【精选】OpenCV多视角摄像头融合的目标检测系统:全面部署指南&源代码
1.研究背景与意义
随着计算机视觉和图像处理技术的快速发展,人们对于多摄像头拼接行人检测系统的需求日益增加。这种系统可以利用多个摄像头的视角,实时监测和跟踪行人的活动,为公共安全、交通管理、视频监控等领域提供重要的支持和帮助。
在传统的行人检测系统中,通常只使用单个摄像头进行监测,这种方法存在一些局限性。首先,单个摄像头的视野有限,无法全面覆盖监测区域,导致行人漏检的情况较为常见。其次,由于单个摄像头的视角固定,行人在摄像头视野之外的区域无法被检测到,这给行人的追踪和监测带来了困难。此外,由于摄像头的位置和角度不同,行人在不同摄像头下的外观和姿态也会发生变化,增加了行人检测和跟踪的难度。
为了解决以上问题,基于OpenCV和ORB的多摄像头拼接行人检测系统应运而生。OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法,可以方便地进行图像的处理、特征提取和目标检测等操作。ORB(Oriented FAST and Rotated BRIEF)是一种快速的特征提取和匹配算法,具有旋转不变性和尺度不变性,适用于多摄像头拼接行人检测系统中的特征匹配和跟踪。
多摄像头拼接行人检测系统的意义在于提高行人检测的准确性和鲁棒性。通过利用多个摄像头的视角,可以全面覆盖监测区域,减少行人漏检的情况,提高检测的召回率。同时,多摄像头的布局可以使得行人在不同摄像头下的外观和姿态变化更加明显,从而提高行人检测和跟踪的准确性。此外,多摄像头拼接行人检测系统还可以实现行人的实时跟踪和轨迹分析,为公共安全和交通管理等领域提供更加全面和精确的数据支持。
总之,基于OpenCV和ORB的多摄像头拼接行人检测系统具有重要的研究意义和应用价值。通过充分利用多个摄像头的视角和特征提取算法,可以提高行人检测的准确性和鲁棒性,为公共安全和交通管理等领域提供更加全面和精确的数据支持。相信随着技术的不断进步和应用的推广,多摄像头拼接行人检测系统将在实际应用中发挥越来越重要的作用。
2.图片演示



3.视频演示
https://www.bilibili.com/video/BV1YN411z7Pi/?spm_id_from=333.999.0.0&vd_source=ff015de2d29cbe2a9cdbfa7064407a08
4.网络结构设计
在目前的行人识别研究中,提取的特征主要分为两种:全局特征和局部特征。全局特征通过提取整张行人图像的特征信息,来整体的对行人的外观进行描述。这种方法虽然十分简单并易于训练,但是在复杂的现实环境中,由于缺失细粒度特征,就会导致模型对外观相似度较高的难样本分辨能力过差。而使用行人的局部特征就可以将网络的注意力放在行人身体的部分特殊区域上,如帽子,背包等特征明显的部分。通过过滤掉行人区域外的繁杂信息的干扰,就可以学习到更具有判别力的局部细节特征,从而更好的反应难样本之间的细节差异,从而实现更好的识别效果。但是仅使用局部特征的话也会忽视行人图像的整体全局特征,而且在实际的训练中会产生特征丢失的现象,一定程度上影响网络的性能。
因此,参考该博客的代码,本文提出了一种多分支特征融合的网络结构,该网络可以将局部特征信息与全局特征信息相结合,弥补各自的缺陷。局部特征的加入可以帮助网络分辨出行人之间只靠全局特征分辨不出的微小差异,而全局特征的应用可以一定程度上缓解仅使用局部特征所造成的特征丢失的现象。该模型具有两个分支,一个是全局特征分支用于学习行人图像的全局特征,另一个是采用水平切条方式来获取行人局部特征的局部特征分支,这两个分支共享一个基于ResNet-50的主干网络。通过两种不同类型的行人图像特征的合理组合,可以为模型带来更优的识别精度。同时网络结合交叉嫡损失和三元组损失进行训练,来得到一个端到端的行人识别任务的特征提取网络。
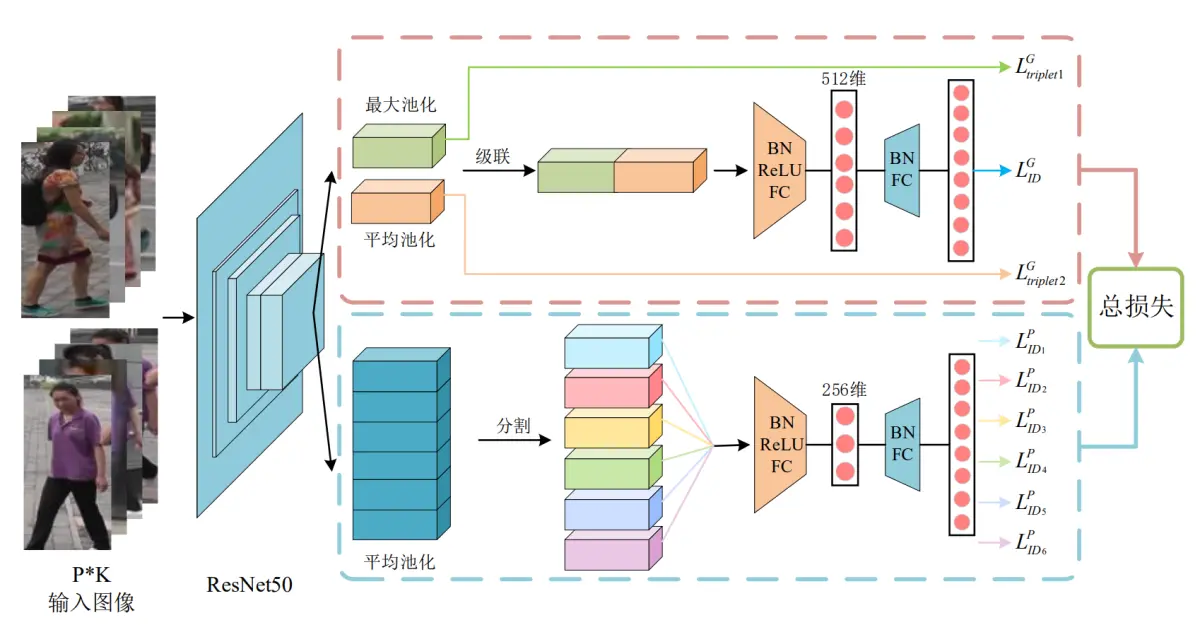
4.1.主干网络
主干网络主要用来对行人图像进行特征提取,然后将提取出的特征图分别输出到后面的局部和全局分支中去。ResNet-50在许多计算机视觉系统中表现出了很强的竞争力,并被广泛用作行人识别系统中。因此本文也选择ResNet-50作为该行人重识别模型的主干网络,并加载其在ImageNet上的预训练的网络参数。但是为了行人识别任务的需要,需要对其网络结构做出一些修改。主要是移除了其原结构中的最后一个全连接层,并增加降维模块和分类层进行多损失训练;
由于高空间分辨率可以丰富特征的粒度,所有删除了res_conv5_1块中的最后一个下采样层(down-sample);同时将最后一个卷积层的步长从2更改为1,以获得具有更高空间分辨率的特征图。例如,输入一张分辨率256×128的图片,如果其步长为2,经过网络处理后只能得到一张分辨率为8×4的特征图,而如果将其步长改为1,就能得到一个分辨率为16×8的特征图。在接下来的所有实验中,输入图像的大小总为288×144,当步长为1时,输出特征图的空间大小总为18×9。要说明的是,这个操作只增加了很小的计算成本,且没有引入其他的训练参数,但特征图空间分辨率的提高却能带来性能的提高。
4.2 全局特征分支
参考该博客代码的方案,在全局特征分支被设置在主干网络之后用于学习行人图像的全局特征。它将主干网络输出的特征图作为输入,其尺寸为[1,2048,18,9]。其中第一个数字1代表输入图像的数量;第二个数字2048代表的是输入的特征图的通道总数;第三位数字18和第四位数字9即为输入特征图的高度和宽度。在获得前置主干网络的输入后,分别用一个输出尺寸为1×1的全局最大池化GMP和一个输出尺寸同样为1x1的全局平均池化GAP去对输入的特征图进行池化操作,得到两个尺寸为[1,2048,1,1]的特征图.然后分别对这两个特征图进行降维操作后输出两个2048维的特征向量,并分别使用两个不同的三元组损失函数对其进行训练。同时将这两个2048维的特征向量级联(Concatenate)起来得到一个4096维的特征向量,再连接一个BN层、LeakyReLU层、输出维度为512的全连接层、第二个BN层后,最后连接一个输出维度为行人数目的全连接层,并对该输出使用一个交叉嫡损失函数进行训练。
4.3 局部特征分支
为了学习行人图像的局部特征描述(Local Feature Representations)来提高网络模型重识别的能力,设计了该局部特征分支。不同与上面的全局特征分支用两个尺寸为1x1的池化层进行池化操作,在局部特征分支中仅使用一个输出尺寸为6×1的全局平均池化GAP来对主干网络输出的特征图进行池化操作。池化操作后会得到一个尺寸为[1,2048,6,1]的特征图,然后对其第三个维度进行分割,可以得到6个不同的尺寸为[1,2048,1,1]特征图。相当于将一张行人图像水平划分为6块,拆分后的每一个特征图分别对应其中的一块。然后对上面的6个特征图进行降维操作,得到6个2048维的特征向量。同样的将这6个特征向量分别连接一个BN层、LeakyReLU层、256维的全连接层、第二个BN层,一个维度为行人ID数的全连接层,最后使用6个交叉嫡损失函数分别对6个输出进行训练。

5.核心代码讲解
5.1 match.py
class ImageStitcher:def __init__(self, src, des):self.src = srcself.des = desself.GOOD_POINTS_LIMITED = 0.99def stitch_images(self):img1_3 = cv.imread(self.src, 1) # 基准图像img2_3 = cv.imread(self.des, 1) # 拼接图像orb = cv.ORB_create()kp1, des1 = orb.detectAndCompute(img1_3, None)kp2, des2 = orb.detectAndCompute(img2_3, None)bf = cv.BFMatcher.create()matches = bf.match(des1, des2)matches = sorted(matches, key=lambda x: x.distance)goodPoints = []for i in range(len(matches) - 1):if matches[i].distance < self.GOOD_POINTS_LIMITED * matches[i + 1].distance:goodPoints.append(matches[i])src_pts = np.float32([kp1[m.queryIdx].pt for m in goodPoints]).reshape(-1, 1, 2)dst_pts = np.float32([kp2[m.trainIdx].pt for m in goodPoints]).reshape(-1, 1, 2)M, mask = cv.findHomography(dst_pts, src_pts, cv.RHO)h1, w1, p1 = img2_3.shapeh2, w2, p2 = img1_3.shapeh = np.maximum(h1, h2)w = np.maximum(w1, w2)......dst = cv.add(dst1, imageTransform)dst_no = np.copy(dst)dst_target = np.maximum(dst1, imageTransform)return dst_target
这个程序文件名为match.py,主要功能是进行图像匹配和拼接。程序的大致流程如下:
- 导入所需的库:numpy、cv2、matplotlib等。
- 定义了一个常量GOOD_POINTS_LIMITED,用于筛选匹配点。
- 读取两张图像作为基准图像和拼接图像。
- 使用ORB算法检测并计算图像的特征点和特征描述符。
- 创建一个暴力匹配器bf,并使用它对两张图像的特征描述符进行匹配。
- 对匹配结果进行排序,并筛选出距离较近的好的匹配点。
- 使用cv.drawMatches函数绘制匹配结果图像。
- 提取好的匹配点的坐标,用于计算透视变换矩阵。
- 使用cv.findHomography函数计算透视变换矩阵M。
- 获取原图像的高和宽,并计算拼接后图像的大小。
- 使用cv.warpPerspective函数对拼接图像进行透视变换。
- 使用cv.warpAffine函数对基准图像进行仿射变换。
- 将两张变换后的图像进行叠加,得到最终的拼接结果。
- 使用matplotlib库绘制图像,并保存结果图像。
- 显示拼接结果图像,并等待用户按键退出。
总体来说,这个程序实现了图像匹配和拼接的功能,通过ORB算法检测图像的特征点和特征描述符,使用暴力匹配器进行匹配,筛选出好的匹配点,并利用透视变换和仿射变换将两张图像拼接在一起。最终将拼接结果保存并显示出来。
5.2 sift.py
class Stitcher:def __init__(self):global modelmodel = ['ORB', 'SIFT', 'SURF', 'BRISK', 'AKAZE']# determine if we are using OpenCV v3.Xself.isv3 = imutils.is_cv3()def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):(imageB, imageA) = imagesstart = time.time()(kpsA, featuresA) = self.detectAndDescribe(imageA)end = time.time()print('%.5f s' % (end - start))(kpsB, featuresB) = self.detectAndDescribe(imageB)start = time.time()M = self.matchKeypoints(kpsA, kpsB,featuresA, featuresB, ratio, reprojThresh)end = time.time()print('%.5f s' % (end - start))if M is None:return Noneif showMatches:start = time.time()vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,status)end = time.time()print('%.5f s' % (end - start))return (result, vis)return resultdef detectAndDescribe(self, image):global modelgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)if self.isv3:descriptor = cv2.xfeatures2d.SIFT_create()(kps, features) = descriptor.detectAndCompute(image, None)else:detector = cv2.FeatureDetector_create(model[0])kps = detector.detect(gray)extractor = cv2.DescriptorExtractor_create(model[0])(kps, features) = extractor.compute(gray, kps)kps = np.float32([kp.pt for kp in kps])return (kps, features)def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB,ratio, reprojThresh):matcher = cv2.DescriptorMatcher_create("BruteForce")rawMatches = matcher.knnMatch(featuresA, featuresB, 2)matches = []for m in rawMatches:if len(m) == 2 and m[0].distance < m[1].distance * ratio:matches.append((m[0].trainIdx, m[0].queryIdx))......return Nonedef drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):(hA, wA) = imageA.shape[:2](hB, wB) = imageB.shape[:2]vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")vis[0:hA, 0:wA] = imageAvis[0:hB, wA:] = imageBfor ((trainIdx, queryIdx), s) in zip(matches, status):if s == 1:ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))cv2.line(vis, ptA, ptB, (0, 255, 0), 1)return vis该程序文件名为sift.py,是一个图像拼接的程序。程序通过使用SIFT算法来检测关键点和提取局部不变特征,并使用RANSAC算法进行特征匹配。程序中还包含了一个Stitcher类,该类包含了拼接图像的方法。程序还使用了OpenCV库来处理图像和视频。程序通过读取两个视频文件来获取图像,并将两个图像进行拼接。拼接的结果可以通过设置showMatches参数来显示两个图像特征的匹配情况。程序会不断循环读取视频帧并进行拼接,直到按下键盘上的q键退出程序。
5.3 test.py
class Stitcher:def __init__(self):self.isv3 = imutils.is_cv3()def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):(imageB, imageA) = imagesstart = time.time()(kpsA, featuresA) = self.detectAndDescribe(imageA)end = time.time()print('%.5f s' % (end - start))(kpsB, featuresB) = self.detectAndDescribe(imageB)start = time.time()M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)end = time.time()print('%.5f s' % (end - start))if M is None:return None(matches, H, status) = Mstart = time.time()result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))result[0:imageB.shape[0], 0:imageB.shape[1]] = imageBend = time.time()print('%.5f s' % (end - start))if showMatches:start = time.time()vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)end = time.time()print('%.5f s' % (end - start))return (result, vis)return resultdef matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):matcher = cv2.DescriptorMatcher_create("BruteForce")rawMatches = matcher.knnMatch(featuresA, featuresB, 2)matches = []for m in rawMatches:if len(m) == 2 and m[0].distance < m[1].distance * ratio:matches.append((m[0].trainIdx, m[0].queryIdx))if len(matches) > 4:ptsA = np.float32([kpsA[i] for (_, i) in matches])ptsB = np.float32([kpsB[i] for (i, _) in matches])(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)return (matches, H, status)return Nonedef drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):(hA, wA) = imageA.shape[:2](hB, wB) = imageB.shape[:2]vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")vis[0:hA, 0:wA] = imageAvis[0:hB, wA:] = imageBfor ((trainIdx, queryIdx), s) in zip(matches, status):if s == 1:ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))cv2.line(vis, ptA, ptB, (0, 255, 0), 1)return vis
这个程序文件是一个图像拼接的工具,可以将两张图像拼接成一张全景图。它使用了OpenCV库和imutils库来进行图像处理和特征提取。
程序中定义了一个Stitcher类,它包含了拼接图像的方法。在拼接方法中,首先会将输入的两张图像转换为灰度图像,然后使用SIFT算法检测关键点和提取局部不变特征。接下来,会对两张图像的特征进行匹配,使用RANSAC算法计算出两张图像之间的透视变换矩阵。最后,将第二张图像通过透视变换矩阵进行变换,然后将两张图像拼接在一起。
程序还提供了一些辅助方法,如绘制匹配的特征点和保存拼接结果的方法。
在程序的主函数中,首先加载两张图像,并调用Stitcher类的拼接方法将两张图像拼接在一起。如果设置了showMatches参数为True,则会返回拼接结果和绘制了匹配特征点的图像。最后,将拼接结果保存到文件中。
整个程序的运行时间会被打印出来,方便了解程序的性能。
5.4 models\experimental.py
class CrossConv(nn.Module):# Cross Convolution Downsampledef __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):# ch_in, ch_out, kernel, stride, groups, expansion, shortcutsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, (1, k), (1, s))self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class Sum(nn.Module):# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070def __init__(self, n, weight=False): # n: number of inputssuper().__init__()self.weight = weight # apply weights booleanself.iter = range(n - 1) # iter objectif weight:self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weightsdef forward(self, x):y = x[0] # no weightif self.weight:w = torch.sigmoid(self.w) * 2for i in self.iter:y = y + x[i + 1] * w[i]else:for i in self.iter:y = y + x[i + 1]return yclass MixConv2d(nn.Module):# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategysuper().__init__()n = len(k) # number of convolutionsif equal_ch: # equal c_ per groupi = torch.linspace(0, n - 1E-6, c2).floor() # c2 indicesc_ = [(i == g).sum() for g in range(n)] # intermediate channelselse: # equal weight.numel() per groupb = [c2] + [0] * na = np.eye(n + 1, n, k=-1)a -= np.roll(a, 1, axis=1)a *= np.array(k) ** 2a[0] = 1c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = bself.m = nn.ModuleList([nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU()def forward(self, x):return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))class Ensemble(nn.ModuleList):# Ensemble of modelsdef __init__(self):super().__init__()def forward(self, x, augment=False, profile=False, visualize=False):y = []for module in self:y.append(module(x, augment, profile, visualize)[0])# y = torch.stack(y).max(0)[0] # max ensemble# y = torch.stack(y).mean(0) # mean ensembley = torch.cat(y, 1) # nms ensemblereturn y, None # inference, train outputdef attempt_load(weights, map_location=None, inplace=True, fuse=True):from models.yolo import Detect, Model# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=amodel = Ensemble()for w in weights if isinstance(weights, list) else [weights]:ckpt = torch.load(attempt_download(w), map_location=map_location) # loadif fuse:model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 modelelse:model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse# Compatibility updatesfor m in model.modules():if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:m.inplace = inplace # pytorch 1.7.0 compatibilityif type(m) is Detect:if not isinstance(m.anchor_grid, list): # new Detect Layer compatibilitydelattr(m, 'anchor_grid')setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)elif type(m) is Conv:m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibilityif len(model) == 1:return model[-1] # return modelelse:print(f'Ensemble created with {weights}\n')for k in ['names']:setattr(model, k, getattr(model[-1], k))model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stridereturn model # return ensemble
文件中定义了以下几个类:
-
CrossConv:交叉卷积下采样模块。它包含了两个卷积层,用于将输入特征图进行下采样。可以选择是否添加shortcut连接。
-
Sum:多个层的加权和模块。可以选择是否对不同层的特征图进行加权求和。
-
MixConv2d:混合深度卷积模块。它包含了多个不同尺寸的卷积核,用于提取不同尺度的特征。
-
Ensemble:模型集合模块。可以将多个模型组合成一个集合,用于进行推理。
此外,文件还定义了一个辅助函数attempt_load,用于加载模型权重。
以上就是这个程序文件的概述。
6.系统整体结构
整体功能和构架概述:
该程序是一个图像处理和目标检测的工具,主要实现了图像匹配、图像拼接、特征提取、模型训练和推理等功能。它使用了多个模块和文件来实现不同的功能,包括图像处理、模型构建、数据集处理、工具函数等。
下表整理了每个文件的功能:
| 文件路径 | 功能概述 |
|---|---|
| code.py | 主程序文件,实现图像处理和目标检测的整体流程 |
| match.py | 图像匹配和拼接的功能实现 |
| sift.py | 图像拼接的实验模块 |
| test.py | 图像拼接工具,将两张图像拼接成一张全景图 |
| ui.py | 用户界面模块,提供图形界面交互 |
| models\common.py | 公共模型组件和函数 |
| models\experimental.py | 实验性模型和功能 |
| models_init_.py | 模型模块的初始化文件 |
| utils\activations.py | 激活函数的实现 |
| utils\augmentations.py | 数据增强函数的实现 |
| utils\autoanchor.py | 自动锚框生成的功能实现 |
| utils\autobatch.py | 自动批处理的功能实现 |
| utils\callbacks.py | 回调函数的实现 |
| utils\datasets.py | 数据集处理的功能实现 |
| utils\downloads.py | 下载功能的实现 |
| utils\general.py | 通用工具函数的实现 |
| utils\loss.py | 损失函数的实现 |
| utils\metrics.py | 评估指标的实现 |
| utils\plots.py | 绘图函数的实现 |
| utils\torch_utils.py | PyTorch工具函数的实现 |
| utils_init_.py | 工具模块的初始化文件 |
| utils\aws\resume.py | AWS平台的模型恢复功能实现 |
| utils\aws_init_.py | AWS模块的初始化文件 |
| utils\flask_rest_api\example_request.py | Flask REST API的示例请求 |
| utils\flask_rest_api\restapi.py | Flask REST API的实现 |
| utils\loggers_init_.py | 日志记录模块的初始化文件 |
| utils\loggers\wandb\log_dataset.py | 使用WandB记录数据集的功能实现 |
| utils\loggers\wandb\sweep.py | 使用WandB进行超参数搜索的功能实现 |
| utils\loggers\wandb\wandb_utils.py | WandB工具函数的实现 |
| utils\loggers\wandb_init_.py | WandB模块的初始化文件 |
以上是对每个文件功能的简要概述。由于文件较多,具体的功能实现可能还包括更多细节。
7.系统整合
下图完整源码&环境部署视频教程&自定义UI界面

参考博客《OpenCV多摄像头融合目标检测系统(部署教程&源码)》
8.参考文献
[1]罗浩,姜伟,范星,等.基于深度学习的行人重识别研究进展[J].自动化学报.2019,(11).DOI:10.16383/j.aas.c180154.
[2]佚名.Person re-identification with dictionary learning regularized by stretching regularization and label consistency constraint[J].Neurocomputing.2020,379(Feb.28).356-369.DOI:10.1016/j.neucom.2019.11.001.
[3]Xiang Bai,Mingkun Yang.Deep-Person: Learning discriminative deep features for person Re-Identification[J].Pattern Recognition.2020.98107036.DOI:10.1016/j.patcog.2019.107036.
[4]Lin, Yutian,Zheng, Liang,Zheng, Zhedong,等.Improving person re-identification by attribute and identity learning[J].Pattern Recognition: The Journal of the Pattern Recognition Society.2019.95151-161.DOI:10.1016/j.patcog.2019.06.006.
[5]Huafeng Li,Shuanglin Yan,Zhengtao Yu,等.Attribute-Identity Embedding and Self-Supervised Learning for Scalable Person Re-Identification[J].Circuits & Systems for Video Technology, IEEE Transactions on.2019,30(10).3472-3485.DOI:10.1109/TCSVT.2019.2952550.
[6]Li, Huafeng,Xu, Jiajia,Zhu, Jinting,等.Top distance regularized projection and dictionary learning for person re-identification[J].Information Sciences: An International Journal.2019.502472-491.DOI:10.1016/j.ins.2019.06.046.
[7]Zhedong Zheng,Liang Zheng,Yi Yang.Pedestrian Alignment Network for Large-scale Person Re-Identification[J].Circuits & Systems for Video Technology, IEEE Transactions on.2018,29(10).3037-3045.DOI:10.1109/TCSVT.2018.2873599.
[8]Hao Liu,Jiashi Feng,Meibin Qi,等.End-to-End Comparative Attention Networks for Person Re-Identification[J].IEEE Transactions on Image Processing.2017,26(7).3492-3506.DOI:10.1109/TIP.2017.2700762.
[9]Dapeng Tao,Yanan Guo,Baosheng Yu,等.Deep Multi-View Feature Learning for Person Re-Identification[J].IEEE Transactions on Circuits & Systems for Video Technology.2017,28(10).2657-2666.
[10]Zhao, Rui,Ouyang, Wanli,Wang, Xiaogang.Unsupervised Salience Learning for Person Re-identification[C].2013.
相关文章:
【精选】OpenCV多视角摄像头融合的目标检测系统:全面部署指南&源代码
1.研究背景与意义 随着计算机视觉和图像处理技术的快速发展,人们对于多摄像头拼接行人检测系统的需求日益增加。这种系统可以利用多个摄像头的视角,实时监测和跟踪行人的活动,为公共安全、交通管理、视频监控等领域提供重要的支持和帮助。 …...

力扣算法练习BM45—滑块窗口的最大值
题目 给定一个长度为 n 的数组 num 和滑动窗口的大小 size ,找出所有滑动窗口里数值的最大值。 例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针…...

最小二乘估计及与极大似然估计的关系
最小二乘估计(Least Squares Estimation)和极大似然估计(Maximum Likelihood Estimation)是统计学中常用的参数估计方法,它们在某些情况下是等价的,但在一般情况下并不总是相同的。 最小二乘估计ÿ…...
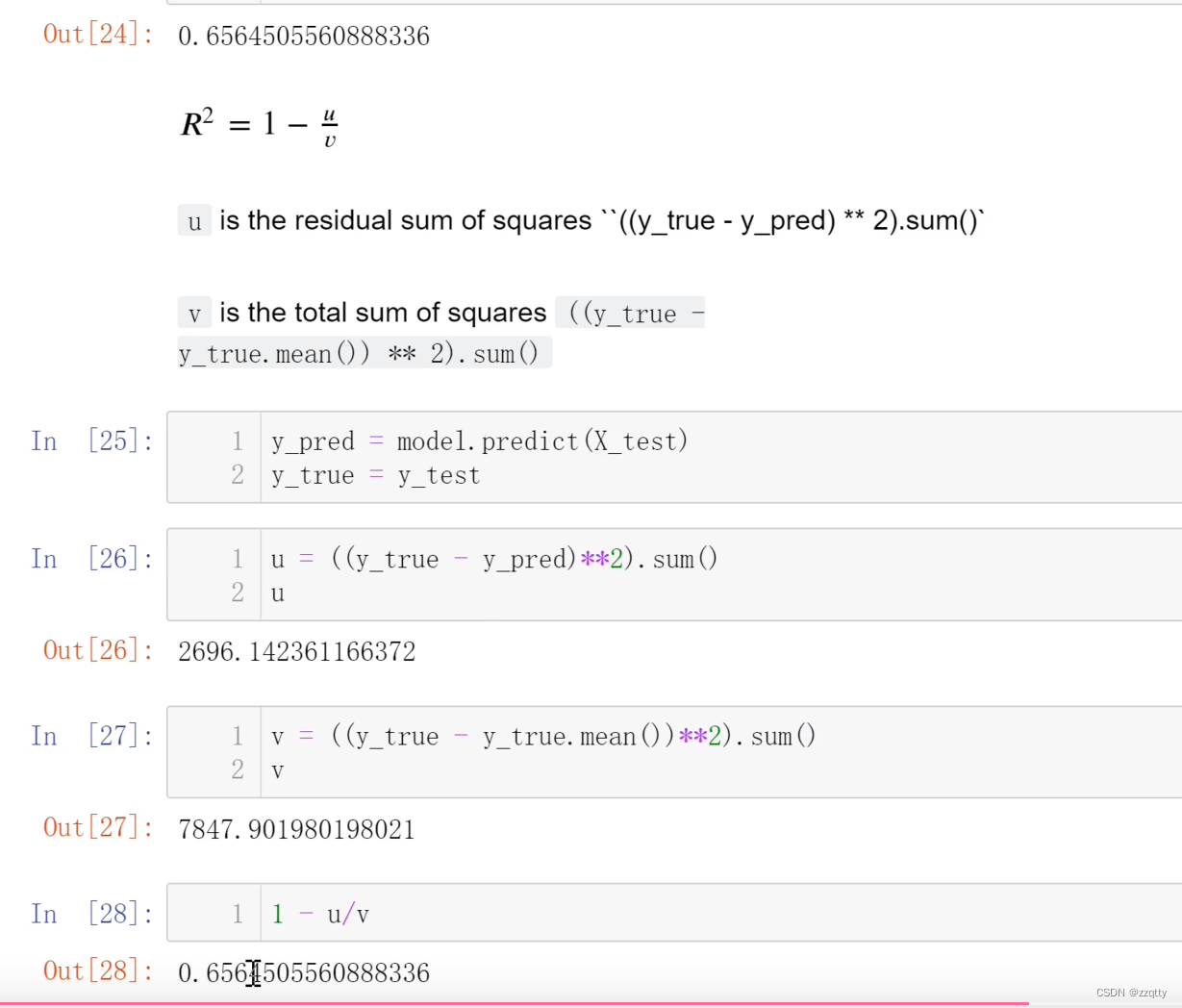
02房价预测
目录 代码 评分算法: 代码 import numpy as np from sklearn import datasets from sklearn.linear_model import LinearRegression# 指定版本才有数据集 # C:\Users\14817\PycharmProjects\pythonProject1\venv\Scripts\activate.bat # pip install scikit-le…...

【Springboot】pom.xml中的<build>标签详解
默认值及其标签解释 <build><!-- 指定最终构建产物的名称, 例如生成的 JAR 文件的名称 --><finalName>${artifactId}-${version}</finalName><!-- 指定源代码文件的目录路径 --><sourceDirectory>src/main/java</sourceDirectory>&l…...
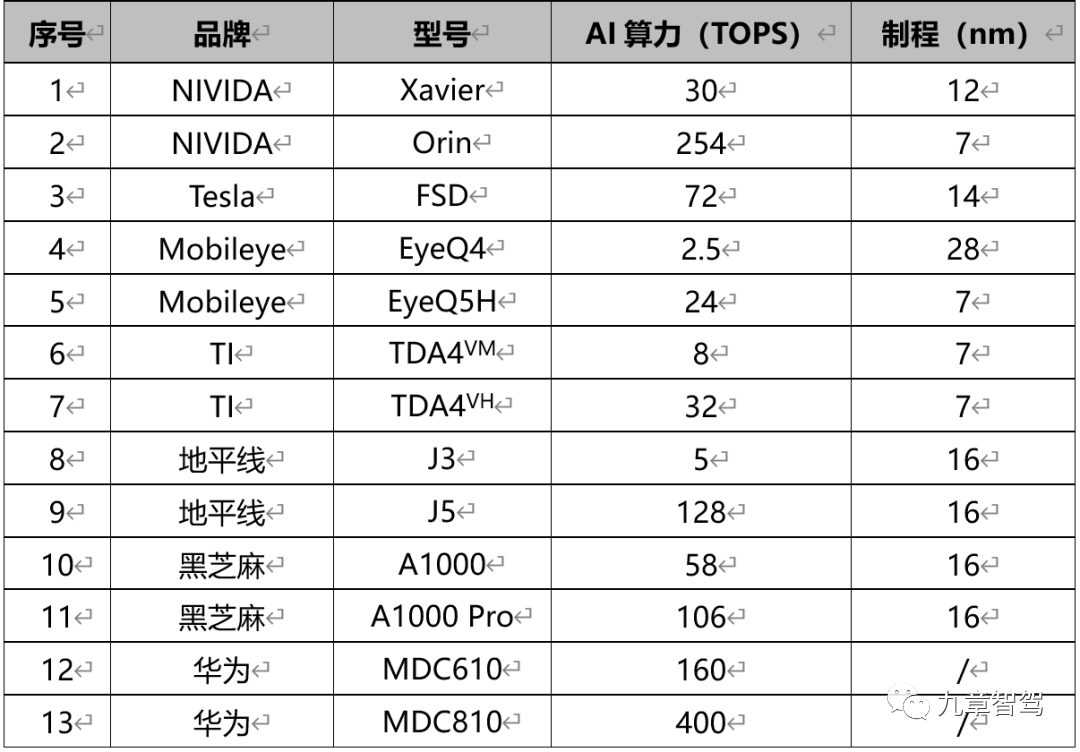
智能驾驶产品开发中如何贯彻“正向开发”理念
摘要: 基于演绎法的正向开发理念,能够让智能驾驶产品在充分满足用户需求,保证产品质量的同时,确保开发目标合理且得到落实。 前段时间,微博CEO吐槽理想L9智能驾驶“行驶轨迹不居中”,在网上引发了热烈讨论…...
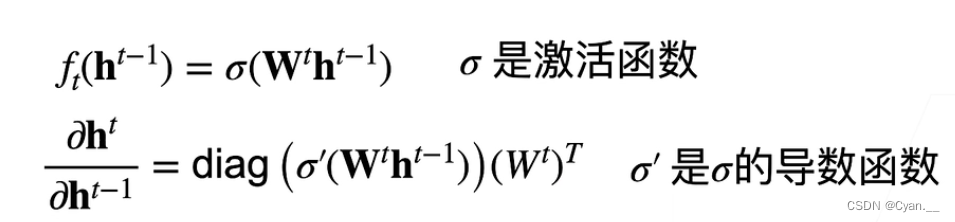
【机器学习】038_梯度消失、梯度爆炸
一、原因 神经网络梯度 假设现在有一个 层的神经网络,每层的输出为一个对输入作 变换的函数结果 用 来表示第 层的输出,那么有下列公式: 链式法则计算损失 关于某一层某个参数 的梯度: 注意到, 为向量&am…...
【转】OAK-D双目相机进行标定及标定结果说明
编辑:OAK中国 首发:A. hyhCSDN 喜欢的话,请多多👍⭐️✍ 内容来自用户的分享,如有疑问请与原作者交流! ▌前言 Hello,大家好,这里是OAK中国,我是助手君。 近期在CSDN刷…...

whip和whep
原文为runner365.git大佬的文章 原文链接:https://blog.csdn.net/sweibd/article/details/124552793 WHIP接口 什么是whip 全称: WebRTC-HTTP ingestion protocol (WHIP). rfc地址: rfc-draft-murillo-whip-00 简单说,就是通过HTTP接口能导入webrtc媒…...

SpringBoot集成jjwt和使用
1.引入jwt依赖(这里以jjwt为例,具体其他jwt产品可以参见jwt官网) <dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version> </dependency>…...

RedisConnectionFactory is required已解决!!!!
1.起因🤶🤶🤶🤶 redis搭建完成后,准备启动主程序,异常兴奋,结果报错了!!!! 2.究竟是何原因 😭😭😭…...

redis的高可用之持久化
1、redis的高可用考虑指标 (1)正常服务 (2)数据容量的扩展 (3)数据的安全性 2、redis实现高可用的四种方式 (1)持久化 (2)主从复制 (3&…...
onnx模型转换opset版本和固定动态输入尺寸
背景:之前我想把onnx模型从opset12变成opset12,太慌乱就没找着,最近找到了官网上有示例的,大爱onnx官网,分享给有需求没找着的小伙伴们。 1. onnx模型转换opset版本 官网示例: import onnx from onnx im…...
远程运维如何更高效的远程管理?向日葵的这几项功能会帮到你
远程运维如何更高效的远程管理?向日葵的这几项功能会帮到你 具备一定规模的企业,其IT运维需求普遍会面临设备数量众多、难以统一高效管理、始终存在安全敞口等问题,尤其是针对分部广泛的无人值守设备时,更是如此。 举一个简单的例…...

python BDD 的相关概念
在Python 语言中进行BDD的规格和测试文件的编写的时候,常常会遇到下面的概念: Fixture : 测试设施。设定测试环境的预设状态或值的机制。Background: 背景。所有场景的公共部分。Scenario: 场景。Given : 前置条件Whe…...

【Exception】Error: Dynamic require of “path“ is not supported
Talk is cheap, show me the code. 环境 | Environment kversionOSwindows 11Node.jsv18.14.2npm9.5.0vite5.0.0vue3.3.8 报错日志 | Error log >npm run dev> app10.0.0 dev > viteERROR failed to load config from C:\code\frontend\app1\vite.config.js …...

【蓝桥杯选拔赛真题25】C++两个数比大小 第十三届蓝桥杯青少年创意编程大赛C++编程选拔赛真题解析
目录 C/C++两个数比大小 一、题目要求 1、编程实现 2、输入输出 二、算法分析...
)
C++学习——C++运算符重载(含义、格式、示例、遵循的规则)
以下内容源于C语言中文网的学习与整理,非原创,如有侵权请告知删除。 一、运算符重载的含义 所谓重载,就是赋予新的含义。函数重载(Function Overloading)可以让一个函数名有多种功能,在不同情况下进行不同…...

【unity实战】unity3D中的PRG库存系统和换装系统(附项目源码)
文章目录 先来看看最终效果前言素材简单绘制库存UI前往mixamo获取人物模型动画获取一些自己喜欢的装备物品模型库存系统换装系统装备偏移问题添加消耗品最终效果源码完结 先来看看最终效果 前言 之前2d的换装和库存系统我们都做过不少了,这次就来学习一个3d版本的&…...

编程语言发展史:C语言的诞生及其影响
预计更新 第一部分:早期编程语言 1.1布尔代数和机器语言 1.2汇编语言的出现和发展 1.3高级语言的兴起 第二部分:主流编程语言 1.1 C语言的诞生及其影响 1.2 C语言的发展和应用 1.3 Java语言的出现和发展 1.4 Python语言的兴起和特点 1.5 JavaScript语言…...
5分钟搞定!uniApp微信小程序用户头像上传与存储完整流程(从chooseAvatar到服务器)
5分钟实现uniApp微信小程序头像上传全流程:从选择到存储的实战指南 微信小程序的头像上传功能一直是开发者关注的焦点。随着微信官方对用户隐私保护的加强,传统的wx.getUserProfile接口已不再返回真实头像,开发者需要转向更合规的chooseAvata…...

如何高效获取八大网盘直链:LinkSwift专业级下载助手实战指南
如何高效获取八大网盘直链:LinkSwift专业级下载助手实战指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 …...

ai辅助pid开发:让快马平台智能推荐参数并生成优化控制结构代码
最近在做一个化工反应釜的温度控制项目,发现传统PID调参实在太费时间了。正好试用了InsCode(快马)平台的AI辅助开发功能,整个过程顺畅了很多。这里分享下AI如何帮我们解决非线性时变系统的控制难题。 被控对象特性分析 这个反应釜系统有几个头疼的特点&…...
)
ArcGIS、Global Mapper、MATLAB三剑客,手把手教你精准裁剪DEM高程TIF文件(附代码)
ArcGIS、Global Mapper与MATLAB:DEM裁剪实战指南与工具选型策略 引言 数字高程模型(DEM)作为地理信息系统中的基础数据类型,其精确裁剪直接影响地形分析的可靠性。面对市场上主流的ArcGIS、Global Mapper和MATLAB三大工具…...

英雄联盟国服换肤神器R3nzSkin:3分钟解锁全皮肤免费体验指南
英雄联盟国服换肤神器R3nzSkin:3分钟解锁全皮肤免费体验指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟国服皮肤价格高…...

教育科技公司如何通过Taotoken为不同课程匹配最合适的大模型
教育科技公司如何通过Taotoken为不同课程匹配最合适的大模型 1. 教育场景中的多模型需求 教育科技公司在开发教学辅助工具时,不同学科对AI模型的需求差异显著。编程课程需要模型具备精准的代码生成与解释能力,文科类课程则更依赖创意写作和文本分析功能…...

体验 Taotoken 官方价折扣活动对个人项目月度开发成本的实际影响
体验 Taotoken 官方价折扣活动对个人项目月度开发成本的实际影响 1. 折扣活动参与方式 Taotoken 平台会不定期推出针对特定模型的官方价折扣活动。个人开发者可以通过平台首页的活动入口查看当前可参与的折扣方案。以近期推出的"Claude 系列模型限时 8 折"活动为例…...

从USB3.0到PCIe 5.0:高速串行链路耦合电容的‘规矩’与‘变通’全解析
从USB3.0到PCIe 5.0:高速串行链路耦合电容的设计哲学与技术演进 在数字通信领域,高速串行链路的设计犹如在钢丝上跳舞——需要在信号完整性与系统可靠性之间寻找精妙的平衡。耦合电容的放置策略,这个看似简单的设计选择,实则蕴含…...
,仅开放前500名开发者下载)
【限时开源】农业物联网C驱动SDK v2.1(含Modbus RTU/LoRaWAN双模适配层、OTA升级钩子接口),仅开放前500名开发者下载
更多请点击: https://intelliparadigm.com 第一章:农业物联网C驱动SDK v2.1整体架构与开源策略 核心设计理念 农业物联网C驱动SDK v2.1以轻量、可裁剪、跨平台为设计基石,面向资源受限的边缘传感节点(如STM32H7、ESP32-C3&#…...

解锁Windows家庭版多用户远程桌面:RDP Wrapper Library完全指南
解锁Windows家庭版多用户远程桌面:RDP Wrapper Library完全指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否正在使用Windows家庭版,却因为无法支持多用户远程桌面连接而感到困扰&…...