论文阅读 Forecasting at Scale (二)
最近在看时间序列的文章,回顾下经典
论文地址
项目地址
Forecasting at Scale
- 3.2、季节性
- 3.3、假日和活动事件
- 3.4、模型拟合
- 3.5、分析师参与的循环建模
- 4、自动化预测评估
- 4.1、使用基线预测
- 4.2、建模预测准确性
- 4.3、模拟历史预测
- 4.4、识别大的预测误差
- 5、结论
- 6、致谢
3.2、季节性
企业时间序列通常由于它们所代表的人类行为而具有多期季节性。例如,5天的工作周可以在时间序列上产生每周重复的效应,而假期安排和学校放假可以产生每年重复的效应。为了拟合和预测这些效应,我们必须指定季节性模型,这些模型是关于 t 的周期函数。
我们依靠傅立叶级数提供周期效应的灵活模型(Harvey & Shephard 1993)。让 P 表示我们期望时间序列具有的常规周期(例如,对于年度数据,P = 365.25;对于每周数据,当我们将时间变量按天计算时,P = 7)。我们可以用傅立叶级数来近似任意平滑的季节效应
s ( t ) = ∑ n = 1 N ( a n c o s ( 2 π n t P ) + b n s i n ( 2 π n t P ) ) s(t)= \sum_{n=1}^{N}(a_ncos(\frac{ 2πnt}{P})+b_nsin(\frac{ 2πnt}{P})) s(t)=∑n=1N(ancos(P2πnt)+bnsin(P2πnt))
标准傅立叶级数。拟合季节性需要估计2N个参数 β = [ a 1 , b 1 , . . . , a N , b N ] T β=[a_1,b_1,...,a_N,b_N]^{\texttt{T}} β=[a1,b1,...,aN,bN]T。这是通过为历史和未来数据中的每个 t 值构建一个季节性向量矩阵来完成的,例如,对于每年的季节性和 N = 10。
X ( t ) = [ c o s ( 2 π ( 1 ) t 356.25 ) , . . . , s i n ( 2 π ( 10 ) t 356.25 ) ] X(t)=\begin{bmatrix} cos(\frac{ 2π(1)t}{356.25}), ...,sin(\frac{ 2π(10)t}{356.25}) \end{bmatrix} X(t)=[cos(356.252π(1)t),...,sin(356.252π(10)t)] (5)
季节性成分是
s ( t ) = X ( t ) β s(t)=X(t)β s(t)=X(t)β (6)
在我们的生成模型中,我们采用 β N o r m a l ( 0 , σ 2 ) β~Normal(0, σ^2) β Normal(0,σ2)对季节性施加平滑先验。
将序列截断到 N,对季节性施加了低通滤波器,因此增加 N 可以适应更快变化的季节模式,尽管存在过度拟合的风险。对于年度和每周季节性,我们发现分别使用 N = 10 和 N = 3 对大多数问题效果良好。选择这些参数可以使用诸如 AIC 的模型选择过程进行自动化。
3.3、假日和活动事件
假期和事件对许多企业时间序列提供了大而有些可预测的冲击,通常不遵循周期模式,因此它们的影响无法很好地通过平滑周期来建模。例如,美国的感恩节是在11月的第四个星期四举行的。美国最大的电视节目之一——超级碗则在1月或2月的某个星期日举行,难以编程声明。世界上许多国家有根据农历计算的重要节日。特定假期对时间序列的影响通常每年相似,因此将其纳入预测非常重要。
我们允许分析师提供一个自定义的过去和未来事件列表,由该事件或假期的唯一名称识别,如表1所示。我们包括一个国家列,以便除全球节日外,保留特定于国家的节日列表。对于给定的预测问题,我们使用全球节日集合和特定国家节日集合的并集。
将这个假期列表纳入模型中是基于假设假期效应是独立的。对于每个假期 i,设 D i D_i Di 为该假期的过去和未来日期集合。我们添加一个指示函数,表示时间 t 是否在假期 i 期间,并为每个假期分配一个参数 κ i κ_i κi,该参数是相应预测变化。这与季节性类似,通过生成回归器矩阵来完成。
Z ( t ) = [ 1 ( t ∈ D 1 ) , . . . , 1 ( t ∈ D L ) ] Z(t) = [1(t \in D_1),..., 1(t \in D_L)] Z(t)=[1(t∈D1),...,1(t∈DL)]
并采用
h ( t ) = Z ( t ) κ h(t)=Z(t)κ h(t)=Z(t)κ (7)
与季节性一样,我们使用先验 κ ∼ N o r m a l ( 0 , v 2 ) κ \sim Normal(0,v^2) κ∼Normal(0,v2)。
通常,包括特定假期前后一段时间窗口的效应非常重要,比如感恩节周末。为了解决这个问题,我们为假期周围的日期添加额外的参数,本质上将假期周围的每一天都视为一个假期。
3.4、模型拟合
当将每个观测的季节性和假期特征结合到矩阵X中,并将变化点指示符a(t)结合到矩阵A中时,模型(1)可以在几行Stan代码(Carpenter et al. 2017)中表示,如下所示。对于模型拟合,我们使用Stan的L-BFGS算法找到最大后验估计,但也可以进行完整的后验推断,将模型参数的不确定性包括在预测的不确定性中。

图4显示了Prophet模型对图3中Facebook事件时间序列的预测。这些预测与图3中相同的三个日期一样,仅使用该日期之前的数据进行预测。Prophet模型能够预测每周和每年的季节性,与图3中的基准模型不同,它不会对第一年的假期下降作出过度反应。在第一个预测中,Prophet模型在只有一年数据的情况下稍微过拟合了每年的季节性。在第三个预测中,模型还没有学习到趋势已经发生变化。图5显示了一个包含最近三个月数据的预测展示了趋势的变化(虚线)。
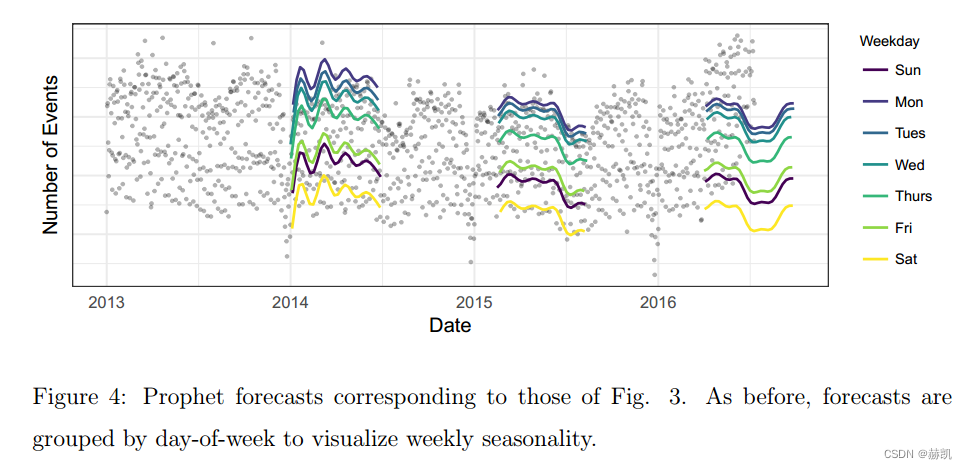
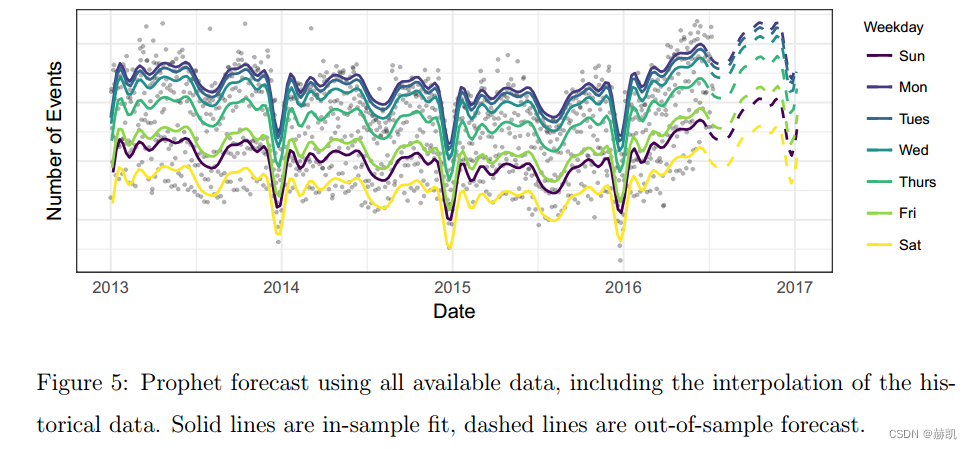
可分解模型的一个重要优势是它允许我们分别观察预测的每个组成部分。图6显示了与图4中最后一个预测相对应的趋势、每周季节性和每年季节性组件。除了产生预测之外,这为分析师提供了洞察他们的预测问题的有用工具。
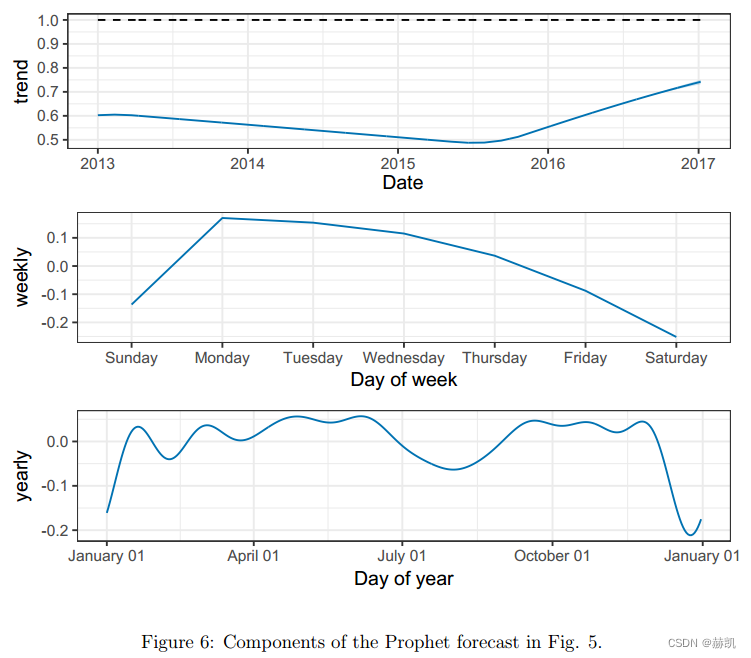
清单1中的参数tau和sigma是对模型变化点和季节性正则化程度的控制参数。正则化对于避免过拟合是重要的,然而,很可能没有足够的历史数据通过交叉验证来选择最佳的正则化参数。我们设置了适用于大多数预测问题的默认值,并且当需要优化这些参数时,会与分析师进行协商。
3.5、分析师参与的循环建模
经常进行预测的分析师通常对其所预测的数量具有丰富的领域知识,但在统计知识方面却知之甚少。在Prophet模型规范中,有几个地方可以让分析师调整模型以应用他们的专业知识和外部知识,而无需理解底层统计学。
-
能力:分析师可能拥有关于总市场规模的外部数据,并可以直接通过指定容量来应用这些知识。
-
变化点:已知的变化点日期,如产品变更日期,可以直接指定。
-
假期和季节性:我们合作的分析师具有哪些假期影响哪些地区增长的经验,他们可以直接输入相关的假期日期和适用的季节性时间尺度。
-
平滑参数:通过调整 τ τ τ,分析师可以从更全局或局部平滑的模型范围内进行选择。季节性和假期平滑参数 ( σ , ν ) (σ,ν) (σ,ν)允许分析师告诉模型未来预期的历史季节变化有多少。
借助良好的可视化工具,分析师可以使用这些参数来改进模型拟合。当将模型拟合绘制在历史数据上时,很快就能发现自动变化点选择中遗漏了哪些变化点。τ参数是一个单一的旋钮,可以调整趋势的灵活性,σ是调整季节性分量强度的旋钮。可视化提供了许多其他有益的人为干预机会:线性趋势或逻辑增长、确定季节性的时间尺度以及确定应该从拟合中剔除的异常时间段等。所有这些干预都可以在没有统计专业知识的情况下进行,是分析师应用其见解或领域知识的重要途径。
预测文献通常区分基于历史数据拟合的统计预测和人为判断的预测(也称为管理预测),后者由人类专家使用已经学到对特定时间序列有效的任何过程产生。这两种方法各有其优势。统计预测需要较少的领域知识和人类预测者的努力,并且可以轻松扩展到许多预测。人为判断的预测可以包含更多信息,并且对变化的条件更具响应性,但可能需要分析师进行大量工作。
我们的分析师参与的循环建模方法是一种替代方法,试图通过使分析师的努力集中于在必要时改进模型而不是通过某种未经说明的程序直接产生预测,从而融合了统计和人为判断预测的优势。我们发现我们的方法与Wickham和Grolemund(2016)提出的“转换-可视化-建模”循环非常相似,其中人类领域知识在一些迭代之后被编码到改进的模型中。
典型的预测扩展依赖于完全自动化的程序,但已经在许多应用中显示,人为判断的预测在准确性上表现出色。我们提出的方法让分析师可以通过一小组直观的模型参数和选项对预测进行判断,同时保留在必要时回归到完全自动化的统计预测的能力。截至目前,我们只有零星的实证证据表明可能会改进准确性,但我们期待未来的研究可以评估分析师在模型辅助设置中的改进效果。
在规模化的情况下,让分析师参与其中的能力至关重要,这在很大程度上依赖于预测质量的自动评估和良好的可视化工具。我们现在描述如何自动化预测评估,以确定最相关的预测以供分析师输入。
4、自动化预测评估
在本节中,我们概述了一种通过比较各种方法并确定需要手动干预的预测的流程来自动化预测绩效评估的方法。这个部分与所使用的预测方法无关,并包含我们在多种应用中进行生产业务预测时制定的一些最佳实践。
4.1、使用基线预测
在评估任何预测过程时,比较一组基线方法非常重要。我们喜欢使用简单的预测方法,对底层过程进行强烈的假设,但在实践中可以产生合理的预测。我们发现比较简单的模型(最后一个值和样本均值)以及第2节中描述的自动预测程序非常有用。
4.2、建模预测准确性
预测是在一定的时间范围内进行的,我们用H表示这个范围。这个范围是我们关心预测未来多少天的数量,通常是30、90、180或365天。因此,对于任何具有每日观察的预测,我们会产生高达H个未来状态的估计,每个状态都会与一些误差相关联。我们需要声明一个预测目标来比较方法和跟踪绩效。此外,了解我们的预测过程有多容易出错可以让企业预测的使用者决定是否信任它。
设 y ^ ( t ∣ T ) \widehat{y}(t|T) y (t∣T)表示用直到时间t的历史信息对时间T进行的预测,并且 d ( y , y ′ ) d(y,{y}') d(y,y′)是距离度量,例如平均绝对误差, d ( y , y ′ ) = ∣ y − y ′ ∣ d(y,{y}')=|y- {y}'| d(y,y′)=∣y−y′∣。距离函数的选择应该是特定于问题的。De Gooijer和Hyndman(2006)回顾了几种这样的误差度量{在实践中,我们更喜欢平均绝对百分比误差(MAPE)的可解释性。我们将时间T之前 h ∈ ( 0 , H ] h \in(0,H] h∈(0,H]时段的预测的经验准确性定义为:
ϕ ( T , h ) = d ( y ^ ( T + h ∣ T ) , y ( T + h ) ) \phi (T,h)=d(\widehat{y}(T+h|T),y(T+h)) ϕ(T,h)=d(y (T+h∣T),y(T+h))
为了对准确性及其随h的变化进行估计,通常会指定误差项的参数模型,并从数据中估计其参数。例如,如果我们使用AR(1)模型 y ( t ) = α + β y ( t − 1 ) + ν ( t ) y(t) = α + βy(t − 1) + ν(t) y(t)=α+βy(t−1)+ν(t),我们会假设 ν ( t ) ∼ N o r m a l ( 0 , σ v 2 ) ν(t) ∼ Normal(0,σ_{v}^{2}) ν(t)∼Normal(0,σv2),并专注于从数据中估计方差项 σ v 2 σ_{v}^{2} σv2。然后,我们可以通过模拟或使用错误总和的期望的解析表达式来使用任何距离函数形成期望。不幸的是,这些方法只在已经针对过程指定了正确模型的条件下给出正确的误差估计,而这在实践中不太可能发生。
我们更倾向于采用适用于各种模型的非参数方法来估计预期误差。这种方法类似于在独立同分布数据上对进行预测的模型估计外样本误差的交叉验证。给定一组历史预测,我们拟合一个关于不同预测时域h的预期误差模型。
ξ ( h ) = E [ ϕ ( T , h ) ] ξ(h)=E[\phi (T, h)] ξ(h)=E[ϕ(T,h)] (8)
该模型应该是灵活的,但也可以提出一些简单的假设。首先,函数在h上应该是局部平滑的,因为我们预计连续几天犯的错误相对类似。其次,我们可能会假设该函数在h上应该是微弱递增的,尽管这并不适用于所有预测模型。在实践中,我们使用局部回归(Cleveland和Devlin 1988)或同位素回归(Dykstra 1981)作为误差曲线的灵活非参数模型。
为了生成历史预测误差以拟合该模型,我们使用一种称为模拟历史预测的过程。
4.3、模拟历史预测
我们希望通过拟合(8)式中的预期误差模型来进行模型选择和评估。遗憾的是,使用类似交叉验证的方法比较困难,因为观测数据不可互换 - 我们不能简单地随机划分数据。我们使用模拟历史预测(SHFs)在历史的不同截断点处产生K个预测,这些截断点被选择为使预测时间段位于历史之内,并且可以评估总体误差。这个过程基于传统的“滚动起源”预测评估程序(Tashman,2000),但只使用了一小组截断日期,而不是每个历史日期都进行一次预测。使用较少的模拟日期的主要优点是节约计算资源,同时提供更少相关性的准确度测量。
SHFs模拟了我们在过去的那些时间点上使用该预测方法所犯的误差。图3和图4中的预测就是SHFs的例子。这种方法的优点是简单易懂,容易向分析师和决策者解释,而且用于生成对预测误差的洞察相对无争议。在使用SHF方法评估和比较预测方法时,需要注意两个主要问题。
首先,我们进行的模拟预测越多,它们对误差的估计就越相关。在极端情况下,如果在历史的每一天进行一次模拟预测,考虑到额外的一天信息,预测不太可能发生太大变化,并且从一天到下一天的误差几乎相同。另一方面,如果我们只进行很少的模拟预测,那么我们就只有很少的历史预测误差观测值可供我们基于其选择模型。作为一种经验法则,对于预测时间段为H,我们通常每隔H=2个周期进行一次模拟预测。尽管相关的估计不会引入模型准确度的偏差,但它们会产生较少有用的信息并减慢预测评估的速度。
其次,更多的数据可能导致预测方法的表现更好或更差。当模型规范错误且过度拟合过去时,更长的历史可能会导致更糟糕的预测,例如使用样本均值来预测具有趋势的时间序列。图7显示了LOESS方法在图3和图4的时间序列上使用的预测期间的预期平均绝对百分比误差函数ξ(h)的估计值。该估计是使用九个模拟预测日期进行的,每个季度开始后选择一个日期。Prophet在所有预测时间段上都具有较低的预测误差。Prophet的预测是使用默认设置进行的,调整参数可能进一步提高性能。
在可视化预测时,我们更喜欢使用点而不是线来表示历史数据,因为这些点代表精确的测量结果,永远不会进行插值。然后,我们通过预测叠加线条。对于SHFs,将模型在不同预测时间段上的误差可视化是有用的,既可以作为时间序列(如图3),也可以作为SHFs的汇总(如图7)。
即使对于单个时间序列,SHFs也需要计算许多预测,而且在规模上,我们可能希望对许多不同的指标以及多个不同的聚合级别进行预测。只要这些机器可以写入相同的数据存储,SHFs可以在独立的机器上进行计算。我们将预测和相关误差存储在Hive或MySQL中,具体取决于它们的预期使用方式。
4.4、识别大的预测误差
当有太多的预测需要分析师手动检查时,能够自动识别可能存在问题的预测就变得非常重要。自动识别不良预测可以让分析师更有效地利用有限的时间,并利用他们的专业知识来纠正任何问题。以下是使用SHFs来识别预测可能存在问题的几种方法:
-
当相对于基准线而言,预测误差较大时,可能是因为模型规范错误。分析师可以根据需要调整趋势模型或季节性模型。
-
对于特定日期,所有方法都存在较大的误差,这可能是异常值的表现。分析师可以识别并排除异常值。
-
当某个方法的SHF误差从一个截断点急剧增加到下一个截断点时,这可能表明数据生成过程发生了变化。添加变点或将不同阶段分开建模可能会解决这个问题。
虽然有些问题无法轻易纠正,但我们遇到的大多数问题都可以通过指定变点和排除异常值来纠正。一旦预测被标记为需要审核并可视化,这些问题就很容易被识别和纠正。
5、结论
规模化预测的一个重要主题是,具有不同背景的分析师必须进行比他们能够手动完成的更多的预测。我们预测系统的第一个组成部分是我们在Facebook上对各种数据进行多次迭代预测后开发的新模型。我们使用简单、模块化的回归模型,通常使用默认参数效果良好,并允许分析师选择与他们的预测问题相关的组件,并根据需要轻松进行调整。第二个组成部分是用于测量和跟踪预测准确性,并标记应该手动检查的预测的系统,以帮助分析师进行增量改进。这是一个关键的组成部分,它可以让分析师识别何时需要对模型进行调整,或者何时可能需要完全不同的模型。简单、可调整的模型和可扩展的性能监控结合起来,使大量分析师能够对大量和多样的时间序列进行预测,这就是我们所认为的规模化预测。
6、致谢
我们感谢Dan Merl让Prophet的开发成为可能,并在开发过程中提供建议和见解。我们还感谢Dirk Eddelbuettel、Daniel Kaplan、Rob Hyndman、Alex Gilgur和Lada Adamic对本文的有益审阅。我们特别感谢Rob Hyndman将我们的工作与主观预测联系起来的见解。
至此结束,主要是作者能把公式列出来就比较厉害。
相关文章:
论文阅读 Forecasting at Scale (二)
最近在看时间序列的文章,回顾下经典 论文地址 项目地址 Forecasting at Scale 3.2、季节性 3.3、假日和活动事件3.4、模型拟合3.5、分析师参与的循环建模4、自动化预测评估4.1、使用基线预测4.2、建模预测准确性4.3、模拟历史预测4.4、识别大的预测误差 5、结论6、致…...

刷题感悟w
题目很长的一定要慢慢把题目的意思搞清楚 有重复操作不知道怎么办 可以用数组去标记 你好!在C中,replace 函数通常是用于替换容器(例如 std::vector 或 std::string)中的特定元素的函数。以下是 std::replace 函数的一般用法&…...
记一次linux操作系统实验
前言 最近完成了一个需要修改和编译linux内核源码的操作系统实验,个人感觉这个实验还是比较有意思的。这次实验总共耗时4天,从对linux实现零基础,通过查阅资料和不断尝试,直到完成实验目标,在这过程中确实也收获颇丰&…...

java操作富文本插入到word模板
最近项目有个需求,大致流程是前端保存富文本(html的代码)到数据库,后台需要将富文本代码转成带格式的文字,插入到word模板里,然后将word转成pdf,再由前端调用接口下载pdf文件! 1、思…...

JMeter---BeanShell实现接口前置和后置操作
在JMeter中,可以使用BeanShell脚本来实现接口的前置和后置操作。 下面是使用BeanShell脚本实现接口前置和后置操作的步骤: 1、在测试计划中添加一个BeanShell前置处理器或后置处理器。 右键点击需要添加前置或后置操作的接口请求,选择&quo…...
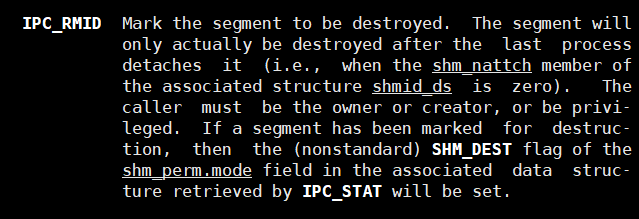
【Linux】共享内存
文章目录 一、共享内存的原理详谈共享内存的实现过程二、共享内存的接口函数1.shmget2. shmatshmdtshmctl 进程间使用共享内存通信三、共享内存的特性 关于代码 一、共享内存的原理 共享内存是由操作系统维护和管理的一块内存。 共享内存的本质是内核级的缓冲区。 一个进程向…...
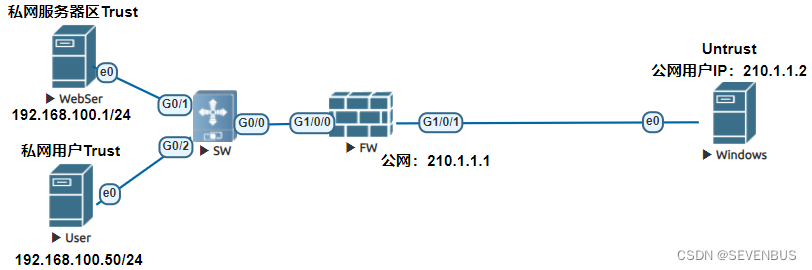
五、双向NAT
学习防火墙之前,对路由交换应要有一定的认识 双向NAT1.1.基本原理1.2.NAT Inbound NAT Server1.3.域内NATNAT Server —————————————————————————————————————————————————— 双向NAT 经过前面介绍,…...
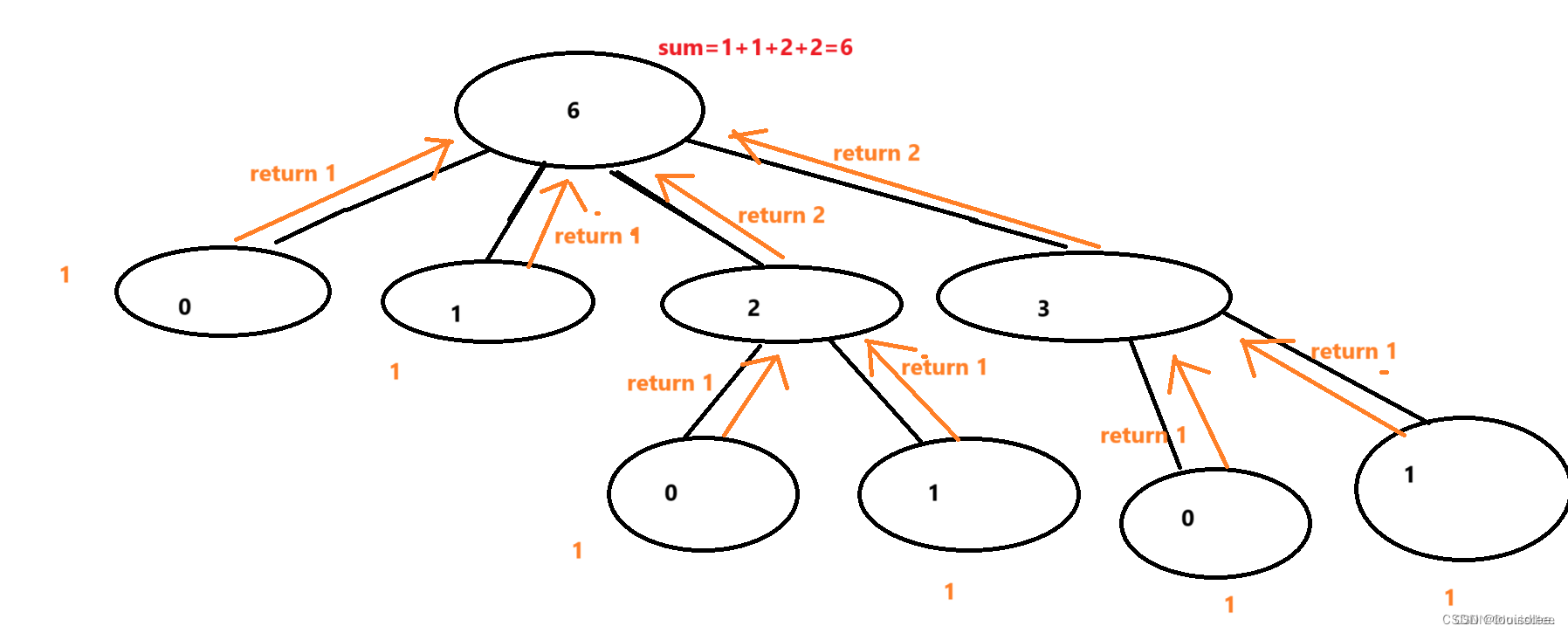
P1028 [NOIP2001 普及组] 数的计算
时刻记住一句话:写递归,1画图,2大脑放空!!! 意思是,自己写递归题目,先用样例给的数据画图,然后想一个超级简单的思路,直接套上去就可以了。 上题干ÿ…...
浅析三相异步电动机控制的电气保护
安科瑞 华楠 摘 要:要求三相异步电动机的控制系统不仅要保证电机正常启动和运行,完成制动操作,还要通过相关保护措施维护电动机的安全使用。基于此,本文以电动机电气保护作为研究对象,结合三相异步电动机的机械特点&…...
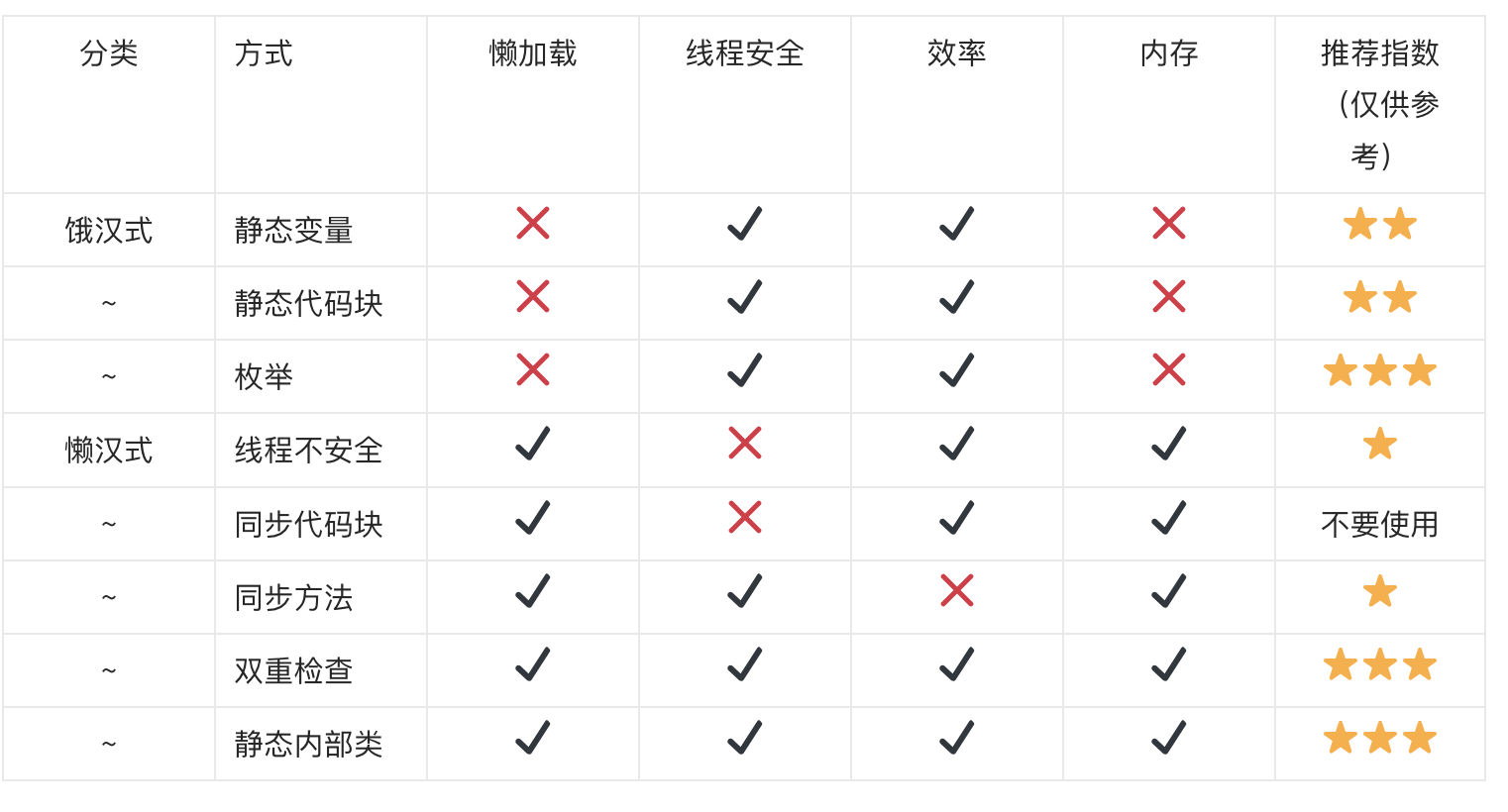
Java设计模式系列:单例设计模式
Java设计模式系列:单例设计模式 介绍 所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例,并且该类只提供一个取得其对象实例的方法(静态方法) 比如 Hiberna…...

开拓新天地:探讨数位行销对医药产业医病连结的影响
数字营销模式多元,主要围绕医生和患者。赛道各企业凭借各自优势(技术、学术、流量等)入局,提供各自差异化营销工具或服务。目前,围绕医生的数字营销旨在为医生提供全面学术解决方案从而提升对医药产品的认可࿰…...

[tsai.shen@mailfence.com].faust勒索病毒数据怎么处理|数据解密恢复
导言: [support2022cock.li].faust、[tsai.shenmailfence.com].faust、[Encrypteddmailfence.com].faust勒索病毒是一种具有恶意目的的勒索软件,其主要特点包括对受害者文件进行强力加密,然后勒索受害者支付赎金以获取解密密钥。攻击者通常通…...
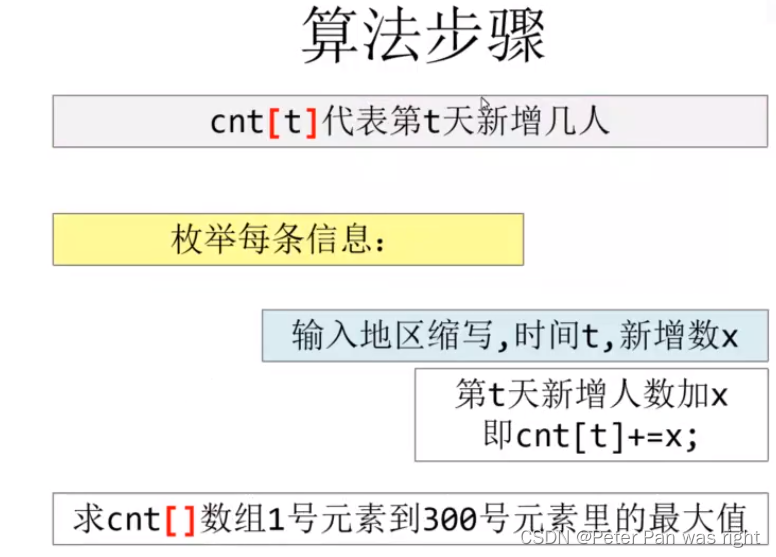
Peter算法小课堂—前缀和数组的应用
桶 相当于计数排序,看一个视频 桶排序 太戈编程1620题 算法解析 #include <bits/stdc.h> using namespace std; const int R11; int cnt[R];//cnt[t]代表第t天新增几人 int s[R];//s[]数组是cnt[]数组的前缀和数组 int n,t; int main(){cin>>n;for(…...

线性表之链式表
文章目录 主要内容一.单链表1.头插法建立单链表代码如下(示例): 2.尾插法建立单链表代码如下(示例): 3.按序号查找结点值代码如下(示例): 4.按值查找表结点代码如下(示例): 5.插入节…...
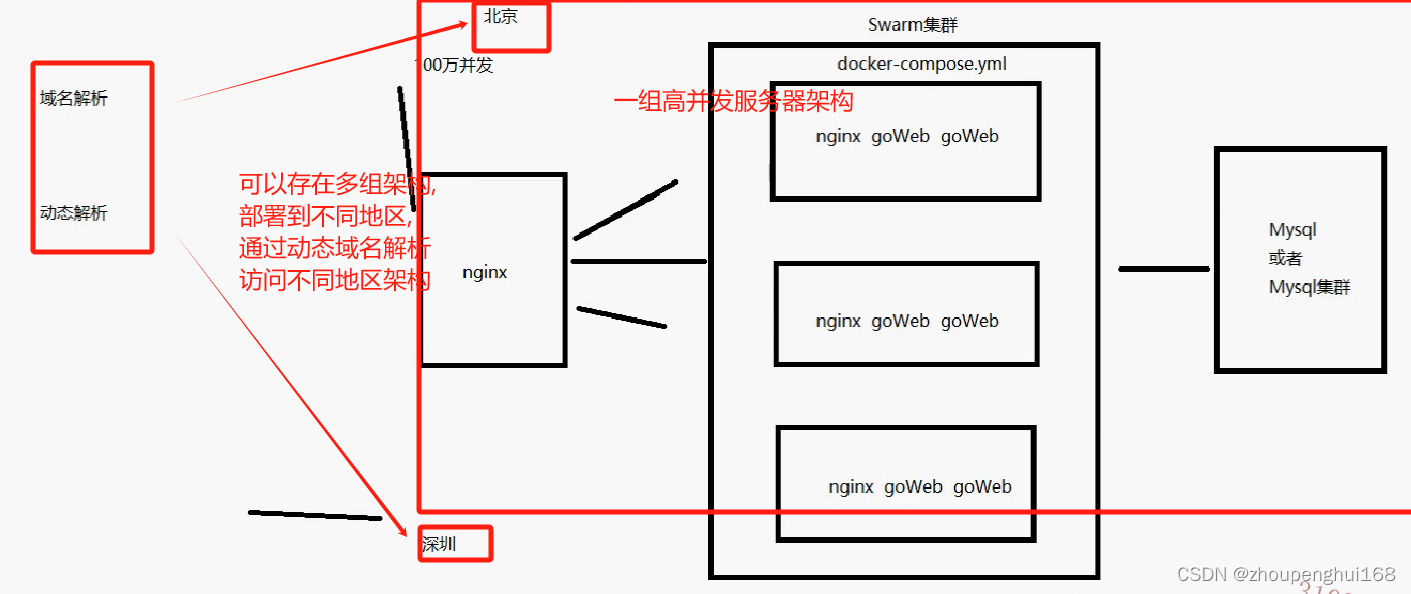
[Docker]十.Docker Swarm讲解
一.Dokcer Swarm集群介绍 1.Dokcer Swarm 简介 Docker Swarm 是 Docker 公司推出的用来管理 docker 集群的工具, 使用 Docker Swarm 可以快速方便的实现 高可用集群 ,Docker Compose 只能编排单节点上的容器, Docker Swarm 可以让我们在单一主机上操作来完成对 整…...

相机机模组需求示例
产品需求名称摄像头采集图片数据补充说明产品需求描述 As:用户 I want to:通过相机模组获取到自定义格式图片数据,要求包括: 1、支持多种场景,如:手持相机拍摄舌苔 2、支持图片分辨率至少达到1920X1080 3、…...

Uniapp 微信登录流程解析
本文将介绍在 Uniapp 应用中实现微信登录的流程,包括准备工作、授权登录、获取用户信息等步骤。 内容大纲: 介绍Uniapp和微信登录: 简要介绍 Uniapp 框架以及微信登录的重要性和流行程度。 准备工作: 注册微信开发者账号创建应用…...
)
红旗Asianux Server Linux V8 安装万里数据库(GreatSQL)
红旗Asianux Server Linux V8 安装万里数据库(GreatSQL) 红旗Asianux介绍: 红旗Asianux Server Linux 8.0是为云时代重新设计的操作系统,为云时代的到来引入了大量新功能,包括用于配置管理、快速迁移框架、编程语言和…...
一文2000字使用JMeter进行接口测试教程!(建议收藏)
安装 使用JMeter的前提需要安装JDK,需要JDK1.7以上版本目前在用的是JMeter5.2版本,大家可自行下载解压使用 运行 进入解压路径如E: \apache-jmeter-5.2\bin,双击jmeter.bat启动运行 启动后默认为英文版本,可通过Options – Cho…...
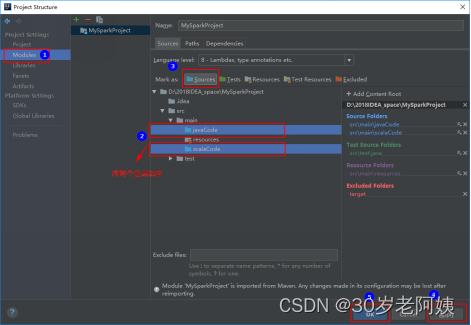
Spark---介绍及安装
一、Spark介绍 1、什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但…...

暗黑2重制 Mod开发工具汇总
《Diablo II: Resurrected》的 Mod 开发,并不是简单改几行数值,而是一套完整的数据重构过程。游戏内部的物品、技能、怪物、掉落,本质上全部是结构化表数据,通过 Casc 存储体系封装,再由加载链路按规则读取。CascView …...

AI殖民主义数据战争:软件测试从业者的挑战、角色与破局之路
在数字时代的宏大叙事中,“AI殖民主义”正从一个学术概念演变为一场席卷全球的静默战争。这场战争的核心战场并非物理疆域,而是数据、算法与认知主权。对于身处技术前线的软件测试从业者而言,这场战争并非遥不可及的宏观叙事,而是…...
)
VNC连上了但GUI应用打不开?手把手教你解决DISPLAY环境变量问题(以Swingbench为例)
VNC连接成功但GUI应用无法启动?深度解析DISPLAY环境变量问题 当你通过VNC成功连接到远程Linux服务器,却发现Swingbench等图形界面应用无法启动时,这种挫败感可能让人抓狂。本文将带你深入理解X Window系统的工作原理,并提供一套完…...

Midscene性能调优实战:从卡顿到流畅的自动化体验
Midscene性能调优实战:从卡顿到流畅的自动化体验 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 当你的自动化脚本运行缓慢,AI操作响应延…...

7个高效技巧:用Ice彻底改造你的macOS菜单栏体验
7个高效技巧:用Ice彻底改造你的macOS菜单栏体验 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 你是否曾因macOS菜单栏图标过多而感到困扰?当十几个应用图标挤在屏幕顶部时&a…...

Elasticsearch架构核心:Node节点详解与角色功能全解析
Elasticsearch架构核心:Node节点详解与角色功能全解析一、前言二、什么是 Elasticsearch Node(节点)?1. 官方定义2. 通俗理解3. 节点核心特点三、节点角色与功能流程图四、Elasticsearch 节点的 5 种核心角色与功能1. 主节点&…...

从市场调研到用户画像:因子分析如何帮你发现隐藏的‘消费者因子’?
解码消费者心智:如何用因子分析从海量问卷中提炼黄金洞察 当市场部同事将一份包含87个问题的用户满意度问卷扔到你桌上时,那些密密麻麻的评分数据就像未经处理的矿石——价值连城却难以直接利用。这正是因子分析大显身手的时刻。想象一下,你不…...
)
别再只会用sinfo了!Slurm节点状态全解析(从alloc到drain,附排查脚本)
深度解析Slurm节点状态:从基础诊断到高效运维实战 在HPC集群管理中,Slurm作为最常用的作业调度系统,其节点状态监控直接影响着运维效率和资源利用率。许多管理员习惯使用sinfo命令快速查看节点概况,但当遇到作业排队异常或节点故障…...

别再手动清理AL11了!用ABAP函数EPS2_GET_DIRECTORY_LISTING自动管理SAP服务器文件
告别手动清理:用ABAP自动化管理SAP服务器文件的终极方案 每次打开AL11看到堆积如山的日志文件和临时数据时,你是否感到一阵无力?那些需要定期清理的接口文件、归档数据,是否总在消耗你宝贵的时间?作为SAP系统管理员或A…...

Windows和Office激活难题?KMS_VL_ALL_AIO一站式智能解决方案详解
Windows和Office激活难题?KMS_VL_ALL_AIO一站式智能解决方案详解 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 面对Windows系统或Office办公软件的激活过期警告,你是否…...