导页管理系统
易航自主开发了一款极其优雅的易航网址引导页管理系统,后台采用全新的光年 v5 模板开发。该系统完全开源,摒弃了后门风险,可以管理无数个引导页主题。数据管理采用易航原创的JsonDb数据包,无需复杂的安装解压过程即可使用。目前系…...
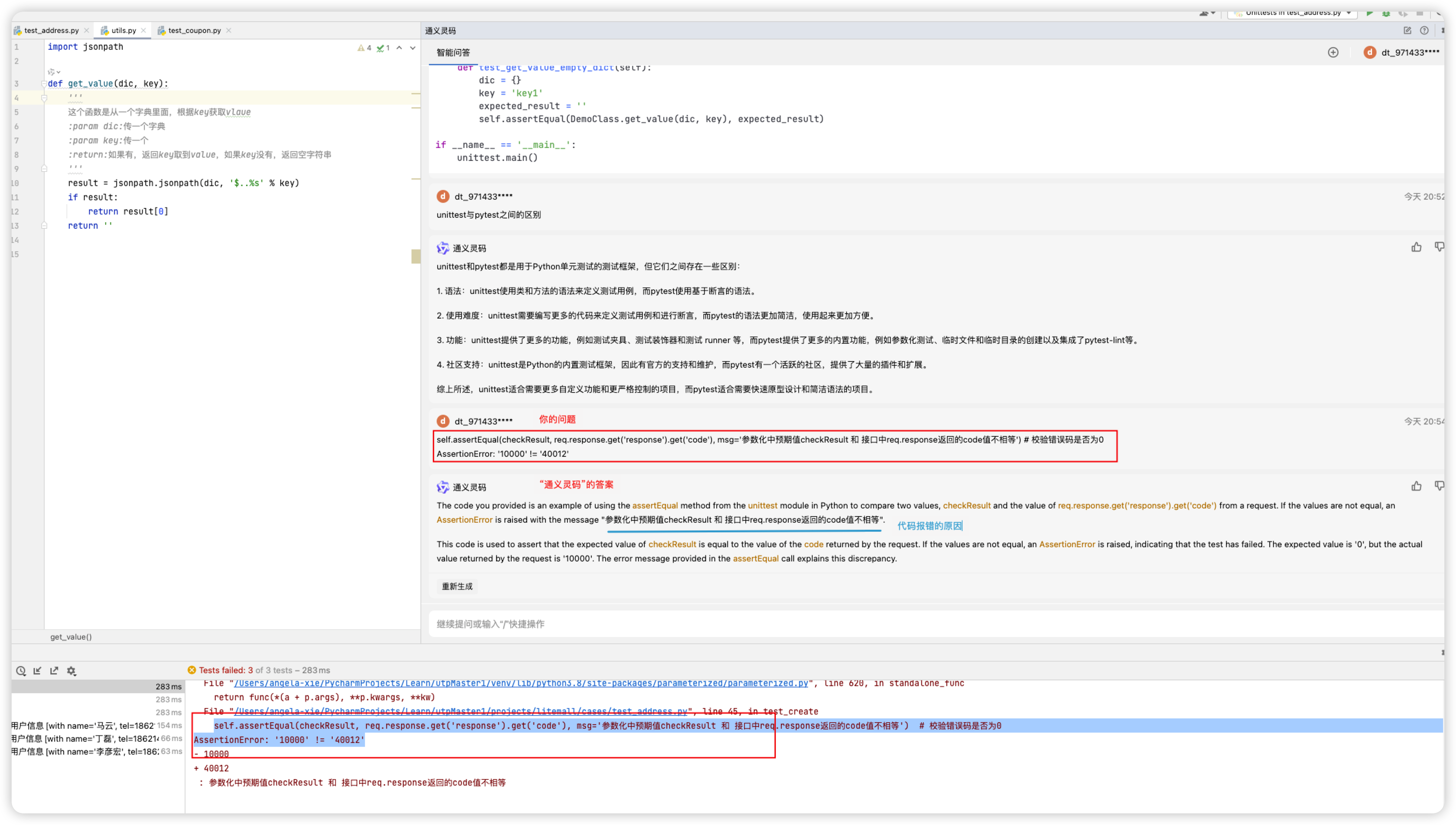
创新无界:通义灵码在测试过程中展现的独特魅力
通义灵码基于通义大模型,提供代码智能生成、研发智能问答能力。本文就来介绍下通义灵码在测试过程中的应用。 操作手册: 通义灵码, 阿里云提供的一款基于通义大模型的智能编码辅助工具_云效-阿里云帮助中心 1. 什么是通义灵码 是阿里云出品的一款基于通…...

crmchat安装搭建教程文档 bug问题调试
一、安装PHP插件:fileinfo、redis、swoole4。 二、删除PHP对应版本中的 proc_open禁用函数。 一、设置网站运行目录public, 二、设置PHP版本选择纯静态。 三、可选项如有需求则开启SSL,配置SSL证书,开启强制https域名。 四、添加反向代理。 …...

别再乱起名了!Windows文件命名避坑指南:从CON到260字符限制,这些坑你踩过吗?
Windows文件命名避坑实战:从CON到长路径的终极解决方案 你是否曾在命令行中尝试创建名为CON.txt的文件却遭遇系统拒绝?或是将精心整理的文档同步到云端时,突然提示"路径过长无法传输"?这些看似简单的文件命名问题&#…...

隐私计算框架Tensory:加密张量运算与机器学习安全实践
1. 项目概述与核心价值最近在开源社区里,一个名为kryptogrib/tensory的项目引起了我的注意。乍一看这个标题,它巧妙地融合了“Krypto”(加密)和“Tensor”(张量)这两个词根,直指其核心定位&…...

换背景照片怎么制作?2026年最全工具对比指南
你是不是也遇到过这样的问题——手机里的照片背景乱糟糟,想要一张干净的证件照却被收费吓退,或者商品图总是拍不出理想效果?其实换背景照片没有想象中那么复杂。今天我就把自己用过的所有工具都测试了一遍,给大家详细讲讲换背景照…...

射频电路设计进阶指南:从基础到实战的注意事项与小技巧
在射频(RF)电路设计中,从理论到工程实物的跨越往往充满挑战。许多初学者能熟练推导传输线方程,却在第一版PCB上被寄生效应、阻抗失配和意想不到的损耗打败。本文面向具备一定射频基础的工程师,梳理射频电路设计中六个核心层面的注意事项与实用技巧,帮助你避开常见陷阱,提…...

# 百万字不崩线的秘密——上下文衰减与长篇一致性治理
百万字不崩线的秘密——上下文衰减与长篇一致性治理 本文收录于《工程化AI人机协同方法论》系列专栏,对应系列第58篇核心文章,为《AI小说创作工程化实战》系列第五篇 核心结论前置:百万字长篇小说不崩线的核心敌人,从来不是AI的写作能力,而是上下文衰减——随着章节与文本…...

XUnity.AutoTranslator终极指南:让Unity游戏瞬间跨越语言障碍
XUnity.AutoTranslator终极指南:让Unity游戏瞬间跨越语言障碍 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言不通而错过那些精彩的日系RPG、欧美独立游戏或小众佳作&#…...

零NRE成本实现FPGA转ASIC:技术原理、流程与选型指南
1. 项目概述:零NRE成本的FPGA转ASIC之路在芯片设计领域,FPGA(现场可编程门阵列)和ASIC(专用集成电路)的路线选择,一直是工程师和产品经理们需要反复权衡的经典命题。FPGA以其灵活性、快速上市的…...

基于Termux的安卓恶意软件本地化分析平台OpenClaw实战指南
1. 项目概述与核心价值最近在移动安全研究圈里,一个名为OpenClaw_Termux的项目引起了我的注意。乍一看这个标题,很多朋友可能会有点懵——“OpenClaw”听起来像某个开源工具,“Termux”是安卓上的强大终端模拟器,这俩组合在一起是…...

智能代码助手WeClaw:基于LLM的开发者效率革命
1. 项目概述:一个面向开发者的智能代码助手 最近在GitHub上看到一个挺有意思的项目,叫 fastclaw-ai/weclaw 。乍一看这个名字,可能会有点摸不着头脑,但如果你是一个经常和代码打交道的开发者,尤其是需要处理大量重复…...

别再乱设False Path了!异步电路CDC Signoff中Max Delay约束的实战避坑指南
异步电路CDC Signoff中Max Delay约束的实战避坑指南 在数字芯片设计的后端实现流程中,异步时钟域(CDC)的时序收敛一直是个令人头疼的问题。不同于同步电路STA中清晰的setup/hold检查,CDC验证需要工程师对跨时钟域数据传输的本质有深刻理解。本文将聚焦一…...