正则表达式(Java)(韩顺平笔记)
正则表达式(Java)
底层实现
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp00 {public static void main(String[] args) {String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。" +"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:" +"J2ME(Java2 Micro Edition,Java2平台的微型版),应用于移动、无线及" +"有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的标" +"准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台" +"的企业版),应用于基于Java的应用服务器。Java 2平台的发布,是Java发展" +"过程中最重要的一个里程碑,标志着Java的应用开始普及。";
// String regStr = "\\d\\d\\d\\d";String regStr = "(\\d\\d)(\\d\\d)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);/*** matcher.find() 完成的任务* 1. 根据指定的规则,定位满足规则的子字符串(比如1998)* 2. 找到后,将子字符串的开始的索引记录到matcher对象的属性int[] groups;* group[0] = 0, 把该子字符串的结束的索引+1的值记录到 groups[1] = 4;* 3. 同时记录 oldLast 的值为 子字符串的结束的 索引+1的值即4 即下次执行find时 就从4开始匹配** matcher.find() 完成的任务* 1. 根据指定的规则,定位满足规则的子字符串(比如(19)(98))* 2. 找到后,将子字符串的开始的索引记录到matcher对象的属性int[] groups;* 2.1 group[0] = 0, 把该子字符串的结束的索引+1的值记录到 groups[1] = 4;* 2.2 记录1组的()匹配到的字符串 groups[2] = 0 groups[3] = 2* 2.3 记录2组的()匹配到的字符串 groups[4] = 2 groups[5] = 4* 3. 同时记录 oldLast 的值为 子字符串的结束的 索引+1的值即4 即下次执行find时 就从4开始匹配*/while (matcher.find()) {System.out.println("找到:" + matcher.group(0));System.out.println("找到:" + matcher.group(1));//表示匹配到的子字符串的第一组子串System.out.println("找到:" + matcher.group(2));//表示匹配到的子字符串的第二组子串//分组不能越界}}
}matcher.find
public boolean find() {int nextSearchIndex = last;if (nextSearchIndex == first)nextSearchIndex++;// If next search starts before region, start it at regionif (nextSearchIndex < from)nextSearchIndex = from;// If next search starts beyond region then it failsif (nextSearchIndex > to) {for (int i = 0; i < groups.length; i++)groups[i] = -1;return false;}return search(nextSearchIndex);}
matcher.group
public String group(int group) {if (first < 0)throw new IllegalStateException("No match found");if (group < 0 || group > groupCount())throw new IndexOutOfBoundsException("No group " + group);if ((groups[group*2] == -1) || (groups[group*2+1] == -1))return null;return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();}
基础用法
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp01 {public static void main(String[] args) {String content = "a_bchHKKay66 66sABc_jdj*@fDH \n Y298HU 寒冷 韩顺平 han";
// String regStr = "[a-z]";// 查找小写字母a-z任意一个字符
// String regStr = "[A-Z]";// 查找大写字母A-Z任意一个字符
// String regStr = "abc";// 查找abc字符串 (默认区分大小写)
// String regStr = "(?i)abc";// 查找abc字符串 (不区分大小写)
// String regStr = "[0-9]";// 查找0-9任意一个字符
// String regStr = "[^0-9]";// 查找不在0-9任意一个字符
// String regStr = "[^a-z]";// 查找不在a-z任意一个字符
// String regStr = "[abcd]";// 查找abcd任意一个字符
// String regStr = "[^abcd]";// 查找不是abcd任意一个字符
// String regStr = "\\D";// 查找不是数字0-9字符
// String regStr = "\\w";// 查找字母,数字,下划线 @不属于范围
// String regStr = "\\W";// 上式取反 相当于[^0-9a-zA-Z_]
// String regStr = "\\s";// 查找空白字符
// String regStr = "\\S";// 查找非空白字符
// String regStr = ".";// 查找非 \n 以外所有字符 查找.需要用 \\.String regStr = "寒|韩|han";// 选择匹配符//Pattern.CASE_INSENSITIVE 表示匹配不区分大小写Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);// 创建对象Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
正则限定符
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
|---|---|---|---|---|
| * | 指定字符重复0次或n次(无要求) | (abc)* | 仅包含任意个abc字符串,相当于\w* | abc abcabcabc |
| + | 指定字符重复1次或n次(至少1次) | m+(abc)* | 以至少1个m开头,后接任意个abc的字符串 | m mabc mabcabc |
| ? | 指定字符重复0次或1次(最多1次) | m+abc? | 以至少1个m开头,后接ab或abc的字符串 | mab mabc mmmab mmabc |
| {n} | 只能输入n个字符 | [abcd]{3} | 由abcd中字母组成的任意长度为3的字符串 | abc dbc adc |
| {n,} | 指定至少n个匹配 | [abcd]{3,} | 由abcd中字母组成的任意长度不小于3的字符串 | aab dbc aaabdc |
| {n,m} | 指定至少n个但不多于m个匹配 | [abcd]{3,5} | 由abcd中字母组成的任意长度不小于3,不大于5的字符串 | abc abcd aaaaa bcdab |
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp02 {public static void main(String[] args) {String content = "11111111aaaaaaahello";// String regStr = "a{3}";// 匹配 aaa
// String regStr = "1{4}";// 匹配 1111
// String regStr = "\\d{2}";// 匹配 两位任意数字字符//Java默认匹配多的(贪婪匹配)
// String regStr = "a{3,4}";// 匹配 aaa 或 aaaa(优先)
// String regStr = "1{4,5}";// 匹配 1111 或 11111(优先)
// String regStr = "\\d{2,5}";// 匹配 2位数 或 3,4,5 实际 sout (找到 11111 (换行) 找到 111)// String regStr = "1+";// 匹配 1个1 或 多个1
// String regStr = "\\d+";// 匹配 1个数字 或 多个数字// String regStr = "1*"; // 匹配0个1或者多个1String regStr = "a1?";// 匹配 a 或 a1Pattern pattern = Pattern.compile(regStr, Pattern.CASE_INSENSITIVE);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}正则定位符
| 符号 | 含义 | 示例 | 说明 | 匹配输入 |
|---|---|---|---|---|
| ^ | 指定起始字符 | 1+[a-z]* | 以至少一个数字开头,后接任意个小写字母的字符串 | 123 6aa 555edf |
| $ | 指定结束字符 | 2\\-[a-z]+$ | 以一个数字开头后接连字符“-”,并以至少1个小写字母结尾的字符串 | 1-a |
| \\b | 匹配目标字符串的边界 | han\\b | 这里说的字符串边界指的是子串间有空格,或者是目标字符串的结束位置 | hanshunping sphan nnhan |
| \\B | 匹配目标字符串的非边界 | han\\B | 和\b的含义相反 | hanshuping sphan nnhan |
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp03 {public static void main(String[] args) {
// String content = "123anj-556abc-945BGh";
// String content = "123-ljj";String content = "hanshunping sphan nnhan";// String regStr = "^[0-9]+[a-z]*";// 找到123anj
// String regStr = "^[0-9]+\\-[a-z]+$";// 找到123-ljj
// String regStr = "^[0-9]+\\-[a-z]+$";// 找到123-ljj// String regStr = "han\\b";// 找到 han (sphan) 找到 han (nnhan)String regStr = "han\\B";// 找到 han (hanshunping)Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
捕获分组
| 常用分组构造形式 | 说明 |
|---|---|
| (pattern) | 非命名捕获。捕获匹配的子字符串。编号为0的第一个捕获是由整个正则表达式模式匹配的文本,其他捕获结果则根据左括号的顺序从1开始自动编号。 |
| (?'name’pattern) | 命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name的字符串不能包含任何标点符号,并且不能以数字开头。可以使用尖括号代替单引号。 |
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp04 {public static void main(String[] args) {String content = "hanshunping s7789 nn1189han";// String regStr = "(\\d\\d)(\\d\\d)";//匹配四个数组的字符串(7789)(1189)// String regStr = "(\\d\\d)(\\d)(\\d)";/*** 找到 7789* 第一个分组 77* 第二个分组 8* 第三个分组 9* 找到 1189* 第一个分组 11* 第二个分组 8* 第三个分组 9*/String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";/*** 找到 7789* 第一个分组[编号] 77* 第二个分组[编号] 89* 找到 1189* 第一个分组[编号] 11* 第二个分组[编号] 89*/Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));
// System.out.println("第一个分组 " + matcher.group(1));System.out.println("第一个分组[编号] " + matcher.group("g1"));
// System.out.println("第二个分组 " + matcher.group(2));System.out.println("第二个分组[编号] " + matcher.group("g2"));
// System.out.println("第三个分组 " + matcher.group(3));}}
}
非捕获分组
| 常用分组构造形式 | 说明 |
|---|---|
| (?:pattern) | 匹配pattern但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“or”字符(|)组合模式部件的情况很有用。 |
| (?=pattern) | 它是一个非捕获匹配。 |
| (?!pattern) | 该表达式匹配不处于匹配pattern的字符串的起始点的搜索字符串。 |
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp05 {public static void main(String[] args) {String content = "hello韩顺平教育 Jack韩顺平老师 韩顺平同学hello";//找到 韩顺平教育 、 韩顺平老师 、 韩顺平同学
// String regStr = "韩顺平(?:教育|老师|同学)";//不能group(1)//找到 韩顺平教育中的韩顺平 韩顺平老师中的韩顺平
// String regStr = "韩顺平(?=教育|老师)";//找到 不是韩顺平教育中的韩顺平 不是韩顺平老师中的韩顺平String regStr = "韩顺平(?!教育|老师)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {//非捕获分组 不能使用group(1)System.out.println("找到 " + matcher.group(0));}}
}
非贪婪匹配
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp06 {public static void main(String[] args) {String content = "hello1111111";String regStr = "\\d+?";/*** 找到 1* 找到 1* 找到 1* 找到 1* 找到 1* 找到 1* 找到 1*/Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {//非捕获分组 不能使用group(1)System.out.println("找到 " + matcher.group(0));}}
}
应用实例
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp07 {public static void main(String[] args) {//汉字
// String content = "韩顺平教育";
// String regStr = "^[\u0391-\uffe5]+$";//true//1-9开头的一个六位数
// String content = "112344";
// String regStr = "^[1-9]\\d{5}$";//true//1-9开头的一个(5-10位数)
// String content = "12389";
// String regStr = "^[1-9]\\d{4,9}$";//true//以11、13、18开头的11位数String content = "11588889999";String regStr = "^1[1|3|8]\\d{9}$";//truePattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if (matcher.find()) {System.out.println("true");} else {System.out.println("false");}}
}
验证复杂URL
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp09 {public static void main(String[] args) {String content = "https://www.bilibili.com/video/BV1fh411y7R8?;/** ((http|https)://)开始部分* ([\w-]+\.)+[\w-]+ 匹配 www.bilibili.com* (\/[\w-?=&/%.#]*)? 匹配 /video/BV1fh411y7R8?p=894&vd_source=a8223634aa8a190c7233a2dc3f8a15e3* []里面的元素相当于一个集合* 如果查找 "(去掉http)edu.metastudy.vip/mt/official/pc/mxmt-ksjhdj"* regStr = "^((http|https)://)?([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$";*/String regStr = "^((http|https)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if (matcher.find()) {System.out.println("true");} else {System.out.println("false");}}
}
Pattern类matches方法
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp10 {public static void main(String[] args) {String content = "10https://www.bilibili.com/video/BV1fh411y7R8?p=894&vd_source=";String regStr = "((http|https)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);//find匹配必须加^$定位符if (matcher.find()) {System.out.println("true");} else {System.out.println("false");}//整体匹配System.out.println(Pattern.matches(regStr, content));/*** true* false*/}
}
Pattern类中的源码:
public static boolean matches(String regex, CharSequence input) {Pattern p = Pattern.compile(regex);Matcher m = p.matcher(input);return m.matches();}
matcher方法
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp11 {public static void main(String[] args) {String content = "hello edu jack hspedutom hello smith hello";
// String regStr = "hello";String regStr = "hello edu jack tom hello smith hello";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("================");System.out.println(matcher.start());System.out.println(matcher.end());System.out.println(content.substring(matcher.start(),matcher.end()));}System.out.println("整体匹配 " + matcher.matches());regStr = "hspedu";pattern = Pattern.compile(regStr);matcher = pattern.matcher(content);String newContent = matcher.replaceAll("韩顺平教育");//并没有改变原来的contentSystem.out.println("content = " + content);System.out.println("new = " + newContent);}
}
反向引用
- 分组 可以使用()组成一个比较复杂的匹配模式,一个圆括号的部分我们可以看作一个子表达式/一个分组
- 捕获 把正则表达式中子表达式/分组匹配内容,保存到一个组里,方便后面引用
0代表整个表达式 - 反向引用 圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp12 {public static void main(String[] args) {String content = "hello hspedu11111 hello22 12345-111222333";//找到两个连续相同的数字
// String regStr = "(\\d)\\1";//找到五个连续相同的数字
// String regStr = "(\\d)\\1{4}";//找到个位与千位相同 十位与百位相同的数字
// String regStr = "(\\d)(\\d)\\2\\1";//找到以下格式 "五位数-九位数连续每三位相同(例如:12345-111222333)"String regStr = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
替换分割匹配
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExp13 {public static void main(String[] args) {String content = "我....我要....学学学学....编程java!";//去掉所有的 .Pattern pattern = Pattern.compile("\\.");Matcher matcher = pattern.matcher(content);content = matcher.replaceAll("");System.out.println("content=" + content);//去掉重复的字 (.)查找任意的字符 \\1反向引用出'(.)'的内容 +指重复多次 $1表示重复字符替换为1个//如果要替换ABAB型 例如"我要我要" 使用(..)\\1+content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");System.out.println("content=" + content);}
}
练习题
package com.hspedu.RegExp;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegExpHomework {public static void main(String[] args) {//匹配电子邮箱 例如 shu@sohu.com shu@sougo.org.cnString content01 = "shu@sougo.org.cn";//[\\w-](@前面的英文) @([a-zA-z]+\.)(至少匹配一次@英文.)String regStr01 = "^[\\w-]+@([a-zA-z]+\\.)+[a-zA-Z]+$";if (content01.matches(regStr01)) {System.out.println("true");} else {System.out.println("false");}//匹配整数或者小数String content02 = "-0.56";//([1-9]\d*|0)判断整数部分 不能出现0034.56String regStr02 = "^[-+]?([1-9]\\d*|0)(\\.\\d+)?$";if (content02.matches(regStr02)) {System.out.println("true");} else {System.out.println("false");}//解析urlString content03 = "http://www.sohu.com:8080/abc/index.html";String regStr03 = "^([a-zA-Z]+)://([a-zA-Z.]+):(\\d+)[\\w-/]*/([\\w.]+)$";Pattern pattern = Pattern.compile(regStr03);Matcher matcher = pattern.matcher(content03);if (matcher.matches()) {System.out.println("true");System.out.println("整体匹配=" + matcher.group(0));System.out.println("协议=" + matcher.group(1));System.out.println("域名=" + matcher.group(2));System.out.println("端口=" + matcher.group(3));System.out.println("文件=" + matcher.group(4));} else {System.out.println("false");}}
}
0-9 ↩︎
0-9 ↩︎
相关文章:
(韩顺平笔记))
正则表达式(Java)(韩顺平笔记)
正则表达式(Java) 底层实现 package com.hspedu.RegExp;import java.util.regex.Matcher; import java.util.regex.Pattern;public class RegExp00 {public static void main(String[] args) {String content "1998年12月8日,第二代J…...
)
LLVM学习笔记(62)
4.4.3.3.2. 指令处理的设置 4.4.3.3.2.1. 目标机器相关设置 除了基类以外,X86TargetLowering构造函数本身也是一个庞然大物,我们必须要分段来看。V7.0做了不小的改动,改进了代码的结构,修改了一些指令的设置。 100 X86Targ…...
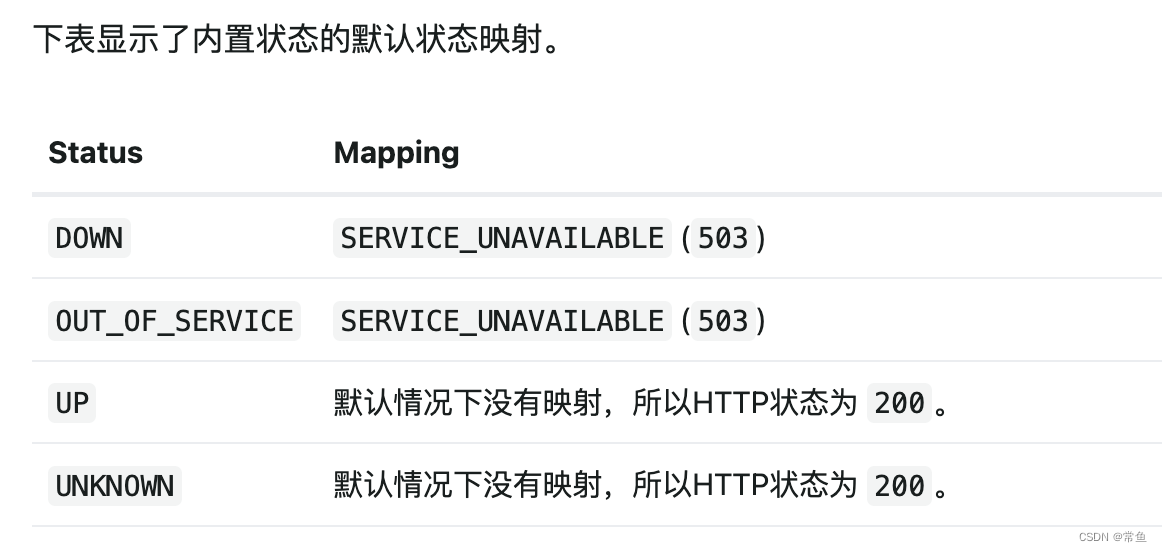
解决Spring Boot应用在Kubernetes上健康检查接口返回OUT_OF_SERVICE的问题
现象 在将Spring Boot应用部署到Kubernetes上时,健康检查接口/healthcheck返回的状态为{"status":"OUT_OF_SERVICE","groups":["liveness","readiness"]},而期望的是返回正常的健康状态。值得注意的…...

Java对象逃逸
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 未经允许不得转载 目录 一、导读二、概览三、相关知识3.1 逃逸…...

Greenplum的数据库年龄检查处理
概述 Greenplum是基于Postgresql数据库的分布式数据库,而PG数据库在事务及多版本并发控制的实现方式上很特别,采用的是递增事务id的方法,事务id大的事务,认为比较新,反之事务id小,认为比较旧。 事务id的上…...
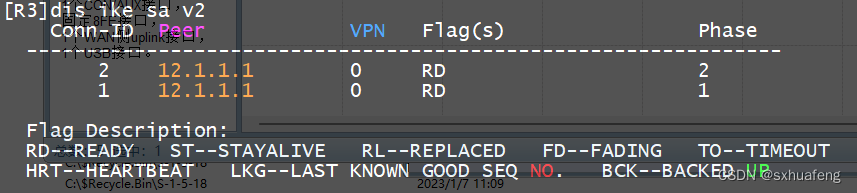
[HCIE] IPSec-VPN (IKE自动模式)
概念: IKE:因特网密钥交换 实验目标:pc1与pc2互通 步骤1:R1与R3配置默认路由 R1: ip route-static 0.0.0.0 0.0.0.0 12.1.1.2 R2: ip route-static 0.0.0.0 0.0.0.0 23.1.1.2 步骤2:配ACL…...

Qt/QML编程学习之心得:一个Qt工程的学习笔记(九)
这里是关于如何使用Qt Widget开发,而Qt Quick/QML的开发是另一种方式。 1、.pro文件 加CONFIG += c++11,才可以使用Lamda表达式(一般用于connect的内嵌槽函数) 2、QWidget 这是Qt新增加的一个类,基类,窗口类,QMainWindow和QDialog都继承与它。 3、Main函数 QApplicati…...

c++ 课程笔记
105课: cpp文件分为 .h .cpp .cpp 文件 110课:124课 深拷贝 浅拷贝 自建拷贝构造解决浅拷贝释放new后堆区析构函数的问题 (浅拷贝 拷贝内存地址, 释放堆区时 导致源数据 释放时,该地址无数据?而报错) 浅拷贝: 拷贝了对方的值和 堆区内存地址(删除 影响原数据堆区) 深拷贝…...
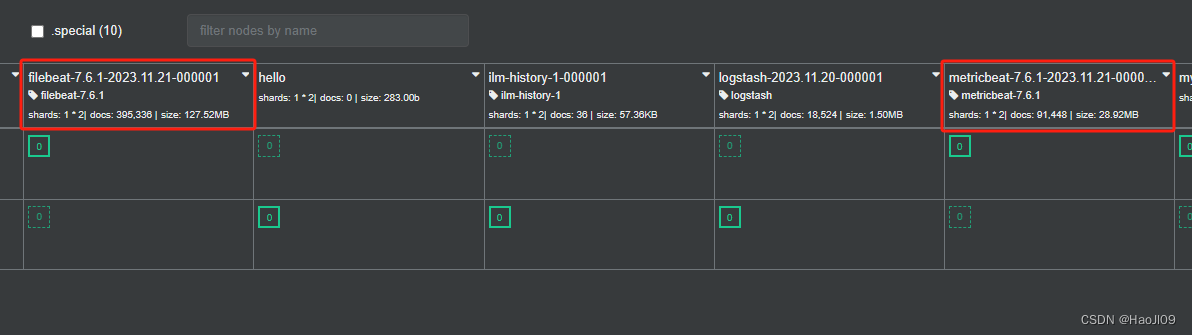
ELK企业级日志分析平台——ES集群监控
启用xpack认证 官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/configuring-tls.html#node-certificates 在elk1上生成证书 [rootelk1 ~]# cd /usr/share/elasticsearch/[rootelk1 elasticsearch]# bin/elasticsearch-certutil ca[rootelk1 ela…...
Twincat使用:EtherCAT通信扫描硬件设备链接PLC变量
EtherCAT通信采用主从架构,其中一个主站设备负责整个EtherCAT网络的管理和控制,而从站设备则负责在数据环网上传递数据。 主站设备可以是计算机、工控机、PLC等, 而从站设备可以是传感器、执行器、驱动器等。 EL3102:MDP5001_300_CF8D1684;…...
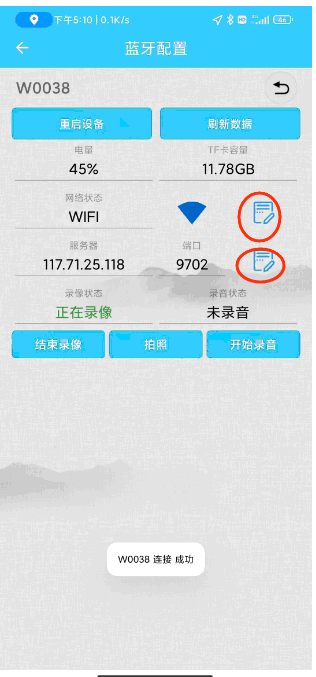
手机APP-MCP走蓝牙无线遥控智能安全帽~执法记录仪~拍照录像,并可做基础的配置,例如修改服务器IP以及配置WiFi等
手机APP-MCP走蓝牙无线遥控智能安全帽~执法记录仪~拍照录像,并可做基础的配置,例如修改服务器IP以及配置WiFi等 手机APP-MCP走蓝牙无线遥控智能安全帽~执法记录仪~拍照录像,并可做基础的配置,例如修改服务器IP以及配置WiFi等, AIoT万物智联,智能安全帽…...
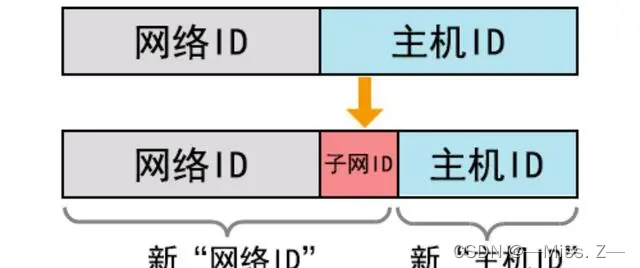
网络互联与IP地址
目录 网络互联概述网络的定义与分类网络的定义网络的分类 OSI模型和DoD模型网络拓扑结构总线型拓扑结构星型拓扑结构环型拓扑结构 传输介质同轴电缆双绞线光纤 介质访问控制方式CSMA/CD令牌 网络设备网卡集线器交换机路由器总结 IP地址A、B、C类IP地址特殊地址形式 子网与子网掩…...
Android设计模式--模板方法模式
一,定义 定义一个操作中的算法的框架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 在面向对象的开发过程中,通常会遇到这样一个问题,我们知道一个算法所需的关键步…...

大语言模型——BERT和GPT的那些事儿
前言 自然语言处理是人工智能的一个分支。在自然语言处理领域,有两个相当著名的大语言模型——BERT和GPT。两个模型是同一年提出的,那一年BERT以不可抵挡之势,让整个人工智能届为之震动。据说当年BERT的影响力是GPT的十倍以上。而现在&#…...

Docker 命令详解
1. 容器生命周期管理 命令说明文档run创建一个新的容器并运行一个命令Docker run 命令start/stop/restart启动、停止、重启容器Docker start/stop/restart 命令kill杀掉一个运行中的容器Docker kill 命令rm删除一个或多个容器Docker rm 命令pause/unpause暂停 恢复容器中所有的…...
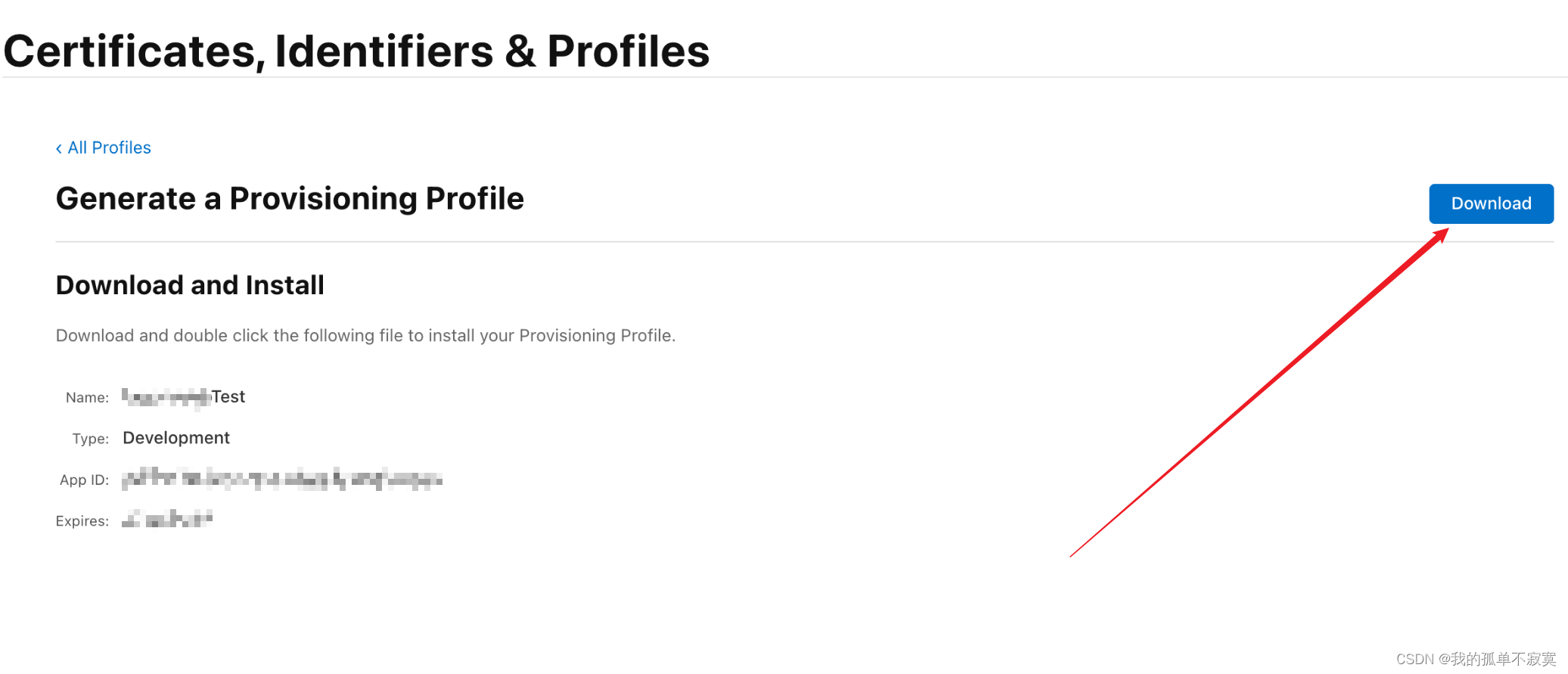
ios打包,证书获取
HBuilderX 打包ios界面: Bundle ID(AppID): 又称应用ID,是每一个ios应用的唯一标识,就像一个人的身份证号码; 每开发一个新应用,首先都需要先去创建一个Bundle ID Bundle ID 格式: 一般为&…...

linux(nginx安装配置,tomcat服务命令操作)
首先进系统文件夹 /usr/lib/systemd/systemLs | grep mysql 查看带有命名有MySQL的文件夹修改tomcat.service文件复制jdk目录替换成我们的路径替换成我们的路径进入这个目录,把修改好的文件拖到我们的工具里面重新刷新系统 systemctl daemon-reload查看tomcat状态…...

jQuery_03 dom对象和jQuery对象的互相转换
dom对象和jQuery对象 dom对象 jQuery对象 在一个文件中同时存在两种对象 dom对象: 通过js中的document对象获取的对象 或者创建的对象 jQuery对象: 通过jQuery中的函数获取的对象。 为什么使用dom或jQuery对象呢? 目的是 要使用dom对象的函数或者属性 以及呢 要…...

Mysql 中如何导入数据?
文章目录 前言使用 LOAD DATA 导入数据使用 mysqlimport 导入数据mysqlimport的常用选项介绍后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有很多知识和技术需要掌握,正…...
深入了解前馈网络、CNN、RNN 和 Hugging Face 的 Transformer 技术!
一、说明 本篇在此对自然语言模型做一个简短总结,从CNN\RNN\变形金刚,和抱脸的变形金刚库说起。 二、基本前馈神经网络: 让我们分解一个基本的前馈神经网络,也称为多层感知器(MLP)。此代码示例将࿱…...
)
跳出“暴力美学”:一个模块化、类脑的大模型架构构想(大模型的思考:三)
跳出“暴力美学”之后:一次模块化大模型构想的自我纠偏与落地思考从“同步振荡”到“语法骨架”,从“词不达意”到失语症证据——一场关于解耦智能的思想实验如何走向严谨写在前面之前,我发表了一篇《跳出“暴力美学”:一个模块化…...

万象视界灵坛一文详解:像素风UI如何降低多模态分析认知负荷
万象视界灵坛一文详解:像素风UI如何降低多模态分析认知负荷 1. 多模态分析的认知挑战 现代多模态分析系统面临一个核心矛盾:技术越强大,界面往往越复杂。传统视觉识别平台通常采用专业术语密集的仪表盘和数据表格,这种设计虽然精…...

告别枯燥实验报告!用Multisim仿真RLC交流电路,手把手教你复现92分实验数据
用Multisim玩转RLC交流电路:从理论到仿真的实战指南 在电子工程领域,RLC电路是理解交流电特性的重要基石。传统实验室里,学生们需要面对一堆实体仪器和复杂的接线过程,稍有不慎就会得到错误数据。而借助NI Multisim这款强大的电路…...

LLM Compressor性能优化:如何选择最佳的压缩方案和硬件配置
LLM Compressor性能优化:如何选择最佳的压缩方案和硬件配置 【免费下载链接】llm-compressor Transformers-compatible library for applying various compression algorithms to LLMs for optimized deployment with vLLM 项目地址: https://gitcode.com/gh_mirr…...

2025全新指南:零代码优化AI代理的Azure搜索服务配置
2025全新指南:零代码优化AI代理的Azure搜索服务配置 【免费下载链接】ai-agents-for-beginners 12 Lessons to Get Started Building AI Agents 项目地址: https://gitcode.com/GitHub_Trending/ai/ai-agents-for-beginners 在AI应用开发中,Azure…...
和T5(T507)在智能车载与工业HMI场景下的真实表现差异)
别只看主频!全志T3(A40I)和T5(T507)在智能车载与工业HMI场景下的真实表现差异
全志T3与T5芯片在智能车载与工业HMI中的实战选型指南 当工程师面对智能车载中控和工业人机界面(HMI)这两类截然不同的应用场景时,芯片选型往往成为决定产品成败的关键。全志T3(A40I)和T5(T507)作为两款定位不同的处理器,在实际应用中展现出的差异远比参数…...

Pearcleaner:为你的Mac来一次彻底的数字大扫除
Pearcleaner:为你的Mac来一次彻底的数字大扫除 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经疑惑过,为什么删除了一个应…...

RoboMaster备赛神器:除了搭裁判系统,RM Referee Aid的局域网文件传输功能也太香了!
RoboMaster战队协作利器:RM Referee Aid的隐藏文件传输功能实战指南 在RoboMaster战队备战过程中,技术文档、代码更新、调试日志的快速共享往往成为影响效率的关键环节。当十余名队员同时修改同一份机械图纸,或是操作手需要在训练间隙获取最新…...

Hook实战:从零手写一个通用Debugger拦截器,支持Chrome插件与油猴脚本
通用Debugger拦截器实战:从原型污染到浏览器插件开发 打开Chrome开发者工具时,你是否曾被突如其来的无限debugger打断调试节奏?那些隐藏在混淆代码中的定时器陷阱、递归调用和原型链污染,常常让逆向分析变成一场猫鼠游戏。但今天&…...

Ofd2Pdf终极指南:5分钟掌握OFD转PDF的3种高效方法
Ofd2Pdf终极指南:5分钟掌握OFD转PDF的3种高效方法 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 在数字办公时代,OFD作为中国自主的电子文档格式标准,在政务、金融…...