SpringBoot : ch04 整合数据源
前言
Spring Boot 是当今最流行的 Java 开发框架之一,它以简洁、高效的特点帮助开发者快速构建稳健的应用程序。在实际项目中,涉及到数据库操作的需求时,我们需要对数据源进行整合。本文将重点介绍如何在 Spring Boot 中整合数据源,以及如何利用 Spring Boot 的便利特性来简化这一过程。
无论是传统的关系型数据库,还是当下流行的 NoSQL 数据库,Spring Boot 都提供了丰富的支持。通过本文的学习,读者将能够掌握在 Spring Boot 中整合各类数据源的方法,并且了解如何利用 Spring Boot 的自动配置和简化的注解来简化数据源配置工作,从而更专注于应用程序的业务逻辑开发。
如果你对 Spring Boot 中数据源整合的方法感到困惑,或者希望了解如何通过 Spring Boot 来更高效地处理数据库操作,那么本文将为你提供宝贵的指导和实用的技巧。让我们一起深入探索 Spring Boot 中数据源整合的精彩世界吧!
一、前期准备
1、新建项目,结构如下
2、导入依赖
<dependencies><!-- spring boot 的核心starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- spring jdbc 的 starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- Druid 连接池的 starter --><!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.18</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><image><builder>paketobuildpacks/builder-jammy-base:latest</builder></image></configuration></plugin></plugins></build>
这是一个关于 Spring Boot 整合数据源的 Maven 依赖配置和构建插件示例。这些依赖项将帮助你在项目中使用 Spring Boot 和相关的数据库连接池进行数据源整合。以下是示例中包含的依赖项和插件说明:
spring-boot-starter:Spring Boot 的核心依赖,提供了基本的 Spring Boot 功能。spring-boot-starter-jdbc:Spring Boot 的 JDBC Starter,用于支持 JDBC 数据库操作。lombok:Java 开发工具,简化了代码编写过程。druid-spring-boot-starter:Druid 连接池的 Spring Boot Starter,用于管理数据库连接。mysql-connector-j:MySQL 数据库的 JDBC 驱动。spring-boot-starter-test:Spring Boot 的测试 Starter,用于编写单元测试。在构建部分,示例使用了
spring-boot-maven-plugin插件来配置 Docker 镜像构建时所使用的镜像构建器。
二、使用 yml 配置SpringBoot 内置的 hikari 连接池
# 数据源连接池
spring:datasource:# 连接属性driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/psmusername: rootpassword: 123456# SpringBoot 内置的 hikari 连接池hikari:# 最小空闲连接minimum-idle: 5# 最大连接数maximum-pool-size: 20# 最大空闲时长idle-timeout: 900000# 连接的超时时间connection-timeout: 3000# 检查连接的有效性connection-test-query: select 1
driver-class-name:指定 JDBC 驱动类的完整类名,用于连接数据库。在示例中,我们使用了 MySQL 的驱动类com.mysql.cj.jdbc.Driver。url:指定数据库的连接 URL。在示例中,我们连接的是本地的 MySQL 数据库,监听端口为 3306,数据库名称为psm。username和password:指定连接数据库所需的用户名和密码。接下来,我们配置了 Spring Boot 内置的 HikariCP 连接池相关的属性:
minimum-idle:指定连接池中最小空闲连接数。在示例中,我们设置为 5,表示连接池中至少保持 5 个空闲连接。maximum-pool-size:指定连接池中的最大连接数。在示例中,我们设置为 20,表示连接池中最多可以拥有 20 个连接。idle-timeout:指定连接的最大空闲时长,超过该时长的空闲连接将被释放。在示例中,我们设置为 900000 毫秒(15 分钟)。connection-timeout:指定连接的超时时间,即获取连接的最大等待时间。
connection-test-query:这里可以指定一个用于测试连接是否有效的SQL查询语句,比如select 1。连接池会定期执行这个查询来检测连接的有效性。
1、测试一下
@Slf4j
@SpringBootTest
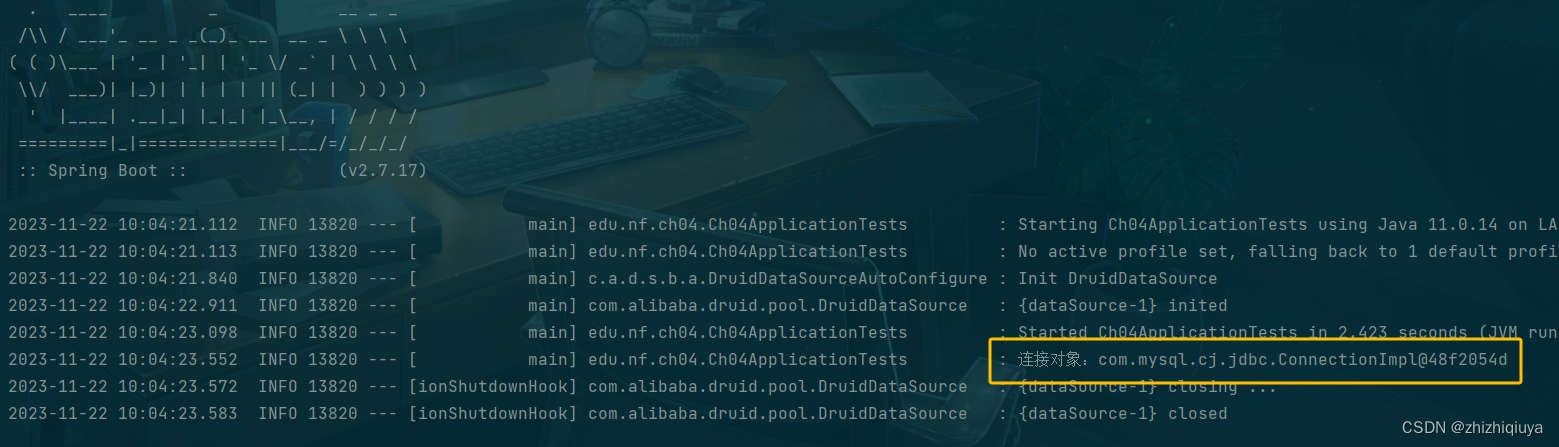
class Ch04ApplicationTests {@Autowiredprivate DataSource dataSource;@Testvoid contextLoads() throws SQLException {Connection connection = dataSource.getConnection();log.info("连接对象:" + connection);}
}这是一个简单的Junit测试类,用来验证你在Spring Boot应用中配置数据源连接池是否成功。以下是这个测试类的详细说明:
@Slf4j注解:这个注解会自动生成一个名为log的日志对象,用来输出日志信息。
@SpringBootTest注解:这个注解告诉JUnit测试框架,需要加载整个Spring应用上下文来执行测试。
@Autowired注解:这个注解用来自动装配数据源连接池对象,也就是在Spring容器中查找一个数据源对象并将其注入到dataSource变量中。
contextLoads()方法:这个方法是一个测试用例,用来测试数据源连接池是否正常工作。在这个方法中,你调用了dataSource.getConnection()方法获取一个数据库连接,并使用log.info()方法输出这个连接对象。当你运行这个测试类时,如果能够正常输出连接对象,就说明你已经成功地配置了数据源连接池,并且能够使用它来管理数据库连接了。
运行结果:
三、使用 yml 配置 druid 连接池
# 数据源连接池
spring:datasource:# 连接属性driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/psmusername: rootpassword: 123456# 使用 druid 连接池druid:# 最大连接数max-active: 100# 初始化连接数initial-size: 10# 最小连接池数min-idle: 10# 最大等待时间max-wait: 1000# 如果连接空闲时间大于等于( min-evictable-idle-time-millis)# 的时长则关闭连接time-between-eviction-runs-millis: 60000# 连接保持空闲而不被驱逐出连接池min-evictable-idle-time-millis: 300000# 检查连接有效性validation-query: select 1# 是否缓存 preparedStatement (MySQL 建议关闭)pool-prepared-statements: false
以下是一些重要的设置说明:
driver-class-name、url、username和password:这些属性指定了数据库连接的基本信息,包括驱动类名、数据库URL、用户名和密码。
druid.max-active:这个属性指定了连接池中允许的最大活动连接数,即最大连接池大小。
druid.initial-size:这个属性指定了连接池的初始大小,即在连接池刚刚创建时,连接池中包含的连接数。
druid.min-idle:这个属性指定了连接池中保持的最小空闲连接数。
druid.max-wait:当连接池中没有可用连接时,客户端在等待连接时最长的时间,单位为毫秒。
druid.time-between-eviction-runs-millis:用于检测连接池中空闲连接的时间间隔,单位为毫秒。如果连接空闲时间大于等于min-evictable-idle-time-millis的时长,则关闭连接。
druid.min-evictable-idle-time-millis:连接保持空闲而不被驱逐出连接池的时长,单位为毫秒。
druid.validation-query:用来检测连接是否有效的SQL查询语句,例如select 1。
druid.pool-prepared-statements:是否缓存prepared statements,对于MySQL数据库,建议将此属性设置为false。
1、测试一下
@Slf4j
@SpringBootTest
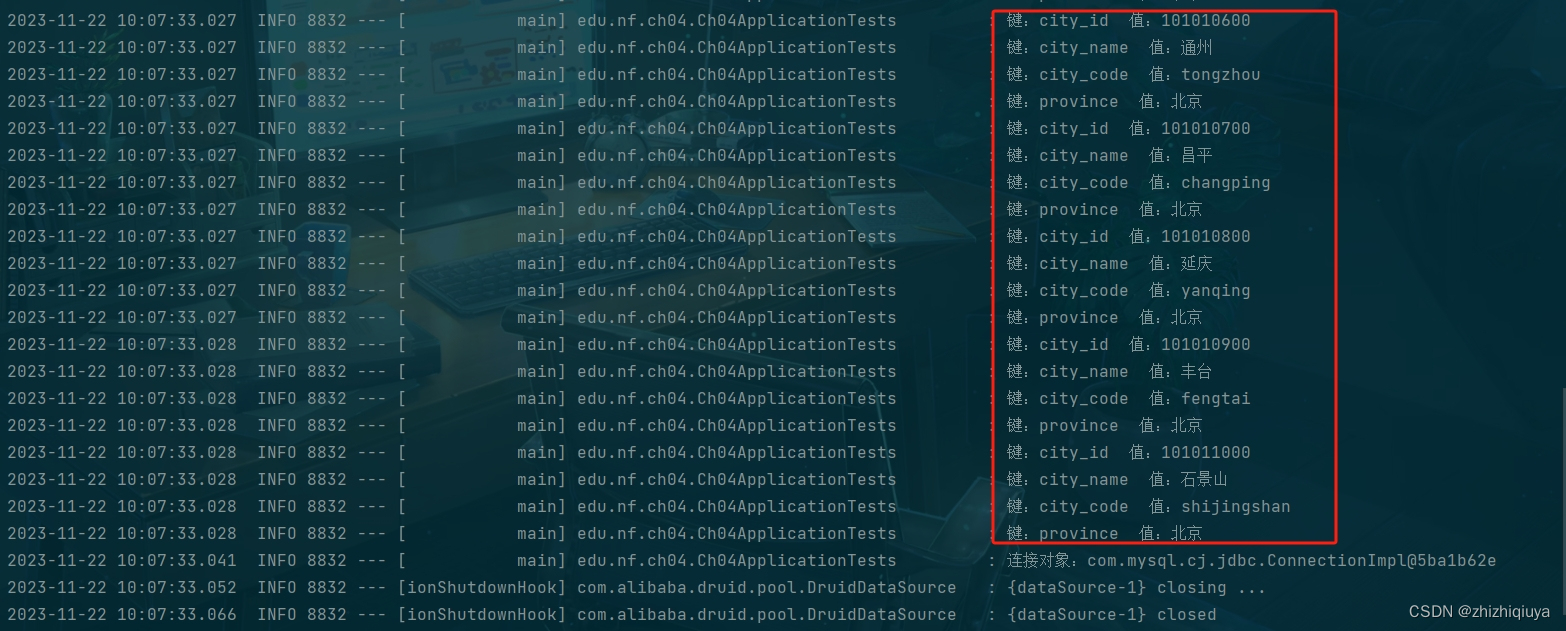
class Ch04ApplicationTests {@Autowiredprivate DataSource dataSource;/*** 注入 JDBC 的 Template,用于操作数据*/@Autowiredprivate JdbcTemplate template;@Testvoid contextLoads() throws SQLException {Connection connection = dataSource.getConnection();log.info("连接对象:" + connection);}@Testpublic void testJdbcTemplate(){List<Map<String, Object>> list = template.queryForList("select * from psm.city_info limit 0,10");list.forEach(map -> map.forEach((k,v) -> {log.info("键:" + k +" " + "值:" + v);}) );}}这段代码是一个Spring Boot的测试类,用于测试数据源和JdbcTemplate是否能够正常工作。
首先,在
@Autowired注解下,DataSource对象被注入到测试类中。这个数据源对象可以用来获取数据库连接,在contextLoads方法中,通过调用dataSource.getConnection()方法获得了一个数据库连接对象,然后在日志中记录了这个连接对象。另外,在
testJdbcTemplate方法中,可以看到JdbcTemplate对象也被注入到测试类中。JdbcTemplate是Spring框架提供的一个用于简化JDBC操作的工具类,可以用它来执行SQL查询、更新等操作。在这个方法中,使用了template.queryForList方法查询了psm.city_info表的前10行数据,并打印出了每一行数据中的键值对。通过这些测试,可以验证数据源和JdbcTemplate是否已经正确配置和注入到Spring容器中,以及它们是否能够正常地连接和操作数据库。如果测试通过,则说明你已经成功地配置了数据源和JdbcTemplate,并能够使用它们来操作数据库。
运行结果:
四、hikari 和Druid的区别
Hikari和Druid都是Java语言中常用的数据库连接池。它们之间的不同主要体现在以下几个方面:
-
性能和效率: HikariCP通常被认为是性能最好的连接池之一,因为它专注于快速、轻量级和高效的连接管理。相比之下,Druid虽然功能强大,但在某些情况下可能会牺牲一些性能以换取更多的特性和功能。
-
配置和简洁性: HikariCP的配置相对简单,通常只需要很少的参数设置就可以工作良好。而Druid提供了更多的配置选项和功能,这使得它在一些复杂的场景下更具灵活性,但也增加了学习和配置的复杂性。
-
监控和扩展性: Druid内置了丰富的监控和统计功能,可以方便地查看连接池的状态和性能指标。此外,Druid还提供了诸如防火墙、SQL转义等额外的功能,这些功能在HikariCP中可能需要额外的集成或扩展。
综上所述,HikariCP适合那些追求高性能、简洁配置的场景,而Druid则适合那些对监控和扩展性有较高要求的场景。选择哪个连接池取决于具体的项目需求和性能考量。
相关文章:
SpringBoot : ch04 整合数据源
前言 Spring Boot 是当今最流行的 Java 开发框架之一,它以简洁、高效的特点帮助开发者快速构建稳健的应用程序。在实际项目中,涉及到数据库操作的需求时,我们需要对数据源进行整合。本文将重点介绍如何在 Spring Boot 中整合数据源ÿ…...

Docker Swarm总结
目录 1、swarm 理论基础 1.1 简介 1.2 节点架构 1.3 服务架构 1.4 服务部署模式 2、swarm 集群搭建 2.1 需求 2.2 克隆主机 2.3 启动5个docker宿主机 2.4 查看 swarm 激活状态 2.5 关闭防火墙 2.6 swarm 初始化 2.7 添加 worker 节点 2.8 添加 manager 节点 3…...

特殊token的特殊用途
特殊token的特殊用途 特殊voc设计传统的特殊token 用途特殊用途例子特殊voc设计 普通token1 。。。。普通token1000,特殊token1,,,,,特殊token100 ,特殊指示token1,,,特殊指示token100 传统的特殊token 用途 在您提供的示例中,有1000个普通 token(从普通 token …...
苹果Siri怎么打开?教你两招轻松唤醒!
苹果Siri助手是苹果公司开发的智能语音助手。作为智能语音助手,Siri可以理解用户的指令,并给出相应的回答或执行相应的操作,帮助大家完成各种任务,比如发送短信、查询天气、播放音乐、设置提醒等等。 然而,还有一些小…...

分类问题的评价指标
一、logistic regression logistic regression也叫做对数几率回归。虽然名字是回归,但是不同于linear regression,logistic regression是一种分类学习方法。 同时在深度神经网络中,有一种线性层的输出也叫做logistic,他是被输入…...

Hive 定义变量 变量赋值 引用变量
Hive 定义变量 变量赋值 引用变量 变量 hive 中变量和属性命名空间 命名空间权限描述hivevar读写用户自定义变量hiveconf读写hive相关配置属性system读写java定义额配置属性env只读shell环境定义的环境变量 语法 Java对这个除env命名空间内容具有可读可写权利; …...
51单片机LED灯渐明渐暗实验
51单片机LED灯渐明渐暗实验 1.概述 这篇文章介绍使用单片机控制两个LED彩灯亮度渐明渐暗效果,详细介绍了操作步骤以及完整的程序代码,动手就能制作的小实验。 2.操作步骤 2.1.硬件搭建 1.硬件准备 名称型号数量单片机STC12C2052AD1LED彩灯无2晶振1…...

美团面试:微服务如何拆分?原则是什么?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如美团、字节、如阿里、滴滴、极兔、有赞、希音、百度、网易的面试资格,遇到很多很重要的面试题: 微服务如何拆分? 微服务拆分的规范和原则…...
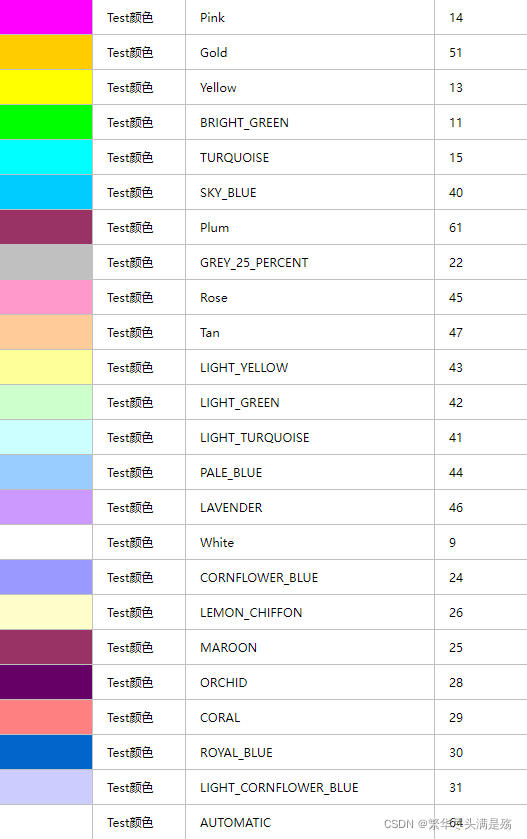
easyExcel注解详情
前言11个注解字段注解 类注解基础综合示例补充颜色总结 11个注解 ExcelProperty ColumnWith 列宽 ContentFontStyle 文本字体样式 ContentLoopMerge 文本合并 ContentRowHeight 文本行高度 ContentStyle 文本样式 HeadFontStyle 标题字体样式 HeadRowHeight 标题高度 HeadStyle…...

S7-1200PLC 作为MODBUSTCP服务器通信(多客户端访问)
S7-1200PLC作为MODBUSTCP服务器端通信编程应用,详细内容请查看下面文章链接: ModbusTcp通信(S7-1200PLC作为服务器端)-CSDN博客文章浏览阅读239次。S7-200Smart plc作为ModbusTcp服务器端的通信S7-200SMART PLC ModbusTCP通信(ModbusTcp服务器)_s7-200 modbustcp-CSDN博客文…...

泰勒多项式
泰勒展开 f ( x ) P n ( x ) R n ( x ) f(x)P_n(x)R_n(x) f(x)Pn(x)Rn(x) P n ( x ) ∑ 0 n f ( k ) ( x 0 ) k ! ( x − x 0 ) k P_n(x)\sum_0^n\frac{f^{(k)}(x_0)}{k!}(x-x_0)^k Pn(x)∑0nk!f(k)(x0)(x−x0)k R n ( x ) f ( n 1 ) ( ξ x 0 ) ( n 1 ) !…...
【Hello Go】Go语言文本文件处理
文本文件处理 字符串处理字符串操作ContainsJoinindexrepeatReplaceSplitTrimFields 字符串转换AppendFormatParse 正则表达式Json处理编码Json通过结构体生产Json通过map生产json 解码Json解析到结构体解析到interface 文件操作相关api介绍建立和打开文件关闭文件写文件读文件…...
ppt录屏制作微课,轻松打造精品课程
微课作为一种新型的教学方式逐渐受到广大师生的欢迎。微课具有方便快捷、内容丰富、互动性强等特点,可以有效地帮助教师传达知识,提高学生的学习效果。其中,ppt录屏制作微课就是一种常见的方式。本文将介绍ppt录屏的使用方法,帮助…...
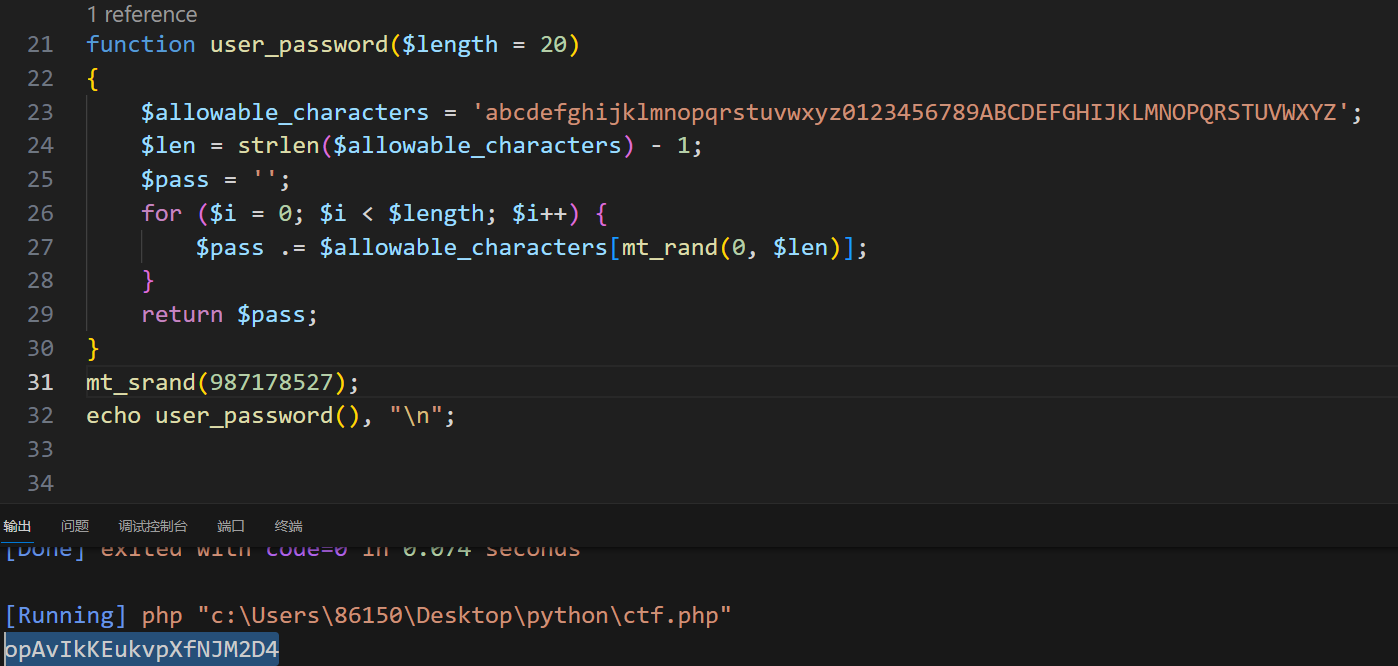
php伪随机数
利用工具 php_mt_seed <?php // php 7.2function white_list() {return mt_rand();}echo white_list(), "\n";echo white_list(), "\n";echo white_list(), "\n"; 输入命令: ./php_mt_seed 1035656029 <?phpmt_srand(181095…...
为什么录屏没声音?实用技巧大放送!
录屏已成为我们在数字时代记录和分享内容的重要方式之一。但有时,您可能会遇到录制视频却没有声音的问题。这个问题可能出现在不同的录屏软件中,导致许多人感到疑惑。在本文中,我们将探讨为什么录屏没声音,并提供两种解决方案&…...
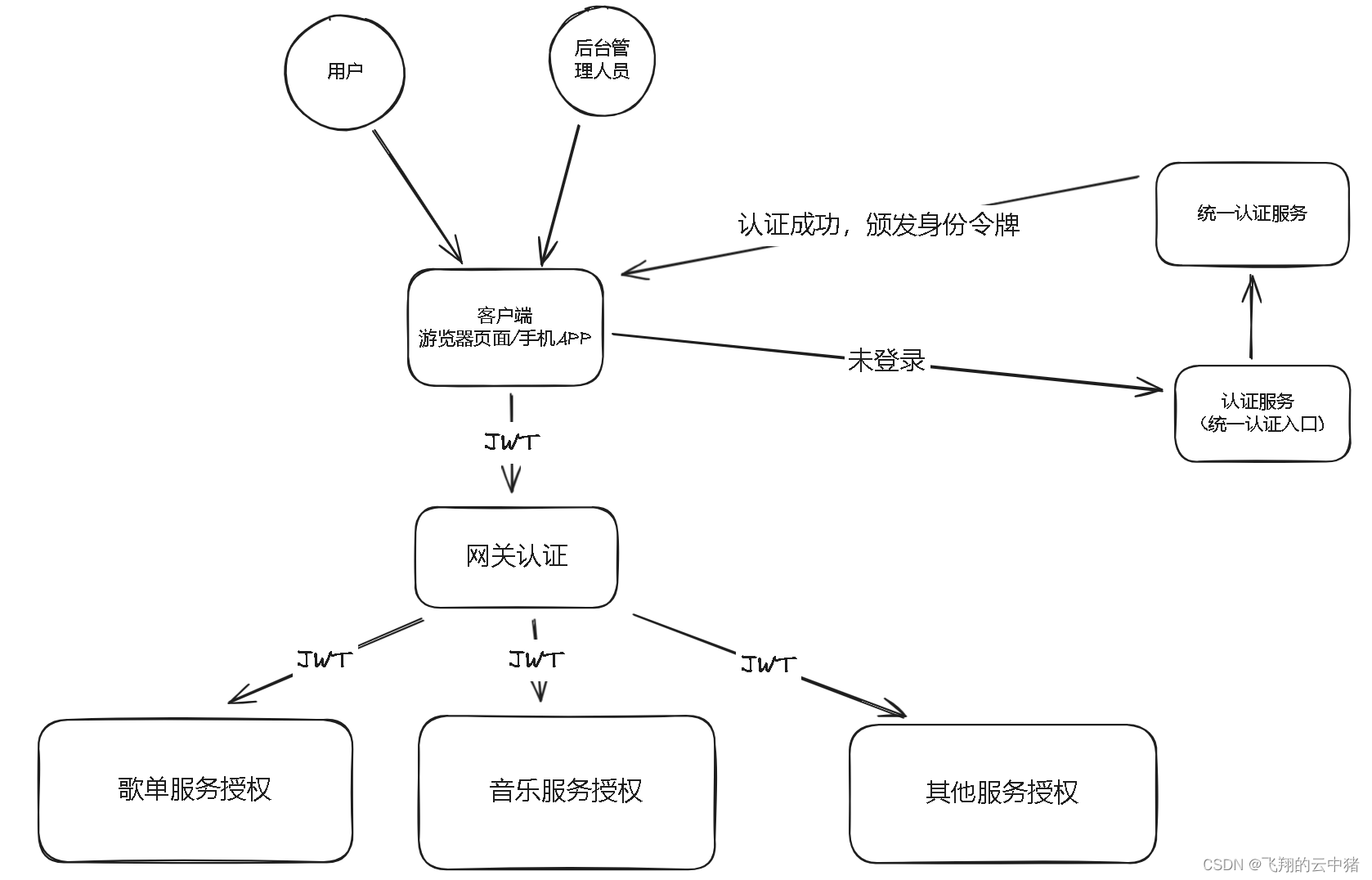
分布式系统的认证授权
一.分布式系统的认证授权大致架构 以云音乐系统为例: 注:一般情况下,我们会把认证的部分的接口提取为一个单独的认证服务模块中。 二.单点登录(Single Sign On) 单点登录,Single Sign On,简称…...
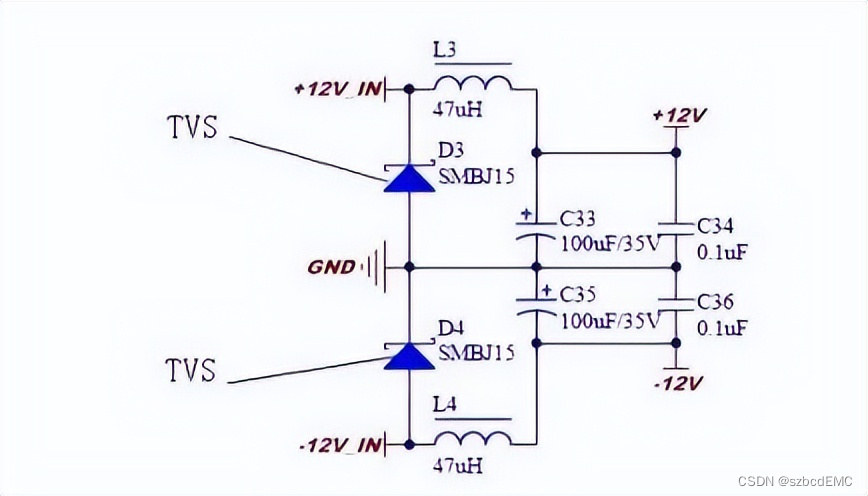
TVS瞬态抑制二极管的工作原理和特点?|深圳比创达电子EMC
TVS二极管一般是用来防止端口瞬间的电压冲击造成后级电路的损坏。防止端口瞬间的电压冲击造成后级电路的损坏。有单向与双向之分,单向TVS一般应用于直流供电电路,双向TVS应用于交流供电电路。 TVS产品的额定瞬态功率应大于电路中可能出现的最大瞬态浪涌…...

csdn - mermaid
目录 方向节点样式形状箭头 子图流程图类图uml图甘特图 https://blog.csdn.net/sandalphon4869/article/details/89341443 https://blog.csdn.net/swinfans/article/details/89393853 https://zhuanlan.zhihu.com/p/614018391 https://blog.csdn.net/qq_42491125/article/detai…...

C题目11:数组a[m]排序
每日小语 双手,且放下一切劳作,前额,也忘掉忧思,此时此刻我所有的感觉就想沉入安睡。 自己敲写 这个问题老师上课讲了一种方法,叫做冒泡排序。基本思想是 1.找最小值,放到a[0] 2.从a[1]~a[3]找最小值&a…...
编译器安全
在供应链安全中,大家一直关注采用SCA工具分析开源组件中的安全漏洞以及许可证的合规性。但是对于底层软件开发使用的编译器、链接器等安全却容易被忽视,其中有没有安全漏洞、有没有运行时缺陷、有没有被植入漏洞、木马等,似乎并没有引起多少人…...

XUnity.AutoTranslator:打破语言壁垒的Unity游戏实时翻译终极解决方案
XUnity.AutoTranslator:打破语言壁垒的Unity游戏实时翻译终极解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂的外文游戏而烦恼吗?XUnity.AutoTranslator 是你…...

3分钟掌握ncmdump:让你的网易云音乐在任意设备自由播放
3分钟掌握ncmdump:让你的网易云音乐在任意设备自由播放 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 你是否曾有过这样的体验?在网易云音乐下载了心爱的歌曲,准备在…...

AISMM团队组建必须避开的6个致命误区,国家级测评中心首席专家亲授“评估效能衰减预警模型”
更多请点击: https://intelliparadigm.com 第一章:AISMM模型评估团队组建指南 组建一支高效、跨职能的AISMM(AI Software Maturity Model)模型评估团队,是保障AI系统可解释性、鲁棒性与合规性的关键前提。该团队并非传…...

Docker 安装 数据库工单系统Yearning以及使用
文档以及部署 什么是Yearning? 一个强大且本地部署的平台,专为数据库管理员(DBA)和开发人员设计,提供无缝的SQL检测和查询审计。专注于隐私和效率,为MYSQL审计提供直观且安全的环境。 功能 AI 助手:我…...

终极桌面整理指南:如何使用NoFences免费打造高效工作空间
终极桌面整理指南:如何使用NoFences免费打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上杂乱无章的图标?重…...

C语言实现精简Smalltalk运行时:探索面向对象与消息传递的本质
1. 项目概述:当“小结构”遇上“小对话”如果你在开源社区里混迹过一段时间,可能会发现一个有趣的现象:很多项目的名字,乍一看不知所云,但一旦你理解了它的设计哲学,就会觉得无比贴切。tinystruct/smalltal…...

内容创作团队如何借助Taotoken灵活调用不同模型优化文案生成
内容创作团队如何借助Taotoken灵活调用不同模型优化文案生成 1. 多模型统一接入的价值 内容创作团队在日常工作中需要处理多种风格的文案需求,从正式商业报告到社交媒体短文,每种场景对语言风格和内容结构的要求各不相同。传统单一模型接入方式往往难以…...

wall-vault:构建高可用AI代理骨干网络,实现密钥管理与智能故障转移
1. 项目概述:一个为AI工作流打造的“永不掉线”中枢如果你和我一样,重度依赖像OpenClaw这样的AI代理框架进行日常开发、写作或自动化,那你一定经历过那种“断线”的恐慌。深夜,一个API密钥配额耗尽,或者服务商突发故障…...

可视化编程入门:5个步骤让你用MIT App Inventor零代码开发移动应用
可视化编程入门:5个步骤让你用MIT App Inventor零代码开发移动应用 【免费下载链接】appinventor-sources MIT App Inventor Public Open Source 项目地址: https://gitcode.com/gh_mirrors/ap/appinventor-sources 你是否曾想过开发自己的手机应用ÿ…...

长芯微LMD9245完全P2P替代AD9245,14位、20/40/65/80MSPS模数转换器ADC
描述长芯微LMD9245是一款单芯片、14位、20 MSPS/40 MSPS/65 MSPS/80 MSPS模数转换器(ADC),采用3 V单电源供电,内置一个高性能采样保持放大器(SHA)和基准电压源。它采用多级差分流水线架构,内置输…...