【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
- 前言
- GoogLeNet(InceptionV4)讲解
- Stem结构
- Inception-A结构
- Inception- B结构
- Inception-C结构
- Redution-A结构
- Redution-B结构
- GoogLeNet(InceptionV4)模型结构
- GoogLeNet(InceptionV4) Pytorch代码
- 完整代码
- 总结
前言
GoogLeNet(InceptionV4)是由谷歌的Szegedy, Christian等人在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning【AAAI-2017】》【论文地址】一文中提出的改进模型,InceptionV4保留了此前的Inception模块的核心思想基础上进行了改进和优化,InceptionV4的所有模块都采用了统一的设计原则,即采用Inception模块作为基本单元,通过堆叠纯Inception基本单元来实现复杂的网络结构。
因为InceptionV4、Inception-Resnet-v1和Inception-Resnet-v2同出自一篇论文,大部分读者对InceptionV4存在误解,认为它是Inception模块与残差学习的结合,其实InceptionV4没有使用残差学习的思想,它基本延续了Inception v2/v3的结构,只有Inception-Resnet-v1和Inception-Resnet-v2才是Inception模块与残差学习的结合产物。
GoogLeNet(InceptionV4)讲解
InceptionV4的三种基础Inception结构与InceptionV3【参考】中使用的结构基本一样,但InceptionV4引入了一些新的模块形状及其间的连接设计,在网络的早期阶段引入了“Stem”模块,用于快速降低特征图的分辨率,从而减少后续Inception模块的计算量。
Stem结构
stem结构实际上是替代了此前的Inception系列网络中Inception结构组之前的网络层,Stem中借鉴了InceptionV3中使用的并行结构、不对称卷积核结构,并使用1*1的卷积核用来降维和增加非线性,可以在保证信息损失足够小的情况下,使得计算量降低。
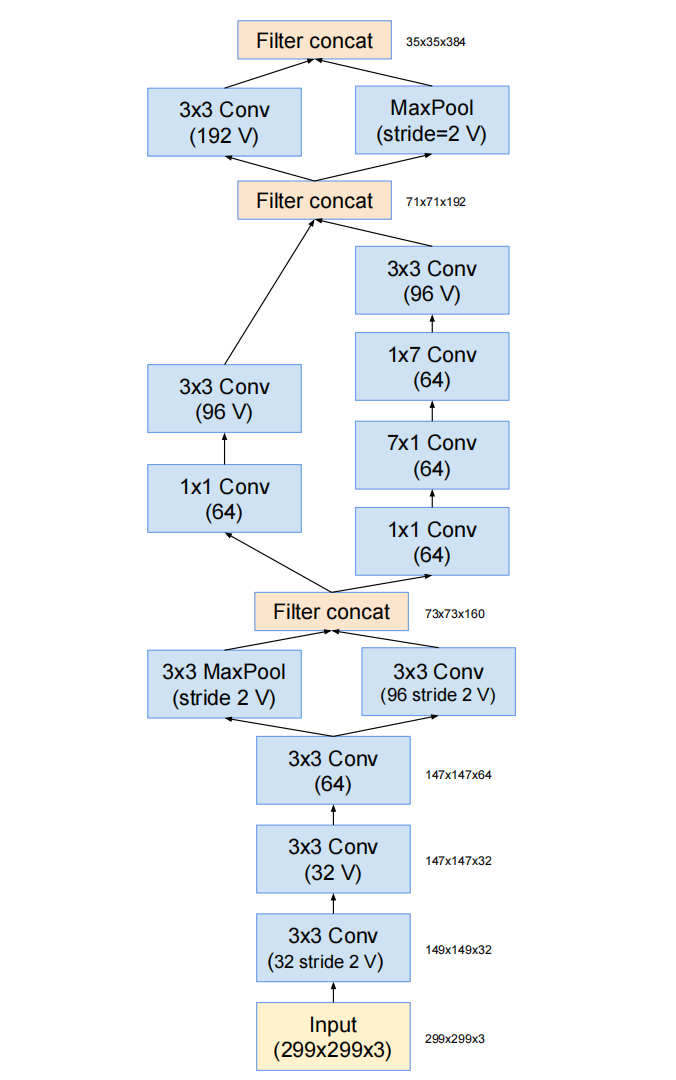
所有卷积中没有标记为V表示填充方式为"SAME Padding",输入和输出维度一致;标记为V表示填充方式为"VALID Padding",输出维度视具体情况而定。
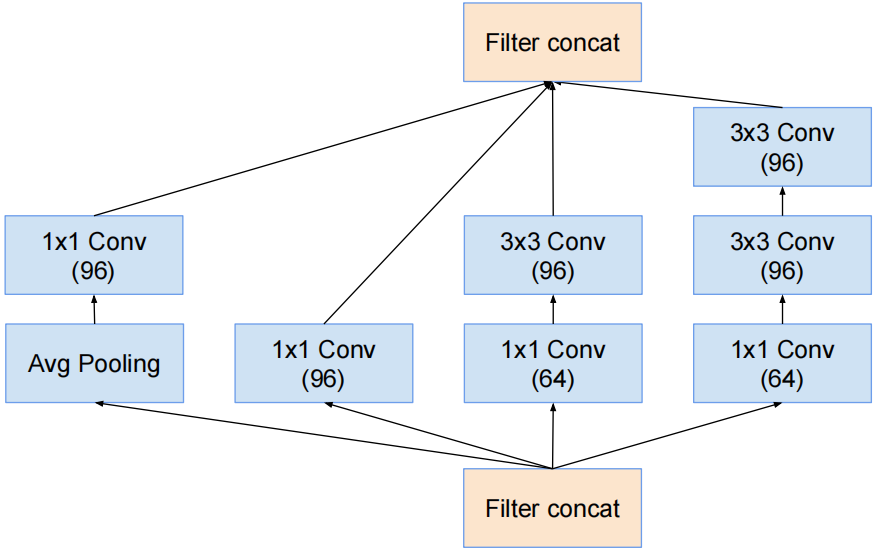
Inception-A结构
对应InceptionV3中的结构Ⅰ。
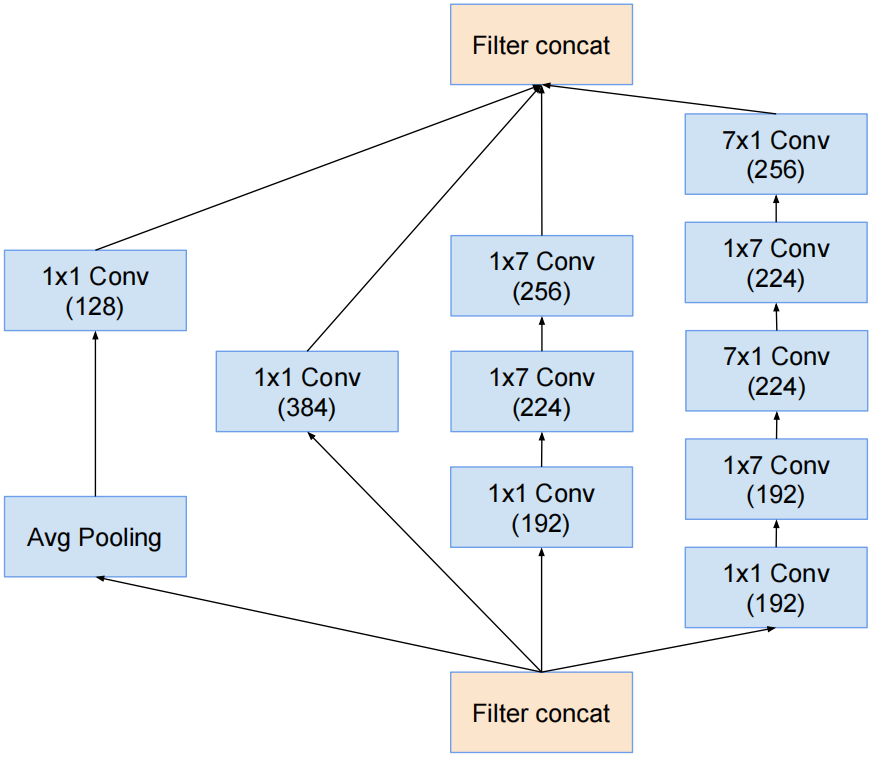
Inception- B结构
对应InceptionV3中的结构Ⅱ,只是1×3卷积和3×1卷积变成了1×7卷积和7×1卷积。
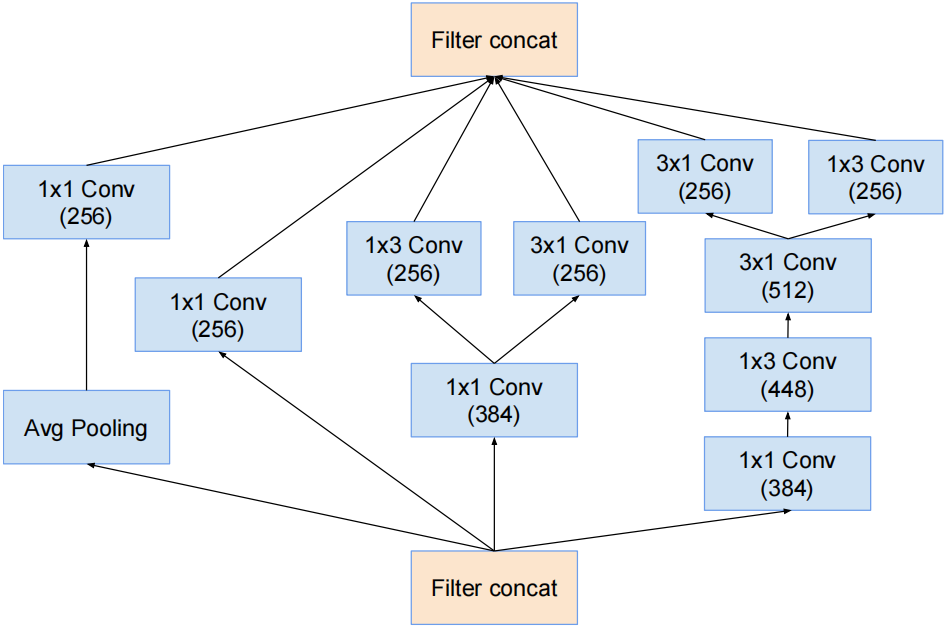
Inception-C结构
对应InceptionV3中的结构Ⅲ,只是3×3卷积变成了1×3卷积和3×1卷积的串联结构。
Redution-A结构
对应InceptionV3中的特殊结构。

k和l表示卷积个数,不同网络结构的redution-A结构k和l是不同的,Inception-ResNet在其他博文【参考】中介绍。

Redution-B结构
采用并行、不对称卷积和1*1的卷积来降低计算量。

GoogLeNet(InceptionV4)模型结构
下图是原论文给出的关于 GoogLeNet(InceptionV4)模型结构的详细示意图:
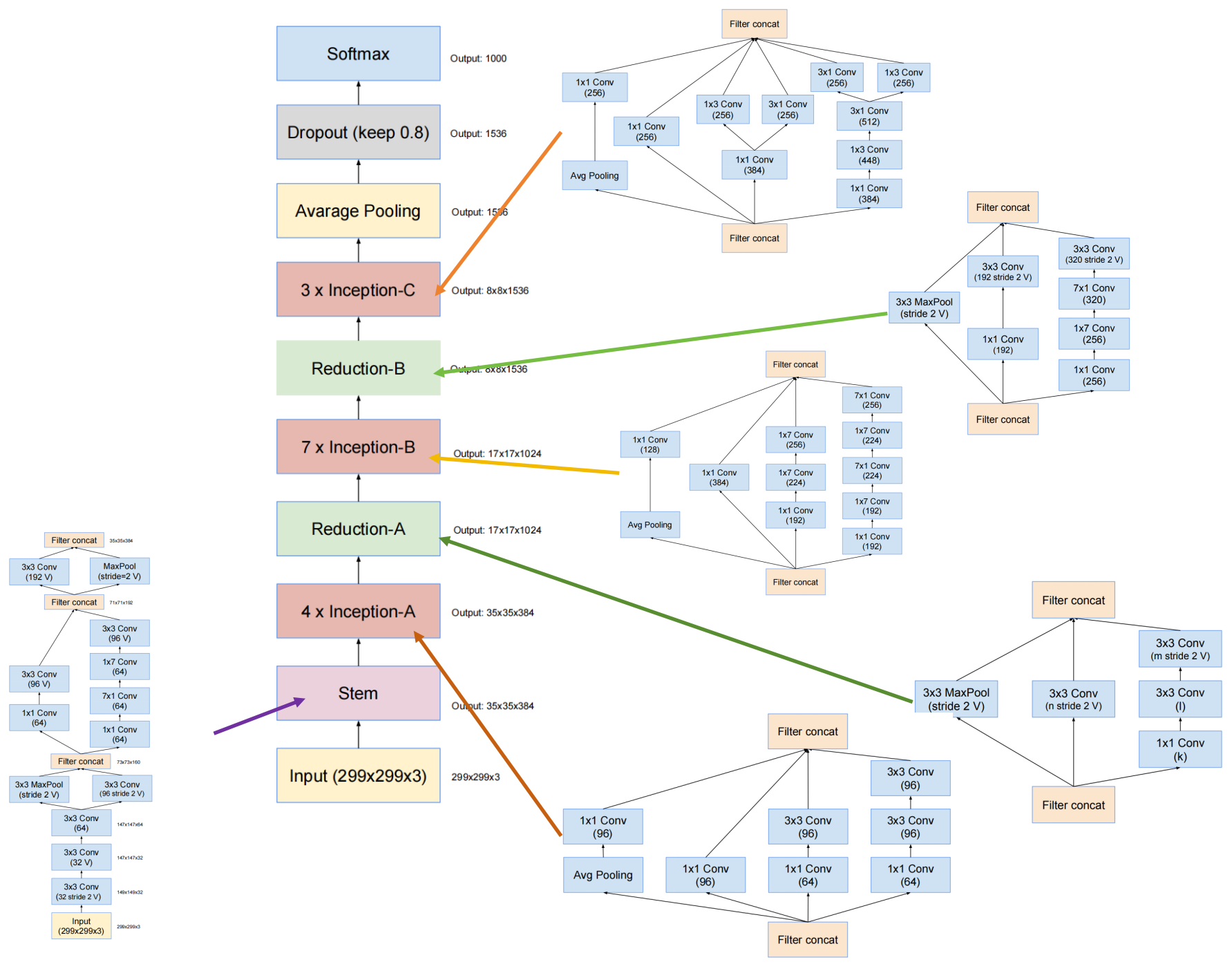
GoogLeNet(InceptionV4)在图像分类中分为两部分:backbone部分: 主要由InceptionV4模块、Stem模块和池化层(汇聚层)组成,分类器部分:由全连接层组成。
InceptionV4三种Inception模块的个数分别为4、7、3个,而InceptionV3中则为3、5、2个,因此InceptionV4的层次更深、结构更复杂,feature map更多。为了降低计算量,在Inception-A和Inception-B后面分别添加了Reduction-A和Reduction-B的结构,用来降低计算量。
GoogLeNet(InceptionV4) Pytorch代码
卷积层组: 卷积层+BN层+激活函数
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return x
Stem模块: 卷积层组+池化层
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):def __init__(self, in_channels):super(Stem, self).__init__()# conv3*3(32 stride2 valid)self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)# conv3*3(32 valid)self.conv2 = BasicConv2d(32, 32, kernel_size=3)# conv3*3(64)self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)# conv1*1(64)+conv3*3(96 valid)self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)# conv3*3(192 valid) & maxpool3*3(stride2 valid)self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)def forward(self, x):x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))x1 = torch.cat([x1_1, x1_2], 1)x2_1 = self.conv5_1_2(self.conv5_1_1(x1))x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(y1))))x2 = torch.cat([x2_1, x2_2], 1)x3_1 = self.conv6(x2)x3_2 = self.maxpool6(x2)x3 = torch.cat([x3_1, x3_2], 1)return x3
Inception-A模块: 卷积层组+池化层
# InceptionV4A:BasicConv2d+MaxPool2d
class InceptionV4A(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):super(InceptionV4A, self).__init__()# conv1*1(96)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(64)+conv3*3(96)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# conv1*1(64)+conv3*3(96)+conv3*3(96)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# avgpool + conv1*1(96)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
Inception-B模块: 卷积层组+池化层
# InceptionV4B:BasicConv2d+MaxPool2d
class InceptionV4B(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3_1, ch3x3_2, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, pool_proj):super(InceptionV4B, self).__init__()# conv1*1(384)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(192)+conv1*7(224)+conv1*7(256)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3_1, ch3x3_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# conv1*1(192)+conv1*7(192)+conv7*1(224)+conv1*7(224)+conv7*1(256)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3redX2, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[7, 1], padding=[3, 0]),BasicConv2d(ch3x3X2_1, ch3x3X2_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# avgpool+conv1*1(128)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
Inception-C模块: 卷积层组+池化层
# InceptionV4C:BasicConv2d+MaxPool2d
class InceptionV4C(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch3x3X2_3,pool_proj):super(InceptionV4C, self).__init__()# conv1*1(256)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(384)+conv1*3(256) & conv3*1(256)self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1)self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1])self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0])# conv1*1(384)+conv1*3(448)+conv3*1(512)+conv3*1(256) & conv7*1(256)self.branch3_0 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[1, 3], padding=[0, 1]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[3, 1], padding=[1, 0]),)self.branch3_1 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[1, 3], padding=[0, 1])self.branch3_2 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[3, 1], padding=[1, 0])# avgpool+conv1*1(256)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2_0 = self.branch2_0(x)branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1)branch3_0 = self.branch3_0(x)branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
redutionA模块: 卷积层组+池化层
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):def __init__(self, in_channels, k, l, m, n):super(redutionA, self).__init__()# conv3*3(n stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, n, kernel_size=3, stride=2),)# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, k, kernel_size=1),BasicConv2d(k, l, kernel_size=3, padding=1),BasicConv2d(l, m, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)
redutionB模块: 卷积层组+池化层
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):def __init__(self, in_channels, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2):super(redutionB, self).__init__()# conv1*1(192)+conv3*3(192 stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2))# conv1*1(256)+conv1*7(256)+conv7*1(320)+conv3*3(320 stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3redX2, kernel_size=(1, 7), padding=(0, 3)),# 保证输出大小等于输入大小BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=(7, 1), padding=(3, 0)),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)
完整代码
GoogLeNet(InceptionV4)的输入图像尺寸是299×299
import torch.nn as nn
import torch
from torchsummary import summaryclass GoogLeNetV4(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(GoogLeNetV4, self).__init__()# stem模块self.stem = Stem(3)# InceptionA模块self.inceptionA = InceptionV4A(384, 96, 64, 96, 64, 96, 96)# RedutionA模块self.RedutionA = redutionA(384, 192, 224, 256, 384)# InceptionB模块self.InceptionB = InceptionV4B(1024, 384, 192, 224, 256, 192, 224,256,128)# RedutionB模块self.RedutionB = redutionB(1024, 192, 192, 256, 320)# InceptionC模块self.InceptionC = InceptionV4C(1536, 256, 384, 256, 384, 448, 512, 256,256)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.8)self.fc = nn.Linear(1536, num_classes)if init_weights:self._initialize_weights()def forward(self, x):# Stem Module# N x 3 x 299 x 299x = self.stem(x)# InceptionA Module * 4# N x 384 x 26 x 26x = self.inceptionA(self.inceptionA(self.inceptionA(self.inceptionA(x))))# ReductionA Module# N x 384 x 26 x 26x = self.RedutionA(x)# InceptionB Module * 7# N x 1024 x 12 x 12x = self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(x)))))))# ReductionB Module# N x 1024 x 12 x 12x = self.RedutionB(x)# InceptionC Module * 3# N x 1536 x 5 x 5x = self.InceptionC(self.InceptionC(self.InceptionC(x)))# Average Pooling# N x 1536 x 5 x 5x = self.avgpool(x)# N x 1536 x 1 x 1x = x.view(x.size(0), -1)# Dropout# N x 1536x = self.dropout(x)# Linear(Softmax)# N x 1536x = self.fc(x)# N x 1000return x# 对模型的权重进行初始化操作def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)# InceptionV4A:BasicConv2d+MaxPool2d
class InceptionV4A(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):super(InceptionV4A, self).__init__()# conv1*1(96)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(64)+conv3*3(96)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# conv1*1(64)+conv3*3(96)+conv3*3(96)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# avgpool+conv1*1(96)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# InceptionV4B:BasicConv2d+MaxPool2d
class InceptionV4B(nn.Module):def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch_redX2, ch_X2_1, ch_X2_2, pool_proj):super(InceptionV4B, self).__init__()# conv1*1(384)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(192)+conv1*7(224)+conv1*7(256)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch_red, kernel_size=1),BasicConv2d(ch_red, ch_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_1, ch_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# conv1*1(192)+conv1*7(192)+conv7*1(224)+conv1*7(224)+conv7*1(256)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch_redX2, kernel_size=1),BasicConv2d(ch_redX2, ch_redX2, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_redX2, ch_X2_1, kernel_size=[7, 1], padding=[3, 0]),BasicConv2d(ch_X2_1, ch_X2_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_X2_1, ch_X2_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# avgpool+conv1*1(128)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# InceptionV4C:BasicConv2d+MaxPool2d
class InceptionV4C(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch3x3X2_3,pool_proj):super(InceptionV4C, self).__init__()# conv1*1(256)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(384)+conv1*3(256) & conv3*1(256)self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1)self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1])self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0])# conv1*1(384)+conv1*3(448)+conv3*1(512)+conv3*1(256) & conv7*1(256)self.branch3_0 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[1, 3], padding=[0, 1]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[3, 1], padding=[1, 0]),)self.branch3_1 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[1, 3], padding=[0, 1])self.branch3_2 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[3, 1], padding=[1, 0])# avgpool+conv1*1(256)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2_0 = self.branch2_0(x)branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1)branch3_0 = self.branch3_0(x)branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):def __init__(self, in_channels, k, l, m, n):super(redutionA, self).__init__()# conv3*3(n stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, n, kernel_size=3, stride=2),)# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, k, kernel_size=1),BasicConv2d(k, l, kernel_size=3, padding=1),BasicConv2d(l, m, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):def __init__(self, in_channels, ch3x3red, ch3x3, ch_redX2, ch_X2):super(redutionB, self).__init__()# conv1*1(192)+conv3*3(192 stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2))# conv1*1(256)+conv1*7(256)+conv7*1(320)+conv3*3(320 stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch_redX2, kernel_size=1),BasicConv2d(ch_redX2, ch_redX2, kernel_size=(1, 7), padding=(0, 3)),# 保证输出大小等于输入大小BasicConv2d(ch_redX2, ch_X2, kernel_size=(7, 1), padding=(3, 0)),BasicConv2d(ch_X2, ch_X2, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):def __init__(self, in_channels):super(Stem, self).__init__()# conv3*3(32 stride2 valid)self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)# conv3*3(32 valid)self.conv2 = BasicConv2d(32, 32, kernel_size=3)# conv3*3(64)self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)# conv1*1(64)+conv3*3(96 valid)self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)# conv3*3(192 valid) & maxpool3*3(stride2 valid)self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)def forward(self, x):x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))x1 = torch.cat([x1_1, x1_2], 1)x2_1 = self.conv5_1_2(self.conv5_1_1(x1))x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(x1))))x2 = torch.cat([x2_1, x2_2], 1)x3_1 = self.conv6(x2)x3_2 = self.maxpool6(x2)x3 = torch.cat([x3_1, x3_2], 1)return x3# 卷积组: Conv2d+BN+ReLU
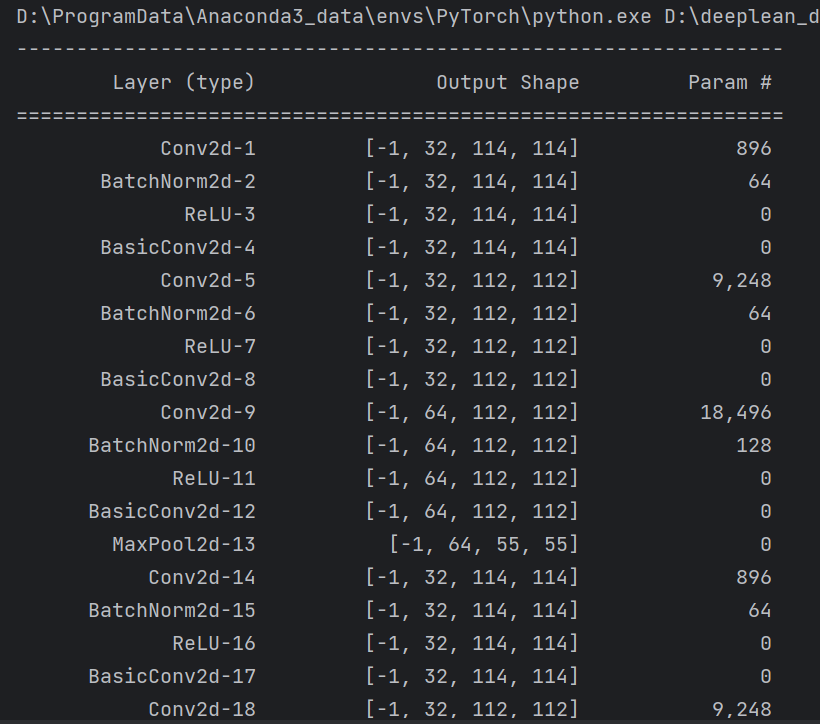
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return xif __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = GoogLeNetV4().to(device)summary(model, input_size=(3, 229, 229))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了InceptionV4的改进方案,讲解了GoogLeNet(InceptionV4)模型的结构和pytorch代码。
相关文章:
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解 文章目录 【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解前言GoogLeNet(InceptionV4)讲解Stem结构Inception-A结构Inception- B结构Inception-C结构Redution-A结构Re…...

opencv dots_image_kernel
1,opencv dots_image_kernel // halcon dots_image kernel估算(d5) cv::Mat getDotKernel(int d 5){// 保证d为正的奇数d | 0x01;cv::Mat kernel cv::Mat::zeros(d 2, d 2, CV_8UC1);int cx kernel.cols / 2;int cy kernel.rows / 2;int cnt255 0, cnt128 …...
使用pytorch利用神经网络原理进行图片的训练(持续学习中....)
1.做这件事的目的 语言只是工具,使用python训练图片数据,最终会得到.pth的训练文件,java有使用这个文件进行图片识别的工具,顺便整合,我觉得Neo4J正确率太低了,草莓都能识别成为苹果,而且速度慢,不能持续识别视频帧 2.什么是神经网络?(其实就是数学的排列组合最终得到统计结果…...

2023年中国合成云母行业现状及市场格局分析[图]
合成云母是一种通过化工原料经高温熔融冷却析晶而制得的单斜晶系矿物,属于典型的层状硅酸盐,许多性能都优于天然云母,如合成云母的耐温高达1200℃以上,而天然白云母在550℃下就会开始分解,金云母则在800℃开始分解。除…...

Vue3+Vite实现工程化,插值表达式和v-text以及v-html
1、插值表达式 插值表达式最基本的数据绑定形式是文本插值,它使用的是"Mustache"语法,即 双大括号{{}} 插值表达式是将数据 渲染 到元素的指定位置的手段之一插值表达式 不绝对依赖标签,其位置相对自由插值表达式中支持javascript的…...

艾泊宇产品战略:灵感于鬼屋,掌握打造卓越用户体验的关键要素
在当今的商业环境中,用户体验已经成为产品成功的关键因素。 无论是线上产品还是实体产品,用户体验都是决定用户是否愿意使用和推荐该产品的关键因素。 那么,艾泊宇产品战略理论告诉大家,如何做好用户体验? 我们可以…...
深度学习环境配置(Anaconda+pytorch+pycharm+cuda)
NVIDIA驱动安装 首先查看电脑的显卡版本,步骤为:此电脑右击-->管理-->设备管理器-->显示适配器。就可以看到电脑显卡的版本了。 然后按照电脑信息,到地址 去安装相应的驱动,Notebooks是笔记本的意思,然后下…...
不是说人工智能是风口吗,那为什么工作还那么难找?
最近确实有很多媒体、机构渲染人工智能可以拿高薪,这在行业内也是事实,但前提是你有足够的竞争力,真的懂人工智能。 首先,人工智能岗位技能要求高,人工智能是一个涵盖了多个学科领域的综合性学科,包括数学、…...
 发生了什么)
new Vue() 发生了什么
前言: 在Vue.js中,当你创建一个新的Vue实例时,通过 new Vue() 发生了一系列重要的操作,包括Vue实例的初始化、数据绑定、模板编译等。这个过程是Vue应用的核心,本文将深入探讨new Vue()发生了什么以及其原理,提供示例…...

【算法】二叉树的存储与遍历模板
二叉树的存储与遍历 const int N 1e6 10;// 二叉树的存储,l数组为左节点,r数组为右结点 int l[N], r[N]; // 存储节点的数据 char w[N]; // 节点的下标指针 int idx 0;// 先序创建 int pre_create(int n) {cin >> w[n];if (w[n] #) return -1;l[n] pre_create(idx)…...
【Go学习之 go mod】gomod小白入门,在github上发布自己的项目(项目初始化、项目发布、项目版本升级等)
参考 Go语言基础之包 | 李文周的博客Go mod的使用、发布、升级 | weiGo Module如何发布v2及以上版本1.2.7. go mod命令 — 新溪-gordon V1.7.9 文档golang go 包管理工具 go mod的详细介绍-腾讯云开发者社区-腾讯云Go Mod 常见错误的原因 | walker的博客 项目案例 oceanweav…...
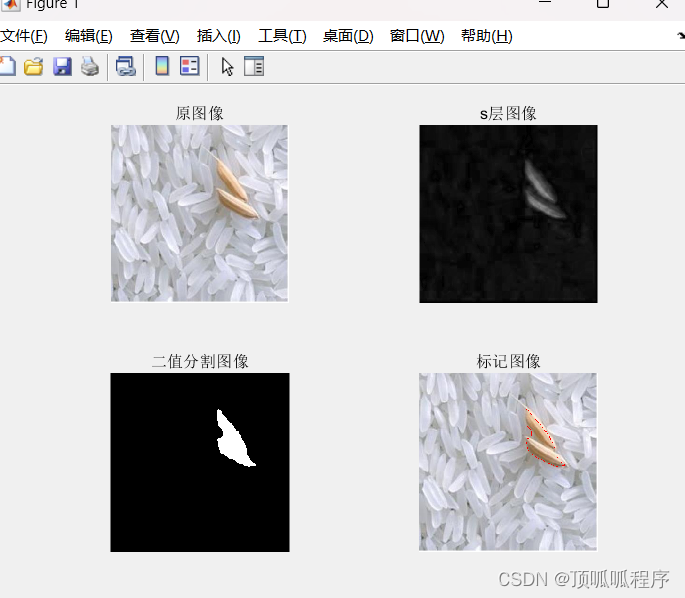
79基于matlab的大米粒中杂质识别
基于matlab的大米粒中杂质识别,数据可更换自己的,程序已调通,可直接运行。 79matlab图像处理杂质识别 (xiaohongshu.com)...

Vue 项目实战——如何在页面中展示 PDF 文件以及 PDFObject 插件实战
文章目录 📋前言🎯使用 HTML 标签🧩 embed 标签🧩 object标签🧩 iframe标签🧩完整代码 🎯使用 PDFObject 插件🧩为什么使用 PDFObject 插件(AI翻译)…...
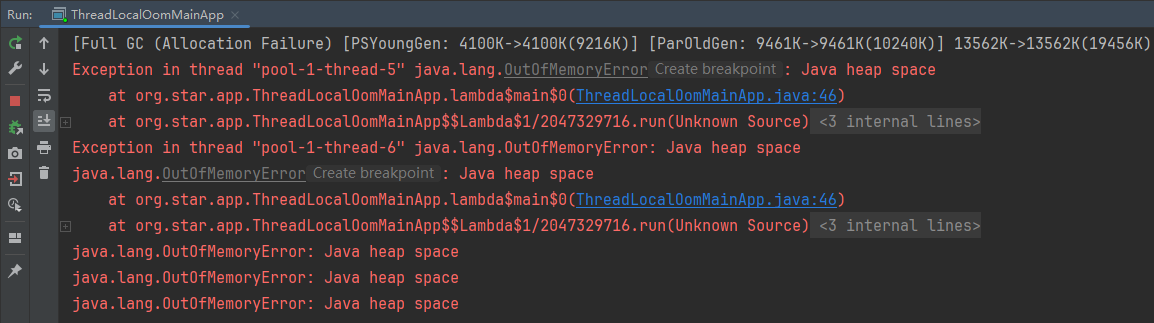
系列六、ThreadLocal内存泄露案例
一、ThreadLocal内存泄露案例 /*** Author : 一叶浮萍归大海* Date: 2023/11/22 10:56* Description: 写一段代码导致内存泄露* VM Options:-Xms20m -Xmx20m -Xmn10m -XX:PrintGCDetails* 说明:内存泄露最终会导致内存溢出*/ public class ThreadLocalO…...

Java学习笔记44——Stream流
Stream流 体验Stream流Stream流的生成方式ColLection体系的集合可以使用默认方法stream ()生成流Map体系的集合间接的生成流数组可以通过stream接口的静态方法of (T... values)生成流 Stream流的中间操作方法Stream<T> filter(Predicate predicate)Stream<T>limit(…...

excel表格忘记密码,如何找回?
找回和去除Excel表格密码的方法非常简单。具体步骤如下:第一步百度搜索【 密码帝官网 】,第二步点击“立即开始”在用户中心上传文件即可。这个方法既安全又简单,不需要下载任何软件,而且可以在手机和电脑上都使用。密码帝官网支持…...
 -Mybatis初识和框架搭建)
IDEA版SSM入门到实战(Maven+MyBatis+Spring+SpringMVC) -Mybatis初识和框架搭建
第一章 初识Mybatis 1.1 框架概述 生活中“框架” 买房子笔记本电脑 程序中框架【代码半成品】 Mybatis框架:持久化层框架【dao层】SpringMVC框架:控制层框架【Servlet层】Spring框架:全能… 1.2 Mybatis简介 Mybatis是一个半自动化持久化…...

差分放大器工作原理(差分放大器和功率放大器区别)
差分放大器是一种特殊的放大器,它可以将两个输入信号的差异放大输出。其工作原理基于差分放大器的电路结构和差分输入特性。 一、差分放大器电路结构 差分放大器一般由四个基本电路组成:正反馈网络、反相输入端、共模抑制电路和差分输入端。其中…...

SystemV
a...
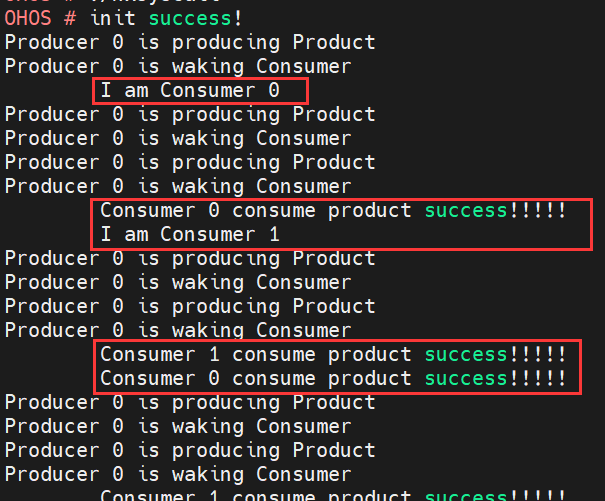
LiteOS同步实验(实现生产者-消费者问题)
效果如下图: 给大家解释一下上述效果:在左侧(顶格)的是生产者(Producer);在右侧(空格)的是消费者(Consumer)。生产者有1个,代号为“0”…...

【软考高级架构】案例题考前突击13:SAAM / ATAM / CBAM
一、SAAM 架构情景分析法 1. 场景开发:与系统相关风险承担者共同协商,开发一组任务场景。 2. 架构描述:对系统架构进行正式描述,包含计算构件、数据构件及构件间交互关系。 3. 单个场景评估:逐一评估每个场景,判断架构对直接场景、间接场景的支持程度。 4. 场景交互:…...

LuaDec51 终极实战:三步解密 Lua 5.1 字节码的完整指南
LuaDec51 终极实战:三步解密 Lua 5.1 字节码的完整指南 【免费下载链接】luadec51 Lua Decompiler for Lua version 5.1 项目地址: https://gitcode.com/gh_mirrors/lu/luadec51 当我们面对一个被编译成字节码的 Lua 5.1 文件时,就像拿到了一本加…...

LuaDec51 终极指南:如何高效反编译 Lua 5.1 字节码的完整解决方案
LuaDec51 终极指南:如何高效反编译 Lua 5.1 字节码的完整解决方案 【免费下载链接】luadec51 Lua Decompiler for Lua version 5.1 项目地址: https://gitcode.com/gh_mirrors/lu/luadec51 LuaDec51 是一款专注于 Lua 5.1 版本的专业反编译工具,能…...

VScode安装后,如果修改中文版本? 坑是啥?
1 就是安装后,按照网上方法没有中文版本出来。结果测试好几次都不行,,,坑货啊。重新卸载插件后,重新安装,提示就有了。改变语言并且重启。才成功了。搞了半小时才出来, 为了这个。...
:2024年起,未完成Stage-3认证者将丧失行业发声权)
技术影响力断层危机(AISMM预警报告):2024年起,未完成Stage-3认证者将丧失行业发声权
更多请点击: https://intelliparadigm.com 第一章:技术影响力断层危机(AISMM预警报告):2024年起,未完成Stage-3认证者将丧失行业发声权 什么是AISMM Stage-3认证 AISMM(AI-Savvy Maturity Mod…...
,以更小代价捕获全局上下文)
ConvNeXt 系列改进:引入 SMFA(稀疏多尺度频域注意力),以更小代价捕获全局上下文
摘要:在卷积网络(CNN)与视觉 Transformer(ViT)持续博弈的今天,ConvNeXt 作为纯卷积架构的标杆,虽已证明了“无 Attention 也能打”的硬实力,但其在全局上下文建模与纹理细节捕获方面的隐性短板始终存在。本文将深入探讨近三个月内 CV 社区的前沿热点——在 ConvNeXt 架…...

Showdown.js 实战指南:掌握双向 Markdown 转换的 5 大核心技巧
Showdown.js 实战指南:掌握双向 Markdown 转换的 5 大核心技巧 【免费下载链接】showdown A bidirectional Markdown to HTML to Markdown converter written in Javascript 项目地址: https://gitcode.com/gh_mirrors/sh/showdown Showdown.js 是一款强大的…...

终极游戏光标增强工具:如何让你的鼠标指针在游戏中清晰可见
终极游戏光标增强工具:如何让你的鼠标指针在游戏中清晰可见 【免费下载链接】YoloMouse Game Cursor Changer 项目地址: https://gitcode.com/gh_mirrors/yo/YoloMouse 你是否曾在激烈的游戏对战中因为鼠标光标太小而迷失方向?是否因为光标颜色与…...

linux server中搭建questasim 10.6c ise14.7
1:背景:公司是公用的服务器,这个服务器里面需要额外的shell打开ise。老的项目维护是ise14.7,需要仿真2:在linux下找到ise的目录,Xilinx\14.7\ISE_DS\ISE\bin\nt64\compxlibgui (花了好些时间&am…...

5分钟快速解锁Steam游戏:Onekey智能配置工具完全指南
5分钟快速解锁Steam游戏:Onekey智能配置工具完全指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为Steam游戏解锁的复杂配置而烦恼吗?想要轻松获取游戏DLC内容却…...