大数据基础设施搭建 - Flume
文章目录
- 一、上传压缩包
- 二、解压压缩包
- 三、监控本地文件(file to kafka)
- 3.1 编写配置文件
- 3.2 自定义拦截器
- 3.2.1 开发拦截器jar包
- (1)创建maven项目
- (2)开发拦截器类
- (3)开发pom文件
- (4)打成jar包上传到Flume
- 3.2.3 修改配置文件
- 3.3 创建Kafka Topic
- 3.4 启动Flume
- 3.5 停止Flume
- 四、监控Kafka(kafka to hdfs)
- 3.0 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
- 3.1 自定义拦截器
- 3.2 编写配置文件
- 3.3 启动Flume
- 3.4 停止Flume
- 五、监控 ip+port(TODO)
一、上传压缩包
官网:https://flume.apache.org/
二、解压压缩包
[mall@mall software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
三、监控本地文件(file to kafka)
Flume是用java写的,所以需要确保JDK环境可用
需求描述:监控目录下多个文件写入Kafka
TAILDIR SOURCE:本质是tail -F [file]命令,只能监控文件的新增和修改,不能处理历史文件。
3.1 编写配置文件
[mall@mall ~]$ cd /opt/module/apache-flume-1.9.0-bin/
[mall@mall apache-flume-1.9.0-bin]$ mkdir job
[mall@mall apache-flume-1.9.0-bin]$ cd job/
[mall@mall job]$ vim file_to_kafka.conf
内容:
# 0、配置agent:给source channel sink组件命名
a1.sources = r1
a1.channels = c1# 1、配置source组件
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/app.*
# 断点续传标记信息存储位置
a1.sources.r1.positionFile = /opt/module/apache-flume-1.9.0-bin/taildir_position.json# 2、配置channel组件:event临时缓冲区
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = topic_mall_applog# 按照字符串类型传到kafka去
a1.channels.c1.parseAsFlumeEvent = false# 3、配置source、channel、sink之间的连接关系
a1.sources.r1.channels = c1
3.2 自定义拦截器
作用:拦截events,经拦截器处理,输出处理后的events。
开发:创建maven项目,打成jar包形式上传到flume所在机器
3.2.1 开发拦截器jar包
(1)创建maven项目
(2)开发拦截器类
package com.songshuang.flume.interceptor;import com.alibaba.fastjson.JSONException;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;/*** @date 2023/11/21 20:40* 功能:剔除掉非json格式数据** 1、实现接口* 2、实现抽象方法* 3、建造者模式:静态内部类*/
public class ETLInterceptor implements Interceptor {public void initialize() {}// 将log中event为非json格式数据置为nullpublic Event intercept(Event event) {byte[] body = event.getBody();// byte数组转为字符串String log = new String(body, StandardCharsets.UTF_8);boolean flag = false;// 判断log是否是json格式try {JSONObject jsonObject = JSONObject.parseObject(log);flag = true;} catch (JSONException e) {}return flag ? event : null;}// 将log中event为null的删掉public List<Event> intercept(List<Event> events) {// 遍历eventsIterator<Event> iterator = events.iterator();while (iterator.hasNext()) {Event event = iterator.next();if (intercept(event) == null) {iterator.remove();}}return events;}public void close() {}// 建造者模式public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new ETLInterceptor();}@Overridepublic void configure(Context context) {}}
}
(3)开发pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.songshuang</groupId><artifactId>flume_interceptor</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
(4)打成jar包上传到Flume
上传到 /opt/module/apache-flume-1.9.0-bin/lib 目录下
3.2.3 修改配置文件
[mall@mall job]$ vim file_to_kafka.conf
新增内容:
# 自定义拦截器
a1.sources.r1.interceptors = i1
# 指定自定义拦截器的建造者类名(入口)
a1.sources.r1.interceptors.i1.type = com.songshuang.flume.interceptor.ETLInterceptor$Builder
3.3 创建Kafka Topic
为什么要手动创建topic:flume自动创建的topic默认1个分区,每个分区1个副本。手动创建可以指定分区和副本数,可以有效利用Kafka集群资源。
–bootstrap-server参数作用:连接Kafka集群
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --create --replication-factor 2 --partitions 3 --topic topic_mall_applog
3.4 启动Flume
注意:放开Kafka集群所在机器9092端口,对Flume所在机器放开。
原因:Flume需要向Kafka集群写入数据,所以需要具有访问Kafka集群端口的权限。
– conf参数:配置文件存储所在目录
– name参数:agent名称,每个Flume配置文件就是一个agent。
– conf-file参数:flume本次启动读取的配置文件
nohup配合&:后台运行
&>/dev/null:将标准输出重定向到 /dev/null ,即丢弃所有输出
2>/dev/null:将标准错误输出重定向到 /dev/null ,即丢弃所有错误输出
[mall@mall ~]$ cd /opt/module/apache-flume-1.9.0-bin/
[mall@mall apache-flume-1.9.0-bin]$ nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file job/file_to_kafka.conf &>/dev/null 2>/dev/null &
3.5 停止Flume
[mall@mall apache-flume-1.9.0-bin]$ ps -ef | grep file_to_kafka.conf
[mall@mall apache-flume-1.9.0-bin]$ kill 11001
四、监控Kafka(kafka to hdfs)
需求描述:监控Kafka,将数据写入HDFS
如果想要从头消费需要设置kafka.consumer.auto.offset.reset = earliest,默认从最新offset开始
注意:需要在HDFS所在机器部署FLume,需要调用HADOOP相关jar包。
3.0 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
否则Flume向HDFS写数据时会失败!
[hadoop@hadoop104 ~]$ rm /opt/module/apache-flume-1.9.0-bin/lib/guava-11.0.2.jar
3.1 自定义拦截器
作用:按照kafka消息中的时间字段,决定消息存储到hdfs的哪个文件中。
代码:
package com.songshuang.flume.interceptor;import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;/*** @date 2023/11/22 16:52* 作用:获取kafka中时间戳字段,放入event头中,flume写入hdfs时,从头部获取时间,作为该event放入hdfs的文件夹名称*/
public class TimestampInterceptor implements Interceptor {@Overridepublic void initialize() {}// 获取kafka时间戳字段,放入event的header@Overridepublic Event intercept(Event event) {byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);JSONObject jsonObject = JSONObject.parseObject(log);String ts = jsonObject.getString("ts");Map<String, String> headers = event.getHeaders();headers.put("timestamp",ts); // event是引用变量类型,存储的是地址,header变了,自然event所对应地址上的值就变了return event;}@Overridepublic List<Event> intercept(List<Event> events) {for (Event event : events) {intercept(event);}return events;}@Overridepublic void close() {}// 建造者模式public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampInterceptor();}@Overridepublic void configure(Context context) {}}
}
3.2 编写配置文件
[hadoop@hadoop104 job]$ vim kafka_to_hdfs.conf
内容:
a1.sources.r1.kafka.consumer.group.id:消费者组名。
a1.channels.c1.type:file类型channel,缓冲数据放在磁盘中,而不是内存中。
a1.channels.c1.dataDirs:file channel缓冲内容落盘地址。
a1.channels.c1.checkpointDir:检查点存放位置,用于断点续传。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 配置source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics = topic_mall_applog
a1.sources.r1.kafka.consumer.group.id = consumer_group_flume
# 指定consumer从哪个offset开始消费,默认latest
# a1.sources.r1.kafka.consumer.auto.offset.reset = earliest
# 自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.songshuang.flume.interceptor.TimestampInterceptor$Builder# 配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /warehouse/applog/%Y-%m-%d
a1.sinks.k1.hdfs.codeC = gzip# 配置channel
a1.channels.c1.type = file
a1.channels.c1.dataDirs = /opt/module/apache-flume-1.9.0-bin/data/kafka_to_hdfs
a1.channels.c1.checkpointDir = /opt/module/apache-flume-1.9.0-bin/checkpoint/kafka_to_hdfs# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.3 启动Flume
注意1:需要放开kafka端口,即9092端口,Flume要读Kafka。
[hadoop@hadoop104 job]$ cd /opt/module/apache-flume-1.9.0-bin/
[hadoop@hadoop104 apache-flume-1.9.0-bin]$ nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file job/kafka_to_hdfs.conf &>/dev/null 2>/dev/null &
3.4 停止Flume
[mall@mall apache-flume-1.9.0-bin]$ ps -ef | grep kafka_to_hdfs.conf
[mall@mall apache-flume-1.9.0-bin]$ kill 11001
五、监控 ip+port(TODO)
相关文章:

大数据基础设施搭建 - Flume
文章目录 一、上传压缩包二、解压压缩包三、监控本地文件(file to kafka)3.1 编写配置文件3.2 自定义拦截器3.2.1 开发拦截器jar包(1)创建maven项目(2)开发拦截器类(3)开发pom文件&a…...

华为OD机试 - 找朋友(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述大白话解释一下就是:1、输入:2、输出:3、说明 四、解题思路五、Java算法源码六、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专…...

ESP32 MicroPython 颜色及二维码识别⑫
ESP32 MicroPython 颜色及二维码识别⑫ 1、颜色识别2、二维码识别 1、颜色识别 使用AI颜色识别功能,可以实现颜色辨别、颜色追踪等应用。颜色识别模型内置有9种常见的颜色识别和一种颜色学习识别模式。他们分别是: ai.COLOR_RED 表示识别红色 ai.COLOR…...

数据结构与算法编程题15
设计一个算法,通过遍历一趟,将链表中所有结点的链接方向逆转,仍利用原表的存储空间。 #include <iostream> using namespace std;typedef int Elemtype; #define ERROR 0; #define OK 1;typedef struct LNode {Elemtype data; …...

基于Mapmost Alpha工具快速搭建3D场景可视化大屏
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
OpenAI再次与Sam Altman谈判;ChatGPT Voice正式上线
11月22日,金融时报消息,OpenAI迫于超过700名员工联名信的压力,再次启动了与Sam Altman的谈判,希望他回归董事会。 在Sam确定加入微软后,OpenAI超700名员工签署了一封联名信,要求Sam和Greg Brockman&#x…...

技术是增长关键驱动!传音控股新专利亮相,看未来手机趋势
近日,有媒体报道从国家知识产权局发现传音控股取得多项突破性的技术专利,包括图像处理技术、准共址关系指示、panel状态处理等。当下的智能手机行业,已进入高度成熟阶段,技术是产业新一轮增长点已成为业内共识。 传音控股认为&am…...
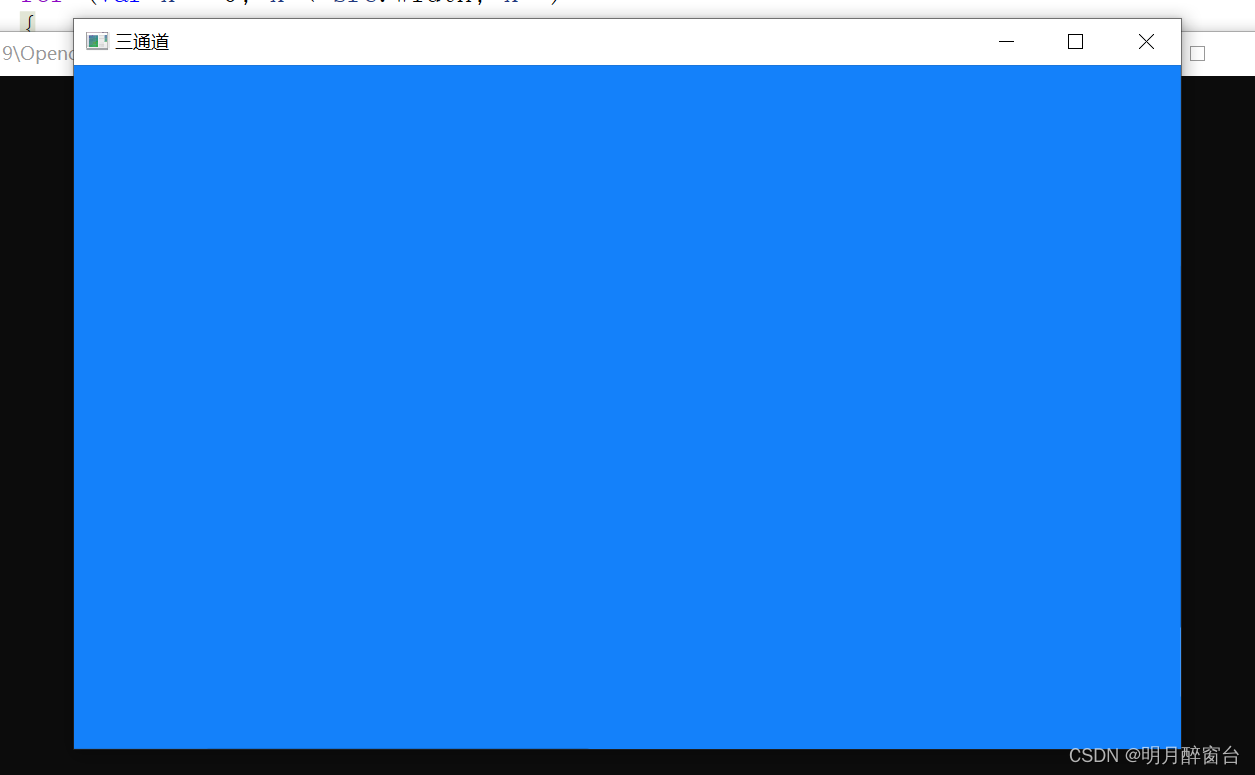
C# - Opencv应用(2) 之矩阵Mat使用[矩阵创建、图像显示、像素读取与赋值]
C# - Opencv应用(2) 之矩阵Mat使用[矩阵创建、图像显示、像素读取与赋值] 矩阵创建图像显示与保存像素读取与赋值新建sample02项目,配置opencv4相关包,新建.cs进行测试 1.矩阵创建 //创建空白矩阵 var dst new Mat()//创建并赋…...
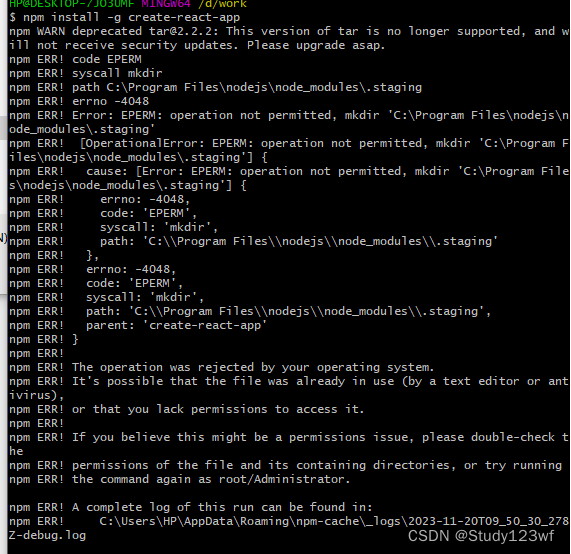
执行npm的时候报权限问题的解决方案
我们在执行npm操作的过程中,会出现以下权限问题,解决方案: 管理员身份 运行cmd 切换目录到要执行命令的文件下 再进行npm操作即可...
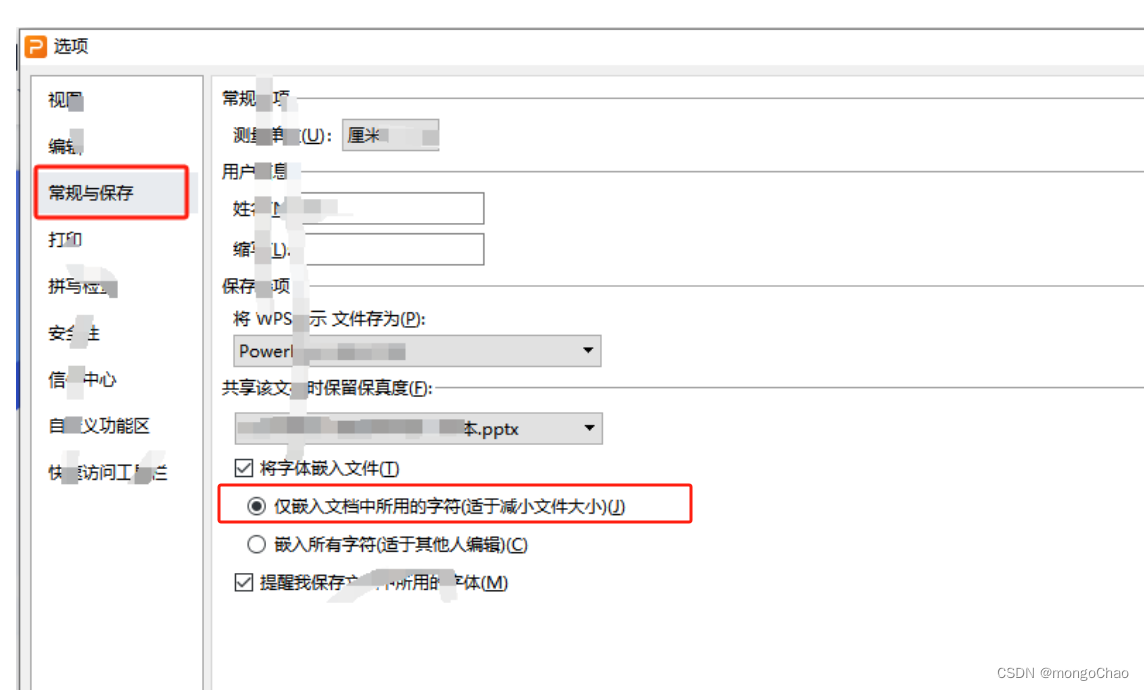
【实用】PPT没几页内存很大怎么解决
PPT页数很少但导出内存很大解决方法 1.打开ppt点击左上角 “文件”—“选项” 2.对话框选择 “常规与保存” (1)如果想要文件特别小时可 取消勾选 “将字体嵌入文件” (2)文件大小适中 可选择第一个选项 “仅最入文档中所用的字…...
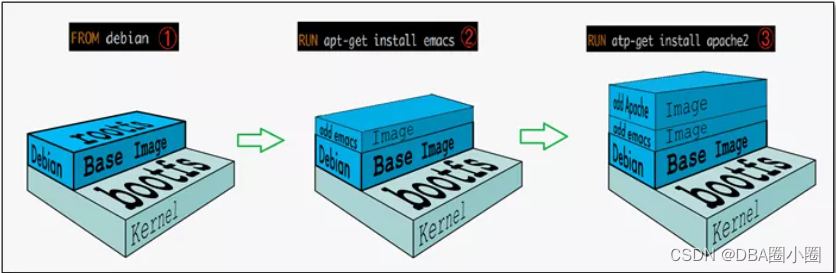
【Docker】从零开始:8.Docker命令:Commit提交命令
【Docker】从零开始:8.Docker命令:Commit命令 基本概念镜像镜像分层什么是镜像分层为什么 Docker 镜像要采用这种分层结构 本章要点commit 命令命令格式docker commit 操作参数实例演示1.下载一个新的ubuntu镜像2.运行容器3.查看并安装vim4.退出容器5提交自己的镜像…...
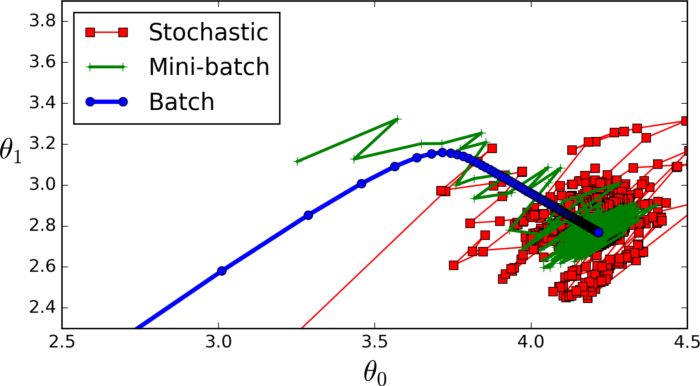
【深度学习】神经网络术语:Epoch、Batch Size和迭代
batchsize:中文翻译为批大小(批尺寸)。 简单点说,批量大小将决定我们一次训练的样本数目。 batch_size将影响到模型的优化程度和速度。 为什么需要有 Batch_Size : batchsize 的正确选择是为了在内存效率和内存容量之间寻找最…...
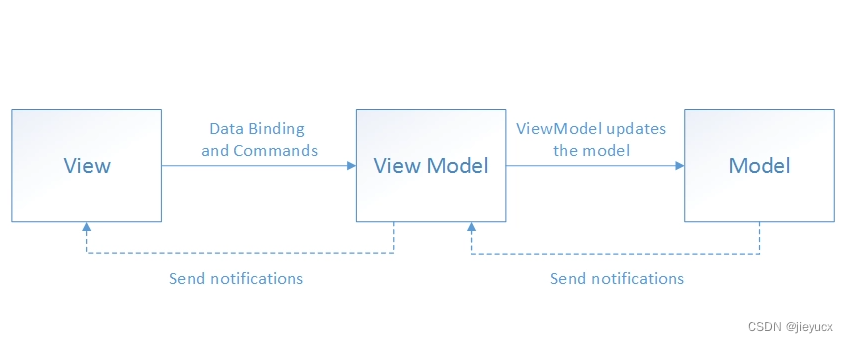
谈谈你对mvc和mvvm的理解
MVC和MVVM是软件开发中两种常见的架构模式,各自有不同的优缺点。 MVC(Model-View-Controller)是一种经典的架构模式,将应用程序分为三个部分:模型(Model)、视图(View)和…...
C语言每日一题(35)有效的括号
力扣网 20 有效的括号 题目描述 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。每个右…...

【DevOps】Git 图文详解(七):标签管理
Git 图文详解(七):标签管理 标签(Tags)指的是某个分支某个特定时间点的状态,是对某一个提交记录的 固定 “指针” 引用。一经创建,不可移动,存储在工作区根目录下 .git\refs\tags。可…...

BootStrap【表格二、基础表单、被支持的控件、表单状态】(二)-全面详解(学习总结---从入门到深化)
目录 表格二 表单_基础表单 表单_被支持的控件 表单_表单状态 表格二 紧缩表格 通过添加 .table-condensed 类可以让表格更加紧凑,单元格中的内补(padding)均会减半 <table class"table table-condensed table-bordered"…...

亿赛通电子文档安全管理系统UploadFileFromClientServiceForClient接口存在任意文件上传漏洞 附POC
@[toc] 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。 1. 亿赛通电子文档安全管理系统接口简介 微信…...

SPSS系统聚类
前言: 本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0 本专栏所有的数据文件请点击此链接下…...
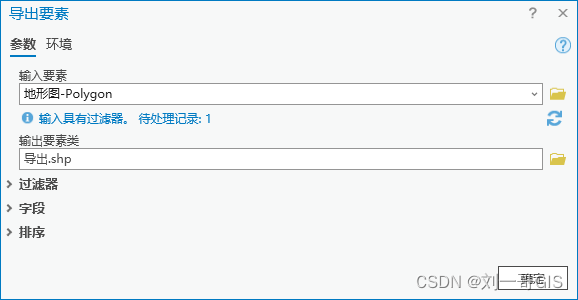
【ArcGIS Pro微课1000例】0033:ArcGIS Pro处理cad数据(格式转换、投影变换)
文章目录 一、cad dwg转shp1. 导出为shp2. cad至地理数据库3. data interoperability tools二、shp投影变换一、cad dwg转shp 1. 导出为shp 加载cad数据,显示如下: 选择需要导出的数据,如面状,右键→数据→导出要素: 导出要素参数如下,点击确定。 导出的要素不带空间参…...
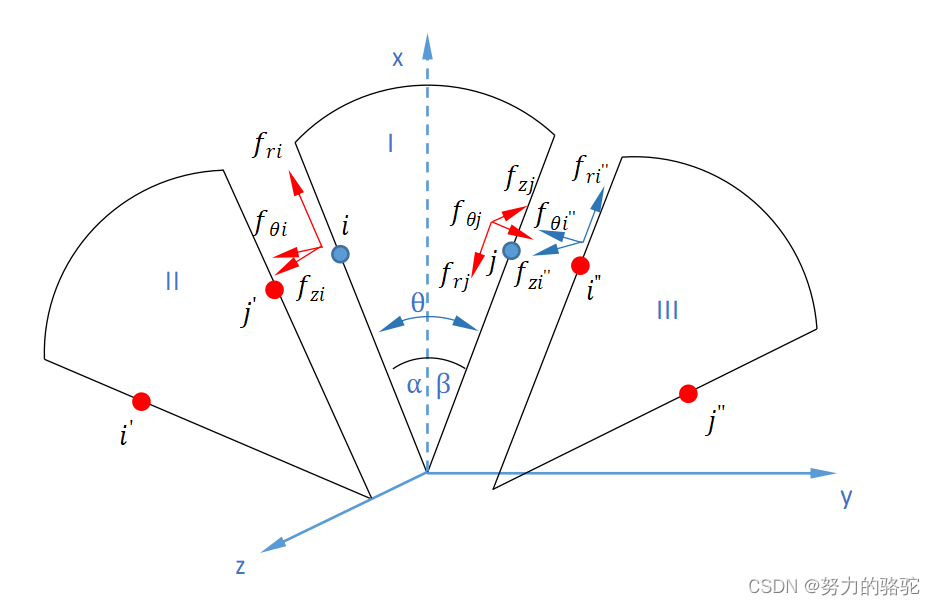
【小呆的力学笔记】有限元专题之循环对称结构有限元原理
文章目录 1. 循环对称问题的提出2. 循环对称条件2.1 节点位移的循环对称关系2.2 节点内力的循环对称关系 3. 在平衡方程中引入循环对称条件 1. 循环对称问题的提出 许多工程结构都是其中某一扇面的n次周向重复,也就是是周期循环对称结构。如果弹性体的几何形状、约…...

GetBox-PyMOL-Plugin:分子对接盒子计算的终极完整指南
GetBox-PyMOL-Plugin:分子对接盒子计算的终极完整指南 【免费下载链接】GetBox-PyMOL-Plugin A PyMOL Plugin for calculating docking box for LeDock, AutoDock and AutoDock Vina. 项目地址: https://gitcode.com/gh_mirrors/ge/GetBox-PyMOL-Plugin 在分…...

Python发票自动化处理实战:Invoice Forge解析、生成与集成指南
1. 项目概述与核心价值 最近在折腾一个个人项目,需要处理大量的发票数据,从PDF里提取信息、生成结构化数据,再根据模板批量生成新的发票文档。一开始想着用现成的库拼凑一下,但试了几个方案,要么功能太单一,…...

新手应该怎样选择第一把琴?尤克里里入门推荐攻略一次讲清
很多想尝试学习乐器的朋友都会把尤克里里当做入门之选,但在学琴前,大部份人都会被“如何选择第一把琴”难住。市面上太多五花八门的品牌和型号,各种尺寸、材质让人眼花缭乱,选贵了怕浪费,选便宜的怕踩雷。尤克里里入门…...

GeoRA:几何感知的低秩适配优化技术解析
1. 项目概述:GeoRA的核心创新与价值 在大型语言模型(LLM)的强化学习可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)场景中,参数高效微调(Parameter-Efficient Fine-Tuning,…...
及长期生存预后的机制联系)
如何将多时间点影像组学特征与肿瘤细胞死亡与微环境重塑建立关联,并进一步解释其与主要病理缓解(MPR)及长期生存预后的机制联系
01导语各位同学,大家好。现在做影像组学,如果还只停留在“提取特征—建个模型—算个AUC”,那就有点像算命算得挺准,但为啥准,自己也说不明白。别人一问:你这特征到底代表啥?背后有啥道理&#x…...

SDQM:合成数据质量评估的创新方法与实践
1. 合成数据质量评估的行业痛点与SDQM创新在计算机视觉领域,数据饥渴已成为制约模型性能提升的主要瓶颈。以工业质检场景为例,要训练一个能识别金属零件表面缺陷的YOLOv11模型,通常需要数万张标注精准的样本。但实际生产中,缺陷样…...

AI智能体安全沙箱AgentKernel:构建生产级防火墙与权限控制
1. 项目概述:为AI智能体构建一道坚不可摧的防火墙 如果你正在或计划在生产环境中部署AI智能体(Agent),无论是基于LangChain、OpenClaw还是AutoGPT,那么有一个问题你迟早会面对: 安全 。这些智能体本质上是…...

雅思词汇资源合集
【21】雅思听力资料 文件大小: 1.4GB内容特色: 1.4GB 雅思听力真题音频精讲适用人群: 备考雅思、冲刺听力高分考生核心价值: 覆盖全题型,精听跟读同步提分下载链接: https://pan.quark.cn/s/8bebe1c27218 13【雅思英语】【97.49GB】 文件大小: 96.9GB内容特色: 9…...

中国数字资产安全新纪元:Ledger 官方直营时代开启
中国数字资产安全新纪元:Ledger 官方直营时代开启 【核心摘要】 2026 年,中国数字资产安全领域迎来里程碑式变革——法国 Ledger 正式确立大中华区直营服务体系。通过京东(JD.com)及微信生态构建的官方授权链路,彻底解…...

如何选择适合项目的「限流 / 熔断 / 降级」方案
如何选择适合项目的「限流 / 熔断 / 降级」方案 一、先分清 3 个核心概念(避免选错) 限流:防刷、防打爆、控制 QPS熔断:依赖服务超时 / 报错太多,直接断开,防止雪崩(比如大模型接口超时、向量库…...