MySQL 的执行原理(四)
5.5. MySQL 的查询重写规则
对于一些执行起来十分耗费性能的语句,MySQL 还是依据一些规则,竭尽全力的把这个很糟糕的语句转换成某种可以比较高效执行的形式,这个过程也可以 被称作查询重写。
5.5.1. 条件化简
我们编写的查询语句的搜索条件本质上是一个表达式,这些表达式可能比较繁杂,或者不能高效的执行,MySQL 的查询优化器会为我们简化这些表达式。
5.5.1.1. 移除不必要的括号
有时候表达式里有许多无用的括号,比如这样:
((a = 5 AND b = c) OR ((a > c) AND (c < 5)))
看着就很烦,优化器会把那些用不到的括号给干掉,就是这样:
(a = 5 and b = c) OR (a > c AND c < 5)
5.5.1.2. 常量传递(constant_propagation)
有时候某个表达式是某个列和某个常量做等值匹配,比如这样:
a = 5
当这个表达式和其他涉及列 a 的表达式使用 AND 连接起来时,可以将其他
表达式中的 a 的值替换为 5,比如这样:
a = 5 AND b > a
就可以被转换为:
a = 5 AND b > 5
等值传递(equality_propagation)
有时候多个列之间存在等值匹配的关系,比如这样:
a = b and b = c and c = 5
这个表达式可以被简化为:
a = 5 and b = 5 and c = 5
5.5.1.3. 移除没用的条件(trivial_condition_removal)
对于一些明显永远为 TRUE 或者 FALSE 的表达式,优化器会移除掉它们,比如这个表达式:
(a < 1 and b = b) OR (a = 6 OR 5 != 5)
很明显,b = b 这个表达式永远为 TRUE,5 != 5 这个表达式永远为 FALSE,所
以简化后的表达式就是这样的:
(a < 1 and TRUE) OR (a = 6 OR FALSE)
可以继续被简化为
a < 1 OR a = 6
5.5.1.4. 表达式计算
在查询开始执行之前,如果表达式中只包含常量的话,它的值会被先计算出来,比如这个:
a = 5 + 1
因为 5 + 1 这个表达式只包含常量,所以就会被化简成:
a = 6
但是这里需要注意的是,如果某个列并不是以单独的形式作为表达式的操作数时,比如出现在函数中,出现在某个更复杂表达式中,就像这样:ABS(a) > 5 或者: -a < -8
优化器是不会尝试对这些表达式进行化简的。我们前边说过只有搜索条件中索引列和常数使用某些运算符连接起来才可能使用到索引,所以如果可以的话,
最好让索引列以单独的形式出现在表达式中。
5.5.1.5. 常量表检测
MySQL 觉得下边这种查询运行的特别快:
使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表。
MySQL 觉得这两种查询花费的时间特别少,少到可以忽略,所以也把通过这两种方式查询的表称之为常量表(英文名:constant tables)。优化器在分析一个查询语句时,先首先执行常量表查询,然后把查询中涉及到该表的条件全部替 换成常数,最后再分析其余表的查询成本,比方说这个查询语句:
SELECT * FROM table1 INNER JOIN table2
ON table1.column1 = table2.column2
WHERE table1.primary_key = 1;
很明显,这个查询可以使用主键和常量值的等值匹配来查询 table1 表,也就是在这个查询中 table1 表相当于常量表,在分析对 table2 表的查询成本之前, 就会执行对 table1 表的查询,并把查询中涉及 table1 表的条件都替换掉,也就是上边的语句会被转换成这样:
SELECT table1 表记录的各个字段的常量值, table2.* FROM table1 INNER JOIN table2 ON table1 表 column1 列的常量值 = table2.column2;
5.5.2. 外连接消除
我们前边说过,内连接的驱动表和被驱动表的位置可以相互转换,而左(外)连接和右(外)连接的驱动表和被驱动表是固定的。这就导致内连接可能通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。
我们之前说过,外连接和内连接的本质区别就是:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 ON 子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用 NULL 值填充;而内连接的驱动表的记录如果无法在被驱动表中找到匹配 ON 子句中的过滤条件的记录,那么该记录会被舍弃。查询效果就是这样:
SELECT * FROM e1 INNER JOIN e2 ON e1.m1 = e2.m2;

SELECT * FROM e1 LEFT JOIN e2 ON e1.m1 = e2.m2;
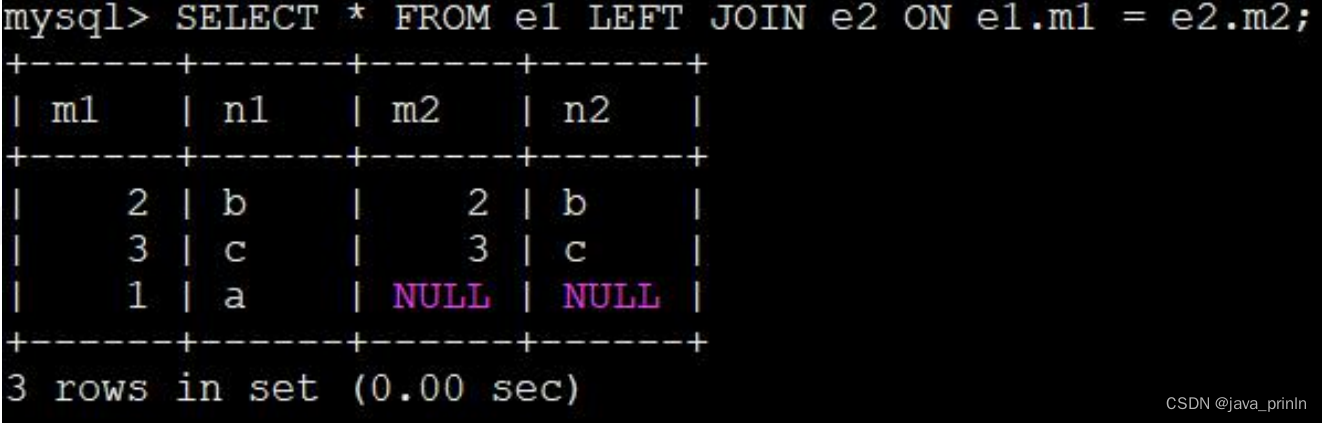
对于上边例子中的(左)外连接来说,由于驱动表 e1 中 m1=1, n1='a’的记录无法在被驱动表 e2 中找到符合 ON 子句条件 e1.m1 = e2.m2 的记录,所以就直接把这条记录加入到结果集,对应的 e2 表的 m2 和 n2 列的值都设置为 NULL。
因为凡是不符合 WHERE 子句中条件的记录都不会参与连接。只要我们在搜索条件中指定关于被驱动表相关列的值不为 NULL,那么外连接中在被驱动表中找不到符合ON子句条件的驱动表记录也就被排除出最后的结果集了,也就是说:在这种情况下:外连接和内连接也就没有什么区别了!比方说这个查询:
mysql> SELECT * FROM e1 LEFT JOIN e2 ON e1.m1 = e2.m2 WHERE e2.n2 IS
NOT NULL;
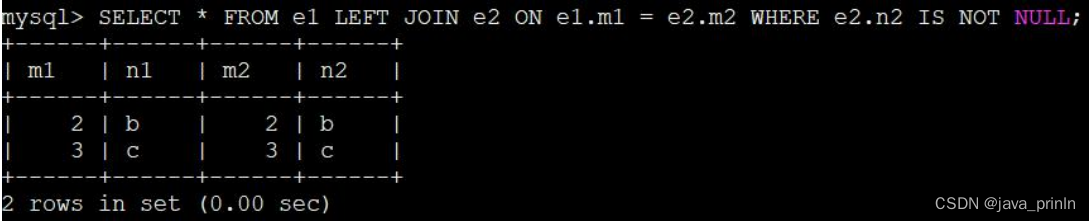
由于指定了被驱动表 e2 的 n2 列不允许为 NULL,所以上边的 e1 和 e2 表的左(外)连接查询和内连接查询是一样的。当然,我们也可以不用显式的指定被驱动表的某个列 IS NOT NULL,只要隐含的有这个意思就行了,比方说这样:
mysql> SELECT * FROM e1 LEFT JOIN e2 ON e1.m1 = e2.m2 WHERE e2.m2 = 2;
在这个例子中,我们在 WHERE 子句中指定了被驱动表 e2 的 m2 列等于 2,也就相当于间接的指定了 m2 列不为 NULL 值,所以上边的这个左(外)连接查询其实和下边这个内连接查询是等价的:
mysql> SELECT * FROM e1 INNER JOIN e2 ON e1.m1 = e2.m2 WHERE e2.m2 = 2;
我们把这种在外连接查询中,指定的 WHERE 子句中包含被驱动表中的列不为 NULL 值的条件称之为空值拒绝(英文名:reject-NULL)。在被驱动表的 WHERE子句符合空值拒绝的条件后,外连接和内连接可以相互转换。这种转换带来的好处就是查询优化器可以通过评估表的不同连接顺序的成本,选出成本最低的那种连接顺序来执行查询。
5.5.3. 子查询优化
5.5.3.1. 子查询语法
在一个查询语句 A 里的某个位置也可以有另一个查询语句 B,这个出现在 A语句的某个位置中的查询 B 就被称为子查询,A 也被称之为外层查询。子查询可以在一个外层查询的各种位置出现,比如:
SELECT 子句中
也就是我们平时说的查询列表中,比如这样:
mysql> SELECT (SELECT m1 FROM e1 LIMIT 1);
其中的(SELECT m1 FROM e1 LIMIT 1)就是子查询。
FROM 子句中
比如:
SELECT m, n FROM (SELECT m2 + 1 AS m, n2 AS n FROM e2 WHERE m2 > 2) AS
t;
这个例子中的子查询是:
(SELECT m2 + 1 AS m, n2 AS n FROM e2 WHERE m2 >2),
这里可以把子查询的查询结果当作是一个表,子查询后边的 AS t 表明这个子查询的结果就相当于一个名称为 t 的表,这个名叫 t 的表的列就是子查询结果中的列,比如例子中表 t 就有两个列:m 列和 n 列。这个放在 FROM 子句中的子查询本质上相当于一个表,但又和我们平常使用的表有点儿不一样,MySQL 把这种由子查询结果集组成的表称之为派生表。
WHERE 或 ON 子句中
把子查询放在外层查询的 WHERE 子句或者 ON 子句中可能是我们最常用的一种使用子查询的方式了,比如这样:
mysql> SELECT * FROM e1 WHERE m1 IN (SELECT m2 FROM e2);
这个查询表明我们想要将(SELECT m2 FROM e2)这个子查询的结果作为外层查询的 IN 语句参数,整个查询语句的意思就是我们想找 e1 表中的某些记录,这些记录的 m1 列的值能在 e2 表的 m2 列找到匹配的值。
ORDER BY 子句、GROUP BY 子句中
虽然语法支持,但没啥意义。
按返回的结果集区分子查询
因为子查询本身也算是一个查询,所以可以按照它们返回的不同结果集类型而把这些子查询分为不同的类型:
标量子查询
那些只返回一个单一值的子查询称之为标量子查询,比如这样:
SELECT (SELECT m1 FROM e1 LIMIT 1);
或者这样:
SELECT * FROM e1 WHERE m1 = (SELECT MIN(m2) FROM e2);
SELECT * FROM e1 WHERE m1 < (SELECT MIN(m2) FROM e2);
这两个查询语句中的子查询都返回一个单一的值,也就是一个标量。这些标量子查询可以作为一个单一值或者表达式的一部分出现在查询语句的各个地方。
行子查询
顾名思义,就是返回一条记录的子查询,不过这条记录需要包含多个列(只包含一个列就成了标量子查询了)。比如这样:
SELECT * FROM e1 WHERE (m1, n1) = (SELECT m2, n2 FROM e2 LIMIT 1);
其中的(SELECT m2, n2 FROM e2 LIMIT 1)就是一个行子查询,整条语句的含义就是要从 e1 表中找一些记录,这些记录的 m1 和 n1 列分别等于子查询结果中的m2 和 n2 列。
列子查询
列子查询自然就是查询出一个列的数据喽,不过这个列的数据需要包含多条记录(只包含一条记录就成了标量子查询了)。比如这样:
SELECT * FROM e1 WHERE m1 IN (SELECT m2 FROM e2);
其中的(SELECT m2 FROM e2)就是一个列子查询,表明查询出 e2 表的 m2 列 的值作为外层查询 IN 语句的参数。
表子查询
顾名思义,就是子查询的结果既包含很多条记录,又包含很多个列,比如这样:
SELECT * FROM e1 WHERE (m1, n1) IN (SELECT m2, n2 FROM e2);
其中的(SELECT m2, n2 FROM e2)就是一个表子查询,这里需要和行子查询对比一下,行子查询中我们用了 LIMIT 1 来保证子查询的结果只有一条记录,表子 查询中不需要这个限制。
按与外层查询关系来区分子查询
- 不相关子查询
如果子查询可以单独运行出结果,而不依赖于外层查询的值,我们就可以把
这个子查询称之为不相关子查询。我们前边介绍的那些子查询全部都可以看作不
相关子查询。 - 相关子查询
如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称之 为相关子查询。比如:
SELECT * FROM e1 WHERE m1 IN (SELECT m2 FROM e2 WHERE n1 = n2);
例子中的子查询是(SELECT m2 FROM e2 WHERE n1 = n2),可是这个查询中有一个搜索条件是 n1 = n2,别忘了 n1 是表 e1 的列,也就是外层查询的列,也就是说子查询的执行需要依赖于外层查询的值,所以这个子查询就是一个相关子查询。
[NOT] IN/ANY/SOME/ALL 子查询
对于列子查询和表子查询来说,它们的结果集中包含很多条记录,这些记录相当于是一个集合,所以就不能单纯的和另外一个操作数使用操作符来组成布尔表达式了,MySQL 通过下面的语法来支持某个操作数和一个集合组成一个布尔表达式:
IN 或者 NOT IN
具体的语法形式如下:
操作数 [NOT] IN (子查询)
这个布尔表达式的意思是用来判断某个操作数在不在由子查询结果集组成
的集合中,比如下边的查询的意思是找出 e1 表中的某些记录,这些记录存在于 子查询的结果集中:
SELECT * FROM e1 WHERE (m1, n1) IN (SELECT m2, n2 FROM e2);
ANY/SOME(ANY 和 SOME 是同义词)
具体的语法形式如下:
操作数 比较符 ANY/SOME(子查询)
这个布尔表达式的意思是只要子查询结果集中存在某个值和给定的操作数
做比较操作,比较结果为 TRUE,那么整个表达式的结果就为 TRUE,否则整个表达式的结果就为 FALSE。比方说下边这个查询:
SELECT * FROM e1 WHERE m1 > ANY(SELECT m2 FROM e2);
这个查询的意思就是对于 e1 表的某条记录的 m1 列的值来说,如果子查询(SELECT m2 FROM e2)的结果集中存在一个小于 m1 列的值,那么整个布尔表达式的值就是 TRUE,否则为 FALSE,也就是说只要 m1 列的值大于子查询结果集中最小的值,整个表达式的结果就是 TRUE,所以上边的查询本质上等价于这个查询:
SELECT * FROM e1 WHERE m1 > (SELECT MIN(m2) FROM e2);
另外,=ANY 相当于判断子查询结果集中是否存在某个值和给定的操作数相等,它的含义和 IN 是相同的。
ALL
具体的语法形式如下:
操作数 比较操作 ALL(子查询)
这个布尔表达式的意思是子查询结果集中所有的值和给定的操作数做比较
操作比较结果为 TRUE,那么整个表达式的结果就为 TRUE,否则整个表达式的结 果就为 FALSE。比方说下边这个查询:
SELECT * FROM e1 WHERE m1 > ALL(SELECT m2 FROM e2);
这个查询的意思就是对于 e1 表的某条记录的 m1 列的值来说,如果子查询 (SELECT m2 FROM e2)的结果集中的所有值都小于 m1 列的值,那么整个布尔表达式的值就是 TRUE,否则为 FALSE,也就是说只要 m1 列的值大于子查询结果集中最大的值,整个表达式的结果就是 TRUE,所以上边的查询本质上等价于这个查询:
SELECT * FROM e1 WHERE m1 > (SELECT MAX(m2) FROM e2);
EXISTS 子查询
有的时候我们仅仅需要判断子查询的结果集中是否有记录,而不在乎它的记录具体是个啥,可以使用把 EXISTS 或者 NOT EXISTS 放在子查询语句前边,就像这样:
SELECT * FROM e1 WHERE EXISTS (SELECT 1 FROM e2);
对于子查询(SELECT 1 FROM e2)来说,我们并不关心这个子查询最后到底查询出的结果是什么,所以查询列表里填*、某个列名,或者其他啥东西都无所谓,我们真正关心的是子查询的结果集中是否存在记录。也就是说只要(SELECT 1 FROM e2)这个查询中有记录,那么整个 EXISTS 表达式的结果就为 TRUE。
子查询语法注意事项
子查询必须用小括号扩起来。
在 SELECT 子句中的子查询必须是标量子查询,如果子查询结果集中有多个列或者多个行,都不允许放在 SELECT 子句中,在想要得到标量子查询或者行子查询,但又不能保证子查询的结果集只有一条记录时,应该使用 LIMIT 1 语句来 限制记录数量。
对于[NOT] IN/ANY/SOME/ALL 子查询来说,子查询中不允许有 LIMIT 语句,而且这类子查询中 ORDER BY 子句、DISTINCT 语句、没有聚集函数以及 HAVING子句的 GROUP BY 子句没有什么意义。因为子查询的结果其实就相当于一个集合,集合里的值排不排序等一点儿都不重要。
不允许在一条语句中增删改某个表的记录时同时还对该表进行子查询。
5.5.3.2. 子查询在 MySQL 中是怎么执行的
想象子查询的执行方式
想象中子查询的执行方式是这样的:
如果该子查询是不相关子查询,比如下边这个查询:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2);
先单独执行(SELECT order_note FROM s2)这个子查询。然后在将上一步子查询得到的结果当作外层查询的参数再执行外层查询
SELECT * FROM s1 WHERE order_note IN (...)。
如果该子查询是相关子查询,比如下边这个查询:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE
s1.order_no= s2.order_no);
这个查询中的子查询中出现了 s1.order_no= s2.order_no 这样的条件,意味着该子查询的执行依赖着外层查询的值,先从外层查询中获取一条记录,本例中也就是先从 s1 表中获取一条记录,然后执行子查询。
最后根据子查询的查询结果来检测外层查询 WHERE 子句的条件是否成立,如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。、
再次执行第一步,获取第二条外层查询中的记录,依次类推。
但真的是这样吗?其实 MySQL 用了一系列的办法来优化子查询的执行,大部分情况下这些优化措施其实挺有效的,下边我们来看看各种不同类型的子查询具体是怎么执行的。
标量子查询、行子查询的执行方式
对于不相关标量子查询或者行子查询来说,它们的执行方式很简单,比方说
下边这个查询语句:
SELECT * FROM s1 WHERE order_note = (SELECT order_note FROM s2 WHERE
key3 = 'a' LIMIT 1);
它的执行方式和我们前面想象的一样:先单独执行(SELECT order_note FROM s2 WHERE key3 = ‘a’ LIMIT 1)这个子查询。然后在将上一步子查询得到的结果当作外层查询的参数再执行外层查询 SELECT * FROM s1 WHERE order_note= …。
也就是说对于包含不相关的标量子查询或者行子查询的查询语句来说,MySQL 会分别独立的执行外层查询和子查询,就当作两个单表查询就好了。
对于相关的标量子查询或者行子查询来说,比如下边这个查询:
SELECT * FROM s1 WHERE
order_note = (SELECT order_note FROM s2 WHERE s1.order_no=
s2.order_no LIMIT 1);
事情也和我们前面想象的一样,它的执行方式就是这样的:
- 先从外层查询中获取一条记录,本例中也就是先从 s1 表中获取一条记录。
- 然后从上一步骤中获取的那条记录中找出子查询中涉及到的值,本例中就是从 s1 表中获取的那条记录中找出 s1.order_no 列的值,然后执行子查询。
- 最后根据子查询的查询结果来检测外层查询 WHERE 子句的条件是否成立,如果成立,就把外层查询的那条记录加入到结果集,否则就丢弃。
- 再次执行第一步,获取第二条外层查询中的记录,依次类推。
也就是说对于两种使用标量子查询以及行子查询的场景中,MySQL 优化器的执行方式并没有什么新鲜的。
MySQL 对 IN 子查询的优化
物化表
对于不相关的 IN 子查询,比如这样:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE
order_no = 'a');
我们最开始的感觉就是这种不相关的 IN 子查询和不相关的标量子查询或者 行子查询是一样一样的,都是把外层查询和子查询当作两个独立的单表查询来对待。但是 MySQL 为了优化 IN 子查询下了很大力气,所以整个执行过程并不像我们想象的那么简单。
对于不相关的 IN 子查询来说,如果子查询的结果集中的记录条数很少,那么把子查询和外层查询分别看成两个单独的单表查询效率很高,但是如果单独执行子查询后的结果集太多的话,就会导致这些问题:
1、结果集太多,可能内存中都放不下。
2、对于外层查询来说,如果子查询的结果集太多,那就意味着 IN 子句中的参数特别多,这就导致:无法有效的使用索引,只能对外层查询进行全表扫描。
在对外层查询执行全表扫描时,由于 IN 子句中的参数太多,这会导致检测一条记录是否符合和 IN 子句中的参数匹配花费的时间太长。
比如说 IN 子句中的参数只有两个:
SELECT * FROM tbl_name WHERE column IN (a, b);
这样相当于需要对 tbl_name 表中的每条记录判断一下它的 column 列是否符合 column = a OR column = b。在 IN 子句中的参数比较少时这并不是什么问题,
如果 IN 子句中的参数比较多时,比如这样:
SELECT * FROM tbl_name WHERE column IN (a, b, c ..., ...);
那么这样每条记录需要判断一下它的 column 列是否符合 column = a OR
column = b OR column = c OR …,这样性能耗费可就多了。
MySQL 的改进是不直接将不相关子查询的结果集当作外层查询的参数,而是 将该结果集写入一个临时表里。写入临时表的过程是这样的:
1、该临时表的列就是子查询结果集中的列。
2、写入临时表的记录会被去重,临时表也是个表,只要为表中记录的所有 列建立主键或者唯一索引。
一般情况下子查询结果集不会大的离谱,所以会为它建立基于内存的使用Memory 存储引擎的临时表,而且会为该表建立哈希索引。
如果子查询的结果集非常大,超过了系统变量 tmp_table_size 或者
max_heap_table_size,临时表会转而使用基于磁盘的存储引擎来保存结果集中的记录,索引类型也对应转变为 B+树索引。
MySQL 把这个将子查询结果集中的记录保存到临时表的过程称之为物化(英文名:Materialize)。为了方便起见,我们就把那个存储子查询结果集的临时表称之为物化表。正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有 B+树索引),通过索引执行 IN 语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。
物化表转连接
事情到这就完了?我们还得重新审视一下最开始的那个查询语句:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE
order_no = 'a');
当我们把子查询进行物化之后,假设子查询物化表的名称为
materialized_table,该物化表存储的子查询结果集的列为 m_val,那么这个查询就相当于表 s1 和子查询物化表 materialized_table 进行内连接:
SELECT s1.* FROM s1 INNER JOIN materialized_table ON order_note = m_val;
转化成内连接之后就有意思了,查询优化器可以评估不同连接顺序需要的成本是多少,选取成本最低的那种查询方式执行查询。我们分析一下上述查询中使用外层查询的表 s1 和物化表 materialized_table 进行内连接的成本都是由哪几部分组成的:
1、如果使用 s1 表作为驱动表的话,总查询成本由下边几个部分组成:
物化子查询时需要的成本
扫描 s1 表时的成本
s1 表中的记录数量 × 通过 m_val = xxx 对 materialized_table 表进行单表访问的成本(我们前边说过物化表中的记录是不重复的,并且为物化表中的列建立了索引,所以这个步骤显然是非常快的)。
2、如果使用 materialized_table 表作为驱动表的话,总查询成本由下边几个部分组成:
物化子查询时需要的成本
扫描物化表时的成本
物化表中的记录数量 × 通过 order_note= xxx 对 s1 表进行单表访问的成本(如果 order_note 列上建立了索引,这个步骤还是非常快的)。
MySQL 查询优化器会通过运算来选择上述成本更低的方案来执行查询。
将子查询转换为 semi-join
虽然将子查询进行物化之后再执行查询都会有建立临时表的成本,但是不管=怎么说,我们见识到了将子查询转换为连接的强大作用,MySQL 继续开脑洞:能不能不进行物化操作直接把子查询转换为连接呢?让我们重新审视一下上边的
查询语句:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE
order_no = 'a');
我们可以把这个查询理解成:对于 s1 表中的某条记录,如果我们能在 s2 表(准确的说是执行完 WHERE s2.order_no= 'a’之后的结果集)中找到一条或多条记录,这些记录的 order_note 的值等于 s1 表记录的 order_note 列的值,那么该条s1 表的记录就会被加入到最终的结果集。这个过程其实和把 s1 和 s2 两个表连接
起来的效果很像:
SELECT s1.* FROM s1 INNER JOIN s2
ON s1.order_note = s2.order_note
WHERE s2.order_no= 'a';
只不过我们不能保证对于 s1 表的某条记录来说,在 s2 表(准确的说是执行完 WHERE s2.order_no= 'a’之后的结果集)中有多少条记录满足 s1.order_no = s2.order_no 这个条件,不过我们可以分三种情况讨论:
- 情况一:对于 s1 表的某条记录来说,s2 表中没有任何记录满足 s1.order_note = s2.order_note 这个条件,那么该记录自然也不会加入到最后的结果集。
- 情况二:对于 s1 表的某条记录来说,s2 表中有且只有 1 条记录满足
s1.order_note = s2.order_note 这个条件,那么该记录会被加入最终的结果集。 - 情况三:对于 s1 表的某条记录来说,s2 表中至少有 2 条记录满足
s1.order_note = s2.order_note 这个条件,那么该记录会被多次加入最终的结果集。
对于 s1 表的某条记录来说,由于我们只关心 s2 表中是否存在记录满足
s1.order_no = s2.order_note 这个条件,而不关心具体有多少条记录与之匹配,又因为有情况三的存在,我们上边所说的 IN 子查询和两表连接之间并不完全等价。
但是将子查询转换为连接又真的可以充分发挥优化器的作用,所以 MySQL 在这里提出了一个新概念 — 半连接(英文名:semi-join)。
将 s1 表和 s2 表进行半连接的意思就是:对于 s1 表的某条记录来说,我们只关心在 s2 表中是否存在与之匹配的记录,而不关心具体有多少条记录与之匹配,最终的结果集中只保留 s1 表的记录。为了让大家有更直观的感受,我们假设 MySQL 内部是这么改写上边的子查询的:
SELECT s1.* FROM s1 SEMI JOIN s2
ON s1.order_note = s2.order_note
WHERE order_no= 'a';
注意: semi-join 只是在 MySQL 内部采用的一种执行子查询的方式,MySQL 并没有提供面向用户的 semi-join 语法。
概念是有了,怎么实现这种所谓的半连接呢?MySQL 准备了好几种办法。
Table pullout (子查询中的表上拉)
当子查询的查询列表处只有主键或者唯一索引列时,可以直接把子查询中的表上拉到外层查询的 FROM 子句中,并把子查询中的搜索条件合并到外层查询的搜索条件中,比如假设 s2 中存在这个一个 key2 列,列上有唯一性索引:
SELECT * FROM s1
WHERE key2 IN (SELECT key2 FROM s2 WHERE key3 = 'a');
由于 key2 列是 s2 表的唯一二级索引列,所以我们可以直接把 s2 表上拉到外层查询的 FROM 子句中,并且把子查询中的搜索条件合并到外层查询的搜索条件中,上拉之后的查询就是这样的:
SELECT s1.* FROM s1 INNER JOIN s2
ON s1.key2 = s2.key2
WHERE s2.key3 = 'a';
为啥当子查询的查询列表处只有主键或者唯一索引列时,就可以直接将子查询转换为连接查询呢?因为主键或者唯一索引列中的数据本身就是不重复的嘛!
所以对于同一条 s1 表中的记录,你不可能找到两条以上的符合 s1.key2 = s2.key2的记录。
DuplicateWeedout execution strategy (重复值消除)
对于这个查询来说:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE
order_no= 'a');
转换为半连接查询后,s1 表中的某条记录可能在 s2 表中有多条匹配的记录,
所以该条记录可能多次被添加到最后的结果集中,为了消除重复,我们可以建立一个临时表,比方说这个临时表长这样:
CREATE TABLE tmp (
id PRIMARY KEY
);
这样在执行连接查询的过程中,每当某条 s1 表中的记录要加入结果集时,
就首先把这条记录的 id 值加入到这个临时表里,如果添加成功,说明之前这条 s1 表中的记录并没有加入最终的结果集,现在把该记录添加到最终的结果集;
如果添加失败,说明之前这条 s1 表中的记录已经加入过最终的结果集,这里直接把它丢弃就好了,这种使用临时表消除 semi-join 结果集中的重复值的方式称 之为 DuplicateWeedout。
LooseScan execution strategy (松散扫描)
大家看这个查询:
SELECT * FROM s1 WHERE order_note IN (SELECT order_no FROM s2 WHERE
order_no> 'a' AND order_no< 'b');
在子查询中,对于 s2 表的访问可以使用到 order_no 列的索引,而恰好子查询的查询列表处就是 order_no 列,这样在将该查询转换为半连接查询后,如果 将 s2 作为驱动表执行查询的话,那么执行过程就是这样:
在 s2 表的 idx_order_no 索引中,值为’aa’的二级索引记录一共有 3 条,那么只需要取第一条的值到 s1 表中查找 s1.order_note= 'aa’的记录,如果能在 s1 表中找到对应的记录,那么就把对应的记录加入到结果集。依此类推,其他值相同的二级索引记录,也只需要取第一条记录的值到 s1 表中找匹配的记录,这种虽然是扫描索引,但只取值相同的记录的第一条去做匹配操作的方式称之为松散扫描。
当然除了我们上面所说的,MySQL 中的半连接方式还有好几种,比如
Semi-join Materializationa 半连接物化、FirstMatch execution strategy (首次匹配)等等,我们就不更深入的讨论了。
semi-join 的适用条件
当然,并不是所有包含 IN 子查询的查询语句都可以转换为 semi-join,只有形如这样的查询才可以被转换为 semi-join:
SELECT ... FROM outer_tables
WHERE expr IN (SELECT ... FROM inner_tables ...) AND ...
或者这样的形式也可以:
SELECT ... FROM outer_tables
WHERE (oe1, oe2, ...) IN (SELECT ie1, ie2, ... FROM inner_tables ...) AND ...
用文字总结一下,只有符合下边这些条件的子查询才可以被转换为 semi-join:
该子查询必须是和 IN 语句组成的布尔表达式,并且在外层查询的 WHERE 或者 ON 子句中出现。
外层查询也可以有其他的搜索条件,只不过和 IN 子查询的搜索条件必须使用 AND 连接起来。
该子查询必须是一个单一的查询,不能是由若干查询由 UNION 连接起来的形式。
该子查询不能包含 GROUP BY 或者 HAVING 语句或者聚集函数。
MySQL 对不能转为 semi-join 查询的子查询优化
1、对于不相关子查询来说,可以尝试把它们物化之后再参与查询
比如我们上边提到的这个查询:
SELECT * FROM s1 WHERE order_note NOT IN (SELECT order_note FROM s2
WHERE order_no= 'a')
先将子查询物化,然后再判断 order_note 是否在物化表的结果集中可以加快查询执行的速度。
2、不管子查询是相关的还是不相关的,都可以把 IN 子查询尝试转为 EXISTS 子查询
其实对于任意一个 IN 子查询来说,都可以被转为 EXISTS 子查询,通用的例子如下:
outer_expr IN (SELECT inner_expr FROM ... WHERE subquery_where)
可以被转换为:
EXISTS (SELECT inner_expr FROM ... WHERE subquery_where AND
outer_expr=inner_expr)
为啥要转换呢?这是因为不转换的话可能用不到索引,比方说下边这个查询:
SELECT * FROM s1 WHERE order_no IN (SELECT order_no FROM s2 where
s1.order_note = s2.order_note) OR insert_time > ‘2021-03-22 18:28:28’;
这个查询中的子查询是一个相关子查询,而且子查询执行的时候不能使用到索引,但是将它转为 EXISTS 子查询后却可以使用到索引:
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 where s1.order_note =
s2.order_note AND s2.order_no= s1.order_no) OR insert_time > ‘2021-03-22
18:28:28’00;
转为 EXISTS 子查询时便可能使用到 s2 表的 idx_order_no 索引了。
需要注意的是,如果 IN 子查询不满足转换为 semi-join 的条件,又不能转换为物化表或者转换为物化表的成本太大,那么它就会被转换为 EXISTS 查询。
在 MySQL5.5 以及之前的版本没有引进 semi-join 和物化的方式优化子查询时,优化器都会把 IN 子查询转换为 EXISTS 子查询,所以当时好多声音都是建议大家
把子查询转为连接,不过随着 MySQL 的发展,最近的版本中引入了非常多的子查询优化策略,内部的转换工作优化器会为大家自动实现。
小结
如果 IN 子查询符合转换为 semi-join 的条件,查询优化器会优先把该子查询转换为 semi-join,然后再考虑下边 5 种执行半连接的策略中哪个成本最低:
Table pullout
DuplicateWeedout
LooseScan
Materialization
FirstMatch
选择成本最低的那种执行策略来执行子查询。
如果 IN 子查询不符合转换为 semi-join 的条件,那么查询优化器会从下边两种策略中找出一种成本更低的方式执行子查询:
先将子查询物化之后再执行查询
执行 IN to EXISTS 转换。
ANY/ALL 子查询优化
如果 ANY/ALL 子查询是不相关子查询的话,它们在很多场合都能转换成我们熟悉的方式去执行,比方说:
原始表达式 转换为
< ANY (SELECT inner_expr ...) < (SELECT MAX(inner_expr) ...)
> ANY (SELECT inner_expr ...) > (SELECT MIN(inner_expr) ...)
< ALL (SELECT inner_expr ...) < (SELECT MIN(inner_expr) ...)
> ALL (SELECT inner_expr ...) > (SELECT MAX(inner_expr) ...)
[NOT] EXISTS 子查询的执行
如果[NOT] EXISTS 子查询是不相关子查询,可以先执行子查询,得出该[NOT]EXISTS 子查询的结果是 TRUE 还是 FALSE,并重写原先的查询语句,比如对这个 查询来说:
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 WHERE expire_time= 'a')
OR order_no> ‘2021-03-22 18:28:28’0;
因为这个语句里的子查询是不相关子查询,所以优化器会首先执行该子查询,假设该 EXISTS 子查询的结果为 TRUE,那么接着优化器会重写查询为:
SELECT * FROM s1 WHERE TRUE OR order_no> ‘2021-03-22 18:28:28’0;
进一步简化后就变成了:
SELECT * FROM s1 WHERE TRUE;
对于相关的[NOT] EXISTS 子查询来说,比如这个查询:
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 WHERE s1.order_note =
s2.order_note);
很不幸,这个查询只能按照我们想象中的那种执行相关子查询的方式来执行。
不过如果[NOT] EXISTS 子查询中如果可以使用索引的话,那查询速度也会加快不少,比如:
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 WHERE
s1.order_note = s2.order_no);
上边这个 EXISTS 子查询中可以使用 idx_order_no 来加快查询速度。
相关文章:
MySQL 的执行原理(四)
5.5. MySQL 的查询重写规则 对于一些执行起来十分耗费性能的语句,MySQL 还是依据一些规则,竭尽全力的把这个很糟糕的语句转换成某种可以比较高效执行的形式,这个过程也可以 被称作查询重写。 5.5.1. 条件化简 我们编写的查询语句的搜索条件…...
PHP 正则式 全能匹配URL(UBB)
PHP 正则式 全能匹配URL(UBB) 语言:PHP 注明:正则式 无语言限制(js、PHP、JSP、ASP、VB、.net、C#...)一切皆可。 简介:PHP UBB 正则式 全能匹配URL 自动加超级链接。网上找了很多都不匹配或…...
hadoop shell操作 hdfs处理文件命令 hdfs上传命令 hadoop fs -put命令hadoop fs相关命令 hadoop(十三)
hadoop fs -help rm 查看rm命令作用 hadoop fs 查看命令 1. 创建文件夹: # hdfs前缀也是可以的。更推荐hadoop hadoop fs -mkdir /sanguo 2.上传至hdfs命令: 作用: 从本地上传hdfs系统 (本地文件被剪切走,不存在了&…...
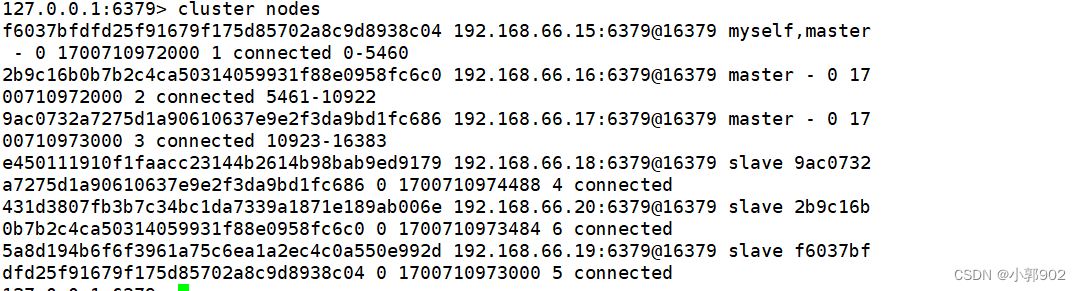
redis-cluster集群
1.redis-cluster集群 redis3.0引入的分布式存储方案 集群由多个node节点组成,redis数据分布在这些节点之中。 在集群之中分为主节点和从节点 集群模式当中,主从一一对应,数据写入和读取与主从模式一样,主负责写,从…...
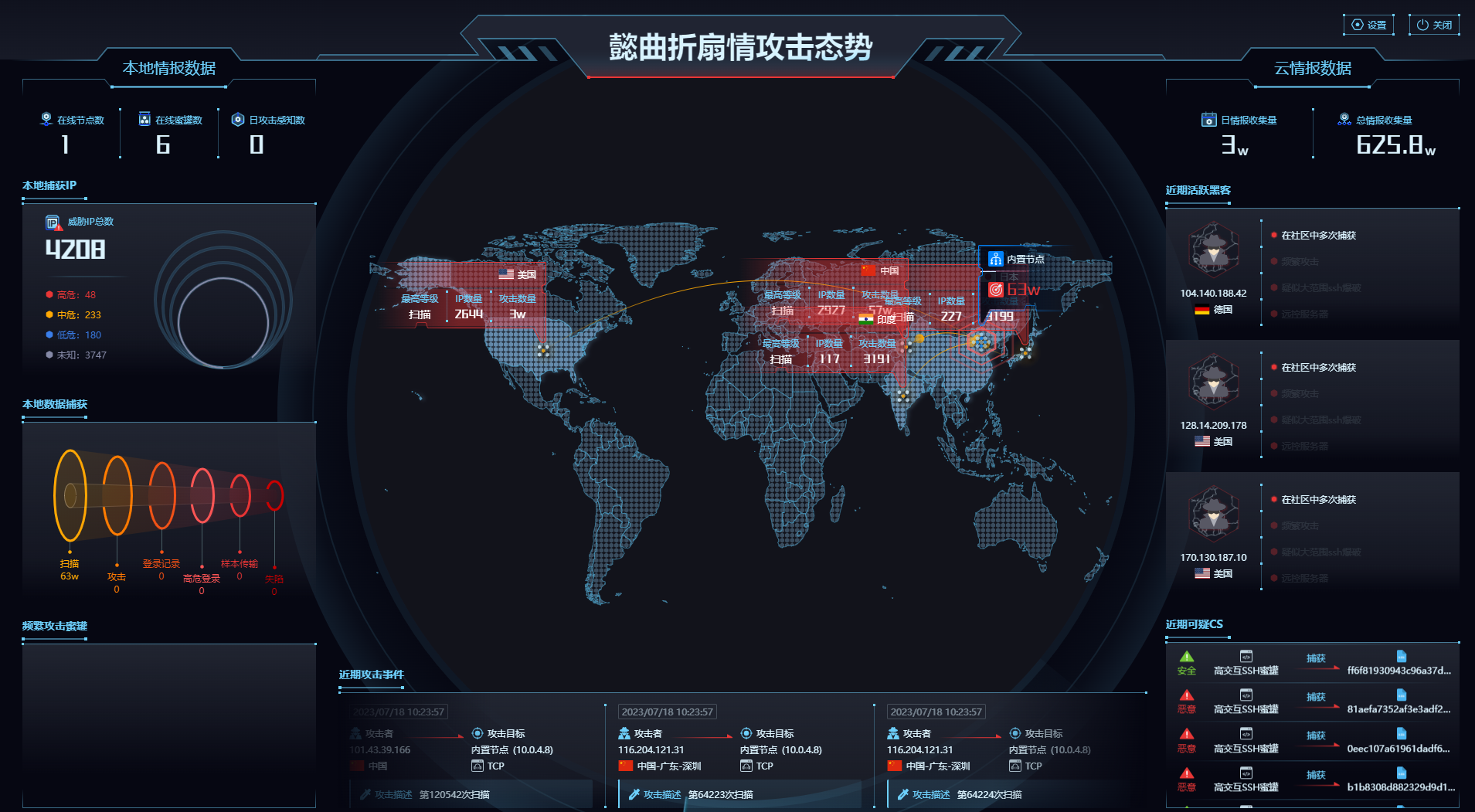
Hfish安全蜜罐部署
一、Hfish蜜罐介绍 HFish蜜罐官网 HFish是一款社区型免费蜜罐,侧重企业安全场景,从内网失陷检测、外网威胁感知、威胁情报生产三个场景出发,为用户提供可独立操作且实用的功能,通过安全、敏捷、可靠的中低交互蜜罐增加用户在失陷…...
Apache POI(Java)
一、Apache POI介绍 Apache POI是Apache组织提供的开源的工具包(jar包)。大多数中小规模的应用程序开发主要依赖于Apache POI(HSSF XSSF)。它支持Excel 库的所有基本功能; 文本的导入和导出是它的主要特点。 我们可以使用 POI 在…...
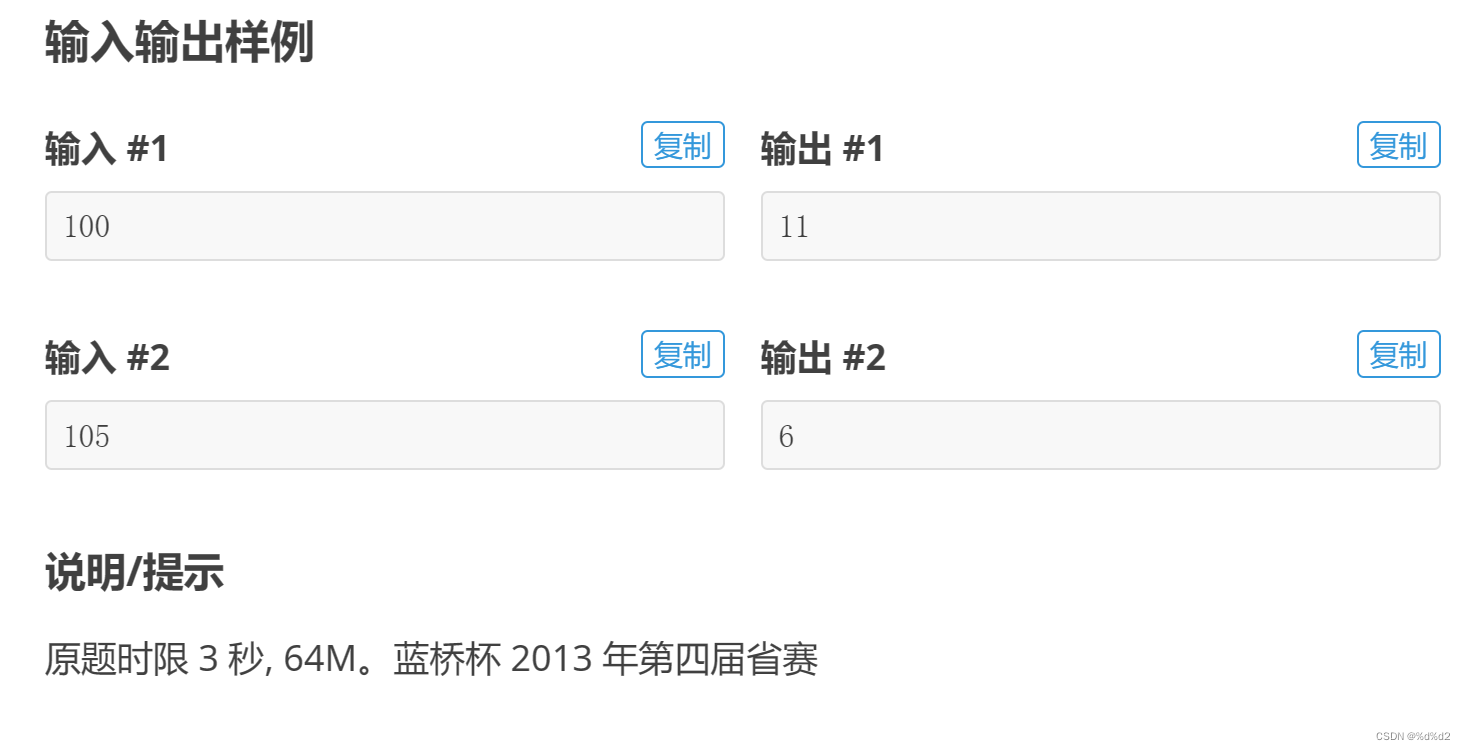
P8599 [蓝桥杯 2013 省 B] 带分数(dfs+全排列+断点判断)
思路:1.深度枚举所有排列情况 2.设置为每个排列设置两个断点,分为三部分:a,b,c 3.转换为乘法判断条件,满足加一 代码如下:(可用next_permutation全排列函数代替dfs) #include<iostream>…...

PS右边的图层窗口没有显示出来?
问题描述:PS右边的图层窗口没有显示出来? 解决步骤: 键盘F7快捷键即可调出来。...
Sealos 云操作系统私有化部署教程
Sealos 私有云已经正式发布了,它为企业用云提供了一种革命性的新方案。Sealos 的核心优势在于,它允许企业在自己的机房中一键构建一个功能与 Sealos 公有云完全相同的私有云。这意味着企业可以在自己的控制和安全范围内,享受到公有云所提供的…...

信息系统的安全保护等级的五个级别
信息系统的安全保护等级分为五级:第一级为自主保护级、第二级为指导保护级、第三级为监督保护级、第四级为强制保护级、第五级为专控保护级。 法律依据:《信息安全等级保护管理办法》第四条 信息系统的安全保护等级分为以下五级: &#…...

c语言使用modbus库
Modbus是一种串行通信协议,被广泛用于连接工业电子设备。Modbus库可以提供用于实现Modbus通信的功能。 以下是一个简单的示例,展示了如何在C语言中使用Modbus库来读取一个Modbus设备中的保持寄存器。 #include <stdio.h> #include <modbus.…...
【Flask使用】全知识md文档,4大部分60页第3篇:Flask模板使用和案例
本文的主要内容:flask视图&路由、虚拟环境安装、路由各种定义、状态保持、cookie、session、模板基本使用、过滤器&自定义过滤器、模板代码复用:宏、继承/包含、模板中特有变量和函数、Flask-WTF 表单、CSRF、数据库操作、ORM、Flask-SQLAlchemy…...

芯片的测试方法
半导体的生产流程包括晶圆制造和封装测试,在这两个环节中分别需要完成晶圆检测(CP, Circuit Probing)和成品测试(FT, Final Test)。无论哪个环节,要测试芯片的各项功能指标均须完成两个步骤:一是将芯片的引脚与测试机的功能模块连接起来&…...

网络安全等级保护2.0国家标准
等级保护2.0标准体系主要标准如下:1.网络安全等级保护条例2.计算机信息系统安全保护等级划分准则3.网络安全等级保护实施指南4.网络安全等级保护定级指南5.网络安全等级保护基本要求6.网络安全等级保护设计技术要求7.网络安全等级保护测评要求8.网络安全等级保护测评…...
从根到叶:随机森林模型的深入探索
一、说明 在本综合指南中,我们将超越基础知识。当您盯着随机森林模型的文档时,您将不再对“节点杂质”、“加权分数”或“成本复杂性修剪”等术语感到不知所措。相反,我们将剖析每个参数,阐明其作用和影响。通过理论和 Python 实践…...

python数据结构与算法-15_堆与堆排序
堆(heap) 前面我们讲了两种使用分治和递归解决排序问题的归并排序和快速排序,中间又穿插了一把树和二叉树, 本章我们开始介绍另一种有用的数据结构堆(heap), 以及借助堆来实现的堆排序,相比前两种排序算法要稍难实现一些。 最后我…...
vscode提交代码到Gitee(保姆教程)
Visual Studio Code(VSCode) 提交代码到Gitee(保姆教程) 1 环境配置1.1 git本地安装1.2 Vscode安装1.3 配置注册gitee账号 2 Vscode代码提交到Gitee2.1 新建仓库2.2 Vscode提交代码 1 环境配置 电脑需要已经安装好的Vscode已经配…...

【洛谷算法题】P5714-肥胖问题【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5714-肥胖问题【入门2分支结构】🌏题目描述🌏输入格式&a…...

促进材料基因工程基础理论、前沿技术和关键装备的发展和应用,第七届材料基因工程高层论坛将于12月重庆举办,龙讯旷腾出席会议
为了进一步促进材料基因工程基础理论、前沿技术和关键装备的发展和应用,加强国际交流,加速我国新材料的研发和应用,由中国材料研究学会、西部科学城重庆高新区管理委员会主办,重庆大学、北京科技大学、北京云智材料大数据研究院等…...

Cypress-浏览器操作篇
Cypress-浏览器操作篇 页面的前进与后退 后退 cy.go(back); cy.go(-1);前进 cy.go(forward); cy.go(1);页面刷新 cy.reload() cy.reload(forceReload) cy.reload(options) cy.reload(forceReload, options)**options:**只有 timeout 和 log forceReload 是否…...

告别CH341 SPI的2MHz限制:实测对比CH347,性能提升30倍的全新选择
突破CH341性能瓶颈:CH347高速SPI接口实战指南与深度评测 在嵌入式开发与硬件通信领域,SPI接口因其全双工、高速、简单的特性成为众多工程师的首选。然而,当项目需求从基础数据传输升级到高速、高稳定性场景时,传统CH341芯片的2MH…...
对时序的影响)
别再死记公式了!用Python+SPICE仿真,5分钟搞懂MOS管沟道宽长比(W/L)对时序的影响
用PythonSPICE仿真揭秘MOS管宽长比如何影响电路时序 在数字电路设计中,我们常常听到"宽长比(W/L)"这个参数,但你真的理解它如何影响电路的实际性能吗?传统教材中复杂的公式推导往往让初学者望而生畏,而今天我们将通过Py…...

DRIFT技术:动态微调提升多模态大模型推理性能
1. 项目概述 DRIFT(Dynamic Refinement through Injected Fine-Tuning)是一种针对多模态大模型的轻量级优化技术,通过在推理阶段动态注入梯度信号,显著提升模型在复杂任务中的表现。这项技术特别适合处理需要跨模态对齐的视觉-语言…...

C# .NET 周刊|2026年4月1期
国内文章.NET 高级开发 | 开发 .NET 诊断工具、链路追踪原理https://www.cnblogs.com/whuanle/p/19809387文章详细介绍了.NET诊断工具中的System.Diagnostics和Microsoft.Diagnostics命名空间,重点讲解了Debug和Trace的使用方法及区别。通过实例演示Debug.Assert的断…...

3个实战技巧掌握obs-virtual-cam:从零构建专业级虚拟摄像头系统
3个实战技巧掌握obs-virtual-cam:从零构建专业级虚拟摄像头系统 【免费下载链接】obs-virtual-cam obs-studio plugin to simulate a directshow webcam 项目地址: https://gitcode.com/gh_mirrors/ob/obs-virtual-cam 你是否厌倦了视频会议中单调的摄像头画…...

【Linux】VirtualBox安装虚拟机实操记录
文章目录0 前言1 基本使用流程1.1 新建虚拟机1.2 配置增强功能1.3 ssh配置2 可能遇到的问题2.1 安装完虚拟机之后打开报错0 前言 工作之后开始重视软件版权了,原来一直使用的VMware被迫不能再使用,转而使用开源的VirtualBox,简单记录一下使用…...

2025最权威的十大AI学术网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 维普检测系统针对人工智能生成文本的识别能力正一天天变得越发强大起来,研究者得…...

如何高效捕获网页媒体资源?3步掌握猫抓浏览器扩展实用技巧
如何高效捕获网页媒体资源?3步掌握猫抓浏览器扩展实用技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为无法保存网页上的视频…...

MHmarkets迈汇平台:点差结构与交易成本控制
摘要: 在金融信息服务领域,参与者选择平台的关键考量因素之一在于其费用结构的清晰度与执行效率。MHmarkets迈汇平台通过精心设计的点差机制及全面的成本管理策略,致力于为全球参与者提供透明、公正的价值流转环境。本文深入解析该平台在点差…...

告别命令行恐惧!用PyCharm专业版+AutoDL,像操作本地文件一样玩转远程服务器
告别命令行恐惧!用PyCharm专业版AutoDL,像操作本地文件一样玩转远程服务器 对于许多刚接触深度学习的开发者来说,Linux命令行操作就像一堵高墙,让人望而生畏。每次看到黑底白字的终端窗口,输入那些神秘的命令时&#x…...