26 - 原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢?
其实不然,它们的使用是分场景的。在有些场景下,我们需要重复创建多个实例,例如在循环体中赋值一个对象,此时我们就可以采用原型模式来优化对象的创建过程;而在有些场景下,我们则可以避免重复创建多个实例,在内存中共享对象就好了。
今天我们就来看看这两种模式的适用场景,了解了这些你就可以更高效地使用它们提升系统性能了。
1、原型模式
我们先来了解下原型模式的实现。原型模式是通过给出一个原型对象来指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象,该模式就是用这种方式来创建出更多同类型的对象。
使用这种方式创建新的对象的话,就无需再通过 new 实例化来创建对象了。这是因为 Object 类的 clone 方法是一个本地方法,它可以直接操作内存中的二进制流,所以性能相对 new 实例化来说,更佳。
1.1、实现原型模式
我们现在通过一个简单的例子来实现一个原型模式:
// 实现 Cloneable 接口的原型抽象类 Prototype class Prototype implements Cloneable {// 重写 clone 方法public Prototype clone(){Prototype prototype = null;try{prototype = (Prototype)super.clone();}catch(CloneNotSupportedException e){e.printStackTrace();}return prototype;}}// 实现原型类class ConcretePrototype extends Prototype{public void show(){System.out.println(" 原型模式实现类 ");}}public class Client {public static void main(String[] args){ConcretePrototype cp = new ConcretePrototype();for(int i=0; i< 10; i++){ConcretePrototype clonecp = (ConcretePrototype)cp.clone();clonecp.show();}}}要实现一个原型类,需要具备三个条件:
- 实现 Cloneable 接口:Cloneable 接口与序列化接口的作用类似,它只是告诉虚拟机可以安全地在实现了这个接口的类上使用 clone 方法。在 JVM 中,只有实现了 Cloneable 接口的类才可以被拷贝,否则会抛出 CloneNotSupportedException 异常。
- 重写 Object 类中的 clone 方法:在 Java 中,所有类的父类都是 Object 类,而 Object 类中有一个 clone 方法,作用是返回对象的一个拷贝。
- 在重写的 clone 方法中调用 super.clone():默认情况下,类不具备复制对象的能力,需要调用 super.clone() 来实现。
从上面我们可以看出,原型模式的主要特征就是使用 clone 方法复制一个对象。通常,有些人会误以为 Object a=new Object();Object b=a; 这种形式就是一种对象复制的过程,然而这种复制只是对象引用的复制,也就是 a 和 b 对象指向了同一个内存地址,如果 b 修改了,a 的值也就跟着被修改了。
我们可以通过一个简单的例子来看看普通的对象复制问题:
class Student { private String name; public String getName() { return name; } public void setName(String name) { this.name= name; } }
public class Test { public static void main(String args[]) { Student stu1 = new Student(); stu1.setName("test1"); Student stu2 = stu1; stu1.setName("test2"); System.out.println(" 学生 1:" + stu1.getName()); System.out.println(" 学生 2:" + stu2.getName()); }
}如果是复制对象,此时打印的日志应该为:
学生 1:test1
学生 2:test2然而,实际上是:
学生 2:test2
学生 2:test2通过 clone 方法复制的对象才是真正的对象复制,clone 方法赋值的对象完全是一个独立的对象。刚刚讲过了,Object 类的 clone 方法是一个本地方法,它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。我们可以用 clone 方法再实现一遍以上例子。
// 学生类实现 Cloneable 接口
class Student implements Cloneable{ private String name; // 姓名public String getName() { return name; } public void setName(String name) { this.name= name; } // 重写 clone 方法public Student clone() { Student student = null; try { student = (Student) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } }
public class Test { public static void main(String args[]) { Student stu1 = new Student(); // 创建学生 1stu1.setName("test1"); Student stu2 = stu1.clone(); // 通过克隆创建学生 2stu2.setName("test2"); System.out.println(" 学生 1:" + stu1.getName()); System.out.println(" 学生 2:" + stu2.getName()); }
}运行结果:
学生 1:test1
学生 2:test21.2、深拷贝和浅拷贝
在调用 super.clone() 方法之后,首先会检查当前对象所属的类是否支持 clone,也就是看该类是否实现了 Cloneable 接口。
如果支持,则创建当前对象所属类的一个新对象,并对该对象进行初始化,使得新对象的成员变量的值与当前对象的成员变量的值一模一样,但对于其它对象的引用以及 List 等类型的成员属性,则只能复制这些对象的引用了。所以简单调用 super.clone() 这种克隆对象方式,就是一种浅拷贝。
所以,当我们在使用 clone() 方法实现对象的克隆时,就需要注意浅拷贝带来的问题。我们再通过一个例子来看看浅拷贝。
// 定义学生类
class Student implements Cloneable{ private String name; // 学生姓名private Teacher teacher; // 定义老师类public String getName() { return name; } public void setName(String name) { this.name = name; } public Teacher getTeacher() { return teacher; } public void setName(Teacher teacher) { this.teacher = teacher; } // 重写克隆方法public Student clone() { Student student = null; try { student = (Student) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } } // 定义老师类
class Teacher implements Cloneable{ private String name; // 老师姓名public String getName() { return name; } public void setName(String name) { this.name= name; } // 重写克隆方法,堆老师类进行克隆public Teacher clone() { Teacher teacher= null; try { teacher= (Teacher) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } }
public class Test { public static void main(String args[]) {Teacher teacher = new Teacher (); // 定义老师 1teacher.setName(" 刘老师 ");Student stu1 = new Student(); // 定义学生 1stu1.setName("test1"); stu1.setTeacher(teacher);Student stu2 = stu1.clone(); // 定义学生 2stu2.setName("test2"); stu2.getTeacher().setName(" 王老师 ");// 修改老师System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu1.getTeacher().getName); System.out.println(" 学生 " + stu1.getName + " 的老师是:" + stu2.getTeacher().getName); }
}运行结果:
学生 test1 的老师是:王老师
学生 test2 的老师是:王老师观察以上运行结果,我们可以发现:在我们给学生 2 修改老师的时候,学生 1 的老师也跟着被修改了。这就是浅拷贝带来的问题。
我们可以通过深拷贝来解决这种问题,其实深拷贝就是基于浅拷贝来递归实现具体的每个对象,代码如下:
public Student clone() { Student student = null; try { student = (Student) super.clone(); Teacher teacher = this.teacher.clone();// 克隆 teacher 对象student.setTeacher(teacher);} catch (CloneNotSupportedException e) { e.printStackTrace(); } return student; } 1.3、适用场景
前面我详讲了原型模式的实现原理,那到底什么时候我们要用它呢?
在一些重复创建对象的场景下,我们就可以使用原型模式来提高对象的创建性能。例如,我在开头提到的,循环体内创建对象时,我们就可以考虑用 clone 的方式来实现。
例如:
for(int i=0; i<list.size(); i++){Student stu = new Student(); ...
}我们可以优化为:
Student stu = new Student();
for(int i=0; i<list.size(); i++){Student stu1 = (Student)stu.clone();...
}除此之外,原型模式在开源框架中的应用也非常广泛。例如 Spring 中,@Service 默认都是单例的。用了私有全局变量,若不想影响下次注入或每次上下文获取 bean,就需要用到原型模式,我们可以通过以下注解来实现,@Scope(“prototype”)。
2、享元模式
享元模式是运用共享技术有效地最大限度地复用细粒度对象的一种模式。该模式中,以对象的信息状态划分,可以分为内部数据和外部数据。内部数据是对象可以共享出来的信息,这些信息不会随着系统的运行而改变;外部数据则是在不同运行时被标记了不同的值。
享元模式一般可以分为三个角色,分别为 Flyweight(抽象享元类)、ConcreteFlyweight(具体享元类)和 FlyweightFactory(享元工厂类)。抽象享元类通常是一个接口或抽象类,向外界提供享元对象的内部数据或外部数据;具体享元类是指具体实现内部数据共享的类;享元工厂类则是主要用于创建和管理享元对象的工厂类。
2.1、实现享元模式
我们还是通过一个简单的例子来实现一个享元模式:
// 抽象享元类
interface Flyweight {// 对外状态对象void operation(String name);// 对内对象String getType();
}
// 具体享元类
class ConcreteFlyweight implements Flyweight {private String type;public ConcreteFlyweight(String type) {this.type = type;}@Overridepublic void operation(String name) {System.out.printf("[类型 (内在状态)] - [%s] - [名字 (外在状态)] - [%s]\n", type, name);}@Overridepublic String getType() {return type;}
}
// 享元工厂类
class FlyweightFactory {private static final Map<String, Flyweight> FLYWEIGHT_MAP = new HashMap<>();// 享元池,用来存储享元对象public static Flyweight getFlyweight(String type) {if (FLYWEIGHT_MAP.containsKey(type)) {// 如果在享元池中存在对象,则直接获取return FLYWEIGHT_MAP.get(type);} else {// 在响应池不存在,则新创建对象,并放入到享元池ConcreteFlyweight flyweight = new ConcreteFlyweight(type);FLYWEIGHT_MAP.put(type, flyweight);return flyweight;}}
}
public class Client {public static void main(String[] args) {Flyweight fw0 = FlyweightFactory.getFlyweight("a");Flyweight fw1 = FlyweightFactory.getFlyweight("b");Flyweight fw2 = FlyweightFactory.getFlyweight("a");Flyweight fw3 = FlyweightFactory.getFlyweight("b");fw1.operation("abc");System.out.printf("[结果 (对象对比)] - [%s]\n", fw0 == fw2);System.out.printf("[结果 (内在状态)] - [%s]\n", fw1.getType());}
}输出结果:
[类型 (内在状态)] - [b] - [名字 (外在状态)] - [abc]
[结果 (对象对比)] - [true]
[结果 (内在状态)] - [b]观察以上代码运行结果,我们可以发现:如果对象已经存在于享元池中,则不会再创建该对象了,而是共用享元池中内部数据一致的对象。这样就减少了对象的创建,同时也节省了同样内部数据的对象所占用的内存空间。
2.2、适用场景
享元模式在实际开发中的应用也非常广泛。例如 Java 的 String 字符串,在一些字符串常量中,会共享常量池中字符串对象,从而减少重复创建相同值对象,占用内存空间。代码如下:
String s1 = "hello";String s2 = "hello";System.out.println(s1==s2);//true还有,在日常开发中的应用。例如,线程池就是享元模式的一种实现;将商品存储在应用服务的缓存中,那么每当用户获取商品信息时,则不需要每次都从 redis 缓存或者数据库中获取商品信息,并在内存中重复创建商品信息了。
3、总结
通过以上讲解,相信你对原型模式和享元模式已经有了更清楚的了解了。两种模式无论是在开源框架,还是在实际开发中,应用都十分广泛。
在不得已需要重复创建大量同一对象时,我们可以使用原型模式,通过 clone 方法复制对象,这种方式比用 new 和序列化创建对象的效率要高;在创建对象时,如果我们可以共用对象的内部数据,那么通过享元模式共享相同的内部数据的对象,就可以减少对象的创建,实现系统调优。
4、思考题
上一讲的单例模式和这一讲的享元模式都是为了避免重复创建对象,你知道这两者的区别在哪儿吗?
相关文章:

26 - 原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢? 其实不然,它们的使用是分场…...

【Web安全】sqlmap的使用笔记及示例
【Web安全】sqlmap的使用笔记 文章目录 【Web安全】sqlmap的使用笔记1. 目标2. 脱库2.1. 脱库(补充) 3. 其他3.1. 其他(补充) 4. 绕过脚本tamper讲解 1. 目标 操作作用必要示例-u指定URL,检测注入点sqlmap -u http://…...
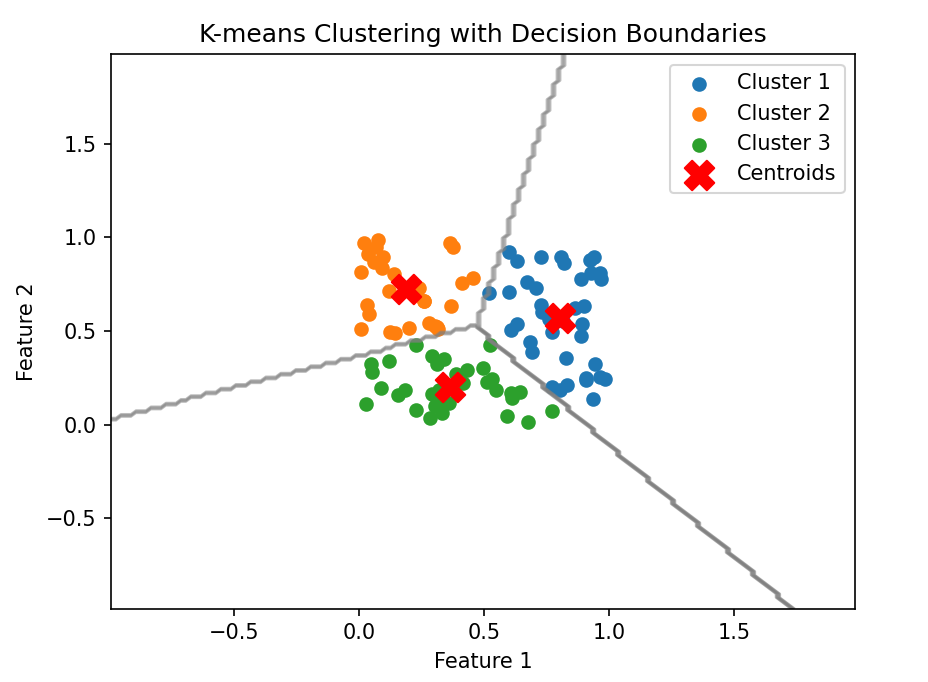
机器学习第12天:聚类
文章目录 机器学习专栏 无监督学习介绍 聚类 K-Means 使用方法 实例演示 代码解析 绘制决策边界 本章总结 机器学习专栏 机器学习_Nowl的博客-CSDN博客 无监督学习介绍 某位著名计算机科学家有句话:“如果智能是蛋糕,无监督学习将是蛋糕本体&a…...

若依框架导出下载pdf/excel以及导入打印等
一、打印文件 // 报表打印 handlePdf(row) {wayAPI(row.billcode).then((res) > {var binaryData [];binaryData.push(res);let url window.URL.createObjectURL(new Blob(binaryData, {type: "application/pdf"})); window.open("/static/pdf/web/v…...

汇编-PROC定义子过程(函数)
过程定义 过程用PROC和ENDP伪指令来声明, 并且必须为其分配一个名字(有效的标识符) 。目前为止, 我们所有编写的程序都包含了一个main过程, 例如: 当要创建的过程不是程序的启动过程时, 就用RET指令来结束它。RET强制…...

服务器主机安全的重要性及防护策略
在数字化时代,服务器主机安全是任何组织都必须高度重视的问题。无论是大型企业还是小型企业,无论是政府机构还是个人用户,都需要确保其服务器主机的安全,以防止数据泄露、网络攻击和系统瘫痪等严重后果。 一、服务器主机安全的重…...

PDF转成图片
使用开源库Apache PDFBox将PDF转换为图片 依赖 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>fontbox</artifactId><version>2.0.4</version> </dependency> <dependency><groupId>org.apache…...

Qt无边框设计
//指定窗口为无边框 this->setWindowFlags(Qt::FramelessWindowHint | Qt::WindowMinMaxButtonsHint);重写鼠标事件: void mousePressEvent(QMouseEvent* event) override; void mouseMoveEvent(QMouseEvent* event) override;定义位置: QPoint dif…...
高级语法)
规则引擎Drools使用,0基础入门规则引擎Drools(二)高级语法
文章目录 系列文章索引五、规则属性1、enabled属性2、dialect属性3、salience属性4、no-loop属性5、activation-group属性6、agenda-group属性7、auto-focus属性8、timer属性9、date-effective属性10、date-expires属性 六、Drools高级语法1、global全局变量2、query查询3、fun…...

C语言二十三弹---求第N项斐波那契数列的值
C语言求第N项斐波那契数列的值 定义:斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89…自然中的斐波那契数列࿰…...

Pickcode:教孩子们编码的新视觉语言
Pickcode 通过视觉课程、聊天机器人、游戏和绘图来教授编程。 Pickcode 是一种新的语言和编辑器,可以直观地指导用户编写代码来制作聊天机器人、动画图画和游戏。Pickcode 旨在让用户在学习更高级的语言之前能够充满信心地开始学习编码。 Pickcode 可视化编程语言…...

乐划锁屏插画大赏热度持续,进一步促进价值内容的创造与传播
锁屏,原本只是为了防止手机在口袋里“误触”而打造的功能,现如今逐渐成为文化传播领域的热门入口。乐划锁屏不断丰富锁屏内容和场景玩法,通过打造“乐划锁屏插画大赏”系列活动为广大内容创作者提供了更多展示自我的机会,丰富平台内容。 从2020年到2023年,乐划锁屏插画大赏已连…...

【ArcGIS Pro微课1000例】0034:矢量数据几何校正案例(Spatial Adjustment)
本案例讲解矢量数据几何校正,根据一个矢量数据去校正另外一个矢量数据。 文章目录 一、加载实验数据二、空间校正三、注意事项一、加载实验数据 在ArcGIS Pro中加载数据效果如下: design:需要校正的数据图层plan+roadcenter:目标图层可以看到,design图层没有在正确的位置…...

2023亚太杯数学建模B题:玻璃温室中的微气候法规,思路模型代码论文
问题B 玻璃温室中的微气候法规 赛题思路:思路获取见文末名片,第一时间更新 温室作物的产量受到各种气候因素的影响,包括温度、湿度和风速[1]。其中,适 宜的温度和风速是植物生长[2]的关键。为了调节玻璃温室内的温度、风速等气…...
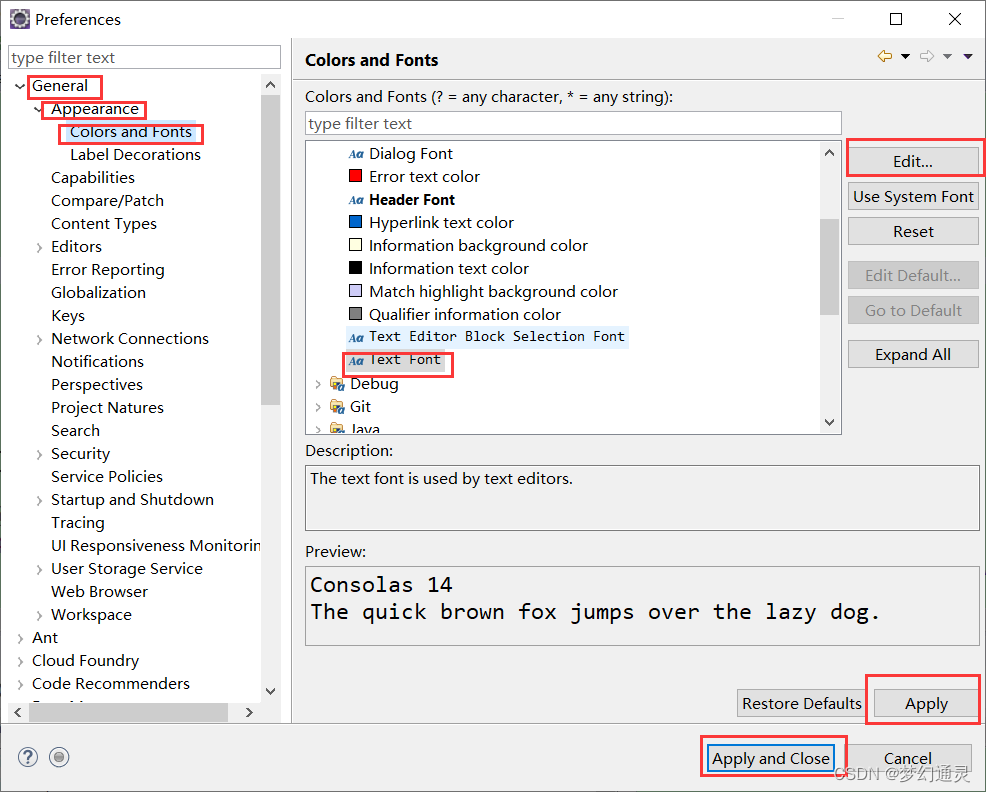
Eclipse常用设置-乱码
在用Eclipse进行Java代码开发时,经常会遇到一些问题,记录下来,方便查看。 一、properties文件乱码 常用的配置文件properties里中文的乱码,不利于识别。 处理流程:Window -> Preferences -> General -> Ja…...
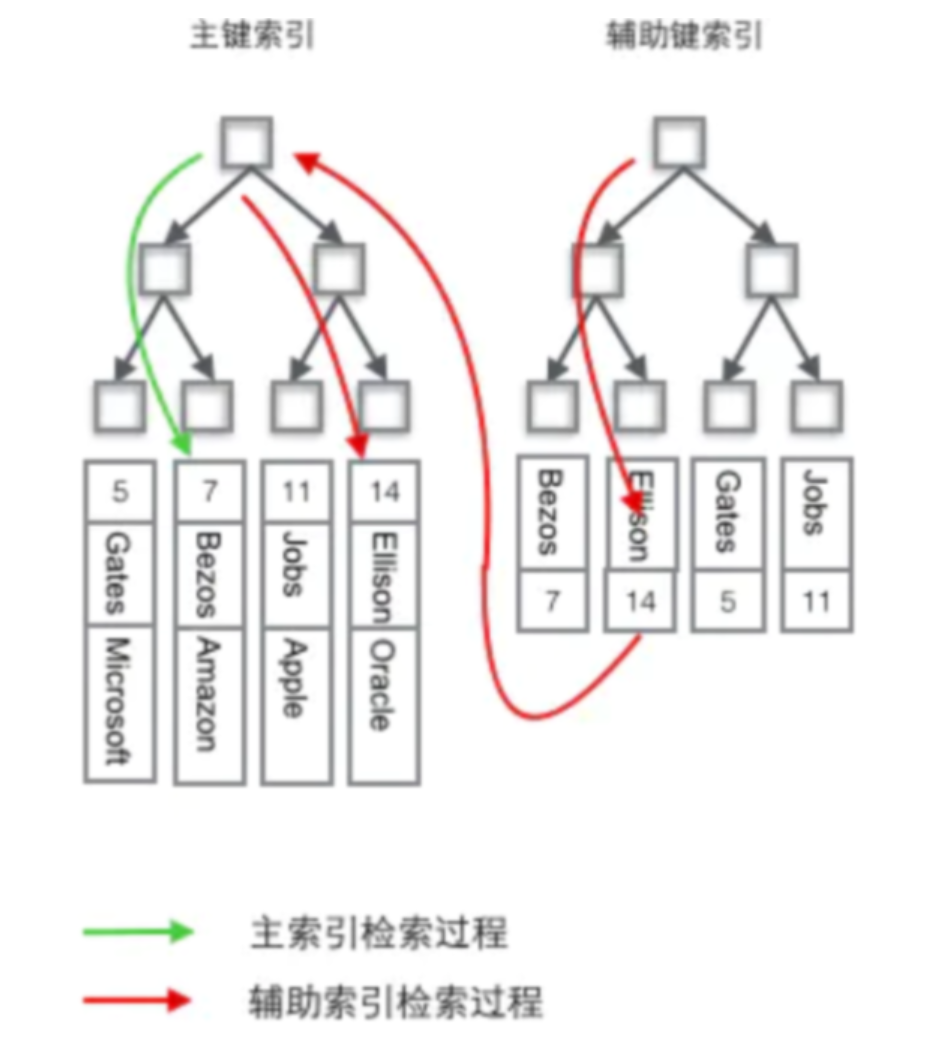
MySQL面试,MySQL事务,MySQL锁,MySQL集群,主从,MySQL分区,分表,InnoDB
文章目录 数据库-MySQLMySQL主从、集群模式简单介绍1、主从模式 Replication2、集群模式3、主从模式部署注意事项 UNION 和 UNION ALL 区别分库分表1.垂直拆分2、水平拆分 MySQL有哪些数据类型1、整数类型**,2、实数类型**,3、字符串类型**,4…...

HarmonyOS应用开发者认证题目满分指南
为了帮助大家快速的上手HarmonyOS应用程序开发,官方制作了一些免费的课程:HarmonyOS第一课。每个课程后面都有一些练习题,下面就是这些题目的满分答案。 【习题】运行Hello World工程 判断题 1.DevEco Studio是开发HarmonyOS应用的一站式集…...
)
openssl+ SM2 + linux 签名校验开发实例(C++)
文章目录 一、SM2校验理论基础二、SM2签名校验开发实例(C) 一、SM2校验理论基础 SM2的校验过程是使用椭圆曲线上的公钥验证签名的有效性。以下是SM2校验的理论基础相关知识点: SM2签名算法: SM2的校验基于椭圆曲线数字签名算法&a…...

有关Vue、微信小程序、UniApp中的CSS中的宽度width单位、自适应
在Vue中,可以使用以下单位来设置宽度(width) 像素(px):最常用的单位,表示一个绝对长度单位。例如,width: 200px; 表示宽度为200像素。百分比(%):…...
黑马React18: ReactRouter
黑马React: ReactRouter Date: November 21, 2023 Sum: React路由基础、路由导航、导航传参、嵌套路由配置 路由快速上手 1. 什么是前端路由 一个路径 path 对应一个组件 component 当我们在浏览器中访问一个 path 的时候,path 对应的组件会在页面中进行渲染 2. …...

从QPushButton到QAction:Qt中‘可切换’控件的统一处理模式与实战技巧
从QPushButton到QAction:Qt中‘可切换’控件的统一处理模式与实战技巧 在构建复杂的Qt应用程序时,我们经常需要处理各种可切换状态的控件——从工具栏按钮到菜单项,从单选按钮到复选框。这些控件看似形态各异,但Qt框架通过统一的抽…...

智能代码助手架构设计:从LLM集成到本地部署的完整实践
1. 项目概述:一个面向开发者的智能代码助手 最近在GitHub上看到一个挺有意思的项目,叫 haojichong/coding-codex 。乍一看这个名字,可能有点摸不着头脑,但如果你是一个经常和代码打交道的开发者,尤其是对提升编码效率…...

RTOS共享服务运行时安全创建技术解析
1. RTOS共享服务创建的传统困境与挑战在嵌入式实时操作系统(RTOS)开发中,任务间通信和资源共享是核心需求。互斥锁(mutex)、消息队列(queue)、信号量(semaphore)等共享服务的创建与管理方式,直接影响系统的可靠性、可维护性和扩展性。传统的主从式(Maste…...

量子计算误差缓解与基准测试技术解析
1. 量子优化问题中的误差缓解与基准测试挑战在量子计算领域,噪声和误差一直是阻碍实现量子优势的主要障碍。特别是在量子优化问题中,如寻找物理系统的基态能量,量子电路的深度和复杂度使得计算结果极易受到噪声影响。传统基准测试方法往往忽略…...
: 数据源抽象与插件架构:异构数据的统一接入)
osgEarth深度分析(3): 数据源抽象与插件架构:异构数据的统一接入
在第二部分中,我们深入剖析了 Rex 引擎如何通过瓦片调度机制实现高性能渲染。本部分将聚焦于 osgEarth 的数据接入层,揭示其如何通过插件化架构与抽象工厂模式,将千差万别的 GIS 数据源(本地文件、网络服务、数据库)转…...

别再只用GO/KEGG了!用R语言做GSEA分析,一眼看懂通路是激活还是抑制
别再只用GO/KEGG了!用R语言做GSEA分析,一眼看懂通路是激活还是抑制 当你拿到差异表达分析结果,兴冲冲地跑完GO/KEGG富集分析后,是否经常遇到这样的困惑:同一个通路里,有的基因上调,有的基因下调…...

阿里云OSS Java SDK安全升级指南:从硬编码AK到环境变量,我这样管理敏感配置
阿里云OSS密钥管理进阶:从环境变量到企业级安全方案实战 在Java开发者的日常工作中,阿里云OSS作为对象存储服务被广泛使用。许多开发者最初接触OSS时,往往直接在代码中硬编码AccessKey进行身份验证——这就像把家门钥匙贴在门框上,…...

SKILL快速构建你的Java、Python和Node.js开发环境
最新案例动态,请查阅SKILL快速构建你的Java、Python和Node.js开发环境小伙伴们快来进行实操吧! 一、概述 1.1 案例介绍 本案例使用技能一键配置Java、Python、Node.js开发环境,帮助开发者快速搭建高效编程环境,适合初学者和团队…...

Illustrator脚本集:释放Adobe Illustrator隐藏生产力的10个实用工具
Illustrator脚本集:释放Adobe Illustrator隐藏生产力的10个实用工具 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾经在Adobe Illustrator中重复执行繁琐操作&…...
)
手把手教你配置TMS320F28335的SCI串口(从寄存器到代码实战)
深入解析TMS320F28335的SCI串口开发:从寄存器配置到代码实战 在嵌入式系统开发中,串口通信是最基础也最关键的通信方式之一。对于使用德州仪器(TI)TMS320F28335数字信号处理器的开发者来说,掌握其串行通信接口(SCI)的底层配置是必备技能。本文…...