基于动量的梯度下降

丹尼尔·林肯 (Daniel Lincoln)在Unsplash上拍摄的照片
一、说明
基于动量的梯度下降是一种梯度下降优化算法变体,它在更新规则中添加了动量项。动量项计算为过去梯度的移动平均值,过去梯度的权重由称为 Beta 的超参数控制。
这有助于解决与普通梯度下降相关的一些问题,例如振荡、收敛速度慢以及陷入局部最小值。
基于动量的梯度下降背后的基本直觉是物理学中动量的概念。一个经典而简单的例子是,一个球从山上滚下来,它聚集了足够的动量来克服高原区域,使其达到全局最小值,而不是陷入局部最小值。Momentum 为下降问题的参数更新添加了历史记录,从而显着加速了优化过程。
更新方程中包含的历史量由超参数确定。该超参数的值范围为0到1,其中动量值为0相当于没有动量的梯度下降。动量值越高意味着考虑过去(历史)的更多梯度。
二、梯度下降的问题
让我们首先概述一些影响普通梯度下降算法的问题。
- 局部极小值
梯度下降可能会陷入局部最小值,即不是成本函数的全局最小值但仍低于周围点的点。当成本函数有多个谷值时,就会发生这种情况,并且算法陷入其中而不是达到全局最小值,如下所示:

所有图像均由作者创建
2. 鞍点
鞍点是成本函数中的一个点,其中一个维度具有比周围点更高的值,而另一个维度具有更低的值。梯度下降可能会在这些点上陷入困境,因为一个方向上的梯度指向较低的值,而另一个方向上的梯度则指向较高的值。
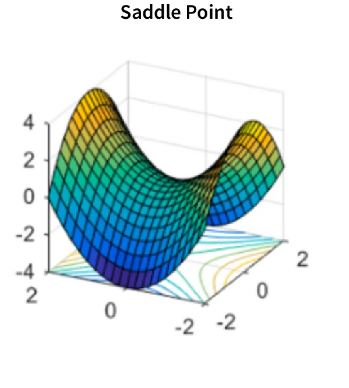
3. 高原期
平稳期是成本函数中梯度非常小或接近于零的区域。这可能会导致梯度下降需要很长时间或不收敛。

4. 振荡
当学习率太高时就会出现振荡,导致算法超过最小值并来回振荡。
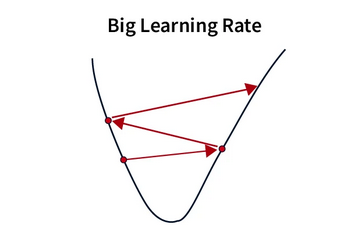
梯度下降还面临其他一些困难,其中最值得注意和广泛讨论的是梯度消失和梯度爆炸。
三、基于动量的梯度下降如何工作
在研究了梯度下降的问题以及提出增强和改进的动机之后,让我们继续讨论梯度下降的实际工作原理。这只需要一些基本的代数,并且会用简单的英语进行解释。
常规梯度下降的基本表达式如下:
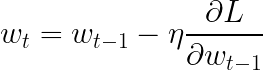
这里,w_t是当前时间步的权重,w_{t-1}是上一个时间步的权重,η是学习率,最后一项是损失函数相对于权重的偏导数上一步(又名渐变)。
现在,我们必须包含动量项并修改更新方程以考虑新的超参数和动量。
![]()
这里,V_t定义为:
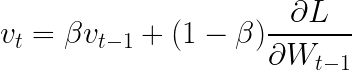
该方程称为指数加权平均值。β 是我们的动量超参数。当 β = 0 时,方程与普通梯度下降相同。
我们从 V_0 = 0 开始,并将方程更新为 t= 1…n。
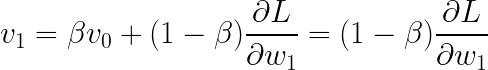
使用Codecog制作
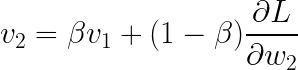
替换:

简化:

现在,
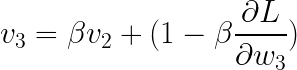
替换:
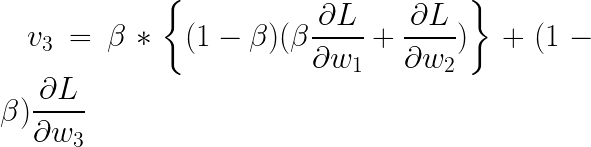
简化:
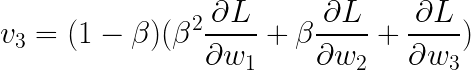
概括:
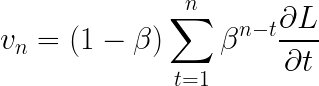
广义求和包括通过所有迭代建立的所有先前梯度。
四、超参数 Beta
现在的问题是我们将新的超参数 β 设置为什么。
如果我们将其设置为一个较低的值,例如0.1,那么t=3时的梯度将贡献其值的100%,t=2时的梯度将贡献其值的10%,而t=1时的梯度将仅贡献其值。贡献其价值的1%。您可以看到,如果我们将 β 设置得太低,早期梯度的贡献会迅速减少。
另一方面,如果我们为 β 设置一个较高的值,例如 0.9,则 t=3 时的梯度将贡献其值的 100%,t=2 时的梯度将贡献其值的 90%,而 t=3 时的梯度将贡献其值的 90%。 t=1将贡献其价值的81%。
我们得出的结论是,较高的 β 将包含更多来自过去的梯度。这就是动力的含义以及它如何在整个过程中建立起来。
五、使用 NumPy 在 Python 中实现
这是带有动量的梯度下降的实现,以及与普通梯度下降的逐步解释和输出比较。在深入实现之前,我们先了解一下普通梯度下降和动量梯度下降之间的区别:
普通梯度下降:
1. 计算损失函数相对于参数的梯度。
2. 通过从当前参数值中减去梯度大小的一小部分(学习率)来更新参数。
3. 重复步骤 1 和 2,直到达到收敛。
带动量的梯度下降:
1. 计算损失函数相对于参数的梯度。
2. 计算步骤 1 中梯度的指数加权移动平均值(动量)。
3. 通过使用动量项修改普通梯度下降中的更新步骤来更新参数。
4. 重复步骤 1-3,直至达到收敛。
现在,我们来看看实现过程:
import numpy as npdef gradient_descent_momentum(X, y, learning_rate=0.01, momentum=0.9, num_iterations=100):# Initialize the parametersnum_samples, num_features = X.shapetheta = np.zeros(num_features)# Initialize the velocity vectorvelocity = np.zeros_like(theta)# Perform iterationsfor iteration in range(num_iterations):# Compute the predictions and errorspredicted = np.dot(X, theta)errors = predicted - y# Compute the gradientsgradients = (1/num_samples) * np.dot(X.T, errors)# Update the velocityvelocity = momentum * velocity + learning_rate * gradients# Update the parameterstheta -= velocity# Compute the mean squared errormse = np.mean(errors**2)# Print the MSE at each iterationprint(f"Iteration {iteration+1}, MSE: {mse}")return theta
Now, let’s compare the output of Gradient Descent with Momentum to Vanilla Gradient Descent using a simple linear regression problem:# Generate some random data
np.random.seed(42)
X = np.random.rand(100, 1)
y = 2 + 3 * X + np.random.randn(100, 1)# Apply Gradient Descent with Momentum
theta_momentum = gradient_descent_momentum(X, y, learning_rate=0.1, momentum=0.9, num_iterations=100)# Apply Vanilla Gradient Descent
theta_vanilla = gradient_descent(X, y, learning_rate=0.1, num_iterations=100)现在,让我们使用简单的线性回归问题将动量梯度下降与普通梯度下降的输出进行比较:
# Generate some random data
np.random.seed(42)
X = np.random.rand(100, 1)
y = 2 + 3 * X + np.random.randn(100, 1)# Apply Gradient Descent with Momentum
theta_momentum = gradient_descent_momentum(X, y, learning_rate=0.1, momentum=0.9, num_iterations=100)# Apply Vanilla Gradient Descent
theta_vanilla = gradient_descent(X, y, learning_rate=0.1, num_iterations=100)输出:
Iteration 1, MSE: 5.894802675477298
Iteration 2, MSE: 4.981474209682729
Iteration 3, MSE: 4.543813739311503
...
Iteration 98, MSE: 0.639280357661573
Iteration 99, MSE: 0.6389711476228525
Iteration 100, MSE: 0.63867258334531Iteration 1, MSE: 5.894802675477298
Iteration 2, MSE: 4.981474209682729
Iteration 3, MSE: 4.543813739311503
...
Iteration 98, MSE: 0.639280357661573
Iteration 99, MSE: 0.6389711476228525
Iteration 100, MSE: 0.63867258334531正如我们从输出中看到的,动量梯度下降和普通梯度下降都提供了相似的结果。然而,由于动量项,动量梯度下降可以更快地收敛,这加速了最新梯度方向的更新,从而导致更快的收敛。
六、应用领域
动量在机器学习社区中广泛用于优化非凸函数,例如深度神经网络。根据经验,动量方法优于传统的随机梯度下降方法。在深度学习中,SGD 广泛流行,是许多优化器(例如 Adam、Adadelta、RMSProp 等)的底层基础,这些优化器已经利用动量来降低计算速度
优化算法的动量扩展可在许多流行的机器学习框架中使用,例如 PyTorch、张量流和 scikit-learn。一般来说,任何可以用随机梯度下降解决的问题都可以从动量的应用中受益。这些通常是无约束的优化问题。可以应用动量的一些常见 SGD 应用包括岭回归、逻辑回归和支持向量机。当实施动量时,包括与癌症诊断和图像确定相关的分类问题也可以减少运行时间。就医疗诊断而言,计算速度的提高可以通过神经网络内更快的诊断时间和更高的诊断准确性直接使患者受益。
七、总结
动量通过减少振荡效应并充当优化问题解决的加速器来改善梯度下降。此外,它还找到全局(而不仅仅是局部)最优值。由于这些优点,动量常用于机器学习,并通过 SGD 广泛应用于所有优化器。尽管动量的超参数必须谨慎选择,并且需要一些试验和错误,但它最终解决了梯度下降问题中的常见问题。随着深度学习的不断发展,动量应用将使模型和问题的训练和解决速度比没有的方法更快。
参考
Brownlee, J.(2021 年,10 月 11 日)。从头开始的梯度下降势头。掌握机器学习。Gradient Descent With Momentum from Scratch - MachineLearningMastery.com。
Sum,C.-S。Leung 和 K. Ho,“梯度下降学习的局限性”,发表于 IEEE Transactions on Neural Networks and Learning Systems,卷。31、没有。6,第 2227–2232 页,2020 年 6 月,doi:10.1109/TNNLS.2019.2927689 弗朗西斯科·佛朗哥
Srihari,S.(nd)。基本优化算法。深度学习。https://cedar.buffalo.edu/~srihari/CSE676/8.3%20BasicOptimizn.pdf
相关文章:
基于动量的梯度下降
丹尼尔林肯 (Daniel Lincoln)在Unsplash上拍摄的照片 一、说明 基于动量的梯度下降是一种梯度下降优化算法变体,它在更新规则中添加了动量项。动量项计算为过去梯度的移动平均值,过去梯度的权重由称为 Beta 的超参数控制。 这有助于解决与普通梯度下降相…...
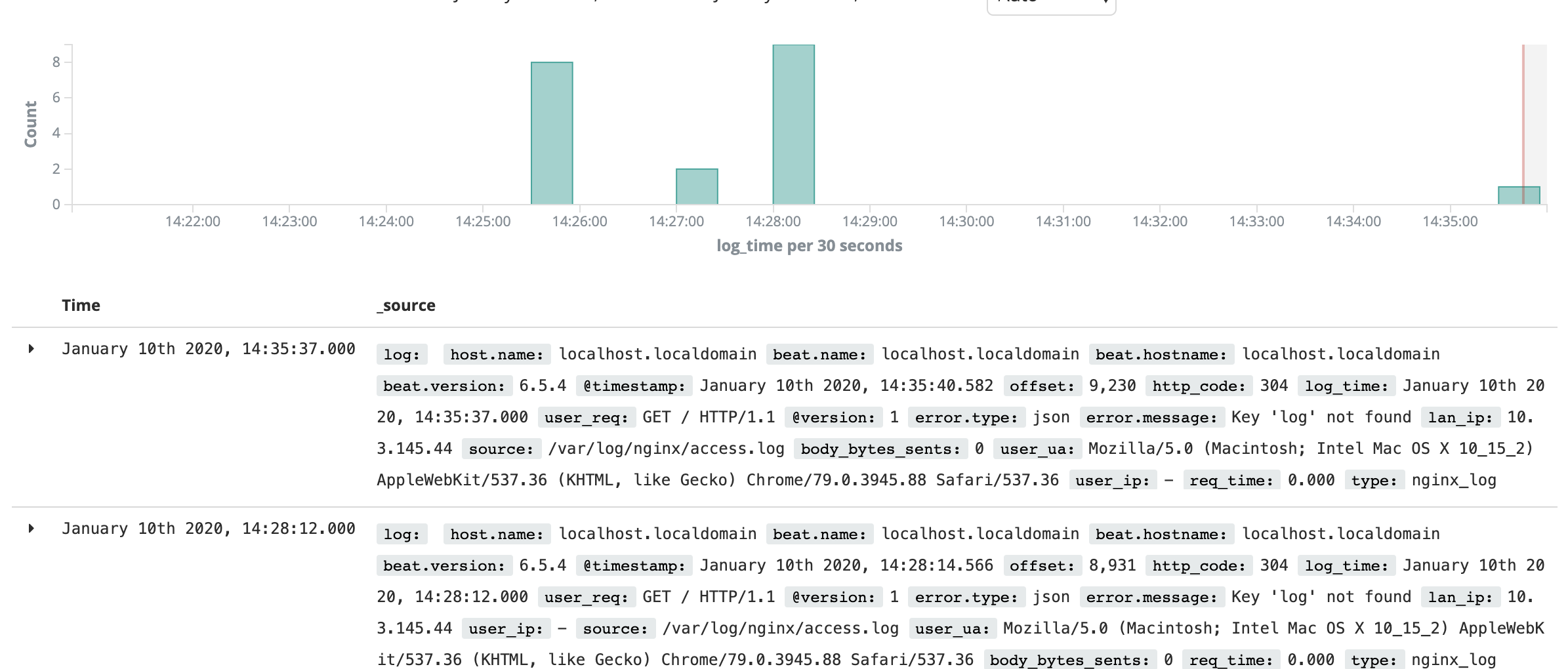
ELK+kafka+filebeat企业内部日志分析系统
1、组件介绍 1、Elasticsearch: 是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布…...

MyBatis-Plus: 简化你的MyBatis应用
MyBatis-Plus: 简化你的MyBatis应用 在Java开发中,MyBatis一直是一个受欢迎的持久层框架,提供了灵活的数据访问方式。然而,MyBatis的使用往往涉及许多样板代码,这在一定程度上增加了开发的复杂性。这里,MyBatis-Plus&…...

在 go 的项目中使用验证器
1:使用validate 包验证: 安装包: go get github.com/go-playground/validator/v10 package controllerimport ("fmt""github.com/gin-gonic/gin""github.com/go-playground/validator/v10""net/http&quo…...

Handler系列-sendMessage和post的区别
sendMessage和post基本一样,区别在于post的Runnable会被赋值给Message的callback,在最后调用dispatchMessage的时候,callback会被触发执行。 1.sendMessage 调用sendMessageDelayed发送消息 public class Handler {public final boolean s…...
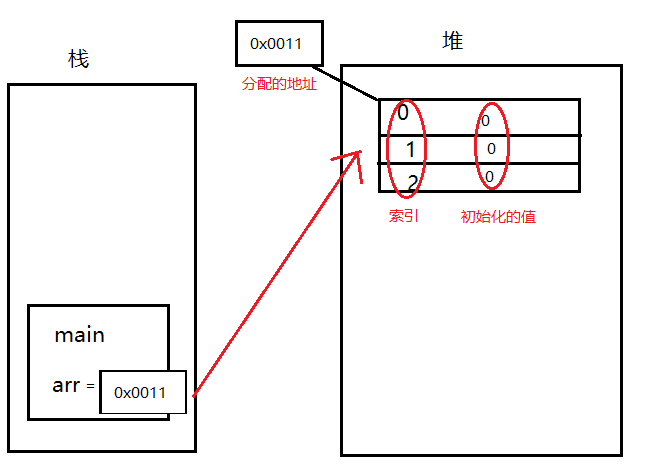
java中 自动装箱与拆箱,基本数据类型,java堆与栈,面向对象与面向过程
文章目录 自动装箱与拆箱基本数据类型与包装类的区别(int 和 Integer 有什么区别)应用场景的区别: 堆和栈的区别重点来说一下堆和栈:那么堆和栈是怎么联系起来的呢? 堆与栈的区别 很明显:延伸:关于Integer…...

C语言第二十八弹--输入一个非负整数,返回组成它的数字之和
C语言求输入一个非负整数,返回组成它的数字之和 方法一、递归法 思路:设计一个初始条件,通过递归获取非负整数的个位,不断接近递归条件即可。 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h>int DigitSum(int n) {…...
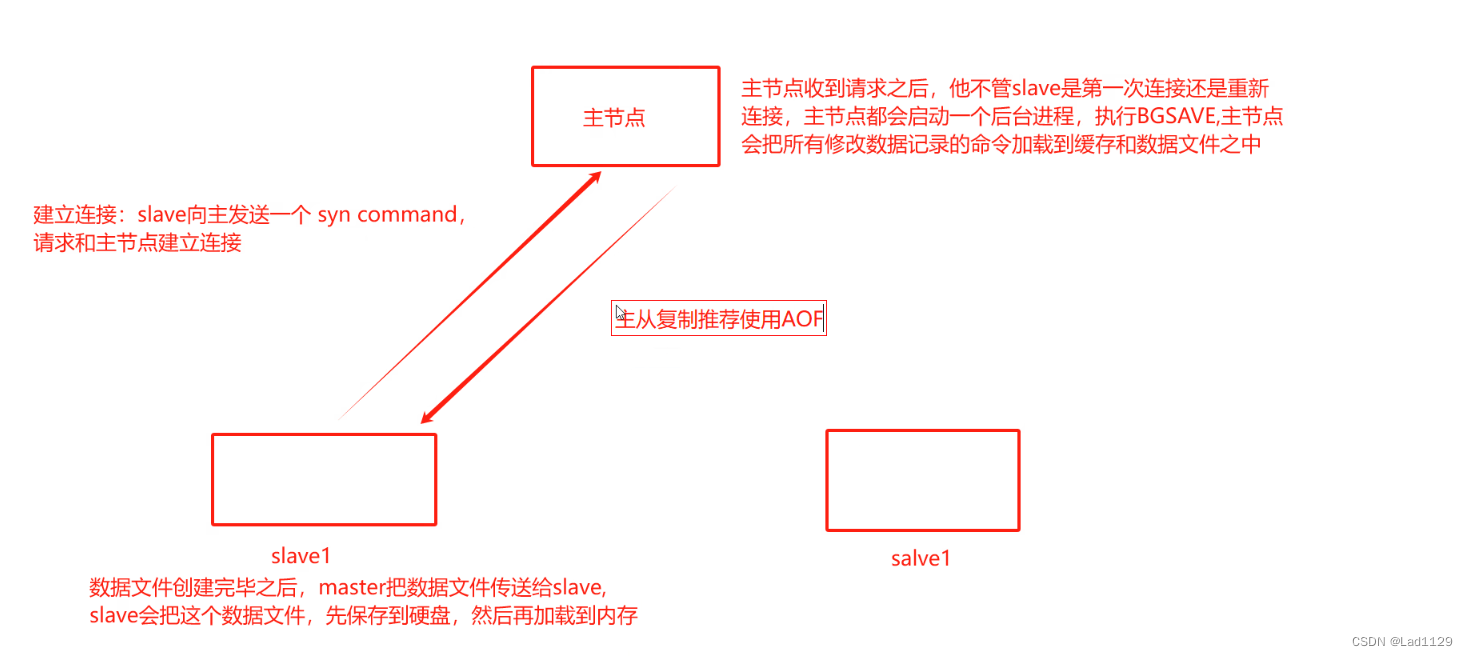
redis---主从复制及哨兵模式(高可用)
主从复制 主从复制:主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础之上实现高可用。 主从负责的工作原理 1、主节点(master) 从节点(slave)组成,数据复制是单向的&a…...

【不同请求方式在springboot中对应的注解】
GET 请求方法:用于获取资源。使用 GetMapping 注解来处理 GET 请求。 示例代码: RestController public class MyController {GetMapping("/resource")public ResponseEntity<String> getResource() {// 处理 GET 请求逻辑} }POST 请求方…...
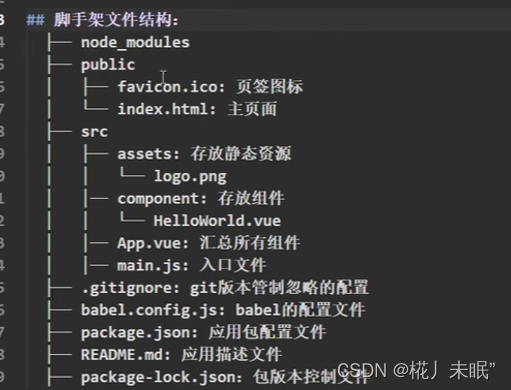
前端入门(三)Vue生命周期、组件技术、事件总线、
文章目录 Vue生命周期Vue 组件化编程 - .vue文件非单文件组件组件的注意点组件嵌套Vue实例对象和VueComponent实例对象Js对象原型与原型链Vue与VueComponent的重要内置关系 应用单文件组件构建 Vue脚手架 - vue.cli项目文件结构refpropsmixin插件scoped样式 Vue生命周期 1、bef…...
消息推送到微信,快速实现WxPusher
文章目录 前言一、平台二、代码总结 前言 我的博客里也有其他方法,测试了下感觉这个方法还是比较实用。 一、平台 先仔细阅读下平台的使用方法。 平台地址请点击 二、代码 import requests text 孪生网络模型已经训练完成,请注意查阅相关信息。 req…...
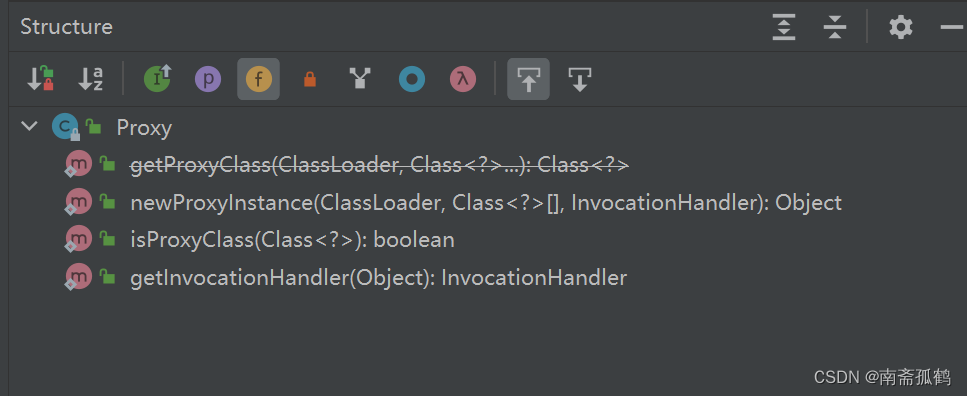
【Spring篇】JDK动态代理
目录 什么是代理? 代理模式 动态代理 Java中常用的代理模式 问题来了,如何动态生成代理类? 动态代理底层实现 什么是代理? 顾名思义,代替某个对象去处理一些问题,谓之代理,那么何为动态&a…...
【从零开始实现意图识别】中文对话意图识别详解
前言 意图识别(Intent Recognition)是自然语言处理(NLP)中的一个重要任务,它旨在确定用户输入的语句中所表达的意图或目的。简单来说,意图识别就是对用户的话语进行语义理解,以便更好地回答用户…...

腾讯云点播小程序端上传 SDK
云点播是专门应对上传大视频文件的。 腾讯云点播文档:https://cloud.tencent.com/document/product/266/18177 这个文档比较简单,实在不行,把demo下载下来,一看就明白了,然后再揉一下挪到自己的项目里。完事。 getSign…...
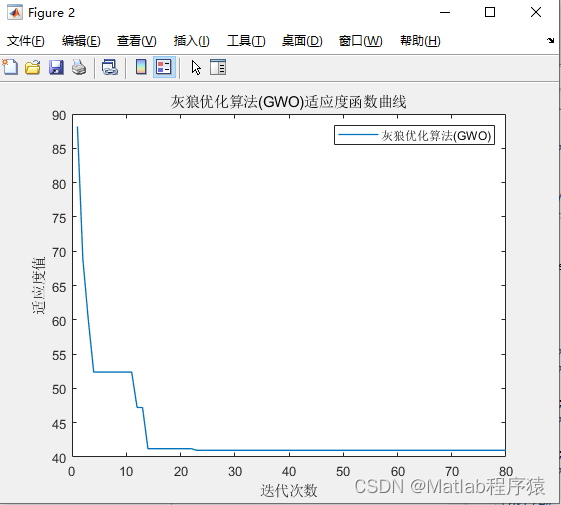
【MATLAB源码-第88期】基于matlab的灰狼优化算法(GWO)的栅格路径规划,输出做短路径图和适应度曲线
操作环境: MATLAB 2022a 1、算法描述 灰狼优化算法(Grey Wolf Optimizer, GWO)是一种模仿灰狼捕食行为的优化算法。灰狼是群居动物,有着严格的社会等级结构。在灰狼群体中,通常有三个等级:首领ÿ…...

electron使用electron-builder macOS windows 打包 签名 更新 上架
0. 前言 0.1 项目工程 看清目录结构,以便您阅读后续内容 0.2 参考资料 (1)macOS开发 证书等配置/打包后导出及上架 https://www.jianshu.com/p/c9c71f2f6eac首先需要为Mac App创建App ID: 填写信息如下—Description为"P…...

autojs项目搭建和入门实践
Auto.js 是一款无需root权限的javascript自动化软件,它可以帮助用户在手机上自动执行各种任务,比如自动填写表单、自动点击按钮、自动切换应用等,并且可以通过图形用户界面来管理和编辑脚本。 软件环境 操作系统:win10 VSCODE&…...
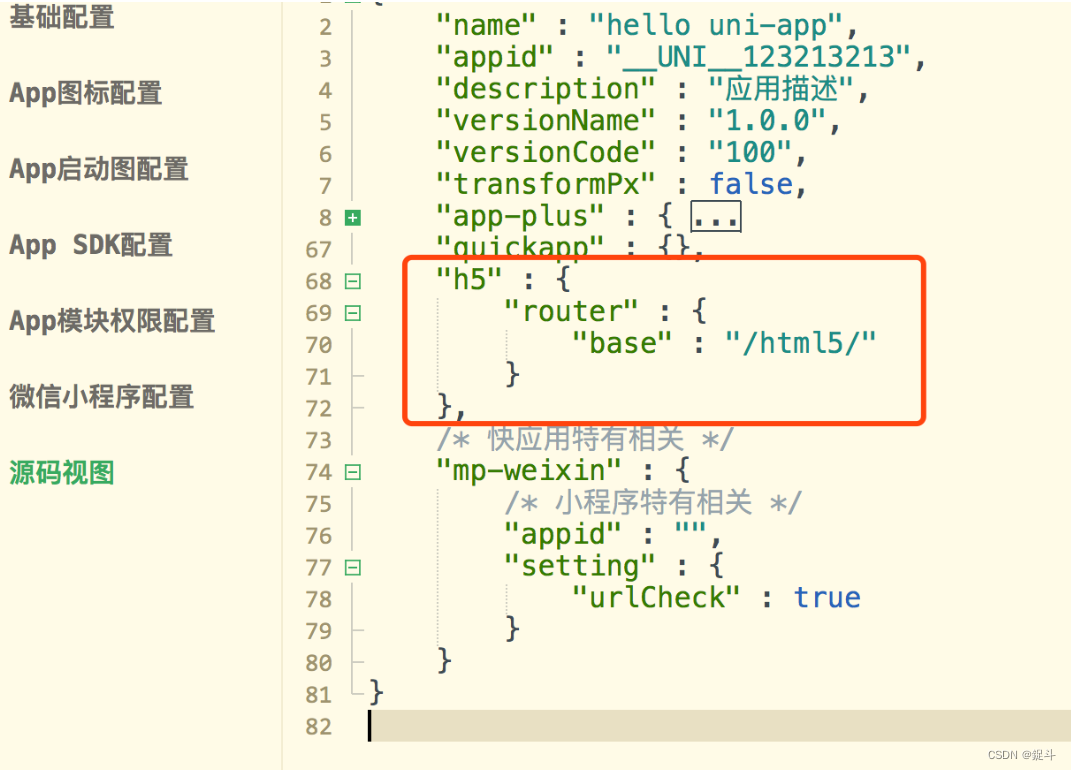
uni-app 跨端开发注意事项
文章目录 前言H5正常但App异常的可能性标题二H5正常但小程序异常的可能性小程序正常但App异常的可能性小程序或App正常,但H5异常的可能性App正常,小程序、H5异常的可能性使用 Vue.js 的注意区别于传统 web 开发的注意H5 开发注意微信小程序开发注意支付宝…...

在 vscode 中的json文件写注释,不报错的解决办法
打开 vscode 的「设置」,搜索:files: associations,然后添加 *.json jsonc最后...
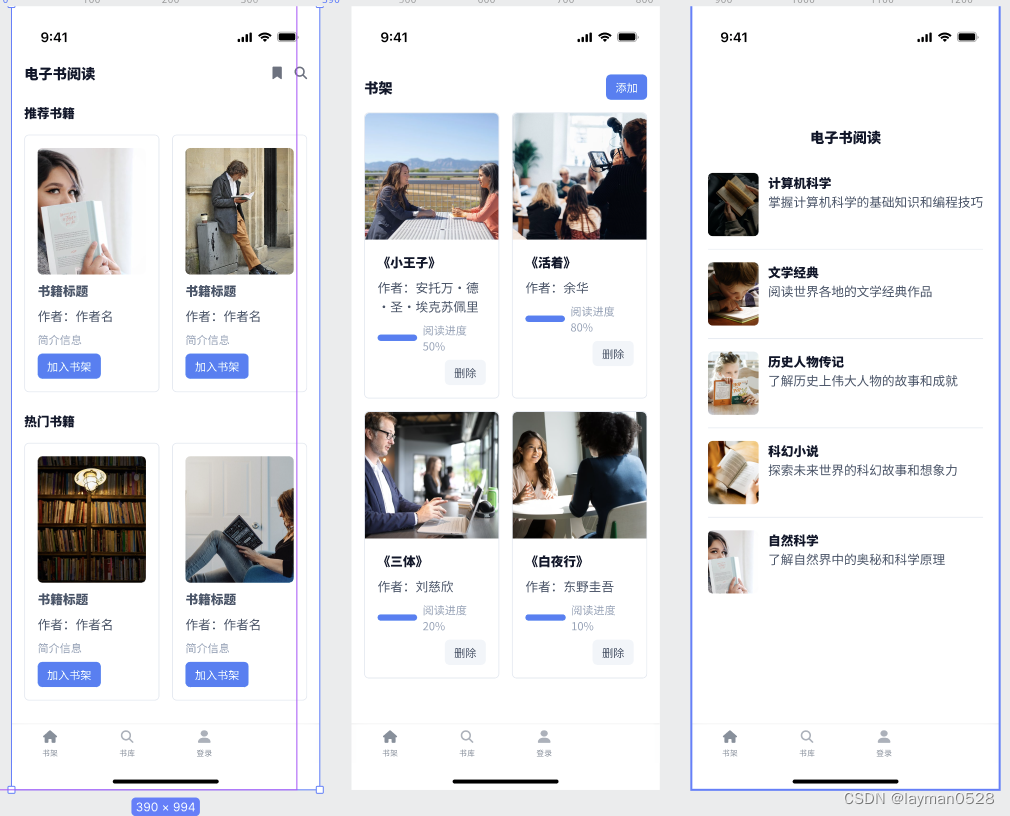
基于uniapp的 电子书小程序——需求整理
前言 想开发一个很简单的 电子书阅读小程序,要怎么做的。下面从功能、数据库设计这一块来说一下。说不一定能从某个角度提供一些思路 开发语言 springcloud uniapp 小程序(vue2)mysql 说明 电子书的主题是电子书,我们在日常…...

TX141F 双极锁存型霍尔位置传感器
产品特点 ● 双极锁存型霍尔效应传感器 ● 宽的工作电压范围: 3.8V~30V ● 集电极开路输出 ● 最大输出灌电流:50mA ● 电源反极性保护 ● 工作温度:-40℃~125℃ ● 封装形式: SIP3L(TO92S) 典型应用 ● 直流无刷电机 ● 位置控制 ● 安全报警装置 ● 转…...

解读鱼类社会选择模型中的秩缺陷问题
在统计学和数据分析中,秩缺陷(rank deficiency)是一个常见的挑战,特别是在处理复杂的交互效应模型时。让我们通过一个实际案例,探讨如何解决在R语言中构建的广义线性混合模型(GLMM)中的秩缺陷问题。 案例背景 假设我们正在研究鱼类的社会选择行为。我们有五个自变量(…...

如何用免费开源在线3D查看器实现跨平台CAD协作与模型分析?
如何用免费开源在线3D查看器实现跨平台CAD协作与模型分析? 【免费下载链接】Online3DViewer A solution to visualize and explore 3D models in your browser. 项目地址: https://gitcode.com/gh_mirrors/on/Online3DViewer 在数字化设计时代,3D…...

如何在Windows 11 LTSC 24H2中一键恢复微软商店:完整安装指南
如何在Windows 11 LTSC 24H2中一键恢复微软商店:完整安装指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正在使用Windows 11 L…...

ConfettiSwiftUI源码解析:揭秘纯SwiftUI实现的动画引擎原理
ConfettiSwiftUI源码解析:揭秘纯SwiftUI实现的动画引擎原理 【免费下载链接】ConfettiSwiftUI SwiftUI Package for Configurable Confetti Animation 🎉 项目地址: https://gitcode.com/gh_mirrors/co/ConfettiSwiftUI ConfettiSwiftUI是一个基于…...

终极指南:Windows Cleaner如何快速解决C盘爆红问题
终极指南:Windows Cleaner如何快速解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也曾经历过这样的焦虑时刻?电脑运…...

Android Studio布局编辑器偷懒技巧:用Guideline和圆形定位快速实现复杂UI
Android Studio布局编辑器进阶技巧:Guideline与圆形定位实战指南 在移动应用界面设计中,非标准布局往往需要开发者投入大量时间计算坐标位置。传统解决方案要么依赖嵌套视图组导致性能损耗,要么需要手动编写复杂的定位逻辑。ConstraintLayout…...

从RockYou.txt字典说起:聊聊密码安全与Kali Linux中的那些经典工具包
从RockYou.txt字典到现代密码安全:技术演进与防御实践 2009年12月,社交应用开发商RockYou遭遇数据泄露事件,超过3200万用户的明文密码被公之于众。这个被称为"RockYou.txt"的密码清单,意外成为了渗透测试领域的标准工具…...

索尼相机完全解锁终极指南:OpenMemories-Tweak让你的设备发挥100%潜能
索尼相机完全解锁终极指南:OpenMemories-Tweak让你的设备发挥100%潜能 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 你是否曾为索尼相机的30分钟录像限制而烦恼…...

从无人机云台到3D打印机:聊聊伺服电机三环控制在不同硬件里的‘脾气’与调参心得
从无人机云台到3D打印机:伺服电机三环控制的硬件适配艺术 当云台在强风中依然保持画面稳定,当3D打印机精确挤出每一丝耗材,当CNC雕刻机在金属表面刻出0.01mm精度的花纹——这些看似毫不相关的硬件奇迹,背后都站着同一个"无名…...