Hadoop综合案例 - 聊天软件数据
目录
- 1、聊天软件数据分析案例需求
- 2、基于Hive数仓实现需求开发
- 2.1 建库
- 2.2 建表
- 2.3 加载数据
- 2.4 ETL数据清洗
- 2.5 需求指标统计---都很简单
- 3、FineBI实现可视化报表
- 3.1 FineBI介绍
- 3.2 FineBI配置数据
- 3.3 构建可视化报表
1、聊天软件数据分析案例需求
MR速度慢—引入hive
背景:大量的用户在线,通过对聊天数据的分析,构建用户画像,为用户提供更好的服务、以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。
目标:基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表

需求:
- 统计今日总消息量
- 统计今日每小时消息量、发送和接收用户数
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的Top10用户
- 统计今日接收消息最多的Top10用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
原始数据:业务系统中导出的某一天24小时的用户聊天数据,TSV文件。列分隔符:制表符 \t


2、基于Hive数仓实现需求开发
在Notepad中可以通过显示所有字符来判断间隔符
打开Datagrip,创建一个hive工程,语言选择hive,并与hive服务器创建连接。
Datagrip中:
2.1 建库
--------------1、建库---------------------如果数据库已存在就删除
drop database if exists db_msg cascade;
--创建数据库
create database db_msg;
--切换数据库
use db_msg;2.2 建表
--------------2、建表-------------------
--如果表已存在就删除
drop table if exists db_msg.tb_msg_source;
--建表
create table db_msg.tb_msg_source(msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容"
)
--指定分隔符为制表符
row format delimited fields terminated by '\t';
2.3 加载数据
--------------3、加载数据-------------------
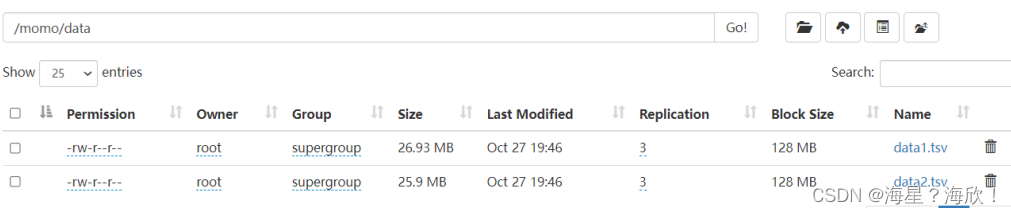
--上传数据文件到node1服务器本地文件系统(HS2服务所在机器)
--shell: mkdir -p /root/hivedata--加载数据到表中
load data local inpath '/root/hivedata/data1.tsv' into table db_msg.tb_msg_source;
load data local inpath '/root/hivedata/data2.tsv' into table db_msg.tb_msg_source;--查询表 验证数据文件是否映射成功
select * from tb_msg_source limit 10;--统计行数
select count(*) as cnt from tb_msg_source;
2.4 ETL数据清洗
加载完数据后,需要判断加载过来的数据是否有效–ETL
问题与解决:
- sender_gps字段有些记录为空,如何处理? – where length(sender_gps) =0筛选出非空的
- 时间字段,只需要提取中间的小时信息? —substr(字段,12,1)提取小时
- GPS经纬度是一个字段,需要获取经纬度两个? — split(字段,‘,’)根据逗号进行字段切割
- 将ETL处理后的结果保存到一张新hive表中?—CTAS语法
create table … as select … 表结构和数据全部都有了
--ETL实现
--如果表已存在就删除
drop table if exists db_msg.tb_msg_etl;
--将Select语句的结果保存到新表中
create table db_msg.tb_msg_etl as
select*,substr(msg_time,0,10) as dayinfo, --获取天substr(msg_time,12,2) as hourinfo, --获取小时split(sender_gps,",")[0] as sender_lng, --提取经度split(sender_gps,",")[1] as sender_lat --提取纬度
from db_msg.tb_msg_source
--过滤字段为空的数据
where length(sender_gps) > 0 ;
数据量太多–记得limit 10
--验证ETL结果
selectmsg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat
from db_msg.tb_msg_etl
limit 10;
2.5 需求指标统计—都很简单
需求1:统计今日总消息量
group by 每日后count计数
create table if not exists tb_rs_total_msg_cnt
comment "今日消息总量"
as
selectdayinfo,count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo;select * from tb_rs_total_msg_cnt;--结果验证
需求2:统计今日每小时消息量、发送和接收用户数
按每天,每小时分组,计数
create table if not exists tb_rs_hour_msg_cnt
comment "每小时消息量趋势"
as
selectdayinfo,hourinfo,count(*) as total_msg_cnt,count(distinct sender_account) as sender_usr_cnt,count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo,hourinfo;select * from tb_rs_hour_msg_cnt;--结果验证
需求3:统计今日各地区发送消息数据量
按照每日与地区GPS分组,
出现在select后的字段,要么是group by 后的字段,要么是聚合函数字段,所以分组还加了经纬度字段。
case函数:将原本经纬度的string类型转换成double数字类型
cast(sender_lng as double)
create table if not exists tb_rs_loc_cnt
comment "今日各地区发送消息总量"
as
selectdayinfo,sender_gps,cast(sender_lng as double) as longitude,cast(sender_lat as double) as latitude,count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_gps,sender_lng,sender_lat;select * from tb_rs_loc_cnt; --结果验证
需求4:统计今日发送消息和接收消息的用户数
按照天分组,对用户数进行去重统计
create table if not exists tb_rs_usr_cnt
comment "今日发送消息人数、接受消息人数"
as
selectdayinfo,count(distinct sender_account) as sender_usr_cnt,count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo;select * from tb_rs_usr_cnt; --结果验证
需求5:统计今日发送消息最多的Top10用户
按照天,用户分组,计数后排序,limit 10
create table if not exists tb_rs_susr_top10
comment "发送消息条数最多的Top10用户"
as
selectdayinfo,sender_name as username,count(*) as sender_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_name
order by sender_msg_cnt desc
limit 10;select * from tb_rs_susr_top10; --结果验证
需求6:统计今日接收消息最多的Top10用户
按照天,用户分组,计数后排序,limit 10
create table if not exists tb_rs_rusr_top10
comment "接受消息条数最多的Top10用户"
as
selectdayinfo,receiver_name as username,count(*) as receiver_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,receiver_name
order by receiver_msg_cnt desc
limit 10;select * from tb_rs_rusr_top10; --结果验证
需求7:统计发送人的手机型号分布情况
按照天,用户手机型号分组,对用户去重计数
create table if not exists tb_rs_sender_phone
comment "发送人的手机型号分布"
as
selectdayinfo,sender_phonetype,count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_phonetype;select * from tb_rs_sender_phone; --结果验证
需求8:统计发送人的设备操作系统分布情况
create table if not exists tb_rs_sender_os
comment "发送人的OS分布"
as
selectdayinfo,sender_os,count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_os;select * from tb_rs_sender_os; --结果验证
3、FineBI实现可视化报表
进入可视化展示阶段
3.1 FineBI介绍
FineBI:https://www.finebi.com/
FineBI特点:可多人协作、拖拽不需要代码、适合各种分析场景、支持各种图表、支持大数据
已下载安装好
3.2 FineBI配置数据
将hive中数据连接到BI上。
FineBI与Hive集成的官方文档:https://help.fanruan.com/finebi/doc-view-301.html
驱动配置、安装插件-----都配置好了,可直接连接hive数据
配置数据操作
3.3 构建可视化报表
FineBI上各种拖拽操作
最后效果:

总结:很简单的一个案例,但把数据分析的整个流程走完了
相关文章:
Hadoop综合案例 - 聊天软件数据
目录1、聊天软件数据分析案例需求2、基于Hive数仓实现需求开发2.1 建库2.2 建表2.3 加载数据2.4 ETL数据清洗2.5 需求指标统计---都很简单3、FineBI实现可视化报表3.1 FineBI介绍3.2 FineBI配置数据3.3 构建可视化报表1、聊天软件数据分析案例需求 MR速度慢—引入hive 背景&a…...

Python进阶-----面向对象1.0(对象和类的介绍、定义)
目录 前言: 面向过程和面向对象 类和对象 Python中类的定义 (1)类的定义形式 (2)深层剖析类对象 前言: 感谢各位的一路陪伴,我学习Python也有一个月了,在这一个月里我收获满满…...

天猫淘宝企业服务为中小微企业打造供应链智能协同网络,让采购不再将就!丨爱分析报告
编者按:近日天猫淘宝企业服务&爱分析联合发布《2023中小微企业电商采购白皮书》,为中小微企业采购数字化带来红利。 某水泵企业:线上客户主要是中小微企业,线上业绩遇到瓶颈,如何突破呢?某焊割设备企业…...

基于四信网络摄像机的工业自动化应用
方案背景 随着数控机床被广泛的应用在工业生产中,数控技术发展成为制造业的核心。 鉴于数控机床的复杂性,以及企业人力储备有限,设备的监控和维护必须借助外部力量,而如何实现车间实时监测成了目前迫切解决的问题。 方案需求 ①兼…...

软件测试2
一 web掐断三大核心技术 HTML:负责网页的结构 CSS:负责网页的美化 JS:负责网页的行为 二 工具的使用 改变HBuilder文字的大小: 工具-视觉主题设置-大小22-确定 三 html简介 中文定义:超文本标记语言 新建一个html…...
leetcode162. 寻找峰值)
(二分查找)leetcode162. 寻找峰值
文章目录一、题目1、题目描述2、基础框架3、原题链接二、解题报告1、思路分析2、时间复杂度3、代码详解三、本题小知识一、题目 1、题目描述 峰值元素是指其值严格大于左右相邻值的元素。 给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值…...
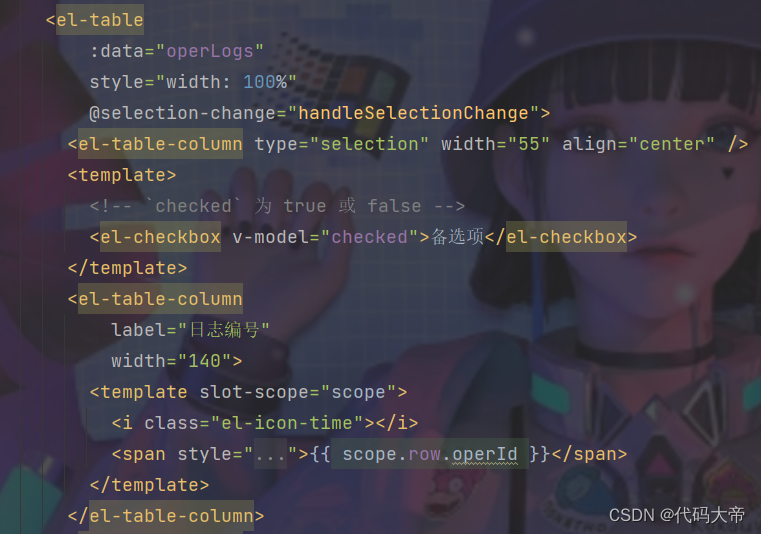
spring boot 配合element ui vue实现表格的批量删除(前后端详细教学,简单易懂,有手就行)
目录 一.前言: 二. 前端代码: 2.1.element ui组件代码 2.2删除按钮 2.3.data 2.4.methods 三.后端代码: 一.前言: 研究了其他人的博客,找到了一篇有含金量的,进行了部分改写实现前后端分离࿰…...
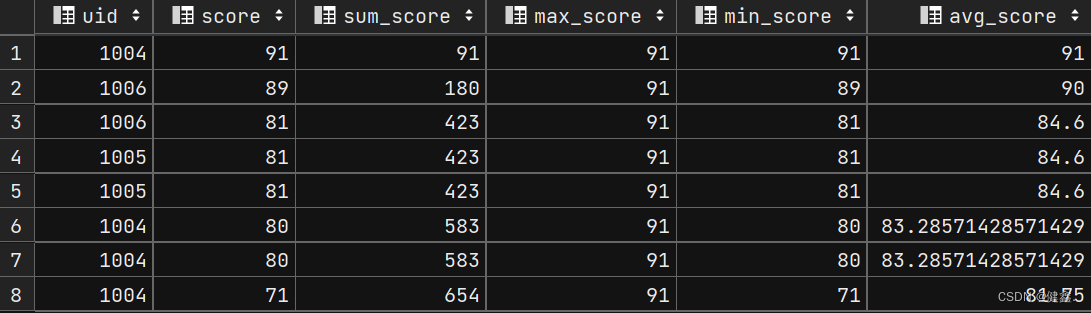
hiveSQL开窗函数详解
hive开窗函数 文章目录hive开窗函数1. 开窗函数概述1.1 窗口函数分类1.2 窗口函数和普通聚合函数的区别2. 窗口函数的基本用法2.1 基本用法2.2 设置窗口的方法2.2.1 window_name2.2.2 partition by2.2.3 order by 子句2.2.4 rows指定窗口大小窗口框架2.3 开窗函数中加 order by…...

深度学习基础实例与总结
一、神经网络 1 深度学习 1 什么是深度学习? 简单来说,深度学习就是一种包括多个隐含层 (越多即为越深)的多层感知机。它通过组合低层特征,形成更为抽象的高层表示,用以描述被识别对象的高级属性类别或特征。 能自生成数据的中…...

在 WIndows 下安装 Apache Tinkerpop (Gremlin)
一、安装 JDK 首先安装 Java JDK,这个去官网下载即可,我下载安装的 JDK19(jdk-19_windows-x64_bin.msi),细节不赘述。 二、去 Tinkerpop 网站下载 Gremlin 网址:https://tinkerpop.apache.org/ 点击下面…...

从软件的角度看待PCI和PCIE(一)
1.最容易访问的设备是什么? 是内存! 要读写内存,知道它的地址就可以了,不需要什么驱动程序; volatile unsigned int *p 0xffff8811; unsigned int val; *p val; val *p;只有内存能这样简单、方便的使用吗…...

DSP_TMS320F28377D_ADC学习笔记
前言 DSP各种模块的使用,基本上就是 GPIO复用配置、相关控制寄存器的配置、中断的配置。本文主要记录本人对ADC模块的学习笔记。TMS320F28377D上面有24路ADC专用IO,这意味着不需要进行GPIO复用配置。 只需要考虑相关控制寄存器和中断的配置。看代码请直…...
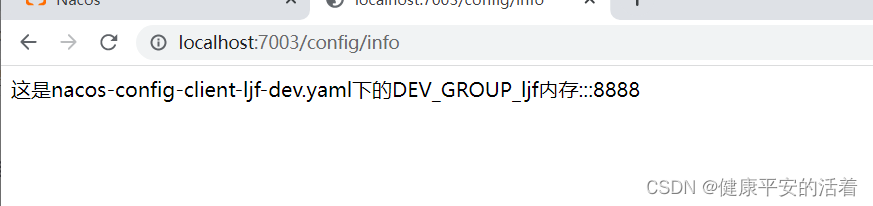
springcloud3 Nacos中namespace和group,dataId的联系
一 Namespance和group和dataId的联系 1.1 3者之间的联系 话不多说,上答案,如下图: namespance用于区分部署环境,group和dataId用于逻辑上区分两个目标对象。 二 案例:实现读取注册中心的不同环境下的配置文件 …...
[YOLO] yolo理解博客笔记
YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的过程详细解读 YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解https://blog.csdn.net/shenkunchang1877/article/details/105648111YOLO v1网络结构计算 Yolov1-pytorch版 …...

清华源pip安装Python第三方包
一、更换PIP源PIP源在国外,速度慢,可以更换为国内源,以下是国内一些常用的PIP源。豆瓣(douban) http://pypi.douban.com/simple/ (推荐)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/阿里云 http://mirrors.aliyun.com/pypi/simple/中…...

python线程池【ThreadPoolExecutor()】批量获取博客园标题数据
转载:蚂蚁学python 网址:【【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行】 https://www.bilibili.com/video/BV1bK411A7tV/?p8&share_sourcecopy_web&vd_sourced0ef3d08fdeef1740bab49cdb3e96467实战案…...
LearnOpenGL-入门-8.坐标系统
本人刚学OpenGL不久且自学,文中定有代码、术语等错误,欢迎指正 我写的项目地址:https://github.com/liujianjie/LearnOpenGLProject LearnOpenGL中文官网:https://learnopengl-cn.github.io/ 文章目录坐标系统概述局部空间世界空…...

windows10使用wsl2安装docker
配环境很麻烦,想利用docker的镜像环境跑一下代码整个安装过程的原理是:windows使用docker,必须先安装一个linux虚拟机,才可运行docker,而采用wsl2安装虚拟机是目前最好的方法第一步 windows安装wsl2控制面板->程序-…...

Javascript的API基本内容(六)
一、正则表达式 1.定义规则 const reg /表达式/ 其中/ /是正则表达式字面量正则表达式也是对象 2.使用正则 test()方法 用来查看正则表达式与指定的字符串是否匹配如果正则表达式与指定的字符串匹配 ,返回true,否则false 3.元字符 比如࿰…...

电压放大器和电流放大器的区别是什么意思
在日常电子实验测试中,很多电子工程师都会使用到电压放大器和电流放大器,但是很多新手工程师却无法区分两者的区别,下面就让安泰电子来为我们讲解电压放大器和电流放大器的区别是什么意思。 一、电压放大器介绍: 电压放大器是一种…...

教育科技产品集成AI答疑功能的技术方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育科技产品集成AI答疑功能的技术方案与接入实践 在在线教育领域,为学生提供即时、准确的答疑服务是提升学习体验和效…...

为什么你的项目需要Remix Icon?3200+免费矢量图标的完整解决方案
为什么你的项目需要Remix Icon?3200免费矢量图标的完整解决方案 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon 你是否曾为寻找合适的图标而烦恼?设计界面时图标风格…...

晨芯阳HC9611高PSRR、防Inrush电流、低压差LDO转换器
HC9611系列是高PSRR,防Inrush电流,低噪声,低压差线性稳压器。HC9611系列稳压器内置固定电压基准,温度保护,限流电路以及快速响应电路,达到低功耗,低噪声,高纹波抑制,快速…...

新手避坑指南:用Virtuoso和Calibre做DRC/LVS检查时,IO Pad和电源连接的那些坑
数字后端验证实战:Virtuoso与Calibre中的DRC/LVS避坑指南 第一次用Virtuoso和Calibre做DRC/LVS检查的新手工程师,往往会在IO Pad和电源连接上栽跟头。这些看似基础的问题,轻则导致验证失败,重则影响芯片功能。本文将结合SIMC 0.18…...

第八部分-企业级实践——37. 容器编排选型
37. 容器编排选型 1. 容器编排概述 容器编排平台负责管理容器的整个生命周期,包括部署、扩缩容、负载均衡、服务发现、滚动更新等。Docker Swarm 和 Kubernetes 是目前主流的容器编排方案。 ┌──────────────────────────────────…...
)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战) 在基因组学研究中,数据可视化不仅是结果展示的手段,更是科学叙事的重要语言。一张精心设计的SNP密度图,能够直观呈现全基因组范围内单核…...

机器视觉在人工智能领域的应用
机器视觉在人工智能领域的应用 目录机器视觉在人工智能领域的应用一、图像处理与机器视觉的概念阐述1. 图像处理(Image Processing)2. 机器视觉(Machine Vision / Computer Vision)二、图像处理与机器视觉的区别与共同点区别共同点…...

搞懂VMware三种网络模式:从NAT断网到桥接、仅主机的实战选择指南
VMware虚拟网络模式深度解析:从原理到场景化实战 当你在深夜赶项目时,虚拟机突然无法联网——这种经历对于开发者而言无异于噩梦。我曾亲眼见过团队新人在演示前夜因NAT模式配置问题崩溃,也见证过安全工程师因选错网络模式导致测试环境暴露。…...

3分钟搞定!VideoDownloadHelper视频下载插件终极安装使用指南
3分钟搞定!VideoDownloadHelper视频下载插件终极安装使用指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页…...

从图形变换到机器学习:行列式到底在‘衡量’什么?一个直观的几何理解指南
从图形变换到机器学习:行列式到底在‘衡量’什么?一个直观的几何理解指南 想象你手中有一张弹性薄膜,拉伸、旋转或挤压它时,薄膜覆盖的面积会如何变化?这种直观的几何变换背后,隐藏着线性代数中行列式的本质…...