【Python爬虫】8大模块md文档集合从0到scrapy高手,第7篇:selenium 数据提取详解

本文主要学习一下关于爬虫的相关前置知识和一些理论性的知识,通过本文我们能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度复习一下http协议。
爬虫全套笔记地址: 请移步这里
共 8 章,37 子模块
Selenium本文概要
本阶段本文主要学习selenium自动化测试框架在爬虫中的应用,selenium能够大幅降低爬虫的编写难度,但是也同样会大幅降低爬虫的爬取速度。在逼不得已的情况下我们可以使用selenium进行爬虫的编写。
selenium提取数据
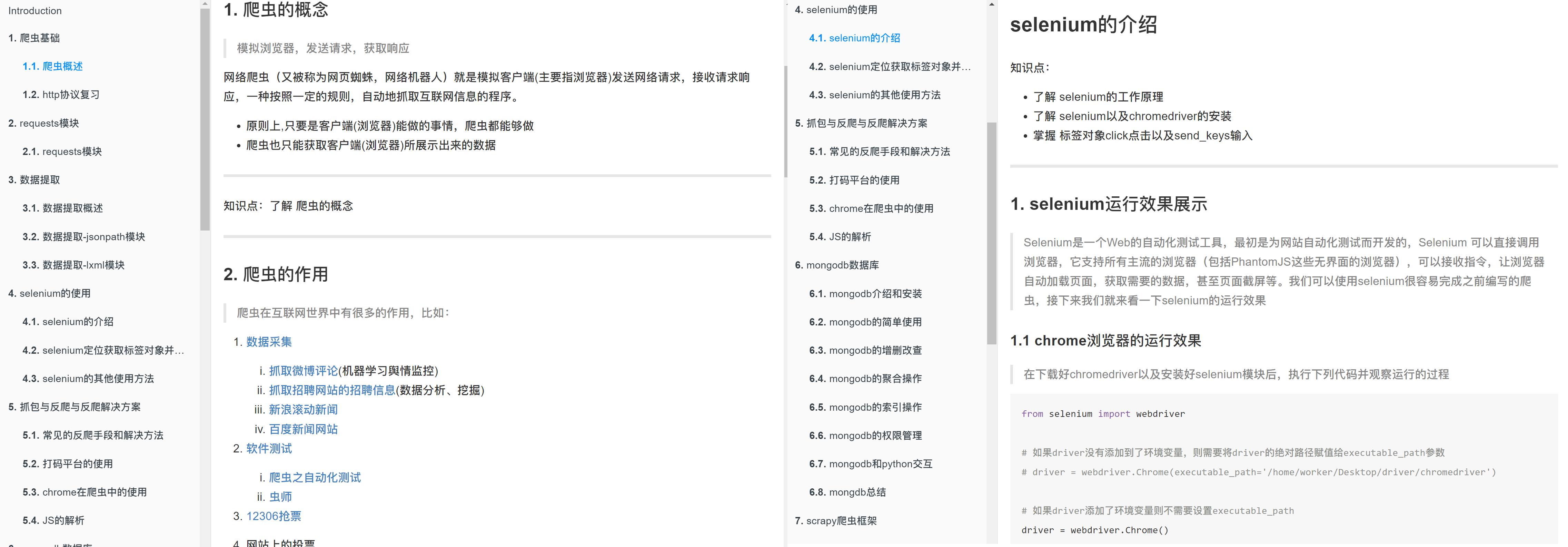
知识点:
- 了解 driver对象的常用属性和方法
- 掌握 driver对象定位标签元素标签对象的方法
- 掌握 标签对象提取文本和属性值的方法
1. driver对象的常用属性和方法
在使用selenium过程中,实例化driver对象后,driver对象有一些常用的属性和方法
driver.page_source当前标签页浏览器渲染之后的网页源代码driver.current_url当前标签页的urldriver.close()关闭当前标签页,如果只有一个标签页则关闭整个浏览器driver.quit()关闭浏览器driver.forward()页面前进driver.back()页面后退driver.screen_shot(img_name)页面截图
知识点:了解 driver对象的常用属性和方法
2. driver对象定位标签元素标签对象的方法
在selenium中可以通过多种方式来定位标签,返回标签元素对象
find_element_by_id (返回一个元素)
find_element(s)_by_class_name (根据类名元素列表)
find_element(s)_by_name (根据标签的name属性值返回包含标签对象元素的列表)
find_element(s)_by_xpath (返回一个包含元素的列表)
find_element(s)_by_link_text (根据连接文本元素列表)
find_element(s)_by_partial_link_text (根据链接包含的文本元素列表)
find_element(s)_by_tag_name (根据标签名元素列表)
find_element(s)_by_css_selector (根据css选择器来元素列表)
-
注意:
-
find_element和find_elements的区别:
- 多了个s就返回列表,没有s就返回匹配到的第一个标签对象
- find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
-
by_link_text和by_partial_link_tex的区别:全部文本和包含某个文本
-
以上函数的使用方法
driver.find_element_by_id('id_str')
-
知识点:掌握 driver对象定位标签元素标签对象的方法
3. 标签对象提取文本内容和属性值
find_element仅仅能够元素,不能够直接其中的数据,如果需要数据需要使用以下方法
-
对元素执行点击操作
element.click()- 对定位到的标签对象进行点击操作
-
向输入框输入数据
element.send_keys(data)- 对定位到的标签对象输入数据
-
文本
element.text- 通过定位的标签对象的
text属性,文本内容
- 通过定位的标签对象的
-
属性值
element.get_attribute("属性名")- 通过定位的标签对象的
get_attribute函数,传入属性名,来属性的值
- 通过定位的标签对象的
-
代码实现,如下:
from selenium import webdriverdriver = webdriver.Chrome()driver.get('http://www.itcast.cn/')ret = driver.find_elements_by_tag_name('h2')
print(ret[0].text) # ret = driver.find_elements_by_link_text('黑马程序员')
print(ret[0].get_attribute('href'))driver.quit()
selenium的其它使用方法
知识点:
- 掌握 selenium控制标签页的切换
- 掌握 selenium控制iframe的切换
- 掌握 利用seleniumcookie的方法
- 掌握 手动实现页面等待
- 掌握 selenium控制浏览器执行js代码的方法
- 掌握 selenium开启无界面模式
- 了解 selenium使用代理ip
- 了解 selenium替换user-agent
1. selenium标签页的切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要我们做以下两步:
-
所有标签页的窗口句柄
-
利用窗口句柄字切换到句柄指向的标签页
- 这里的窗口句柄是指:指向标签页对象的标识
- 关于句柄请课后了解更多,本小节不做展开
-
具体的方法
# 1. 当前所有的标签页的句柄构成的列表current_windows = driver.window_handles# 2. 根据标签页句柄列表索引下标进行切换driver.switch_to.window(current_windows[0])
- 参考代码示例:
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.baidu.com/")time.sleep(1)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)# 通过执行js来新开一个标签页js = 'window.open("https://www.sogou.com");'
driver.execute_script(js)
time.sleep(1)# 1. 当前所有的窗口windows = driver.window_handlestime.sleep(2)# 2. 根据窗口索引进行切换driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])time.sleep(6)
driver.quit()
知识点:掌握 selenium控制标签页的切换
2. switch_to切换frame标签
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是driver.switch_to.frame(frame_element)。接下来我们通过qq邮箱模拟登陆来学习这个知识点
- 参考代码:
import time
from selenium import webdriverdriver = webdriver.Chrome()url = 'https://mail.qq.com/cgi-bin/loginpage'
driver.get(url)
time.sleep(2)login_frame = driver.find_element_by_id('login_frame') # 根据id定位 frame元素
driver.switch_to.frame(login_frame) # 转向到该frame中driver.find_element_by_xpath('//*[@id="u"]').send_keys('1596930226@qq.com')
time.sleep(2)driver.find_element_by_xpath('//*[@id="p"]').send_keys('hahamimashicuode')
time.sleep(2)driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(2)"""操作frame外边的元素需要切换出去"""
windows = driver.window_handles
driver.switch_to.window(windows[0])content = driver.find_element_by_class_name('login_pictures_title').text
print(content)driver.quit()
-
总结:
-
切换到定位的frame标签嵌套的页面中
driver.switch_to.frame(通过find_element_by函数定位的frame、iframe标签对象)
-
利用切换标签页的方式切出frame标签
-
windows = driver.window_handles driver.switch_to.window(windows[0])
-
-
知识点:掌握 selenium控制frame标签的切换
3. selenium对cookie的处理
selenium能够帮助我们处理页面中的cookie,比如、删除,接下来我们就学习这部分知识
3.1 cookie
driver.get_cookies()返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
# 当前标签页的全部cookie信息print(driver.get_cookies())# 把cookie转化为字典cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
3.2 删除cookie
#删除一条cookiedriver.delete_cookie("CookieName")# 删除所有的cookiedriver.delete_all_cookies()
知识点:掌握 利用seleniumcookie的方法
4. selenium控制浏览器执行js代码
selenium可以让浏览器执行我们规定的js代码,运行下列代码查看运行效果
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.itcast.cn/")
time.sleep(1)js = 'window.scrollTo(0,document.body.scrollHeight)' # js语句
driver.execute_script(js) # 执行js的方法time.sleep(5)
driver.quit()
- 执行js的方法:
driver.execute_script(js)
知识点:掌握 selenium控制浏览器执行js代码的方法
5. 页面等待
页面在加载的过程中需要花费时间等待网站服务器的响应,在这个过程中标签元素有可能还没有加载出来,是不可见的,如何处理这种情况呢?
- 页面等待分类
- 强制等待介绍
- 显式等待介绍
- 隐式等待介绍
- 手动实现页面等待
5.1 页面等待的分类
首先我们就来了解以下selenium页面等待的分类
- 强制等待
- 隐式等待
- 显式等待
5.2 强制等待(了解)
- 其实就是time.sleep()
- 缺点时不智能,设置的时间太短,元素还没有加载出来;设置的时间太长,则会浪费时间
5.3 隐式等待
-
隐式等待针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
-
在设置的时间内没有定位成功,则会报超时加载
-
示例代码
from selenium import webdriverdriver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待,最长等20秒 driver.get('https://www.baidu.com')driver.find_element_by_xpath()
5.4 显式等待(了解)
-
每经过多少秒就查看一次等待条件是否达成,如果达成就停止等待,继续执行后续代码
-
如果没有达成就继续等待直到超过规定的时间后,报超时异常
-
示例代码
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By driver = webdriver.Chrome()driver.get('https://www.baidu.com')# 显式等待WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located((By.LINK_TEXT, '好123'))) # 参数20表示最长等待20秒# 参数0.5表示0.5秒检查一次规定的标签是否存在# EC.presence_of_element_located((By.LINK_TEXT, '好123')) 表示通过链接文本内容定位标签# 每0.5秒一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行;如果不存在,直到20秒上限就抛出异常print(driver.find_element_by_link_text('好123').get_attribute('href'))
driver.quit()
5.5 手动实现页面等待
在了解了隐式等待和显式等待以及强制等待后,我们发现并没有一种通用的方法来解决页面等待的问题,比如“页面需要滑动才能触发ajax异步加载”的场景,那么接下来我们就以淘宝网首页为例,手动实现页面等待
-
原理:
- 利用强制等待和显式等待的思路来手动实现
- 不停的判断或有次数限制的判断某一个标签对象是否加载完毕(是否存在)
-
实现代码如下:
import time
from selenium import webdriver
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver')driver.get('https://www.taobao.com/')
time.sleep(1)# i = 0# while True:for i in range(10):i += 1try:time.sleep(3)element = driver.find_element_by_xpath('//div[@class="shop-inner"]/h3[1]/a')print(element.get_attribute('href'))breakexcept:js = 'window.scrollTo(0, {})'.format(i*500) # js语句driver.execute_script(js) # 执行js的方法
driver.quit()
知识点:掌握 手动实现页面等待
6. selenium开启无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的,这一小节我们就来学习如何开启无界面模式(又称之为无头模式)
-
开启无界面模式的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加开启无界面模式的命令
options.add_argument("--headless")
-
配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome(chrome_options=options)
-
-
注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
-
参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument("--headless") # 开启无界面模式
options.add_argument("--disable-gpu") # 禁用gpu# options.set_headles() # 无界面模式的另外一种开启方式driver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象driver.get('http://www.itcast.cn')
print(driver.title)
driver.quit()
知识点:掌握 selenium开启无界面模式
7. selenium使用代理ip
selenium控制浏览器也是可以使用代理ip的!
-
使用代理ip的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加使用代理ip的命令
options.add_argument('--proxy-server=http://202.20.16.82:9527')
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
-
参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument('--proxy-server=http://202.20.16.82:9527') # 使用代理ipdriver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象driver.get('http://www.itcast.cn')
print(driver.title)
driver.quit()
知识点:了解 selenium使用代理ip
8. selenium替换user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,这一小节我们就来学习使用不同的User-Agent
-
替换user-agent的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
-
参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument('--user-agent=Mozilla/5.0 HAHA') # 替换User-Agentdriver = webdriver.Chrome('./chromedriver', chrome_options=options)driver.get('http://www.itcast.cn')
print(driver.title)
driver.quit()
知识点:了解 selenium替换user-agent
反爬与反反爬
本阶段本文主要学习爬虫的反爬及应对方法。
未完待续 下一期下一章
全套笔记直接地址: 请移步这里
相关文章:
【Python爬虫】8大模块md文档集合从0到scrapy高手,第7篇:selenium 数据提取详解
本文主要学习一下关于爬虫的相关前置知识和一些理论性的知识,通过本文我们能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度复习一下http协议。 爬虫全套笔记地址: 请移步这里 共 8 章&#x…...

【python基础(三)】操作列表:for循环、正确缩进、切片的使用、元组
文章目录 一. 遍历整个列表1. 在for循环中执行更多操作2. 在for循环结束后执行一些操作 二. 避免缩进错误三. 创建数值列表1. 使用函数range()2. 使用range()创建数字列表3. 指定步长。4. 对数字列表执行简单的统计计算5. 列表解析 五. 使用列表的一部分-切片1. 切片2. 遍历切片…...

使用VSCode调试全志R128的C906 RISC-V核心
使用 VSCode 调试 调试 XuanTie C906 核心 准备工具 T-Head DebugServer(CSkyDebugServer) - 搭建调试服务器 下载地址:T-Head DebugServer手册:T-Head Debugger Server User Guide驱动:cklink_dirvers VSCode - 开…...

Node.js之http模块
http模块是什么? http 模块是 Node,js 官方提供的、用来创建 web 服务器的模块。通过 http 模块提供的 http.createServer() 方法,就能方便的把一台普通的电脑,变成一台Web 服务器,从而对外提供 Web 资源服务。 如果我们想在node…...
golang 断点调试
1.碰见如下报错,调试器没有打印变量信息 Delve is too old for Go version 1.21.2 (maximum supported version 1.19) 2. 解决办法 升级delve delve是go语言的debug工具。 go install github.com/go-delve/delve/cmd/dlvlatest报错 Get “https://proxy.golang.org/github…...

定时器如何计算触发频率?
定时器触发频率的计算公式为:定时器时钟频率/(预分频系数*计数周期1)。其中,定时器时钟频率是指定时器所连接的总线频率,预分频系数和计数周期需要根据具体的需求进行设置。预分频系数用于将总线频率分频,计…...

【数据库】数据库中的检查点Checkpoint,数据落盘的重要时刻
检查点(checkpoint) 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定…...
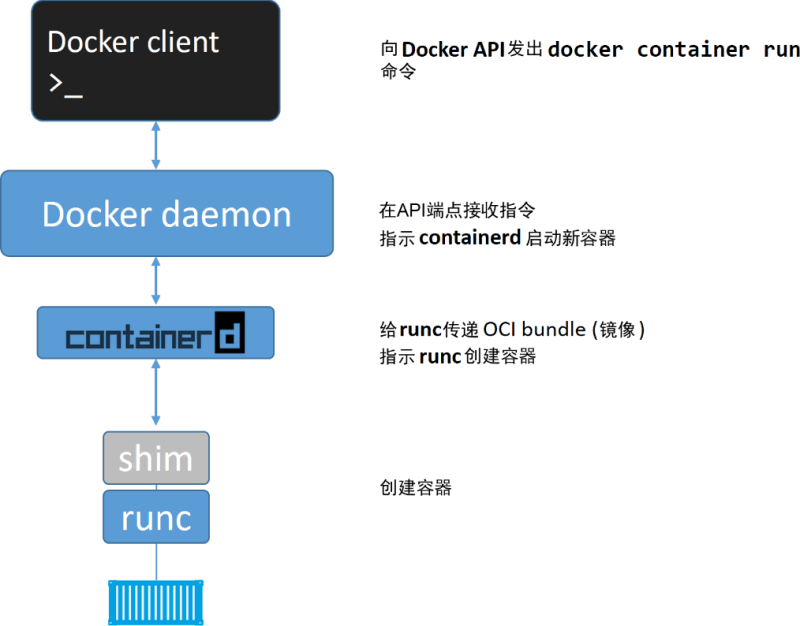
关于 Docker
关于 Docker 1. 术语Docker Enginedockerd(Docker daemon)containerdOCI (Open Container Initiative)runcDocker shimCRI (Container Runtime Interface)CRI-O 2. 容器启动过程在 Linux 中的实现daemon 的作用 Docker 是个划时代的开源项目,…...

LeetCode解法汇总2342. 数位和相等数对的最大和
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个下…...

数据库的级联删除
级联删除是指在数据库中删除一个对象时,与该对象有关的其他对象也被自动删除。在 Django 中,级联删除通常通过在模型中定义外键时使用 on_delete 参数来实现。以下是一些常见的 on_delete 选项: 1.models.CASCADE: 当关联的对象被删除时&…...

【Python 千题 —— 基础篇】奇数列表
题目描述 题目描述 创建奇数列表。使用 for 循环创建一个包含 20 以内奇数的列表。 输入描述 无输入。 输出描述 输出创建的列表。 示例 示例 ① 输出: 创建的奇数列表为: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]代码讲解 下面是本题的代码: #…...

当npm下载库失败时可以用cnpm替代
下载cnpm npm install -g cnpm --registryhttp://registry.npmmirror.com 然后使用cnpm代替npm下载即可 cnpm install...

PyTorch多GPU训练时同步梯度是mean还是sum?
PyTorch 通过两种方式可以进行多GPU训练: DataParallel, DistributedDataParallel. 当使用DataParallel的时候, 梯度的计算结果和在单卡上跑是一样的, 对每个数据计算出来的梯度进行累加. 当使用DistributedDataParallel的时候, 每个卡单独计算梯度, 然后多卡的梯度再进行平均.…...

Spring Framework IoC依赖注入-按Bean类型注入
Spring Framework 作为一个领先的企业级开发框架,以其强大的依赖注入(Dependency Injection,DI)机制而闻名。DI使得开发者可以更加灵活地管理对象之间的关系,而不必过多关注对象的创建和组装。在Spring Framework中&am…...
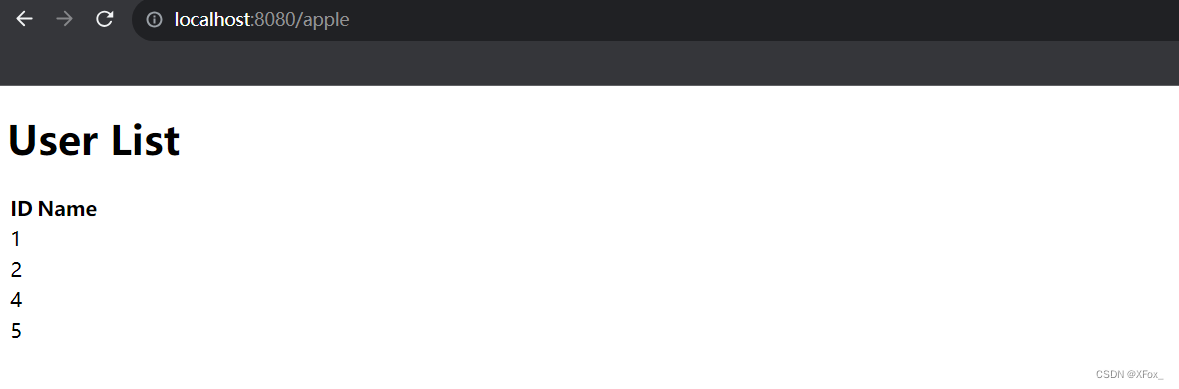
IDEA运行thymeleaf的html文件打开端口为63342且连不上数据库
这边贴apple.html代码 <!DOCTYPE html> <html xmlns:th"http://www.thymeleaf.org"> <head><meta charset"UTF-8"><title>User List</title> </head> <body> <h1>User List</h1> <table&…...

sql报错注入和联合注入
1.[NISACTF 2022]join-us 过滤: as IF rand() LEFT by updatesubstring handler union floor benchmark COLUMN UPDATE & sys.schema_auto_increment_columns && 11 database case AND right CAST FLOOR left updatexml DATABASES BENCHMARK BY sleep…...

028 - STM32学习笔记 - ADC结构体学习(二)
028 - STM32学习笔记 - 结构体学习(二) 上节对ADC基础知识进行了学习,这节在了解一下ADC相关的结构体。 一、ADC初始化结构体 在标准库函数中基本上对于外设都有一个初始化结构体xx_InitTypeDef(其中xx为外设名,例如…...
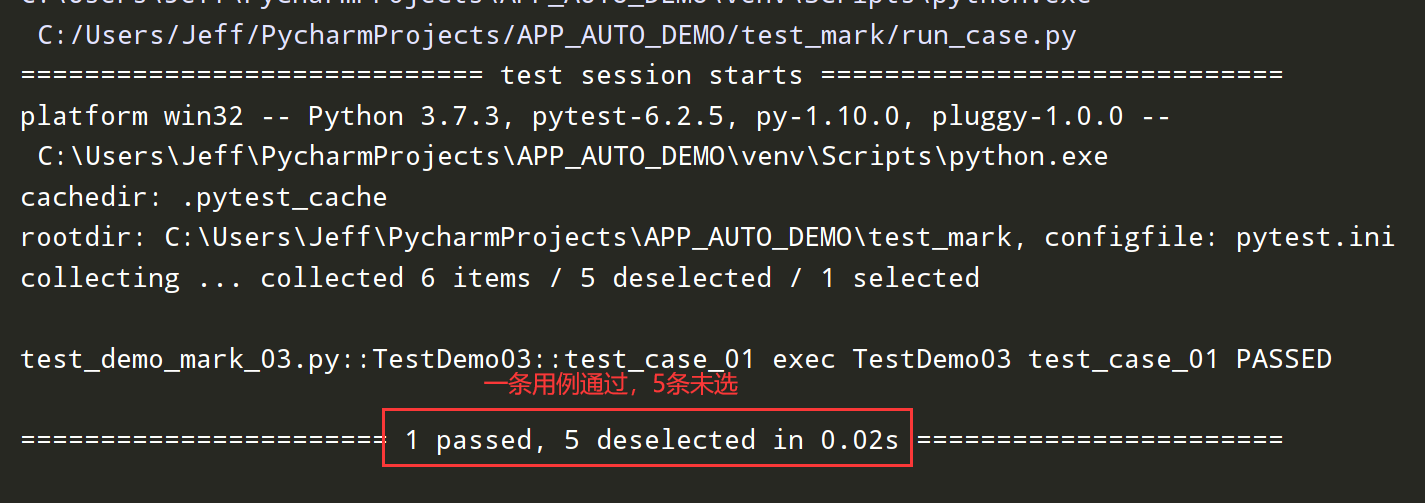
Pytest自动化测试框架:mark用法---测试用例分组执行
pytest中的mark: mark主要用于在测试用例/测试类中给用例打标记(只能使用已注册的标记名),实现测试分组功能,并能和其它插件配合设置测试方法执行顺序等。 如下图,现在需要只执行红色部分的测试方法,其它方法不执行&am…...

【TCP连接的状态】
linux查看tcp的状态命令: 1)、netstat -nat 查看TCP各个状态的数量 2)、lsof -i:port 可以检测到打开套接字的状况 3)、 sar -n SOCK 查看tcp创建的连接数 4)、tcpdump -iany tcp port 9000 对tcp端口为9000的进行抓包 查看占用端口…...
Node.js入门指南(一)
目录 Node.js入门 什么是Node.js Node.js的作用 Node.js安装 Node.js编码注意事项 Buffer(缓冲器) 定义 使用 fs模块 概念 文件写入 文件读取 文件移动与重命名 文件删除 文件夹操作 查看资源状态 路径问题 path模块 Node.js入门 什么是Node.js …...

奇点护理指南
软件测试的“健康焦虑”在软件研发的精密“造车工程”里,测试人员是把控安全与性能的质检专家。但随着软件系统复杂度呈指数级增长,测试团队正面临前所未有的“健康挑战”:迭代周期压缩导致测试深度不足,多环境兼容问题像慢性疾病…...

Ollama Colab V4:云端免费部署大语言模型的完整指南
1. 项目概述:在云端免费运行大语言模型的“瑞士军刀” 如果你对运行像 Llama、Mistral 这类开源大语言模型(LLM)感兴趣,但又苦于没有足够性能的本地显卡,或者不想在环境配置上耗费大量时间,那么 Ollama C…...

OpenClaw AI Agent会话实时监控仪表盘:零配置部署与深度使用指南
1. 项目概述:一个为AI Agent会话打造的实时监控仪表盘如果你正在使用OpenClaw这类AI Agent框架进行开发或日常使用,那你一定遇到过这样的场景:Agent在后台默默运行,处理着复杂的对话和工具调用,但你却对它的“内心活动…...

蓝牙精准定位的“内卷”之路:从RSSI、AoA到Channel Sounding,技术选型别再踩坑
蓝牙定位技术进阶指南:从米级误差到厘米级精度的实战选型策略 在智能仓储、医疗设备追踪和工业自动化等场景中,室内定位技术的精度直接决定着系统效能。当传统GPS在室内完全失效时,蓝牙技术凭借其低功耗、低成本的优势成为主流选择。但面对RS…...

Colly代码重构终极指南:提升Go爬虫框架代码质量的10个关键方法
Colly代码重构终极指南:提升Go爬虫框架代码质量的10个关键方法 【免费下载链接】colly Elegant Scraper and Crawler Framework for Golang 项目地址: https://gitcode.com/gh_mirrors/co/colly Colly作为一款优雅的Go语言爬虫框架,为开发者提供了…...

2025届最火的降重复率平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于当下的学术写作场景之中,各种各样的论文 AI 工具已然深度地融入到了研究的整个…...

别再被大小写坑了!高德地图AMap.AutoComplete插件从加载到调用的完整避坑指南
高德地图AMap.AutoComplete插件实战:从加载异常到精准搜索的完整解决方案 第一次在高德地图JS API中集成地址搜索功能时,我盯着控制台反复出现的TypeError: AMap.Autocomplete is not a constructor错误百思不得其解。这个看似简单的功能背后,…...

基于UNIX哲学的文档评审工具Recensio:命令行驱动的模块化协作方案
1. 项目概述:一个为UNIX哲学而生的文档评审工具在软件开发、系统运维乃至技术写作的日常里,我们常常面临一个看似简单却异常繁琐的任务:评审文档。无论是代码注释、API文档、配置说明还是项目报告,传统的评审方式往往陷入邮件附件…...

VIOLA框架:视频理解中的最小标注技术解析
1. 项目背景与核心价值最近在视频分析领域出现了一个让我眼前一亮的开源框架VIOLA,这个项目解决了视频理解任务中一个长期存在的痛点——标注成本过高的问题。作为一个在计算机视觉领域摸爬滚打多年的从业者,我深知视频数据标注的难度是图像标注的数十倍…...

B企业电商物流中心仓库布局和货位SLP方法【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,查看文章底部二维码(1)基于改进SLP与SHA的多目标布局优化模型:…...