交通流合成数据生成原理及实现代码
移动数据是设备的地理位置,通过正常活动被动产生。 它具有从交通规划到迁移预测的重要应用。 由于移动数据稀有且难以收集,研究人员已开始探索综合生成移动数据的解决方案。
在本文中,我将讨论一种用于合成移动数据的简单解决方案。 该合成数据可用于研究目的和训练/微调算法。 例如,可以综合生成标记的移动数据,并训练模型来预测城市交通拥堵。 然后,训练好的模型可以应用于现实生活中的数据。
代码可以在这里找到,你可以使用这个 colab 笔记本自己尝试一下。
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、合成数据结构
合成数据将代表从手机设备收集的位置数据记录。 通常,此类数据包含以下属性:
- phone_id — 手机的唯一标识符
- phone_type — 手机操作系统(iOS / Android)
- 时间戳(以纪元时间为单位)
- 纬度
- 经度
- 精度(以米为单位)
phone_id,phone_type,timestamp,latitude,longitude,accuracy
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:00:10,30.34639898170681,-97.73158031325373,81.12640643460236
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:09:13,30.34642963771432,-97.73140260170493,25.094041385659516
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:18:55,30.346380588102306,-97.73148816652471,122.98442053366325
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:28:16,30.34643576891581,-97.7315210760708,185.08383036465293
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:37:36,30.346366281965476,-97.73138285597729,55.565838723523676
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:47:04,30.346372413166982,-97.7316461323459,36.26985794887487
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 00:56:20,30.346384675569983,-97.73156056752609,144.42897717113405
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 01:05:23,30.34640511290831,-97.73140918361412,43.246590356759704
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 01:14:25,30.34634584462714,-97.73150791225235,46.35681270455376
cfcd208495d565ef66e7dff9f98764da,iOS,2022-01-01 01:23:57,30.346441900117316,-97.73162638661823,157.833821488090422、获取公开的位置数据
在美国选择一个位置并创建一个 x 米的 bbox(边界框)。 接下来,获取公共数据集:
- 居住地点 — bbox 内的建筑物示例 (ArcGIS Rest API)
- POI(兴趣点)— bbox 内的企业 (Kaggle数据集)
- Roads — bbox 内的所有道路,以图表形式表示(OSM Overpass API,使用 osmnx)
创建包围框:
import osmnx as ox
lat, lng, radius = 45.496920, -122.665803, 10000
bbox = ox.utils_geo.bbox_from_point((lat, lng), radius)
bbox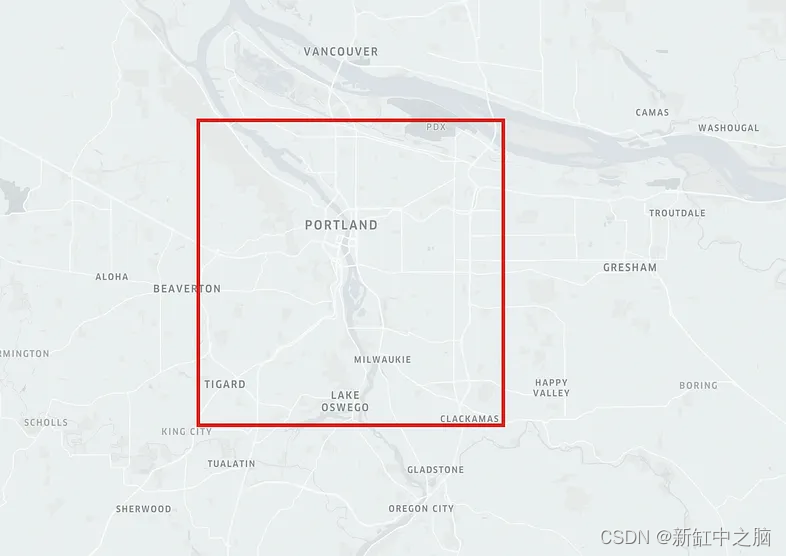 使用 arcgis_rest_url 获取 bbox 内建筑物的多边形,最多2000 个多边形样本。
使用 arcgis_rest_url 获取 bbox 内建筑物的多边形,最多2000 个多边形样本。
import geopandas as gpdARCGIS_REST_URL = 'https://services.arcgis.com/P3ePLMYs2RVChkJx/ArcGIS/rest/services/MSBFP2/FeatureServer/0/query?f=json&returnGeometry=true&spatialRel=esriSpatialRelIntersects&geometry={"ymax":%s,"ymin":%s,"xmax":%s,"xmin":%s,"spatialReference":{"wkid":4326}}&geometryType=esriGeometryEnvelope&outSR=4326'residence_df = gpd.read_file(ARCGIS_REST_URL % bbox)
residence_df['lat'] = residence_df['geometry'].centroid.y
residence_df['lng'] = residence_df['geometry'].centroid.x
residence_df.head()结果如下:
BlockgroupID geometry lat lng
0 410510005012 POLYGON ((-122.59120 45.48139, -122.59120 45.4... 45.481425 -122.591104
1 410510059001 POLYGON ((-122.67869 45.49746, -122.67869 45.4... 45.497409 -122.678765
2 410510074002 POLYGON ((-122.60844 45.56566, -122.60844 45.5... 45.565693 -122.608380
3 410050216022 POLYGON ((-122.59890 45.43605, -122.59890 45.4... 45.435959 -122.598965
4 410510017012 POLYGON ((-122.58212 45.52941, -122.58212 45.5... 45.529375 -122.582223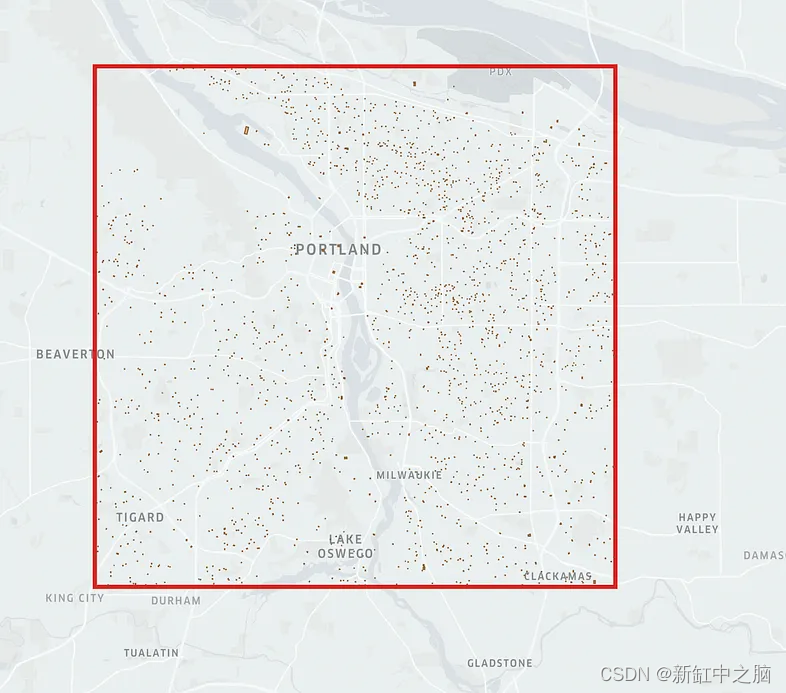 使用 Kaggle API 下载 POI 数据集。 然后解析它,将其加载到 geopandas 并将数据集过滤为仅 bbox 内的点。
使用 Kaggle API 下载 POI 数据集。 然后解析它,将其加载到 geopandas 并将数据集过滤为仅 bbox 内的点。
def isin_box(lat, lng, bounds):ymax, ymin, xmax, xmin = boundswithin = Falseif xmin < lng < xmax:if ymin < lat < ymax:within = Truereturn withinimport os
import json
import pandas as pd
from shapely.geometry import Pointexport_path = '<your_export_path_here>'API_TOKEN = {"username": 'your_kaggle_username_here', "key": 'your_kaggle_key_here'}os.system('mkdir ~/.kaggle')
os.system('touch ~/.kaggle/kaggle.json')with open('/root/.kaggle/kaggle.json', 'w') as file:json.dump(API_TOKEN, file)os.system('chmod 600 ~/.kaggle / kaggle.json')
os.system(f'mkdir /{export_path}/pois_data/')os.system(f'kaggle datasets download -d timmofeyy/-pizza-hut-restaurants-locations-in-us -p /{export_path}/pois_data/pizza-hut --unzip')
os.system(f'kaggle datasets download -d timmofeyy/-walmart-stores-location -p /{export_path}/pois_data/walmart --unzip')
os.system(f'kaggle datasets download -d appleturnovers/dunkin-locations -p /{export_path}/pois_data/dunkin --unzip')
os.system(f'kaggle datasets download -d timmofeyy/-subway-locations-in-us -p /{export_path}/pois_data/subway --unzip')pois_dfs = []for chain_name in os.listdir('/content/pois_data'):chain_file = [i for i in os.listdir(f'/{export_path}/pois_data/{chain_name}') if i.endswith('.csv')][0]chain_df = pd.read_csv(os.path.join(f'/{export_path}/pois_data', chain_name, chain_file))chain_df['poi_name'] = chain_namechain_df = chain_df.rename(columns={'latitude': 'lat','longitude': 'lng','lon': 'lng','loc_lat': 'lat','loc_long': 'lng','Latitude': 'lat','Longitude': 'lng'})[['poi_name', 'lat', 'lng']]chain_df['lat'], chain_df['lng'] = chain_df['lat'].astype(float), chain_df['lng'].astype(float)pois_dfs.append(chain_df)pois_df = pd.concat(pois_dfs, ignore_index=True)
pois_df = pois_df.dropna(subset=['lat', 'lng'], how='any')pois_df = pois_df[pois_df.apply(lambda x: isin_box(x['lat'], x['lng'], bbox), axis=1)]
pois_df['id'] = pois_df.index
pois_df['geometry'] = pois_df.apply(lambda x: Point(x['lng'], x['lat']), axis=1)
pois_df = gpd.GeoDataFrame(pois_df)pois_df.head() 结果如下:
poi_name lat lng id geometry
2996 Pizanos Pizza 45.516327 -122.559344 2996 POINT (-122.55934 45.51633)
3626 Washington Street Palace 45.518799 -122.654747 3626 POINT (-122.65475 45.51880)
6131 Fred Meyer 45.586069 -122.738125 6131 POINT (-122.73813 45.58607)
7392 Moberi 45.510439 -122.682163 7392 POINT (-122.68216 45.51044)
7920 Ether 45.526996 -122.698438 7920 POINT (-122.69844 45.52700)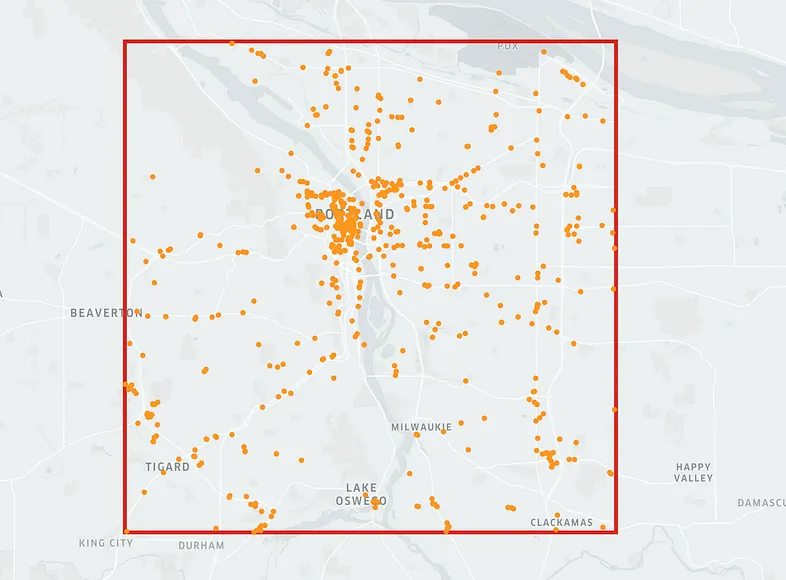
从 Overpass API 获取 OSM 道路:
G = ox.graph_from_bbox(*bbox, network_type="drive", retain_all=True, truncate_by_edge=True)结果如下:
现在我们已经拥有了创建电话时间线所需的一切 — 居住位置(将用于在家中、家人和朋友家中的停留)、POI 位置(将用于商店访问)和道路(将用于 住宿期间开车)。 在生成实际的移动数据之前,我们将生成一个综合时间线,其中包含手机停留时间及其时间范围。
3、生成合成时间线
合成时间线逻辑将迭代开始日期和结束日期之间的所有日期,并随机化在工作场所、居住地点和 POI 的停留时间。 为了保证正常的人类行为,该逻辑将仅在工作日产生工作停留,并确保用户晚上回家。
在运行逻辑之前,请确保:
- 设置随机的家庭和工作地点
- 设置时间范围(开始日期和结束日期)
- 设置指定日期要访问的最大 POI 和最大居住地点
home_info = residence_df.sample(1).to_dict(orient='records')[0] # pick a random home location
work_info = pois_df.sample(1).to_dict(orient='records')[0] # pick a random work location
start_date = '2022-10-01' # timeline start time
end_date = '2022-11-01' # timeline end time
max_residence = 3 # max residence stay in a day
max_pois = 3 # max poi stay in a dayfrom datetime import timedelta
import numpy as npphone_timeline = []stays_counter = 0
for day in pd.date_range(start_date, end_date):n_residence = np.random.choice(range(1, max_residence))n_pois = np.random.choice(range(1, max_pois))levaing_hour = np.random.choice([6,7,8])start_time = dayend_time = day + timedelta(hours=int(levaing_hour))phone_timeline.append({'stay_id': stays_counter,"start_time": start_time,"end_time": end_time,'entity_id': 'home','entity_name': 'home','entity_type': 'home','lat': home_info['lat'],'lng': home_info['lng']})stays_counter+=1if day.weekday() not in [5,6]: # if working dayworking_hours = np.random.choice([7,8,9])start_time = end_timeend_time += timedelta(hours=int(working_hours))phone_timeline.append({'stay_id': stays_counter,"start_time": start_time,"end_time": end_time,"entity_id": 'work','entity_name': 'work','entity_type': 'work','lat': work_info['lat'],'lng': work_info['lng']})stays_counter+=1time_left = 24 - end_time.hourif n_residence !=0 or n_pois !=0:time_left -= 1 # leave 1 hour to stay at home at the end of the timelinetime_per_stay = np.floor(time_left/(n_residence + n_pois))if n_residence !=0:for row in residence_df.sample(n_residence).itertuples():start_time = end_timeend_time += timedelta(hours=int(time_per_stay))time_left -= time_per_stayphone_timeline.append({'stay_id': stays_counter,"start_time": start_time,"end_time": end_time,'entity_name': row.Index,'entity_type': 'building','entity_id': row.Index,'lat': row.lat,'lng': row.lng})stays_counter+=1if n_pois !=0:for row in pois_df.sample(n_pois).itertuples():start_time = end_timeend_time += timedelta(hours=int(time_per_stay))time_left -= time_per_stayphone_timeline.append({'stay_id': stays_counter,"start_time": start_time,"end_time": end_time,'entity_name': row.poi_name,'entity_type': 'venue','entity_id': row.Index,'lat': row.lat,'lng': row.lng})stays_counter+=1start_time = end_timeend_time += timedelta(hours=int(time_left))phone_timeline.append({'stay_id': stays_counter,"start_time": start_time,"end_time": end_time + timedelta(hours=abs(end_time.hour-24)),'entity_id': 'home','entity_name': 'home','entity_type': 'home','lat': home_info['lat'],'lng': home_info['lng']})stays_counter+=1
phone_timeline = pd.DataFrame(phone_timeline)
phone_timeline.head()结果如下:
stay_id start_time end_time entity_id entity_name entity_type lat lng
0 0 2022-10-01 00:00:00 2022-10-01 08:00:00 home home home 45.410639 -122.552044
1 1 2022-10-01 08:00:00 2022-10-01 10:00:00 1290 1290 building 45.449074 -122.758561
2 2 2022-10-01 10:00:00 2022-10-01 12:00:00 249212 Al's Garden Center poi 45.458765 -122.710870
3 3 2022-10-01 12:00:00 2022-10-01 14:00:00 502973 Lloyd Center poi 45.532621 -122.653473
4 4 2022-10-01 14:00:00 2022-10-01 16:00:00 225659 B&B Barbershop poi 45.483497 -122.581378下面的 gif 显示了我们合成时间线中的第一天: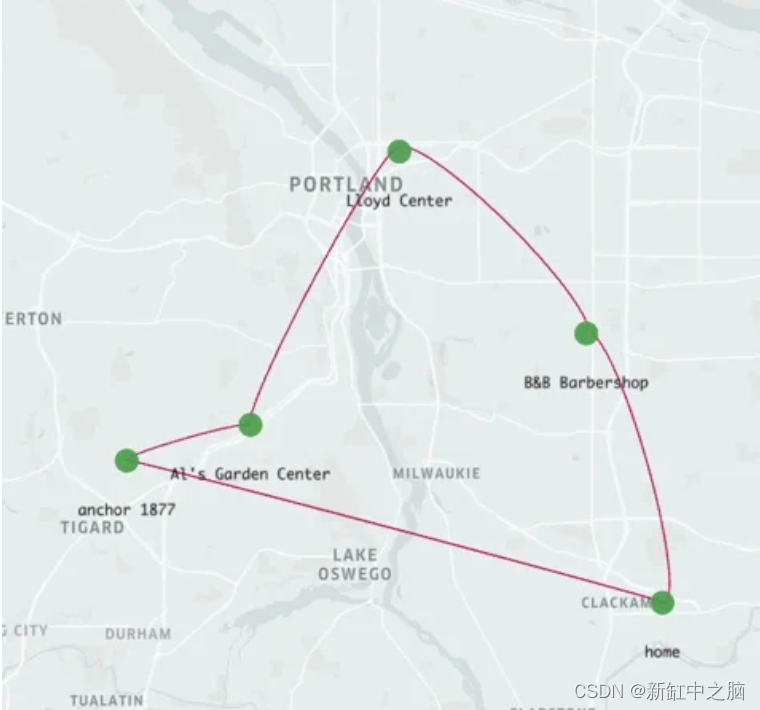
4、生成合成移动数据(信号)
我们的合成时间线已准备就绪,需要新的逻辑将其转换为合成信号。 我们时间线中的第一个事件是寄宿家庭 (00:00 -> 08:00),所以让我们从为这次住宿生成信号开始。
4.1 静态模式信号
以下脚本将生成停留开始和停留结束之间的信号数据帧。 采样率(相邻信号之间的时间间隔)是一个可配置的参数。 我将其设置为 600 秒(5 分钟)。 每个信号的 lat,lng 将使用随机“噪声系数”进行噪声处理
def generate_static_signals(lat, lng, start_time, end_time, sampling_rate=600):signals_list = []signal_time = start_time + timedelta(seconds=int(np.random.choice([5,10,15]))) # start smaple couple of second after visits startnoise_list = np.linspace(0.9999997, 1.000003) # noise factorwhile end_time > signal_time:signals_list.append({'lat': lat*np.random.choice(noise_list), 'lng': lng*np.random.choice(noise_list),'timestamp': signal_time})signal_time += timedelta(seconds=sampling_rate - int(np.random.choice(range(0,59))))return pd.DataFrame(signals_list).sort_values('timestamp')在第一次停留时应用逻辑将产生以下输出:
4.2 驾驶模式信号
我们时间线上的下一个事件是在“Residence 1290”停留,但在为本次停留生成信号之前,我们需要为将手机从出发地(家)带到目的地(“Residence 1290”)的驱动器生成信号 。
为此,我们将使用道路图并寻找从起点到目的地的最短路径。 然后,我们将以 60 秒的采样率在有序路段上随机生成信号。
from shapely.ops import linemerge, nearest_points, snap
from shapely.geometry import LineString, Point, MultiLineString
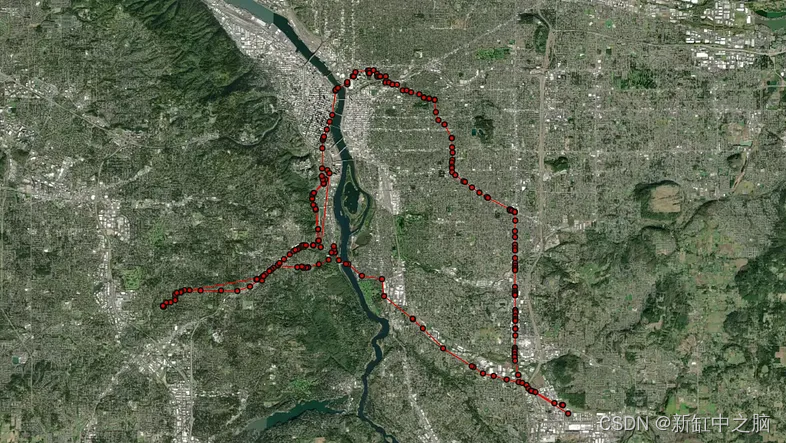
import taxicab as tcdef generate_route_signals(route_geo, start_time, sampling_rate=60):end_time = start_time + timedelta(minutes=int(np.random.choice(range(15,50))))N_POINTS = round((end_time - start_time).total_seconds() / sampling_rate)POINTS_PER_SEGMENT = 10noise_list = np.linspace(0.9999999, 1.000001) # add noise to pointssignal_time = start_time - timedelta(seconds=int(np.random.choice([5,10,15])))timestamps_list = []for i in range(0,N_POINTS):timestamps_list.append(signal_time)signal_time += timedelta(seconds=sampling_rate + int(np.random.choice(range(0,9))))line_to_points = np.array([{'lat': y*np.random.choice(noise_list), 'lng': x*np.random.choice(noise_list)}for p1, p2 in zip(route_geo.coords, route_geo.coords[1:]) # iterate through line segmentsfor x, y in zip(np.linspace(p1[0], p2[0], POINTS_PER_SEGMENT),np.linspace(p1[1], p2[1], POINTS_PER_SEGMENT),)])indexes = np.sort(np.random.choice(range(0, len(line_to_points)),replace=False,size=min(N_POINTS, len(line_to_points)))) random_points = line_to_points[indexes]signals_df = pd.DataFrame([i for i in random_points])signals_df['timestamp'] = timestamps_list[:len(signals_df)]return signals_df, signal_timedef get_route_geometry(route, orig, dest):x, y = [], []for u, v in zip(route[tc.constants.BODY][:-1], route[tc.constants.BODY][1:]):# if there are parallel edges, select the shortest in lengthdata = min(G.get_edge_data(u, v).values(), key=lambda d: d["length"])if "geometry" in data:# if geometry attribute exists, add all its coords to listxs, ys = data["geometry"].xyx.extend(xs)y.extend(ys)else:# otherwise, the edge is a straight line from node to nodex.extend((G.nodes[u]["x"], G.nodes[v]["x"]))y.extend((G.nodes[u]["y"], G.nodes[v]["y"]))final_route = []if route[2]:final_route.append(LineString([Point(orig[1], orig[0]),nearest_points(Point(orig[1], orig[0]),route[2])[1]]))final_route.append(route[2])else:final_route.append(LineString([Point(orig[1], orig[0]),Point(x[0],y[0])]))final_route.append(LineString([Point(lng,lat) for lng, lat in list(zip(x, y))]))if route[3]:final_route.append(route[3])final_route.append(LineString([nearest_points(Point(dest[1],dest[0]), route[3])[1],Point(dest[1],dest[0])]))else:final_route.append(LineString([Point(x[-1],y[-1]), Point(dest[1],dest[0])]))final_route_geo = linemerge(final_route)if isinstance(final_route_geo, MultiLineString):final_route_geo = linemerge([snap(i, j,0.000001) for i,j in zip(final_route, final_route[1:])])if isinstance(final_route_geo, MultiLineString):final_route_geo = list(final_route_geo)[np.argmax(np.array([len(i.coords) for i in list(final_route_geo)]))]return final_route_geo这就是合成驾驶信号在地图上的样子: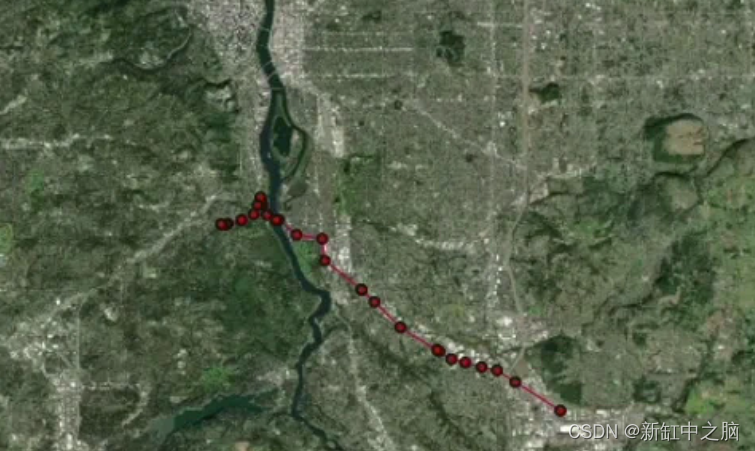
4.3 完整的合成移动数据生成
在最后一步中,我们将迭代所有的合成时间线。 对于每次停留,我们将生成静态模式信号,并且在每两次停留之间,我们将生成驾驶模式信号。
def generate_signals_df(device_timeline, G):signals_dfs = []drive_end = Nonefor row in device_timeline\.join(device_timeline[['lat','lng']].shift(-1), lsuffix='_orig', rsuffix='_dest')\.dropna(subset=['lat_orig','lng_orig','lat_dest','lng_dest'],how='any').itertuples():if not drive_end:drive_end = row.start_timestay_signals = generate_static_signals(row.lat_orig, row.lng_orig, drive_end, row.end_time)signals_dfs.append(stay_signals)route = tc.distance.shortest_path(G, (row.lat_orig, row.lng_orig), (row.lat_dest,row.lng_dest))route_geo = get_route_geometry(route, (row.lat_orig, row.lng_orig), (row.lat_dest,row.lng_dest))drive_signals, drive_end = generate_route_signals(route_geo, row.end_time, 45)signals_dfs.append(drive_signals)device_signals = pd.concat(signals_dfs, ignore_index=True).sort_values('timestamp')return device_signals好了! 我们现在拥有由开源包和免费数据生成的完整的移动合成数据。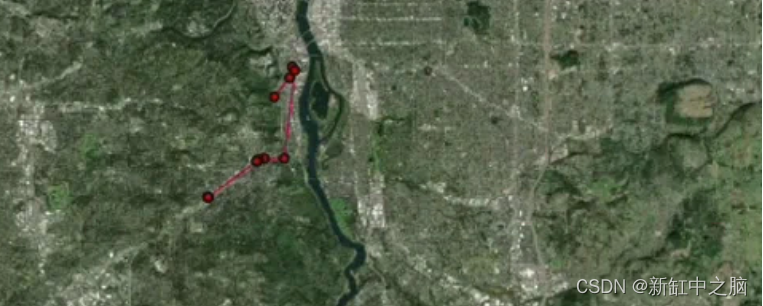
5、结束语
生成合成移动数据是可行的,不需要特殊资源。 我们需要的所有数据都在那里并且可以免费使用。 话虽如此,仍有改进的空间:
- 逻辑的幼稚:逻辑非常简单,因此输出并不能真正代表完整的人类行为(例如出国旅行、移民等)
- 逻辑的效率:逻辑需要一些时间来运行。 主要瓶颈是驾驶生成部分(最短路径计算)
- 逻辑的覆盖范围:仅支持美国,这是因为我使用了
USBuildingFootprints,它非常准确,但不幸的是仅覆盖美国。
原文链接:交通流动合成数据生成 - BimAnt
相关文章:
交通流合成数据生成原理及实现代码
移动数据是设备的地理位置,通过正常活动被动产生。 它具有从交通规划到迁移预测的重要应用。 由于移动数据稀有且难以收集,研究人员已开始探索综合生成移动数据的解决方案。 在本文中,我将讨论一种用于合成移动数据的简单解决方案。 该合成数…...

leetcode 240. 搜索二维矩阵 II
2023.11.22 本题最先想到的是暴力法和二分法,暴力法就不写了,写一下二分法的解法,java代码如下: class Solution {public boolean searchMatrix(int[][] matrix, int target) {for(int[] row : matrix){int left 0;int right r…...

a标签超链接 —— 实现点击前中后变色
浅浅记录下 <style type"text/css"> a:link {color: yellow; /*未访问链接颜色*/ }a:visited {color: red; /*已访问链接颜色*/ }a:hover {color: blue; /*鼠标移动到链接颜色*/text-decoration: underline; }a:active {color: orange; /*鼠标点击时颜色*/ }a…...
【好玩的开源项目】Linux系统之部署proxx扫清黑洞小游戏
【好玩的开源项目】Linux系统之部署proxx扫清黑洞小游戏 一、proxx小游戏介绍1.1 proxx小游戏简介1.2 开源地址 二、本地环境介绍2.1 本地环境规划2.2 本次实践介绍 三、检查本地环境3.1 检查本地操作系统版本3.2 检查系统内核版本 四、部署Node.js环境4.1 下载Node.js安装包4.…...
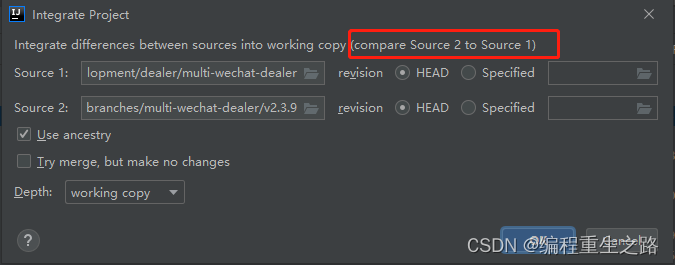
IDEA-SVN合并分支到主干
IDEA-SVN合并branch分支到主干master 1.选择VCS的 Integrate Project 2.选择分支合并 Source1 是合并后的分支 , 主分支 master Source2 是被合并的分支 , 分支 branch Try merge 可以尝试是否可以能够被合并,并且无冲突 3.合并完成后当前项目会出现需要提交的内容,检查一…...

kettle如何写日志
var subject"自定义日志输出"; //实例化工厂类 var logFactory new org.pentaho.di.core.logging.LogChannelFactory(); //实例化日志channel对象 var log logFactory.create(subject); //日志输出 log.logMinimal("XXXXXXXXXXXXXXXXXXXXXXXX-preRows"acc…...

新能源车将突破2000万辆,汉威科技为电池安全保驾护航
近年来,我国新能源汽车销量持续突破新高。据中汽协数据,1~10月,国内新能源汽车销量达728万辆,同比增长37.8%,市场占有率达到30.4%。随着第四季度车市传统旺季的到来,新能源消费需求将进一步释放,…...
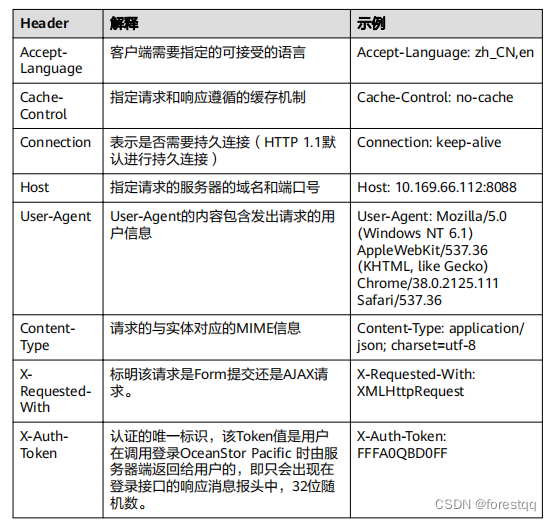
基于文心一言AI大模型,编写一段python3程序以获取华为分布式块存储REST接口的实时数据
本文尝试基于文心一言AI大模型,编写一段python3程序以获取华为分布式块存储REST接口的实时数据。 一、用文心一言AI大模型将需求转化为样例代码 1、第一次对话:“python3写一段从rest服务器获取数据的样例代码” 同时生成了以下注解 这段代码首先定义…...

2022-4-11 南科大现代控制与最优估计
CLEAR_LAB B站视频 矩阵的分块矩阵操作 diagonal 对角阵 identity matrix 单位矩阵 矩阵克罗内克积...
【注册Huggingface】获取token
Hugging Face是一家美国公司,专门开发用于构建机器学习应用的工具。该公司的代表产品是其为自然语言处理应用构建的transformers库,以及允许用户共享机器学习模型和数据集的平台。 Huggingface 是一个开源的cv、nlp框架,提供了超过100,000个…...

【蓝桥杯软件赛 零基础备赛20周】第4周——简单模拟1
文章目录 什么是简单模拟简单模拟和编程能力刷题 什么是简单模拟 正在学编程语言(C/C、Python、Java),或者刚学过语言,还没有开始学数据结构和算法的同学,有一些疑问:如何快速入门算法竞赛?如何…...

使用OpenCV将图像转换为NV12格式并加载NV12数据
摘要:在新项目中,需要为上层应用开放几个接口,但又不想让上层应用过多依赖OpenCV。本文将详细介绍如何使用C和OpenCV,通过加载图片并转换为NV12格式,实现对图像数据的处理,以及如何加载NV12数据并显示。这些…...

【Lodash】 Filter 与Map 的结合使用
用Filter过滤数据之后,想给某个字段重新赋值 在使用 filter() 方法过滤数据后,如果你想给某个字段赋值,你可以使用 map() 方法来修改数组中的元素。map() 方法可以对数组中的每个元素应用一个函数,并返回一个新的数组。 以下是一…...

python命令行 引导用户填写可用的ip地址和端口号
字多不看,直接体验 待补充 演示代码 # -*- coding:UTF-8 -*- """ author: dyy contact: douyaoyuan126.com time: 2023/11/23 10:29 file: 引导用户填写可用的ip地址和端口号.py desc: xxxxxx """# region 引入必要的依赖 import …...

【小黑送书—第九期】>>重磅!这本30w人都在看的Python数据分析畅销书:更新了!
想学习python进行数据分析,这本《利用python进行数据分析》是绕不开的一本书。目前该书根据Python3.10已经更新到第三版。 Python 语言极具吸引力。自从 1991 年诞生以来,Python 如今已经成为最受欢迎的解释型编程语言。 pandas 诞生于2008年。它是由韦…...
关于APP备案的通知以及APP备案的常见问题
前言 众所周知今年8月份,工信部出台了《工业和信息化部关于开展移动互联网应用程序备案工作的通知》,APP开发者的影晌是显而易见的。开发者需要按照要求提交相关材料进行备案,这无疑增加了开发者的时间和精力成本。虽然备案制度会增加开发者…...

iOS 17.0 YYText 崩溃处理
YYText,发现在iOS 17上运行会崩溃,触发了系统的断言: UIGraphicsBeginImageContext() failed to allocate CGBitampContext: size{382, 0}, scale3.000000, bitmapInfo0x2002. Use UIGraphicsImageRenderer to avoid this assert. 查了下 ap…...
微信小程序面试题【100道】
文章目录 小程序面试题100问前言一、技术性问题1.有哪些参数传值的方法2.小程序修改数据值与Vue和React有什么差异3.如何实现下拉刷新与上拉加载4.bindtap和catchtap的区别是什么5.小程序有哪些导航API,它们各自的应用场景与差异区别是什么6.小程序中如何使用第三方…...
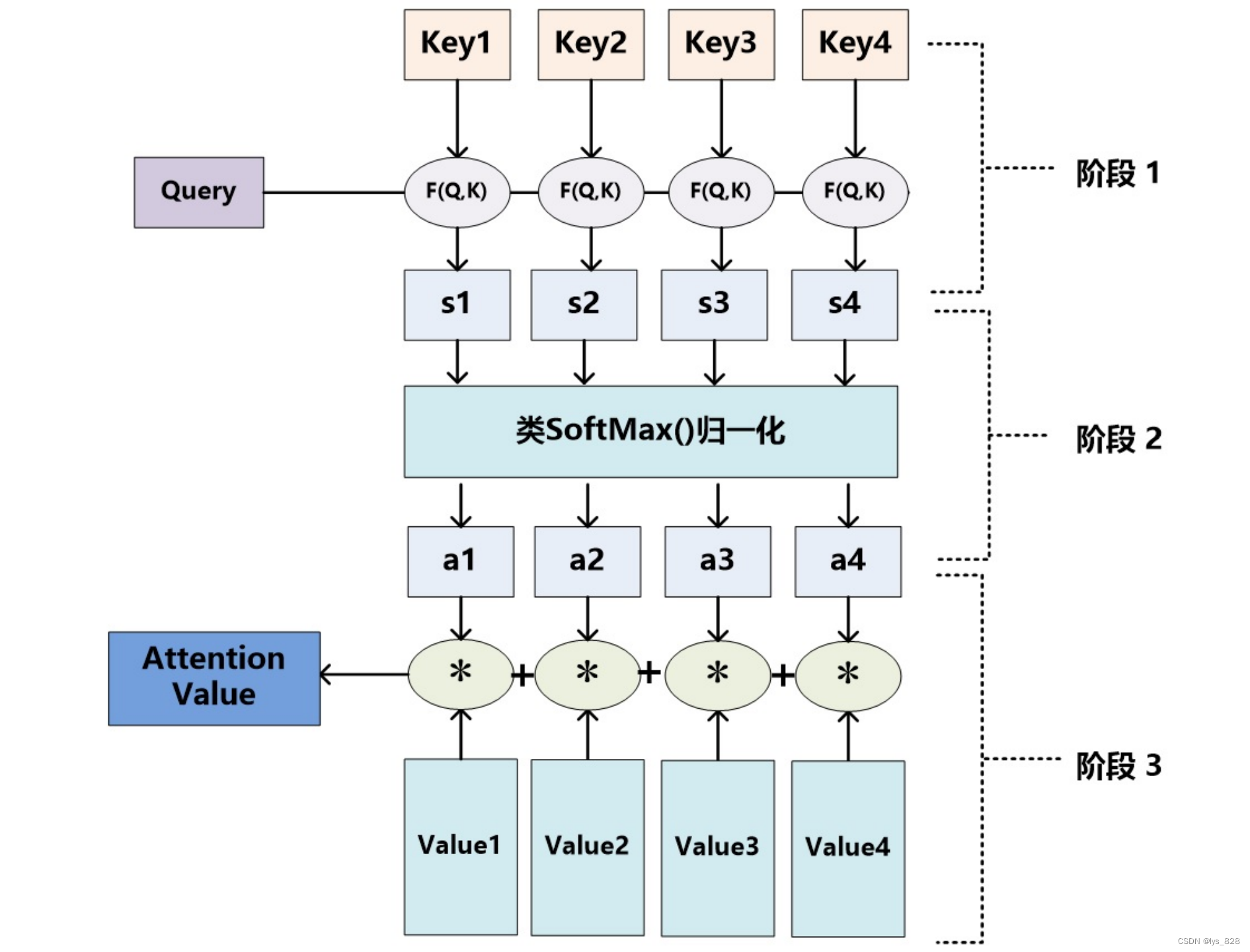
【nlp】2.8 注意力机制拓展
注意力机制拓展 1 注意力机制原理1.1 注意力机制示意图1.2 Attention计算过程1.3 Attention计算逻辑1.4 有无attention模型对比1.4.1 无attention机制的模型1.4.2 有attention机制的模型1 注意力机制原理 1.1 注意力机制示意图 Attention机制的工作原理并不复杂,我们可以用下…...

mysql 存储引擎ROWS与实际行数不一致
引言 在使用 MySQL 数据库时,我们经常会用到 SHOW TABLE STATUS 命令来获取表的统计信息,其中包括行数(rows)的估计值。然而,有时候我们会发现这个估计值与实际的行数并不一致。本文将探讨这个问题,并提供…...

声定向系统改良设计——大功率集成化声频定向扬声器系统
声定向系统改良设计——大功率集成化声频定向扬声器系统 摘要 声频定向扬声器系统是一种利用超声波在空气中的非线性传播效应产生高指向性可听声的新型声学设备。针对原有系统在输出功率不足、模块分立程度高、系统集成度低等方面存在的问题,本文提出了一套完整的改良设计方…...

Fan Control终极指南:三步告别电脑噪音烦恼,打造个性化散热方案
Fan Control终极指南:三步告别电脑噪音烦恼,打造个性化散热方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.co…...

别只当键盘用!用RISE 75的热插拔PCB,我给自己做了个无线宏命令控制器
别只当键盘用!用RISE 75的热插拔PCB,我给自己做了个无线宏命令控制器 作为一名效率工具发烧友,我一直在寻找能够提升工作流的硬件解决方案。直到某天盯着闲置的RISE 75 PCB板,突然意识到这块支持蓝牙5.2双模和全键编程的电路板&am…...

NCM文件解密终极指南:3分钟快速转换网易云音乐加密文件为MP3
NCM文件解密终极指南:3分钟快速转换网易云音乐加密文件为MP3 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放?NCM加密格式的限…...

职场加班记录程序,加班时间,内容上链,不可篡改,用于薪资核算维权。
一、实际应用场景描述在软件开发、互联网运营、运维等岗位中,加班现象较为普遍。典型流程为:1. 员工在下班后继续处理工作2. 通过聊天工具或口头告知主管3. 人事/财务在月底统计加班时长4. 薪资核算时存在争议或遗漏本系统通过客户端自主上链 哈希存证的…...

在安卓手机上用Termux跑Ubuntu桌面:手把手教你配置xfce4和VNC远程连接
在安卓手机上打造便携式Linux工作站:TermuxUbuntuxfce4全攻略 把安卓手机变成一台能跑完整Linux桌面的便携设备?这听起来像是极客们的幻想,但借助Termux和Ubuntu,这个想法已经变得触手可及。不同于简单的终端模拟,我们…...

Appian引入MCP协议并与Snowflake合作,为智能体提供强管控能力
商业流程自动化软件公司Appian在其年度用户大会Appian World 2026上宣布了平台重大更新,重点聚焦于AI辅助应用开发与模型上下文协议(MCP)集成,进一步强化其在智能体AI领域的布局。Appian在大会上阐述了将AI锚定于业务流程之中的理…...

ArcGIS Python API 地理编码完全指南:地址解析与反向地理编码
ArcGIS Python API 地理编码完全指南:地址解析与反向地理编码 【免费下载链接】arcgis-python-api Documentation and samples for ArcGIS API for Python 项目地址: https://gitcode.com/gh_mirrors/ar/arcgis-python-api ArcGIS Python API 是一款功能强大…...

Manus、Openclaw、Claude Code 和 Codex之间的关系
Manus、Openclaw、Claude Code 和 Codex 都是 2025-2026 年 AI Agent(智能体)浪潮中的代表性工具,它们的核心共同点是“不仅仅聊天,而是能自主规划、执行任务并交付成果”(agentic AI),区别于传…...

Sargentech-AI框架解析:模块化LLM应用开发与生产部署实践
1. 项目概述:一个面向未来的AI应用开发框架最近在GitHub上看到一个挺有意思的项目,叫“Sargentech-AI/sargentech-ai”。光看这个名字,你可能会觉得有点神秘,或者猜测它是不是某个特定公司的内部工具。但点进去仔细研究后…...