【Pytorch】Visualization of Fature Maps(2)

学习参考来自
- 使用CNN在MNIST上实现简单的攻击样本
- https://github.com/wmn7/ML_Practice/blob/master/2019_06_03/CNN_MNIST%E5%8F%AF%E8%A7%86%E5%8C%96.ipynb
文章目录
- 在 MNIST 上实现简单的攻击样本
- 1 训练一个数字分类网络
- 2 控制输出的概率, 看输入是什么
- 3 让正确的图片分类错误
在 MNIST 上实现简单的攻击样本
要看某个filter在检测什么,我们让通过其后的输出激活值较大。
想要一些攻击样本,有一个简单的想法就是让最后结果中是某一类的概率值变大,接着进行反向传播(固定住网络的参数),去修改input
原理图:

1 训练一个数字分类网络
模型基础数据、超参数的配置
import time
import csv, osimport PIL.Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
from cv2 import resizeimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data.sampler import SubsetRandomSampler
from torch.autograd import Variableimport copy
import torchvision
import torchvision.transforms as transforms
os.environ["CUDA_VISIBLE_DEVICES"] = "1"# --------------------
# Device configuration
# --------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# ----------------
# Hyper-parameters
# ----------------
num_classes = 10
num_epochs = 3
batch_size = 100
validation_split = 0.05 # 每次训练集中选出10%作为验证集
learning_rate = 0.001# -------------
# MNIST dataset
# -------------
train_dataset = torchvision.datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)test_dataset = torchvision.datasets.MNIST(root='./',train=False,transform=transforms.ToTensor())
# -----------
# Data loader
# -----------
test_len = len(test_dataset) # 计算测试集的个数 10000
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)for (inputs, labels) in test_loader:print(inputs.size()) # [100, 1, 28, 28]print(labels.size()) # [100]break# ------------------
# 下面切分validation
# ------------------
dataset_len = len(train_dataset) # 60000
indices = list(range(dataset_len))
# Randomly splitting indices:
val_len = int(np.floor(validation_split * dataset_len)) # validation的长度
validation_idx = np.random.choice(indices, size=val_len, replace=False) # validatiuon的index
train_idx = list(set(indices) - set(validation_idx)) # train的index
## Defining the samplers for each phase based on the random indices:
train_sampler = SubsetRandomSampler(train_idx)
validation_sampler = SubsetRandomSampler(validation_idx)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,sampler=train_sampler,batch_size=batch_size)
validation_loader = torch.utils.data.DataLoader(train_dataset,sampler=validation_sampler,batch_size=batch_size)
train_dataloaders = {"train": train_loader, "val": validation_loader} # 使用字典的方式进行保存
train_datalengths = {"train": len(train_idx), "val": val_len} # 保存train和validation的长度
搭建简单的神经网络
# -------------------------------------------------------
# Convolutional neural network (two convolutional layers)
# -------------------------------------------------------
class ConvNet(nn.Module):def __init__(self, num_classes=10):super(ConvNet, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.layer2 = nn.Sequential(nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.fc = nn.Linear(7*7*32, num_classes)def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = out.reshape(out.size(0), -1)out = self.fc(out)return out
绘制损失和精度变化曲线
# -----------
# draw losses
# -----------
def draw_loss_acc(train_list, validation_list, mode="loss"):plt.style.use("seaborn")# set interdata_len = len(train_list)x_ticks = np.arange(1, data_len + 1)plt.xticks(x_ticks)if mode == "Loss":plt.plot(x_ticks, train_list, label="Train Loss")plt.plot(x_ticks, validation_list, label="Validation Loss")plt.xlabel("Epoch")plt.ylabel("Loss")plt.legend()plt.savefig("Epoch_loss.jpg")elif mode == "Accuracy":plt.plot(x_ticks, train_list, label="Train AccuracyAccuracy")plt.plot(x_ticks, validation_list, label="Validation Accuracy")plt.xlabel("Epoch")plt.ylabel("Accuracy")plt.legend()plt.savefig("Epoch_Accuracy.jpg")
定义训练模型的函数
# ---------------
# Train the model
# ---------------
def train_model(model, criterion, optimizer, dataloaders, train_datalengths, scheduler=None, num_epochs=2):"""传入的参数分别是:1. model:定义的模型结构2. criterion:损失函数3. optimizer:优化器4. dataloaders:training dataset5. train_datalengths:train set和validation set的大小, 为了计算准确率6. scheduler:lr的更新策略7. num_epochs:训练的epochs"""since = time.time()# 保存最好一次的模型参数和最好的准确率best_model_wts = copy.deepcopy(model.state_dict())best_acc = 0.0train_loss = [] # 记录每一个epoch后的train的losstrain_acc = []validation_loss = []validation_acc = []for epoch in range(num_epochs):print('Epoch [{}/{}]'.format(epoch + 1, num_epochs))print('-' * 10)# Each epoch has a training and validation phasefor phase in ['train', 'val']:if phase == 'train':if scheduler != None:scheduler.step()model.train() # Set model to training modeelse:model.eval() # Set model to evaluate moderunning_loss = 0.0 # 这个是一个epoch积累一次running_corrects = 0 # 这个是一个epoch积累一次# Iterate over data.total_step = len(dataloaders[phase])for i, (inputs, labels) in enumerate(dataloaders[phase]):# inputs = inputs.reshape(-1, 28*28).to(device)inputs = inputs.to(device)labels = labels.to(device)# zero the parameter gradientsoptimizer.zero_grad()# forward# track history if only in trainwith torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1) # 使用output(概率)得到预测loss = criterion(outputs, labels) # 使用output计算误差# backward + optimize only if in training phaseif phase == 'train':loss.backward()optimizer.step()# statisticsrunning_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)if (i + 1) % 100 == 0:# 这里相当于是i*batch_size的样本个数打印一次, i*100iteration_loss = loss.item() / inputs.size(0)iteration_acc = 100 * torch.sum(preds == labels.data).item() / len(preds)print('Mode {}, Epoch [{}/{}], Step [{}/{}], Accuracy: {}, Loss: {:.4f}'.format(phase, epoch + 1,num_epochs, i + 1,total_step,iteration_acc,iteration_loss))epoch_loss = running_loss / train_datalengths[phase]epoch_acc = running_corrects.double() / train_datalengths[phase]if phase == 'train':train_loss.append(epoch_loss)train_acc.append(epoch_acc)else:validation_loss.append(epoch_loss)validation_acc.append(epoch_acc)print('*' * 10)print('Mode: [{}], Loss: {:.4f}, Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print('*' * 10)# deep copy the modelif phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())print()time_elapsed = time.time() - sinceprint('*' * 10)print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))print('*' * 10)# load best model weightsfinal_model = copy.deepcopy(model) # 最后得到的modelmodel.load_state_dict(best_model_wts) # 在验证集上最好的modeldraw_loss_acc(train_list=train_loss, validation_list=validation_loss, mode='Loss') # 绘制Loss图像draw_loss_acc(train_list=train_acc, validation_list=validation_acc, mode='Accuracy') # 绘制准确率图像return (model, final_model)
开始训练,并保存模型
if __name__ == "__main__":# 模型初始化model = ConvNet(num_classes=num_classes).to(device)# 打印模型结构#print(model)"""ConvNet((layer1): Sequential((0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(layer2): Sequential((0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(fc): Linear(in_features=1568, out_features=10, bias=True))"""# -------------------# Loss and optimizer# ------------------criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# -------------# 进行模型的训练# -------------(best_model, final_model) = train_model(model=model, criterion=criterion, optimizer=optimizer,dataloaders=train_dataloaders, train_datalengths=train_datalengths,num_epochs=num_epochs)"""Epoch [1/3]----------Mode train, Epoch [1/3], Step [100/570], Accuracy: 96.0, Loss: 0.0012Mode train, Epoch [1/3], Step [200/570], Accuracy: 96.0, Loss: 0.0011Mode train, Epoch [1/3], Step [300/570], Accuracy: 100.0, Loss: 0.0004Mode train, Epoch [1/3], Step [400/570], Accuracy: 100.0, Loss: 0.0003Mode train, Epoch [1/3], Step [500/570], Accuracy: 96.0, Loss: 0.0010**********Mode: [train], Loss: 0.1472, Acc: 0.9579********************Mode: [val], Loss: 0.0653, Acc: 0.9810**********Epoch [2/3]----------Mode train, Epoch [2/3], Step [100/570], Accuracy: 99.0, Loss: 0.0005Mode train, Epoch [2/3], Step [200/570], Accuracy: 98.0, Loss: 0.0003Mode train, Epoch [2/3], Step [300/570], Accuracy: 98.0, Loss: 0.0003Mode train, Epoch [2/3], Step [400/570], Accuracy: 97.0, Loss: 0.0005Mode train, Epoch [2/3], Step [500/570], Accuracy: 98.0, Loss: 0.0004**********Mode: [train], Loss: 0.0470, Acc: 0.9853********************Mode: [val], Loss: 0.0411, Acc: 0.9890**********Epoch [3/3]----------Mode train, Epoch [3/3], Step [100/570], Accuracy: 99.0, Loss: 0.0006Mode train, Epoch [3/3], Step [200/570], Accuracy: 99.0, Loss: 0.0009Mode train, Epoch [3/3], Step [300/570], Accuracy: 98.0, Loss: 0.0004Mode train, Epoch [3/3], Step [400/570], Accuracy: 99.0, Loss: 0.0003Mode train, Epoch [3/3], Step [500/570], Accuracy: 100.0, Loss: 0.0002**********Mode: [train], Loss: 0.0348, Acc: 0.9890********************Mode: [val], Loss: 0.0432, Acc: 0.9867********************Training complete in 0m 32sBest val Acc: 0.989000**********"""torch.save(model, 'CNN_MNIST.pkl')
训练完的 loss 和 acc 曲线


载入模型进行简单的测试,以下面这张 7 为例子

model = torch.load('CNN_MNIST.pkl')
# print(test_dataset.data[0].shape) # torch.Size([28, 28])
# print(test_dataset.targets[0]) # tensor(7)
#
unload = transforms.ToPILImage()
img = unload(test_dataset.data[0])
img.save("test_data_0.jpg")# 带入模型进行预测
inputdata = test_dataset.data[0].view(1,1,28,28).float()/255
inputdata = inputdata.to(device)
outputs = model(inputdata)
print(outputs)
"""
tensor([[ -7.4075, -3.4618, -1.5322, 1.1591, -10.6026, -5.5818, -17.4020,14.6429, -4.5378, 1.0360]], device='cuda:0',grad_fn=<AddmmBackward0>)
"""
print(torch.max(outputs, 1))
"""
torch.return_types.max(
values=tensor([14.6429], device='cuda:0', grad_fn=<MaxBackward0>),
indices=tensor([7], device='cuda:0'))
"""
OK,预测结果正常,为 7
2 控制输出的概率, 看输入是什么
步骤
- 初始随机一张图片
- 我们希望让分类中某个数的概率最大
- 最后看一下这个网络认为什么样的图像是这个数字
# hook类的写法
class SaveFeatures():"""注册hook和移除hook"""def __init__(self, module):self.hook = module.register_forward_hook(self.hook_fn)def hook_fn(self, module, input, output):# self.features = output.clone().detach().requires_grad_(True)self.features = output.clone()def close(self):self.hook.remove()
下面开始操作
# hook住模型
layer = 2
activations = SaveFeatures(list(model.children())[layer])# 超参数
lr = 0.005 # 学习率
opt_steps = 100 # 迭代次数
upscaling_factor = 10 # 放大的倍数(为了最后图像的保存)# 保存迭代后的数字
true_nums = []
random_init, num_init = 1, 0 # the type of initial# 带入网络进行迭代
for true_num in range(0, 10):# 初始化随机图片(数据定义和优化器一定要在一起)# 定义数据sz = 28if random_init:img = np.uint8(np.random.uniform(0, 255, (1,sz, sz))) / 255img = torch.from_numpy(img[None]).float().to(device)img_var = Variable(img, requires_grad=True)if num_init:# 将7变成0,1,2,3,4,5,6,7,8,9img = test_dataset.data[0].view(1, 1, 28, 28).float() / 255img = img.to(device)img_var = Variable(img, requires_grad=True)# 定义优化器optimizer = torch.optim.Adam([img_var], lr=lr, weight_decay=1e-6)for n in range(opt_steps): # optimize pixel values for opt_steps timesoptimizer.zero_grad()model(img_var) # 正向传播if random_init:loss = -activations.features[0, true_num] # 这里的loss确保某个值的输出大if num_init:loss = -activations.features[0, true_num] + F.mse_loss(img_var, img) # 这里的loss确保某个值的输出大, 并且与原图不会相差很多loss.backward()optimizer.step()# 打印最后的img的样子print(activations.features[0, true_num]) # tensor(23.8736, device='cuda:0', grad_fn=<SelectBackward0>)print(activations.features[0])"""tensor([ 23.8736, -32.0724, -5.7329, -18.6501, -16.1558, -18.9483, -0.3033,-29.1561, 14.9260, -13.5412], device='cuda:0',grad_fn=<SelectBackward0>)"""print('========')img = img_var.cpu().clone()img = img.squeeze(0)# 图像的裁剪(确保像素值的范围)img[img > 1] = 1img[img < 0] = 0true_nums.append(img)unloader = transforms.ToPILImage()img = unloader(img)img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)sz = int(upscaling_factor * sz) # calculate new image sizeimg = cv2.resize(img, (sz, sz), interpolation=cv2.INTER_CUBIC) # scale image upif random_init:cv2.imwrite('random_regonize{}.jpg'.format(true_num), img)if num_init:cv2.imwrite('real7_regonize{}.jpg'.format(true_num), img)"""========tensor(22.3530, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-22.4025, 22.3530, 6.0451, -9.4460, -1.0577, -17.7650, -11.3686,-11.8474, -5.5310, -16.9936], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(50.2202, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-16.9364, -16.5120, 50.2202, -9.5287, -25.2837, -32.3480, -22.8569,-20.1231, 1.1174, -31.7244], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(48.8004, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-33.3715, -30.5732, -6.0252, 48.8004, -34.9467, -17.8136, -35.1371,-17.4484, 2.8954, -11.9694], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(31.5068, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-24.5204, -13.6857, -5.1833, -22.7889, 31.5068, -20.2855, -16.7245,-19.1719, 2.4699, -16.2246], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(37.4866, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-20.2235, -26.1013, -25.9511, -2.7806, -19.5546, 37.4866, -10.8689,-30.3888, 0.1591, -8.5250], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(35.9310, device='cuda:0', grad_fn=<SelectBackward0>)tensor([ -6.1996, -31.2246, -8.3396, -21.6307, -16.9098, -9.5194, 35.9310,-33.0918, 10.2462, -28.6393], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(23.6772, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-21.5441, -10.3366, -4.9905, -0.9289, -6.9219, -23.5643, -23.9894,23.6772, -0.7960, -16.9556], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(57.8378, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-13.5191, -53.9004, -9.2996, -10.3597, -27.3806, -27.5858, -15.3235,-46.7014, 57.8378, -17.2299], device='cuda:0',grad_fn=<SelectBackward0>)========tensor(37.0334, device='cuda:0', grad_fn=<SelectBackward0>)tensor([-26.2983, -37.7131, -16.6210, -1.8686, -11.5330, -11.7843, -25.7539,-27.0036, 6.3785, 37.0334], device='cuda:0',grad_fn=<SelectBackward0>)========"""
# 移除hook
activations.close()for i in range(0,10):_ , pre = torch.max(model(true_nums[i][None].to(device)),1)print("i:{},Pre:{}".format(i,pre))"""i:0,Pre:tensor([0], device='cuda:0')i:1,Pre:tensor([1], device='cuda:0')i:2,Pre:tensor([2], device='cuda:0')i:3,Pre:tensor([3], device='cuda:0')i:4,Pre:tensor([4], device='cuda:0')i:5,Pre:tensor([5], device='cuda:0')i:6,Pre:tensor([6], device='cuda:0')i:7,Pre:tensor([7], device='cuda:0')i:8,Pre:tensor([8], device='cuda:0')i:9,Pre:tensor([9], device='cuda:0')"""

可以看到相应最高的图片的样子,依稀可以看见 0,1,2,3,4,5,6,7,8,9 的轮廓
3 让正确的图片分类错误
步骤如下
- 使用特定数字的图片,如数字7(初始化方式与前面的不一样,是特定而不是随机)
- 使用上面训练好的网络,固定网络参数;
- 最后一层因为是10个输出(相当于是概率), 我们 loss 设置为某个的负的概率值(利于梯度下降)
- 梯度下降, 使负的概率下降,即相对应的概率值上升,我们最终修改的是初始的图片
- 这样使得网络认为这张图片识别的数字的概率增加
简单描述,输入图片数字7,固定网络参数,让其他数字的概率不断变大,改变输入图片,最终达到迷惑网络的目的
只要将第二节中的代码 random_init, num_init = 1, 0 # the type of initial 改为 random_init, num_init = 0, 1 # the type of initial 即可

成功用 7 迷惑了所有类别
注意损失函数中还额外引入了 F.mse_loss(img_var, img) ,确保某个数字类别的概率输出增大, 并且与原图数字 7 像素上不会相差很多
相关文章:
【Pytorch】Visualization of Fature Maps(2)
学习参考来自 使用CNN在MNIST上实现简单的攻击样本https://github.com/wmn7/ML_Practice/blob/master/2019_06_03/CNN_MNIST%E5%8F%AF%E8%A7%86%E5%8C%96.ipynb 文章目录 在 MNIST 上实现简单的攻击样本1 训练一个数字分类网络2 控制输出的概率, 看输入是什么3 让正确的图片分…...
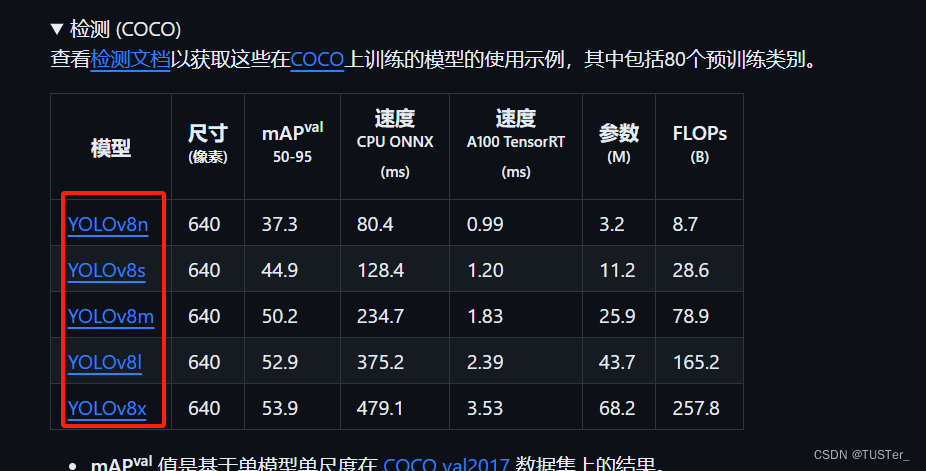
【目标检测】保姆级别教程从零开始实现基于Yolov8的一次性筷子计数
前言 一,环境配置 一,虚拟环境创建 二,安装资源包 前言 最近事情比较少,无意间刷到群聊里分享的基于百度飞浆平台的一次性筷子检测,感觉很有意思,恰巧自己最近在学习Yolov8,于是看看能不能复…...
笔记:内网渗透流程之信息收集
信息收集 首先,收集目标内网的信息,包括子网结构、域名信息、IP地址范围、开放的端口和服务等。这包括通过主动扫描和渗透测试工具收集信息,以及利用公开的信息源进行信息搜集。 本机信息收集 查看系统配置信息 查看系统详细信息…...
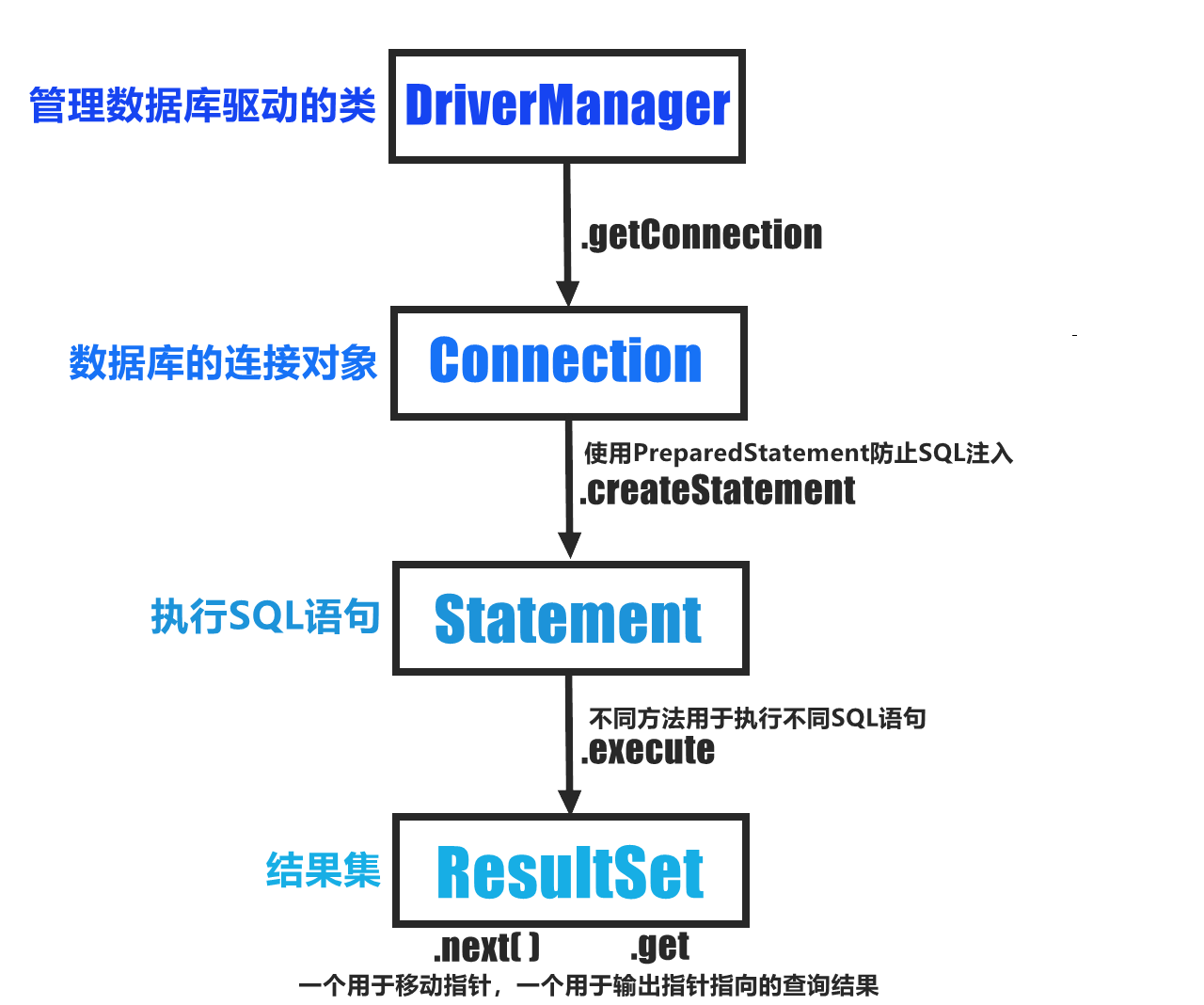
【2023.11.23】JDBC基本连接语法学习➹
1.导入jar包依赖:mysql-connector-java-8.0.27.jar 2.连接数据库! 3.无法解析类->导入java.sql.*,(将项目方言改为Mysql) JDBC,启动!! public class Main {public static voi…...

ubuntu 安装python3.13
列出 /usr/bin/ 目录下所有以 python 开头的文件和目录 ls /usr/bin/python* 添加Python软件源。您可以通过以下命令将Python的软件源添加到您的系统中 sudo add-apt-repository ppa:deadsnakes/ppa 然后运行以下命令以更新软件包列表: sudo apt-get update 安…...

OpenCV数据类型及CV_16UC1深度图ros订阅
最近用到深度图,对其数据类型及显示有些迷惑,记笔记于此: 目录 一、cv::Mat 的数据类型及转换方式1. cv::Mat 数据类型2. cv::Mat 数据类型互转2.1 OpenCV数据类型转换的函数2.2 可视化深度图像(CV_16UC1)二、cv::Mat 与 sensor_msgs::msg::Image 互转(基于cv_bridge)1.…...
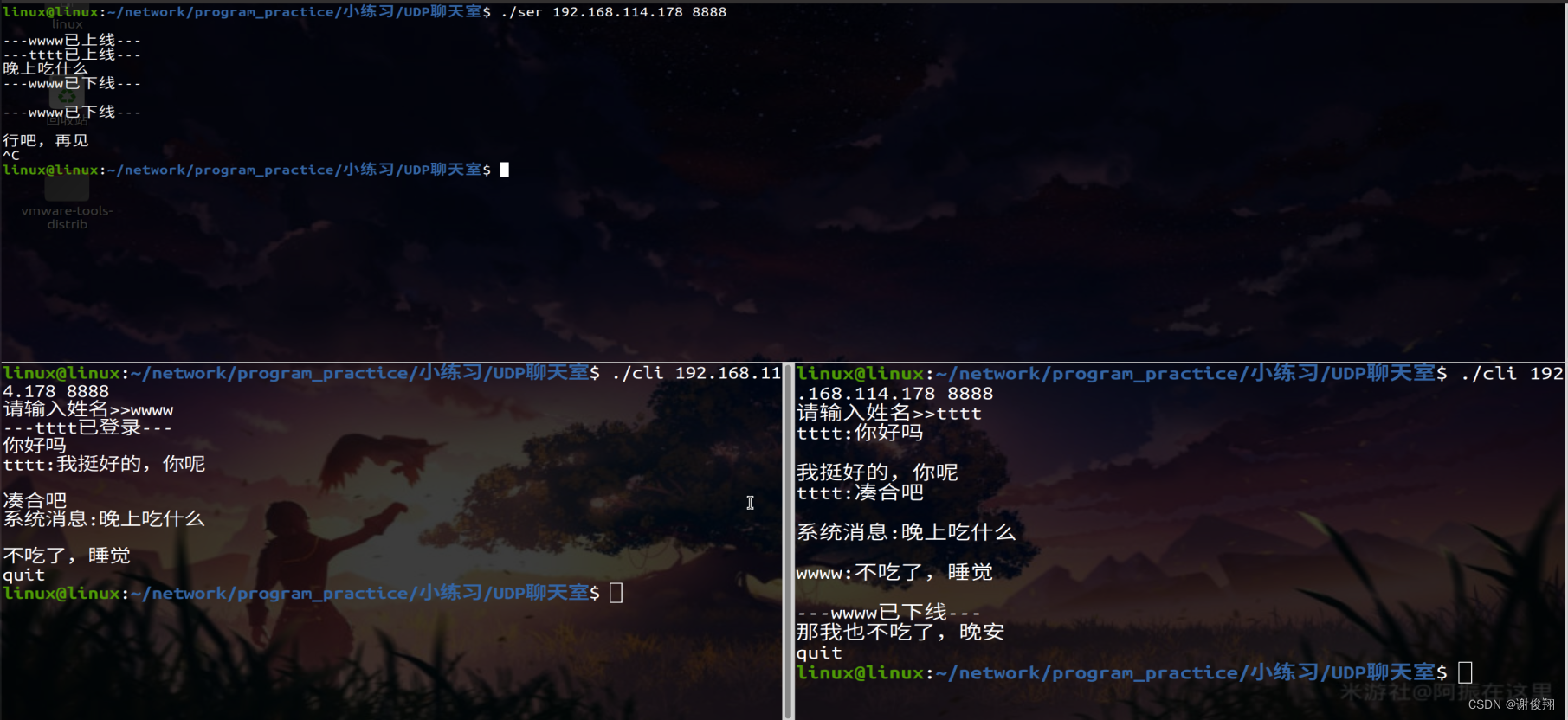
华清远见嵌入式学习——网络编程——小项目
项目要求: 代码实现: 服务器端: #include <myhead.h>//定义协议包 struct proto {char type;char name[20];char text[128]; };int main(int argc, const char *argv[]) {//判断从终端输入的字符串的个数if(argc ! 3){printf("…...

分库分表、分布式数据库、MPP
分库分表、分布式数据库、MPP的区别吗? 一、MySQL分库分表和MySQL分布式集群在性能方面各有优劣,具体取决于应用场景和需求。 MySQL分库分表: 在分库分表的场景下,可以将负载分散到多个数据库实例上,从而提高整体性能…...
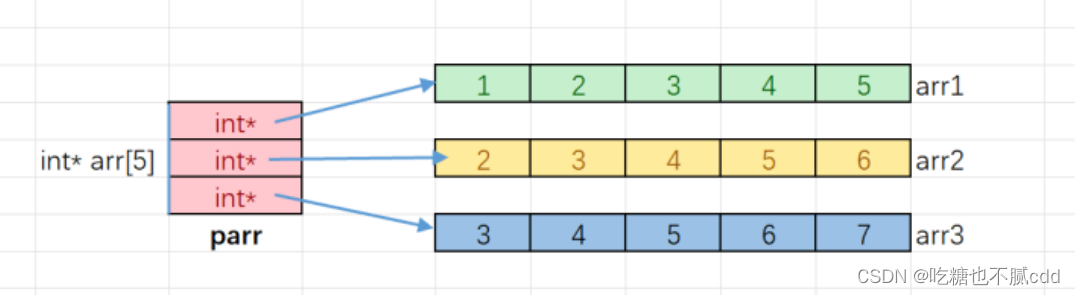
浅学指针(2)数组函数传值调用
系列文章目录 文章目录 系列文章目录前言1. 指针的使⽤和传址调⽤结论:实参传递给形参的时候,形参会单独创建⼀份临时空间来接收实参,对形参的修改不影响实 参。那么这个时候,就要搬出指针大哥,在main函数中将a和b的地…...
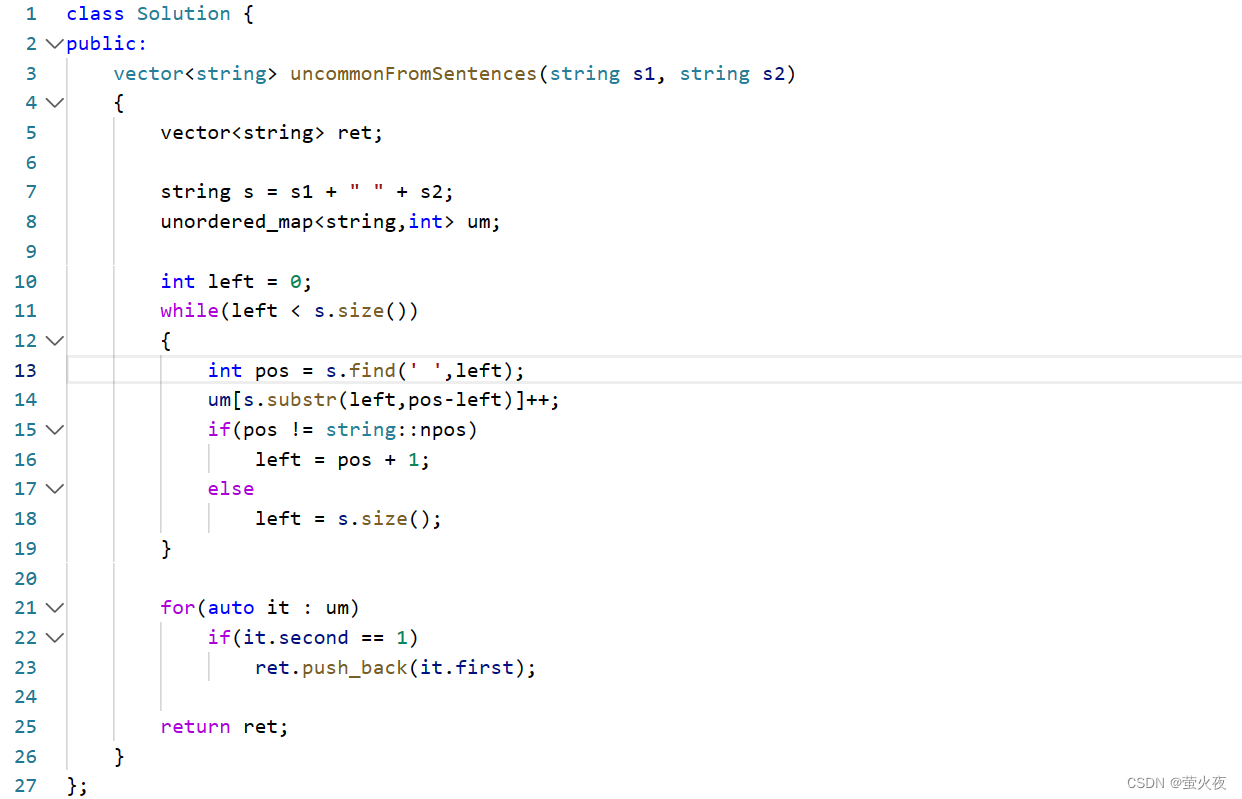
C++之unordered_map/set的使用
前面我们已经学习了STL中底层为红黑树结构的一系列关联式容器——set/multiset 和 map/multimap(C98). unordered系列关联式容器 在C98中, STL提供了底层为红黑树结构的一系列关联式容器, 在查询时效率可达到log2N,即最差情况下需要比较红黑树的高度次, 当树中的节点非常多时,…...
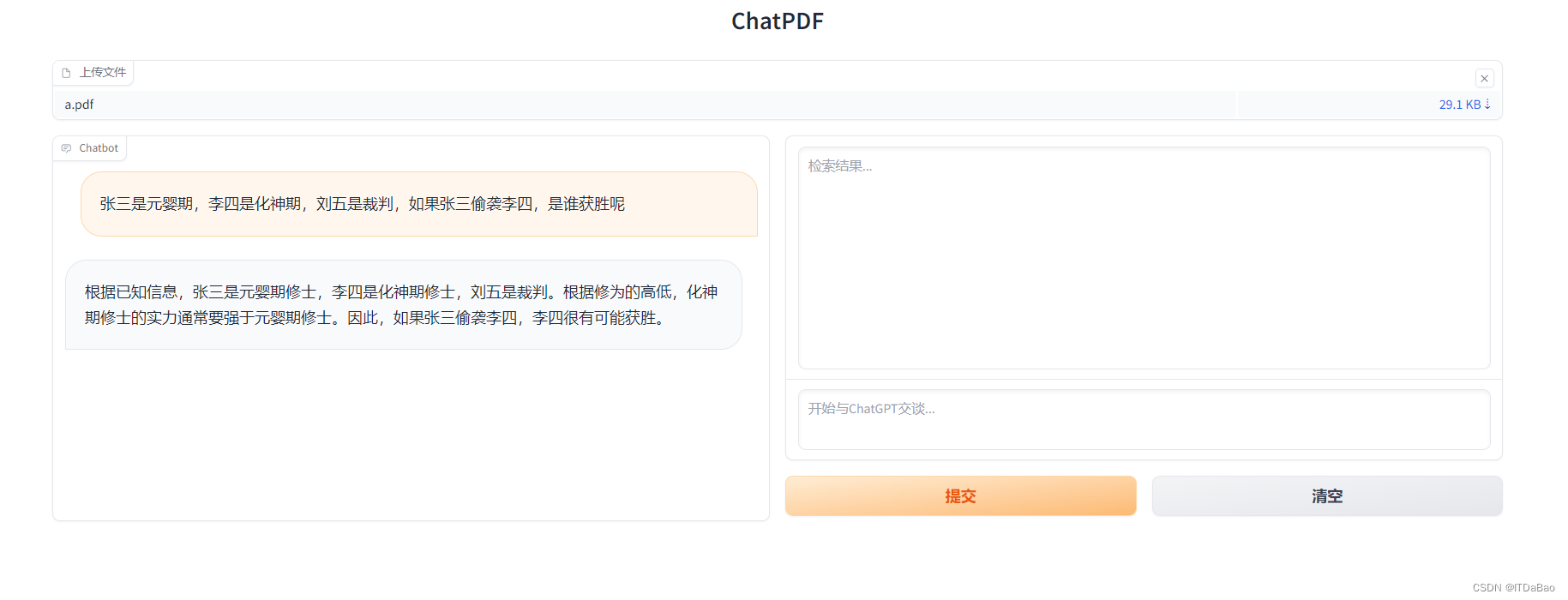
docker打包chatpdf(自写)
docker打包上传 docker build -t kitelff/chatpdf:v0.1 .##修改镜像名字 docker tag c2c1a0eb4e08 kitelff/chatpdf:v0.1## push docker push kitelff/chatpdf:v0.1上传文件,测试效果...
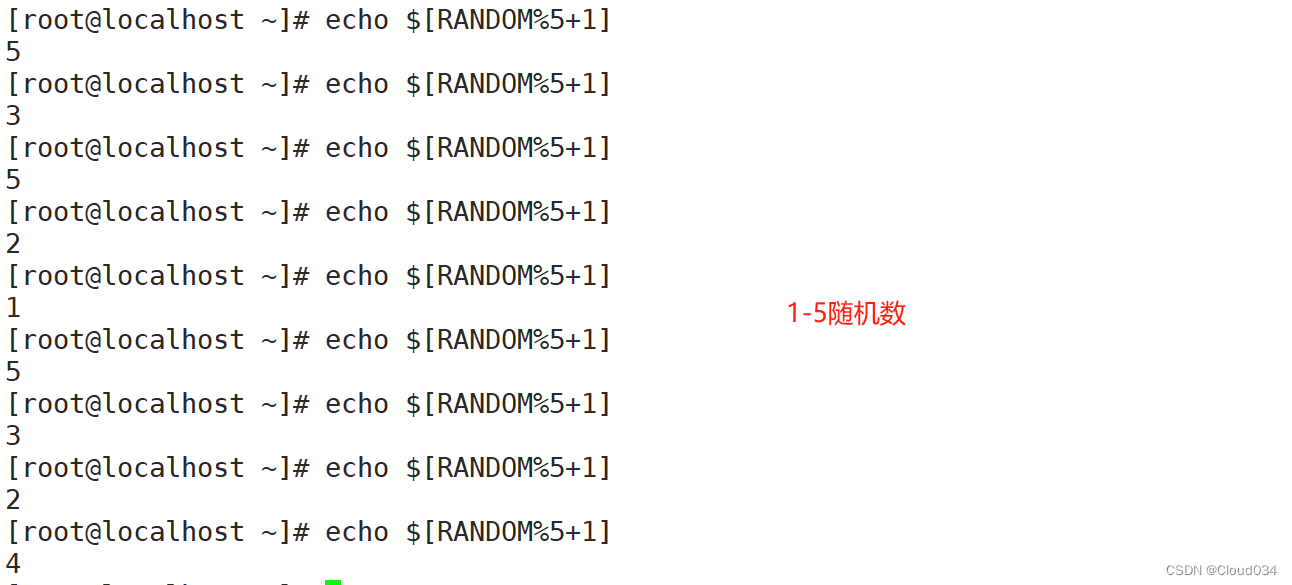
shell基础
一.Shell脚本编程概述 1.基本概念 将要执行的命令按顺序保存到一个文本文件; 给该文件可执行权限; 可结合各种Shell控制语句以完成更复杂的操作。 2.作用 Linux系统中的Shell是一个特殊的应用程序,它介于操作系统内核与用户之间&#x…...
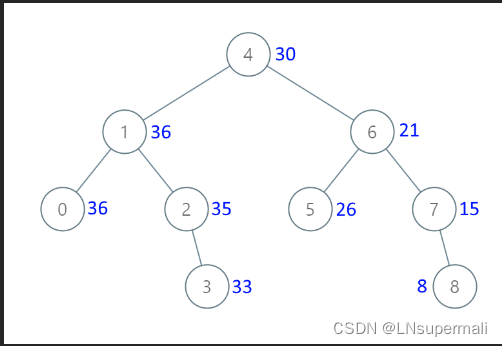
力扣1038. 从二叉搜索树到更大和树(java,树的中序遍历解法)
Problem: 1038. 从二叉搜索树到更大和树 文章目录 题目描述思路解题方法复杂度Code 题目描述 给定一个二叉搜索树 root (BST),请将它的每个节点的值替换成树中大于或者等于该节点值的所有节点值之和。 提醒一下, 二叉搜索树 满足下列约束条件ÿ…...

使用正则表达式来判断一个字符串只是否包含数字
使用正则表达式来判断一个字符串只是否包含数字 1、第一种 import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String inputString "12345";if (containsOnlyDigits(inputString)) {System.out.println("字符串只…...

C#Wpf关于日志的相关功能扩展
目录 一、日志Sink(接收器) 二、Trace追踪实现日志 三、日志滚动 一、日志Sink(接收器) 安装NuGet包:Serilog Sink有很多种,这里介绍两种: Console接收器(安装Serilog.Sinks.Console); File接收器(安装…...
亚马逊云科技AI创新应用下的托管在AWS上的数据可视化工具—— Amazon QuickSight
目录 Amazon QuickSight简介 Amazon QuickSight的独特之处 Amazon QuickSight注册 Amazon QuickSight使用 Redshift和Amazon QuickSightt平台构建数据可视化应用程序 构建数据仓库 数据可视化 Amazon QuickSight简介 亚马逊QuickSight是一项可用于交付的云级商业智能 (BI…...

MySQL安全性:用户认证、防范SQL注入和SSL/TLS配置详解
MySQL作为广泛使用的关系型数据库管理系统,安全性至关重要。在本篇技术博客中,我们将深入探讨MySQL的用户认证方式、防范SQL注入攻击的方法以及SSL/TLS加密的配置。 1. MySQL用户认证方式 MySQL支持多种用户认证方式,其中两种常见方式是cac…...
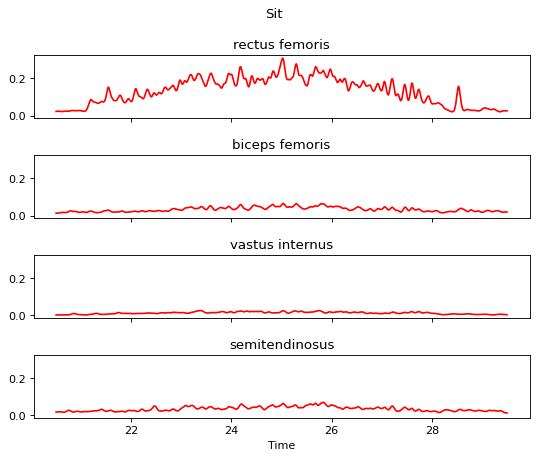
EMG肌肉信号处理合集 (一)
本文归纳了常见的肌肉信号预处理流程,方便EMG信号的后续分析。使用pyemgpipeline库 来进行信号的处理。文中使用了 UC Irvine 数据库的下肢数据。 目录 1 使用wrappers 定义数据类,来进行后续的操作 2 肌电信号DC偏置去除 3 带通滤波器处理 4 对肌电…...

学自动化测试?我劝你还是算了吧。。。
本人7年测试经验,在学测试之前对电脑的认知也就只限于上个网,玩个办公软件。这里不能跑题,我为啥说:自学软件测试,一般人我还是劝你算了吧?因为我就是那个一般人! 软件测试基础真的很简单&…...

第一百七十八回 介绍一个三方包组件:SlideSwitch
文章目录 1. 概念介绍2. 使用方法3. 代码与效果3.1 示例代码3.2 运行效果 4. 内容总结 我们在上一章回中介绍了"如何创建垂直方向的Switch"相关的内容,本章回中将 介绍SlideSwitch组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们…...

Python Playwright 安装
官方文档 https://playwright.net.cn/python/docs/actionability 1,Pip 安装 # 安装 Playwright 库 pip install playwright# 自动安装浏览器二进制文件(Chromium/Firefox/WebKit) playwright install playwright install 默认安装全部 3 …...

终极Docker镜像优化指南:如何用Dive解决权限难题并提升存储效率
终极Docker镜像优化指南:如何用Dive解决权限难题并提升存储效率 【免费下载链接】dive A tool for exploring each layer in a docker image 项目地址: https://gitcode.com/GitHub_Trending/di/dive Docker镜像优化是每个开发者必须掌握的技能,而…...
)
PAT/PTA刷题实战:L1-027‘出租’题的三种解法与效率对比(C语言实现)
L1-027‘出租’题的三种解法与效率对比(C语言实现) 当你面对PTA题库中的L1-027题时,是否曾思考过如何用更高效的方式解决这个看似简单的电话号码转换问题?本文将带你深入探讨三种不同的C语言实现方案,从基础的冒泡排序…...

力诺特玻亮相第139届广交会 展示中国耐热玻璃硬核实力
4月23日,第139届中国进出口商品交易会第二期“品质家居”主题展正式开幕。本届展会紧扣“新、绿、智”主线,聚焦新兴赛道与未来产业,深度对接全球采购新趋势。深耕高硼硅耐热玻璃30年,力诺特玻(301188.SZ)携…...

Vector-Graph-RAG-用一套向量库搞定多跳问答无需图数据库
用一套向量库搞定多跳问答:Vector Graph RAG 的工程哲学方向:AI / RAG工程 / 向量数据库做过 RAG 的工程师,大概都被"多跳问答"折磨过。 问一个简单问题——“二甲双胍适合哪类糖尿病患者?”——Naive RAG 能直接命中&a…...

深度解析RePKG:Wallpaper Engine资源提取与TEX转换的终极解决方案
深度解析RePKG:Wallpaper Engine资源提取与TEX转换的终极解决方案 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专业的C#开源工具,专门用于解包…...

别再让数据库扛下所有:用Memcached给MySQL减负的5个实战场景与配置要点
从MySQL到Memcached:高并发场景下的缓存实战手册 当你的电商网站在大促期间突然变慢,数据库监控面板上的CPU使用率飙升至红线,这往往意味着关系型数据库正在承受它本不该承受的压力。Memcached作为一款久经考验的内存缓存系统,能在…...

从一次线上BUG复盘说起:strict-origin-when-cross-origin如何影响你的第三方登录与支付回调
从一次线上BUG复盘说起:strict-origin-when-cross-origin如何影响你的第三方登录与支付回调 那天凌晨2点,我被一连串报警短信惊醒——支付回调接口突然大面积失败。用户完成微信支付后,系统无法正确跳转回订单详情页,而是不断重定…...

网页端如何通过jQuery完成芯片制造文档的断点续传?
政府项目大文件传输系统开发方案 一、技术选型与架构设计 作为项目技术负责人,针对政府招投标系统的特殊需求,设计以下技术方案: 1.1 核心架构 #mermaid-svg-8u3j4uQ1dCpxy0J0{font-family:"trebuchet ms",verdana,arial,sans-s…...
)
RestSharp实战:5分钟搞定微信支付/天气API接口调用(C#保姆级教程)
RestSharp实战:5分钟搞定微信支付与天气API调用(C#保姆级教程) 当我们需要快速集成第三方API时,一个高效、简洁的HTTP客户端库能大幅提升开发效率。RestSharp作为.NET生态中广受欢迎的轻量级解决方案,以其直观的API设计…...