InfoNCE Loss公式及源码理解
InfoNCE Loss公式及源码理解–从交叉熵损失谈起
当谈论到信息论中的损失函数时,InfoNCE(Noise Contrastive Estimation)和交叉熵损失都是两个关键的概念。它们不仅在衡量概率分布之间的差异方面发挥着重要作用,而且在深度学习的自监督学习领域扮演着重要角色。虽然它们的形式和应用环境有所不同,但是我们可以发现它们之间存在着微妙的联系。
交叉熵损失作为衡量两个概率分布之间距离的指标,在分类任务和神经网络训练中广泛使用。而InfoNCE Loss,则是针对自监督学习任务中特征学习的一种损失函数。它通过比较正样本和负样本的相似性来学习模型参数,从而提高特征的区分度。
在这篇博客中,我们将深入探讨交叉熵损失和InfoNCE之间的联系,探究它们在信息论和深度学习中的联系与异同。我们将分析两者的数学形式、应用领域以及它们之间可能的内在关系,以期对这两个重要概念有更深入的理解。
InfoNCE
InfoNCE Loss(Noise Contrastive Estimation Loss)是一种用于自监督学习的损失函数,通常用于学习特征表示或者表征学习。它基于信息论的思想,通过对比正样本和负样本的相似性来学习模型参数。
公式介绍
InfoNCE Loss的公式如下:
InfoNCE Loss = − 1 N ∑ i = 1 N log ( exp ( q i ⋅ k i + τ ) ∑ j = 1 N exp ( q i ⋅ k j − τ ) ) \text{InfoNCE Loss} = -\frac{1}{N} \sum_{i=1}^{N} \log \left( \frac{\exp \left( \frac{q_i \cdot k_{i^+}}{\tau} \right)}{\sum_{j=1}^{N} \exp \left( \frac{q_i \cdot k_{j^-}}{\tau} \right)} \right) InfoNCE Loss=−N1i=1∑Nlog ∑j=1Nexp(τqi⋅kj−)exp(τqi⋅ki+)
其中:
- N N N是样本的数量
- q i q_i qi是查询样本 i i i的编码向量
- k i + k_{i+} ki+是与查询样本 i i i相对应的正样本的编码向量
- k i − k_{i-} ki−是与查询样本 i i i不对应的负样本的编码向量
- τ \tau τ是温度系数,用于调节相似度得分的分布,后面会详细讨论
算法思想
从INfoNCE的公式中我们可以发现,分子只包含一对正样本,分母则包含一个batch下的 N N N个所有样本,即1个与 q i q_i qi对应的正样本和 ( N − 1 ) (N-1) (N−1)个负样本,那么上述公式我们也可以简化为下述形式:
InfoNCE Loss = − 1 N ∑ i = 1 N log A + A + + B − \text{InfoNCE Loss} = -\frac{1}{N} \sum_{i=1}^{N} \log\frac{A_+}{A_++B_-} InfoNCE Loss=−N1i=1∑NlogA++B−A+
首先,分式部分一定是介于(0,1)之间的,而log在(0,1)之间是单增的且函数值小于0
在损失优化过程中,我们希望达成的结果是 A + A_+ A+尽可能大,也就是正样本之间的距离尽可能尽,其实也隐含着与负样本之间的相似度尽可能低,距离尽可能远。从公式上来看,我们在最小化loss的过程中,需要让公式接近0,也就是让log内部的分式接近1,要达到这个效果,应该使 A > > B A>>B A>>B,可以发现跟我们的训练思路是吻合的,这就达到了对于查询向量而言,推近它和正样本之间的距离,拉远它和负样本的距离
写到这里,基本上把InfoNCE的公式以及公式背后的主要思想讲清楚了,下面就要说Cross Entropy Loss跟它的关系了,其实主要还是InfoNCELoss代码是基于交叉熵损失实现的,看不明白交叉熵损失的代码逻辑也看不懂InfoNCELoss了
Cross Entropy Loss
交叉熵损失是衡量两个概率分布之间差异的一种指标。在分类问题中,我们通常有一个真实的概率分布 P P P(通常是一个独热编码向量,代表了样本的真实标签分布),和一个模型预测的概率分布 Q Q Q。交叉熵损失用于衡量这两个概率分布之间的差异。
其数学公式为:
CrossEntropy ( P , Q ) = − ∑ i P ( i ) ⋅ log ( Q ( i ) ) \text{CrossEntropy}(P, Q) = - \sum_i P(i) \cdot \log(Q(i)) CrossEntropy(P,Q)=−i∑P(i)⋅log(Q(i))
- P ( i ) P(i) P(i) 是真实标签的概率分布,代表了样本属于类别 i i i的概率
- Q ( i ) Q(i) Q(i)是模型预测的概率分布,代表了模型对样本属于类别 i i i的预测概率
- l o g log log 是自然对数函数。
交叉熵损失的含义和主要思想是在真实分布和模型预测分布之间衡量误差。当模型的预测与真实情况相符时,交叉熵损失会趋近于0。换句话说,交叉熵损失函数的优化目标是使得模型的预测概率分布尽可能地接近真实标签的概率分布,以最小化误差。
在深度学习中,交叉熵损失通常用作分类任务中的损失函数,在训练过程中用来衡量模型预测与真实标签之间的差异,并通过反向传播来优化模型参数。
结合上述解释,下面来看一下交叉熵损失的代码
'''创建原始数据样例
x:3row x 4col的张量,表示数据中包含三条数据,每条数据预测四个类别
y:3d张量,与三条数据对应;每个元素属于0-3,与四个类别对应'''# 1.创建原始数据
x=torch.rand((3,4))
y=torch.tensor([3,0,2])# 2.计算x_sfm=softmax(x),求出归一化后的每个类别概率值
softmax_func=nn.Softmax()
x_sfm=softmax_func(x)# 3.计算log(x_sfm),由于原来的概率值位于0-1,取对数后一定是负值
# 概率值越大,取对数后的绝对值越小,符合我们的损失目标
x_log=torch.log(x_sfm)# ls = nn.LogSoftmax(dim=1)# 也可以使用nn.LogSoftmax()进行测试,二者结果一致
# print(ls(x))# 4.最后使用nn.NLLLoss求损失
# 思路,按照交叉熵的计算过程,将真值与经过LogSoftmax后的预测值求和取平均
index=range(len(x))
loss=x_log[index,y]
print(abs(sum(loss)/len(x)))
从代码中可以很好理解交叉熵如何发挥作用,并且也能理解交叉熵的真值标签为啥只是一维张量
InfoNCE loss 代码
import torch
import torch.nn.functional as Fdef approx_infoNCE_loss(q, k):# 计算query和key的相似度得分similarity_scores = torch.matmul(q, k.t()) # 矩阵乘法计算相似度得分# 计算相似度得分的温度参数temperature = 0.07# 计算logitslogits = similarity_scores / temperature# 构建labels(假设有N个样本)N = q.size(0)labels = torch.arange(N).to(logits.device)# 计算交叉熵损失loss = F.cross_entropy(logits, labels)return loss相关文章:

InfoNCE Loss公式及源码理解
InfoNCE Loss公式及源码理解–从交叉熵损失谈起 当谈论到信息论中的损失函数时,InfoNCE(Noise Contrastive Estimation)和交叉熵损失都是两个关键的概念。它们不仅在衡量概率分布之间的差异方面发挥着重要作用,而且在深度学习的自…...

经典双指针算法试题(二)
📘北尘_:个人主页 🌎个人专栏:《Linux操作系统》《经典算法试题 》《C》 《数据结构与算法》 ☀️走在路上,不忘来时的初心 文章目录 一、有效三角形的个数1、题目讲解2、讲解算法原理3、代码实现 二、查找总价格为目标值的两个商…...

MySQL -- DQL
1、select查询列和列名: --查询所有员工信息(*通配符,默认查询所有的列) select * from emp;--查询员工的姓名 select ename from emp;--查询员工的薪资 select sal from emp;--查询员工的姓名和薪资 select ename , sal from emp; select ename sal fr…...

高防CDN:保障网络安全的未来之路
在当前数字化飞速发展的时代,网络安全问题日益成为企业和个人关注的焦点。高防CDN(Content Delivery Network,内容分发网络)作为一种专注于防御网络攻击的解决方案,尽管在技术上表现卓越,但其普及却面临一系…...
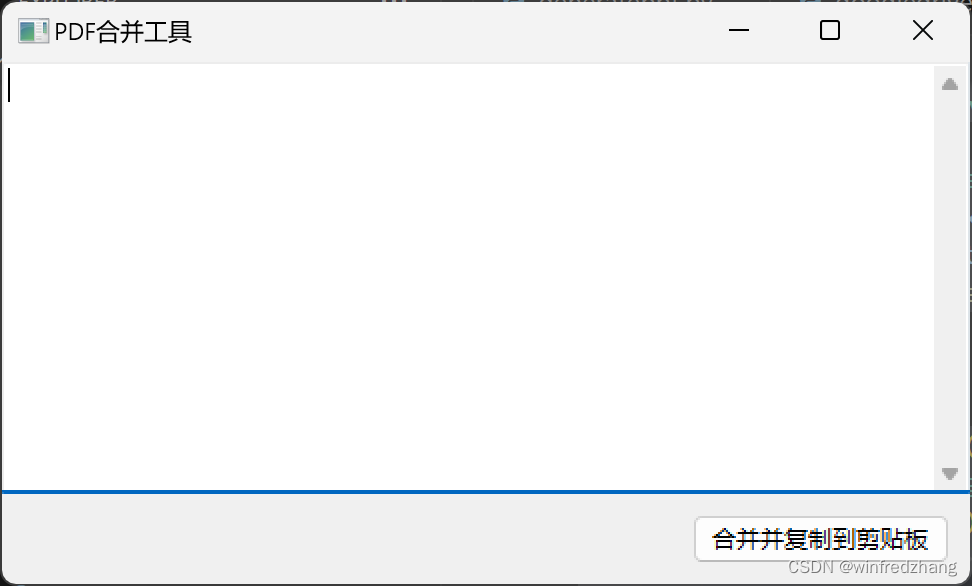
使用wxPython和PyMuPDF合并PDF文档并自动复制到剪贴板
导语:处理大量的PDF文档可能会变得复杂和耗时。但是,使用Python编程和一些强大的库,如wxPython和PyMuPDF,可以使这个任务变得简单而高效。本文将详细解释一个示例代码,展示如何使用这些库来创建一个可以选择文件夹中的…...

Redis篇---第十四篇
系列文章目录 文章目录 系列文章目录前言一、为什么Redis的操作是原子性的,怎么保证原子性的?二、了解Redis的事务吗?四、Redis 的数据类型及使用场景前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男…...

python之文件操作
文件的读取、修改、写入 知识点:不可以使用for循环生成变量,替代方式:将每次循环生成的数据添加到列表中,再对列表进行操作 例子:根据输入的环境名称操作hosts文件,注释掉其他环境 #env1 127.0.0.1 127.0.…...

android实时投屏软件QtScrcpy
QtScrcpy 可以通过 USB / 网络连接Android设备,并进行显示和控制。无需root权限。 同时支持 GNU/Linux ,Windows 和 MacOS 三大主流桌面平台。 QtScrcpy: Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制…...
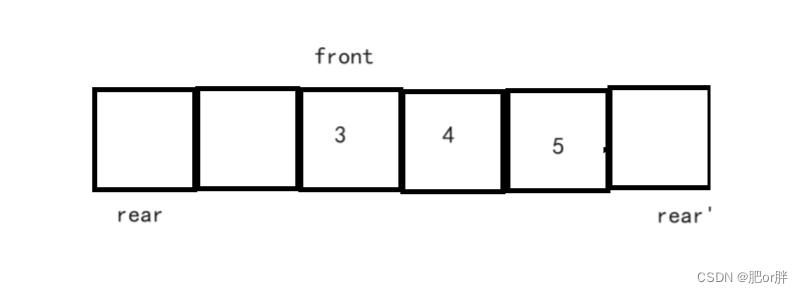
LeetCode - 622. 设计循环队列(C语言,顺序存储结构,配图)
目录 编辑定义结构体: 1. MyCircularQueue(k): 构造器,设置队列长度为 k 2. Front: 从队首获取元素。如果队列为空,返回 -1 3. Rear: 获取队尾元素。如果队列为空,返回 -1 4. enQueue(value): 向循环队列插入一个元素。…...

在 Qt 框架中,有许多内置的信号可用于不同的类和对象\triggered
在 Qt 框架中,有许多内置的信号可用于不同的类和对象 以下是一些常见的内置信号的示例: clicked():按钮(QPushButton、QToolButton 等)被点击时触发的信号。 pressed() 和 released():按钮被按下和释放时…...
springBoot中starter
springBoot项目中引入starter 项目引入xxljob,仅需要导入对应的starter包,即可进行快速开发 <dependency><groupId>com.ydl</groupId><artifactId>xxl-job-spring-boot-starter</artifactId><version>0.0.1-SNAPS…...
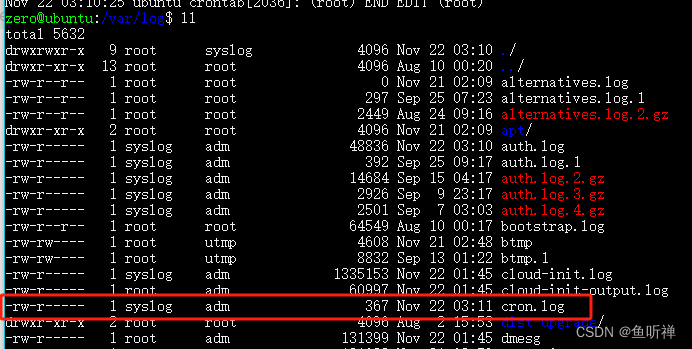
Linux学习笔记-Ubuntu下使用Crontab设置定时任务
文章目录 一、概述二、基于crontab的设置2.1 基本命令说明2.2 使用-e指令编辑命令2.2.1 进入编辑模式2.2.2 指令信息格式2.2.4 开启日志1) 修改rsyslog配置文件2) 重启rsyslog3) 查看日志 2.2.3 设置后之后重启服务 三、示例3.1 每隔一分钟往文件中日期3.2 使用-l查看任务列表3…...
 java 实现)
动态规划求数组中相邻两数的最小差值( 即相差的绝对值 ) java 实现
算法的核心是:计算当前数和前一个数的差值,用该差值和以前最小的连续数的差值作比较;如果当前的差值更小,则发现了更小的连续数的差值;如果当前的差值更大,则沿用以前的最小连续数差值作为新的最小连续数差值。 MinDif…...
webGL开发微信小游戏
WebGL 是一种用于在浏览器中渲染 2D 和 3D 图形的 JavaScript API。微信小游戏本质上是在微信环境中运行的基于 Web 技术的应用,因此你可以使用 WebGL 来开发小游戏。以下是基于 WebGL 开发微信小游戏的一般步骤,希望对大家有所帮助。北京木奇移动技术有…...

leetcode面试经典150题——29 三数之和
题目:盛最多水的容器 描述: 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意…...
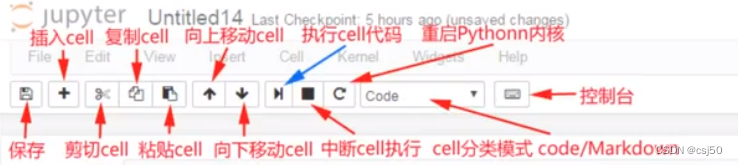
数据分析基础之《jupyter notebook工具》
一、安装库 1、linux库 yum install python3-devel 2、python库 pip3 install -U matplotlib pip3 install -U numpy pip3 install -U pandas pip3 install -U TA-Lib pip3 install -U tables pip3 install -U notebook 3、如果TA-Lib安装不上,先手动安装依赖库 …...
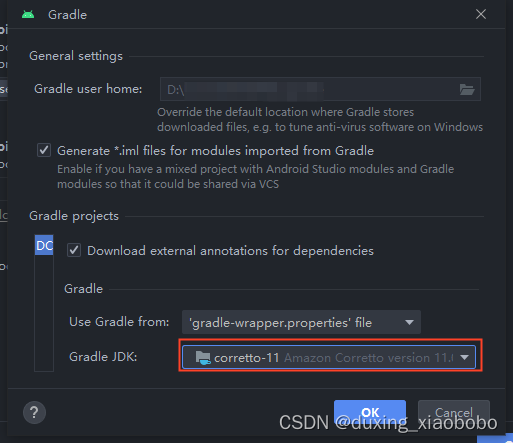
Android Studio Error “Unsupported class file major version 61“---异常信息记录
编译时异常信息 原因及解决办法 问题出在JAVA 17上,并且使用的Gradle JDK是:Android Studio java home版本17.0.1将其更改为:Android Studio默认JDK版本11.0.10 即可解决 操作步骤 1 2 3...
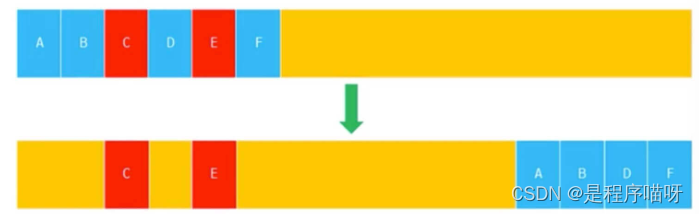
javaScript 内存管理
1 js 内存机制 内存空间:栈内存(stack)、堆内存(heap) 栈内存:所有原始数据类型都存储在栈内存中,如果删除一个栈原始数据,遵循先进后出;如下图:a 最先进栈&…...
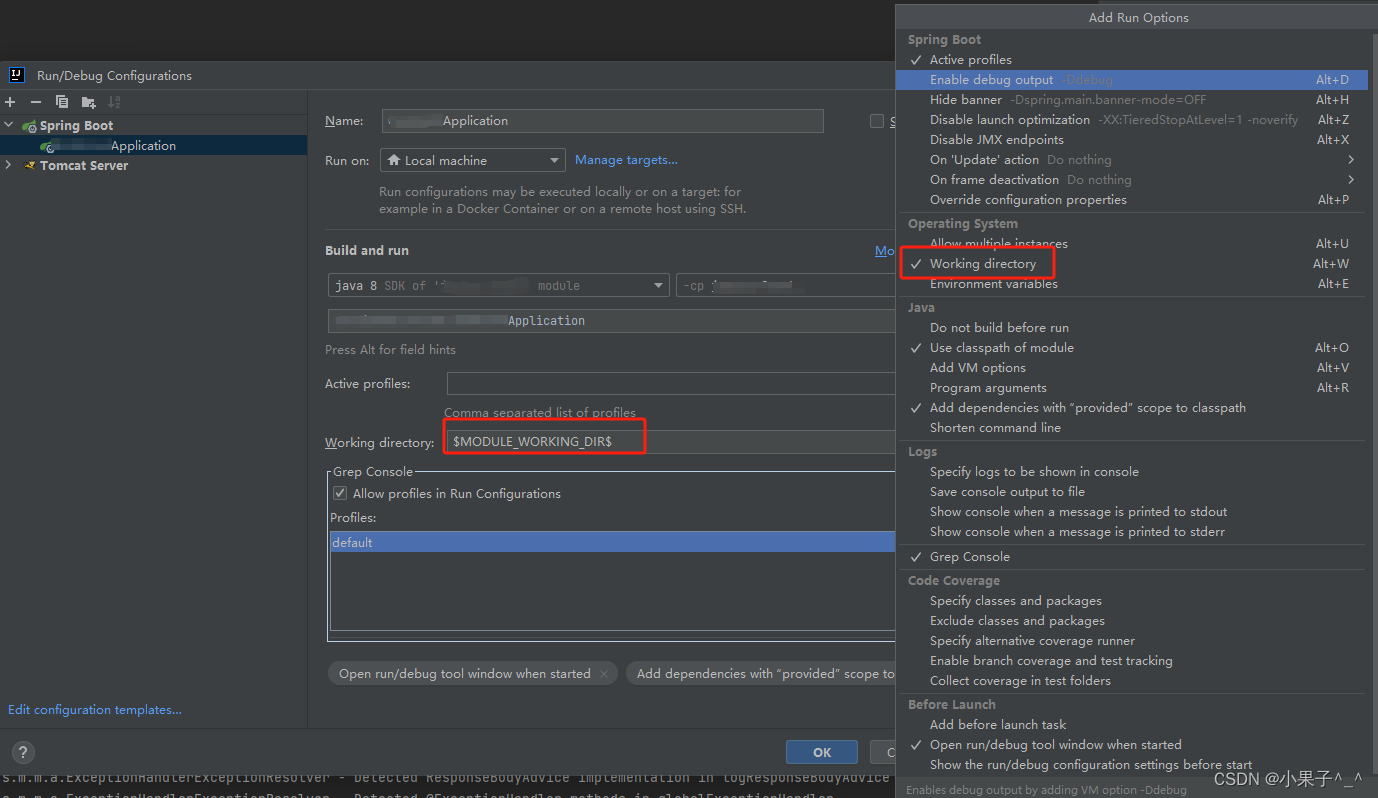
Idea2023 Springboot web项目正常启动,页面展示404解决办法
Idea2023 Springboot web项目正常启动,页面展示404解决办法 问题: 项目启动成功,但是访问网页,提示一直提示重定向次数过多,404 解决方法 在IDEA的Run/Debug Configurations窗口下当前的Application模块的Working directory中添…...
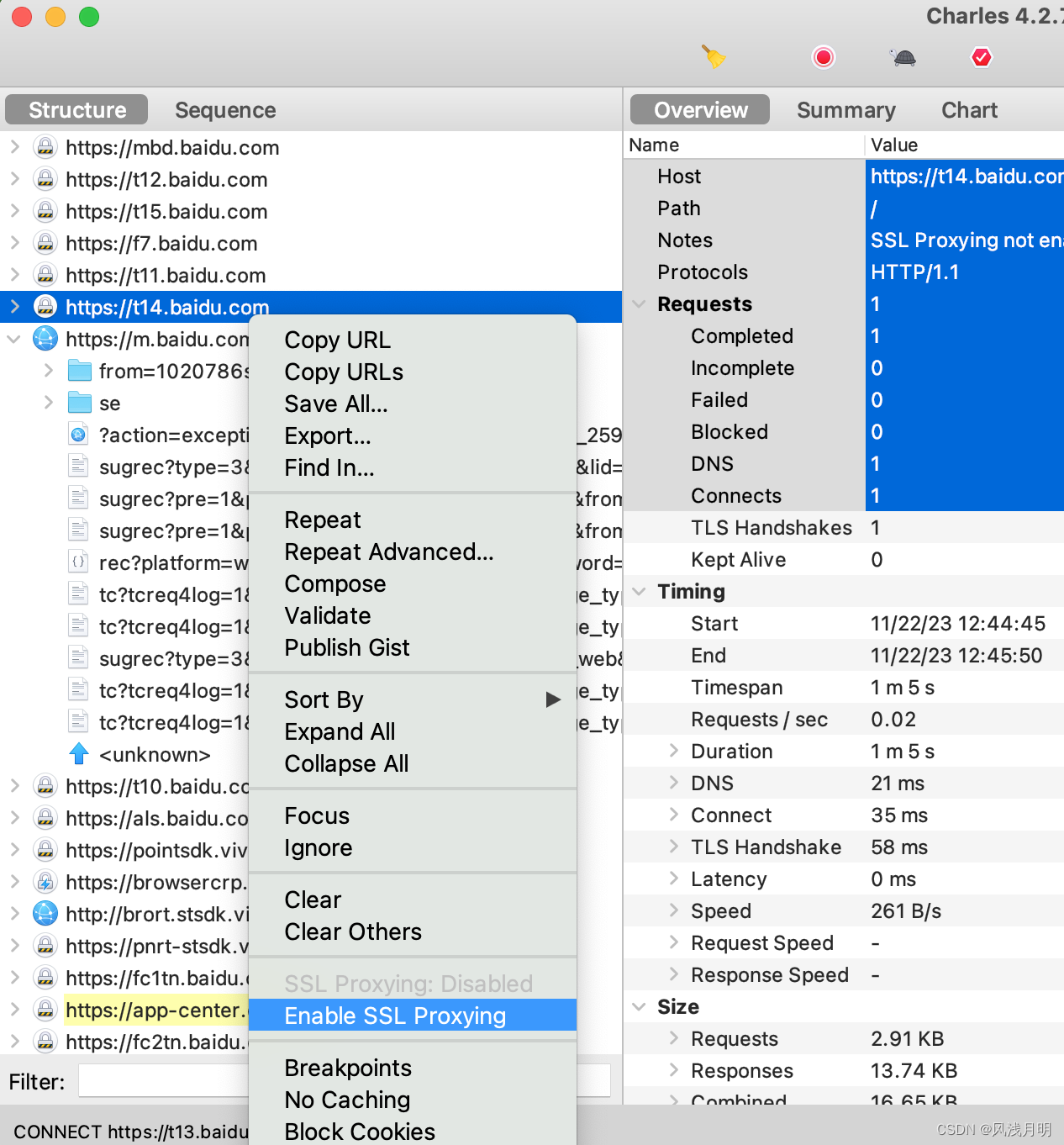
Android手机如何用Charles抓包HTTPS接口
对Charles的安装和使用,这里就不重复介绍了,之前有介绍Charles工具。 本文重点介绍在Android手机上如何配置抓包环境 1.获取Charles配置 去Help -> SSL Proxying -> Install Charles Root Certificate on a Mobile Device or Remote Browser 查…...

为Claude Code配置Taotoken后端实现稳定无感的编程辅助
为Claude Code配置Taotoken后端实现稳定无感的编程辅助 对于日常使用Claude Code作为编程助手的开发者而言,一个稳定、可控的API服务是保证流畅编码体验的基础。直接连接单一服务商可能会遇到服务波动或访问限制,而手动切换不同模型又增加了配置的复杂度…...

如何保障fastbook实验可复现性:数据版本控制终极指南
如何保障fastbook实验可复现性:数据版本控制终极指南 【免费下载链接】fastbook The fastai book, published as Jupyter Notebooks 项目地址: https://gitcode.com/gh_mirrors/fa/fastbook fastbook作为fastai的官方教程项目,以Jupyter Notebook…...

StreamingVLM:实时视频流理解框架的技术解析与应用
1. 项目概述:当视频流遇上实时理解去年在给某智能安防系统做技术咨询时,客户指着监控墙上不断刷新的画面问我:"这些摄像头7x24小时工作,但真正需要人工介入的异常事件可能一天就两三起,有没有可能让AI像人一样持续…...

ETA6911,12V/4A 独立开关模式锂离子电池充电器。
1.描述ETA6911是新一代高集成度同步开关模式充电器,内置同步场效应管,具备高开关频率与高充电效率特性。依托钰泰半导体专属电流检测技术,该芯片无需外置检测电阻,可实现最高4安培的充电电流输出。此外,其封装尺寸仅1.…...

OBS多平台直播解决方案:obs-multi-rtmp技术实现与优化指南
OBS多平台直播解决方案:obs-multi-rtmp技术实现与优化指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 在当前的直播生态中,内容创作者面临着一个普遍的技术挑…...
对PHHs功能维持的影响)
原代人肝细胞长期培养模型研究:全人源三培养体系(TCS)对PHHs功能维持的影响
摘要: 原代人肝细胞(Primary Human Hepatocytes,PHHs)是药物代谢、药理学及毒理学研究中的核心模型,但传统培养体系难以长期维持其形态与代谢功能。本文基于全人源三培养体系(TCS)的公开研究资料…...
别只pip install了!深入理解sentence_transformers在PyG MovieLens示例中的角色与替代方案
别只pip install了!深入理解sentence_transformers在PyG MovieLens示例中的角色与替代方案 当你第一次在PyTorch Geometric(PyG)中尝试加载MovieLens数据集时,那个突如其来的ModuleNotFoundError可能让你措手不及。大多数人会本能…...

GetQzonehistory:三步轻松备份你的QQ空间历史说说,永久保存青春记忆
GetQzonehistory:三步轻松备份你的QQ空间历史说说,永久保存青春记忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾经想过,那些年发在QQ空间…...

别再手动量条带了!ImageJ分析Western Blot灰度值的保姆级避坑指南
ImageJ精准分析Western Blot数据的12个关键步骤与常见误区破解 第一次用ImageJ分析Western Blot结果时,我盯着屏幕上那些模糊的条带和复杂的菜单选项,完全不知道从何下手。实验室的师兄只是简单说了句"用矩形框选一下条带就行",但当…...

ASMR资源管理新范式:asmroner如何重新定义音频内容获取体验
ASMR资源管理新范式:asmroner如何重新定义音频内容获取体验 【免费下载链接】asmr-downloader A tool for download asmr media from asmr.one(Thanks for the asmr.one) 项目地址: https://gitcode.com/gh_mirrors/as/asmr-downloader 你是否曾为寻找高质量…...