用一个例子告诉你 怎样使用Spark中RDD的算子
目录
1. 前言
1.1 操作分类
1.2 语法知识
2. transformations
2.1 map
2.2 mapPartitions
2.3 flatMap
2.4 glom
2.5 groupBy
2.6 filter
2.7 sample
2.8 distinct
2.9 coalesce
2.10 repartition
2.11 sortBy
2.12 partitionBy
2.13 reduceByKey
2.14 groupByKey
2.15 aggregateByKey
2.16 foldByKey
2.17 combineByKeyWithClassTag
2.18 combineByKey
2.19 sortByKey
2.20 cogroup
2.21 join、leftOuterJoin、rightOuterJoin、fullOuterJoin
2.22 intersection、union、subtract、zip
3. actions
3.1 reduce
3.2 collect
3.3 count
3.4 first
3.5 take
3.6 takeOrdered
3.7 aggregate
3.8 fold
3.9 countByKey
3.10 saveAsTextFile 、saveAsObjectFile 、 saveAsSequenceFile
3.11 foreach
1. 前言
我们可以将RDD想象成一张分布式的表,表中的数据以分区的形式分布在不同的计算节点上
对表操作称之为算子,可以用SQL的思想来理解这些操作
1.1 操作分类
在spark中,RDD支持两种类型的操作
1.transformations(转换算子)
功能:
从现有的RDD中通过某种转换规则,创建的新RDD
特点:
所有的转换操作都是懒加载,并不会立即进行转换操作
只有当驱动程序需要计算结果时,才会触发转换行为
2.actions(行动算子)
功能:
将各个计算节点上的结果数据,返回给驱动程序(客户端)
通常,我们也会将RDD的操作称之为算子,也就是人们常说 转换算子、行动算子
官方API链接: https://spark.apache.org/docs/latest/api/scala/org/apache/spark/rdd/RDD.html
1.2 语法知识
这块知识需要对scala基本语法有些了解,才会对API调用有更好的理解
什么是Lambda表达式? 传送门
什么是函数柯里化?传送门
什么是隐式转换及隐式函数?传送门
2. transformations
2.1 map
功能: 返回一个新的RDD,对父RDD的每个元素按照f函数进行转换
可以看我之前写的例子 : 传送门
重点关注:
分区内元素依次被指定Lambda表达式执行(串行),多个分区间并发执行(并行)
如果指定的Lambda表达式中存在消耗时间的逻辑(如 数据库连接、IO等)
请选择使用mapPartitions

2.2 mapPartitions
功能: 返回一个新的RDD,对父RDD每个分区按照f函数进行转换
可以看我之前写的例子 : 传送门
重点关注: 1.map和mapPartitions的区别
2.mapPartitions的使用风险和使用场景
3.Lambda表达式每次会处理整个分区的数,小心内存溢出哦😯

2.3 flatMap
功能: 返回一个新的RDD,将父RDD中每个元素转换成集合,再将集合打散
可以看我之前写的例子 : 传送门

2.4 glom
功能: 返回一个新的RDD,将父RDD每个分区中的所有元素封装到数组中去
可以看我之前写的例子 : 传送门

重点关注:
1. 用于将父RDD中每个分区的数据打包成数组
2. 不会触发shuffle操作哦
2.5 groupBy
功能: 返回一个新的RDD,对父RDD所有元素按照f函数的结果进行分组
可以看我之前写的例子 : 传送门
实现1: 使用默认分区器,分区数=父RDD分区数

实现2: 指定分区数,默认使用Hash分区器
 实现3: 使用指定分区器
实现3: 使用指定分区器

重点关注:
1.这个操作会触发shuffle操作,当数据分布不均时,可能会造成某个分区数据量过大
而导致内存溢出哦😯,也就是常说的数据倾斜
2.如果分组的目的是为了做 聚合操作,建议使用 reduceByKey、aggregateByKey
效率会高很多(这些算子,会map端先做一次聚合操作,来减少IO的数据量)
2.6 filter
功能: 返回一个新的RDD,对父RDD的所有元素按照 f(x) = true 进行过滤
可以看我之前写的例子 : 传送门

2.7 sample
功能: 返回一个新的RDD,对父RDD做抽样查询
可以看我之前写的例子 : 传送门

2.8 distinct
功能: 返回一个新的RDD,对父RDD元素去重
可以看我之前写的例子 : 传送门
实现1: 不指定分区个数

实现2: 指定分区个数

重点关注:
1. 会触发shuffle操作,会先在map端对数据去重后,再在reduce端去重
2.9 coalesce
功能: 返回一个新的RDD,增加或减少父RDD的分区个数(合并分区时,可以选择不shuffle)
可以看我之前写的例子 : 传送门

重点关注:
shuffle = true时,会触发shuffle操作,小心数据倾斜哦😱
合并分区时,建议使用 coalesce且shuffle=false
2.10 repartition
功能: 返回一个新的RDD,增加或减少父RDD的分区个数(必触发shuffle)
可以看我之前写的例子 : 传送门

重点关注:
一定会触发shuffle操作,如果是减少分区,建议使用 coalesce
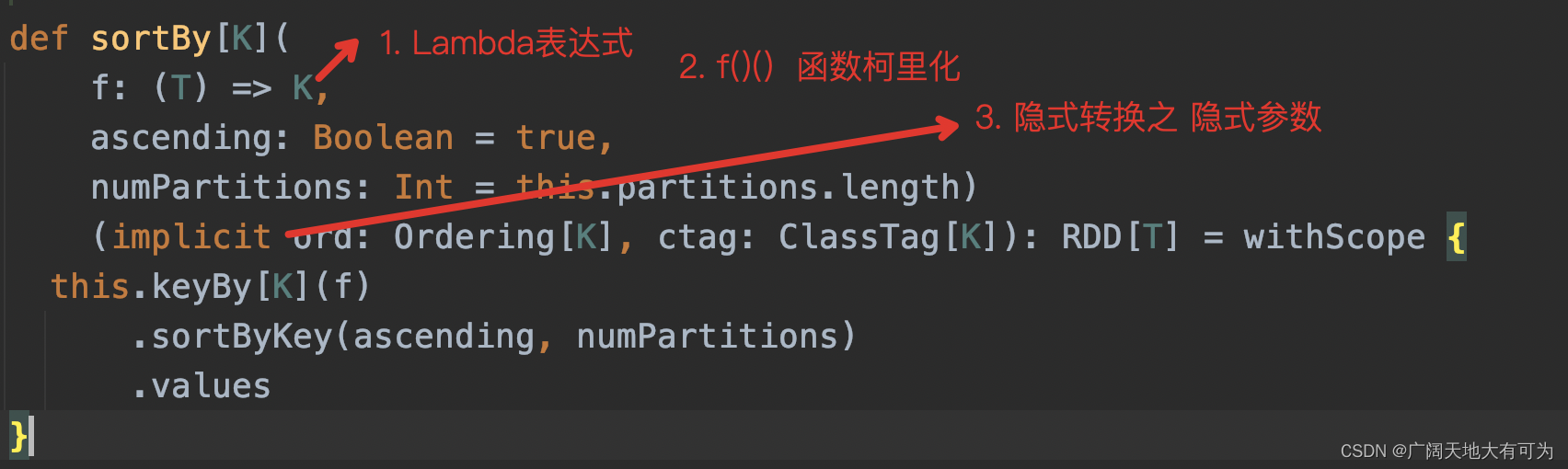
2.11 sortBy
功能: 返回一个新的RDD,对父RDD根据f函数的结果排序
可以看我之前写的例子 : 传送门

重点关注:
会触发shuflle操作,小心数据倾斜哦😱
2.12 partitionBy
功能: 返回一个新的RDD,按照指定分区器对父RDD重新分区
可以看我之前写的例子 : 传送门

注意事项:
1.当父RDD数据分布不均时,可以使用此方法将数据打散
2.13 reduceByKey
功能: 返回一个新的RDD,根据指定的聚合规则对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑相同,且没有初始值参与聚合
可以看我之前写的例子 : 传送门
实现1:

实现2:
 实现3:使用默认分区器,分区数和父RDD相同
实现3:使用默认分区器,分区数和父RDD相同

重点关注:
1. 这个方法 会先在每个map端本地做一次聚合,合并完后再发送到reduce端聚合
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.14 groupByKey
功能: 返回一个新的RDD,按照key对父RDD做分组
可以看我之前写的例子 : 传送门
实现1:

实现2:

重点关注:
1. 目前实现方式,会先将每个key的所有键值对读取到内存中,如果一个key的值过多时
就会导致OutOfMemoryError错误,使用前一定要评估数据量和内存资源
2.这个操作会触发shuffle操作,当数据分布不均时,可能会造成某个分区数据量过大
而导致内存溢出哦😯,也就是常说的数据倾斜
3.如果分组的目的是为了做 聚合操作,那么可以使用 reduceByKey、aggregateByKey
效率会高很多(这些算子,会map端先做一次聚合操作,来减少IO的数据量)
2.15 aggregateByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,且有初始值参与聚合
可以看我之前写的例子 : 传送门
方式1:
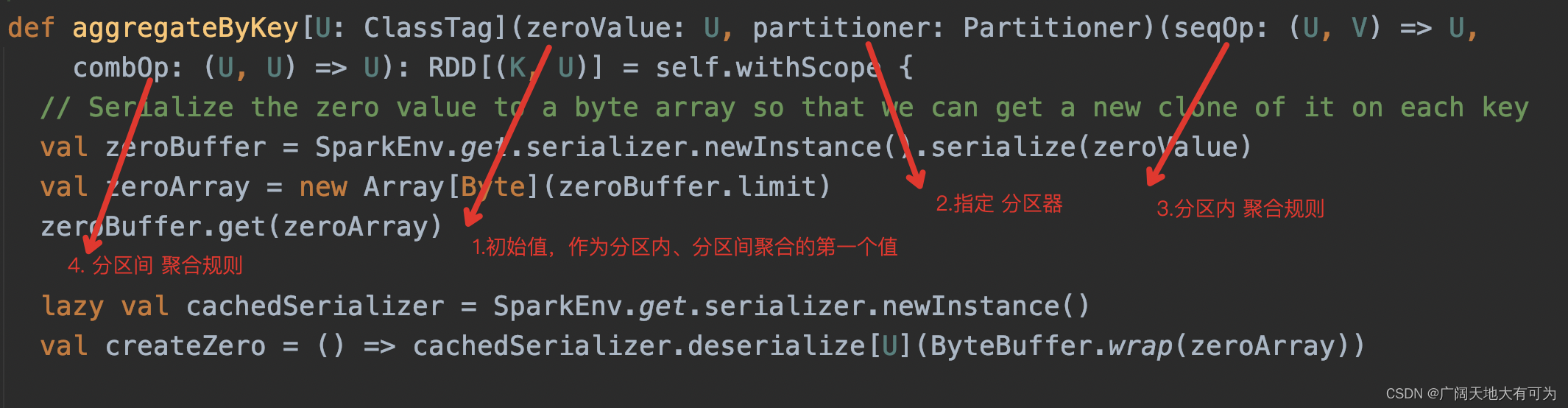 方式2:
方式2:

方式3:
 重要关注:
重要关注:
1. zeroValue值 会参与分区聚合计算和分区间聚合计算
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.16 foldByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑相同,且有初始值参与聚合
可以看我之前写的例子 : 传送门
方式1:

方式2:
 方式3:
方式3:

重要关注:
1. zeroValue值 会参与分区聚合计算和分区间聚合计算
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.17 combineByKeyWithClassTag
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,且有初始值参与聚合
并且可以转换value的数据类型
可以看我之前写的例子 : 传送门
实现1: 实现2:
实现2: 实现3:
实现3:
重点关注:
1. 这是RDD聚合操作中最通用的方法,其他聚合函数都是对它的封装
2. RDD分区数量和数据分布直接会影响聚合操作的效率,使用时注意数据分布哦
2.18 combineByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,没有初始值参与聚合
并且可以转换value的数据类型
可以看我之前写的例子 : 传送门
方式1: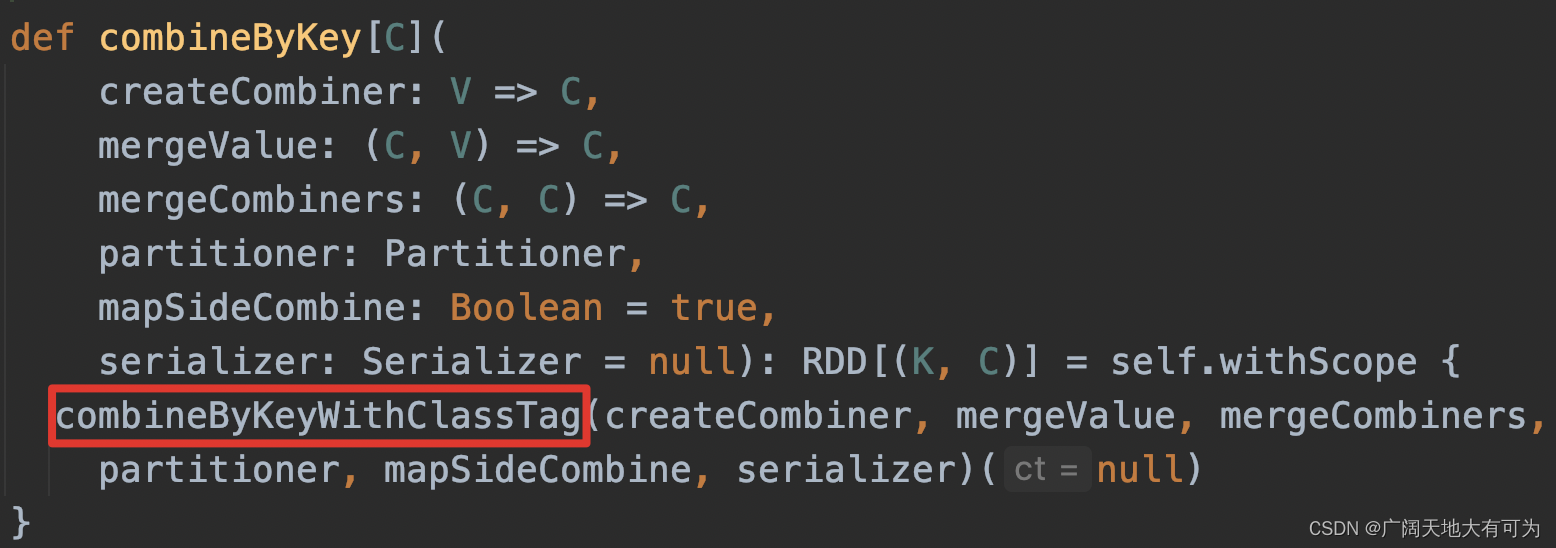 方式2:
方式2: 重点关注:
重点关注:
1. 查看源码,是对combineByKeyWithClassTag的封装
2.19 sortByKey
功能: 返回一个新的RDD,元素值为 父RDD 根据key排序的结果
可以看我之前写的例子 : 传送门

重点关注:
1. key的数据类型 必须实现 Ordered 接口(特质)
2. key类型为tuple时,无法使用该方法排序
3. 存在shuffle过程,小心数据倾斜哦
2.20 cogroup
功能: 返回一个新的RDD,元素值为 多个RDD下相同key下 各自value值的迭代器
可以看我之前写的例子 : 传送门
实现1: 实现2:
实现2:
 实现3:
实现3:
注意事项:
1. 多个RDD关联最通用的方法
2. 会触发shuffle操作,小心数据倾斜哦
2.21 join、leftOuterJoin、rightOuterJoin、fullOuterJoin
功能: 返回一个新的RDD,元素值为 多个RDD下相同key下 的各自value值
可以看我之前写的例子 : 传送门
join: leftOuterJoin:
leftOuterJoin: rightOuterJoin:
rightOuterJoin: fullOuterJoin:
fullOuterJoin: 重点关注:
重点关注:
1. 发下没有,都是通过封装 cogroup + flatMapValues 来实现的
2. 会触发shuffle操作,小心数据倾斜哦
2.22 intersection、union、subtract、zip
功能: 返回一个新的RDD,元素值为 两个RDD求交集、并集、差集 的结果
可以看我之前写的例子 : 传送门
intersection:返回两个RDD的交集,结果将不包含任何重复元素 (内部会触发shuffle过程)
union:返回多个RDD的并集,结果会有重复元素 (内部不会触发shuffle过程)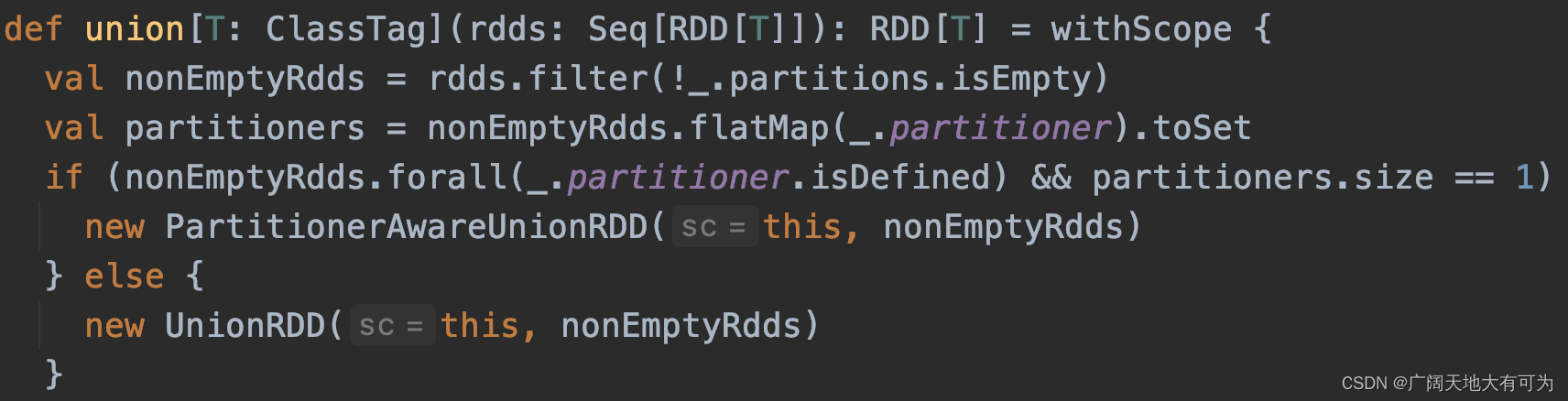
subtract:返回两个RDD的差集 (内部会触发shuffle过程)
zip:返回两个RDD按元素顺序对应的二元组 (内部不会触发shuffle过程)
3. actions
3.1 reduce
功能: 根据指定的计算规则,对RDD所有的元素依次做运算,并返回计算结果给驱动程序(Driver)
可以看我之前写的例子 : 传送门

注意事项:
1.先在每个分区内做聚合操作(Map端),再对各个分区的结果做聚合操作
如果操作不满足结合律和交换律时(如减法、除法), 当分区个数不同时,计算结果也会不同
3.2 collect
功能:返回给Driver端一个数组,数组内容为RDD所有的元素
可以看我之前写的例子 : 传送门

注意事项:
1. 当RDD元素过多时,小心Driver端内存溢出哦
3.3 count
功能:返回RDD元素个数给Driver端
可以看我之前写的例子 : 传送门

3.4 first
功能:返回RDD第一个元素的值 给Driver端
可以看我之前写的例子 : 传送门
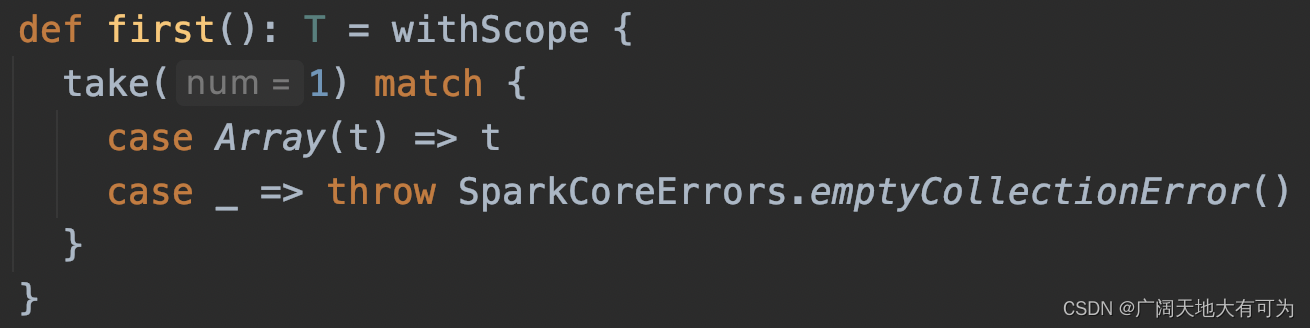
3.5 take
功能: 返回给Driver端一个数组,数组内容为RDD的前n项元素
可以看我之前写的例子 : 传送门
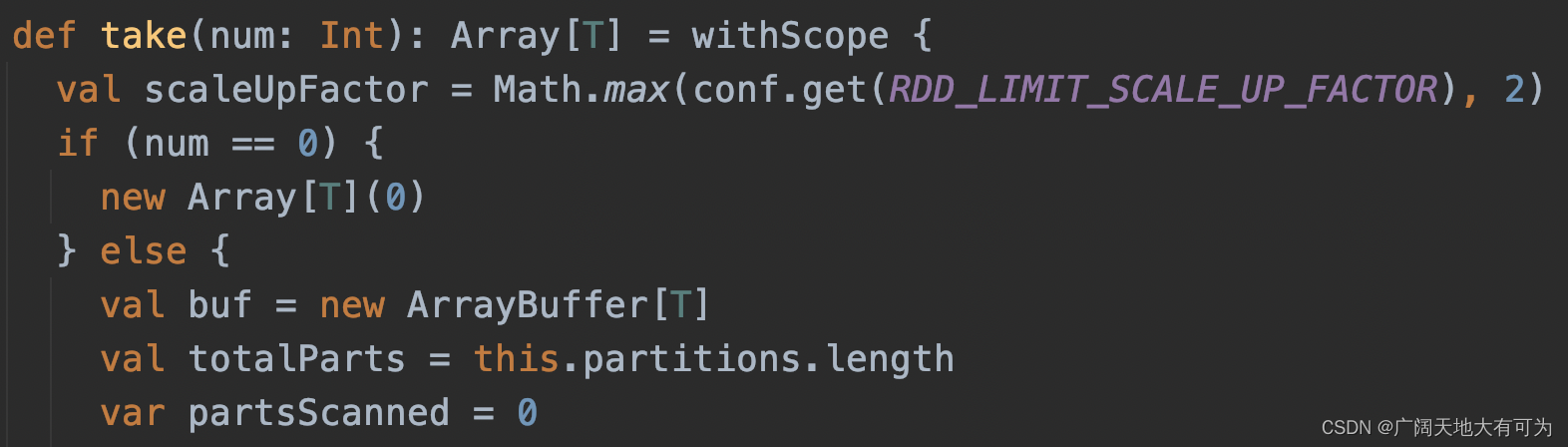 注意事项:
注意事项:
1. 当返回元素过多时,小心Driver端内存溢出哦
2. 如果在Nothing或Null的RDD上调用此方法将引发异常
3.6 takeOrdered
功能: 返回给Driver端一个数组,数组内容为RDD排序后的前n项元素
可以看我之前写的例子 : 传送门

注意事项:
1. 当返回元素过多时,小心Driver端内存溢出哦
3.7 aggregate
功能:对RDD做聚合操作,并将聚合的结果返回给Driver端
可以看我之前写的例子 : 传送门

注意事项:
1.zeroValue会参与分区内聚合运算和分区间聚合运算
通常会将它设置成一个中立元素(列表连接Nil 计数时为0)
3.8 fold
功能:对RDD做聚合操作,并将聚合的结果返回给Driver端
可以看我之前写的例子 : 传送门

3.9 countByKey
功能:计算RDD中每个key下的value的个数,并将结果返回给Driver端
可以看我之前写的例子 : 传送门

注意事项:
1. 当返回结果集过大时,小心Driver端内存溢出哦
3.10 saveAsTextFile 、saveAsObjectFile 、 saveAsSequenceFile
可以看我之前写的例子:传送门
saveAsTextFile:
功能:将RDD以文本文件的格式保存到指定路径
实现1:
实现2:
saveAsObjectFile
功能:将RDD以序列化对象的格式保存到指定路径

saveAsSequenceFile
功能:将RDD以Hadoop SequenceFile的格式保存到指定路径

3.11 foreach
功能:将指定的Lambda表达式,应用在RDD的每个元素上
可以看我之前写的例子:传送门

重点关注:
1. 分区内按元素顺序依次执行Lambda表达式,分区间是并行的
相关文章:
用一个例子告诉你 怎样使用Spark中RDD的算子
目录 1. 前言 1.1 操作分类 1.2 语法知识 2. transformations 2.1 map 2.2 mapPartitions 2.3 flatMap 2.4 glom 2.5 groupBy 2.6 filter 2.7 sample 2.8 distinct 2.9 coalesce 2.10 repartition 2.11 sortBy 2.12 partitionBy 2.13 reduceByKey 2.14 gro…...
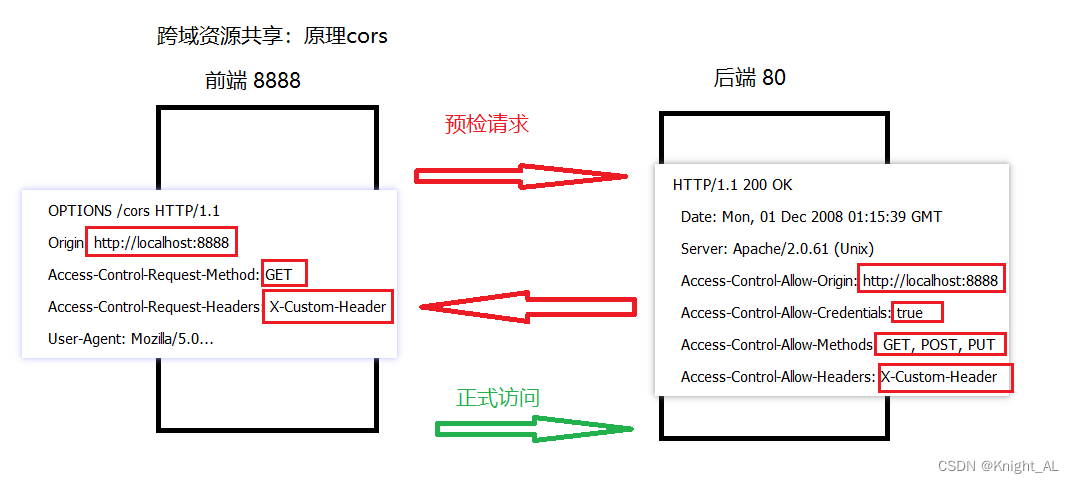
什么是跨域? 出现原因及解决方法
目录一、什么是跨域二、为什么有跨域问题?三、解决跨域问题的方案1.Jsonp2.nginx3.CORS3.1 什么是cors3.2 原理四、GateWay网关中实现跨域步骤一、什么是跨域 跨域:浏览器对于javascript的同源策略的限制 。 同源政策的目的,是为了保证用户…...

低代码系统能够解决哪些痛点?
低代码系统能够解决哪些痛点?如果用4句话去归纳,低代码开发可以解决以下问题—— 为企业提供更高的灵活性,用户可以突破代码的限制自主开发业务应用;通过减少对专业软件开发人员的依赖,公司可以快速响应市场上的新业务…...

华为OD机试题,用 Java 解【两数之和绝对值最小】问题
最近更新的博客 华为OD机试题,用 Java 解【停车场车辆统计】问题华为OD机试题,用 Java 解【字符串变换最小字符串】问题华为OD机试题,用 Java 解【计算最大乘积】问题华为OD机试题,用 Java 解【DNA 序列】问题华为OD机试 - 组成最大数(Java) | 机试题算法思路 【2023】使…...

AcWing算法提高课-3.1.1热浪
宣传一下算法提高课整理 <— CSDN个人主页:更好的阅读体验 <— 题目传送门点这里 题目描述 德克萨斯纯朴的民众们这个夏天正在遭受巨大的热浪!!! 他们的德克萨斯长角牛吃起来不错,可是它们并不是很擅长生产富…...
华为OD机试题【最差产品奖】用 C++ 编码,速通 (2023.Q1)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明最差产…...

NFT市场大战:Blur市场地位可持续吗?
在战胜无数虚张声势的挑战者之后,OpenSea终于迎来了一个实力雄厚的竞争对手,已威胁到它的市场主导地位。opensea是什么?参考《NFT,区块链的产物之一,了解NFT交易平台Opensea》 继成功的空投之后,Blur并没有…...

初识CSS
1.CSS语法形式CSS基本语法规则就是:选择器若干属性声明由选择器选择一个元素,其中的属性声明就作用于该元素.比如:<body><p>这是一个段落</p><!-- style可以放在代码的任意地方 --><style>p{/* 将字体颜色设置为红色 */color: red;}</style&g…...
知识总结(第3期))
kubernetes(k8s)知识总结(第3期)
1. PV 与 PVC PV 是持久卷(Persistent Volume)的首字母缩写。通常情况下,可以事先在 k8s 集群创建 PV 对象: apiVersion: v1 kind: PersistentVolume metadata:name: nfs spec:storageClassName: manualcapacity:storage: 1Giac…...

浅谈跨境电商运行模式
近些年,由于疫情的原因和人们的消费习惯的改变,线下销售越来越不占优势,电商行业由于这几年的飞速发展,成功地吸引到我国的民众,拼多多、淘宝、京东、天猫等各种各样的国内电商平台涌现,依靠着产品质量好、…...

Memcached
什么是MemcachedMemcached 是一个开源免费的高性能的分布式内存对象缓存系统、就是一个软件Memcached的作用缓存数据提高动态网站的速度Memcached的安装//方法一yum installmemcached//方法二1.安装libevent (memcached依赖包)tar -zvxflibevent-release-1.4.15-stable.tar.gzc…...
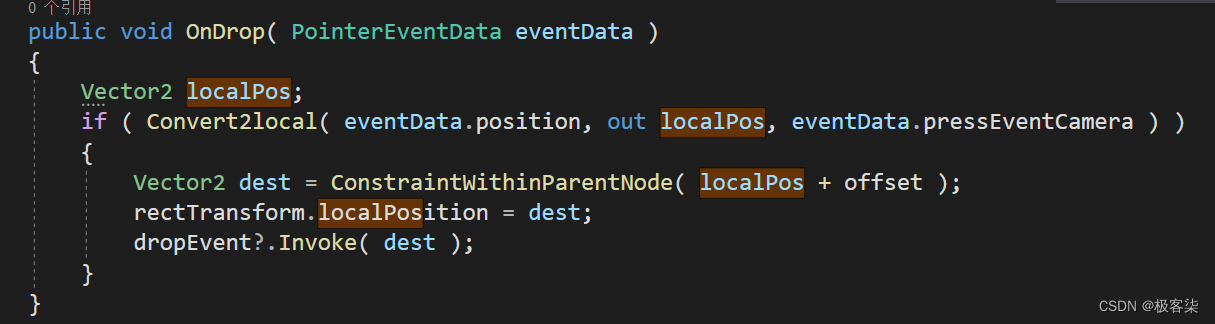
Unity UGUI 拖拽组件
效果展示 使用方式 拖到图片上即可用 父节点会约束它的活动范围哦~ 父节点会约束它的活动范围哦~ 父节点会约束它的活动范围哦~ 源码 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.EventSystems;/// <summary> /…...

面试总结——react生命周期
react生命周期总结 生命周期主要分为以下几个阶段: Mounting:创建虚拟DOM,渲染UI(初始化)Updating:更新虚拟DOM,重新渲染UI;(更新)UnMounting:删除虚拟DOM,移除UI;(销毁) 生命周期…...

初探推荐系统-01
文章目录一、什么是推荐系统是什么为什么长尾理论怎么做二、相似度算法杰卡德相似系数余弦相似度三、基于内容的推荐算法如何获取到用户喜欢的物品如何确定物品的特征四、推荐算法实验方法评测指标推荐效果实验方法1、离线实验2、用户调查3、在线实验评测指标1、预测准确度评分…...

html实现浪漫的爱情日记(附源码)
文章目录1.设计来源1.1 主界面1.2 遇见1.3 相熟1.4 相知1.5 相念2.效果和源码2.1 动态效果2.2 源代码2.3 代码结构源码下载更多爱情表白源码作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/129264757 html实现浪漫的爱情…...
)
detectron2容器环境安装问题(1)
1为避免后面出现需求python版本低于3.7的情况ERROR: Package detectron2 requires a different Python: 3.6.9 not in >3.7可以第一步就使用 nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04镜像2如果使用了18.04的镜像nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04可以使用我…...
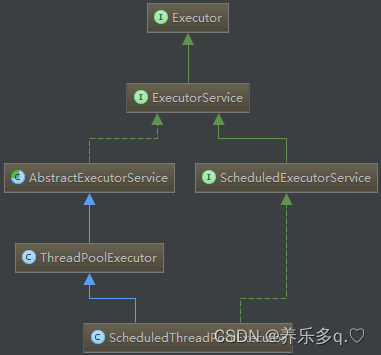
JAVA线程池原理详解二
JAVA线程池原理详解二 一. Executor框架 Eexecutor作为灵活且强大的异步执行框架,其支持多种不同类型的任务执行策略,提供了一种标准的方法将任务的提交过程和执行过程解耦开发,基于生产者-消费者模式,其提交任务的线程相当于生…...

Java 常用 API
文章目录一、Math二、System三、Object1. toString() 方法2. equals() 方法四、Arrays1. 冒泡排序2. Arrays 常用方法五、基本类型包装类1. Integer2. int 和 String 相互转换3. 字符串中数据排序4. 自动装箱和拆箱六、日期类1. Date2. SimpleDateFormat3. Calendar4. 二月天一…...

记一次分布式环境下TOKEN实现用户登录
背景: 以前的单体项目,使用的是session来保存用户登录状态,控制用户的登录过期时间等信息,但是这个session是只保存在该服务器的这个系统内存中。系统只有一个服务就没关系,但是如果是分布式的服务,每个…...

用cpolar发布本地的论坛网站 1
网页论坛向来是个很神奇的地方,曾经的天涯论坛和各种BBS,大家聚在在一起讨论某个问题,也能通过论坛发布想法,各种思维碰撞在一起,发生很多有趣的故事,也产生了很多流传一时的流行语录。当然,如果…...

如何用Matplotlib打造faceai人脸识别可视化分析工具:10个实用技巧
如何用Matplotlib打造faceai人脸识别可视化分析工具:10个实用技巧 【免费下载链接】faceai 一款入门级的人脸、视频、文字检测以及识别的项目. 项目地址: https://gitcode.com/gh_mirrors/fa/faceai faceai是一款功能强大的入门级人脸识别与视觉分析开源工具…...

终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController
终极iOS弹窗解决方案SDCAlertView:10个强大功能超越系统UIAlertController 【免费下载链接】SDCAlertView The little alert that could 项目地址: https://gitcode.com/gh_mirrors/sd/SDCAlertView SDCAlertView是一款强大的iOS弹窗解决方案,它为…...

PPTAgent终极指南:如何5分钟完成专业演示文稿的AI智能生成
PPTAgent终极指南:如何5分钟完成专业演示文稿的AI智能生成 【免费下载链接】PPTAgent An Agentic Framework for Reflective PowerPoint Generation 项目地址: https://gitcode.com/gh_mirrors/pp/PPTAgent 你是否曾为制作演示文稿而熬夜加班?是否…...

谷歌关键词搜索怎么做上去? 提升首页点击率的4个标题优化细节
某家出口企业耗费6个月将“工业水泵制造”推至搜索结果第三位。搜索控制台报表显示,该网页月度曝光量达45,000次,访客仅有540人。点击率停留在1.2%。排在第五位的同行业公司,凭借52个字符的标题,拿走月均3,200个访客。一份针对海外…...

语音提示工程实战:从原理到应用,解锁AI声音表现力
1. 项目概述:语音提示工程的“Awesome”宝库如果你正在探索语音AI的应用,或者想为自己的智能助手、播客、有声书项目寻找更自然、更具表现力的声音,那么你很可能已经意识到一个核心痛点:如何用文字精准地“指挥”一个AI声音&#…...

Ketcher:三步掌握开源化学绘图工具的完整使用指南
Ketcher:三步掌握开源化学绘图工具的完整使用指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 你是否曾因绘制复杂分子结构而烦恼?传统化学绘图软件要么操作复杂,要么…...

5分钟完整指南:Sabaki围棋软件打造专业级对弈环境
5分钟完整指南:Sabaki围棋软件打造专业级对弈环境 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器,专为追求…...
)
从DC到DCG:手把手教你搭建物理感知综合流程(含DEF文件处理避坑指南)
从DC到DCG:物理感知综合全流程实战指南 在28nm以下工艺节点,传统逻辑综合工具已难以应对复杂的物理效应。我们团队在最近一次5nm芯片项目中,由于初期忽视物理感知综合的约束设置,导致时序收敛多耗费三周时间。本文将分享从Design …...

告别窄带!用ADS仿真带你搞懂Doherty放大器带宽瓶颈与三种宽带方案
突破Doherty放大器带宽限制:ADS仿真实战与三大宽带方案解析 在射频功率放大器设计中,Doherty结构因其高效率特性成为5G基站和现代通信系统的核心组件。然而传统设计面临严峻的带宽挑战——当信号频率偏离中心频点时,效率可能骤降30%以上。本文…...

在微服务架构中统一接入Taotoken管理所有AI调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中统一接入Taotoken管理所有AI调用 当企业采用微服务架构时,AI能力的调用往往分散在各个独立的服务中。每…...