Kafka-Producer
1、生产者
从编程的角度而言,生产者是一个消息的生产者,它负责创建消息并发送到Kafka集群中的一个或多个topic中。
1.1、客户端开发
一个正常的生产逻辑需要具备以下几个步骤:
- 配置生产者客户端参数及创建相应的生产者实例
- 构建待发送的消息
- public ProducerRecord(String topic, V value)
- public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable
headers) - public ProducerRecord(String topic, Integer partition, K key, V value)
- public ProducerRecord(String topic, K key, V value)
- public ProducerRecord(String topic, V value, Iterable
headers) - public ProducerRecord(String topic, K key, V value, Iterable
headers) - public ProducerRecord(String topic, Integer partition, K key, V value, Iterable
headers) - public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
- 发送消息
- 同步发送(sync)
- 异步发送(async)
- producer.send(record).get()
- 发后即忘(fire-and-forget)
- 关闭生产者实例
配置生产者客户端参数及创建相应的生产者实例
/*** @author supanpan* @date 2023/11/20*/
public class KafkaProducerAnalysis {public static final String brokerList = "localhost:9092";public static final String topic = "topic-demo";/*** bootstrap.servers 该参数用来指定生产者客户端连接Kafka集群所需的broker地址清单,格式为host:port,host2:port2* serializer 该参数指定了用来对消息key进行序列化的序列化器类,key.serializer和value.serializer两个参数需要设置,必须填写序列化器的全限定类名* client.id 该参数用来设置生产者客户端的ID,是一个字符串,如果不设置,KafkaProducer会自动生成一个非空字符串,格式为"producer-1"、"producer-2"等**/public static Properties initConfig() {Properties props = new Properties();props.put("bootstrap.servers", brokerList);props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");props.put("client.id", "producer.client.id.demo");return props;}/*** 防止配置书写错误,使用ProducerConfig类中的常量来设置参数* @return*/public static Properties initNewConfig() {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.demo");return props;}/*** 通过反射的方式来设置参数,获取序列化器的全限定类名**/public static Properties initPerferConfig() {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());return props;}public static void main(String[] args) throws InterruptedException {Properties props = initConfig();KafkaProducer<String, String> producer = new KafkaProducer<>(props);// KafkaProducer<String, String> producer = new KafkaProducer<>(props,
// new StringSerializer(), new StringSerializer());// 创建ProducerRecord对象,其中topic、value是必填项,其余属性都是可选项,partition、timestamp、key、headersProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!");try {producer.send(record);// 异步发送,获取回调对象获取发送结果
// producer.send(record, new Callback() {
// @Override
// public void onCompletion(RecordMetadata metadata, Exception exception) {
// if (exception == null) {
// System.out.println(metadata.partition() + ":" + metadata.offset());
// }
// }
// });} catch (Exception e) {e.printStackTrace();}finally {// 关闭生产者实例producer.close();}// TimeUnit.SECONDS.sleep(5);}
}
1.2、序列化
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网路发送给Kafka。
消费者需要用反序列化器(Deserializer)把字节数组转换成相应的对象才能使用。
生产者使用的序列化器和消费者使用的反序列化器必须是一致的,否则消费者无法正常消费生产者发送的消息。
常见序列化器:
- ByteArray
- ByteBuffer
- Bytes
- Double
- Integer
- Long
- String
上面列举的序列化器都是Kafka提供的,如果需要自定义序列化器,需要实现Serializer接口
org.apache.kafka.common.serialization.Serializer,此接口有三个方法
- configure(Map<String, ?> configs, boolean isKey)
- 该方法主要用来配置当前类,通过传入的configs参数获取配置信息,isKey参数用来指明当前配置的是key的序列化器还是value的序列化器
- serialize(String topic, T data)
- 该方法用来将给定的对象序列化成字节数组
- close()
- 该方法用来关闭当前序列化器,一般情况下可以空实现
- 如果实现了此方法,则必须保证此方法的幂等性
1.3、分区器
分区器(Partitioner)是生产者在将消息发送到Kafka集群时,根据分区策略选择消息发送的分区。
Kafka提供了默认的分区策略,即DefaultPartitioner,该分区器会根据ProducerRecord对象中的key来计算分区号。
- 如果key为null,则使用轮询的方式选择分区,如果key不为null,则使用key的hash值来计算分区号。
- 如果需要自定义分区器,需要实现Partitioner接口org.apache.kafka.clients.producer.Partitioner,该接口有两个方法:
Partitioner接口的方法
- configure(Map<String, ?> configs)
- 该方法主要用来配置当前类,通过传入的configs参数获取配置信息
- 该方法在创建分区器实例时调用一次,用来初始化分区器
- 这个方法来自Partitioner的父接口Configurable,该接口还有一个方法void close(),用来关闭当前分区器,一般情况下可以空实现
- partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
- 该方法用来计算分区号
- topic:当前消息所属的topic
- key:当前消息的key
- keyBytes:当前消息key的字节数组
- value:当前消息的value
- valueBytes:当前消息value的字节数组
- cluster:当前Kafka集群的信息
- 返回值:当前消息的分区号
自定义分区器
/*** 自定义分区器**/
public class DemoPartitioner implements Partitioner {private final AtomicInteger counter = new AtomicInteger(0);@Overridepublic int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if (null == keyBytes) {return counter.getAndIncrement() % numPartitions;} elsereturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
实现自定义的DemoPartitioner分区器后,需要在配置文件中指定分区器的全限定类名,即partitioner.class属性。
配置添加方式:
-
props.put(“partitioner.class”, “com.supanpan.kafka.demo.partitioner.DemoPartitioner”);
-
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoPartitioner.class.getName());
1.4、生产者拦截器
拦截器(Interceptor)是在消息在序列化和反序列化过程中对消息进行处理的组件,它是在消息生产者和消费者与Kafka集群之间的一个拦截点,可以在消息发送前和消费之后对消息进行一些定制化的操作。
Kafka拦截器有两种类型:
- 生产者拦截器
- 消费者拦截器
拦截器是Producer和Consumer的一个公共接口,分别对应两个子接口:ProducerInterceptor和ConsumerInterceptor。
- ProducerInterceptor
- public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
- public void onAcknowledgement(RecordMetadata metadata, Exception exception);
- public void close();
- public void configure(Map<String, ?> configs);
- ConsumerInterceptor
- public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
- public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
- public void close();
- public void configure(Map<String, ?> configs);
- onSend方法会在消息被序列化以前和封装成ProducerRecord对象之后调用,可以利用该方法对消息进行定制化操作,比如修改消息的某些内容,或者增加消息的头部信息等。
生产者拦截器示例
public class ProducerInterceptorPrefix implements ProducerInterceptor<String, String> {private volatile long sendSuccess = 0;private volatile long sendFailure = 0;@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {String modifiedValue = "prefix1-" + record.value();return new ProducerRecord<>(record.topic(),record.partition(), record.timestamp(),record.key(), modifiedValue, record.headers());
// if (record.value().length() < 5) {
// throw new RuntimeException();
// }
// return record;}@Overridepublic void onAcknowledgement(RecordMetadata recordMetadata,Exception e) {if (e == null) {sendSuccess++;} else {sendFailure++;}}@Overridepublic void close() {double successRatio = (double) sendSuccess / (sendFailure + sendSuccess);System.out.println("[INFO] 发送成功率="+ String.format("%f", successRatio * 100) + "%");}@Overridepublic void configure(Map<String, ?> map) {}
}
在KafkaProducer的配置参数中指定拦截器的全限定类名,即interceptor.classes属性。
配置方式:
-
props.put(“interceptor.classes”, “com.supanpan.kafka.demo.interceptor.ProducerInterceptorPrefix”);
-
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptorPrefix.class.getName())
KafkaProducer中不仅可以指定一个拦截器,还可以指定多个拦截器形成拦截链,
多个拦截器的执行顺序与它们在配置文件中的顺序一致,即先配置的拦截器先执行,后配置的拦截器后执行,
配置的时候,各个拦截器之间使用逗号隔开
1.5、原理分析
整个生产者客户端由两个线程协调运行,这两个线程分别是main线程(主线程)和Sender线程(发送线程)。
- main线程负责接收客户端的请求,将请求转发给Sender线程,然后等待Sender线程的响应结果。
- 在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。
- Sender线程负责从RecordAccumulator中拉取消息批次(Batch),并将消息批次发送给Kafka集群。
- Sender线程将消息批次发送给Kafka集群后,会根据Kafka集群的响应结果,对消息批次中的消息进行分类,分为发送成功的消息和发送失败的消息。
- Sender线程会将发送失败的消息重新放入RecordAccumulator中,等待下次发送。
- Sender线程会将发送成功的消息提交给RecordAccumulator,RecordAccumulator会将消息从消息缓冲区中移除。
RecordAccumulator
-
主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能
-
RecordAccumulator内部维护了一个消息缓冲区,该缓冲区由多个消息批次组成,每个消息批次中可以存放多条消息。
-
RecordAccumulator内部的消息缓冲区是一个双端队列,每个消息批次都是一个双端队列中的一个元素。
- 主线程中发送过来的消息都会被追加到RecordAccumulator的某个双端队列(Deque)中,在RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque < ProducerBatch >。
- 消息写入缓存时,追加到双端队列的尾部
- Sender读取消息时,从双端队列的头部读取
-
RecordAccumulator内部的消息缓冲区中的消息批次是按照消息的topic和partition进行组织的,即每个topic-partition对应一个消息批次。
消息发送流程
- KafkaProducer.send()方法将消息发送给KafkaProducer内部的RecordAccumulator(消息累加器)。
- KafkaProducer内部的Sender线程不断从RecordAccumulator中拉取消息批次(Batch),并将消息批次发送给Kafka集群。
- KafkaProducer内部的Sender线程将消息批次发送给Kafka集群后,会根据Kafka集群的响应结果,对消息批次中的消息进行分类,分为发送成功的消息和发送失败的消息。
- KafkaProducer内部的Sender线程会将发送失败的消息重新放入RecordAccumulator中,等待下次发送。
- KafkaProducer内部的Sender线程会将发送成功的消息提交给RecordAccumulator,RecordAccumulator会将消息从消息缓冲区中移除。
消息发送失败的情况
- 消息发送失败的情况
- 消息发送失败的情况主要有两种:
- 一种是消息发送失败,但是可以重试,比如网络异常等。
- 另一种是消息发送失败,且不可重试,比如消息太大、消息格式错误等。
- 对于第一种情况,KafkaProducer内部的Sender线程会将发送失败的消息重新放入RecordAccumulator中,等待下次发送。
- 对于第二种情况,KafkaProducer内部的Sender线程会将发送失败的消息放入RecordAccumulator中,但是不会重试发送,因为这种情况下消息是不可恢复的。
- 消息发送失败的处理
- 消息发送失败的处理主要有两种方式:
- 一种是将消息发送失败的异常抛出给用户,由用户来决定如何处理。
- 另一种是将消息发送失败的异常记录到日志中,然后由KafkaProducer内部的Sender线程来处理。
- KafkaProducer内部的Sender线程会将发送失败的消息重新放入RecordAccumulator中,等待下次发送。
- KafkaProducer内部的Sender线程会将发送成功的消息提交给RecordAccumulator,RecordAccumulator会将消息从消息缓冲区中移除。
- 消息发送失败的处理主要有两种方式:
1.6、重要的生产者参数
- acks
- 这个参数用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的
- acks默认值
- acks=0
- 生产者在成功写入消息之前不会等待任何来自服务器的响应
- acks设置为0可以达到最大的吞吐量,但是会丢失一些消息
- acks=1
- 默认值即为1,生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应
- 如果leader副本在成功写入消息之后,但是还没有来得及将消息同步到所有的follower副本之前,这时候如果leader副本宕机,那么这条消息就会丢失
- 为了避免消息丢失,生产者可以选择重发消息
- acks=all 或 acks=-1
- 生产者发送消息之后,只有当分区的leader副本成功写入消息,并且所有的follower副本都成功写入消息之后,生产者才会收到来自服务端的成功响应
- 这种情况下,只要有一个副本存活,那么这条消息就不会丢失
- 但是这种情况下,由于需要等待所有的副本都成功写入消息之后,生产者才会收到来自服务端的成功响应,所以生产者的吞吐量会受到影响
- 在这个模式下可以达到最强的可靠性
- acks=0
- 参数配置方式(注意都是字符串形式)
- properties.put(“acks”, “0”);
- properties.put(ProducerConfig.ACKS_CONFIG, “0”);
- max.request.size
- 该参数用来指定生产者发送消息的最大值,默认值为1048576字节,即1MB
- 如果生产者发送的消息大小超过了max.request.size参数指定的值,那么生产者会抛出RecordTooLargeException异常
- 参数配置方式
- properties.put(“max.request.size”, “10485760”);
- properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);
- retries & retry.backoff.ms
- retries参数用来指定生产者发送消息失败后,重试发送的次数,默认值为0,即不进行重试
- retry.backoff.ms参数用来指定两次重试发送消息的间隔,默认值为100ms,避免无效的频繁重试
- 参数配置方式
- properties.put(“retries”, “3”);
- properties.put(ProducerConfig.RETRIES_CONFIG, 3);
- properties.put(“retry.backoff.ms”, “500”);
- properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 500);
- compression.type
- 该参数用来指定消息的压缩类型,默认值为none,即不压缩
- 常见配置
- none:不压缩
- gzip:使用GZIP算法压缩
- snappy:使用Snappy算法压缩
- lz4:使用LZ4算法压缩
- 参数配置方式
- properties.put(“compression.type”, “gzip”);
- properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, “gzip”);
- connections.max.idle.ms
- 该参数用来指定生产者与Kafka集群建立连接的空闲时间,默认值为540000,即9分钟
- linger.ms
- 该参数用来指定生产者在发送消息前等待一段时间,希望可以等到更多的消息一起发送,以减少网络请求的次数,从而提升性能,默认值为0,即立即发送
- 参数配置方式
- properties.put(“linger.ms”, “1000”);
- properties.put(ProducerConfig.LINGER_MS_CONFIG, 1000);
- receive.buffer.bytes
- 该参数用来指定Socket接收消息缓冲区(SO_RECBUF)大小,默认值为32768字节,即32KB
- 参数配置方式
- properties.put(“receive.buffer.bytes”, “65536”);
- properties.put(ProducerConfig.RECEIVE_BUFFER_CONFIG, 65536);
- send.buffer.bytes
- 该参数用来指定Socket发送消息缓冲区(SO_SNDBUF)大小,默认值为131072字节,即128KB
- 参数配置方式
- properties.put(“send.buffer.bytes”, “131072”);
- properties.put(ProducerConfig.SEND_BUFFER_CONFIG, 131072);
- request.timeout.ms
- 该参数用来指定生产者发送消息到Kafka集群时等待响应的最大时间,默认值为30000,即30秒
- 参数配置方式
- properties.put(“request.timeout.ms”, “60000”);
- properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
相关文章:

Kafka-Producer
1、生产者 从编程的角度而言,生产者是一个消息的生产者,它负责创建消息并发送到Kafka集群中的一个或多个topic中。 1.1、客户端开发 一个正常的生产逻辑需要具备以下几个步骤: 配置生产者客户端参数及创建相应的生产者实例构建待发送的消…...

Ubuntu20上离线安装samba
如果联网,一条 sudo apt-get install samba就可能解决问题,但是没有网,那么只能一个一个的解决问题: 我以为装了samba-common就可以了,发现smbd.serverice not found,于是开始了漫长的下载依赖包,安装&…...

【开源】基于Vue.js的教学过程管理系统
项目编号: S 054 ,文末获取源码。 \color{red}{项目编号:S054,文末获取源码。} 项目编号:S054,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 教师端2.2 学生端2.3 微信小程序端2…...
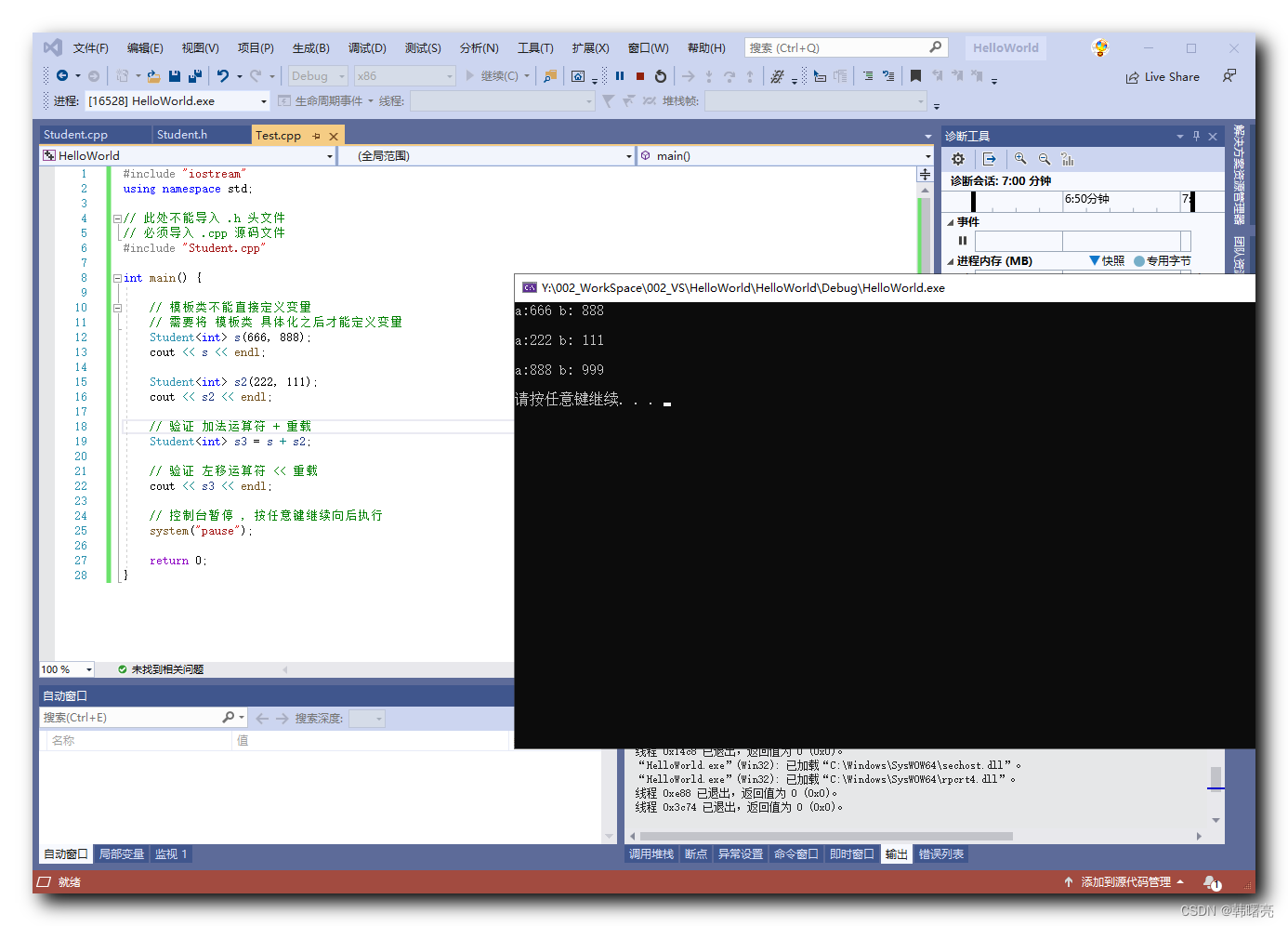
【C++】泛型编程 ⑪ ( 类模板的运算符重载 - 函数实现 写在类外部的不同的 .h 头文件和 .cpp 代码中 )
文章目录 一、类模板的运算符重载 - 函数实现 写在类外部的不同的 .h 头文件和 .cpp 代码中1、分离代码 后的 友元函数报错信息 - 错误示例Student.h 头文件内容Student.cpp 代码文件内容Test.cpp 代码文件内容执行报错信息 2、问题分析 二、代码示例 - 函数实现 写在类外部的不…...
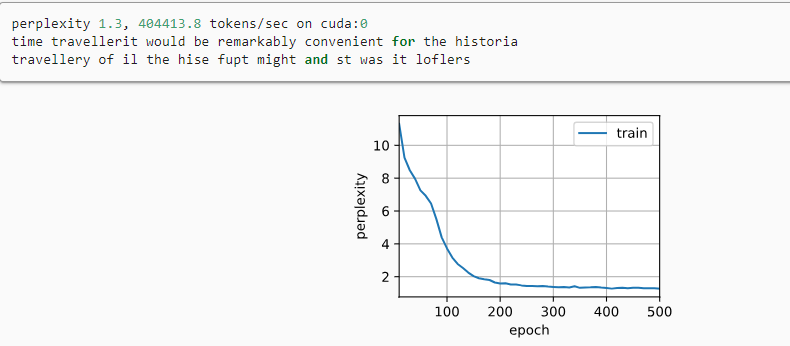
动手学深度学习——循环神经网络的简洁实现(代码详解)
文章目录 循环神经网络的简洁实现1. 定义模型2. 训练与预测 循环神经网络的简洁实现 # 使用深度学习框架的高级API提供的函数更有效地实现相同的语言模型 import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2lbatch_size, …...

19.删除链表的倒数第 N 个节点
题目来源: leetcode题目,网址:19. 删除链表的倒数第 N 个结点 - 力扣(LeetCode) 解题思路: 使用双指针找到倒数第 N1 个节点后删除链表的第 N 个节点即可。注意当 N 为链表长度时,倒数第 N1 …...
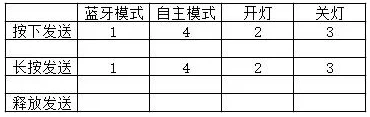
机器人制作开源方案 | 莲花灯
1. 功能描述 莲花灯是一款基于莲花形象设计的机器人,本文示例将用两种模式来实现莲花灯的亮灭功能。 自主模式:用 光强传感器 控制莲花灯的灯叶开合。暗光情况下灯叶打开,灯亮;强光情况下灯叶闭合,灯灭。 …...
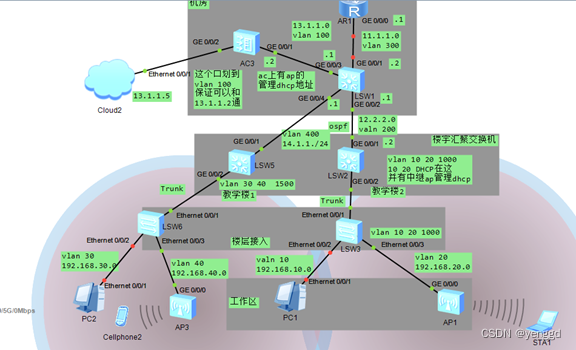
华为无线ac+fit三层组网,每个ap发射不同的业务vlan
ap管理dhcp在ac控制器上,业务dhcp在汇聚上 配置WLAN业务 (1)配置VAP模板 • 配置员工网络的VAP模板(employee) [AC-wlan-view] security-profile name employee //创建名为“employee”的安全模板 [AC-wlan-sec-prof-…...

人工智能:科技之光,生活之美
在科技飞速发展的今天,人工智能已经深入到我们的生活中,它如同一束璀璨的科技之光,照亮我们生活的每一个角落,使我们的生活更加美好。下面我将从人工智能的领域、应用以及对人工智能的看法三个方面来谈谈它对我们生活的影响。 一、…...

mysql8.0英文OCP考试第61-70题
Q61.You wish to protect your MySQL database against SQL injection attacks. Which method would fail to do this? A)using stored procedures for any database access B)using PREPARED STATEMENTS C)installing and configuring the Connection Control plugin ( …...

WaveletPool:抗混叠在微小目标检测中的重要性
文章目录 摘要1、简介2、相关研究2.1、微小物体检测2.2. 抗锯齿过滤器3、方法3.1. Wavelet Pooling3.2 一致顺序的Wavelet Pooling的WaveCNet3.3、Bottom-Heavy Backbone4、实验4.1、预训练数据集4.2、微小目标检测数据集4.3、抗混叠方法的选择及应用顺序4.4、小波的选择4.5、T…...
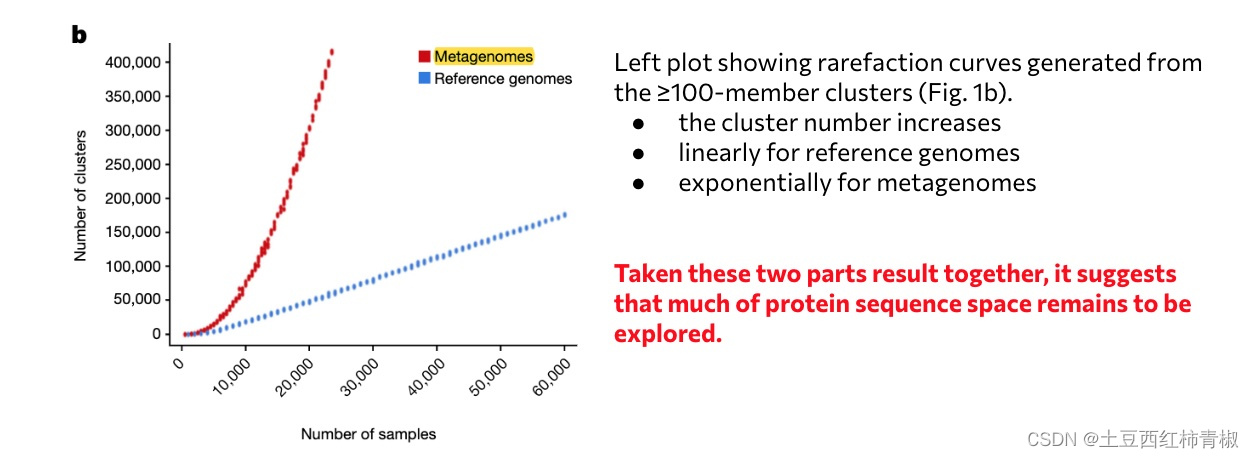
文章系列2:Unraveling the functional dark matter through global metagenomics
这篇文章发布于2023年10月nature。通讯作者是来自于 DOE Joint Genome Institute, Lawrence Berkeley National Laboratory, Berkeley, CA, USA. 背景介绍&目标 作者首先背景介绍了两种主流宏基因组分析方法,包括reads-based reference mapping(eg…...

ubuntu 20.04 搭建crash dump问题分析环境
ubuntu 20.04 搭建crash dump问题分析环境 1 安装依赖软件1.1 linux-dump1.2 kexec-tools1.3 安装crash工具1.4 安装gdb调试工具1.5 安装ubuntu内核调试符号1.5.1 GPG 秘钥导入1.5.2 添加仓库配置1.5.3 更新软件包1.5.4 下载和安装内核调试符号1.5.5 验证内核调试符号已经被安装…...

算法训练营一刷 总结篇
今天就是Day60了,坚持了两个月的算法训练营在今天结束了。这两个月中,学习、练习了许许多多的算法,坚持每天完成博客来打卡,养成了写C的习惯,现在相比于Python我反而更喜欢思路严谨的C。感谢这个平台,感谢C…...
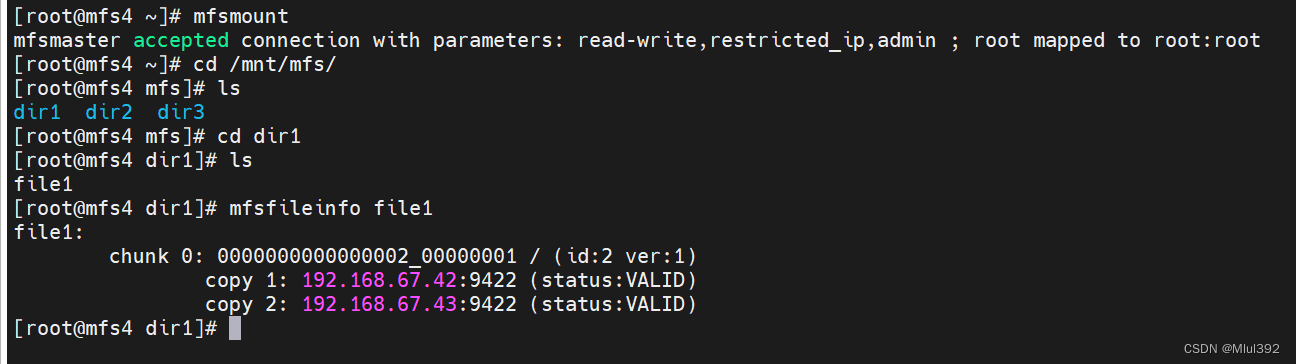
Linux中的MFS分布式文件系统
目录 一、MFS分布式文件系统 1、MooseFS简介 2、Moose File System的体系结构 (1)MooseFS Master (2)MooseFS Chunk Server (3)MooseFS Metalogger (4)MooseFS Client &…...

气相色谱质谱仪样品传输装置中电动针阀和微泄漏阀的解决方案
标题 摘要:针对目前国内外各种质谱仪压差法进样装置无法准确控制进气流量,且无相应配套产品的问题,本文提出了相应的解决方案和配套部件。解决方案主要解决了制作更小流量毛细管和毛细管进气端真空压力精密控制问题,微流量毛细管的…...
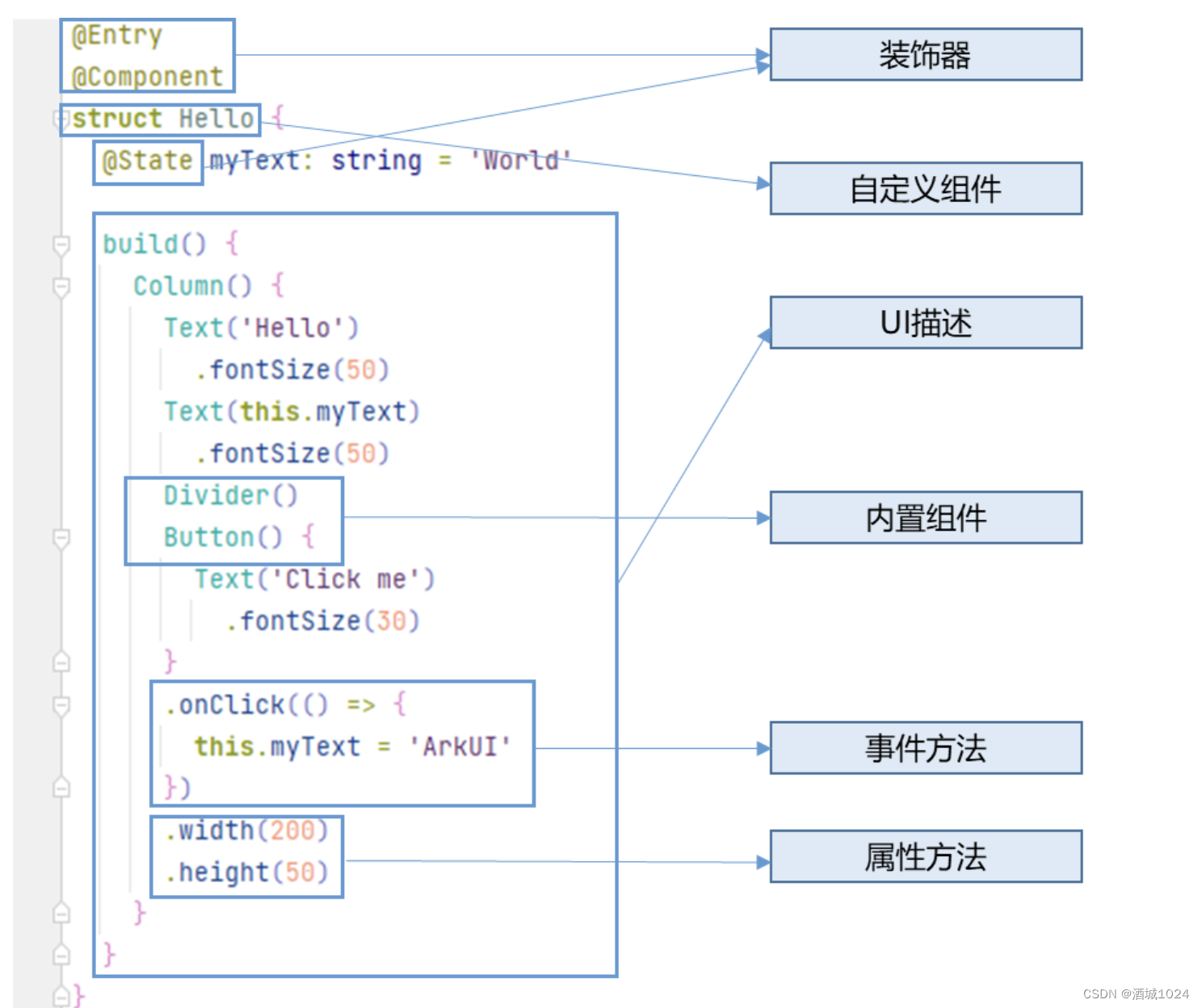
ArkTS基础知识
ArkTS基础知识 ArkUI开发框架 ArkTS声明式开发范式 装饰器: 用来装饰类,结构体,方法及变量。如: Entry:入口组件 Component :表示自定义组件 State 都是装饰器:组件中的状态变量,该…...
)
Kotlin学习(二)
2.kotlin学习(二) 1.条件控制 package com.simon.secondfun main(args: Array<String>) {//ifvar a 1var b 2var max:Intif (a > b){max a}else{max b}//作为表达式结果赋值给max1 感觉这个简单啊var max1 if(a>b)a else bprintln(ma…...

LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型
根据图片生成推广文案, 用的HuggingFace中的image-caption模型 LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数…...

QFontDialog开发详解
QFontDialog 类是 Qt 框架中用于选择字体的对话框类。它允许用户选择字体的各种属性,如字体名称、字号、粗体、斜体等。以下是 QFontDialog 的一些常见用法和详解: 一、QFontDialog基本用法 #include <QApplication> #include <QFontDialog> #include <QMes…...

工业AI质检的下一站:从MVTec AD到3D点云,聊聊少样本学习与异常合成的实战技巧
工业AI质检的下一站:从MVTec AD到3D点云,聊聊少样本学习与异常合成的实战技巧 在工业质检领域,AI技术正经历从实验室到产线的关键跃迁。当算法工程师们刚为MVTec AD数据集上98%的准确率欢呼时,产线上传来的警报却揭示了残酷现实&a…...

如何用开源甘特图软件GanttProject高效管理复杂项目:终极免费指南
如何用开源甘特图软件GanttProject高效管理复杂项目:终极免费指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 还在为昂贵的项目管理软件发愁吗?想找一款功能强…...

三步搞定B站视频下载:这个Python工具让你永久保存任何想看的视频
三步搞定B站视频下载:这个Python工具让你永久保存任何想看的视频 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 你是否曾…...

微信聊天记录永久保存指南:WeChatMsg让珍贵对话永不消失
微信聊天记录永久保存指南:WeChatMsg让珍贵对话永不消失 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeC…...
)
Spring Boot启动慢?5个优化技巧让你的应用秒启动(附实战代码)
Spring Boot启动慢?5个优化技巧让你的应用秒启动(附实战代码) 每次等待Spring Boot应用启动时,看着控制台不断刷新的日志,你是否也感到焦虑?特别是在微服务架构下,频繁的重启和部署让启动时间成…...

月活3.45亿的豆包开启C端收费冒险,AI商业化能否破局?
豆包开启C端收费冒险,AI商业化加速?2026年5月4日,用户在App Store更新豆包时,字节上线“付费服务声明”,标准版68元/月、加强版200元/月、专业版500元/月,基础免费服务不变。“豆包收费”话题冲上热搜&…...

支付差异单怎么设计才方便追查?少单、差额、状态不一致分类一次讲透
支付差异单怎么设计才方便追查?少单、差额、状态不一致分类一次讲透 这篇直接按支付差异单来拆,不只讲“有差异就报警”,而是把差异分类、责任归因、处理状态和审计讲具体。 目标是你看完后,能把差异单从一条异常记录,…...
,限时开放前100份)
【仅限早期项目】AISMM定制化沟通协议(含投资人偏好映射矩阵+话术热键库),限时开放前100份
更多请点击: https://intelliparadigm.com 第一章:AISMM模型与投资人沟通 AISMM(Artificial Intelligence Strategy Maturity Model)是一种面向AI项目投资决策的结构化评估框架,专为技术团队与非技术背景投资人之间的…...

WarcraftHelper实用指南:优化魔兽争霸3在现代系统上的游戏体验
WarcraftHelper实用指南:优化魔兽争霸3在现代系统上的游戏体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为一款经典即时…...

Adobe创意插件一键安装神器:告别繁琐安装流程的跨平台解决方案
Adobe创意插件一键安装神器:告别繁琐安装流程的跨平台解决方案 【免费下载链接】ZXPInstaller Open Source ZXP Installer for Adobe Extensions 项目地址: https://gitcode.com/gh_mirrors/zx/ZXPInstaller 还在为Adobe扩展安装而烦恼吗?每次下载…...