本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)

按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限。但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉钱上“云端”了,本次我们来演示如何在本地训练Bert-VITS2 V2.0.2模型。
Bert-VITS2 V2.0.2基于现有数据集
目前Bert-VITS2 V2.0.2大体上有两种训练方式,第一种是基于现有数据集,即原神各角色已经标注好的语音数据,这部分内容是公开的,但是不能商用,可以在这里下载:
https://pan.ai-hobbyist.org/Genshin%20Datasets/%E4%B8%AD%E6%96%87%20-%20Chinese/%E5%88%86%E8%A7%92%E8%89%B2%20-%20Single/%E8%A7%92%E8%89%B2%E8%AF%AD%E9%9F%B3%20-%20Character
我们只需要选择喜欢的角色进行下载即可:

第二种是没有现有的数据集,即假设我们想克隆地球人随便任意一个人的声音,这种情况下我们需要收集这个人的语音素材,然后自己制作数据集。
本次我们只演示第一种训练方式,即训练现有数据集的原神角色,第二种暂且按下不表。
Bert-VITS2 V2.0.2配置模型
首先克隆项目:
git clone https://github.com/v3ucn/Bert-VITS2_V202_Train.git
随后下载新版的bert模型:
链接:https://pan.baidu.com/s/11vLNEVDeP_8YhYIJUjcUeg?pwd=v3uc
下载成功后,解压放入项目的bert目录,目录结构如下所示:
E:\work\Bert-VITS2-v202\bert>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
│ bert_models.json
│
├───bert-base-japanese-v3
│ config.json
│ README.md
│ tokenizer_config.json
│ vocab.txt
│
├───bert-large-japanese-v2
│ config.json
│ README.md
│ tokenizer_config.json
│ vocab.txt
│
├───chinese-roberta-wwm-ext-large
│ added_tokens.json
│ config.json
│ pytorch_model.bin
│ README.md
│ special_tokens_map.json
│ tokenizer.json
│ tokenizer_config.json
│ vocab.txt
│
├───deberta-v2-large-japanese
│ config.json
│ pytorch_model.bin
│ README.md
│ special_tokens_map.json
│ tokenizer.json
│ tokenizer_config.json
│
└───deberta-v3-large config.json generator_config.json pytorch_model.bin README.md spm.model tokenizer_config.json
随后下载预训练模型:
https://openi.pcl.ac.cn/Stardust_minus/Bert-VITS2/modelmanage/model_readme_tmpl?name=Bert-VITS2%E4%B8%AD%E6%97%A5%E8%8B%B1%E5%BA%95%E6%A8%A1-fix
放入项目的pretrained_models目录,如下所示:
E:\work\Bert-VITS2-v202\pretrained_models>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:. DUR_0.pth D_0.pth G_0.pth
接着把上文提到的刻晴数据集放入项目的Data目录中的raw目录:
E:\work\Bert-VITS2-v202\Data\keqing\raw\keqing>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
vo_card_keqing_endOfGame_fail_01.lab
vo_card_keqing_endOfGame_fail_01.wav
如果想定制化目录结构,可以修改config.yml文件:
bert_gen: config_path: config.json device: cuda num_processes: 2 use_multi_device: false
dataset_path: Data\keqing
mirror: ''
openi_token: ''
preprocess_text: clean: true cleaned_path: filelists/cleaned.list config_path: config.json max_val_total: 8 train_path: filelists/train.list transcription_path: filelists/short_character_anno.list val_path: filelists/val.list val_per_spk: 5
resample: in_dir: raw out_dir: raw sampling_rate: 44100
至此,模型和数据集就配置好了。
Bert-VITS2 V2.0.2数据预处理
标注好的原始数据集并不能够直接进行训练,需要预处理一下,首先需要将原始数据文件转写成为标准的标注文件:
python3 transcribe_genshin.py
生成好的文件:
Data\keqing\raw/keqing/vo_card_keqing_endOfGame_fail_01.wav|keqing|ZH|我会勤加练习,拿下下一次的胜利。
Data\keqing\raw/keqing/vo_card_keqing_endOfGame_win_01.wav|keqing|ZH|胜负本是常事,不必太过挂怀。
Data\keqing\raw/keqing/vo_card_keqing_freetalk_01.wav|keqing|ZH|这「七圣召唤」虽说是游戏,但对局之中也隐隐有策算谋略之理。
这里ZH代表中文,新版的Bert-VITS2 V2.0.2也支持日文和英文,代码分别为JP和EN。
随后对文本进行预处理以及生成bert模型可读文件:
python3 preprocess_text.py python3 bert_gen.py
执行后会产生训练集和验证集文件:
E:\work\Bert-VITS2-v202\Data\keqing\filelists>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:. cleaned.list short_character_anno.list train.list val.list
检查无误后,数据预处理就完成了。
Bert-VITS2 V2.0.2本地训练
万事俱备,只差训练。先不要着急,打开Data/keqing/config.json配置文件:
{ "train": { "log_interval": 50, "eval_interval": 50, "seed": 42, "epochs": 200, "learning_rate": 0.0001, "betas": [ 0.8, 0.99 ], "eps": 1e-09, "batch_size": 8, "fp16_run": false, "lr_decay": 0.99995, "segment_size": 16384, "init_lr_ratio": 1, "warmup_epochs": 0, "c_mel": 45, "c_kl": 1.0, "skip_optimizer": false }, "data": { "training_files": "Data/keqing/filelists/train.list", "validation_files": "Data/keqing/filelists/val.list", "max_wav_value": 32768.0, "sampling_rate": 44100, "filter_length": 2048, "hop_length": 512, "win_length": 2048, "n_mel_channels": 128, "mel_fmin": 0.0, "mel_fmax": null, "add_blank": true, "n_speakers": 1, "cleaned_text": true, "spk2id": { "keqing": 0 } }, "model": { "use_spk_conditioned_encoder": true, "use_noise_scaled_mas": true, "use_mel_posterior_encoder": false, "use_duration_discriminator": true, "inter_channels": 192, "hidden_channels": 192, "filter_channels": 768, "n_heads": 2, "n_layers": 6, "kernel_size": 3, "p_dropout": 0.1, "resblock": "1", "resblock_kernel_sizes": [ 3, 7, 11 ], "resblock_dilation_sizes": [ [ 1, 3, 5 ], [ 1, 3, 5 ], [ 1, 3, 5 ] ], "upsample_rates": [ 8, 8, 2, 2, 2 ], "upsample_initial_channel": 512, "upsample_kernel_sizes": [ 16, 16, 8, 2, 2 ], "n_layers_q": 3, "use_spectral_norm": false, "gin_channels": 256 }, "version": "2.0"
}
这里需要调整的参数是batch_size,如果显存不够,需要往下调整,否则会出现“爆显存”的问题,假设显存为8G,那么该数值最好不要超过8。
与此同时,首次训练建议把log_interval和eval_interval参数调小一点,即训练的保存间隔,方便训练过程中随时进行推理验证。
随后输入命令,开始训练:
python3 train_ms.py
程序返回:
11-22 13:20:28 INFO | data_utils.py:61 | Init dataset...
100%|█████████████████████████████████████████████████████████████████████████████| 581/581 [00:00<00:00, 48414.40it/s]
11-22 13:20:28 INFO | data_utils.py:76 | skipped: 31, total: 581
11-22 13:20:28 INFO | data_utils.py:61 | Init dataset...
100%|████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<?, ?it/s]
11-22 13:20:28 INFO | data_utils.py:76 | skipped: 0, total: 5
Using noise scaled MAS for VITS2
Using duration discriminator for VITS2
INFO:models:Loaded checkpoint 'Data\keqing\models\DUR_0.pth' (iteration 7)
INFO:models:Loaded checkpoint 'Data\keqing\models\G_0.pth' (iteration 7)
INFO:models:Loaded checkpoint 'Data\keqing\models\D_0.pth' (iteration 7)
说明训练已经开始了。
训练过程中,可以通过命令:
python3 -m tensorboard.main --logdir=Data/keqing/models
来查看loss损失率,访问:
http://localhost:6006/#scalars
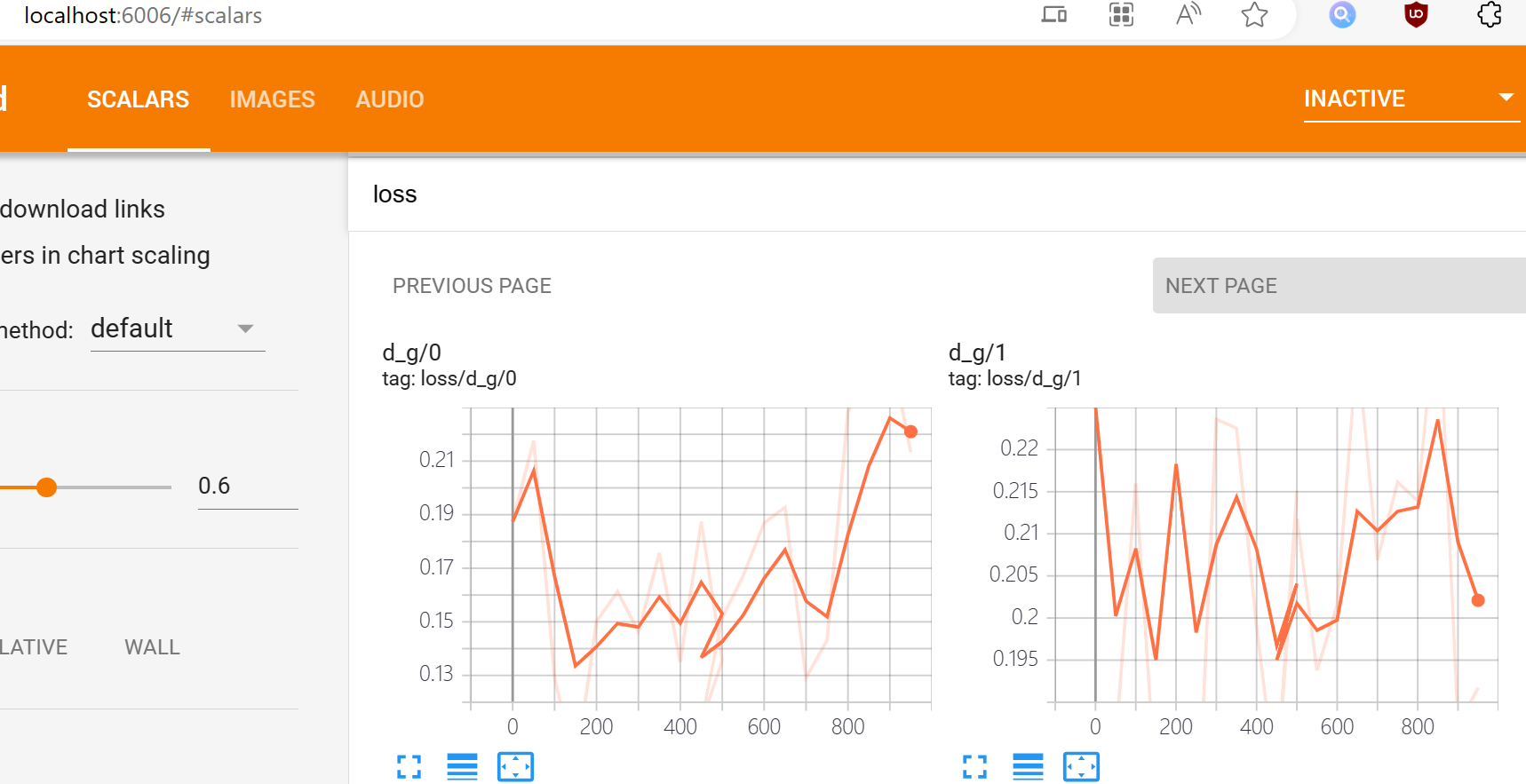
一般情况下,训练损失率低于50%,并且损失函数在训练集和验证集上都趋于稳定,则可以认为模型已经收敛。收敛的模型就可以为我们所用了,如何使用训练好的模型,请移步:又欲又撩人,基于新版Bert-vits2V2.0.2音色模型雷电将军八重神子一键推理整合包分享,囿于篇幅,这里不再赘述。
训练好的模型存放在Data/keqing/models目录:
E:\work\Bert-VITS2-v202\Data\keqing\models>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
│ DUR_0.pth
│ DUR_550.pth
│ DUR_600.pth
│ DUR_650.pth
│ D_0.pth
│ D_600.pth
│ D_650.pth
│ events.out.tfevents.1700625154.ly.24008.0
│ events.out.tfevents.1700630428.ly.20380.0
│ G_0.pth
│ G_450.pth
│ G_500.pth
│ G_550.pth
│ G_600.pth
│ G_650.pth
│ train.log
│
└───eval events.out.tfevents.1700625154.ly.24008.1 events.out.tfevents.1700630428.ly.20380.1
需要注意的是,首次训练需要将预训练模型拷贝到models目录。
结语
除了中文,Bert-VITS2 V2.0.2也支持日语和英语,同时提供中英日混合的Mix推理模式,欲知后事如何,且听下回分解。
相关文章:
本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)
按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限。但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉…...

守护进程的理解
什么是守护进程 daemon False # 是否以守护进程方式运行,True守护,False 非守护 在这段代码中,daemon 变量的值决定了进程是否以守护进程方式运行。如果 daemon 的值为 True,则表示进程将以守护进程方式运行,否则为…...

VMware虚拟机的安装教程
安装VMware虚拟机的步骤如下: 首先,你需要从VMware官方网站(https://www.vmware.com)下载VMware虚拟机软件安装程序。 一旦下载完成,双击运行安装程序。 在安装程序启动后,你将看到一个欢迎界面。点击"…...
Linux环境搭建(tomcat,jdk,mysql下载)
是否具备环境(前端node,后端环境jdk)安装jdk,配置环境变量 JDK下载 - 编程宝库 (codebaoku.com) 进入opt目录 把下好的安装包拖到我们的工具中 把解压包解压 解压完成,可以删除解压包 复制解压文件的目录,配置环境变量…...

80万条中文ChatGPT多轮对话数据集
80万条中文ChatGPT多轮对话数据集 代码代码地址代码解析 代码 import json import numpy as np from tqdm import tqdm import redef find_chinese_text(text):pattern re.compile(r[^\u4e00-\u9fff])return pattern.sub(, text)with open("E:/data_sets/multiturn_chat…...

阿里云ECS服务器如何搭建并连接FTP,完整步骤
怎么用终端连接服务器就不多说了,直接开始搭建FTP。 我是用root账号执行的命令,如果不使用root账号,注意在命令前面加sudo。 一、安装FTP 我这里安装的是vsftpd。 1、检查是否已安装vsftpd: vsftpd -v如果出现了版本信息&…...

uni-app 使用uni.getLocation获取经纬度配合腾讯地图api获取当前地址
前言 最近在开发中需要根据经纬度获取当前位置信息,传递给后端,用来回显显示当前位置 查阅uni-app文档,发现uni.getLocation () 可以获取到经纬度,但是在小程序环境没有地址信息 思考怎么把经纬度换成地址,如果经纬度…...

cocos2dx Animate3D (一)
3D相关的动画都是继承Grid3DAction 本质上是用GirdBase进行创建动画的小块。 Shaky3D 晃动特效 // 持续时间(时间过后不会回到原来的样子) // 整个屏幕被分成几行几列 // 晃动的范围 // z轴是否晃动 static Shaky3D* create(float initWithDuration, const Size& …...
2023年最新PyCharm环境搭建教程(含Python下载安装)
文章目录 写在前面PythonPython简介Python生态圈Python下载安装 PyCharmPyCharm简介PyCharm下载安装PyCharm环境搭建 写在后面 写在前面 最近博主收到了好多小伙伴的吐槽称不会下载安装python,博主听到后非常的扎心,经过博主几天的熬夜加班,…...
3D火山图绘制教程
一边学习,一边总结,一边分享! 本期教程内容 **注:**本教程详细内容 Volcano3D绘制3D火山图 一、前言 火山图是做差异分析中最常用到的图形,在前面的推文中,我们也推出了好几期火山图的绘制教程࿰…...

跳跃游戏[中等]
优质博文:IT-BLOG-CN 一、题目 给你一个非负整数数组nums,你最初位于数组的第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回true;否则,返…...

华为昇腾开发板共享Windows网络上网的方法
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 具体参考文章:linux(内网)通过window 上网。具体是两步:一是在windows上设置internet连接共享。二是打开Atlas 200I D…...
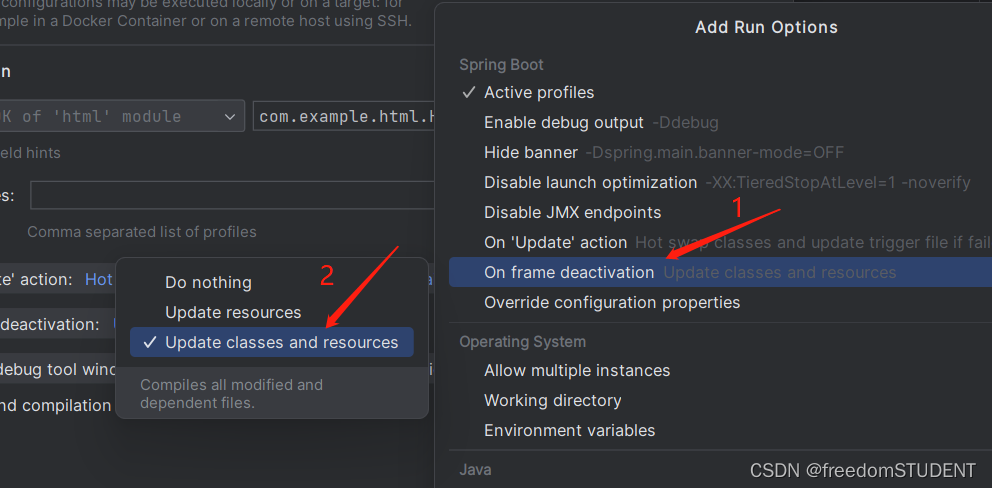
【工具栏】热部署不生效
目录 配置热部署: 解决热部署不生效: 首先检查: 第一步: 第二步: 第三步: 第四步: 配置热部署: https://blog.csdn.net/m0_67930426/article/details/133690559 解决热部署不…...

一键去水印免费网站快速无痕处理图片、视频水印
水印问题往往是一个大麻烦。即使我们只想将这些照片保留在我们的个人相册中以供怀旧,水印也可能像顽固的符号一样刺激我们的眼睛。为了解决这个问题,我们需要不断探索创新的解决方案,让我们深入研究一款强大的一键去水印免费网站“水印云”。…...
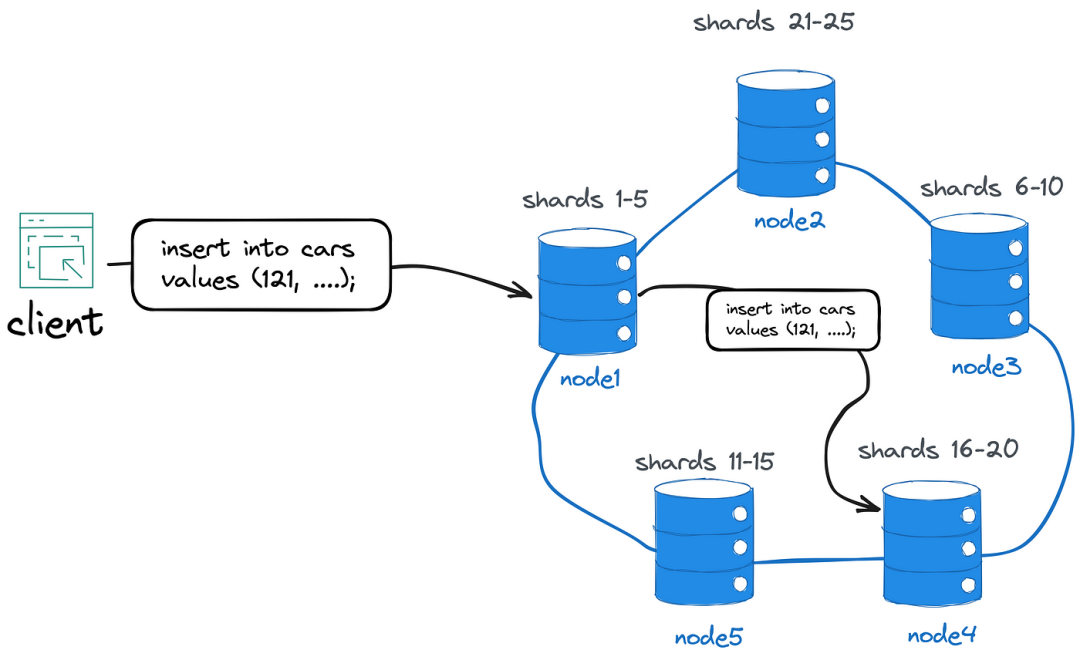
分片并不意味着分布式
Sharding(分片)是一种将数据和负载分布到多个独立的数据库实例的技术。这种方法通过将原始数据集分割为分片来利用水平可扩展性,然后将这些分片分布到多个数据库实例中。 1*yg3PV8O2RO4YegyiYeiItA.png 但是,尽管"分布"…...

Python中的函数
一、函数参数与返回值基础知识 1、不要使用可变类型(list等)作为参数默认值,用None来代替。 参数默认值只会在函数定义阶段被创建一次,之后无论创建多少次,函数内拿到的默认值都是同一个对象,为规避这个问…...
推荐一款png图片打包plist工具pngPackerGUI_V2.0
png图片打包plist工具,手把手教你使用pngPackerGUI_V2.0 此软件是在pngpacker_V1.1软件基础之后,开发的界面化操作软件,方便不太懂命令行的小白快捷上手使用。1.下载并解压缩软件,得到如下目录,双击打开 pngPackerGUI.…...
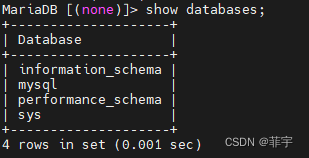
Docker快速安装Mariadb11.1
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,使用XtraDB来代替MySQL的InnoDB。 Mari…...
方法可配置属性)
CuratorFrameworkFactory.builder()方法可配置属性
CuratorFrameworkFactory.builder()方法可以配置以下属性: 1. connectString:ZooKeeper服务器的连接字符串。 2. sessionTimeoutMs:ZooKeeper会话超时时间。 3. connectionTimeoutMs:ZooKeeper连接超时时间。 4. retryPolicy&…...

鸿蒙 ark ui 轮播图实现教程
前言: 各位同学有段时间没有见面 因为一直很忙所以就没有去更新博客。最近有在学习这个鸿蒙的ark ui开发 因为鸿蒙不是发布了一个鸿蒙next的测试版本 明年会启动纯血鸿蒙应用 所以我就想提前给大家写一些博客文章 效果图 具体实现 我们在鸿蒙的ark ui 里面列表使…...
)
从内核panic到App闪退:一条Android Crash的‘全链路’排查指南(附QCOM平台实战)
从内核panic到App闪退:一条Android Crash的‘全链路’排查指南(附QCOM平台实战) 当用户点击App图标时,很少有人会想到这个简单的动作背后,隐藏着从应用层到芯片级的复杂技术栈。一次看似普通的闪退,可能是S…...
)
别急着换电感!手把手教你用示波器定位DCDC电源的‘吱吱’声(附波形分析)
别急着换电感!手把手教你用示波器定位DCDC电源的‘吱吱’声(附波形分析) 实验室里最让人头疼的声音,莫过于DCDC电源模块发出的高频"吱吱"声。这种电感啸叫不仅影响产品体验,更可能预示着潜在的电路问题。但大…...

maven常用命令大全
参考地址: 1.maven常用命令大全(附详细解释),https://blog.csdn.net/good_good_xiu/article/details/116740333 2.maven常用命令集合(收藏大全),https://zhuanlan.zhihu.com/p/355889432 3.Maven查看插件信息&#…...

终极Windows 10瘦身指南:16个核心功能让系统重获新生
终极Windows 10瘦身指南:16个核心功能让系统重获新生 【免费下载链接】Win10BloatRemover Configurable CLI tool to easily and aggressively debloat and tweak Windows 10 by removing preinstalled UWP apps, services and more. Originally based on the W10 d…...

QZoneExport:三步快速永久备份你的QQ空间完整数据指南
QZoneExport:三步快速永久备份你的QQ空间完整数据指南 【免费下载链接】QZoneExport QQ空间导出助手,用于备份QQ空间的说说、日志、私密日记、相册、视频、留言板、QQ好友、收藏夹、分享、最近访客为文件,便于迁移与保存 项目地址: https:/…...

你的Notion又白屏了?可能是这些隐藏设置和缓存机制在搞鬼
Notion白屏故障的底层逻辑与技术解决方案 1. 理解Electron应用的渲染机制 Notion作为基于Electron框架构建的跨平台应用,其白屏问题往往与底层渲染机制密切相关。Electron本质上是一个将Chromium浏览器引擎与Node.js运行时结合的框架,这意味着它同时具备…...

告别网盘限速:LinkSwift直链下载助手完整指南
告别网盘限速:LinkSwift直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南
BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

2026年,沸石转轮厂家光卖设备不够,业主还看重什么?
前些年,工厂只要买环保设备,能达标排放就算交差了。但现在环保检查越来越严,运行成本居高不下,设备三天两头出毛病——业主们渐渐发现:光买一台沸石转轮设备远远不够,后续能不能稳定运行、省不省电、厂家管…...
)
TVA在汽车动力电池模组全流程检测中的应用(2)
前沿技术背景介绍:AI 智能体视觉系统(TVA,Transformer-based Vision Agent),是依托Transformer架构与因式智能体所构建的新一代视觉检测技术。它区别于传统机器视觉与早期AI视觉,代表了工业智能化转型与视觉…...