NLP:使用 SciKit Learn 的文本矢量化方法

一、说明
本文是使用所有 SciKit Learns 预处理方法生成文本数字表示的深入解释和教程。对于以下每个矢量化器,将给出一个简短的定义和实际示例:one-hot、count、dict、TfIdf 和哈希矢量化器。
SciKit Learn 是一个用于机器学习项目的广泛库,包括多种分类器和分类算法、训练和指标收集方法以及预处理输入数据的方法。在每个 NLP 项目中,文本都需要矢量化才能被机器学习算法处理。矢量化方法包括独热编码、计数器编码、频率编码和词向量或词嵌入。其中一些方法在 SciKit Learn 中也可用。
本文的技术相关资源是 Python v3.11和 scikit-learn v1.2.2。所有示例也应该适用于较新的版本。这篇文章最初出现在塞巴的博客 admantium.com。
二、要求和使用的 Python 库
本文是有关使用 Python 进行 NLP 的博客系列的一部分。在我之前的文章中,我介绍了如何创建一个维基百科文章爬虫,它将以文章名称作为输入,然后系统地下载所有链接的文章,直到达到给定的文章总数或深度。爬虫生成文本文件,然后由 WikipediaCorpus 对象进一步处理,WikipediaCorpus 对象是在 NLTK 之上自行创建的抽象,可以方便地访问单个语料库文件和语料库统计信息,例如句子、段落和词汇的数量。在本文中,WikipediaCorpus 对象仅用于加载特定文章,这些文章作为应用 Sci-Kit 学习预处理方法的示例。
三、基本示例
以下代码片段展示了如何使用 WikipediaCorpus 对象从机器学习和人工智能开始抓取 200 个页面。
reader = WikipediaReader(dir = "articles3")
reader.crawl("Artificial Intelligence", total_number = 200)
reader.crawl("Machine Learning")
reader.process()在此基础上,创建语料库对象:
corpus = WikipediaPlaintextCorpus('articles3')
corpus.describe()
#{'files': 189, 'paras': 15039, 'sents': 36497, 'words': 725081, 'vocab': 32633, 'max_words': 16053, 'time': 4.919918775558472}最后,创建一个 SciKit Learn 管道,该管道将对文本进行预处理(忽略所有非文本字符和停用词)并进行标记化。
pipeline = Pipeline([('corpus', WikipediaCorpusTransformer(root_path='./articles3')),('preprocess', TextPreprocessor(root_path='./articles3')),('tokenizer', TextTokenizer()),
])这将生成以下数据框,以下各节将在其上应用进一步的处理步骤:
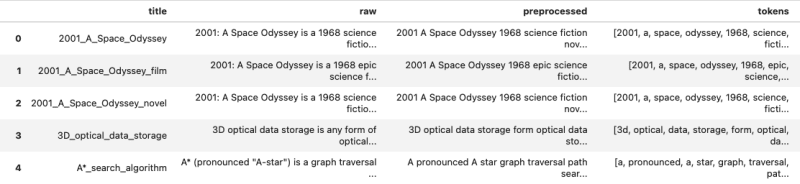
四、One-Hot 矢量化器
独热编码是一种稀疏矩阵,其中行表示文档,列表示词汇表中的单词。每个单元格的值为 0 或 1,以指示文档中是否出现单词。
从 SciKit 了解到OneHotEncoder,它是处理 Pandas 数据框对象中包含的数据最难获得的方法之一,因为它被设计为处理表示为元组的序号数据。因此,需要首先将包含预处理令牌的 Pandas 系列对象转换为矩阵,并提出将列数填充和修剪到合理值的特殊挑战。帮助程序方法如下:
def to_matrix(series, padding_value):matrix = []for vec in np.nditer(series.values,flags=("refs_ok",)):v = vec.tolist()pad = ['' for i in range(0, padding_value)]matrix.append([*v, *pad][:padding_value])return matrix下面是应用于人工智能文章时生成的数据结构(包括填充)的示例:
x_t = to_matrix(X['tokens'], 10000)
#['a.i', '.', 'artificial', 'intelligence', 'simply', 'a.i', '.', '2001', 'american', 'science', #'fiction', 'film', 'directed', 'steven', 'spielberg', '.', 'the', 'screenplay', 'spielberg', #'screen', 'story', 'ian', 'watson', 'based', '1969', 'short', 'story', 'supertoys', 'last',
# ... '', ''以下示例演示如何将 one-hot-encode 应用于填充的令牌列表:
from sklearn.preprocessing import OneHotEncodervectorizer = OneHotEncoder(handle_unknown='ignore')
x_train = vectorizer.fit_transform(np.array(x_t).reshape(-1, 1))print(type(x_train))
#scipy.sparse._csr.csr_matrixprint(x_train)
# (0, 7) 1.0
# (1, 8) 1.0
# (2, 87) 1.0
# (3, 64) 1.0
# (4, 5) 1.0
# (5, 80) 1.0
# (6, 42) 1.0print(vectorizer.get_feature_names_out())
# ['x0_,' 'x0_.' 'x0_...' 'x0_1948' 'x0_1953' 'x0_1968' 'x0_1972' 'x0_2001'
# 'x0_a' 'x0_additionally' 'x0_after' 'x0_amazing' 'x0_arthur' 'x0_artwork'
# 'x0_background' 'x0_based' 'x0_bbc' 'x0_before' 'x0_both' 'x0_breaking'
# 'x0_c.' 'x0_carnon' 'x0_clarke' 'x0_collaboration' 'x0_comet' 'x0_comics'print(len(vectorizer.get_feature_names_out()))
# 34853编码器生成34853特征,并具有用于解码目的的特征名称。
五、计数矢量化器
计数向量化器是一种可定制的 SciKit Learn 预处理器方法。它适用于开箱即用的任何文本,并自行应用预处理、标记化和停用词删除。这些任务可以定制,例如通过提供不同的标记化方法或停用词列表。 (这也适用于所有其他预处理器。)将计数向量化器应用于原始文本会创建一个 (document_id, tokens) 形式的矩阵,其中值是标记计数。
这种矢量化方法无需任何配置,也无需直接对预处理的文本进行任何额外的转换:
from sklearn.feature_extraction.text import CountVectorizervectorizer = CountVectorizer()
x_train = vectorizer.fit_transform(X['preprocessed'])其应用如以下代码片段所示:
print(type(x_train))
#scipy.sparse._csr.csr_matrixprint(x_train.toarray())
# [[0 0 0 ... 0 0 0]
# [0 7 0 ... 0 0 0]
# [0 3 0 ... 0 0 0]
# ...
# [0 0 0 ... 0 0 0]
# [0 1 0 ... 0 0 0]
# [0 2 0 ... 0 0 0]]print(vectorizer.get_feature_names_out())
# array(['00', '000', '0001', ..., 'zy', 'zygomaticus', 'zygote'],
# dtype=object)print(len(vectorizer.get_feature_names_out()))
# 32417此矢量化器可检测32417特征,并且还具有可解码的特征名称。
六、Dict 矢量化器
顾名思义,它将包含文本的字典对象转换为向量。因此,它不能在原始文本中工作,而是需要文本的频率编码表示,例如词袋表示。
以下帮助程序方法提供标记化文本中的词袋表示形式。
from collections import Counterdef bag_of_words(tokens):return Counter(tokens)X['bow'] = X['tokens'].apply(lambda tokens: bag_of_words(tokens))生成的 DataFrame 如下所示:

机器学习文章的标题是这样的:
X['bow'][184]
# Counter({',': 418,# '.': 314,# 'learning': 224,# 'machine': 124,# 'data': 102,# 'training': 49,# 'algorithms': 46,# 'model': 38,# 'used': 35,# 'set': 31,# 'in': 30,# 'artificial': 29,以下代码演示如何将矢量化器应用于额外创建的词袋表示形式。
from sklearn.feature_extraction import DictVectorizervectorizer = DictVectorizer(sparse=False)
x_train = vectorizer.fit_transform(X['bow'])print(type(x_train))
#numpy.ndarrayprint(x_train)
#[[ 15. 0. 10. ... 0. 0. 0.]
# [662. 0. 430. ... 0. 0. 0.]
# [316. 0. 143. ... 0. 0. 0.]
# ...
# [319. 0. 217. ... 0. 0. 0.]
# [158. 0. 147. ... 0. 0. 0.]
# [328. 0. 279. ... 0. 0. 0.]]print(vectorizer.get_feature_names_out())
# array([',', ',1', '.', ..., 'zy', 'zygomaticus', 'zygote'], dtype=object)print(len(vectorizer.get_feature_names_out()))
# 34872此矢量化器可检测# 34872特征,并且还具有可解码的特征名称。
七、TfIdf 矢量化器
术语频率/反向文档频率是信息检索中众所周知的指标。它以这样一种方式对词频进行编码,以便对许多文档中出现的常见术语以及仅在少数文档中出现的不常见术语给予同等重视。该指标在大型语料库中具有很好的概括性,并改进了查找相关主题的能力。
SciKit Learn 实现可以直接用于已预处理的文本。但请记住,其内部步骤(如预处理和标记化)可以根据需要进行定制。
创建此矢量化器很简单:
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer()
x_train = vectorizer.fit_transform(X['preprocessed'])以下是将矢量化器应用于语料库的结果。
print(type(x_train))
# scipy.sparse._csr.csr_matrixprint(x_train.shape)
# (189, 32417)print(x_train)
# (0, 9744) 0.09089003669895346
# (0, 24450) 0.0170691375156829
# (0, 6994) 0.07291108016392849
# (0, 6879) 0.05022416293169798
# (0, 10405) 0.08425453878004373
# (0, 716) 0.048914251894790796
# (0, 32066) 0.06299157591377592
# (0, 17926) 0.042703846745948786print(vectorizer.get_feature_names_out())
# array(['00' '000' '0001' ... 'zy' 'zygomaticus' 'zygote'], dtype=object)print(len(vectorizer.get_feature_names_out()))
# 32417此矢量化器可检测特征,并且还具有可解码的特征名称。32417
八、散列矢量化器
最终的预处理器同时是最通用且性能最高的。它创建一个包含 document_id x 标记的结构化矩阵,但这些值可以标准化为 L1(其值的总和)或 L2(所有平方向量值之和的平方根)。它还有其他好处,例如需要较低的内存并适合处理流式文档。
HashingVector 在预处理的文本上按原样工作。
from sklearn.feature_extraction.text import HashingVectorizervectorizer = HashingVectorizer(norm='l1')
x_train = vectorizer.fit_transform(X['preprocessed'])它产生以下结果:
print(type(x_train))
#scipy.sparse._csr.csr_matrixprint(x_train.shape)
#(189, 1048576)print(x_train)
# (0, 11631) -0.006666666666666667
# (0, 17471) -0.006666666666666667
# (0, 26634) 0.006666666666666667
# (0, 32006) -0.006666666666666667
# (0, 42855) 0.006666666666666667
# (0, 118432) 0.02666666666666667
# (0, 118637) -0.006666666666666667print(vectorizer.get_params())
#{'alternate_sign': True, 'analyzer': 'word', 'binary': False, 'decode_error': 'strict', 'dtype': <class 'numpy.float64'>, 'encoding': 'utf-8', 'input': 'content', 'lowercase': True, 'n_features': 1048576, 'ngram_range': (1, 1), 'norm': 'l1', 'preprocessor': None, 'stop_words': None, 'strip_accents': None, 'token_pattern': '(?u)\\b\\w\\w+\\b', 'tokenizer': None} 此矢量化器检测文档中的特征。唉,它的功能名称无法解码。1048576
九、结论
本文是 SciKit 学习内置文本矢量化方法的深入教程。对于以下每个矢量化器,您都看到了一个实际示例以及如何将它们应用于文本:one-hot、count、字典、TfIdf、哈希。所有矢量化器都使用默认的文本处理实用程序开箱即用,但您可以自定义预处理器、分词器和顶部单词。此外,它们可以处理原始文本本身,但字典除外,它需要文本的词袋表示,以及 one-hot 编码器,它需要手动将 Pandas 系列转换为带有标记填充的 Numpy 矩阵。
参考资料:
塞巴斯蒂安
NLP: Text Vectorization Methods with SciKit Learn | Admantium
相关文章:
NLP:使用 SciKit Learn 的文本矢量化方法
一、说明 本文是使用所有 SciKit Learns 预处理方法生成文本数字表示的深入解释和教程。对于以下每个矢量化器,将给出一个简短的定义和实际示例:one-hot、count、dict、TfIdf 和哈希矢量化器。 SciKit Learn 是一个用于机器学习项目的广泛库,…...
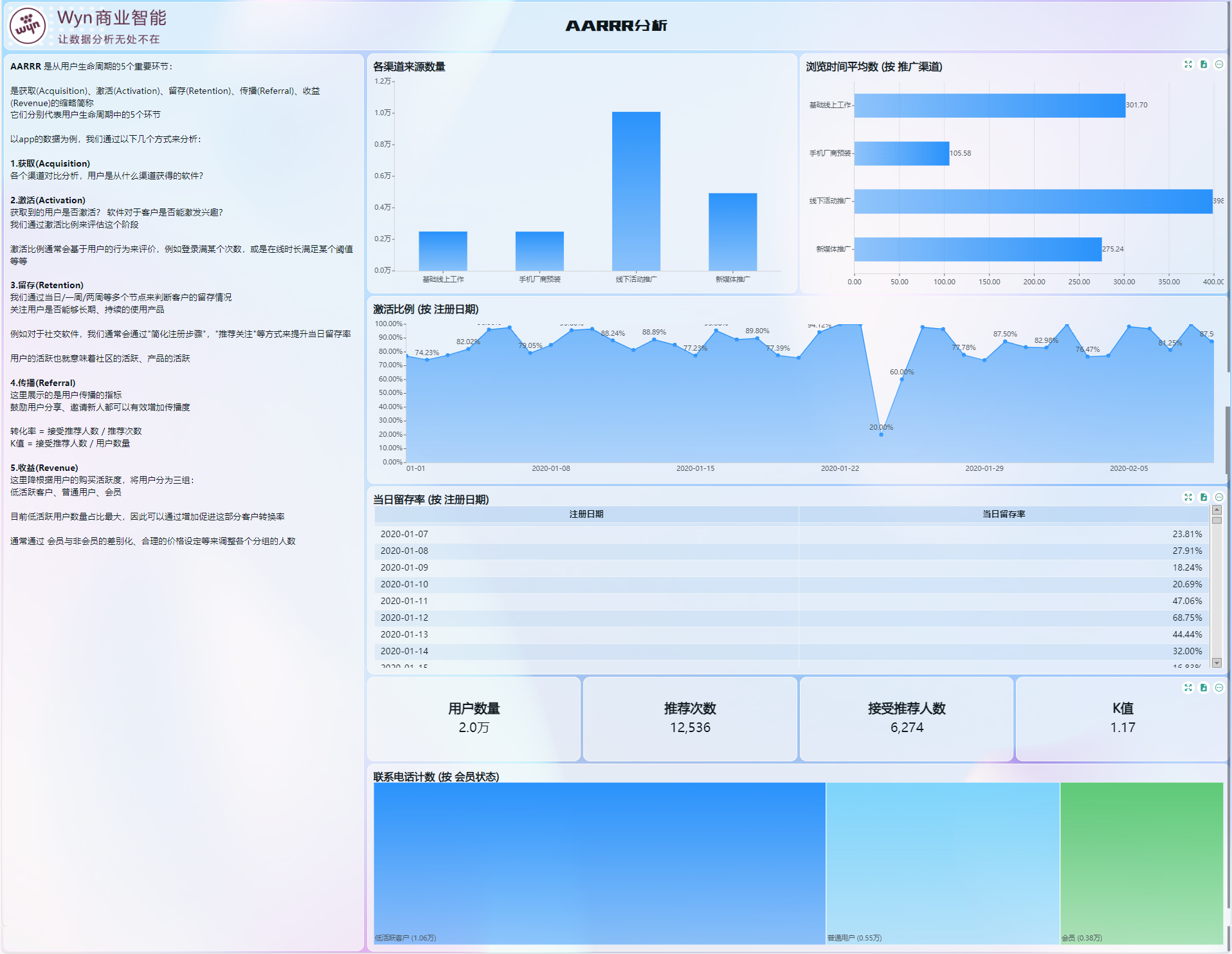
这些仪表板常用的数据分析模型,你都见过吗?
本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 ##前言 在数字化时代,数据已经成为了企业决策和管理的重要依据。而仪表板作为一种数据可视化工具&#x…...

【Proteus仿真】【Arduino单片机】多功能数字时钟设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真Arduino单片机控制器,使用PCF8574、LCD1602液晶、DS1302温度传感器、DS1302时钟、按键、蜂鸣器等。 主要功能: 系统运行后,LCD1602显示当前日期…...

c语言回文数
以下是用C语言编写的回文数代码: #include <stdio.h>int main() { int num, reversedNum 0, remainder, originalNum; printf("请输入一个正整数:"); scanf("%d", &num); originalNum num; while (num …...

【学习记录】从0开始的Linux学习之旅——编译linux内核
一、学习背景 从接触嵌入式至今,除了安装过双系统接触了一丢丢linux外,linux在我眼中向来是个传说。而如今得到了一块树莓派,于是决心把linux搞起来。 二、概念学习 Linux操作系统通常是基于Linux内核,并结合GNU项目中的工具和应…...

uni-app - 日期 · 时间选择器
目录 1.基本介绍 2.案例介绍 ①注意事项: ②效果展示 3.代码展示 ①view部分 ②js部分 ③css样式 1.基本介绍 从底部弹起的滚动选择器。支持五种选择器,通过mode来区分,分别是普通选择器,多列选择器,时间选择器&a…...
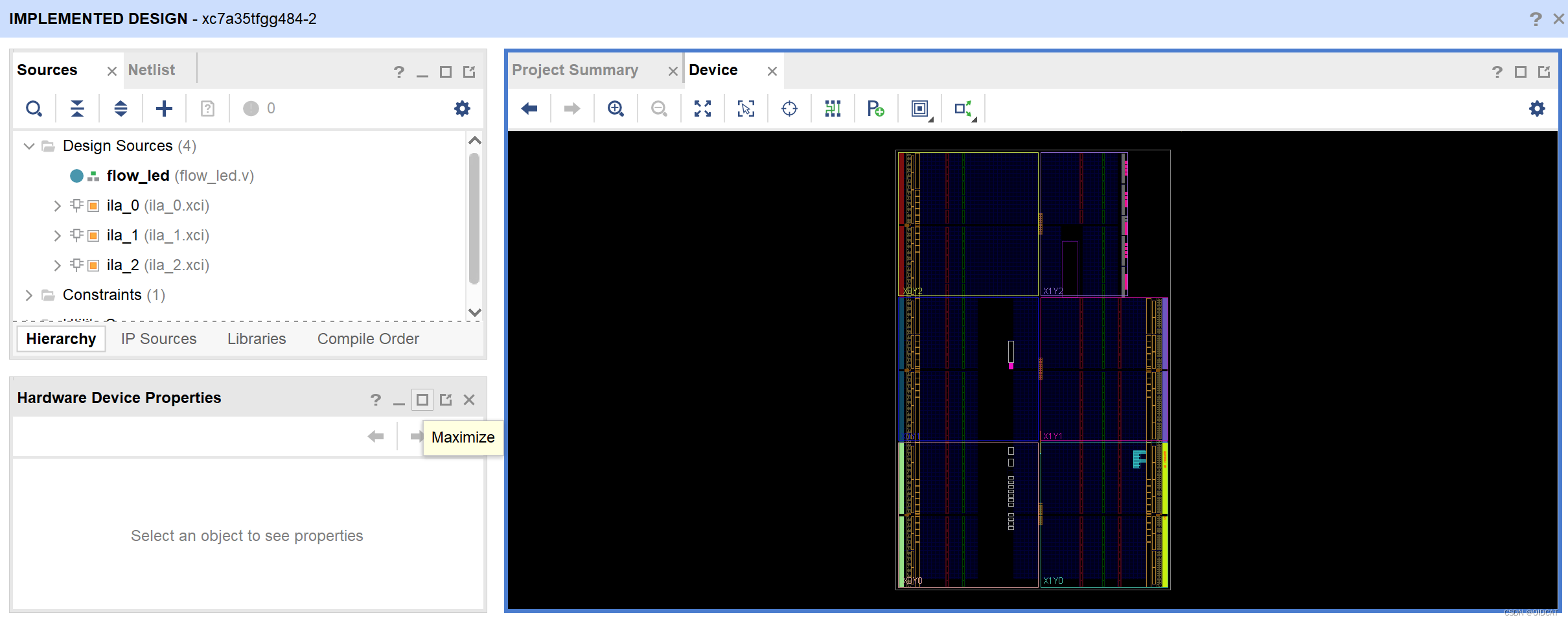
使用USB转JTAG芯片CH347在Vivado下调试
简介 高速USB转接芯片CH347是一款集成480Mbps高速USB接口、JTAG接口、SPI接口、I2C接口、异步UART串口、GPIO接口等多种硬件接口的转换芯片。 通过XVC协议,将CH347应用于Vivado下,简单尝试可以成功,源码如下,希望可以一起共建&a…...
)
硬技能之上的软技巧(三)
在硬技能的基础上,如何运用软技巧来进一步提升个人能力和职业发展。在之前的讨论中,我们提到了硬技能和软技巧的基本概念,以及如何运用软技巧来提升个人能力和职业发展。本篇文章将进一步探讨软技巧中的一些重要方面,包括自我管理…...
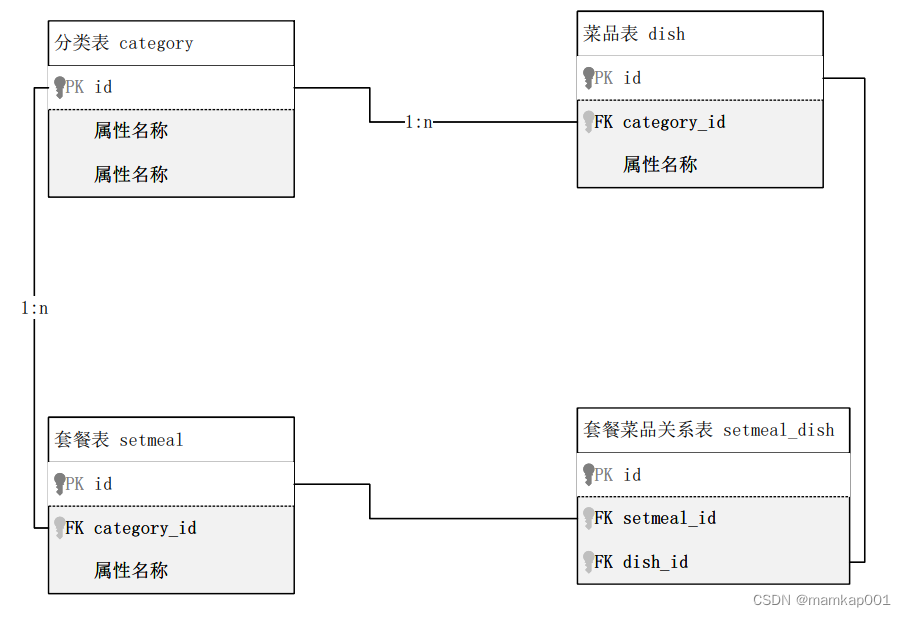
mysql 查询
-- 多表查询select * from tb_dept,tb_emp; 内来链接 -- 内连接 -- A 查询员工的姓名 , 及所属的部门名称 (隐式内连接实现)select tb_emp.name,tb_dept.name from tb_emp,tb_dept where tb_emp.idtb_emp.id;-- 推荐使用select a.name,b.n…...

2311rust过程宏的示例
原文 Rust2018中的过程宏 在Rust2018版本中,我最喜欢的功能是过程宏.在Rust中,过程宏有着悠久而传奇的历史(并继续拥有传奇的未来!) 因为2018年版极大改善了定义和使用它们的体验. 什么是过程宏 过程宏是,在编译时用一段语法,生成新语法的函数.Rust2018中的过程宏有三个风格…...

数据分析:数据预处理流程及方法
数据预处理是数据分析过程中至关重要的一步,它涉及到清洗、转换和整理原始数据,以便更好地适应分析模型或算法。以下是一些常见的数据预处理方法和规则: 数据清洗: 处理缺失值:检测并处理数据中的缺失值,可…...

uniapp 防抖节流封装和使用
防抖(debounce):定义一个时间,延迟n秒执行,n秒内再次调用,会重新计时,计时结束后才会再次执行 主要运用场景: 输入框实时搜索:在用户输入内容的过程中,使用防抖可以减少频繁的查询…...

springcloud alibaba学习视频
阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台...

【MySQL】一些内置函数(时间函数、字符串函数、数学函数等,学会了有妙用)
内置函数 前言正式开始时间函数显示当前日期、时间、日期时间的日期计算相差多少天示例创建一张表,记录生日 留言表 字符串函数charsetconcatinstr(string, substring)ucase和lcaseleft(string, length)length求字符串长度replace(str, search_str, replace_str)tri…...

QtC++与QColumnView详解
介绍 在 Qt 中,QColumnView 是用于显示多列数据的控件,它提供了一种多列列表视图的方式,类似于文件资源管理器中的详细视图。QColumnView 是基于模型/视图架构的,通常与 QFileSystemModel 或自定义模型一起使用。 以下是关于 QC…...
微信小程序配置企业微信的在线客服
配置企业微信后台 代码实现 <button tap"openCustomerServiceChat">打开企业微信客服</button>methods: {openCustomerServiceChat(){wx.openCustomerServiceChat({extInfo: {url: 你刚才的客服地址},corpId: 企业微信的id,showMessageCard: true,});} …...

深入理解Java AQS:从原理到源码分析
目录 AQS的设计原理1、队列节点 Node 和 FIFO队列结构2、state 的作用3、公平锁与非公平锁 AQS 源码解析1、Node节点2、acquire(int)3、release(int)4、自旋(Spin)5、公平性与 FIFO 基于AQS实现的几种同步器1、ReentrantLock:可重入独占锁2、…...
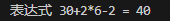
【数据结构(四)】栈(1)
文章目录 1. 关于栈的一个实际应用2. 栈的介绍3. 栈的应用场景4. 栈的简单应用4.1. 思路分析4.2. 代码实现 5. 栈的进阶应用(实现综合计算器)5.1. 栈实现一位数计算(中缀表达式)5.1.1. 思路分析5.1.2. 代码实现 5.2. 栈实现多位数计算(中缀表达式)5.2.1. 解决思路5.2.2. 代码实…...
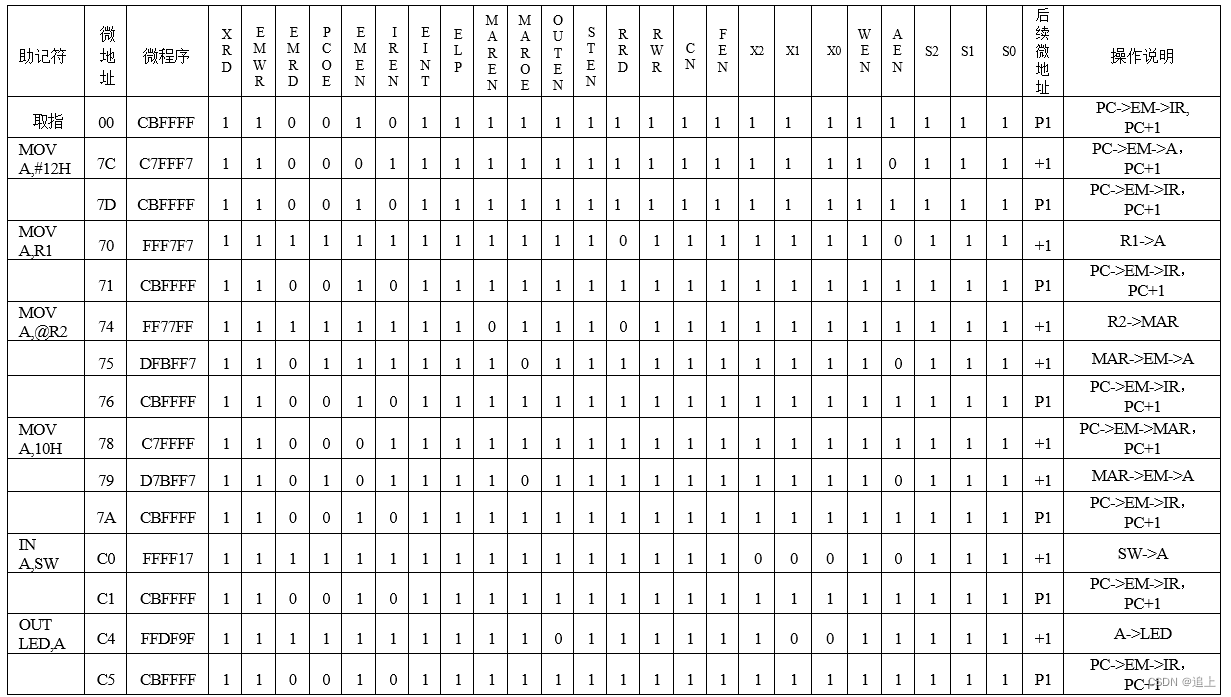
实验(四):指令部件实验
一、实验内容与目的 实验要求: 利用CP226实验仪上的小键盘将程序输入主存储器EM,通过指令的执行实现微程序控制器的程序控制。 实验目的: 1.掌握模型机的操作码测试过程; 2.掌握模型机微程序控制器的基本结构以及程序控制的基本原…...

【Android11】在内置的Tvsettings的界面中显示以太网Mac地址
【Android11】在内置的Tvsettings的界面中显示以太网Mac地址 了解Preference必要信息步骤:1. 在设置页面的xml文件中增加一个Preference ,这是要显示出来的设置项2. 在strings.xml文件中增加我们在第一步新设置的值3. 为新加的设置项增加一个新的XXXPref…...
)
YOLO+Pytorch基于深度学习的水果蔬菜检测系统(源码)
目录 一、项目背景 二、技术介绍 三、功能介绍 四、代码设计 五、系统实现 一、项目背景 我国是全球最大的水果蔬菜生产国和消费国,果蔬产业在国民经济中占据重要地位。然而,果蔬产后处理环节长期依赖人工分拣与品质检测,存在效率低、主…...

Godot官方文档深度解析:从高效使用到开源贡献
1. 项目概述:一份开源游戏引擎的“活”文档如果你正在使用或考虑使用Godot引擎,那么你一定绕不开godotengine/godot-docs这个仓库。这不仅仅是Godot的官方文档,它更像是一个与引擎核心同步呼吸、由全球开发者共同维护的“知识中枢”。作为一个…...

XXL-Job单机模式玩出花:模拟集群、灰度发布与本地调试的三种实战技巧
XXL-Job单机模式玩出花:模拟集群、灰度发布与本地调试的三种实战技巧 在分布式任务调度领域,XXL-Job以其轻量级、易用性和强大的功能成为众多开发者的首选。然而,当大家的目光都聚焦在集群部署和分布式执行时,单机模式的价值往往被…...

LaunchedEffect 的执行机制与实践
Jetpack Compose 技术说明:LaunchedEffect 的执行机制与实践 1. 核心概念 LaunchedEffect 是 Compose 中最常用的副作用(Side-Effect)API。它允许开发者在组件的生命周期内启动一个协程,用于处理非 UI 渲染相关的逻辑(…...

基于Xilinx Open-NIC-Shell的FPGA智能网卡开发实战指南
1. 项目概述:当FPGA遇见网卡,一场硬件加速的范式革命如果你是一名数据中心网络工程师、高性能计算(HPC)开发者,或者对低延迟、高吞吐网络处理有极致追求的硬件爱好者,那么“Xilinx/open-nic-shell”这个名字…...

wait-on 终极指南:如何轻松等待文件和网络资源就绪
wait-on 终极指南:如何轻松等待文件和网络资源就绪 【免费下载链接】wait-on wait-on is a cross-platform command line utility and Node.js API which will wait for files, ports, sockets, and http(s) resources to become available 项目地址: https://git…...

基于MCP协议的文档解析服务器:统一处理PDF与Office文档的AI应用利器
1. 项目概述:一个专为文档解析而生的MCP服务器 如果你正在构建一个需要深度理解各种文档格式(PDF、Word、Excel、PPT)的AI应用,并且厌倦了为每种格式寻找、集成和维护不同的解析库,那么 rendoc-mcp-server 这个项目很…...

3步实现AI视频智能分析:从视频到结构化报告的全新工作流
3步实现AI视频智能分析:从视频到结构化报告的全新工作流 【免费下载链接】video-analyzer Analyze videos using LLMs, Computer Vision and Automatic Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/vi/video-analyzer 你是否曾面对海量视频…...
Translumo:打破语言障碍的终极实时屏幕翻译工具完整指南
Translumo:打破语言障碍的终极实时屏幕翻译工具完整指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否…...

Vibe Coding 与 Agentic Engineering 的边界正在模糊:AI 驱动的开发新常态
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...