PyTorch多GPU训练时同步梯度是mean还是sum?
PyTorch 通过两种方式可以进行多GPU训练: DataParallel, DistributedDataParallel. 当使用DataParallel的时候, 梯度的计算结果和在单卡上跑是一样的, 对每个数据计算出来的梯度进行累加. 当使用DistributedDataParallel的时候, 每个卡单独计算梯度, 然后多卡的梯度再进行平均.
下面是实验验证:
DataParallel
import torch
import os
import torch.nn as nndef main():model = nn.Linear(2, 3).cuda()model = torch.nn.DataParallel(model, device_ids=[0, 1])input = torch.rand(2, 2)labels = torch.tensor([[1, 0, 0], [0, 1, 0]]).cuda()(model(input) * labels).sum().backward()print('input', input)print([p.grad for p in model.parameters()])if __name__=="__main__":main()
执行CUDA_VISIBLE_DEVICES=0,1 python t.py可以看到输出, 代码中对两个样本分别求梯度, 梯度等于样本的值, DataParallel把两个样本的梯度累加起来在不同GPU中同步.
input tensor([[0.4362, 0.4574],[0.2052, 0.2362]])
[tensor([[0.4363, 0.4573],[0.2052, 0.2362],[0.0000, 0.0000]], device='cuda:0'), tensor([1., 1., 0.], device='cuda:0')]
DistributedDataParallel
import torch
import os
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDPdef example(rank, world_size):# create default process groupdist.init_process_group("gloo", rank=rank, world_size=world_size)# create local modelmodel = nn.Linear(2, 3).to(rank)print('model param', 'rank', rank, [p for p in model.parameters()])# construct DDP modelddp_model = DDP(model, device_ids=[rank])print('ddp model param', 'rank', rank, [p for p in ddp_model.parameters()])# forward passinput = torch.randn(1, 2).to(rank)outputs = ddp_model(input)labels = torch.randn(1, 3).to(rank) * 0labels[0, rank] = 1# backward pass(outputs * labels).sum().backward()print('rank', rank, 'grad', [p.grad for p in ddp_model.parameters()])print('rank', rank, 'input', input, 'outputs', outputs)print('rank', rank, 'labels', labels)# update parametersoptimizer.step()def main():world_size = 2mp.spawn(example,args=(world_size,),nprocs=world_size,join=True)if __name__=="__main__":# Environment variables which need to be# set when using c10d's default "env"# initialization mode.os.environ["MASTER_ADDR"] = "localhost"os.environ["MASTER_PORT"] = "29504"main()
执行CUDA_VISIBLE_DEVICES=0,1 python t1.py可以看到输出, 代码中对两个样本分别求梯度, 梯度等于样本的值, 最终的梯度是各个GPU的梯度的平均.
model param rank 0 [Parameter containing:
tensor([[-0.4819, 0.0253],[ 0.0858, 0.2256],[ 0.5614, 0.2702]], device='cuda:0', requires_grad=True), Parameter containing:
tensor([-0.0090, 0.4461, -0.3493], device='cuda:0', requires_grad=True)]
model param rank 1 [Parameter containing:
tensor([[-0.3737, 0.3062],[ 0.6450, 0.2930],[-0.2422, 0.2089]], device='cuda:1', requires_grad=True), Parameter containing:
tensor([-0.5868, 0.2106, -0.4461], device='cuda:1', requires_grad=True)]
ddp model param rank 1 [Parameter containing:
tensor([[-0.4819, 0.0253],[ 0.0858, 0.2256],[ 0.5614, 0.2702]], device='cuda:1', requires_grad=True), Parameter containing:
tensor([-0.0090, 0.4461, -0.3493], device='cuda:1', requires_grad=True)]
ddp model param rank 0 [Parameter containing:
tensor([[-0.4819, 0.0253],[ 0.0858, 0.2256],[ 0.5614, 0.2702]], device='cuda:0', requires_grad=True), Parameter containing:
tensor([-0.0090, 0.4461, -0.3493], device='cuda:0', requires_grad=True)]
rank 1 grad [tensor([[ 0.2605, 0.1631],[-0.0934, -0.5308],[ 0.0000, 0.0000]], device='cuda:1'), tensor([0.5000, 0.5000, 0.0000], device='cuda:1')]
rank 0 grad [tensor([[ 0.2605, 0.1631],[-0.0934, -0.5308],[ 0.0000, 0.0000]], device='cuda:0'), tensor([0.5000, 0.5000, 0.0000], device='cuda:0')]
rank 1 input tensor([[-0.1868, -1.0617]], device='cuda:1') outputs tensor([[ 0.0542, 0.1906, -0.7411]], device='cuda:1',grad_fn=<AddmmBackward0>)
rank 0 input tensor([[0.5209, 0.3261]], device='cuda:0') outputs tensor([[-0.2518, 0.5644, 0.0314]], device='cuda:0',grad_fn=<AddmmBackward0>)
rank 1 labels tensor([[-0., 1., -0.]], device='cuda:1')
rank 0 labels tensor([[1., 0., -0.]], device='cuda:0')
相关文章:

PyTorch多GPU训练时同步梯度是mean还是sum?
PyTorch 通过两种方式可以进行多GPU训练: DataParallel, DistributedDataParallel. 当使用DataParallel的时候, 梯度的计算结果和在单卡上跑是一样的, 对每个数据计算出来的梯度进行累加. 当使用DistributedDataParallel的时候, 每个卡单独计算梯度, 然后多卡的梯度再进行平均.…...

Spring Framework IoC依赖注入-按Bean类型注入
Spring Framework 作为一个领先的企业级开发框架,以其强大的依赖注入(Dependency Injection,DI)机制而闻名。DI使得开发者可以更加灵活地管理对象之间的关系,而不必过多关注对象的创建和组装。在Spring Framework中&am…...
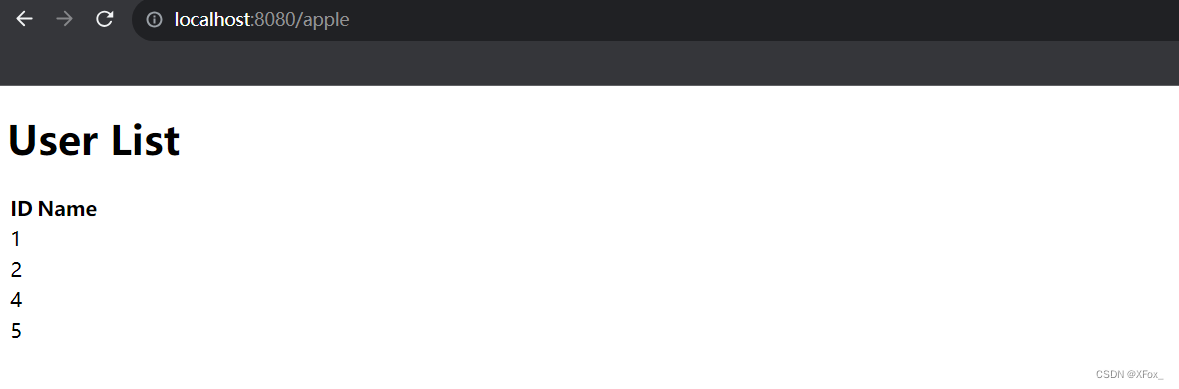
IDEA运行thymeleaf的html文件打开端口为63342且连不上数据库
这边贴apple.html代码 <!DOCTYPE html> <html xmlns:th"http://www.thymeleaf.org"> <head><meta charset"UTF-8"><title>User List</title> </head> <body> <h1>User List</h1> <table&…...

sql报错注入和联合注入
1.[NISACTF 2022]join-us 过滤: as IF rand() LEFT by updatesubstring handler union floor benchmark COLUMN UPDATE & sys.schema_auto_increment_columns && 11 database case AND right CAST FLOOR left updatexml DATABASES BENCHMARK BY sleep…...

028 - STM32学习笔记 - ADC结构体学习(二)
028 - STM32学习笔记 - 结构体学习(二) 上节对ADC基础知识进行了学习,这节在了解一下ADC相关的结构体。 一、ADC初始化结构体 在标准库函数中基本上对于外设都有一个初始化结构体xx_InitTypeDef(其中xx为外设名,例如…...
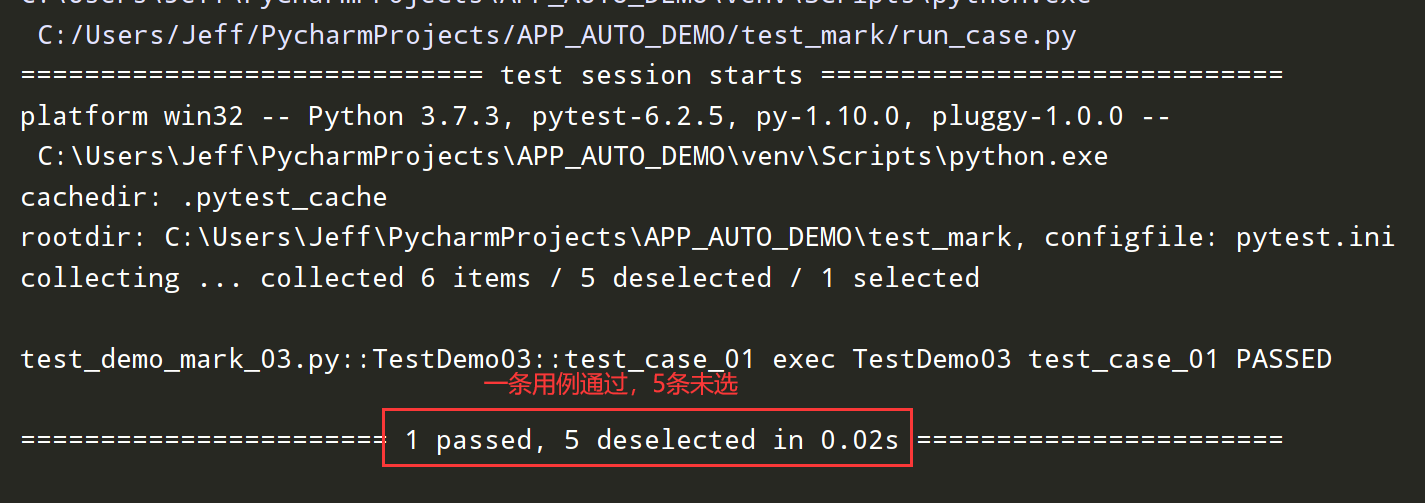
Pytest自动化测试框架:mark用法---测试用例分组执行
pytest中的mark: mark主要用于在测试用例/测试类中给用例打标记(只能使用已注册的标记名),实现测试分组功能,并能和其它插件配合设置测试方法执行顺序等。 如下图,现在需要只执行红色部分的测试方法,其它方法不执行&am…...

【TCP连接的状态】
linux查看tcp的状态命令: 1)、netstat -nat 查看TCP各个状态的数量 2)、lsof -i:port 可以检测到打开套接字的状况 3)、 sar -n SOCK 查看tcp创建的连接数 4)、tcpdump -iany tcp port 9000 对tcp端口为9000的进行抓包 查看占用端口…...
Node.js入门指南(一)
目录 Node.js入门 什么是Node.js Node.js的作用 Node.js安装 Node.js编码注意事项 Buffer(缓冲器) 定义 使用 fs模块 概念 文件写入 文件读取 文件移动与重命名 文件删除 文件夹操作 查看资源状态 路径问题 path模块 Node.js入门 什么是Node.js …...

使用Grpc实现高性能PHP RPC服务
文档:Quick start | PHP | gRPC 下面将介绍使用 Grpc 和 Protobuf 实现高性能 RPC 服务的具体步骤: 1. 安装 Grpc 和 Protobuf 首先需要安装 Grpc 和 Protobuf。可以从官网下载相应的安装包(Supported languages | gRPC)或通过…...

二、爬虫-爬取肯德基在北京的店铺地址
1、算法框架解释 针对这个案例,现在对爬虫的基础使用做总结如下: 1、算法框架 (1)设定传入参数 ~url: 当前整个页面的url:当前页面的网址 当前页面某个局部的url:打开检查 ~data:需要爬取数据的关键字&…...
)
linux驱动开发.之spi测试工具spidev_test源码(一)
同i2c-tools工具类似,spidev_test是用来测试SPI BUS的用户态程序,其源码存在kernel目录下的tools下,具体为tools\spi\spidev_test.c。buildroot同样也提供名为spidev_test的package,可以直接进行编译,方便用户调试spi总…...

基于材料生成算法优化概率神经网络PNN的分类预测 - 附代码
基于材料生成算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于材料生成算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于材料生成优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神…...
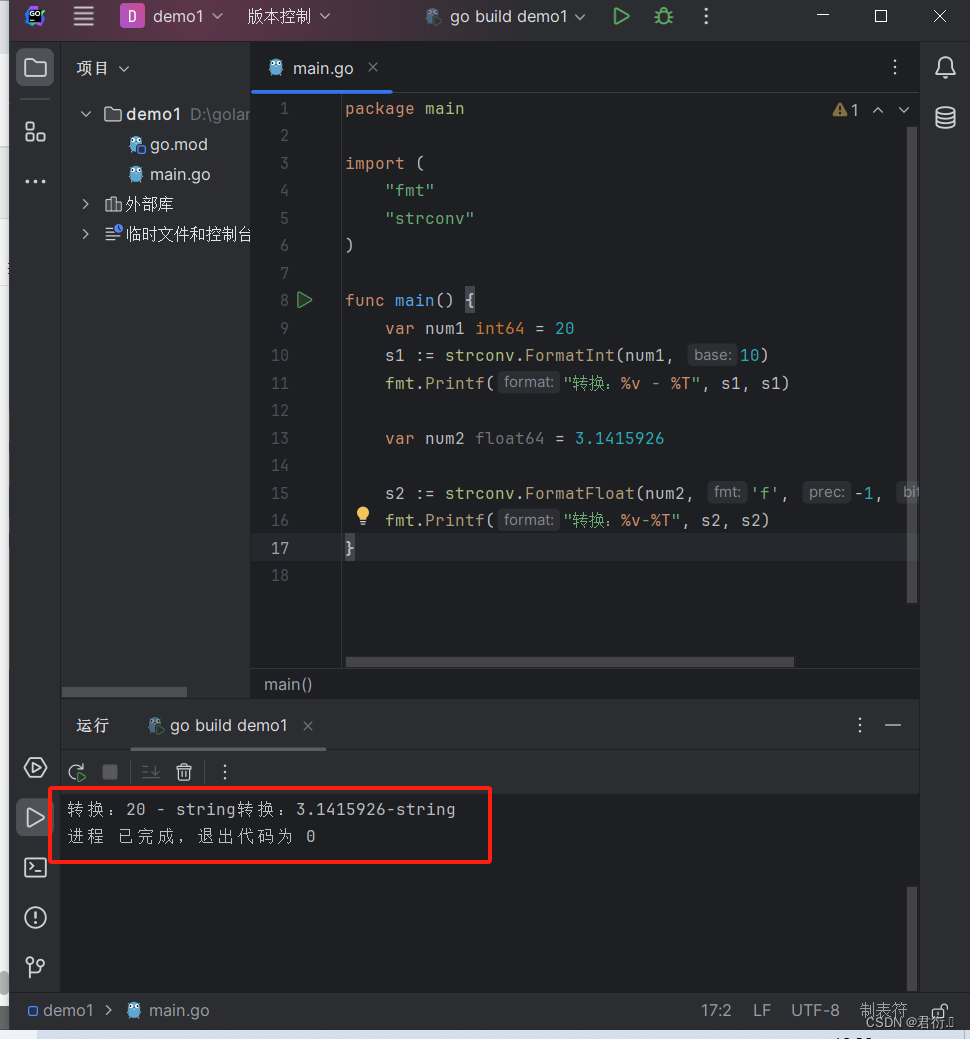
Go——二、变量和数据类型
Go 一、Go语言中的变量和常量1、Go语言中变量的声明2、如何定义变量方式1:方式2:带类型方式3:类型推导方式定义变量方式4:声明多个变量总结 3、如何定义常量4、Const常量结合iota的使用 二、Golang的数据类型1、概述2、整型2.1 类…...
合并区间问题
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输入:intervals [[1,…...
2023 年最新 MySQL 数据库 Windows 本地安装、Centos 服务器安装详细教程
MySQL 基本概述 MySQL是一个流行的关系型数据库管理系统(RDBMS),广泛应用于各种业务场景。它是由瑞典MySQL AB公司开发,后来被Sun Microsystems收购,最终被甲骨文公司(Oracle Corporation)收购…...
——获取和为k的子数组)
每天一道算法题(十)——获取和为k的子数组
文章目录 1、问题2、示例3、解决方法(1)方法1——双指针 总结 1、问题 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 2、示例 示例 1: 输入&#x…...

2023年亚太杯数学建模思路 - 案例:最短时间生产计划安排
文章目录 0 赛题思路1 模型描述2 实例2.1 问题描述2.2 数学模型2.2.1 模型流程2.2.2 符号约定2.2.3 求解模型 2.3 相关代码2.4 模型求解结果 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 最短时…...

在vscode中使用Latex:TexLive2023
安装TexLive2023及配置vscode可参考https://zhuanlan.zhihu.com/p/166523064 然后编译模板 .tex文件时,出现以下几个错误: 1. ctexbook找不到字体集 d:/texlive/2023/texmf-dist/tex/latex/ctex/ctexbook.cls:1678: Class ctexbook Error: CTeX fo…...

Unity开发之C#基础-File文件读取
前言 今天我们将要讲解到c#中 对于文件的读写是怎样的 那么没接触过特别系统编程小伙伴们应该会有一个疑问 这跟文件有什么关系呢? 我们这样来理解 首先 大家对电脑或多或少都应该有不少的了解吧 那么我们这些软件 都是通过变成一个一个文件保存在电脑中 我们才可以…...

深度学习之二(前馈神经网络--Feedforward Neural Network)
概念 前馈神经网络(Feedforward Neural Network)是一种最基本的神经网络结构,也被称为多层感知器(Multilayer Perceptron,MLP)。它的特点是信息只在网络中单向传播,不会形成环路。每一层神经元的输出都作为下一层神经元的输入,没有反馈回路。 结构: 前馈神经网络通…...

Windows系统VBE7INTL.DLL文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

3分钟解决Blender到Unity的FBX转换难题:新手必备插件指南
3分钟解决Blender到Unity的FBX转换难题:新手必备插件指南 【免费下载链接】blender-to-unity-fbx-exporter FBX exporter addon for Blender compatible with Unitys coordinate and scaling system. 项目地址: https://gitcode.com/gh_mirrors/bl/blender-to-uni…...

图像细化不止Zhang-Suen:聊聊骨架提取在OCR和手势识别里的实际应用与选型
图像细化不止Zhang-Suen:骨架提取在OCR和手势识别中的实战选型指南 当你在处理一份模糊的历史文档扫描件时,字符笔画粘连得像被雨水晕染开的墨迹;或者开发手势识别系统时,用户手掌轮廓在低光环境下变得异常粗大——这时࿰…...

3步搞定视频水印:用LAMA模型批量清理平台标识的终极指南
3步搞定视频水印:用LAMA模型批量清理平台标识的终极指南 【免费下载链接】WatermarkRemover 批量去除视频中位置固定的水印 项目地址: https://gitcode.com/gh_mirrors/wa/WatermarkRemover 还在为视频中的平台水印烦恼吗?想要制作干净无痕的视频…...

BloodyAD代码架构深度剖析:从CLI模块到LDAP引擎的实现原理
BloodyAD代码架构深度剖析:从CLI模块到LDAP引擎的实现原理 【免费下载链接】bloodyAD BloodyAD is an Active Directory Privilege Escalation Framework 项目地址: https://gitcode.com/gh_mirrors/bl/bloodyAD BloodyAD是一款功能强大的Active Directory权…...
避坑指南:从管脚唤醒配置到中断安全处理)
CC26XX深度睡眠(Shutdown)避坑指南:从管脚唤醒配置到中断安全处理
CC26XX深度睡眠(Shutdown)实战全解析:从硬件设计到软件安全的完整指南 在物联网设备开发中,电池寿命往往是决定产品成败的关键因素。当我们需要设备在无人操作时保持极低功耗,同时又能通过外部事件快速响应时ÿ…...

利用Taotoken模型广场为AIGC应用动态选择性价比最优的模型
利用Taotoken模型广场为AIGC应用动态选择性价比最优的模型 1. 理解模型选择的核心需求 在构建内容创作应用时,文案生成和图片描述是两种典型的AIGC任务。文案生成通常需要较强的语言理解和创造力,而图片描述则更注重对视觉元素的准确捕捉。不同模型在这…...

老Mac升级终极指南:用OpenCore Legacy Patcher让旧设备焕发新生
老Mac升级终极指南:用OpenCore Legacy Patcher让旧设备焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老款Mac无法升级到最新…...

Windows 11 下用 Node.js 和 crypto-js 逆向分析网站登录密码加密,保姆级实战拆解
Windows 11 下用 Node.js 和 crypto-js 逆向分析网站登录密码加密,保姆级实战拆解 在当今的Web安全领域,前端加密已成为保护用户敏感数据的标配方案。当我们面对一个加密的登录请求时,如何从黑盒状态一步步揭开其加密逻辑?本文将带…...

Subtitle Edit:从零到精通的四阶字幕编辑路径
Subtitle Edit:从零到精通的四阶字幕编辑路径 【免费下载链接】subtitleedit the subtitle editor :) 项目地址: https://gitcode.com/gh_mirrors/su/subtitleedit 你是否曾经为字幕不同步而烦恼?是否在多个字幕格式间转换时感到束手无策…...