mysql的联合索引最左匹配原则问题
MySQL的联合索引
联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配。
这个结论并不全对!去掉 「between 和 like 」这个结论就没问题了
经过实验的证明,我得出的结论是这样的:
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段后面的字段无法用到联合索引。但是,对于 >=、<=、BETWEEN、like 前缀匹配这四种范围查询,并不会停止匹配。
用几个实验例子来说明这个结论:
B+Tree 索引
首先,先来认识下 B+Tree 索引。
MySQL 的 InnoDB 存储引擎会为每一张数据库表创建一个「聚簇索引」来保存表的数据,聚簇索引默认使用的是B+Tree 索引。
为了让大家理解 B+Tree 索引的存储和查询的过程,接下来我通过一个简单例子,说明一下 B+Tree 索引在存储数据中的具体实现。
假设有一张商品表,表里有这些数据:
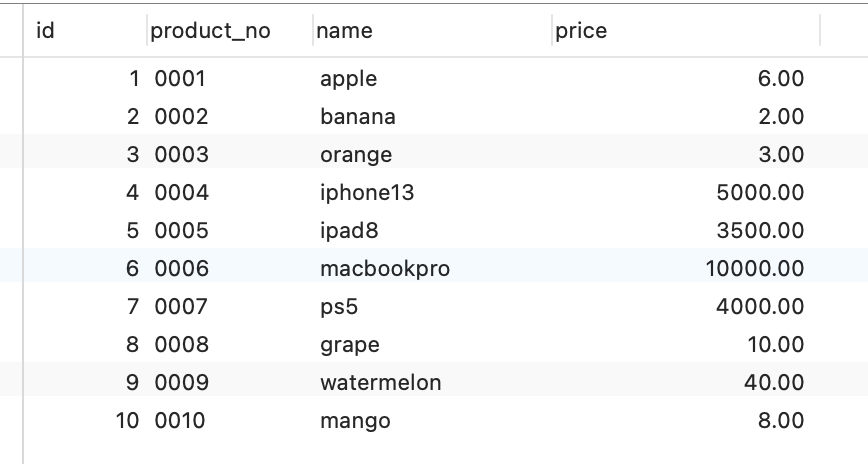
这些数据,存储在 B+Tree 索引时是长什么样子的?
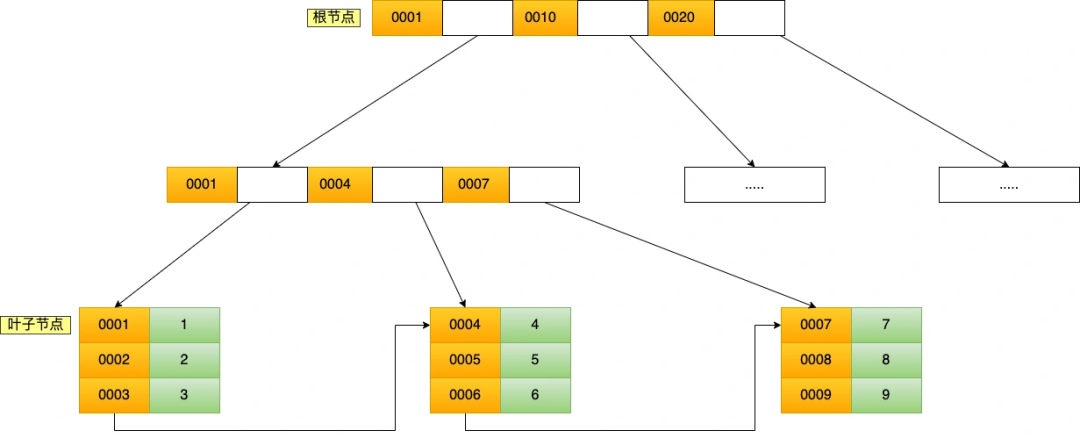
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键值(id)顺序存放的,每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都指向下一个叶子节点,形成一个链表,便于范围查询。
聚簇索引的 B+Tree 如图所示:

假设,执行了 select * from t_product where id = 5查询语句,该查询语句的条件是找到 id(主键)为 5 的这条记录。因为 B+Tree 是一个有序的数据结构,所以可以通过二分查找算法快速定位到这条记录,这也就是我们常说的索引查询,具体过程如下:
- 从根节点开始,将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,根据二分查找算法,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,根据二分查找算法,找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的这条记录。
聚簇索引只能用于主键字段的快速查询,如果想实现「非主键字段」的快速查询,我们就要针对「非主键字段」创建索引,这种索引称作为「二级索引」。二级索引同样基于 B+Tree 实现的,不过二级索引的叶子节点存放的是主键值,不是实际数据。
我这里将前面的商品表中的 product_no (商品编码)字段设置为二级索引,那么二级索引的 B+Tree 如下图,其中非叶子的索引值是 product_no(图中橙色部分),叶子节点存储的数据是主键值(图中绿色部分)。
如果我用 product_no 二级索引查询商品,如下查询语句:
select * from product where product_no = '0002';会先在二级索引的 B+Tree 中快速查找到 product_no 为 0002 的二级索引记录,然后获取主键值,然后利用主键值在主键索引的 B+Tree 中快速查询到对应的叶子节点,然后获取完整的记录。这个过程叫「回表」,也就是说要查两个 B+Tree 才能查到数据。如下图:
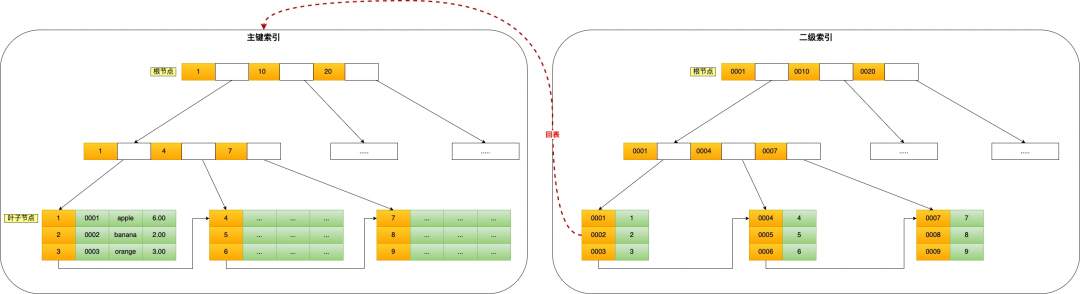
不过,当查询的数据是能在二级索引的 B+Tree 的叶子节点里查询到,这时就不用再查主键索引查,比如下面这条查询语句:
select id from product where product_no = '0002';这种在二级索引的 B+Tree 就能查询到结果的过程就叫作「覆盖索引」,也就是只需要查一个 B+Tree 就能找到数据。
什么是联合索引?
前文我将 product_no 字段设置为了索引,这种二级索引只有一个字段。如果将多个字段组合成一个索引,那么这种二级索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引`(product_no, name)``,创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);联合索引 ``(product_no, name)` 的 B+Tree 示意图如下:
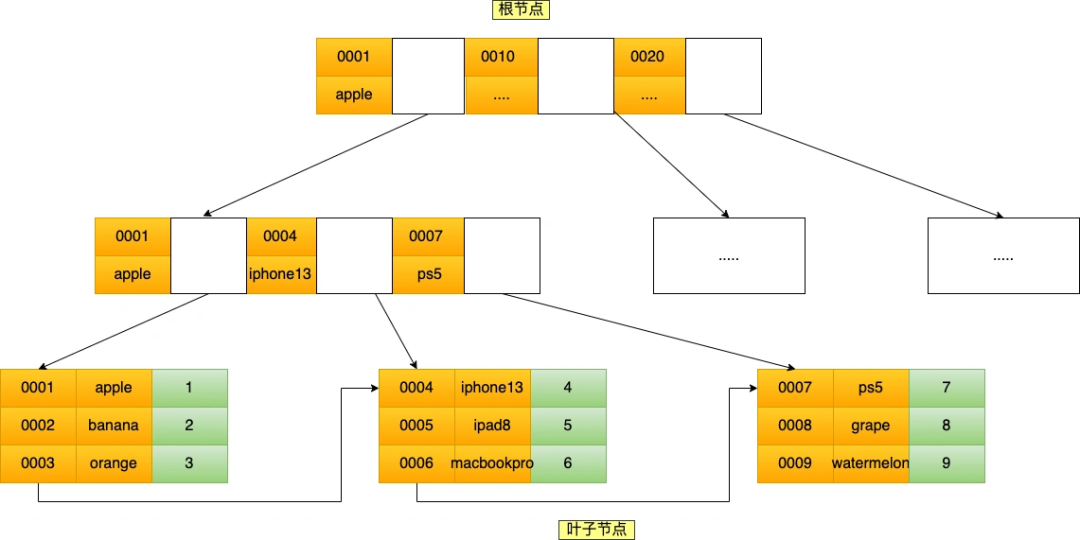
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的索引值。
联合索引的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。记住这句话,很重要!
最左匹配原则
使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。
在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以利用联合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
上面这些查询条件之所以会失效,是因为(a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
我这里举联合索引(a,b)的例子,该联合索引的 B+ Tree 如下:
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是无序的(12,7,8,2,3,8,10,5,2)。因此,直接执行 where b = 2 这种查询条件没有办法利用联合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情况才,b 才是有序的,比如 a 等于 2 的时候,b 的值为(7,8),这时就是有序的,这个有序状态是局部的,因此,执行 where a = 2 and b = 7 这种查询条件时, a 和 b 字段能用到联合索引的,也就是联合索引生效了。
联合索引范围查询
联合索引有一些特殊情况,并不是查询过程使用了联合索引查询,就代表联合索引中的所有字段都用到了联合索引进行索引查询,也就是可能存在部分字段用到联合索引的 B+Tree,部分字段没有用到联合索引的 B+Tree 的情况。
这种特殊情况就发生在范围查询。也就是文章开头的那句话:联合索引的最左匹配原则会一直向右匹配直到遇到「范围查询」就会停止匹配。也就是范围查询的字段可以用到联合索引,但是范围查询字段的后面的字段无法用到联合索引。
范围查询有很多种,那到底是哪些范围查询会导致联合索引的最左匹配原则会停止匹配呢?
接下来,举例几个范围查询的例子,下面的实验案例是基于 MySQL 8.0 做的。
例子一
Q1: select * from t_table where a > 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
由于联合索引(二级索引)是先按照 a 字段的值排序的,所以符合 a > 1 条件的二级索引记录肯定是相邻的,于是在进行索引扫描的时候,可以定位到符合 a > 1 条件的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录不符合 a > 1 条件位置。所以 a 字段可以在联合索引的 B+Tree 中进行索引查询。
但是在符合 a > 1 条件的二级索引记录的范围里,b 字段的值是无序的。
比如,下图的联合索引的 B+ Tree 里:
下面这三条记录的 a 字段的值都符合 a > 1 查询条件,而 b 字段的值是无序的:
- a 字段值为 5 的记录,该记录的 b 字段值为 8;
- a 字段值为 6 的记录,该记录的 b 字段值为 10;
- a 字段值为 7 的记录,该记录的 b 字段值为 5;
因此,我们不能根据查询条件 b = 2 来进一步减少需要扫描的记录数量(b 字段无法利用联合索引进行索引查询的意思)。
所以在执行 Q1 这条查询语句的时候,对应的扫描区间是 (2, + ∞),形成该扫描区间的边界条件是 a > 1,与 b = 2 无关。
因此,Q1 这条查询语句只有 a 字段用到了联合索引进行索引查询,而 b 字段并没有使用到联合索引。
我们也可以在执行计划中的 key_len 知道这一点,在使用联合索引进行查询的时候,通过 key_len 我们可以知道优化器具体使用了多少个字段的查询条件来形成扫描区间的边界条件。
举例个例子 ,a 和 b 都是 int 类型且不为 NULL 的字段,那么 Q1 这条查询语句执行计划如下:
可以看到 key_len 为 4 字节(如果字段允许为 NULL,就在字段类型占用的字节数上加 1,也就是 5 字节),说明只有 a 字段用到了联合索引进行索引查询,而且可以看到,即使 b 字段没用到联合索引,key 为 idx_a_b,说明 Q1 查询语句使用了 idx_a_b 联合索引。
通过 Q1 查询语句我们可以知道,a 字段使用了 > 进行范围查询,联合索引的最左匹配原则在遇到 a 字段的范围查询( >)后就停止匹配了,因此 b 字段并没有使用到联合索引。
例子二
Q2: select * from t_table where a >= 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
Q2 和 Q1 的查询语句很像,唯一的区别就是 a 字段的查询条件「大于等于」。
由于联合索引(二级索引)是先按照 a 字段的值排序的,所以符合 >= 1 条件的二级索引记录肯定是相邻,于是在进行索引扫描的时候,可以定位到符合 >= 1 条件的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录不符合 a>= 1 条件位置。所以 a 字段可以在联合索引的 B+Tree 中进行索引查询。
虽然在符合 a>= 1 条件的二级索引记录的范围里,b 字段的值是「无序」的,但是对于符合 a = 1 的二级索引记录的范围里,b 字段的值是「有序」的(因为对于联合索引,是先按照 a 字段的值排序,然后在 a 字段的值相同的情况下,再按照 b 字段的值进行排序)。
于是,在确定需要扫描的二级索引的范围时,当二级索引记录的 a 字段值为 1 时,可以通过 b = 2 条件减少需要扫描的二级索引记录范围(b 字段可以利用联合索引进行索引查询的意思)。也就是说,从符合 a = 1 and b = 2 条件的第一条记录开始扫描,而不需要从第一个 a 字段值为 1 的记录开始扫描。
所以,Q2 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。执行计划如下:
可以看到 key_len 为 8 字节,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 a 和 b 字段都用到了联合索引进行索引查询。
通过 Q2 查询语句我们可以知道,虽然 a 字段使用了 >= 进行范围查询,但是联合索引的最左匹配原则并没有在遇到 a 字段的范围查询( >=)后就停止匹配了,b 字段还是可以用到了联合索引的。
例子三
Q3: SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
Q3 查询条件中 a BETWEEN 2 AND 8 的意思是查询 a 字段的值在 2 和 8 之间的记录。
不同的数据库对 BETWEEN ... AND 处理方式是有差异的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 边界值,类似于 >= and =<。而有的数据库则不包含 value1 和 value2 边界值(类似于 > and <)。
这里我们只讨论 MySQL。由于 MySQL 的 BETWEEN 包含 value1 和 value2 边界值,所以类似于 Q2 查询语句,因此Q3 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。执行计划如下:
可以看到 key_len 为 8 字节,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 a 和 b 字段都用到了联合索引进行索引查询。
通过 Q3 查询语句我们可以知道,虽然 a 字段使用了 BETWEEN 进行范围查询,但是联合索引的最左匹配原则并没有在遇到 a 字段的范围查询( BETWEEN)后就停止匹配了,b 字段还是可以用到了联合索引的。
例子四
Q4: SELECT * FROM t_user WHERE name like 'j%' and age = 22,联合索引(name, age)哪一个字段用到了联合索引的 B+Tree?
由于联合索引(二级索引)是先按照 name 字段的值排序的,所以前缀为 ‘j’ 的 name 字段的二级索引记录都是相邻的, 于是在进行索引扫描的时候,可以定位到符合前缀为 ‘j’ 的 name 字段的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录的 name 前缀不为 ‘j’ 为止。
所以 a 字段可以在联合索引的 B+Tree 中进行索引查询,形成的扫描区间是['j','k')。注意, j 是闭区间。如下图:
虽然在符合前缀为 ‘j’ 的 name 字段的二级索引记录的范围里,age 字段的值是「无序」的,但是对于符合 name = j 的二级索引记录的范围里,age字段的值是「有序」的(因为对于联合索引,是先按照 name 字段的值排序,然后在 name 字段的值相同的情况下,再按照 age 字段的值进行排序)。
于是,在确定需要扫描的二级索引的范围时,当二级索引记录的 name 字段值为 ‘j’ 时,可以通过 age = 22 条件减少需要扫描的二级索引记录范围(age 字段可以利用联合索引进行索引查询的意思)。也就是说,从符合 name = 'j' and age = 22 条件的第一条记录时开始扫描,而不需要从第一个 name 为 j 的记录开始扫描 。如下图的右边:
所以,Q4 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。本次例子中:
name 字段的类型是 varchar(30) 且不为 NULL,数据库表使用了 utf8mb4 字符集,一个字符集为 utf8mb4 的字符是 4 个字节,因此 name 字段的实际数据最多占用的存储空间长度是 120 字节(30 x 4),然后因为 name 是变长类型的字段,需要再加 2,也就是 name 的 key_len 为 122。
age 字段的类型是 int 且不为 NULL,key_len 为 4。
Q4 查询语句的执行计划如下:
可以看到 key_len 为 126 字节,name 的 key_len 为 122,age 的 key_len 为 4,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 name 和 age 字段都用到了联合索引进行索引查询。
通过 Q4 查询语句我们可以知道,虽然 name 字段使用了 like 前缀匹配进行范围查询,但是联合索引的最左匹配原则并没有在遇到 name 字段的范围查询( like 'j%')后就停止匹配了,age 字段还是可以用到了联合索引的。
小结
网上传来穿去这句话:「联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配」并不是对的。
经过实验的证明,我得出的结论是这样的:
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段后面的字段无法用到联合索引。注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。
相关文章:
mysql的联合索引最左匹配原则问题
MySQL的联合索引 联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配。 这个结论并不全对!去掉 「between 和 like 」这个结论就没问题了 经过实验的证明,我得出的结论是这样的: 联合索引的最…...
三层交换机实现不同VLAN间通讯
默认时,同一个VLAN中的主机才能彼此通信,那么交换机上的VLAN用户之间如何通信? 要实现VLAN之间用户的通信,就必须借助路由器或三层交换机来完成。 下面以三层交换机为例子说明: 注意: 1.交换机与三层交换…...

C#枚举的使用
在C#中经常会用到枚举,是比较常用的定义一组常量集合的数据类型。我们使用枚举可以更方便理解和阅读代码,增强代码可读性,也在某种程度上提升了编程逻辑和维度。 基本语法: enum MyEnum {Value1,Value2,Value3,//...…...
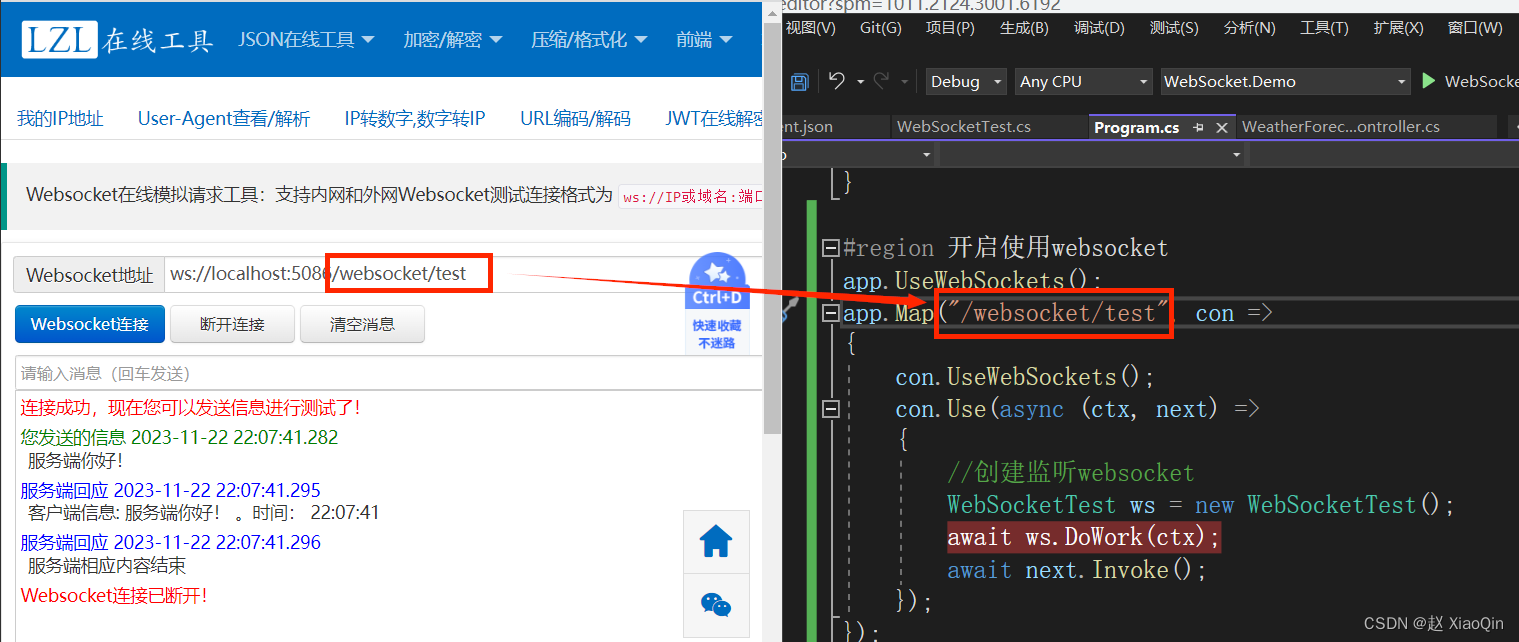
.Net6使用WebSocket与前端进行通信
1. 创建类WebSocketTest: using System.Net.WebSockets; using System.Text;namespace WebSocket.Demo {public class WebSocketTest{//当前请求实例System.Net.WebSockets.WebSocket socket null;public async Task DoWork(HttpContext ctx){socket await ctx.We…...
)
hadoop 编写开启关闭集群脚本, hadoop hdfs,yarn开启关闭脚本。傻瓜式hadoop脚本 hadoop(九)
1. 三台机器: hadoop22, hadoop23, hadoop24 2. hdfs在22机器启动,yarn在hadoop23机器 3. 脚本需要hadoop用户启动才可以 4. 脚本必须在hadoop22机器运行。如果想在所有机器都能运行,你可以自己修改脚本 4. 脚本: #!/bin/bas…...

ArrayList中放的是一个对象,如何同时根据对象中的三个字段对List进行排序
import java.util.ArrayList; import java.util.Collections; import java.util.Comparator;public class YourObject {private int field1;private String field2;private double field3;// 构造函数和其他代码public int getField1() {return field1;}public String getField…...

MONGODB 的基础 NOSQL注入基础
首先来学习一下nosql 这里安装就不进行介绍 只记录一下让自己了解mongodb ubuntu 安装后 进入 /usr/bin ./mongodb即可进入然后可通过 进入的url链接数据库 基本操作 show dbshow dbsshow tablesuse 数据库名插入数据db.admin.insert({json格式的数据})例如 db.admin.inse…...
单链表实现【队列】
目录 队列的概念及其结构 队列的实现 数组队列 链式队列 队列的常见接口的实现 主函数Test.c 头文件&函数声明Queue.h 头文件 函数声明 函数实现Queue.c 初始化QueueInit 创建节点Createnode 空间释放QueueDestroy 入队列QueuePush 出队列QueuePop 队头元…...
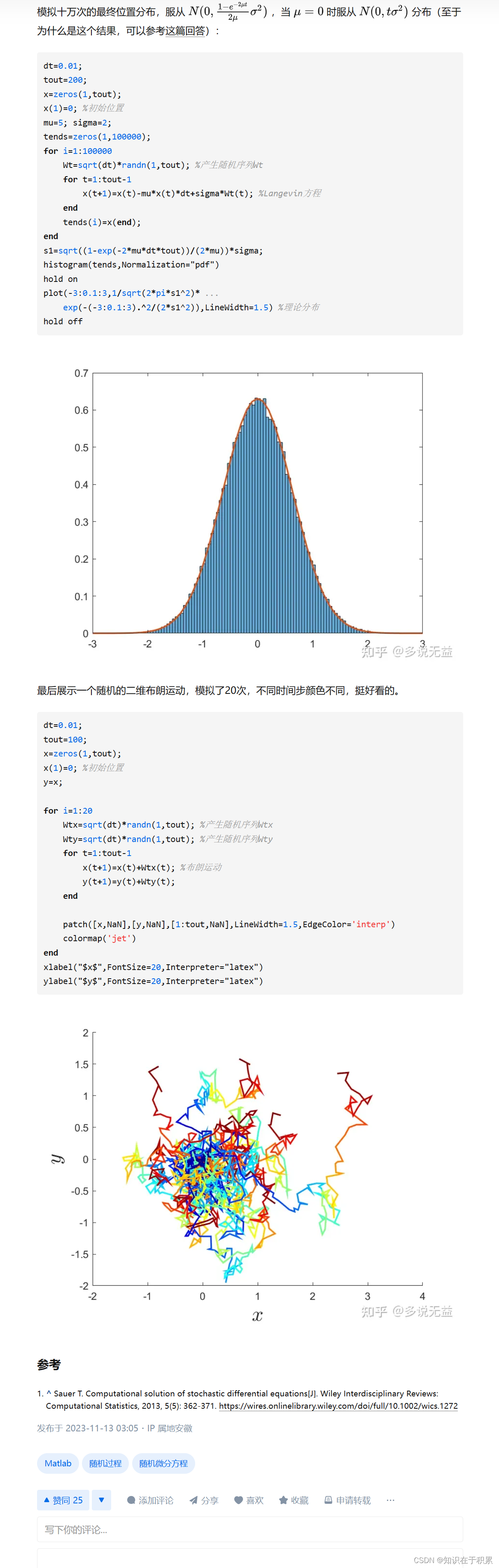
随机微分方程的MATLAB数值求解
dt0.01; tout200; %总时间为2 xzeros(1,tout); x(1)0.5; %初始位置 mu0.2; sigma1; Wtsqrt(dt)*randn(1,tout); %产生随机序列Wt for t1:tout-1x(t1)x(t)mu*x(t)*dtsigma*x(t)*Wt(t); end t11:10:tout; %对原时间序列进行抽样 xtzeros(1,length(t1)); i1; for tt1xt(i)0.5*exp(…...

ChatGPT 也并非万能,品牌如何搭上 AIGC「快班车」
内容即产品的时代,所见即所得,所得甚至超越所见。 无论是在公域的电商平台、社交媒体,还是品牌私域的官网、社群、小程序,品牌如果想与用户发生连接,内容永远是最前置的第一要素。 01 当内容被消费过,就…...

【JavaSE】不允许你不会使用String类
🎥 个人主页:深鱼~🔥收录专栏:JavaSE🌄欢迎 👍点赞✍评论⭐收藏 目录 前言: 一、常用方法 1.1 字符串构造 1.2 String对象的比较 (1)比较是否引用同一个对象 注意…...
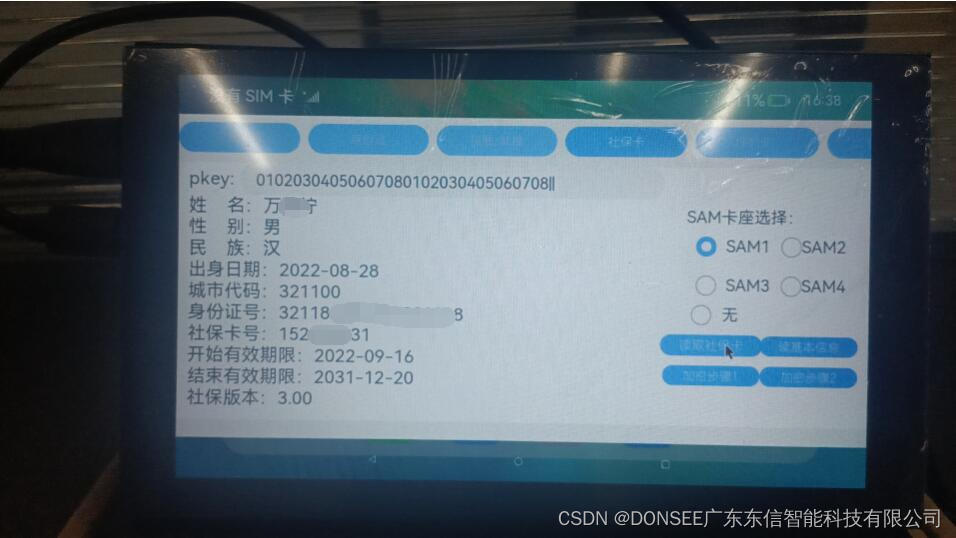
身份证阅读器和社保卡读卡器Harmony鸿蒙系统ArkTS语言SDK开发包
项目需求,用ArkTS新一代开发语言实现了在Harmony鸿蒙系统上面兼容身份证阅读器和社保卡读卡器,调用了DonseeDeviceLib.har这个读卡库。 需要注意的是,鸿蒙系统的app扩展名为.hap,本项目编译输出的应用为:entry-default…...

并发与并行
并发和并行是操作系统中的两个重要概念,它们在定义和处理任务的方式上有一些区别。 并发(concurrency)是指在一段时间内,有多个程序都处于启动运行到运行完毕之间,但任一时刻点上只有一个程序在处理机上运行。它是一种…...
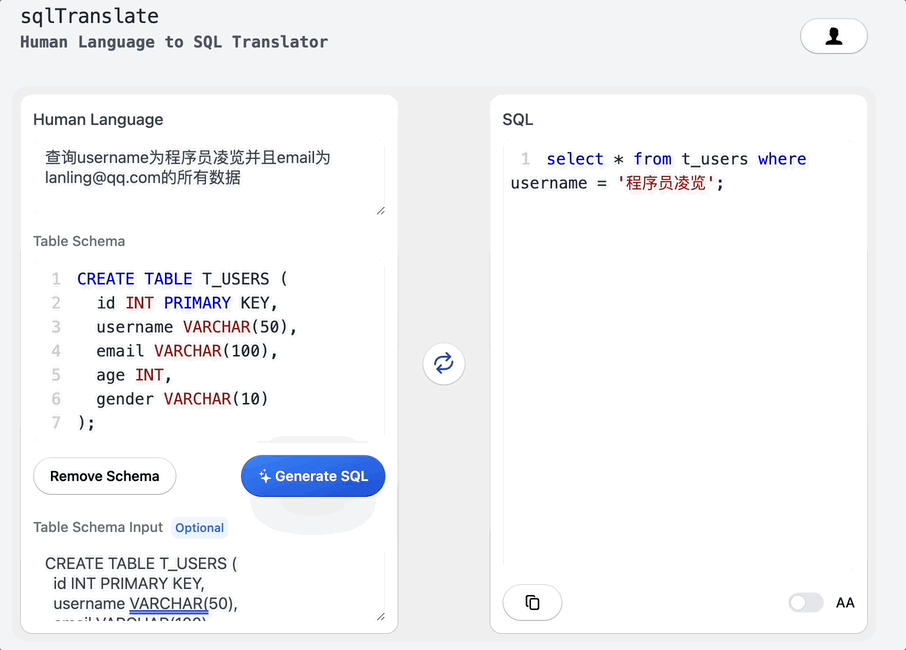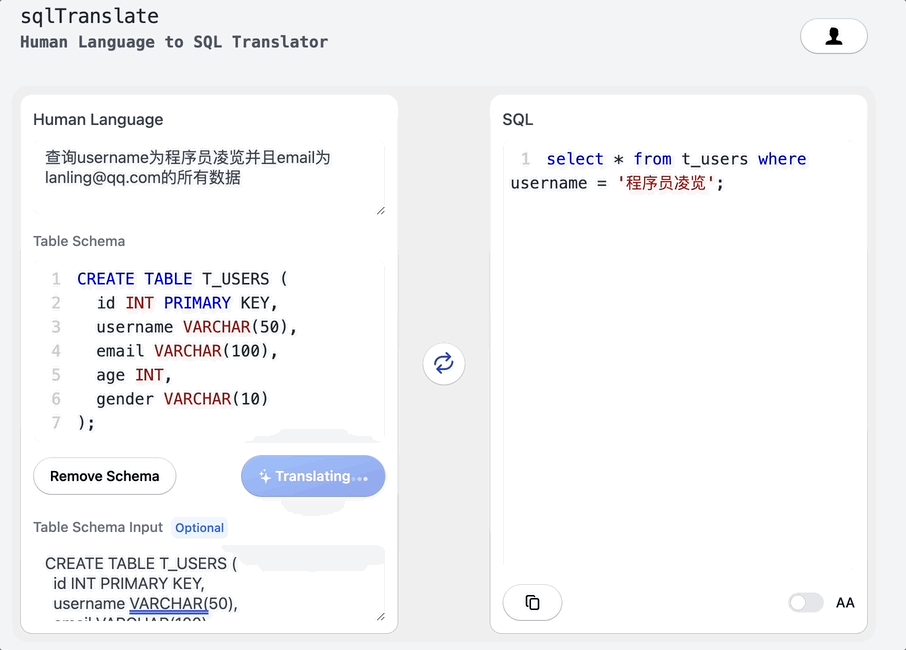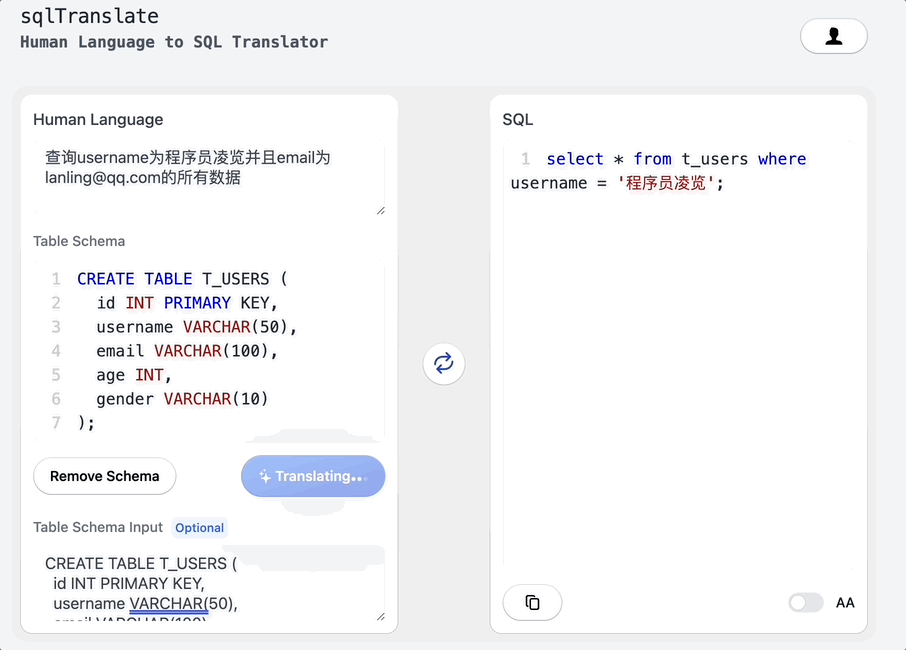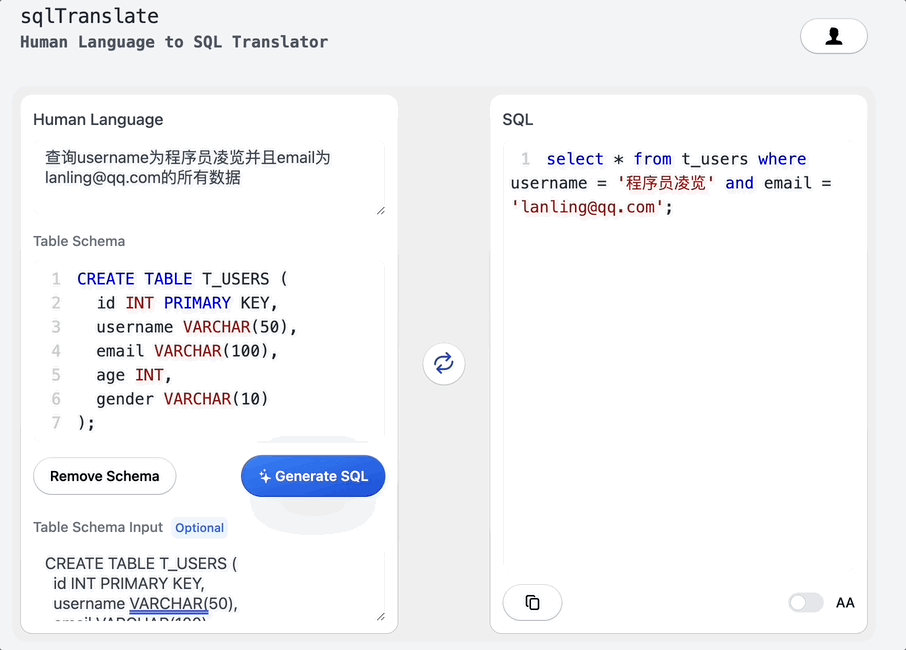
搭个网页应用,让ChatGPT帮我写SQL
大家好,我是凌览。 开门见山,我搭了一个网页应用名字叫sql-translate。访问链接挂在我的个人博客(https://linglan01.cn/about)导航栏,也可以访问https://www.linglan01.cn/c/sql-translate/直达sql-translate。 它的主要功能有:…...

实时云渲染 助力破解智慧园区痛点困局
智慧园区是运用先进的信息技术,如物联网(IoT)、大数据、云计算、人工智能、三维可视化等,对园区内的各类设施、资源以及管理进行智能化和数字化升级。其目标是通过科技手段提升园区的运营效率、资源利用率,提供更便捷、…...

计算机组成原理2
1.浮点数 2.IEEE 754 3.存储器的性能指标 4.存储器的层次化结构 主存类似手机运行内存8g ,辅存类似手机内存128g.... 辅存必须先通过主存才能被cpu接收,就例如微信打开那个月亮小人界面两三秒就是主存在读取辅存的程序然后被cpu接收运行。 5.主存储…...

Py之PyMuPDF:PyMuPDF的简介、安装、使用方法之详细攻略
Py之PyMuPDF:PyMuPDF的简介、安装、使用方法之详细攻略 目录 PyMuPDF的简介 PyMuPDF的安装 PyMuPDF的使用方法 1、基础用法 PyMuPDF的简介 PyMuPDF是一个高性能的Python库,用于PDF(和其他)文档的数据提取,分析,转换和操作。 …...

2023亚太杯数学建模A题B题C题思路模型代码论文指导
2023亚太地区数学建模A题思路:开赛后第一时间更新,获取见文末 名片 2023亚太地区数学建模B题思路:开赛后第一时间更新,获取见文末 名片 2023亚太地区数学建模C题思路:开赛后第一时间更新,获取见文末 名片…...
【C/PTA】函数专项练习(四)
本文结合PTA专项练习带领读者掌握函数,刷题为主注释为辅,在代码中理解思路,其它不做过多叙述。 目录 6-1 计算A[n]1/(1 A[n-1])6-2 递归实现顺序输出整数6-3 自然数的位数(递归版)6-4 分治法求解金块问题6-5 汉诺塔6-6 重复显示字符(递归版)…...

广西柳州机械异形零部件三维扫描3D抄数全尺寸测绘建模-CASAIM中科广电
一、背景介绍 复杂机械异形零部件具有不规则的形状和复杂的结构,给生产制造带来了很大的检测难度。为了确保零部件的制造质量和精度,需要对零部件进行全面的尺寸检测和分析。 CASAIM三维扫描仪在机械异形零部件全尺寸检测应用可以实现对机械异形零部件…...

Cursor Free VIP破解工具:15个功能一键解决AI编程助手试用限制问题
Cursor Free VIP破解工具:15个功能一键解决AI编程助手试用限制问题 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reac…...

终极指南:如何使用开源网盘直链下载助手轻松获取八大网盘真实下载链接
终极指南:如何使用开源网盘直链下载助手轻松获取八大网盘真实下载链接 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国…...

ROS Noetic安装后,用TurtleSim和海龟节点快速验证你的环境是否真的OK
ROS Noetic安装后快速验证:用TurtleSim三分钟完成环境诊断 刚装完ROS Noetic的新手常会遇到这样的困惑:终端明明显示安装成功,但运行节点时却报各种环境错误。上周就有位机械专业的研究生向我求助——他按照教程安装了三次ROS,每次…...

WeChatExporter完整指南:三步永久备份微信聊天记录的终极方案
WeChatExporter完整指南:三步永久备份微信聊天记录的终极方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机丢失或系统重置而丢失珍贵的微信…...

【2026年版|收藏级】RAG系统延迟优化实战:从链路拆解到面试通关,小白也能看懂
说实话,在2026年大模型落地常态化的今天,5秒的RAG系统首字响应时间,在C端产品里基本等于直接流失用户——用户不会耐心等待一个“反应迟钝”的AI,尤其是在对话式交互、智能问答等高频场景中。 不管是日常开发落地,还是…...

C++的数据类型你真的了解吗
前言 C不像python,创建变量的时候必须指定类型,这样才能给变量分配一个合适的内存空间。 1 整型 作用:整型变量表示的是整型类型的数据 整型的数据类型有4种(最常用的是int),其区别在于所占内存空间不同…...

让你的Emacs在MacOS上自动全屏启动
在MacOS 14 Sonoma系统上使用Emacs,尤其是在使用emacs-plus或doomemacs配置时,你可能已经注意到,默认情况下通过emacsclient -c启动的Emacs窗口大小较小,且没有获得焦点。这不仅影响了工作效率,还需要额外的操作来调整窗口大小和获取焦点。今天,我们将探讨如何让Emacs在启…...

C#怎么设置JWT身份认证_C#如何生成并验证Token令牌【实战】
必须在Program.cs中调用AddJwtBearer()配置JWT认证,显式设置TokenValidationParameters各验证开关为true,严格匹配issuer/audience字符串,正确使用SecurityKey和SigningCredentials,并确保Authorization头格式为“Bearer <toke…...

基于ChatGPT与Python的自动化股票报告生成器实战
1. 项目概述:一个基于ChatGPT的自动化股票报告生成器最近在捣鼓一个挺有意思的小项目,我把它叫做“ChatGPT股票报告生成器”。核心想法很简单:作为一个普通投资者,每天看盘、复盘、整理信息,时间成本太高了。能不能让A…...

终极JavaScript面试准备指南:掌握10个实战练习轻松应对面试挑战
终极JavaScript面试准备指南:掌握10个实战练习轻松应对面试挑战 【免费下载链接】javascript-interview-questions List of 1000 JavaScript Interview Questions 项目地址: https://gitcode.com/GitHub_Trending/ja/javascript-interview-questions 正在准备…...