C++:哈希表的模拟实现
文章目录
- 哈希
- 哈希冲突
- 哈希函数
- 解决哈希冲突
- 闭散列:
- 开散列
哈希
在顺序结构和平衡树中,元素的Key和存储位置之间没有必然的联系,在进行查找的时候,要不断的进行比较,时间复杂度是O(N)或O(logN)
而有没有这样一种方案,可以直接不经过比较,从表中得到所需要的元素呢?直接进行获取就可以,如果存在这样的结构,那么对它而言的查找效率是很高的
插入元素
根据上面的原理,在插入元素的时候,根据插入元素的Key,找到一个可以映射到一个表中的具体位置,并进行存放
搜索元素
在对元素的Key进行计算后,就可以直接找到它被映射到了表中的哪一个位置,从而可以直接找到它在表中的位置,如果找到了就返回true
上面的这个原理,就叫做哈希,也叫做散列,而在哈希中使用的这个转换函数就叫做哈希函数,也叫做散列函数,构造出来的结构就叫做哈希表,也叫做散列表
下面用一个例子来举例:
例如数据集合有{1, 7, 6, 4, 5, 9}
那么就可以把根据一个哈希转换函数:hash(key) = key % capacity,得到一个专属于它的下标,把这个值存到下标的位置:
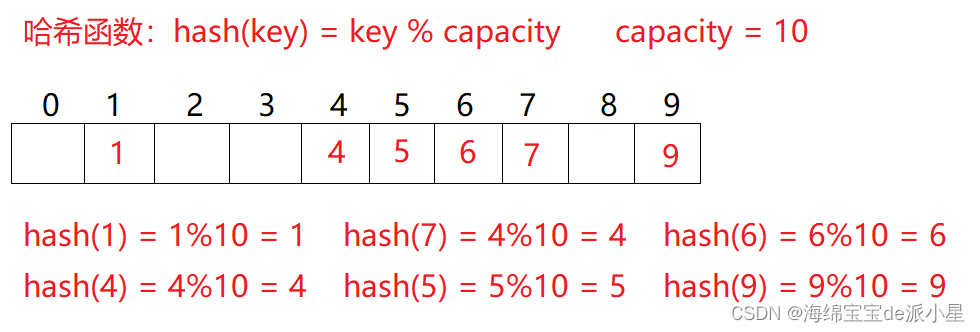
通过这样的方法就可以对元素和下标建立一种关系,在寻找的时候可以直接寻找到,在进行数据的存储和查找的过程拥有相当高的效率
但依旧有问题,如果存储的元素正好已经被存储过了呢?
哈希冲突
所谓哈希冲突,简单来说就是不同的Key值经过计算,得到了一个相同的hash值,此时再向表中填写数据就会有问题,这个过程就叫哈希冲突,也叫做哈希碰撞,那为什么会引起哈希碰撞?如何解决?
哈希函数
通常来说,引起哈希碰撞的一个原因是哈希函数有问题
常见的哈希函数定义:
- 直接定址法:取Key值的某个线性函数作为散列地址,例如Hash(Key)= A*Key + B
- 除留余数法:设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
- 平方取中法
- 折叠法
- 数学分析法
哈希函数设计的越好,出现哈希冲突的可能性就越低,但无法避免哈希冲突,也就是说,哈希冲突是一定会发生的
解决哈希冲突
解决的方法通常有两种,闭散列和开散列
闭散列:
当发生哈希冲突的时候,如果哈希表没有被装满,那么就说明哈希表中肯定还有空余位置,那么就放到冲突位置的下一个位置当中去
- 线性探测
从发生哈希冲突的位置开始,依次向后进行探测,直到探测到了一个空位置为止
那么下面模拟实现一下线性探测的实现过程
bool insert(const pair<K, V>& kv){// 考虑扩容问题if (_n * 10 / _t.size() == 7){size_t newsize = _t.size() * 2;vector<HashData<K, V>> newV;newV.resize(newsize);size_t _newn = 0;// 把原来的数据放到新表中 遍历一次旧表for (int i = 0; i < _t.size(); i++){// 如果旧表中这个位置的值存在 就准备放到新表中if (_t[i]._s == EXIST){size_t newhashi = _t[i]._kv.first % newsize;while (newV[newhashi]._s == EXIST){newhashi++;newhashi %= newsize;}newV[newhashi]._kv = _t[i]._kv;newV[newhashi]._s = EXIST;_newn++;}}_t.swap(newV);_n = newsize;}// 正常插入逻辑size_t hashi = kv.first % _t.size();while (_t[hashi]._s == EXIST){// 如果插入元素的位置有内容,就插入到下一个位置hashi++;hashi %= _t.size();}_t[hashi]._kv = kv;_t[hashi]._s = EXIST;_n++;return true;}
但是闭散列的缺陷是很明显的,比如当插入数据是12,22,32,42…这样的数据的时候,就会导致不停地触发哈希冲突,这样会产生堆积的效应,为了避免出现这样的问题,又提出了开散列的方案
开散列
开散列也叫做哈希桶,也叫做拉链法,原理就是把具有相同地址的Key值放到一起,每一个子集就叫做一个桶,每个桶的元素通过单链表来进行链接,每个链表的头结点在哈希表中
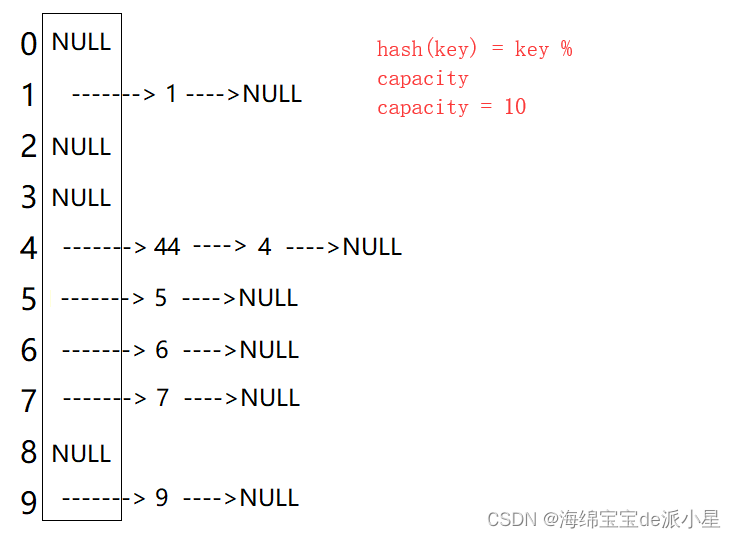
开散列中每个桶中放的都是哈希冲突的元素
namespace opened_hashing
{// 定义节点信息template<class K, class V>struct Node{Node(const pair<K, V>& kv):_next(nullptr), _kv(kv){}Node* _next;pair<K, V> _kv;};template<class K, class V>class HashTable{typedef Node<K, V> Node;public:// 构造函数HashTable():_n(0){_table.resize(10);}// 析构函数~HashTable(){//cout << endl << "*******************" << endl;//cout << "destructor" << endl;for (int i = 0; i < _table.size(); i++){//cout << "[" << i << "]->";Node* cur = _table[i];while (cur){Node* next = cur->_next;//cout << cur->_kv.first << " ";delete cur;cur = next;}//cout << endl;_table[i] = nullptr;}}// 插入元素bool insert(const pair<K, V>& kv){// 如果哈希表中有这个元素,就不插入了if (find(kv.first)){return false;}// 扩容问题if (_n == _table.size()){HashTable newtable;int newsize = _table.size() * 2;newtable._table.resize(newsize, nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 把哈希桶中的元素插入到新表中int newhashi = cur->_kv.first % newsize;// 头插cur->_next = newtable._table[newhashi];newtable._table[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable._table);}// 先找到在哈希表中的位置size_t hashi = kv.first % _table.size();// 把节点插进去Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}Node* find(const K& Key){// 先找到它所在的桶int hashi = Key % _table.size();// 在它所在桶里面找数据Node* cur = _table[hashi];while (cur){if (cur->_kv.first == Key){return cur;}cur = cur->_next;}return nullptr;}void print(){for (int i = 0; i < _table.size(); i++){cout << i << "->";Node* cur = _table[i];while (cur){cout << cur->_kv.first << " ";cur = cur->_next;}cout << endl;}cout << endl;}private:vector<Node*> _table;size_t _n;};
}
上面的实现看似没有问题,实际上依旧有问题,如果要传入的数据是string类,那么在比较的过程中会出现错误,因此要写一个仿函数用以处理这些情况

这里利用版本模板中的特化进行处理即可,处理细节比较巧妙
template<class T>struct _Convert{T& operator()(const T& key){return key;}};template<>struct _Convert<string>{size_t& operator()(const string& key){size_t sum = 0;for (auto e : key){sum += e * 31;}return sum;}};
那么下一步就要进行对于哈希表的封装了,详情见模拟实现篇章
相关文章:
C++:哈希表的模拟实现
文章目录 哈希哈希冲突哈希函数 解决哈希冲突闭散列:开散列 哈希 在顺序结构和平衡树中,元素的Key和存储位置之间没有必然的联系,在进行查找的时候,要不断的进行比较,时间复杂度是O(N)或O(logN) 而有没有这样一种方案…...
echarts实现如下图功能代码
这里写自定义目录标题 const option {tooltip: {trigger: axis},legend: {left: "-1px",top:15px,type: "scroll",icon:rect,data: [{name:1, textStyle:{color: theme?"#E5EAF3":#303133,fontSize:14}}, {name: 2, textStyle:{color: theme…...

Java 开源重试类 guava-retrying 使用案例
使用背景 需要重复尝试执行某些动作,guava-retrying 提供了成型的重试框架 依赖 <dependency><groupId>com.github.rholder</groupId><artifactId>guava-retrying</artifactId><version>${retrying.version}</version>…...
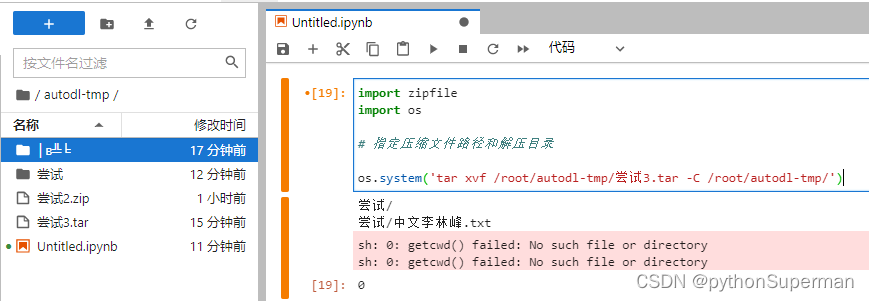
服务器 jupyter 文件名乱码问题
对于本台电脑,autodl服务器,上传中文文件时,从压缩包名到压缩包里的文件名先后会出现中文乱码的问题。 Xftp 首先是通过Xftp传输压缩包到Autodl服务器: 1、打开Xftp,进入软件主界面,点击右上角【文件】菜…...
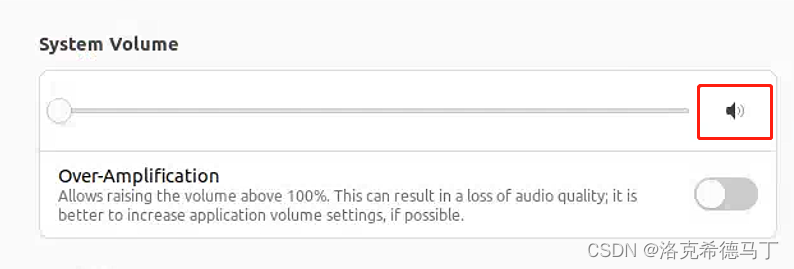
Ubuntu设设置默认外放和麦克风设备
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pulseaudio 是什么?二、配置外放1.查看所有的外放设备2.设定默认的外放设备3.设定外放设备的声音强度4.设定外放设备静音 三、配置麦克风1.查看…...
)
【教程】Sqlite迁移到mysql(django)
1、先将sqlite db文件导出sql sqlite3 db.sqlite3 .dump>output.sql db.sqlite3 是 sqlite 数据库文件 output.sql是导出sql文件的名称 2、sql文件转换、处理 sed s/AUTOINCREMENT/AUTO_INCREMENT/g output.sql | sed s/datetime/timestamp/g | sed s/INTEGER/int/g &g…...
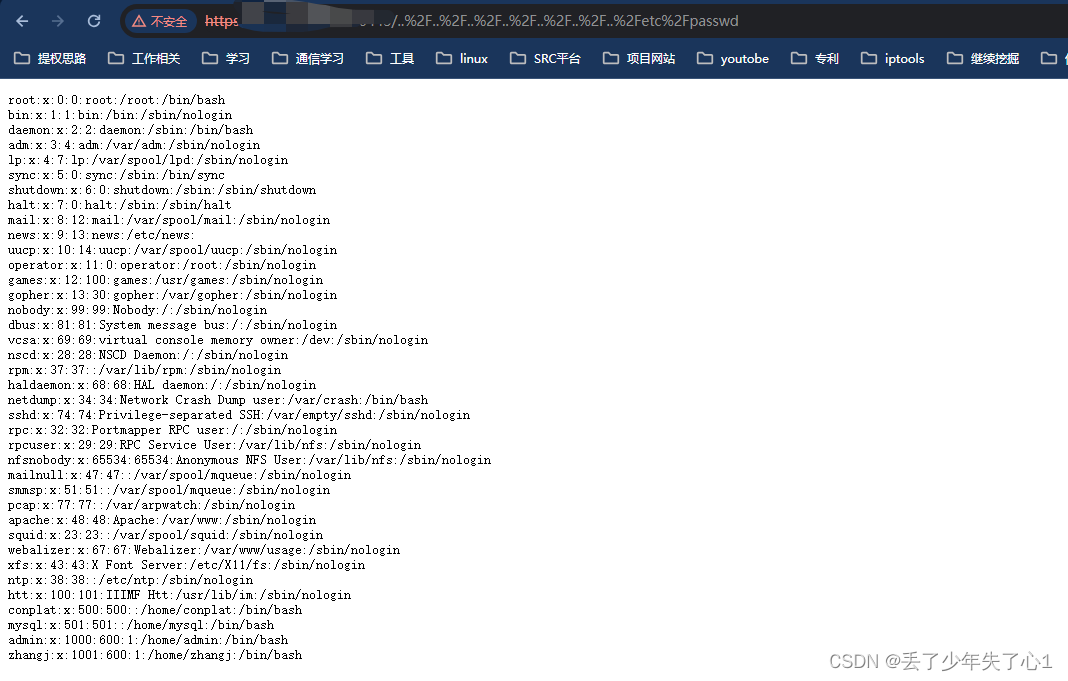
【漏洞复现】DPTech VPN存在任意文件读取漏洞
漏洞描述 DPtech是在网络、安全及应用交付领域集研发、生产、销售于一体的高科技企业。DPtech VPN智能安全网关是迪普科技面向广域互联应用场景推出的专业安全网关产品,集成了IPSec、SSL、L2TP、GRE等多种VPN技术,支持国密算法,实现分支机构…...

CentOS 8搭建WordPress
步骤 1: 更新系统 确保你的系统是最新的,使用以下命令更新: bashCopy code sudo dnf update 步骤 2: 安装Apache bashCopy code sudo dnf install httpd 启动Apache,并设置开机自启动: bashCopy code sudo systemctl star…...

服务器安全防护导致使用多款行业顶尖软件搭配使用,还是单独一款解决呢?
如今,在全球各地,数以千计的公司、组织和个人都依赖于服务器来存储和访问重要数据,托管应用程序,以及提供服务。但是,这些服务器不断面临着来自网络黑客的威胁,因此服务器的安全成为了当务之急。 在这种情…...
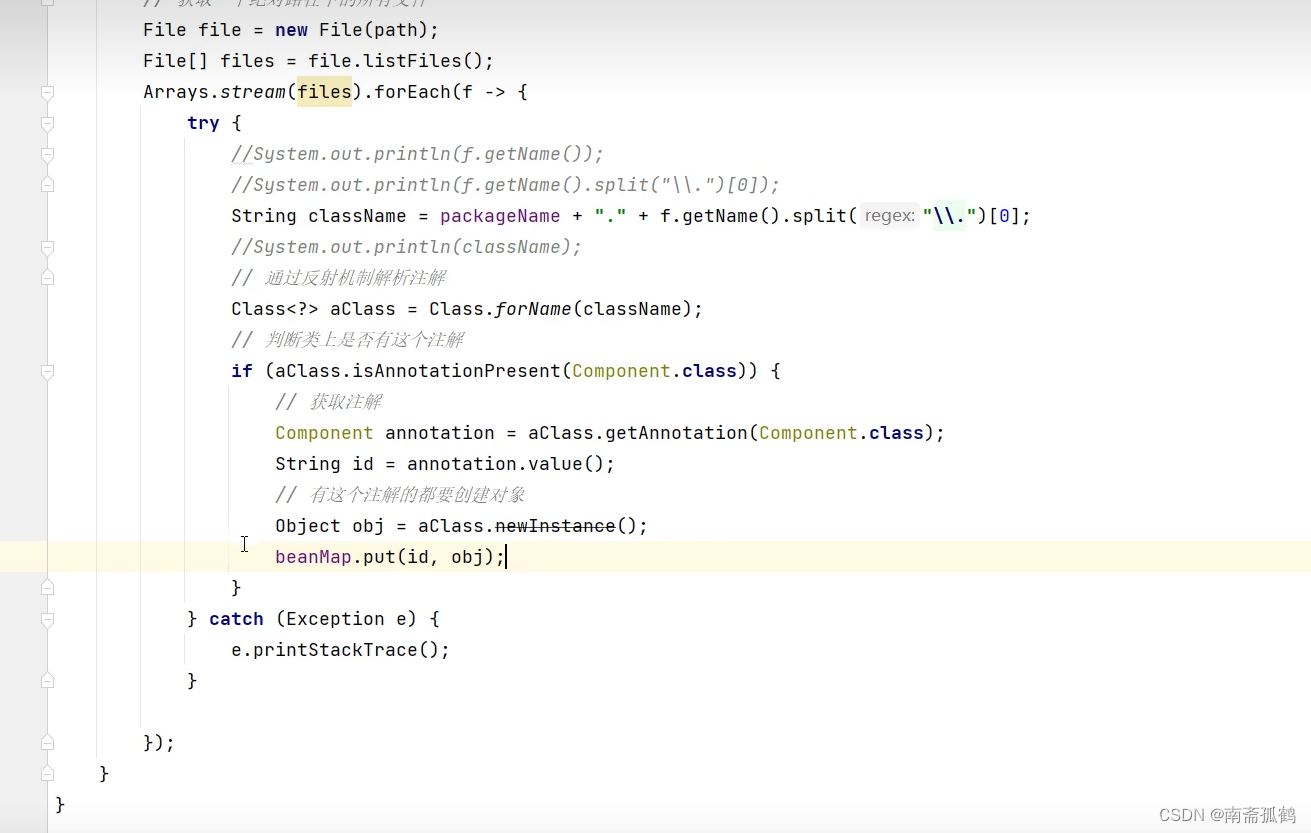
【Spring篇】Spring注解式开发
本文根据哔哩哔哩课程内容结合自己自学所得,用于自己复习,如有错误欢迎指正; 我在想用一句话激励我自己努力学习,却想不出来什么惊为天人、精妙绝伦的句子,脑子里全是上课老师想说却没想起的四个字 “ 唯手熟尔 ”&am…...
14.(vue3.x+vite)组件间通信方式之pinia
前端技术社区总目录(订阅之前请先查看该博客) 示例效果 Pinia简介 Pinia 是 Vue 的存储库,它允许您跨组件/页面共享状态。 Pinia与Vuex比较 (1)Vue2和Vue3都支持,这让我们同时使用Vue2和Vue3的小伙伴都能很快上手。 (2)pinia中只有state、getter、action,抛弃了Vu…...

DolphinDB 浙商银行 | 第二期现场培训圆满结束
自 DolphinDB 高级工程师计划开展以来,客户们纷纷响应,除了定期收看我们每周三开设的线上公开课外,也有部分客户报名参加了 “总部工程师培训计划” 。 上周,我们迎来了总部培训的第二期学员:来自浙商银行的4位策略研…...
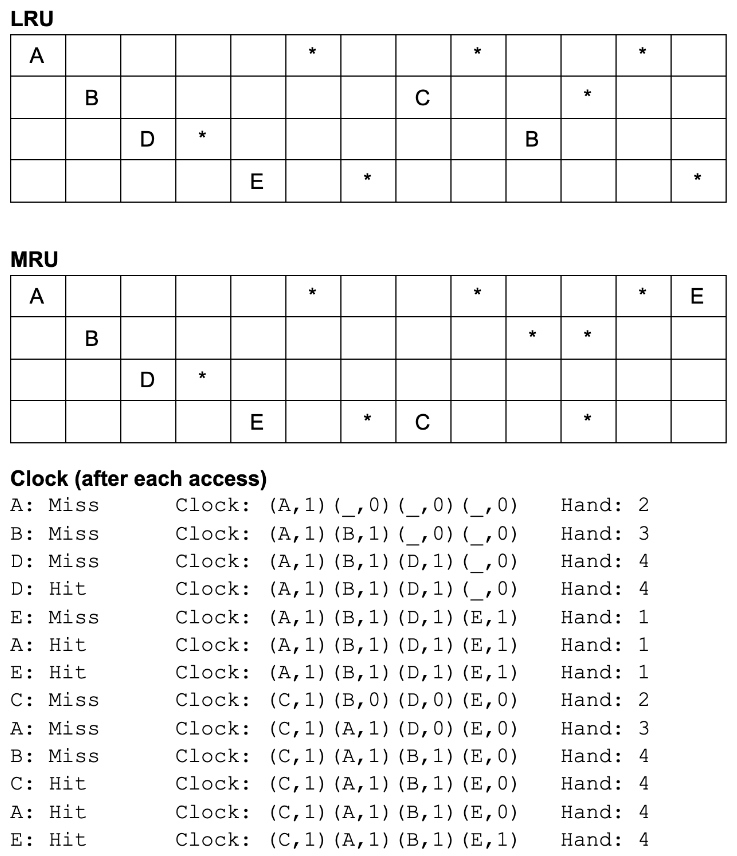
DBS note4:Buffer Management
目录 1、介绍 2、缓冲池 3、处理页面请求 4、LRU替换和时钟策略 1)顺序扫描性能 - LRU 5、最近最常使用替换策略(MRU Replacement) 1)Sequential Scanning Performance - MRU 6、练习题 1)判断真假 2…...

Linux 中 .tar 和 tar.gz 的区别
1、前言 有时候你会发现,即便是有些拥有 3 年左右工作经验的运维或开发工程师对 .tar 和 .tar.gz 的区别并不是很清楚。.tar 和 .tar.gz 是在 Linux 系统中用于打包和压缩文件的两种常见格式。它们之间的主要区别在于压缩算法和文件扩展名。 2、区别 .tar .tar 是…...

区域人员超限AI算法的介绍及TSINGSEE视频智能分析技术的行业应用
视频AI智能分析已经渗透到人类生活及社会发展的各个方面。从生活中的人脸识别、停车场的车牌识别、工厂园区的翻越围栏识别、入侵识别、工地的安全帽识别、车间流水线产品的品质缺陷AI检测等,AI智能分析技术无处不在。在某些场景中,重点区域的人数统计与…...
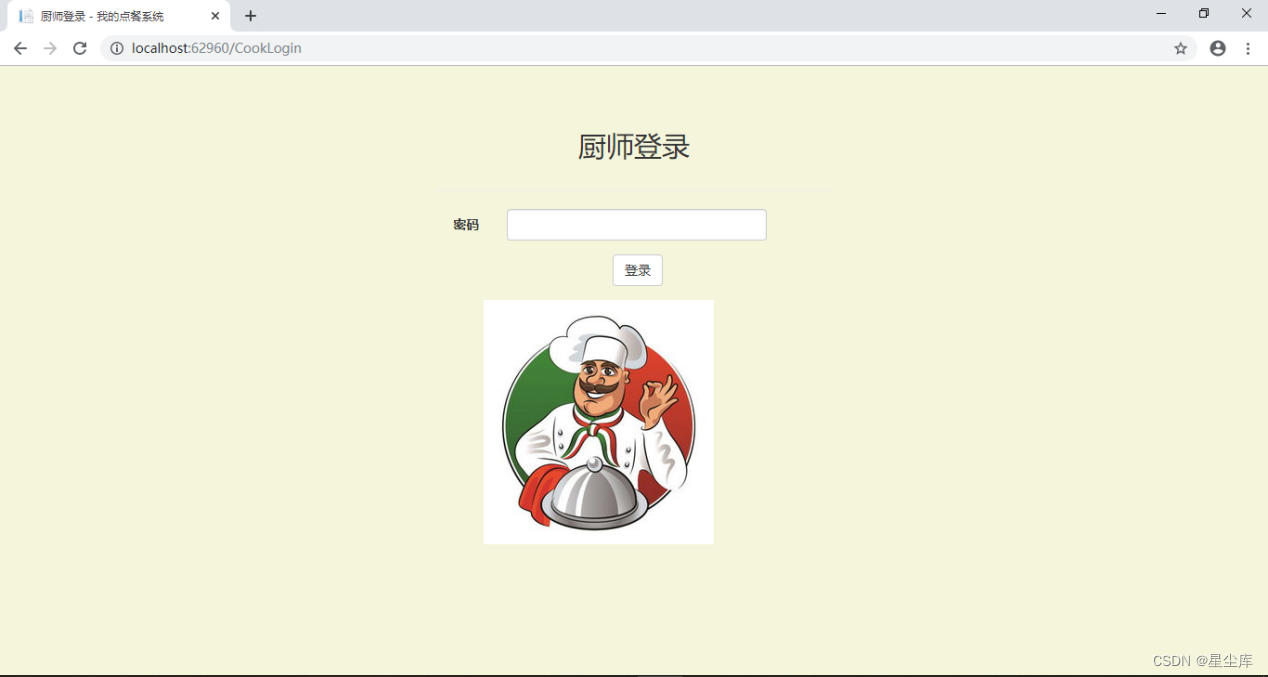
asp.net mvc点餐系统餐厅管理系统
1. 主要功能 ① 管理员、收银员、厨师的登录 ② 管理员查看、添加、删除菜品类型 ③ 管理员查看、添加、删除菜品,对菜品信息进行简介和封面的修改 ④ 收银员浏览、搜索菜品,加入购物车后进行结算,生成订单 ⑤ 厨师查看待完成菜品信息…...

SpringBoot 使用多SqlSessionFactory下的事务问题
如下配置了两个数据源: spring:datasource:ds1:jdbc-url: jdbc:mysql://localhost:3307/spring-boot-demos?serverTimezoneUTC&useUnicodetrue&characterEncodingutf8&useSSLfalse&allowPublicKeyRetrievaltrueusername: rootpassword: passwordd…...

浏览器内置NoSQL数据库IndexedDB
IndexedDB - 浏览器内容数据库 indexedDB 是一种浏览器内置的NoSQL数据库,它使用键值对存储数据,用于在客户端存储大量结构化数据。它支持离线应用程序和高效的数据检索,可以在 Web 应用程序中替代传统的 cookie 和 localStorage。 IndexDB是…...
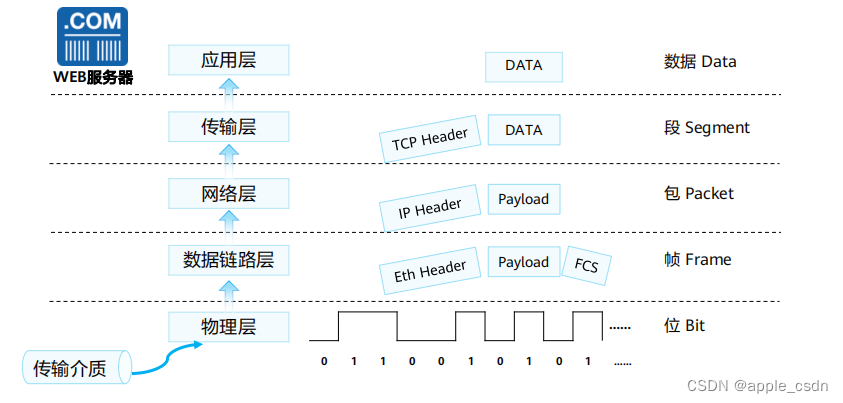
网络参考模型与标准协议(二)-TCP/IP对等模型详细介绍
应用层 应用层为应用软件提供接口,使应用程序能够使用网络服务。应用层协议会指定使用相应的传输层协议,以及传输层所使用的端口等。TCP/IP每一层都让数据得以通过网络进行传输,这些层之间使用PDU ( Paket Data Unit,协议数据单元)彼此交换信…...
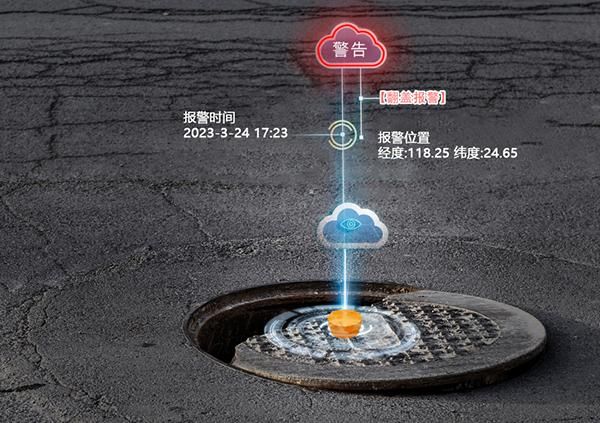
万宾科技智能井盖传感器,预防城市道路安全
随着城市交通的不断发展和城市化进程的加速推进,城市道路安全问题日益凸显。市政井盖作为城市道路的一部分,承担着重要的交通安全保障职责。然而传统的市政井盖管理方式存在许多不足。针对这些问题政府需要采取适当的措施,补足传统管理方式的…...

在自动化测试脚本中集成taotokenapi为硬件日志生成分析摘要
在自动化测试脚本中集成taotokenapi为硬件日志生成分析摘要 对于嵌入式硬件,尤其是STM32这类设备的测试,每天都会产生海量的日志文件。测试工程师需要从中筛选关键信息,定位潜在问题,这个过程耗时且容易遗漏。本文将介绍一种实践…...

XLSX I/O:5分钟掌握C语言Excel文件读写的高效解决方案
XLSX I/O:5分钟掌握C语言Excel文件读写的高效解决方案 【免费下载链接】xlsxio XLSX I/O - C library for reading and writing .xlsx files 项目地址: https://gitcode.com/gh_mirrors/xl/xlsxio XLSX I/O 是一个专为C语言开发者设计的轻量级Excel文件读写库…...
)
别再只会用梯度下降了!用Scipy的basinhopping搞定Python全局优化难题(附多元函数实战)
别再只会用梯度下降了!用Scipy的basinhopping搞定Python全局优化难题(附多元函数实战) 当你在训练神经网络时反复调整学习率却始终无法突破准确率瓶颈,当你的物理仿真模型总在某个参数区间卡住,当投资组合优化算法陷入…...

Cursor Pro激活器终极指南:3步轻松破解AI编程限制
Cursor Pro激活器终极指南:3步轻松破解AI编程限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...

基于Next.js构建极简ChatGPT Web客户端:从部署到二次开发全指南
1. 项目概述:一个极简但功能完整的ChatGPT Web界面如果你厌倦了官方ChatGPT网页版偶尔的卡顿、复杂的界面,或者想拥有一个完全可控、能部署在自己服务器上的AI对话工具,那么chatgpt-minimal这个项目绝对值得你花时间研究。它是一个基于Next.j…...

通达信缠论插件快速入门:3步实现自动化技术分析,告别手动画线烦恼
通达信缠论插件快速入门:3步实现自动化技术分析,告别手动画线烦恼 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 缠论技术分析是股票交易中极具价值的理论体系,但传统…...

yolov5实现火焰识别/检测步骤记录
1.克隆yolov5仓库 git clone https://github.com/ultralytics/yolov5 2.安装python3.7、Pytorch1.7.0环境 3.安装yolov5环境 pip install -r requirements.txt 4.数据集与配置文件 #数据集来源 https://universe.roboflow.com/dataset-9xayt/fire-data-annotations-lwfou 在…/…...

GetQzonehistory:三步轻松备份你的QQ空间完整历史说说
GetQzonehistory:三步轻松备份你的QQ空间完整历史说说 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾经担心QQ空间里那些记录青春岁月的说说会随着时间流逝而消失&…...

题解:洛谷 P15798 [GESP202603 五级] 有限不循环小数
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

ESP32 与 Air780E 4G 模块配合做 HTTP 数据传输:从硬件到代码的实战详解
在物联网(IoT)项目中,设备往往部署在无 Wi-Fi、无以太网的户外或移动场景(如远程环境监测、车载终端、野外监控等)。此时,ESP32 虽具备强大的主控能力,但缺乏蜂窝通信功能;而合宙 Ai…...