Hadoop性能调优建议
一、服务器配置
1. BIOS配置: 关闭smmu/关闭cpu预取/performance策略
2. 硬盘优化 raid0 打卡cache /jbod scheduler/sector_size/read_ahead_kb
3. 网卡优化 rx_buff/ring_buffer/lro/中断绑核/驱动升级
4. 内存插法:要用均衡插法,内存配对插。
5. 占用通道:先把每个通道都插满,再去插对应通道。(内存通道分布请查看机箱背板示意图)
6. Rank数:内存条硬件参数,1R和2R的区别,得用2R的
7. 频率:内存条主频,要选择主频高的。
8. Scheduler策略:ssd硬盘得用noop策略;机械硬盘建议deadline策略
9. 驱动升级:用最新版本的网卡驱动程序
二、操作系统调优
1、关闭selinux:
为了减少selinux的性能损耗,关闭selinux。vim /etc/sysconfig/selinux命令,打开selinux文件。将"SELINUX=enforcing" 改为 "SELINUX=disabled"。保存文件,重启服务器。
2、配置扩展文件描述符:
需要配置最大打开文件数为102400,否则在测试过程中可能会导致软件最大打开文件数被限制在1024,影响服务器性能。在“/etc/security/limits.conf”文件中写入以下配置。保存文件并重启。
*表示所有用户;hard表示严格的设定,必定不能超过这个设定的数值;soft表示警告的设定,可以超过这个设定值,但是若超过则有警告信息。
3、关闭不用的系统服务
Cpus等
4、配置网卡中断:(绑定的核专门用于处理网卡中断)
关闭irqbalance,重启服务器生效
systemctl stop irqbalance.service
systemctl disable irqbalance.service
步骤1:查询网卡中断默认在哪个numa上
cat /sys/class/net/$eth1 /device/numa_node
步骤2:查询中断号
cat /proc/interrupts | grep $eth1 | awk -F ':' '{print $1}'
步骤3:根据中断号,将每个中断各绑定在一个核上。
echo $cpunum > /proc/irq/$irq/smp_affinity_list
步骤4:查看是否绑定成功
cat /proc/irq/$irq/smp_affinity_list
5、关闭透明大页
查看配置:
cat /sys/kernel/mm/transparent_hugepage/enable
若显示不为nener则修改配置:
echo never > /sys/kernel/mm/transparent_hugepage/enable
三、Hadoop参数调优
1、Yarn组件在3.1.0版本合入的新特性支持,支持Yarn组件在启动Container时使能numa 感知功能,原理是读取系统物理节点上每个Numa节点的CPU核、内存容量,使用 Numactl命令指定启动container的CPU范围和mem bind范围,减少跨片访问.
Yarn-default.xml 里的
yarn.nodemanager.numa-awareness.enabled 默认值为false改成ture
yarn.nodemanager.numa-awareness.read-topology 默认值为false改成ture
2、单台服务器可启动容器数量设置:
Mapred-site.xml
根据内存计算:NUM_container(mem)=容器内存/container内存
Mapreduc.map.memory.mb
Mapreduce.reduce.memory.mb
3、根据CPU计算:
NUM_container(vcore)=容器vcore/container vcore
mapreduce.map.cpu.vcores
Mapreduce.reduce.cpu.vcores
默认的DefaultResourceCalculator只考虑内存资源,并不采用vcore相关设置。 采用DominantResourceCalculator可以精确控制设置vcore资
在Capacity-scheduler.xml
yarn.scheduler.capacity.resource-calculator 默认值为DefaultResourceCalculator 改为 DominantResourceCalculator
4、Yarn 资源设置:资源的多少会决定任务执行的性能,而不决定任务运行的成败
Yarn-default.xml
yarn.nodemanager.resource.memory-mb 默认值为-1 改为 容器内存,一般设置物理内存75%左右
yarn.scheduler.minimum-allocation-mb 默认值为1024MB 改为 最小容器内存;最大容器数量(单节点)=容器内存/最小容器内
mapred-default.xml
mapreduce.map.java.opts JVM最大内存,一般设置为container内存的0.75 ~ 0.8
mapreduce.reduce.java.opts JVM最大内存,一般设置为container内存的0.75 ~ 0.8
5、HDFS的Handler数量由dfs.namenode.handler.count、dfs.namenode.service.handler.count和dfs.datanode.handler.count控制。4节点规模不需要配置的太大。
dfs.namenode.handler.count Namenode 的RPC服务的用于监听处理来自客户端请求的线程数
Dfs.namenode.service.handler.count Namenode的RPC服务端用于监听来自datanode和所有非客户端节点请求的线程数
Dfs.datanode.handler.count Datanode同时可以处理来自客户端的请求线程数,当集群规模比较大或者同时跑的任务比较多,可以增加此值
6、减小副本数降低可靠性的方式提升写入的性能。减轻磁盘IO压力和网络压力。
增大客户端任务写入数据时数据包大小。dfs.client-write-packet-size设置过小,导致发送数据包的效率较低,写HDFS数据较慢,适当扩大该参数可以提升写HDFS时的效率(设置会65536的整数倍,推荐131072)
Dfs.replication 默认3副本,但可以修改客户端的副本数设置
Dfs.client-write-packet-size 客户端任务写入数据时数据包大小
6、Map buffer大小:
mapreduce.task.io.sort.mb 一般设置为容器内存的25%,加大可以减少map中间结果spill到硬盘次数。
mapreduce.map.sort.spill.percent 默认0.8 , io sort buffer 达到80%时开始spill到硬盘。
mapreduce.reduce.shuffle.parallelcopies 默认 5或者10 , 可加大
7、reduce merge 内存中merge
每个reduce task把map 结果copy过去时都要对从各个map 端来的数据做merge(合并)动作, reduce端的内存没有那么大的时候, 只能把拉过来的数据先保存到本地磁盘中然后才做merge, 如果reduce端
的内存可以设置的很大, 完全就可以做memtomem的merge动作,
mapreduce.reduce.merge.memtomem.enabled=true当map输出文件达到mapreduce.reduce.merge.memtomem.threshold时,触发合并
8、Heartbeat
yarn.nodemanager.heartbeat.interval-ms 1000 (ms) 设置成100
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
9、读写文件的buffer设置
io.file.buffer.size
这个属性只要是读写文件就都得使用. 默认4K (4K~64K,太大了可能会变差)
相关文章:

Hadoop性能调优建议
一、服务器配置 1. BIOS配置: 关闭smmu/关闭cpu预取/performance策略 2. 硬盘优化 raid0 打卡cache /jbod scheduler/sector_size/read_ahead_kb 3. 网卡优化 rx_buff/ring_buffer/lro/中断绑核/驱动升级 4. 内存插法:要用均衡插法…...
算法的奥秘:常见的六种算法(算法导论笔记2)
算法的奥秘:种类、特性及应用详解(算法导论笔记1) 上期总结算法的种类和大致介绍,这一期主要讲常见的六种算法详解以及演示。 排序算法: 排序算法是一类用于对一组数据元素进行排序的算法。根据不同的排序方式和时间复…...

Python算法——树的路径和算法
Python算法——树的路径和算法 树的路径和算法是一种在树结构中寻找从根节点到叶节点的所有路径,其路径上的节点值之和等于给定目标值的算法。这种算法可以用Python语言实现,本文将介绍如何使用Python编写树的路径和算法,并给出一些示例代码…...

数据结构之链表练习与习题详细解析
个人主页:点我进入主页 专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶 C语言刷题 数据结构初阶 欢迎大家点赞,评论,收藏。 一起努力,一起奔赴大厂。 目录 1.前言 2.习题解…...

QT中使用unity
qt把unity发入widget中 头文件showunitywindowsinqt #ifndef SHOWUNITYWINDOWSINQT_H #define SHOWUNITYWINDOWSINQT_H #include <QObject> #include <QProcess> #include <windows.h> #include <winuser.h> #include <QDebug> class ShowUnity…...

QTableView/QTableWidget设置单元格字体颜色及背景色
1.QTableView设置单元格字体颜色及背景色 QStandardItem * pItem new QStandardItem("AAA"); pItem->setBackground(QBrush(Qt::blue)); // 设置背景色 pItem->setForeground(QBrush(Qt::red)); // 设置字体颜色 2.QTableWidget设置单元格字…...
电脑上可以写便签的软件哪些界面比较可爱且好用?
电脑上可以安装使用的便签类软件比较多,在选择使用电脑便签软件时,很多人对便签的外观界面还是比较在意的,一个好看的便签界面在一方面可以引起大家的注意,另一方面可以增加电脑桌面背景和便签类软件的协调性。 电脑便签软件通常…...

2021秋招-总目录
2021秋招-目录 知识点总结 预训练语言模型: Bert家族 1.1 BERT、attention、transformer理解部分 B站讲解–强烈推荐可视化推倒结合代码理解代码部分常见面试考点以及问题: word2vec 、 fasttext 、elmo;BN 、LN、CN、WNNLP中的loss与评价总结 4.1 loss_function࿱…...
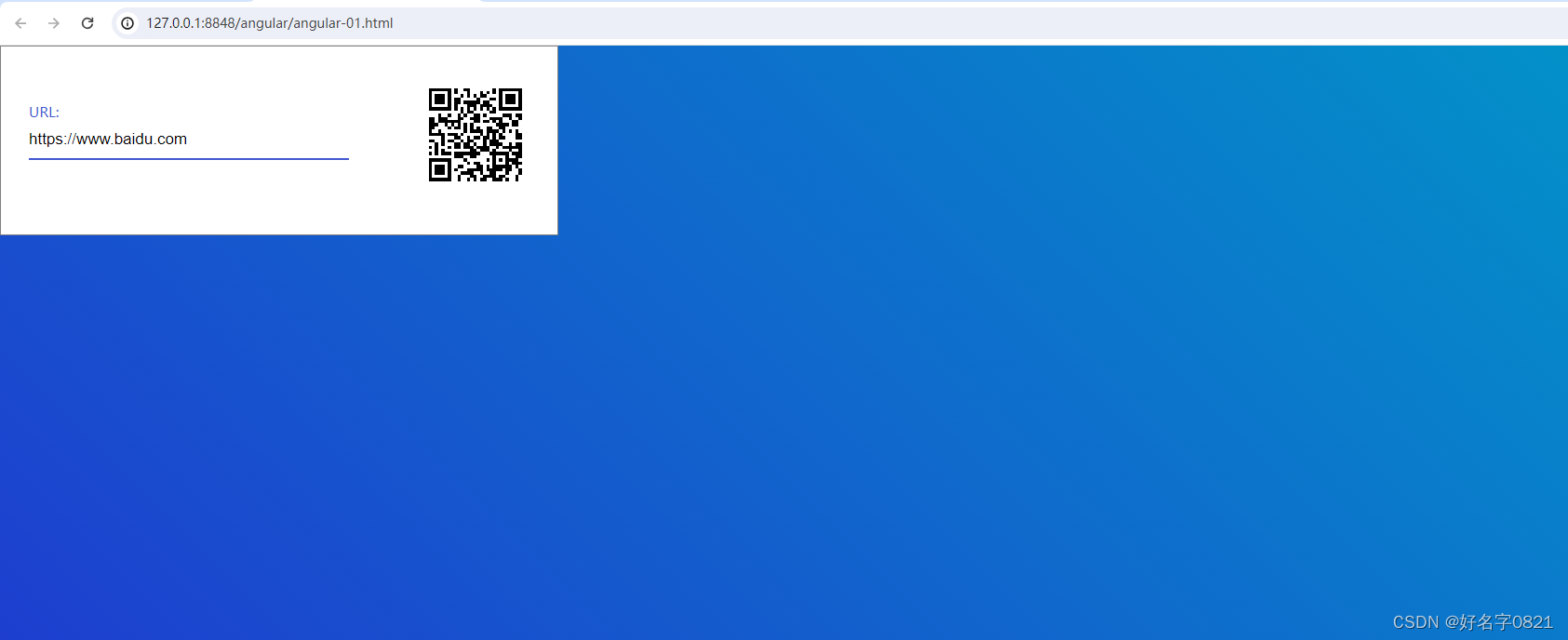
HTML5生成二维码
H5生成二维码 前言二维码实现过程页面实现关键点全部源码 前言 本文主要讲解如何通过原生HTML、CSS、Js中的qrcodejs二维码生成库,实现一个输入URL按下回车后输出URL。文章底部有全部源码,需要可以自取。 实现效果图: 上述实现效果为&#…...
)
大数据-之LibrA数据库系统告警处理(ALM-25005 Nscd服务异常)
告警解释 系统每60秒周期性检测nscd服务的状态,如果连续4次(3分钟)查询不到nscd进程或者无法获取ldapserver中的用户时,产生该告警。 当进程恢复且可以获取ldapserver中的用户时,告警恢复。 告警属性 告警ID 告警级…...

NLP:使用 SciKit Learn 的文本矢量化方法
一、说明 本文是使用所有 SciKit Learns 预处理方法生成文本数字表示的深入解释和教程。对于以下每个矢量化器,将给出一个简短的定义和实际示例:one-hot、count、dict、TfIdf 和哈希矢量化器。 SciKit Learn 是一个用于机器学习项目的广泛库,…...
这些仪表板常用的数据分析模型,你都见过吗?
本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 ##前言 在数字化时代,数据已经成为了企业决策和管理的重要依据。而仪表板作为一种数据可视化工具&#x…...

【Proteus仿真】【Arduino单片机】多功能数字时钟设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真Arduino单片机控制器,使用PCF8574、LCD1602液晶、DS1302温度传感器、DS1302时钟、按键、蜂鸣器等。 主要功能: 系统运行后,LCD1602显示当前日期…...

c语言回文数
以下是用C语言编写的回文数代码: #include <stdio.h>int main() { int num, reversedNum 0, remainder, originalNum; printf("请输入一个正整数:"); scanf("%d", &num); originalNum num; while (num …...

【学习记录】从0开始的Linux学习之旅——编译linux内核
一、学习背景 从接触嵌入式至今,除了安装过双系统接触了一丢丢linux外,linux在我眼中向来是个传说。而如今得到了一块树莓派,于是决心把linux搞起来。 二、概念学习 Linux操作系统通常是基于Linux内核,并结合GNU项目中的工具和应…...

uni-app - 日期 · 时间选择器
目录 1.基本介绍 2.案例介绍 ①注意事项: ②效果展示 3.代码展示 ①view部分 ②js部分 ③css样式 1.基本介绍 从底部弹起的滚动选择器。支持五种选择器,通过mode来区分,分别是普通选择器,多列选择器,时间选择器&a…...
使用USB转JTAG芯片CH347在Vivado下调试
简介 高速USB转接芯片CH347是一款集成480Mbps高速USB接口、JTAG接口、SPI接口、I2C接口、异步UART串口、GPIO接口等多种硬件接口的转换芯片。 通过XVC协议,将CH347应用于Vivado下,简单尝试可以成功,源码如下,希望可以一起共建&a…...
)
硬技能之上的软技巧(三)
在硬技能的基础上,如何运用软技巧来进一步提升个人能力和职业发展。在之前的讨论中,我们提到了硬技能和软技巧的基本概念,以及如何运用软技巧来提升个人能力和职业发展。本篇文章将进一步探讨软技巧中的一些重要方面,包括自我管理…...
mysql 查询
-- 多表查询select * from tb_dept,tb_emp; 内来链接 -- 内连接 -- A 查询员工的姓名 , 及所属的部门名称 (隐式内连接实现)select tb_emp.name,tb_dept.name from tb_emp,tb_dept where tb_emp.idtb_emp.id;-- 推荐使用select a.name,b.n…...

2311rust过程宏的示例
原文 Rust2018中的过程宏 在Rust2018版本中,我最喜欢的功能是过程宏.在Rust中,过程宏有着悠久而传奇的历史(并继续拥有传奇的未来!) 因为2018年版极大改善了定义和使用它们的体验. 什么是过程宏 过程宏是,在编译时用一段语法,生成新语法的函数.Rust2018中的过程宏有三个风格…...

DeepTutor:基于智能体原生的个性化AI学习伴侣架构与实践
1. 项目概述:一个面向未来的智能学习伴侣如果你正在寻找一个能真正理解你学习节奏、能陪你从入门到精通的“AI导师”,而不仅仅是另一个聊天机器人,那么DeepTutor的出现,可能正是你期待已久的答案。这不是一个简单的问答工具&#…...

Taotoken 的容灾与路由机制保障了业务连续性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的容灾与路由机制保障了业务连续性 在依赖外部大模型服务的业务开发中,服务稳定性是核心关切之一。上游服务偶…...

OpenClaw技能实战:构建自动化YouTube视频摘要工作流
1. 项目概述与核心价值如果你和我一样,每天被淹没在YouTube海量的视频信息里,想快速抓住几个关注频道的最新干货,却苦于没时间一个个点开看,那这个项目可能就是你的“数字信息管家”。OpenClaw Skill - YouTube Transcript Summa…...

从零构建主权AI智能体:OpenZero本地部署与核心架构解析
1. 项目概述:从零构建一个主权AI智能体如果你厌倦了那些将你的数据上传到云端、对话内容被审查、功能处处受限的“阉割版”AI助手,那么是时候了解一下“主权AI”这个概念了。今天要深入探讨的,是一个名为OpenZero的开源项目,它代表…...

Home Assistant本地LLM集成指南:隐私与响应速度的双重提升
1. 项目概述:让智能家居的“大脑”真正本地化如果你正在使用Home Assistant(HA)来构建自己的智能家居系统,并且对其中那些需要调用云端API的“智能”功能(比如语音助手对话、意图理解)感到一丝不安——无论…...
推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标)
UPD720202K8-711-BAA-A 是瑞萨电子(Renesas Electronics)推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标
UPD720202K8-711-BAA-A 是瑞萨电子(Renesas Electronics)推出的一款 USB 3.0 主机控制器芯片,支持 xHCI 1.0 和 PCIe Gen2 接口标准,适用于高性能 USB 接口扩展方案。 核心特性: 接口标准:USB 3.0&…...

六层板电气检验别只测通断!4项核心电性能漏检必翻车
六层板量产前电气检验,很多工程师只做通断测试,觉得 “不短路、不断路就合格”,结果批量出货后问题频发:高速信号误码、电源发热烧板、绝缘击穿漏电、阻抗漂移失效。某工控客户惨痛经历:一款工业控制六层板,…...

哔哩下载姬DownKyi完整指南:三步掌握免费高效的B站视频下载
哔哩下载姬DownKyi完整指南:三步掌握免费高效的B站视频下载 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

Windows右键菜单高效管理方案:从杂乱到精简的完整指南
Windows右键菜单高效管理方案:从杂乱到精简的完整指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否厌倦了Windows右键菜单的混乱不堪&#…...

SkeyeVSS开发FAQ:国标视频流媒体转码与多码率自适应
试用安装包下载 | SMS | 在线演示 项目源码地址:https://github.com/openskeye/go-vss 1. 何时需要转码 播放端仅支持 H.264,源为 H.265;要求 低码率 外发,而设备只出主码流;需要将 PS/RTP 转为浏览器友好的 fMP4/HL…...