FastText模型文本分类
项目地址:NLP-Application-and-Practice/07_FastText/7.2-FastText文本分类/text_classification at master · zz-zik/NLP-Application-and-Practice (github.com)
加载数据
load_data.py
# coding: UTF-8
import os
import pickle as pkl
from tqdm import tqdmMAX_VOCAB_SIZE = 10000 # 词表长度限制
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def build_vocab(file_path, tokenizer, max_size, min_freq):vocab_dic = {}with open(file_path, 'r', encoding='UTF-8') as f:for line in tqdm(f):lin = line.strip()if not lin:continuecontent = lin.split('\t')[0]for word in tokenizer(content):vocab_dic[word] = vocab_dic.get(word, 0) + 1vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})return vocab_dicdef build_dataset(config, ues_word):if ues_word:tokenizer = lambda x: x.split(' ') # 以空格隔开,word-levelelse:tokenizer = lambda x: [y for y in x] # char-levelif os.path.exists(config.vocab_path):vocab = pkl.load(open(config.vocab_path, 'rb'))else:vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)pkl.dump(vocab, open(config.vocab_path, 'wb'))print(f"Vocab size: {len(vocab)}")def load_dataset(path, pad_size=32):contents = []with open(path, 'r', encoding='UTF-8') as f:for line in tqdm(f):lin = line.strip()if not lin:continuecontent, label = lin.split('\t')words_line = []token = tokenizer(content)seq_len = len(token)if pad_size:if len(token) < pad_size:token.extend([PAD] * (pad_size - len(token)))else:token = token[:pad_size]seq_len = pad_size# word to idfor word in token:words_line.append(vocab.get(word, vocab.get(UNK)))# -----------------contents.append((words_line, int(label), seq_len))return contents # [([...], 0), ([...], 1), ...]train = load_dataset(config.train_path, config.pad_size)dev = load_dataset(config.dev_path, config.pad_size)test = load_dataset(config.test_path, config.pad_size)return vocab, train, dev, test迭代加载数据
load_data_iter.py
# coding:utf-8
import torch# 批量加载数据
class DatasetIterater(object):def __init__(self, batches, batch_size, device):self.batch_size = batch_sizeself.batches = batchesself.n_batches = len(batches) // batch_sizeself.residue = False # 记录batch数量是否为整数if len(batches) % self.n_batches != 0:self.residue = Trueself.index = 0self.device = devicedef _to_tensor(self, datas):x = torch.LongTensor([_[0] for _ in datas]).to(self.device)y = torch.LongTensor([_[1] for _ in datas]).to(self.device)# pad前的长度(超过pad_size的设为pad_size)seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)return (x, seq_len), ydef __next__(self):if self.residue and self.index == self.n_batches:batches = self.batches[self.index * self.batch_size: len(self.batches)]self.index += 1batches = self._to_tensor(batches)return batcheselif self.index >= self.n_batches:self.index = 0raise StopIterationelse:batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]self.index += 1batches = self._to_tensor(batches)return batchesdef __iter__(self):return selfdef __len__(self):if self.residue:return self.n_batches + 1else:return self.n_batchesdef build_iterator(dataset, config, predict):if predict is True:config.batch_size = 1iter = DatasetIterater(dataset, config.batch_size, config.device)return iterFastText模型
FastText.py
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Config(object):"""配置参数"""def __init__(self):self.model_name = 'FastText'self.train_path = './data/train.txt' # 训练集self.dev_path = './data/dev.txt' # 验证集self.test_path = './data/test.txt' # 测试集self.predict_path = './data/predict.txt'self.class_list = [x.strip() for x in open('./data/class.txt', encoding='utf-8').readlines()]self.vocab_path = './data/vocab.pkl' # 词表self.save_path = './saved_dict/' + self.model_name + '.ckpt' # 模型训练结果self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备self.dropout = 0.5self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = len(self.class_list) # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 5 # epoch数self.batch_size = 128 # mini-batch大小self.pad_size = 32 # 每句话处理成的长度(短填长切)self.learning_rate = 1e-3 # 学习率self.embed = 300 # 字向量维度self.filter_sizes = (2, 3, 4) # 卷积核尺寸self.num_filters = 256 # 卷积核数量(channels数)self.dropout = 0.5 # 随机失活self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = len(self.class_list) # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 10 # epoch数self.batch_size = 128 # mini-batch大小self.pad_size = 32 # 每句话处理成的长度(短填长切)self.learning_rate = 1e-3 # 学习率self.embed = 300 # 字向量维度self.hidden_size = 256 # 隐藏层大小'''Bag of Tricks for Efficient Text Classification'''class Model(nn.Module):def __init__(self, config):super(Model,self).__init__()self.embedding = nn.Embedding(config.n_vocab, # 词汇表达的大小config.embed, # 词向量的的维度padding_idx=config.n_vocab-1 # 填充)self.dropout = nn.Dropout(config.dropout)self.fc1 = nn.Linear(config.embed, config.hidden_size)self.dropout = nn.Dropout(config.dropout)self.fc2 = nn.Linear(config.hidden_size, config.num_classes)def forward(self, x):out_word = self.embedding(x[0])out = out_word.mean(dim=1)out = self.dropout(out)out = self.fc1(out)out = F.relu(out)out = self.fc2(out)return out
训练模型
train_eval.py
# coding: UTF-8
import numpy as np
import torch
import torch.nn.functional as F
from sklearn import metrics# 训练
def train(config, model, train_iter, dev_iter):print("begin")model.train()optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)total_batch = 0 # 记录进行到多少batchdev_best_loss = float('inf')last_improve = 0 # 记录上次验证集loss下降的batch数flag = False # 记录是否很久没有效果提升for epoch in range(config.num_epochs):print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))# 批量训练for i, (trains, labels) in enumerate(train_iter):outputs = model(trains)model.zero_grad()loss = F.cross_entropy(outputs, labels)loss.backward()optimizer.step()if total_batch % 100 == 0:# 每多少轮输出在训练集和验证集上的效果true = labels.data.cpu()predict = torch.max(outputs.data, 1)[1].cpu()train_acc = metrics.accuracy_score(true, predict)dev_acc, dev_loss = evaluate(config, model, dev_iter)if dev_loss < dev_best_loss:dev_best_loss = dev_losstorch.save(model.state_dict(), config.save_path)improve = '*'last_improve = total_batchelse:improve = ''msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, ' \' Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}'print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, improve))model.train()total_batch += 1if total_batch - last_improve > config.require_improvement:# 验证集loss超过1000batch没下降,结束训练print("No optimization for a long time, auto-stopping...")flag = Truebreakif flag:break# 评价
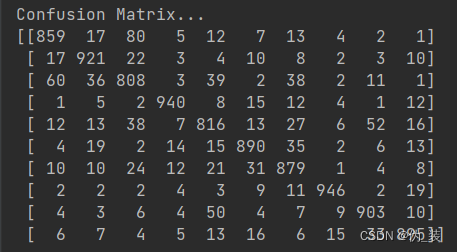
def evaluate(config, model, data_iter, test=False):model.eval()loss_total = 0predict_all = np.array([], dtype=int)labels_all = np.array([], dtype=int)with torch.no_grad():for texts, labels in data_iter:outputs = model(texts)loss = F.cross_entropy(outputs, labels)loss_total += losslabels = labels.data.cpu().numpy()predict = torch.max(outputs.data, 1)[1].cpu().numpy()labels_all = np.append(labels_all, labels)predict_all = np.append(predict_all, predict)acc = metrics.accuracy_score(labels_all, predict_all)if test:report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)confusion = metrics.confusion_matrix(labels_all, predict_all)return acc, loss_total / len(data_iter), report, confusionreturn acc, loss_total / len(data_iter)
预测代码
predict_eval.py
# coding:utf-8
import torch
import numpy as np
from train_eval import evaluateMAX_VOCAB_SIZE = 10000
UNK, PAD = '<UNK>', '<PAD>'tokenizer = lambda x: [y for y in x] # char-leveldef test(config, model, test_iter):# testmodel.load_state_dict(torch.load(config.save_path)) # 加载训练好的的模型model.eval() # 开启评价模式test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'print(msg.format(test_loss, test_acc))print("Precision, Recall and F1-Score...")print(test_report)print("Confusion Matrix...")print(test_confusion)def load_dataset(text, vocab, config, pad_size=32):contents = []for line in text:lin = line.strip()if not lin:continuewords_line = []token = tokenizer(line)seq_len = len(token)if pad_size:if len(token) < pad_size:token.extend([PAD] * (pad_size - len(token)))else:token = token[:pad_size]seq_len = pad_size# word to idfor word in token:words_line.append(vocab.get(word, vocab.get(UNK)))contents.append((words_line, int(0), seq_len))return contents # [([...], 0), ([...], 1), ...]def match_label(pred, config):label_list = config.class_listreturn label_list[pred]def final_predict(config, model, data_iter):map_location = lambda storage, loc: storagemodel.load_state_dict(torch.load(config.save_path, map_location=map_location))model.eval()predict_all = np.array([])with torch.no_grad():for texts, _ in data_iter:outputs = model(texts)pred = torch.max(outputs.data, 1)[1].cpu().numpy()pred_label = [match_label(i, config) for i in pred]predict_all = np.append(predict_all, pred_label)return predict_all
项目运行
run.py
# coding:utf-8from FastText import Config
from FastText import Model
from load_data import build_dataset
from load_data_iter import build_iterator
from train_eval import train
from predict_eval import test,load_dataset,final_predicttext = ['国考28日网上查报名序号查询后务必牢记报名参加2011年国家公务员的考生,如果您已通过资格审查,那么请于10月28日8:00后,登录考录专题网站查询自己的“关键数字”——报名序号。''国家公务员局等部门提醒:报名序号是报考人员报名确认和下载打印准考证等事项的重要依据和关键字,请务必牢记。此外,由于年龄在35周岁以上、40周岁以下的应届毕业硕士研究生和''博士研究生(非在职),不通过网络进行报名,所以,这类人报名须直接与要报考的招录机关联系,通过电话传真或发送电子邮件等方式报名。','高品质低价格东芝L315双核本3999元作者:徐彬【北京行情】2月20日东芝SatelliteL300(参数图片文章评论)采用14.1英寸WXGA宽屏幕设计,配备了IntelPentiumDual-CoreT2390''双核处理器(1.86GHz主频/1MB二级缓存/533MHz前端总线)、IntelGM965芯片组、1GBDDR2内存、120GB硬盘、DVD刻录光驱和IntelGMAX3100集成显卡。目前,它的经销商报价为3999元。','国安少帅曾两度出山救危局他已托起京师一代才俊新浪体育讯随着联赛中的连续不胜,卫冕冠军北京国安的队员心里到了崩溃的边缘,俱乐部董事会连夜开会做出了更换主教练洪元硕的决定。''而接替洪元硕的,正是上赛季在李章洙下课风波中同样下课的国安俱乐部副总魏克兴。生于1963年的魏克兴球员时代并没有特别辉煌的履历,但也绝对称得上特别:15岁在北京青年队获青年''联赛最佳射手,22岁进入国家队,著名的5-19一战中,他是国家队的替补队员。','汤盈盈撞人心情未平复眼泛泪光拒谈悔意(附图)新浪娱乐讯汤盈盈日前醉驾撞车伤人被捕,','甲醇期货今日挂牌上市继上半年焦炭、铅期货上市后,酝酿已久的甲醇期货将在今日正式挂牌交易。基准价均为3050元/吨继上半年焦炭、铅期货上市后,酝酿已久的甲醇期货将在今日正式''挂牌交易。郑州商品交易所(郑商所)昨日公布首批甲醇期货8合约的上市挂牌基准价,均为3050元/吨。据此推算,买卖一手甲醇合约至少需要12200元。业内人士认为,作为国际市场上的''首个甲醇期货品种,其今日挂牌后可能会因炒新资金追捧而出现冲高走势,脉冲式行情过后可能有所回落,不过,投资者在上市初期应关注期现价差异常带来的无风险套利交易机会。','佟丽娅穿白色羽毛长裙美翻,自曝跳舞的女孩能吃苦','江欣燕透露汤盈盈钱嘉乐分手 用冷笑话补救']if __name__ == "__main__":config = Config()print("Loading data...")vocab, train_data, dev_data, test_data = build_dataset(config, False)# 1. 批量加载测试数据train_iter = build_iterator(train_data, config, False)dev_iter = build_iterator(dev_data, config, False)test_iter = build_iterator(test_data,config, False)config.n_vocab = len(vocab)# 2. 加载模型结构model = Model(config).to(config.device)train(config, model, train_iter, dev_iter)# 3. 测试test(config, model, test_iter)print("+++++++++++++++++")# 4. 预测content = load_dataset(text, vocab, config)predict_iter = build_iterator(content, config, predict=True)result = final_predict(config, model, predict_iter)for i, j in enumerate(result):print('text:{}'.format(text[i]), '\t', 'label:{}'.format(j))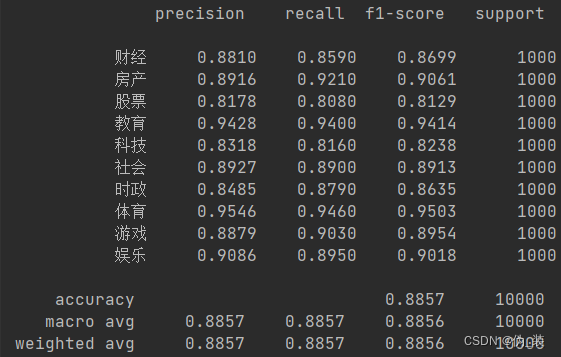
相关文章:
FastText模型文本分类
项目地址:NLP-Application-and-Practice/07_FastText/7.2-FastText文本分类/text_classification at master zz-zik/NLP-Application-and-Practice (github.com) 加载数据 load_data.py # coding: UTF-8 import os import pickle as pkl from tqdm import tqdmMA…...
CentOS 7 使用Fmt库
安装 fmt Git下载地址:https://github.com/fmtlib/fmt 步骤1:首先,你需要下载fmt的源代码。你可以从https://github.com/fmtlib/fmt或者源代码官方网站下载。并上传至/usr/local/source_code/ 步骤2:下载完成后ÿ…...
如何通过宝塔面板搭建一个本地MySQL数据库服务并实现远程访问
宝塔安装MySQL数据库,并内网穿透实现公网远程访问 文章目录 宝塔安装MySQL数据库,并内网穿透实现公网远程访问前言1.Mysql服务安装2.创建数据库3.安装cpolar3.2 创建HTTP隧道 4.远程连接5.固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网…...

普通话考试相关(一文读懂)
文章目录: 一:相关常识 1.考试报名时间 2.报名地方 费用 证件 3.考试流程 4.普通话等级说明 二:题型 三:技巧 1.前三题 2.命题说话 四:普通话考试题库 1.在线题库 2.下载题库 一:相关常识 …...

深度学习动物识别 - 卷积神经网络 机器视觉 图像识别 计算机竞赛
文章目录 0 前言1 背景2 算法原理2.1 动物识别方法概况2.2 常用的网络模型2.2.1 B-CNN2.2.2 SSD 3 SSD动物目标检测流程4 实现效果5 部分相关代码5.1 数据预处理5.2 构建卷积神经网络5.3 tensorflow计算图可视化5.4 网络模型训练5.5 对猫狗图像进行2分类 6 最后 0 前言 &#…...
【Redisson】基于自定义注解的Redisson分布式锁实现
前言 在项目中,经常需要使用Redisson分布式锁来保证并发操作的安全性。在未引入基于注解的分布式锁之前,我们需要手动编写获取锁、判断锁、释放锁的逻辑,导致代码重复且冗长。为了简化这一过程,我们引入了基于注解的分布式锁&…...

QT中样式表常见属性与颜色的设置与应用
常见样式表属性 在Qt中的样式表(QSS)中,有一些特定的英文单词和关键字用于指定不同的样式属性。以下是常见的一些英文单词和关键字: 颜色(Colors): color: 文本颜色 background-color: 背景颜色 border-color: 边框颜色 字体(Fonts): font: 字体 font-family: 字体…...
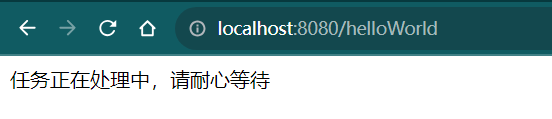
OpenCvSharp从入门到实践-(02)图像处理的基本操作
目录 图像处理的基础操作 1、读取图像 1.1、读取当前目录下的图像 2、显示图像 2.1、Cv2.ImShow 用于显示图像。 2.2、Cv2.WaitKey方法用于等待用户按下键盘上按键的时间。 2.3、Cv2.DestroyAllWindows方法用于销毁所有正在显示图像的窗口。 2.4实例1-显示图像 2.4实例…...

Spring Boot 升级3.x 指南
Spring Boot 升级3.x 指南 1. 升级思路 先创建一个parent项目,打包类型为pom,继承自spring boot的parent项目 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId&…...

使用支付宝的沙箱环境在本地配置模拟支付并发布至公网调试
文章目录 前言1. 下载当面付demo2. 修改配置文件3. 打包成web服务4. 局域网测试5. 内网穿透6. 测试公网访问7. 配置二级子域名8. 测试使用固定二级子域名访问9. 结语 前言 在沙箱环境调试支付SDK的时候,往往沙箱环境部署在本地,局限性大,在沙…...

python-opencv划痕检测
python-opencv划痕检测 这次实验,我们将对如下图片进行划痕检测,其实这个比较有难度,因为清晰度太差了。 我们做法如下: (1)读取图像为灰度图像,进行自适应直方图均衡化处理,增强图…...
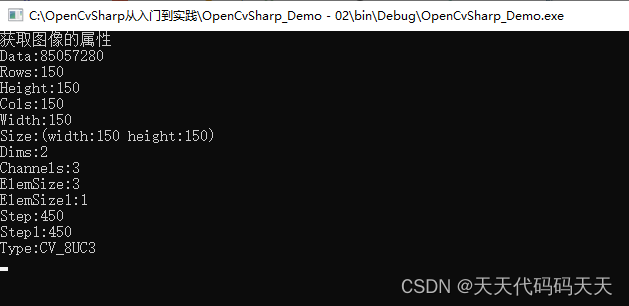
微服务学习|Gateway网关:网关作用、快速入门、路由断言工厂、路由过滤器配置、全局过滤器、过滤器执行顺序、跨域问题处理
为什么需要网关 网关功能: 1.身份认证和权限校验 2.服务路由、负载均衡 3.请求限流 网关的技术实现 在SpringCloud中网关的实现包括两种:gateway、zuul Zuul是基于Servlet的实现,属于阻塞式编程。而SprinaCloudGateway则是基于Spring5中提供的WebFlux…...

七、通过libfdk_aac编解码器实现aac音频和pcm的编解码
前言 测试环境: ffmpeg的4.3.2自行编译版本windows环境qt5.12 AAC编码是MP3格式的后继产品,通常在相同的比特率下可以获得比MP3更高的声音质量,是iPhone、iPod、iPad、iTunes的标准音频格式。 AAC相较于MP3的改进包含: 更多的采…...
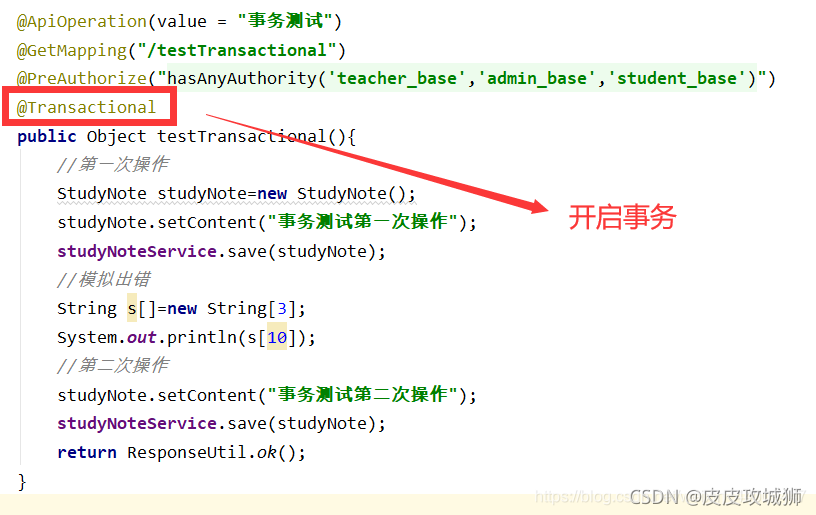
spring 是如何开启事务的, 核心原理是什么
文章目录 spring 是如何开启事务的核心原理1 基于注解开启事务2 基于代码来开启事务 spring 是如何开启事务的 核心原理 Spring事务管理的实现有许多细节,如果对整个接口框架有个大体了解会非常有利于我们理解事务,下面通过讲解Spring的事务接口来了解…...

头歌——操作系统实训总结
死锁 1、系统出现死锁时一定同时保持了四个必要条件,对资源采用按序分配算法后可破坏的条件是(A)。 A、循环等待条件B、互斥条件C、占有并等待条件D、不可抢占条件 2、资源的静态分配算法在解决死锁问题中是用于(B)。 …...
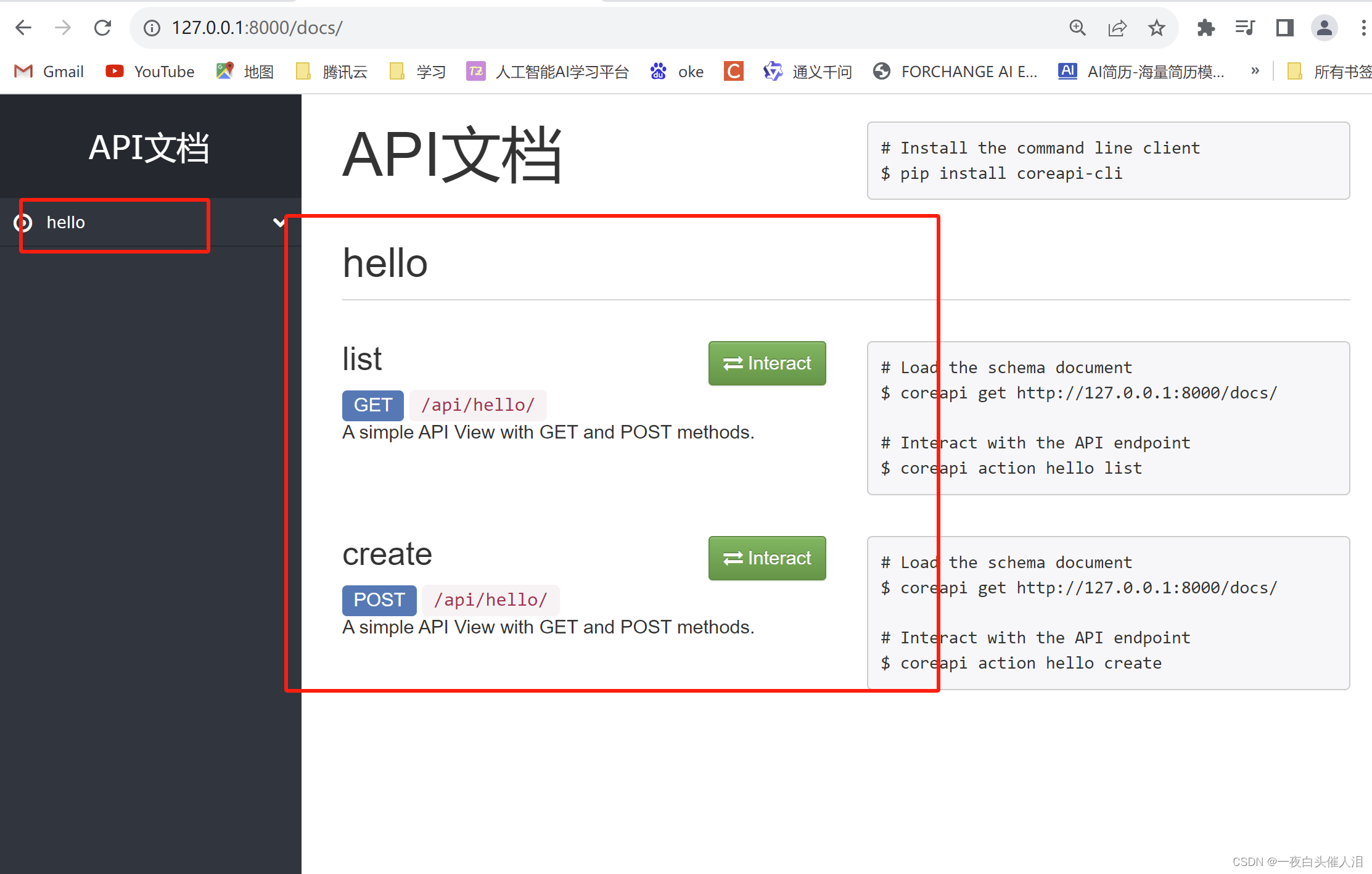
Django自动生成docs接口文档
1.创建Django项目 python manage.py startproject django20252.创建子应用 python manage.py startapp api3.安装依赖包 pip install coreapi4.创建urls.py from django.contrib import admin from django.urls import path, include from rest_framework import routers f…...
Mock 数据
1. Mock 数据的方式 2. json-server 实现 Mock 数据 项目中安装json-server npm i -D json-server准备一个json文件添加启动命令 //package.json"scripts": {"start": "craco start","build": "craco build","test&q…...
C语言之for语句概述)
(三)C语言之for语句概述
(三)C语言之for语句概述 一、使用for语句实现打印华氏温度与摄氏温度转换二、for语句概述三、练习 一、使用for语句实现打印华氏温度与摄氏温度转换 #include <stdio.h> /*当华氏温度为 0,20,40,...300时,打印出华氏温度与摄氏温度对照…...
OpenLDAP配置web管理界面PhpLDAPAdmin服务-centos9stream
之前已经发了一篇关于centos9下面配置openldap多主高可用集群的内容,不会配置ldap集群的请参考:服务器集群配置LDAP统一认证高可用集群(配置tsl安全链接)-centos9stream-openldap2.6.2-CSDN博客 这里跟着前篇文章详细说明如何配置…...

深兰科技多款大模型技术产品登上新闻联播!
11月20日晚,新闻联播报道了2023中国5G工业互联网大会,深兰科技metamind、汉境大型城市智能体空间等大模型技术和产品在众多参展产品中脱颖而出,被重点播报。 2023中国5G工业互联网大会 本届大会由工信部和湖北省人民政府联合主办,…...

如何永久保存微信聊天记录?WeChatMsg完整指南带你轻松备份珍贵对话
如何永久保存微信聊天记录?WeChatMsg完整指南带你轻松备份珍贵对话 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trend…...

如何突破网盘限速:LinkSwift直链下载助手终极指南
如何突破网盘限速:LinkSwift直链下载助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

如何快速配置HS2-HF_Patch:游戏增强补丁完整指南
如何快速配置HS2-HF_Patch:游戏增强补丁完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否厌倦了日文原版Honey Select 2的游戏体验&am…...
 运行 Firefox 浏览器时遇到中文乱码的解决方法)
Windows Subsystem for Linux (WSL) 运行 Firefox 浏览器时遇到中文乱码的解决方法
在使用Windows Subsystem for Linux (WSL) 运行 Firefox 浏览器时,有时会遇到中文乱码的问题。这通常是由于字体支持或字符编码设置不正确导致的。以下是一些解决此问题的步骤:1. 确保系统字体支持中文首先,确保你的WSL发行版安装了支持中文的…...

如何用NVIDIA Profile Inspector解决游戏性能与画质难题
如何用NVIDIA Profile Inspector解决游戏性能与画质难题 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾遇到过这样的困扰:明明显卡性能足够,但游戏画面总是出现撕裂&am…...

加入国内正规水漆定制招商,实际收益和体验究竟如何?
家人们,最近不少人都在考虑加入国内正规水漆定制招商,我作为爱瑞德全屋定制的深度体验者,今天就来跟大家好好唠唠实际收益和体验到底咋样。我之前家里装修,就面临着不少痛点。家里收纳那叫一个混乱,各种东西堆得到处都…...

C语言结构体对齐的坑我帮你踩完了:从#pragma pack到__attribute__的避坑指南
C语言结构体对齐的坑我帮你踩完了:从#pragma pack到__attribute__的避坑指南 凌晨三点,调试器里的十六进制数据像天书一样摊在眼前。本该解析出的温度传感器数值变成了乱码,而这一切只是因为结构体里多了个uint8_t类型的标志位——这是我入行…...

GetQzonehistory:QQ空间历史数据备份的完整指南
GetQzonehistory:QQ空间历史数据备份的完整指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间中的珍贵回忆会随着时间流逝而消失?GetQzonehis…...

告别‘盲搜’!Cheat Engine高级技巧:用指针扫描与代码注入搞定动态地址游戏
告别‘盲搜’!Cheat Engine高级技巧:用指针扫描与代码注入搞定动态地址游戏 每次游戏重启后,那些好不容易找到的地址又变了?面对多级指针就像在迷宫里打转?如果你已经掌握了Cheat Engine的基础扫描功能,却对…...

如何5分钟完成智能OpenCore配置:新手也能轻松构建黑苹果引导
如何5分钟完成智能OpenCore配置:新手也能轻松构建黑苹果引导 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore配置而头…...