机器学习笔记之流形模型——标准流模型基本介绍
机器学习笔记之流形模型——标准流模型基本介绍
- 引言
- 回顾:隐变量模型的缺陷
- 标准流(Normalizing Flow\text{Normalizing Flow}Normalizing Flow)思想
- 分布变换的推导过程
引言
本节将介绍概率生成模型——标准流模型(Normalizing Flow\text{Normalizing Flow}Normalizing Flow)。
回顾:隐变量模型的缺陷
关于隐变量模型(Latent Variable Model,LVM\text{Latent Variable Model,LVM}Latent Variable Model,LVM),如果表示隐变量的随机变量集合Z\mathcal ZZ足够复杂的话,很容易出现积分难问题:
此时隐变量Z\mathcal ZZ的维度(随机变量个数)极高(M)(\mathcal M)(M),对Z\mathcal ZZ求解积分的代价是极大的(Intractable)(\text{Intractable})(Intractable).
P(X)⏟Intractable=∫ZP(Z,X)dZ=∫ZP(Z)⋅P(X∣Z)dZ=∫Z1⋯∫ZMP(Z1,⋯,ZM)⋅P(X∣Z1,⋯,ZM)dZ1,⋯,ZM\begin{aligned} \underbrace{\mathcal P(\mathcal X) }_{\text{Intractable}} & = \int_{\mathcal Z} \mathcal P(\mathcal Z,\mathcal X) d\mathcal Z \\ & = \int_{\mathcal Z} \mathcal P(\mathcal Z) \cdot \mathcal P(\mathcal X \mid \mathcal Z) d\mathcal Z \\ & = \int_{\mathcal Z_1} \cdots \int_{\mathcal Z_{\mathcal M}} \mathcal P(\mathcal Z_1,\cdots,\mathcal Z_{\mathcal M}) \cdot \mathcal P(\mathcal X \mid \mathcal Z_1,\cdots,\mathcal Z_{\mathcal M}) d\mathcal Z_1,\cdots,\mathcal Z_{\mathcal M} \end{aligned}IntractableP(X)=∫ZP(Z,X)dZ=∫ZP(Z)⋅P(X∣Z)dZ=∫Z1⋯∫ZMP(Z1,⋯,ZM)⋅P(X∣Z1,⋯,ZM)dZ1,⋯,ZM
从而,关于隐变量Z\mathcal ZZ的后验概率P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)也同样是极难求解的:
P(Z∣X)⏟Intractable=P(Z,X)P(X)=P(Z)⋅P(X∣Z)P(X)⏟Intractable\begin{aligned} \underbrace{\mathcal P(\mathcal Z \mid \mathcal X)}_{\text{Intractable}} & = \frac{\mathcal P(\mathcal Z,\mathcal X)}{\mathcal P(\mathcal X)} \\ & = \frac{\mathcal P(\mathcal Z) \cdot \mathcal P(\mathcal X \mid \mathcal Z)}{\underbrace{\mathcal P(\mathcal X)}_{\text{Intractable}}} \end{aligned}IntractableP(Z∣X)=P(X)P(Z,X)=IntractableP(X)P(Z)⋅P(X∣Z)
针对这种问题,由于无法得到精确解/精确解计算代价极高,因而通常采用近似推断(Approximate Inference\text{Approximate Inference}Approximate Inference)的方式对P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)近似求解。
例如变分自编码器(Variational Auto-Encoder,VAE\text{Variational Auto-Encoder,VAE}Variational Auto-Encoder,VAE),它的底层逻辑是使用重参数化技巧将人为设定分布Q(Z∣X)\mathcal Q(\mathcal Z \mid \mathcal X)Q(Z∣X)视作关于参数ϕ\phiϕ的函数Q(Z∣X,ϕ)\mathcal Q(\mathcal Z \mid \mathcal X,\phi)Q(Z∣X,ϕ),并通过神经网络学习参数ϕ\phiϕ并使其近似P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)。关于变分自编码器的模型结构表示如下:
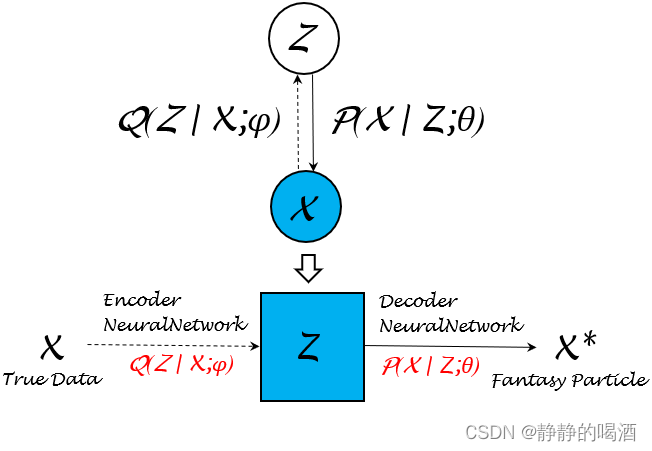
关于编码器(Encoder\text{Encoder}Encoder)函数Q(Z∣X;ϕ)\mathcal Q(\mathcal Z \mid \mathcal X;\phi)Q(Z∣X;ϕ)与解码器(Decoder\text{Decoder}Decoder)函数P(X∣Z;θ)\mathcal P(\mathcal X \mid \mathcal Z;\theta)P(X∣Z;θ),变分自编码器的目标函数表示如下:
一个有趣的现象:其中−KL[Q(Z∣X;ϕ)∣∣P(Z;θ(t))]- \text{KL} [\mathcal Q(\mathcal Z \mid \mathcal X;\phi) || \mathcal P(\mathcal Z ;\theta^{(t)})]−KL[Q(Z∣X;ϕ)∣∣P(Z;θ(t))]只是一个关于ϕ\phiϕ的惩罚项(约束),并且这个约束直接作用于EQ(Z∣X;ϕ)[logP(X∣Z;θ)]\mathbb E_{\mathcal Q(\mathcal Z \mid \mathcal X;\phi)} \left[\log \mathcal P(\mathcal X \mid \mathcal Z;\theta)\right]EQ(Z∣X;ϕ)[logP(X∣Z;θ)].因此真正迭代的只有参数θ(θ(t)⇒θ(t+1))\theta(\theta^{(t)}\Rightarrow \theta^{(t+1)})θ(θ(t)⇒θ(t+1)),参数ϕ\phiϕ仅是迭代过程中伴随着θ\thetaθ的更新而更新。
{L(ϕ,θ,θ(t))=EQ(Z∣X;ϕ)[logP(X∣Z;θ)]−KL[Q(Z∣X;ϕ)∣∣P(Z;θ(t))](θ^(t+1),ϕ^(t+1))=argmaxθ,ϕL(ϕ,θ,θ(t))\begin{cases} \mathcal L(\phi,\theta,\theta^{(t)}) = \mathbb E_{\mathcal Q(\mathcal Z \mid \mathcal X;\phi)} \left[\log \mathcal P(\mathcal X \mid \mathcal Z;\theta)\right] - \text{KL} [\mathcal Q(\mathcal Z \mid \mathcal X;\phi) || \mathcal P(\mathcal Z;\theta^{(t)})] \\ \quad \\ (\hat {\theta}^{(t+1)},\hat {\phi}^{(t+1)}) = \mathop{\arg\max}\limits_{\theta,\phi} \mathcal L(\phi,\theta,\theta^{(t)}) \end{cases}⎩⎨⎧L(ϕ,θ,θ(t))=EQ(Z∣X;ϕ)[logP(X∣Z;θ)]−KL[Q(Z∣X;ϕ)∣∣P(Z;θ(t))](θ^(t+1),ϕ^(t+1))=θ,ϕargmaxL(ϕ,θ,θ(t))
关于目标函数L(ϕ,θ,θ(t))\mathcal L(\phi,\theta,\theta^{(t)})L(ϕ,θ,θ(t))的底层逻辑是最大化ELBO\text{ELBO}ELBO:
(θ^(t+1),ϕ^(t+1))=argmaxθ,ϕ{EQ(Z∣X;ϕ)[logP(X,Z;θ)Q(Z∣X;ϕ)]}(\hat {\theta}^{(t+1)},\hat {\phi}^{(t+1)}) = \mathop{\arg\max}\limits_{\theta,\phi} \left\{\mathbb E_{\mathcal Q(\mathcal Z \mid \mathcal X;\phi)} \left[\log \frac{\mathcal P(\mathcal X,\mathcal Z;\theta)}{\mathcal Q(\mathcal Z \mid \mathcal X;\phi)}\right]\right\}(θ^(t+1),ϕ^(t+1))=θ,ϕargmax{EQ(Z∣X;ϕ)[logQ(Z∣X;ϕ)P(X,Z;θ)]}
也就是说,它仅仅是最大化了极大似然估计logP(X;θ)\log \mathcal P(\mathcal X;\theta)logP(X;θ)的下界。实际上,它并没有直接对对数似然函数求解最优化问题。
这不可避免地存在误差,毕竟最优化对数似然函数和最优化它的下界 是两个概念。这一切的核心问题均在于P(X)\mathcal P(\mathcal X)P(X)无法得到精确解。
如果存在一种模型,它在学习任务过程中,P(X)\mathcal P(\mathcal X)P(X)是可求解的(tractable\text{tractable}tractable),自然不会出现上述一系列的近似操作了。
标准流(Normalizing Flow\text{Normalizing Flow}Normalizing Flow)思想
关于样本X\mathcal XX的概率分布P(X)\mathcal P(\mathcal X)P(X),它可能是复杂的。但流模型(Flow-based Model\text{Flow-based Model}Flow-based Model)的思想是:分布P(X)\mathcal P(\mathcal X)P(X)的复杂并不是一蹴而就的,而是通过若干次的变化而产生出的复杂结果。
关于流模型的概率图结构可表示为如下形式:
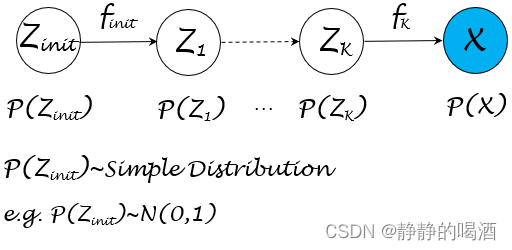
从模型结构中可以观察到,既然分布P(X)\mathcal P(\mathcal X)P(X)比较复杂,那么可以构建隐变量Z\mathcal ZZ与X\mathcal XX之间的函数关系X=f(Z)\mathcal X = f(\mathcal Z)X=f(Z),从而通过换元的方式描述P(Z)\mathcal P(\mathcal Z)P(Z)与P(X)\mathcal P(\mathcal X)P(X)的函数关系。
如果隐变量Z\mathcal ZZ的结构同样复杂,可以继续针对该隐变量创造新的隐变量并构建函数关系。以此类推,最终可以通过一组服从简单分布的随机变量Zinit\mathcal Z_{init}Zinit通过若干次的函数的嵌套表示,得到关于X\mathcal XX的关联关系,从而得到Pinit(Zinit)⇒P(X)\mathcal P_{init}(\mathcal Z_{init}) \Rightarrow \mathcal P(\mathcal X)Pinit(Zinit)⇒P(X)的函数关系。
分布变换的推导过程
以上图中隐变量ZK\mathcal Z_{\mathcal K}ZK和观测变量X\mathcal XX之间关联关系示例:
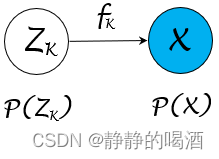
- 创建假设:fKf_{\mathcal K}fK是一个 连续、可逆 函数,满足X=fK(ZK)\mathcal X = f_{\mathcal K}(\mathcal Z_{\mathcal K})X=fK(ZK)。其中ZK,X\mathcal Z_{\mathcal K},\mathcal XZK,X均表示随机变量集合,并服从对应的概率分布:
其中PX(X)\mathcal P_{\mathcal X}(\mathcal X)PX(X)表示关于X\mathcal XX的概率分布,并且变量是X.ZK\mathcal X.\mathcal Z_{\mathcal K}X.ZK对应分布同理。反过来,由于fKf_{\mathcal K}fK函数可逆,因而有:ZK=fK−1(X)\mathcal Z_{\mathcal K} = f_{\mathcal K}^{-1}(\mathcal X)ZK=fK−1(X).
ZK∼PZK(ZK),X∼PX(X);ZK,X∈Rp\mathcal Z_{\mathcal K} \sim \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K}),\mathcal X \sim \mathcal P_{\mathcal X}(\mathcal X);\quad \mathcal Z_{\mathcal K},\mathcal X \in \mathbb R^pZK∼PZK(ZK),X∼PX(X);ZK,X∈Rp
- 不可否认的是,无论是PZK(ZK)\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PZK(ZK)还是PX(X)\mathcal P_{\mathcal X}(\mathcal X)PX(X),它们都是概率分布。根据概率密度积分的定义,必然有:
∫ZKPZK(ZK)dZK=∫XPX(X)dX=1\int_{\mathcal Z_{\mathcal K}} \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K}) d\mathcal Z_{\mathcal K} = \int_{\mathcal X} \mathcal P_{\mathcal X}(\mathcal X) d\mathcal X =1∫ZKPZK(ZK)dZK=∫XPX(X)dX=1
从而有:
在变分推断——重参数化技巧一节中也使用这种描述进行换元,在不定积分中,PZK(ZK)dZK\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K}) d\mathcal Z_{\mathcal K}PZK(ZK)dZK和PX(X)dX\mathcal P_{\mathcal X}(\mathcal X)d \mathcal XPX(X)dX必然相等;但是在定积分中,ZK,X\mathcal Z_{\mathcal K},\mathcal XZK,X位于不同的特征空间,对应的积分值(有正有负)存在差异。因此需要加上‘模’符号。
∣PZK(ZK)dZK∣=∣PX(X)dX∣|\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K}) d\mathcal Z_{\mathcal K}| = |P_{\mathcal X}(\mathcal X) d\mathcal X|∣PZK(ZK)dZK∣=∣PX(X)dX∣
但由于PZK(ZK),PX(X)\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K}),\mathcal P_{\mathcal X}(\mathcal X)PZK(ZK),PX(X)它们是概率密度函数,它们的实际结果表示概率值(恒正)。因此∣PX(X)∣=PX(X)|\mathcal P_{\mathcal X}(\mathcal X)| = \mathcal P_{\mathcal X}(\mathcal X)∣PX(X)∣=PX(X),PZK(ZK)\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PZK(ZK)同理。经过移项,可将概率分布之间的关系表示为如下形式:
PX(X)=∣dZKdX∣⋅PZK(ZK)\mathcal P_{\mathcal X}(\mathcal X) = \left|\frac{d\mathcal Z_{\mathcal K}}{d\mathcal X}\right| \cdot \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PX(X)=dXdZK⋅PZK(ZK)
将ZK=fK−1(X)\mathcal Z_{\mathcal K} = f_{\mathcal K}^{-1}(\mathcal X)ZK=fK−1(X)代入,最终可得到如下形式:
PX(X)=∣∂fK−1(X)∂X∣⋅PZK(ZK)\mathcal P_{\mathcal X}(\mathcal X) = \left|\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right| \cdot \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PX(X)=∂X∂fK−1(X)⋅PZK(ZK) - 观察系数项∣∂fK−1(X)∂X∣\left|\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right|∂X∂fK−1(X),它是一个标量、常数,但∂fK−1(X)∂X\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial\mathcal X}∂X∂fK−1(X)自身是一个矩阵:
该矩阵被称作雅可比矩阵Jacobian\text{Jacobian}Jacobian
∂fK−1(X)∂X=[∂fK−1(X1)∂X1∂fK−1(X1)∂X2⋯∂fK−1(X1)∂Xp∂fK−1(X2)∂X1∂fK−1(X2)∂X2⋯∂fK−1(X2)∂Xp⋮⋮⋱⋮∂fK−1(Xp)∂X1∂fK−1(Xp)∂X2⋯∂fK−1(Xp)∂Xp]p×p\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X} = \begin{bmatrix} \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_1)}{\partial \mathcal X_1} & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_1)}{\partial \mathcal X_2}& \cdots & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_1)}{\partial \mathcal X_p} \\ \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_2)}{\partial \mathcal X_1} & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_2)}{\partial \mathcal X_2} & \cdots & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_2)}{\partial \mathcal X_p}\\ \vdots & \vdots & \ddots & \vdots\\ \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_p)}{\partial \mathcal X_1} & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_p)}{\partial \mathcal X_2} & \cdots & \frac{\partial f_{\mathcal K}^{-1}(\mathcal X_p)}{\partial \mathcal X_p} \end{bmatrix}_{p \times p}∂X∂fK−1(X)=∂X1∂fK−1(X1)∂X1∂fK−1(X2)⋮∂X1∂fK−1(Xp)∂X2∂fK−1(X1)∂X2∂fK−1(X2)⋮∂X2∂fK−1(Xp)⋯⋯⋱⋯∂Xp∂fK−1(X1)∂Xp∂fK−1(X2)⋮∂Xp∂fK−1(Xp)p×p
那么∣∂fK−1(X)∂X∣\left|\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right|∂X∂fK−1(X)实际上是与雅克比矩阵对应的雅克比行列式(Jacobian Determinant\text{Jacobian Determinant}Jacobian Determinant)的绝对值。使用det[∂fK−1(X)∂X]\text{det}\left[\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right]det[∂X∂fK−1(X)]进行表示:
PX(X)=∣det[∂fK−1(X)∂X]∣⋅PZK(ZK)\mathcal P_{\mathcal X}(\mathcal X) = \left|\text{det}\left[\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right]\right| \cdot \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PX(X)=det[∂X∂fK−1(X)]⋅PZK(ZK) - 继续变换,观察∂fK−1(X)∂X\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}∂X∂fK−1(X),可以继续向下变换:
{∂fK−1(X)∂X⋅∂fK(ZK)∂ZK=1⇒∂fK−1(X)∂X=[∂fK(ZK)∂ZK]−1⇒∣det[∂fK−1(X)∂X]∣=∣det[∂fK(ZK)∂ZK]∣−1\begin{cases} \frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X} \cdot \frac{\partial f_{\mathcal K}(\mathcal Z_{\mathcal K})}{\partial \mathcal Z_{\mathcal K}} = 1 \Rightarrow \frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X} = \left[\frac{\partial f_{\mathcal K}(\mathcal Z_{\mathcal K})}{\partial \mathcal Z_{\mathcal K}}\right]^{-1} \\ \Rightarrow \left|\text{det}\left[\frac{\partial f_{\mathcal K}^{-1}(\mathcal X)}{\partial \mathcal X}\right]\right| = \left|\text{det}\left[\frac{\partial f_{\mathcal K}(\mathcal Z_{\mathcal K})}{\partial \mathcal Z_{\mathcal K}}\right]\right|^{-1} \end{cases}⎩⎨⎧∂X∂fK−1(X)⋅∂ZK∂fK(ZK)=1⇒∂X∂fK−1(X)=[∂ZK∂fK(ZK)]−1⇒det[∂X∂fK−1(X)]=det[∂ZK∂fK(ZK)]−1
最终,分布PX(X)\mathcal P_{\mathcal X}(\mathcal X)PX(X)与分布PZK(ZK)\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PZK(ZK)之间的关系表示为:
PX(X)=∣det[∂fK(ZK)∂ZK]∣−1⋅PZK(ZK)\mathcal P_{\mathcal X}(\mathcal X) = \left|\text{det}\left[\frac{\partial f_{\mathcal K}(\mathcal Z_{\mathcal K})}{\partial \mathcal Z_{\mathcal K}}\right]\right|^{-1} \cdot \mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PX(X)=det[∂ZK∂fK(ZK)]−1⋅PZK(ZK)
至此,从随机变量ZK\mathcal Z_{\mathcal K}ZK与随机变量X\mathcal XX之间的函数关系,转化为概率分布PX(X)\mathcal P_{\mathcal X}(\mathcal X)PX(X)与PZK(ZK)\mathcal P_{\mathcal Z_{\mathcal K}}(\mathcal Z_{\mathcal K})PZK(ZK)之间的函数关系已表示出来。而流模型中的每一个过程均是基于上述关系,一层一层计算过来。
不同于以往对P(X)\mathcal P(\mathcal X)P(X)的求解过程,它能够将P(X)\mathcal P(\mathcal X)P(X)描述出来,直到使用隐变量的层数选择完成,其对应的P(X)\mathcal P(\mathcal X)P(X)计算精度达到条件即可。关于流模型的学习方式依然是极大似然估计(Maximum Likelihood Estimation,MLE\text{Maximum Likelihood Estimation,MLE}Maximum Likelihood Estimation,MLE):
logPX(X)=log{∏k=1K∣det[∂fk(Zk)∂Zk]∣−1⋅Pinit(Zinit)}=logPinit(Zinit)+∑k=1Klog{∣det[∂fk(Zk)∂Zk]∣−1}\begin{aligned} \log \mathcal P_{\mathcal X}(\mathcal X) & = \log \left\{\prod_{k=1}^{\mathcal K} \left|\text{det} \left[\frac{\partial f_{k}(\mathcal Z_k)}{\partial \mathcal Z_k}\right]\right|^{-1} \cdot \mathcal P_{init}(\mathcal Z_{init})\right\} \\ & = \log \mathcal P_{init}(\mathcal Z_{init}) + \sum_{k=1}^{\mathcal K} \log \left\{\left|\text{det} \left[\frac{\partial f_{k}(\mathcal Z_k)}{\partial \mathcal Z_k}\right]\right|^{-1}\right\} \end{aligned}logPX(X)=log{k=1∏Kdet[∂Zk∂fk(Zk)]−1⋅Pinit(Zinit)}=logPinit(Zinit)+k=1∑Klog{det[∂Zk∂fk(Zk)]−1}
相关参考:
雅可比矩阵——百度百科
【机器学习白板推导系列(三十三) ~ 流模型(Flow Based Model)】
相关文章:
机器学习笔记之流形模型——标准流模型基本介绍
机器学习笔记之流形模型——标准流模型基本介绍引言回顾:隐变量模型的缺陷标准流(Normalizing Flow\text{Normalizing Flow}Normalizing Flow)思想分布变换的推导过程引言 本节将介绍概率生成模型——标准流模型(Normalizing Flow\text{Normalizing Flow}Normalizi…...

MIT:只需一层RF传感器,就能为AR头显赋予“X光”穿透视力
近年来,AR在仓库、工厂等场景得到应用,比如GlobalFoundries、亚马逊、菜鸟裹裹就使用摄像头扫描定位货品,并使用AR来导航和标记。目前,这种方案主要基于视觉算法,因此仅能定位视线范围内的目标。然而,在一些…...

对 Dom 树的理解
什么是 DOM 从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。 DOM 提供了对 HTML 文档结构化的表述。 在渲染引擎中,DOM 有三个层面的作用: …...

电商搜索入门
一、搜索用途通常一个电商平台里面的商品,少则几十万多则上千万甚至上亿的sku,在这么多的商品中,如何让用户可以快速查找到自己想要的商品,那么就需要用到搜索功能来实现。通过分析数据发现,接近40%的点击率是直接通过…...
(无头不循环单链表))
4.3.1初阶数据结构(C语言)(无头不循环单链表)
1.完整的单链表注释: #pragma once #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<stdlib.h>typedef int SLTDateType; // 重定义数据类型typedef struct SListNode // 定义结构体类型的节点 {SLTDateType data;str…...

一文深度解读音视频行业技术发展历程
从1948年的香农定律,到音视频的今天。IMMENSE、36氪|作者 北京时间2月28日凌晨,FIFA年度颁奖典礼在巴黎举行。梅西荣膺年度最佳球员,斯卡洛尼当选年度最佳男足主帅,马丁内斯荣获年度最佳男足门将!阿根廷因…...

面向对象拓展贴
1. 类和对象的内存分配机制 1.1 分配机制 Java 内存的结构分析 栈: 一般存放基本数据类型(局部变量)堆: 存放对象(Cat cat , 数组等)方法区:常量池(常量,比如字符串), 类加载信息示意图 [Cat (name, age, price)]…...

Android仿QQ未读消息拖拽粘性效果
效果图原理分析首先是在指定某个位置画一个圆出来,手指按到这个圆的时候再绘制一个可以根据手指位置移动的圆,随着手指的移动两个圆逐渐分离,分离的过程中两圆中间出现连接带,随着两圆圆心距的增大,半径也是根据某一比…...

Linux 打包压缩解压指令 gzip bzip2 tar
总结自鸟哥Linux私房菜 Linux压缩文件的扩展名大多是:“.tar, .tar.gz, .tgz, .gz, .Z, .bz2, *.xz”, 不同压缩文件使用了不同的算法,不能通用压缩或解压 常见扩展名: *.Z compress 程序压缩的文件; *.zip zip 程序…...
系统升级丨分享返佣,助力商企实现低成本高转化营销
秉承助力传统经济数字化转型的长远理念 酷雷曼VR再次在VR全景营销中发力 创新研发“分享返佣”功能 进一步拓宽商企VR全景营销渠道 助力商企搭建低成本、高传播、高转化 的VR营销体系 01、什么是“分享返佣”? ●“分享返佣”即“推广”返佣,是酷…...

机试代码模板
文章目录进制转换高精度加/乘法搜索BFSDFS树二叉树遍历图Dijkstra算法Kruskal算法动态规划最长公共子序列(LCS)最长上升子序列(LIS)KMP算法进制转换 #include <iostream> #include <string> #include <cmath> #include <iomanip> #include <algori…...

Java性能优化-垃圾回收算法-理解CMS回收器
垃圾回收算法 理解 CMS回收器 三个基本操作 1.回收新生代(同时暂停所有的应用线程) 2.运行并发周期来清理老年代数据 3.如果有必要则FULL GC压缩老年代 当发生新生代回收 , 如果老年代没有足够的空间容纳晋升的对象则执行FULL GC,所有线程停…...

Oracle11G的表空间数据文件大小限制问题处理
1.表空间数据文件容量 oracle11g的表空间数据文件容量与DB_BLOCK_SIZE有关,在初始建库时,DB_BLOCK_SIZE要根据实际需要,设置为 4K,8K、16K、32K、64K等几种大小,ORACLE的物理文件最大只允许4194304个数据块(由操作系统…...

计算机三级|网络技术|备考指南|网络系统结构与设计的基本原则|1
一、网络系统结构与设计的基本原则宽带城域网的关键技术p1 p2 p3设计一个宽带城域网涉及“三个平台一个出口”,即网络平台、业务平台、管理平台和城市宽带出口。宽带城域网:宽带城域网划分为三个层次:核心层、汇聚层、接入层。核心层承担高速…...

基于 TI Sitara系列 AM64x核心板——程序自启动说明
前 言 本文主要介绍AM64x的Cortex-A53、Cortex-M4F和Cortex-R5F核心程序自启动使用说明。默认使用AM6442进行测试演示,AM6412测试步骤与之类似。 本说明文档适用开发环境如下: Windows开发环境:Windows 7 64bit、Windows 10 64bit 虚拟机:VMware15.5.5 Linux开发环境:Ubun…...

自学5个月Java找到了9K的工作,我的方式值得大家借鉴 第一部分
我是去年9月22日才正式学习Java的,因为在国营单位工作了4年,在天津一个月工资只有5000块,而且看不到任何晋升的希望,如果想要往上走,那背后就一定要有关系才行。而且国营单位的气氛是你干的多了,领导觉得你…...

微电影广告的内容突破方案
微电影作为新媒体时代背景的产物,深受大众的欢迎,同时,微电影广告在微电影模式环境下应运而生,以自己独特的传播优势,俘获了大量企业主的青睐,也获得了广大青年群体的喜爱。微电影广告欲确保可持续发展&…...

茌平区为什么越来越多的企业由请高新技术企业?山东同邦科技分享
茌平区为什么越来越多的企业由请高新技术企业?山东同邦科技分享 近年来,越来越多的企业开始申报高新技术企业,认定为国家高新技术企业能获得非常多的好处,那么具体都有哪些呢? 一、国际高新技术企业认定的好处: 1、财政补贴: 获得高新企业…...

谷歌优化排名怎么做出来的?谷歌排名多久做上去?
本文主要分享谷歌排名的算法机制,让你很容易地用更短的时间把Google的自然排名做到首页。 本文由光算创作,有可能会被剽窃和修改,我们佛系对待这种行为吧。 谷歌优化排名怎么做出来的? 答案是:持续更新原创优质内容…...

字节跳动青训营--Webpack
文章目录前言一、为什么要学习Webpack?二、什么是Webpack?1. 产生背景2. 基础概念三、使用Webpack1. 安装2. 编辑配置文件3. 执行编译命令核心流程四、如何使用Webpack流程类配置配置总览五、理解Loader六、理解插件插件钩子课外关注资料前言 此文章仅用…...

AI中混淆矩阵及其核心评估指标案例
AI中混淆矩阵及其核心评估指标案例...

UI-TARS-desktop环境部署:Ubuntu+Docker下免配置运行Qwen3-4B多模态Agent
UI-TARS-desktop环境部署:UbuntuDocker下免配置运行Qwen3-4B多模态Agent 想体验一个能看懂屏幕、操作软件、帮你处理日常任务的多模态AI助手吗?今天,我们就来手把手教你,如何在Ubuntu系统上,通过Docker一键部署UI-TAR…...

保姆级教程:用LongCat动物百变秀,快速给猫狗加帽子、换造型
保姆级教程:用LongCat动物百变秀,快速给猫狗加帽子、换造型 1. 为什么选择动物百变秀? 给宠物照片添加创意元素一直是许多人的需求,但传统方法要么需要专业PS技能,要么效果生硬不自然。LongCat动物百变秀解决了这个痛…...

Linux下CMake多版本共存实战:不卸载旧版也能用上新功能
Linux下CMake多版本共存实战:不卸载旧版也能用上新功能 在软件开发的世界里,版本管理就像一场永不停歇的舞蹈。想象一下这样的场景:你正在维护一个历史悠久的C项目,突然客户要求你同时开发一个全新的模块,而这个模块需…...

施密特触发器在智能家居中的7个隐藏用法:从空调变频到漏电保护
施密特触发器在智能家居中的7个隐藏用法:从空调变频到漏电保护 智能家居的普及让我们的生活更加便捷,但背后支撑这些设备的电子技术却鲜为人知。施密特触发器作为一种基础的电子元件,在智能家居系统中扮演着关键角色。它不仅能解决信号抖动问…...
)
我的杭州亲子旅游线路总结(坐船版)
我的杭州亲子旅游线路总结(坐船版) 这是我带娃走过的线路。孩子最近迷恋坐船,我看到新闻说梅花碑有公交船,而且梅花开了很漂亮,就去看看。 这里记录一下行程,说不定以后还去,能做参考。 文中提及…...

BilibiliDown:B站视频下载的完整解决方案
BilibiliDown:B站视频下载的完整解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliDo…...

如何快速访问AO3镜像站:新手必看的5个实用技巧
如何快速访问AO3镜像站:新手必看的5个实用技巧 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site Archive of Our Own(AO3)是全球最大的同人创作平台,但部分地区访问受限。…...

使用Alpine配置WSL ssh门户
1. 哑铃图是什么? 哑铃图(Dumbbell Plot),有时也称为DNA图或杠铃图,是一种用于比较两个相关数据点的可视化图表。 它源于人们对更有效数据比较方式的持续探索。 在传统的时间序列比较中,我们通常使用两条折…...

实战教你用美股api获取实时行情与报价
前几天我在整理投资数据,突然发现自己平时关注的几支热门美股,价格波动比新闻还快。光靠网页刷新完全跟不上节奏,尤其是NVDA、META这样的科技股,几分钟就能有明显变化。想随时看到最新行情,又不想盯着网页刷新…...