ELK+kafka+filebeat企业内部日志分析系统
1、组件介绍
1、Elasticsearch:
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2、Logstash:
主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
3、Kibana:
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
4、Kafka:
数据缓冲队列。作为消息队列解耦合处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
-
1.发布和订阅记录流,类似于消息队列或企业消息传递系统。
-
2.以容错持久的方式存储记录流。
-
3.处理记录发生的流。
5、Filebeat:
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
1.Packetbeat(搜集网络流量数据)
2.Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。通过从操作系统和服务收集指标,帮助您监控服务器及其托管的服务。)
3.Filebeat(搜集文件数据)
4.Winlogbeat(搜集 Windows 事件日志数据)
2、环境介绍
注:以下为环境所需所有服务器,配置为测试环境配置。
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch/Logstash/kibana | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| Elasticsearch | Es1 | 10.3.145.57 | centos7.5.1804 | 2核3G |
| Elasticsearch | Es2 | 10.3.145.57 | centos7.5.1804 | 2核3G |
| zookeeper/kafka | Kafka1 | 10.3.145.41 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka2 | 10.3.145.42 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
| Filebeat |
3、版本说明
Elasticsearch: 7.13.2
Logstash: 7.13.2
Kibana: 7.13.2
Kafka: 2.11-1
Filebeat: 7.13.2
相应的版本最好下载对应的插件4、搭建架构
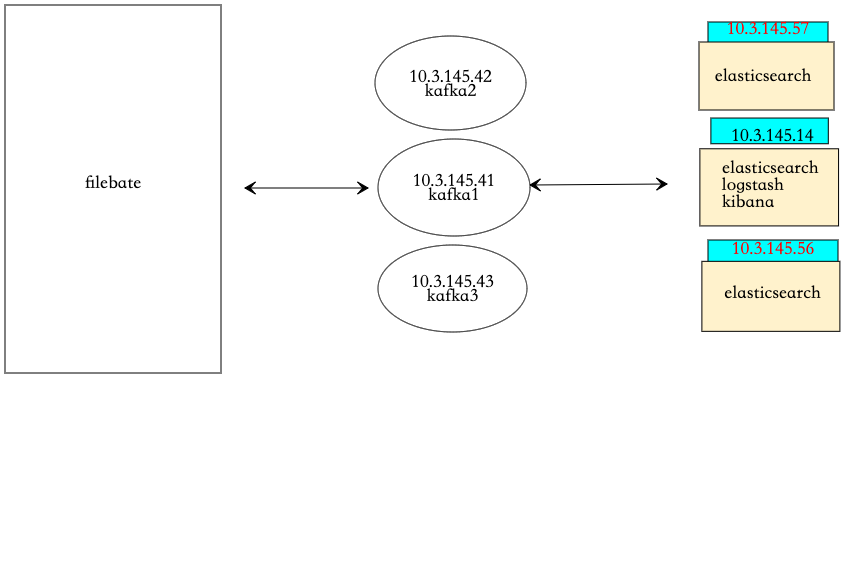
1、日志数据由filebate进行收集,定义日志位置,定义kafka集群,定义要传给kafka的那个topic 2、kafka接受到数据后,端口为9092,等待消费 3、logstash消费kafka中的数据,对数据进行搜集、分析,根据输入条件,过滤条件,输出条件处理后,将数据传输给es集群 4、es集群接受数据后,搜集、分析、存储 5、kibana提供可视化服务,将es中的数据展示。
相关地址:
官网地址:https://www.elastic.co
官网搭建:Starting with the Elasticsearch Platform and its Solutions | Elastic
5、实施部署
1、 Elasticsearch集群部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| Elasticsearch | Es1 | 10.3.145.57 | centos7.5.1804 | 2核3G |
| Elasticsearch | Es2 | 10.3.145.57 | centos7.5.1804 | 2核3G |
-
软件版本:elasticsearch-7.13.2.tar.gz
-
示例节点:10.3.145.14
1、安装配置jdk
可以自行安装,es安装包中自带了jdk
2、安装配置ES
(1)创建运行ES的普通用户
[root@elk ~]# useradd es
[root@elk ~]# echo "******" | passwd --stdin "es"(2)安装配置ES
[root@elk ~]# tar zxvf /usr/local/package/elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local/
[root@elk ~]# vim /usr/local/es/config/elasticsearch.yml
cluster.name: cloud2304-elk
cluster.initial_master_nodes: ["10.36.192.181","10.36.192.182","10.36.192.184"] # 单节点模式这里的地址只填写本机地址
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
# 单节点模式下,将discovery开头的行注释
discovery.seed_hosts: ["10.36.192.182","10.36.192.184"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
# 由于我们的笔记本性能有限,如果要使用单节点多实例的话,添加在原有配置中添加
node.max_local_storage_nodes: 这个配置限制了单节点上可以开启的ES存储实例的个数配置项含义:
cluster.name 集群名称,各节点配成相同的集群名称。 cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置 node.name 节点名称,各节点配置不同。 node.master 指示某个节点是否符合成为主节点的条件。 node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。 path.data 数据存储目录。 path.logs 日志存储目录。 bootstrap.memory_lock 内存锁定,是否禁用交换,测试环境建议改为false。 bootstrap.system_call_filter 系统调用过滤器。 network.host 绑定节点IP。 http.port rest api端口。 discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。 discovery.zen.ping_timeout 节点在发现过程中的等待时间。 discovery.zen.fd.ping_retries 节点发现重试次数。 http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。 http.cors.allow-origin 允许的源地址。
(3)设置JVM堆大小 #7.0默认为4G
[root@elk ~]# sed -i 's/## -Xms4g/-Xms4g/' /usr/local/es/config/jvm.options
[root@elk ~]# sed -i 's/## -Xmx4g/-Xmx4g/' /usr/local/es/config/jvm.options注意: 确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。 如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。 堆内存大小不要超过系统内存的50%
(4)创建ES数据及日志存储目录
[root@elk ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@elk ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)(5)修改安装目录及存储目录权限
[root@elk ~]# chown -R es.es /data/elasticsearch
[root@elk ~]# chown -R es.es /usr/local/es3、系统优化
(1)增加最大文件打开数
永久生效方法:
[root@elk ~]# echo "* soft nofile 65536" >> /etc/security/limits.conf(2)增加最大进程数
[root@elk ~]# echo "* soft nproc 65536" >> /etc/security/limits.conf* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
更多的参数调整可以直接用这个(3)增加最大内存映射数
[root@elk ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0
错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个 解决: 切换到root用户下面:
vim /etc/security/limits.conf
在最后添加
* hard nofile 65536
* hard nofile 65536重新启动elasticsearch,还是无效? 必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。 另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适 启动还会遇到另外一个问题,就是 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行 sysctl -w vm.max_map_count=262144 就可以了
4、启动ES
[root@elk ~]# su - es -c "cd /usr/local/es && nohup bin/elasticsearch &"测试:浏览器访问http://10.3.145.14:9200
5.安装配置head监控插件 (只在第一台es部署)
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Elasticsearch-head-master | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
(1)安装node
[root@elk ~]# wget https://npm.taobao.org/mirrors/node/latest-v10.x/node-v10.0.0-linux-x64.tar.gz
[root@elk ~]# tar -zxf node-v10.0.0-linux-x64.tar.gz –C /usr/local
[root@elk ~]# echo "
NODE_HOME=/usr/local/node-v10.0.0-linux-x64
PATH=\$NODE_HOME/bin:\$PATH
export NODE_HOME PATH
" >>/etc/profile
[root@elk ~]# source /etc/profile
[root@elk ~]# node --version #检查node版本号(2)下载head插件
[root@elk ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@elk ~]# unzip –d /usr/local elasticsearch-head-master.zip(3)安装grunt
[root@elk ~]# cd /usr/local/elasticsearch-head-master
[root@elk ~]# npm install -g grunt-cli
[root@elk ~]# grunt -version #检查grunt版本号(4)修改head源码
[root@elk ~]#vi /usr/local/elasticsearch-head-master/Gruntfile.js +95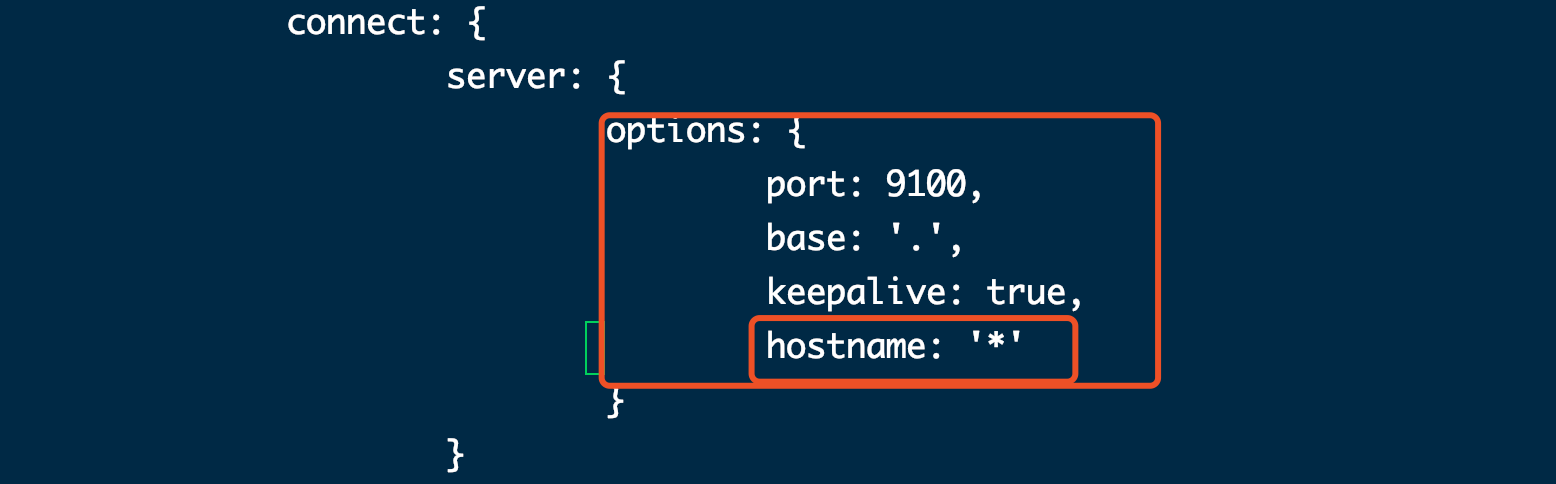
添加hostname,注意在上一行末尾添加逗号,hostname 不需要添加逗号
[root@elk ~]# vim /usr/local/elasticsearch-head-master/_site/app.js +4373
原本是http://localhost:9200 ,如果head和ES不在同一个节点,注意修改成ES的IP地址
(5)下载head必要的文件
[root@elk ~]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@elk ~]# yum -y install bzip2
[root@elk ~]# mkdir /tmp/phantomjs
[root@elk ~]# mv phantomjs-2.1.1-linux-x86_64.tar.bz2 /tmp/phantomjs/
[root@elk ~]# chmod 777 /tmp/phantomjs -R
(6)运行head
[root@elk ~]# cd /usr/local/elasticsearch-head-master/
[root@elk ~]# npm install
[root@elk ~]# nohup grunt server &
[root@elk ~]# ss -tnlp
npm install 执行错误解析:
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! phantomjs-prebuilt@2.1.16 install: `node install.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the phantomjs-prebuilt@2.1.16 install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2021-04-21T09_49_34_207Z-debug.log
解决:
npm install phantomjs-prebuilt@2.1.16 --ignore-scripts # 具体的版本按照上述报错修改
(7)测试
访问http://10.3.145.14:9100
2、 Kibana部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Kibana | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
| 软件版本:nginx-1.14.2、kibana-7.13.2-linux-x86_64.tar.gz |
1. 安装配置Kibana
(1)安装
[root@elk ~]# tar zxf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local/(2)配置
[root@elk ~]# echo '
server.port: 5601
server.host: "10.3.145.14"
elasticsearch.hosts: ["http://10.3.145.14:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
'>>/usr/local/kibana-7.13.2-linux-x86_64/config/kibana.yml配置项含义:
server.port kibana服务端口,默认5601
server.host kibana主机IP地址,默认localhost
elasticsearch.url 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存的searches, visualizations和dashboards,默认.kibana(3)启动
[root@elk ~]# cd /usr/local/kibana-7.13.2-linux-x86_64/
[root@elk ~]# nohup ./bin/kibana &2. 安装配置Nginx反向代理
(1)配置YUM源:
[root@elk ~]# rpm -ivh <http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm>(2)安装:
[root@elk ~]# yum install -y nginx httpd-tools注意:httpd-tools用于生成nginx认证访问的用户密码文件
(3)配置反向代理
[root@elk ~]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes 4;
error_log /var/log/nginx/error.log;
pid /var/run/nginx.pid;
worker_rlimit_nofile 65535;events {worker_connections 65535;use epoll;
}http {include mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;server_names_hash_bucket_size 128;autoindex on;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 120;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;#gzip模块设置gzip on; #开启gzip压缩输出gzip_min_length 1k; #最小压缩文件大小gzip_buffers 4 16k; #压缩缓冲区gzip_http_version 1.0; #压缩版本(默认1.1,前端如果是squid2.5请使用1.0)gzip_comp_level 2; #压缩等级gzip_types text/plain application/x-javascript text/css application/xml; #压缩类型,默认就已经包含textml,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn。gzip_vary on;#开启限制IP连接数的时候需要使用#limit_zone crawler $binary_remote_addr 10m;#tips:#upstream bakend{#定义负载均衡设备的Ip及设备状态}{# ip_hash;# server 127.0.0.1:9090 down;# server 127.0.0.1:8080 weight=2;# server 127.0.0.1:6060;# server 127.0.0.1:7070 backup;#}#在需要使用负载均衡的server中增加 proxy_pass http://bakend/;server {listen 80;server_name 172.16.244.28;#charset koi8-r;# access_log /var/log/nginx/host.access.log main;access_log off;location / { auth_basic "Kibana"; #可以是string或off,任意string表示开启认证,off表示关闭认证。auth_basic_user_file /etc/nginx/passwd.db; #指定存储用户名和密码的认证文件。proxy_pass http://172.16.244.28:5601;proxy_set_header Host $host:5601; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Via "nginx"; }location /status { stub_status on; #开启网站监控状态 access_log /var/log/nginx/kibana_status.log; #监控日志 auth_basic "NginxStatus"; } location /head/{auth_basic "head";auth_basic_user_file /etc/nginx/passwd.db;proxy_pass http://172.16.244.25:9100/;proxy_set_header Host $host:9100;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header Via "nginx";} # redirect server error pages to the static page /50x.htmlerror_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}(4)配置授权用户和密码
[root@elk ~]# htpasswd -cm /etc/nginx/passwd.db kibana
(5)启动nginx[root@elk ~]# systemctl start nginx浏览器访问http://10.3.145.14 刚开始没有任何数据,会提示你创建新的索引。
3、 Kafka部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| zookeeper/kafka | Kafka1 | 10.3.145.41 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka2 | 10.3.145.42 | centos7.5.1804 | 1核2G |
| zookeeper/kafka | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
-
软件版本:jdk-8u121-linux-x64.tar.gz、kafka_2.11-2.0.0.tgz
-
示例节点:10.3.145.41
1.安装配置jdk8
(1)Kafka、Zookeeper(简称:ZK)运行依赖jdk8
[root@kafka1 ~]# tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
[root@kafka1 ~]# echo '
JAVA_HOME=/usr/local/jdk1.8.0_121
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
[root@kafka1 ~]# source /etc/profile2.安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
(1)安装
[root@kafka1 ~]# tar zxvf /usr/local/package/kafka_2.11-2.0.0.tgz -C /usr/local/(2)配置
[root@kafka1 ~]# echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=10.3.145.41:2888:3888 //kafka集群IP:Port .1为id 3处要对应
server.2=10.3.145.42:2888:3888
server.3=10.3.145.43:2888:3888
'> /usr/local/kafka_2.11-2.0.0/config/zookeeper.properties配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
创建data、log目录
[root@kafka1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
创建myid文件
[root@kafka1 ~]# echo 1 > /opt/data/zookeeper/data/myid3.配置Kafka
(1)配置
[root@kafka1 ~]# echo '
broker.id=1
listeners=PLAINTEXT://10.3.145.41:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=10.3.145.41:2181,10.3.145.42:2181,10.3.145.43:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
' >/usr/local/kafka_2.11-2.0.0/config/server.properties配置项含义:
broker.id 每个server需要单独配置broker id,如果不配置系统会自动配置。
listeners 监听地址,格式PLAINTEXT://IP:端口。
num.network.threads 接收和发送网络信息的线程数。
num.io.threads 服务器用于处理请求的线程数,其中可能包括磁盘I/O。
socket.send.buffer.bytes 套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes 套接字服务器将接受的请求的最大大小(防止OOM)
log.dirs 日志文件目录。
num.partitions partition数量。
num.recovery.threads.per.data.dir 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1。
offsets.topic.replication.factor 偏移量话题的复制因子(设置更高保证可用),为了保证有效的复制,偏移话题的复制因子是可配置的,在偏移话题的第一次请求的时候可用的broker的数量至少为复制因子的大小,否则要么话题创建失败,要么复制因子取可用broker的数量和配置复制因子的最小值。
log.retention.hours 日志文件删除之前保留的时间(单位小时),默认168
log.segment.bytes 单个日志文件的大小,默认1073741824
log.retention.check.interval.ms 检查日志段以查看是否可以根据保留策略删除它们的时间间隔。
zookeeper.connect ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间。创建log目录
[root@kafka1 ~]# mkdir -p /opt/data/kafka/logs4、其他kafka节点配置
只需把配置好的安装包直接分发到其他节点,然后修改ZK的myid,Kafka的broker.id和listeners就可以了。
5、启动、验证ZK集群
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &(2)验证
查看ZK配置
下载nmap
[root@kafka1 ~]# yum install nmap
[root@kafka1 ~]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=20
syncLimit=10
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0查看ZK状态
[root@kafka1 ~]# echo stat |nc 127.0.0.1 2181
Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
Clients:/127.0.0.1:51876[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: follower
Node count: 4查看端口
[root@kafka1 ~]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 15002 root 98u IPv4 43385 0t0 TCP *:eforward (LISTEN)6、启动、验证Kafka
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/kafka-server-start.sh config/server.properties &(2)验证
在10.3.145.41上创建topic
[root@kafka1 ~]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic "testtopic".查询10.3.145.41上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.41:2181 --list
testtopic查询10.3.145.42上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.42:2181 --list
testtopic查询10.3.145.43上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 10.3.145.43:2181 --list
testtopic模拟消息生产和消费 发送消息到10.3.145.41
[root@kafka1 ~]# bin/kafka-console-producer.sh --broker-list 10.3.145.41:9092 --topic testtopic
>Hello World!从10.3.145.42接受消息
[root@kafka1 ~]# bin/kafka-console-consumer.sh --bootstrap-server 10.3.145.41:9092 --topic testtopic --from-beginning
Hello World!7、监控 Kafka Manager
Kafka-manager 是 Yahoo 公司开源的集群管理工具。
可以在 Github 上下载安装:GitHub - yahoo/CMAK: CMAK is a tool for managing Apache Kafka clusters
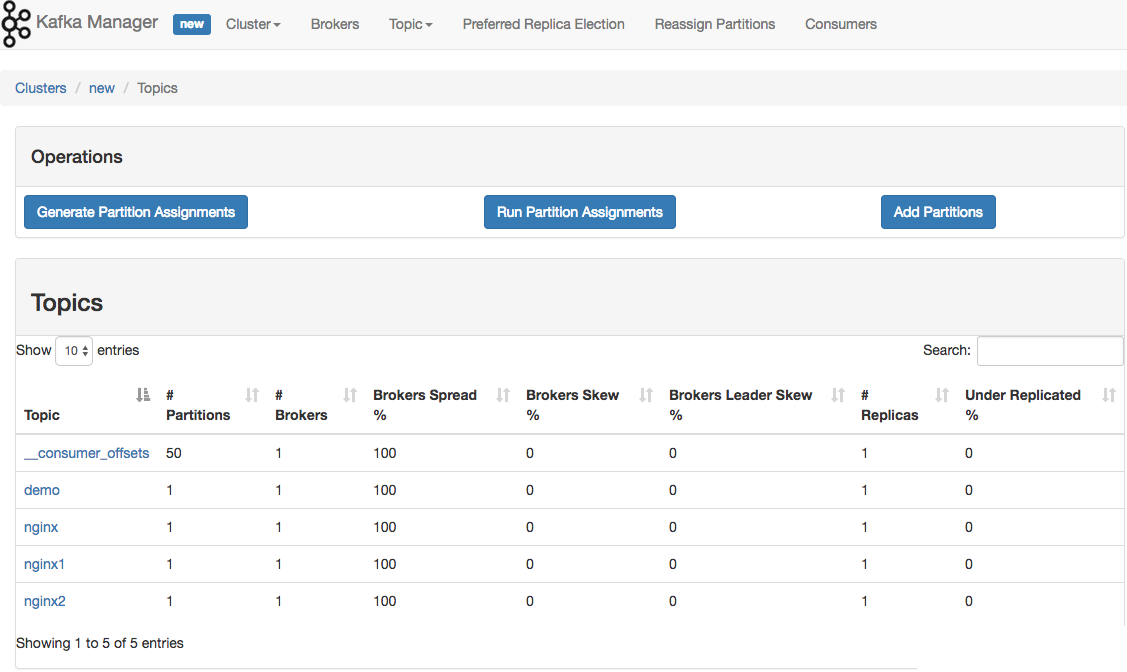
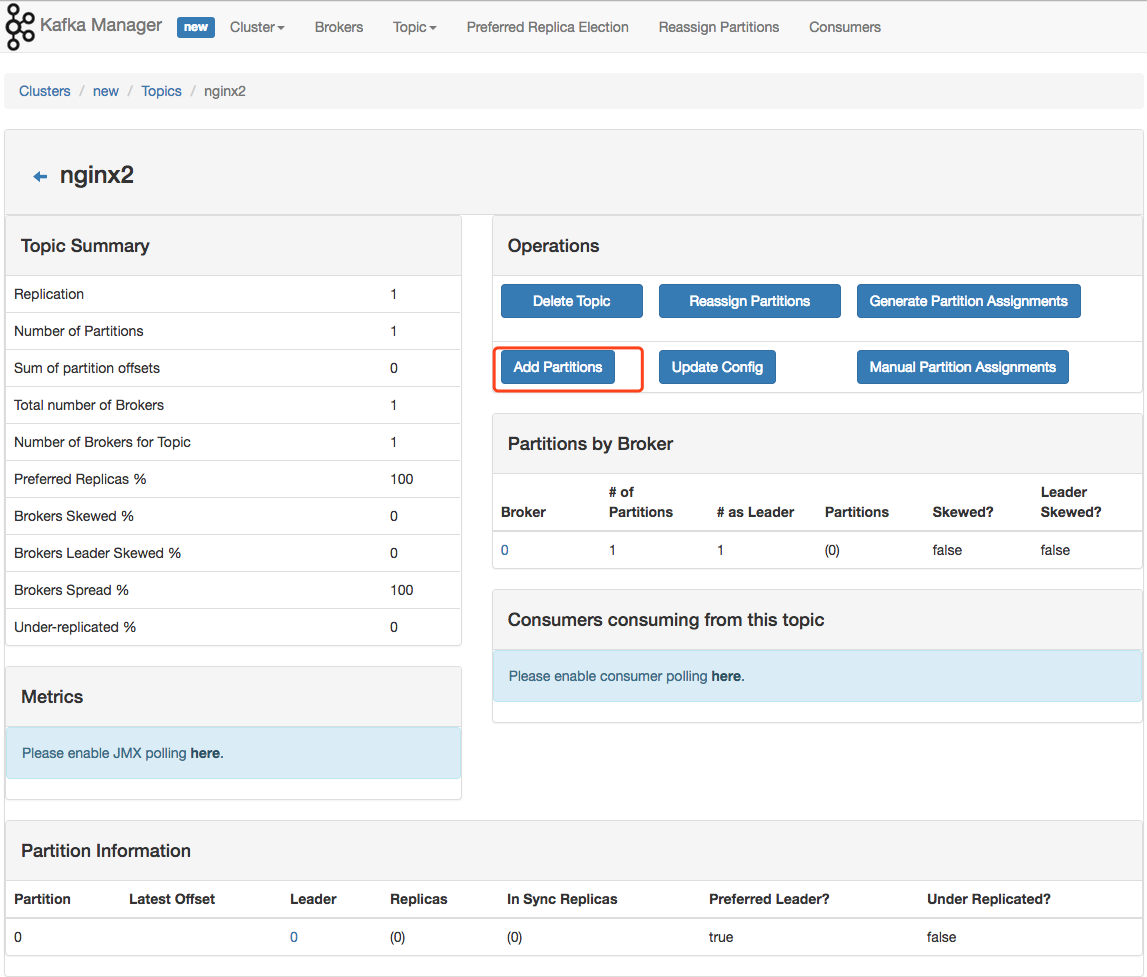
如果遇到 Kafka 消费不及时的话,可以通过到具体 cluster 页面上,增加 partition。Kafka 通过 partition 分区来提高并发消费速度
4、 Logstash部署
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| Logstash | Elk | 10.3.145.14 | centos7.5.1804 | 2核4G |
-
软件版本:logstash-7.13.2.tar.gz
1.安装配置Logstash
Logstash运行同样依赖jdk,本次为节省资源,故将Logstash安装在了10.3.145.14节点。
(1)安装
[root@elk ~]# tar zxf /usr/local/package/logstash-7.13.2.tar.gz -C /usr/local/(2)测试文件
标准输入=>标准输出
1、启动logstash
2、logstash启动后,直接进行数据输入
3、logstash处理后,直接进行返回
input {stdin {}
}
output {stdout {codec => rubydebug}
}标准输入=>标准输出及es集群
1、启动logstash
2、启动后直接在终端输入数据
3、数据会由logstash处理后返回并存储到es集群中
input {stdin {}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}端口输入=>字段匹配=>标准输出及es集群
1、由tcp 的8888端口将日志发送到logstash
2、数据被grok进行正则匹配处理
3、处理后,数据将被打印到终端并存储到es
input {tcp {port => 8888}
}
filter {grok {match => {"message" => "%{DATA:key} %{NUMBER:value:int}"} }
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-debug-%{+YYYY-MM-dd}'}
}
# yum install -y nc
# free -m |awk 'NF==2{print $1,$3}' |nc logstash_ip 8888文件输入=>字段匹配及修改时间格式修改=>es集群
1、直接将本地的日志数据拉去到logstash当中
2、将日志进行处理后存储到es
input {file {type => "nginx-log"path => "/var/log/nginx/error.log"start_position => "beginning" # 此参数表示在第一次读取日志时从头读取# sincedb_path => "自定义位置" # 此参数记录了读取日志的位置,默认在 data/plugins/inputs/file/.sincedb*}
}
filter {grok {match => { "message" => '%{DATESTAMP:date} [%{WORD:level}] %{DATA:msg} client: %{IPV4:cip},%{DATA}"%{DATA:url}"%{DATA}"%{IPV4:host}"'} } date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] }
}output {if [type] == "nginx-log" {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}filebeat => 字段匹配 => 标准输出及es
input {beats {port => 5000}
}
filter {grok {match => {"message" => "%{IPV4:cip}"} }
}
output {elasticsearch {hosts => ["192.168.249.139:9200","192.168.249.149:9200","192.168.249.159:9200"]index => 'test-%{+YYYY-MM-dd}'}stdout { codec => rubydebug }
}(3)配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
[root@elk ~]# mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/input.conf
input {
kafka {type => "audit_log"codec => "json"topics => "nginx"decorate_events => truebootstrap_servers => "10.3.145.41:9092, 10.3.145.42:9092, 10.3.145.43:9092"}
}[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/filter.conf
filter {json { # 如果日志原格式是json的,需要用json插件处理source => "message"target => "nginx" # 组名}
}[root@elk ~]# vim /usr/local/logstash-7.13.2/etc/conf.d/output.conf
output {if [type] == "audit_log" {elasticsearch {hosts => ["10.3.145.14","10.3.145.56","10.3.145.57"]index => 'logstash-audit_log-%{+YYYY-MM-dd}'}}}(3)启动
[root@elk ~]# cd /usr/local/logstash-7.13.2
[root@elk ~]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &5、Filebeat 部署
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。
后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,可以通过 Salt 来推送并安装配置。
-
服务器
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| filebeat | Kafka3 | 10.3.145.43 | centos7.5.1804 | 1核2G |
-
软件版本 filebeat-7.13.2-x86_64.rpm
(1)下载
[root@kafka3 ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-x86_64.rpm(2)解压
[root@kafka3 ~]# yum install -y filebeat-7.13.2-x86_64.rpm(3)修改配置
修改 Filebeat 配置,支持收集本地目录日志,并输出日志到 Kafka 集群中
[r
oot@kafka3 ~]# vim filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.log
output.logstash:hosts: ["192.168.52.134:5000"]output.kafka: hosts: ["10.3.145.41:9092","10.3.145.42:9092","10.3.145.43:9092"]topic: 'nginx'# 注意,如果需要重新读取,请删除/data/registry目录
Filebeat 6.0 之后一些配置参数变动比较大,比如 document_type 就不支持,需要用 fields 来代替等等。
(4)启动
[root@kafka3 ~]# ./filebeat -e -c filebeat.yml(5)配置nginx
因为日志格式的切割需要json格式,kibana中会报错 error decoding json,所以在这里我们将nginx的日志格式修改为json格式。
[root@kafka3 ~]# vim /etc/nginx/nginx.conf
# log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';log_format main '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sents":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';access_log /var/log/nginx/access.log main;
相关文章:
ELK+kafka+filebeat企业内部日志分析系统
1、组件介绍 1、Elasticsearch: 是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布…...

MyBatis-Plus: 简化你的MyBatis应用
MyBatis-Plus: 简化你的MyBatis应用 在Java开发中,MyBatis一直是一个受欢迎的持久层框架,提供了灵活的数据访问方式。然而,MyBatis的使用往往涉及许多样板代码,这在一定程度上增加了开发的复杂性。这里,MyBatis-Plus&…...

在 go 的项目中使用验证器
1:使用validate 包验证: 安装包: go get github.com/go-playground/validator/v10 package controllerimport ("fmt""github.com/gin-gonic/gin""github.com/go-playground/validator/v10""net/http&quo…...

Handler系列-sendMessage和post的区别
sendMessage和post基本一样,区别在于post的Runnable会被赋值给Message的callback,在最后调用dispatchMessage的时候,callback会被触发执行。 1.sendMessage 调用sendMessageDelayed发送消息 public class Handler {public final boolean s…...
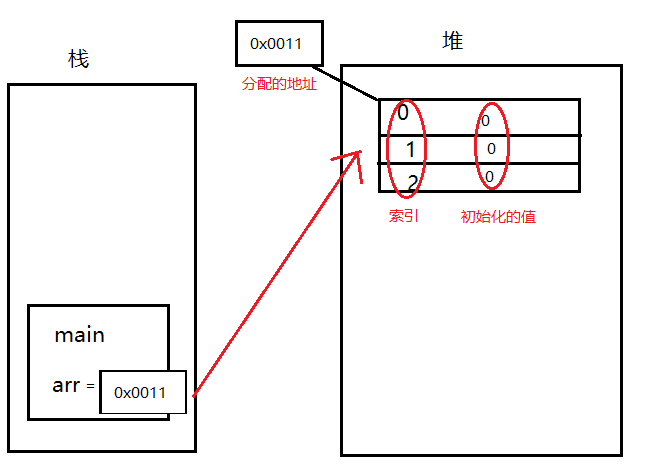
java中 自动装箱与拆箱,基本数据类型,java堆与栈,面向对象与面向过程
文章目录 自动装箱与拆箱基本数据类型与包装类的区别(int 和 Integer 有什么区别)应用场景的区别: 堆和栈的区别重点来说一下堆和栈:那么堆和栈是怎么联系起来的呢? 堆与栈的区别 很明显:延伸:关于Integer…...

C语言第二十八弹--输入一个非负整数,返回组成它的数字之和
C语言求输入一个非负整数,返回组成它的数字之和 方法一、递归法 思路:设计一个初始条件,通过递归获取非负整数的个位,不断接近递归条件即可。 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h>int DigitSum(int n) {…...
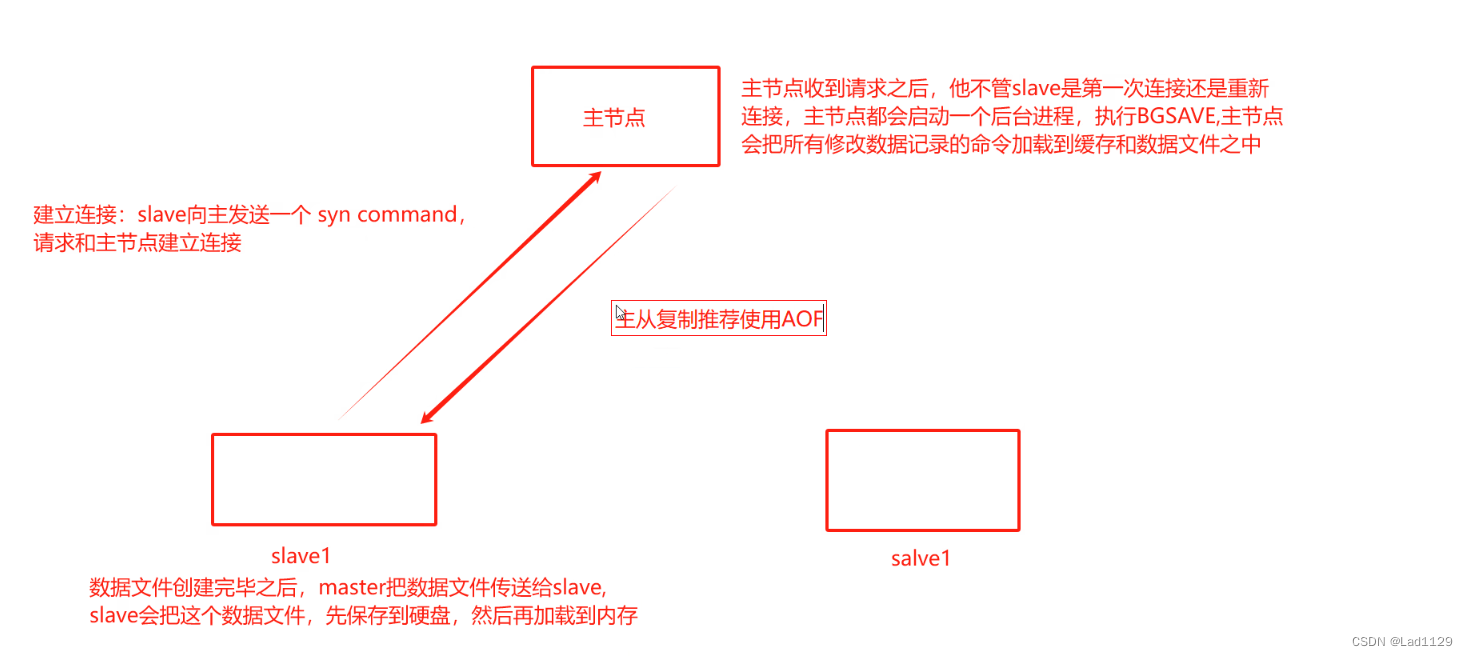
redis---主从复制及哨兵模式(高可用)
主从复制 主从复制:主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础之上实现高可用。 主从负责的工作原理 1、主节点(master) 从节点(slave)组成,数据复制是单向的&a…...

【不同请求方式在springboot中对应的注解】
GET 请求方法:用于获取资源。使用 GetMapping 注解来处理 GET 请求。 示例代码: RestController public class MyController {GetMapping("/resource")public ResponseEntity<String> getResource() {// 处理 GET 请求逻辑} }POST 请求方…...
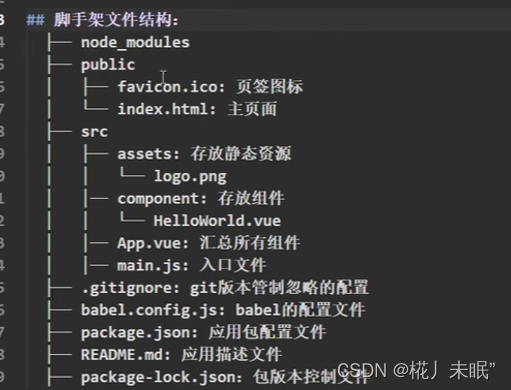
前端入门(三)Vue生命周期、组件技术、事件总线、
文章目录 Vue生命周期Vue 组件化编程 - .vue文件非单文件组件组件的注意点组件嵌套Vue实例对象和VueComponent实例对象Js对象原型与原型链Vue与VueComponent的重要内置关系 应用单文件组件构建 Vue脚手架 - vue.cli项目文件结构refpropsmixin插件scoped样式 Vue生命周期 1、bef…...
消息推送到微信,快速实现WxPusher
文章目录 前言一、平台二、代码总结 前言 我的博客里也有其他方法,测试了下感觉这个方法还是比较实用。 一、平台 先仔细阅读下平台的使用方法。 平台地址请点击 二、代码 import requests text 孪生网络模型已经训练完成,请注意查阅相关信息。 req…...
【Spring篇】JDK动态代理
目录 什么是代理? 代理模式 动态代理 Java中常用的代理模式 问题来了,如何动态生成代理类? 动态代理底层实现 什么是代理? 顾名思义,代替某个对象去处理一些问题,谓之代理,那么何为动态&a…...
【从零开始实现意图识别】中文对话意图识别详解
前言 意图识别(Intent Recognition)是自然语言处理(NLP)中的一个重要任务,它旨在确定用户输入的语句中所表达的意图或目的。简单来说,意图识别就是对用户的话语进行语义理解,以便更好地回答用户…...

腾讯云点播小程序端上传 SDK
云点播是专门应对上传大视频文件的。 腾讯云点播文档:https://cloud.tencent.com/document/product/266/18177 这个文档比较简单,实在不行,把demo下载下来,一看就明白了,然后再揉一下挪到自己的项目里。完事。 getSign…...
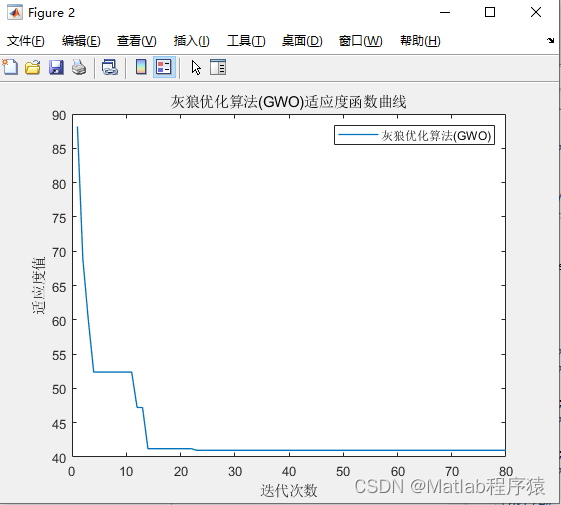
【MATLAB源码-第88期】基于matlab的灰狼优化算法(GWO)的栅格路径规划,输出做短路径图和适应度曲线
操作环境: MATLAB 2022a 1、算法描述 灰狼优化算法(Grey Wolf Optimizer, GWO)是一种模仿灰狼捕食行为的优化算法。灰狼是群居动物,有着严格的社会等级结构。在灰狼群体中,通常有三个等级:首领ÿ…...

electron使用electron-builder macOS windows 打包 签名 更新 上架
0. 前言 0.1 项目工程 看清目录结构,以便您阅读后续内容 0.2 参考资料 (1)macOS开发 证书等配置/打包后导出及上架 https://www.jianshu.com/p/c9c71f2f6eac首先需要为Mac App创建App ID: 填写信息如下—Description为"P…...

autojs项目搭建和入门实践
Auto.js 是一款无需root权限的javascript自动化软件,它可以帮助用户在手机上自动执行各种任务,比如自动填写表单、自动点击按钮、自动切换应用等,并且可以通过图形用户界面来管理和编辑脚本。 软件环境 操作系统:win10 VSCODE&…...
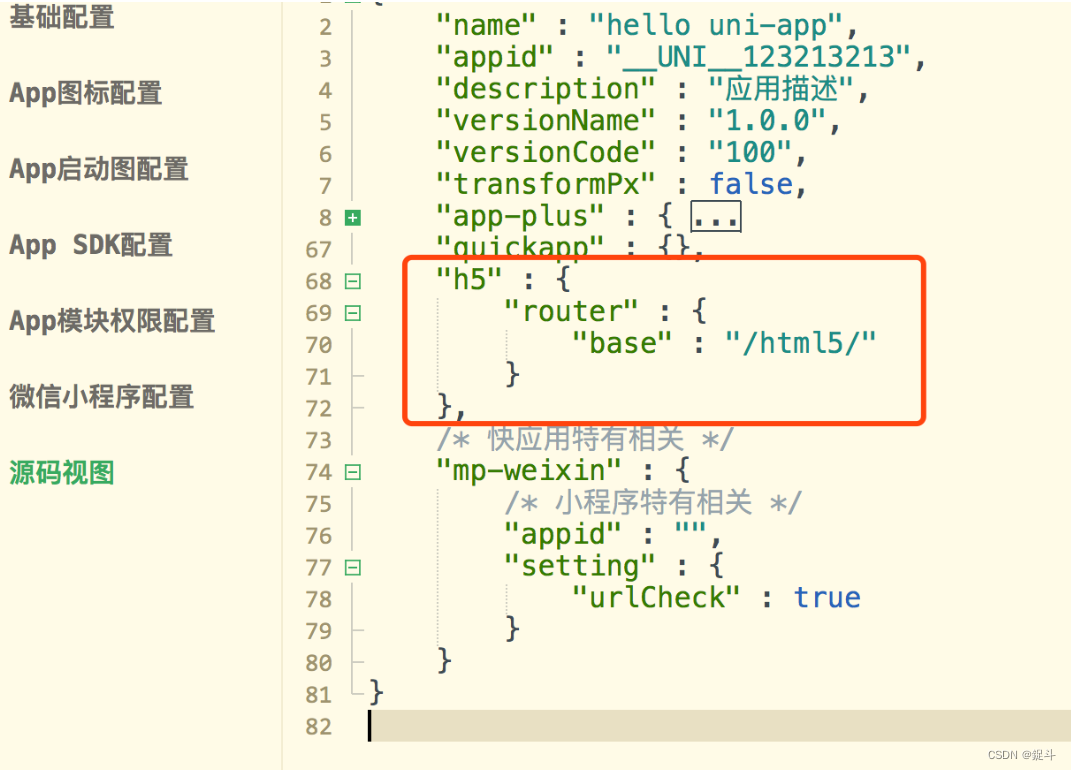
uni-app 跨端开发注意事项
文章目录 前言H5正常但App异常的可能性标题二H5正常但小程序异常的可能性小程序正常但App异常的可能性小程序或App正常,但H5异常的可能性App正常,小程序、H5异常的可能性使用 Vue.js 的注意区别于传统 web 开发的注意H5 开发注意微信小程序开发注意支付宝…...

在 vscode 中的json文件写注释,不报错的解决办法
打开 vscode 的「设置」,搜索:files: associations,然后添加 *.json jsonc最后...
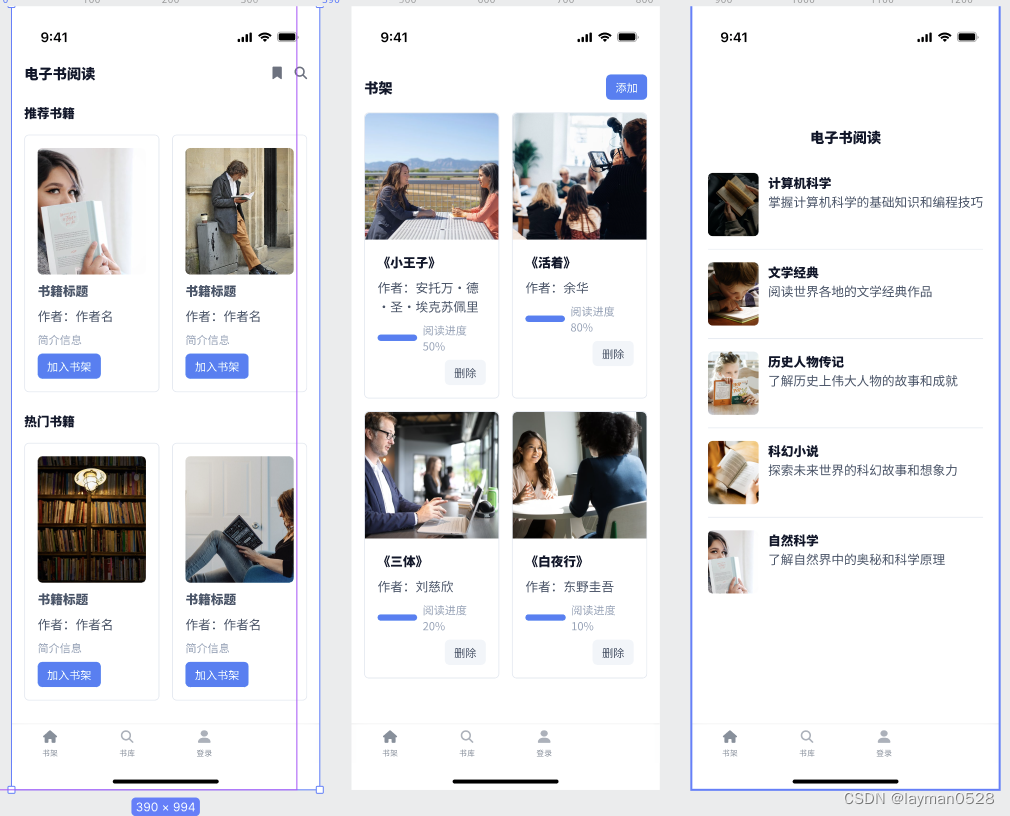
基于uniapp的 电子书小程序——需求整理
前言 想开发一个很简单的 电子书阅读小程序,要怎么做的。下面从功能、数据库设计这一块来说一下。说不一定能从某个角度提供一些思路 开发语言 springcloud uniapp 小程序(vue2)mysql 说明 电子书的主题是电子书,我们在日常…...

Hutool HttpRequest 首次请求正常 第二次被系统拦截
Hutool HttpRequest 首次请求正常 第二次被系统拦截 功能描述异常现象错误代码 异常排查问题跟踪问题总结处理方案最终修改后的代码 功能描述 需要请求第三方某个接口,获取接口中的数据。 异常现象 使用main 方法 通过Hutool 工具类发出请求,获取数据…...

WarcraftHelper终极指南:5分钟解决魔兽争霸3现代兼容性问题
WarcraftHelper终极指南:5分钟解决魔兽争霸3现代兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上的…...

500kg机械臂出口包装:为什么我们最终放弃了木箱?——重型纸箱的承重结构与跌落实测
标题: 500kg机械臂出口包装:为什么我们最终放弃了木箱?——重型纸箱的承重结构与跌落实测一位机械臂厂长曾对我说:“海运集装箱湿度最高能到95%,纸箱直接变软脚虾”,这是他的原话。本文记录了我为一个出口机…...

深度学习损失函数:原理、选择与优化实践
1. 深度学习中损失函数的本质作用在训练神经网络时,损失函数就像一位严格的教练,不断告诉模型当前的表现离完美还有多远。这个看似简单的数学公式,实际上承担着三个关键使命:量化误差:将模型预测值与真实值之间的差异转…...

2032 年全球微型直流电动机市场将达 226.5 亿美元
微型直流电动机作为现代工业与智能终端的核心动力部件,凭借高效、小型化、低能耗等优势,正深度渗透汽车、家电、电子信息等关键领域。在全球智能化浪潮与下游需求扩容的双重驱动下,微型直流电动机行业迎来高速增长期,市场前景广阔…...
即将启幕)
赋能核心力量,共建全球共识 | Alpha大学精英领导人内训营(第二期)即将启幕
随着 AlphaAI 全球战略的深入推进,人才与领导力成为了推动生态进化的核心动能。2026年5月5日至6日,备受瞩目的Alpha大学精英领导人内训营(第二期)将正式拉开帷幕。一、战略对齐,点亮“万家灯火”在 AlphaAI 的全球蓝图…...

别再手动复制粘贴了!用Python-docx+Matplotlib,5分钟搞定周报/月报自动化
告别重复劳动:Python自动化周报生成实战指南 每周五下午,当同事们开始整理数据、复制粘贴图表时,小李已经收拾好背包准备下班。他的秘密武器是一套用Python编写的自动化报告系统,只需5分钟就能生成图文并茂的周报。本文将揭秘这套…...
)
动手实践:用Python仿真一个简易的捷联惯导系统(SINS)
动手实践:用Python仿真一个简易的捷联惯导系统(SINS) 在自动驾驶、无人机和机器人领域,惯性导航系统(INS)扮演着至关重要的角色。它不依赖外部信号,仅通过内部传感器就能实现连续定位࿰…...

将Kali_Linux系统安装到U盘—随身携带_即插即用
将Kali Linux系统安装到U盘—随身携带/即插即用 一、准备工作 1、系统ISO:Get Kali | Kali Linux 版本说明: everything:几乎包含kali系统中全部的渗透测试和安全的软件,大小约12G Kali 2023.4:这个就是发行的稳定版本…...

Yakit WebFuzzer序列实战:巧用数据提取器和Nuclei DSL函数,动态处理上传路径
Yakit WebFuzzer序列实战:动态路径处理与Nuclei DSL高阶应用 在渗透测试中,文件上传漏洞的验证往往需要处理服务器返回的动态路径。这些路径可能包含相对路径符号(如../upload/)、时间戳或随机字符串,直接使用这些路径…...

机器学习数据准备:从清洗到特征工程的完整指南
1. 数据准备:机器学习项目的隐形基石第一次接触机器学习时,我和大多数人一样,迫不及待地想要尝试各种炫酷的算法。但很快我就发现,无论选择多么先进的模型,如果输入的是垃圾数据,输出的也只能是垃圾结果。数…...