Python-Django的“日志功能-日志模块(logging模块)-日志输出”的功能详解
01-综述
可以使用Python内置的logging模块来实现Django项目的日志记录。
所以与其说这篇文章在讲Django的“日志功能-日志模块-日志输出”,不如说是在讲Pthon的“日志功能-日志模块-日志输出”,即Python的logging模块。
下面用一个实例来进行讲解。
02-实例代码及运行效果
现在我要在Django的视图函数index()中输出之前用print()输出的信息。
用logging模块改写前的视图函数index()的代码如下:
def index(request):year = 2023month = 11day = 22day_of_week = 'Wednesday'print(f"Today's date is:{year}-{month}-{day}-{day_of_week}")return render(request, 'index.html') # 将渲染结果输出到index.html模板中
在上面的代码中,print()语句根据上面设置的相关变量值输出下面的字符串:
Today's date is:2023-11-22-Wednesday
接下来,我们就根据Python内置的logging模块的使用方法来将上面的这个字符串输出到日志文件 logfile666.log 中。
首先我把完整的代码给出来,然后再慢慢讲。
视图函数index()的完整代码如下:
from django.shortcuts import render # 默认导入的模块
import logging # 导入日志记录模块# 创建一个名为'index_log'的日志记录器
logger01 = logging.getLogger('index_log')# Create your views here.def index(request):year = 2023month = 11day = 22day_of_week = 'Wednesday'logger01.debug(f"Today's date is:{year}-{month}-{day}-{day_of_week}")return render(request, 'index.html') # 将渲染结果输出到index.html模板中setting.py中添加如下代码:
# 设置日志记录器
LOGGING = {'version': 1,'disable_existing_loggers': True,'handlers': {'file01': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile666.log', # 指定日志文件的路径,相对路径时以Django项目的根目录为此路径的根路径,当然也可用绝对路径,比如E:/log/logfile666.log},},'loggers': {'index_log': {'handlers': ['file01'],'level': 'DEBUG','propagate': False,},},
}
用下面的命令开启Django的web服务后:
python manage.py runserver 127.0.0.1:8010
访问URL:
http://127.0.0.1:8010/index/
发现控制台没有字符串:Today's date is:2023-11-22-Wednesday的输出。
而在目录 BASE_DIR下出现了日志文件:logfile666.log

其内容如下:
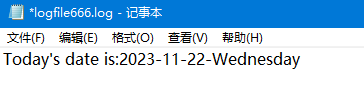
可见,实现了我们的需求。
接下来,对上面这个实例中的相关代码进行详解。
03-整个例子的思路
首先用语句import logging 导入日志记录模块,然后利用语句logger01 = logging.getLogger('index_log')创建一个名为index_log的logger对象,这个logger对象的实例化变量名为logger01。
然后使用语句logger01.debug(f"Today's date is:{year}-{month}-{day}-{day_of_week}")进行日志信息的输出。
语句logger01.debug(f"Today's date is:{year}-{month}-{day}-{day_of_week}")在进行日志信息输出时,因为这是一个名叫index_log的logger对象,所以去调用名叫index_log的logger的配置,具体代码如下:
'loggers': {'index_log': {'handlers': ['file01'],'level': 'DEBUG','propagate': False,},}
而名叫index_log的logger具体在执行日志信息的输出时,调用的是句柄file01,句柄file01的设置如下:
'handlers': {'file01': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile666.log', # 指定日志文件的路径,相对路径时以Django项目的根目录为此路径的根路径,当然也可用绝对路径,比如E:/log/logfile666.log},},
整个过程的大致介绍如上。
接下来对关键代码进行详细解释。
04-视图函数view.py中的关键代码详解
视图函数index()的完整代码如下:
from django.shortcuts import render # 默认导入的模块
import logging # 导入日志记录模块# 创建一个名为'index_log'的日志记录器
logger01 = logging.getLogger('index_log')# Create your views here.def index(request):year = 2023month = 11day = 22day_of_week = 'Wednesday'logger01.debug(f"Today's date is:{year}-{month}-{day}-{day_of_week}")return render(request, 'index.html') # 将渲染结果输出到index.html模板中第01句关键代码:
logger01 = logging.getLogger('index_log')
在这里面,注意参数'index_log',这是我们在setting.py中设置的记录器的名字,setting.py的相关截图如下:
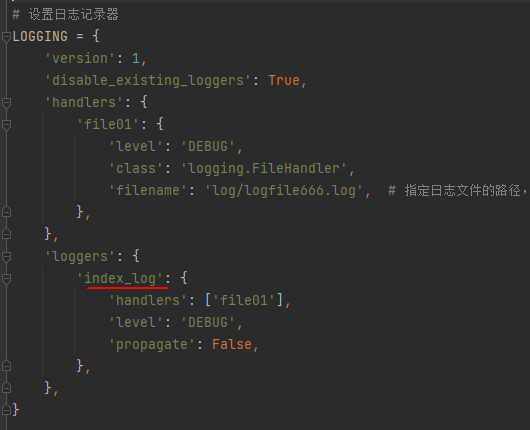
第02句关键代码:
logger01.debug(f"Today's date is:{year}-{month}-{day}-{day_of_week}")
logging模块一共有五个日志输出方法,对应于五个日志级别,分别如下:
logger.debug() # 调试级别的日志输出语句
logger.info() # 信息级别的日志输出语句
logger.warning() # 警告级别的日志输出语句
logger.error() # 错误级别的日志输出语句
logger.critical() # 严重错误级别的日志输出语句
上面这个五个日志级别的级别由低到高的顺序为:
debug→info→warning→error→critical
一条日志,该用哪个级别,由用户自己定义。
值得注意的是:
方法级别越高,那么要想输出相应的日志信息,那么对应的logger的级别应等于或小于其级别,而logger的级别又应比相应的hander级别高才行。
举个例子:
假如用方法logger.warning()输出日志信息,那么logger的级别(level)可以为WARNING或比WARNING小于的INFO、DEBUG,但不能为ERROR、CRITICAL。
假如logger的级别(level)设置为INFO,那么要先想其对应的handler能最终输出日志信息到日志文件,那么就需要handler的级别为INFO或比INFO级别小的DEBUG,但不能为WARNING、ERROR、CRITICAL。
另外,上面提到的五个日志输出方法:
logger.debug() # 调试级别的日志输出语句
logger.info() # 信息级别的日志输出语句
logger.warning() # 警告级别的日志输出语句
logger.error() # 错误级别的日志输出语句
logger.critical() # 严重错误级别的日志输出语句
其用法和print()一模一样。
05-setting.py中对日志器的设置语句详解
相关代码如下:
# 设置日志记录器
LOGGING = {'version': 1,'disable_existing_loggers': True,'handlers': {'file01': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile666.log', # 指定日志文件的路径,相对路径时以Django项目的根目录为此路径的根路径,当然也可用绝对路径,比如E:/log/logfile666.log},},'loggers': {'index_log': {'handlers': ['file01'],'level': 'DEBUG','propagate': False,},},
}
第01句代码:'disable_existing_loggers': False
'disable_existing_loggers': False,
'disable_existing_loggers' 是 Django 中配置日志的一个选项。它是一个布尔值,用于指定是否禁用已经存在的日志记录器(loggers)。
当 'disable_existing_loggers' 设置为 True 时,Django 将禁用所有已经存在的根记录器(root logger)和在 'loggers' 部分中未明确指定的其他记录器。这样可以确保日志记录器的配置是全新的,不受之前的全局配置的影响。
而当 'disable_existing_loggers' 设置为 False 时,Django 会保留已经存在的日志记录器,不禁用它们。这意味着在 'loggers' 部分中配置的记录器只是添加到已经存在的记录器列表中,而不是替换它们。这样的配置可能会导致全局的日志配置不够清晰,因为它们可能受到之前配置的影响。
以下是一个示例,演示了 'disable_existing_loggers' 设置为 True 和 False 时的不同行为:
LOGGING = {'version': 1,'disable_existing_loggers': True, # 或者 False'handlers': {'console': {'class': 'logging.StreamHandler',},},'loggers': {'django': {'handlers': ['console'],'level': 'INFO',},'my_app': {'handlers': ['console'],'level': 'DEBUG',},},
}
如果 'disable_existing_loggers' 设置为 True,那么所有已经存在的根记录器和未明确指定的其他记录器将被禁用。只有 'django' 和 'my_app' 记录器会生效。而如果设置为 False,那么已经存在的记录器仍然有效,所有的记录器都会生效,可能受到全局配置的影响。
在这里,我们设置为False,以避免影响别的日志输出,实践证明,如果这里设置为True,那么除了这里设置的日志输出,别的日志输出全没有了。
第02句代码:'level': 'DEBUG'
handlers里面的level设置语句:
'level': 'DEBUG',
这个level的作用已经在本文的“04-视图函数view.py中的关键代码详解”里进行了详细的说明,这里就不再叙述了。
第03句代码:'class': 'logging.FileHandler'
handlers里面的class设置语句:
'class': 'logging.FileHandler'
'class': 'logging.FileHandler' 是配置 logging 模块中的处理器(handler)的一部分。这个配置指定了使用 FileHandler 类来处理日志消息,并将这些消息写入到文件中。
在 Python 的 logging 模块中,处理器是用于指定日志消息的输出目的地的对象。FileHandler 是一种处理器(handler),它将日志消息写入到文件中。
让我们来详细解释这个配置:
'class': 这个键指定了使用的处理器类的名称。在这里,'logging.FileHandler'表示我们使用FileHandler类。FileHandler类是logging模块提供的标准处理器之一,专门用于将日志消息写入到文件。
使用 FileHandler 处理器的一个典型配置可能如下:
'handlers': {'file': {'class': 'logging.FileHandler','filename': 'logfile.log', # 指定日志文件的路径'level': 'DEBUG', # 指定处理器的日志级别},
},
在上面的配置中,我们创建了一个名为 ‘file’ 的处理器,指定了使用 FileHandler 类。配置还包括了 'filename' 键,用于指定日志文件的路径,以及 'level' 键,用于指定处理器的日志级别。 'level' 的设置将影响处理器接受的日志消息的最低级别,低于该级别的消息将被忽略。
总体而言,'class': 'logging.FileHandler' 是用于将日志消息写入文件的标准配置。如果你需要将日志记录到文件中,可以使用这个配置,并根据需要添加其他相关的设置,比如 'filename' 和 'level'。
问:除了FileHandler类,还有哪些类,请分别介绍。
在 Python 的 logging 模块中,除了 FileHandler 类之外,还有一些其他常用的处理器类。以下是其中一些类的介绍:
-
StreamHandler:
StreamHandler类用于将日志消息输出到流(例如,标准输出或标准错误)。可以通过配置'class': 'logging.StreamHandler'来使用它。
'handlers': {'console': {'class': 'logging.StreamHandler','level': 'DEBUG',}, }, -
RotatingFileHandler:
RotatingFileHandler类用于将日志消息写入到文件,并支持日志文件的滚动(回滚),即在达到一定大小时创建新的日志文件。可以通过配置'class': 'logging.handlers.RotatingFileHandler'来使用它。
'handlers': {'rotating_file': {'class': 'logging.handlers.RotatingFileHandler','filename': 'logfile.log','maxBytes': 1024, # 指定单个日志文件的最大大小'backupCount': 3, # 指定保留的旧日志文件数量'level': 'DEBUG',}, },对于类logging.handlers.RotatingFileHandler,假如日志文字的名字为 logfile.log 并超过指定大小后,会创建新的日志文件,之前的日志文件会被命名为什么呢?
答:RotatingFileHandler类在创建新的日志文件时,会为旧的日志文件添加一个后缀,以标识其顺序。这个后缀通常是一个数字,表示日志文件的旋转顺序。在默认情况下,后缀从 1 开始,每次创建新的日志文件,后缀递增。例如,假设你配置了一个
RotatingFileHandler如下:'handlers': {'rotating_file': {'class': 'logging.handlers.RotatingFileHandler','filename': 'logfile.log','maxBytes': 1024, # 指定单个日志文件的最大大小'backupCount': 3, # 指定保留的旧日志文件数量'level': 'DEBUG',}, },如果
logfile.log超过了1024字节,RotatingFileHandler会创建一个新的日志文件,原始的logfile.log会被重命名为logfile.log.1,而新的日志文件将继续使用logfile.log的文件名。如果再次超过最大大小,会创建另一个新的日志文件
logfile.log,而原来的logfile.log.1会被重命名为logfile.log.2。以此类推,旧的日志文件会依次向后移动并重命名。这样,
backupCount参数指定了保留的旧日志文件数量。在上面的例子中,设置为3表示会保留最新的 3 个旧日志文件,即logfile.log.1、logfile.log.2、logfile.log.3。超过这个数量后,最旧的日志文件会被删除。 -
TimedRotatingFileHandler:
TimedRotatingFileHandler类也用于将日志消息写入到文件,但支持基于时间的日志文件滚动。可以通过配置'class': 'logging.handlers.TimedRotatingFileHandler'来使用它。
'handlers': {'timed_rotating_file': {'class': 'logging.handlers.TimedRotatingFileHandler','filename': 'logfile.log','when': 'midnight', # 指定滚动周期,可以是 'midnight', 'H', 'MIDNIGHT', 'D', 'S', 'W0' 等'interval': 1, # 滚动周期的时间间隔'backupCount': 3, # 指定保留的旧日志文件数量'level': 'DEBUG',}, },问:对于类ogging.handlers.TimedRotatingFileHandler,假如日志文字的名字为 logfile.log 并超过指定大小后,会创建新的日志文件,之前的日志文件会被命名为什么呢?请举一个具体的例子并假设周期为天。
答:TimedRotatingFileHandler类与RotatingFileHandler类不同,它的日志文件滚动是基于时间的。在配置TimedRotatingFileHandler时,你需要指定when参数来定义滚动周期。常见的值包括'midnight'(每天的午夜滚动)以及其他时间单位,如'H'(每小时滚动)等。假设你的配置如下:
'handlers': {'timed_rotating_file': {'class': 'logging.handlers.TimedRotatingFileHandler','filename': 'logfile.log','when': 'midnight', # 指定滚动周期为每天的午夜'interval': 1, # 滚动周期的时间间隔'backupCount': 3, # 指定保留的旧日志文件数量'level': 'DEBUG',}, },在这个例子中,如果
logfile.log超过指定的大小,TimedRotatingFileHandler会创建一个新的日志文件,并在当前日志文件名上附加日期后缀,而不是简单地增加数字序列。每天午夜时,会创建一个新的日志文件,之前的日志文件会被重命名为带有日期后缀的形式。例如,如果当前日期是
2023-01-01,并且logfile.log超过了指定的大小,那么会创建一个新的日志文件,同时原来的logfile.log会被重命名为logfile.log.2023-01-01。下一天(
2023-01-02),再次创建新的日志文件,同时原来的logfile.log会被重命名为logfile.log.2023-01-02。依此类推,每天都会创建一个新的日志文件,并按照日期后缀的形式重命名之前的日志文件。这样,
backupCount参数指定了保留的旧日志文件数量,而when和interval参数则定义了滚动的时间周期。 -
NullHandler:
NullHandler类用于禁用日志记录,即将所有接收到的日志消息忽略。可以通过配置'class': 'logging.NullHandler'来使用它。
'handlers': {'null_handler': {'class': 'logging.NullHandler',}, },
这些处理器类提供了不同的日志记录方式和选项,可以根据项目的需求选择合适的处理器。在配置文件中,通过 'class' 键来指定使用的处理器类,然后可以根据处理器类的不同,配置相应的参数。
第04句代码:'propagate': False
'propagate': False
'propagate' 是配置日志记录器是否传递日志消息给其父记录器的一个属性。当 'propagate' 设置为 True 时,表示该记录器的日志消息将会传递给其父记录器,而父记录器的处理程序也将处理这些消息。如果设置为 False,则该记录器的消息将不会传递给其父记录器。
在 Django 中,默认情况下,'propagate' 属性被设置为 True。这意味着除非明确地指定为 False,否则日志消息会被传递给更高级别的记录器。这种设置允许你在项目的不同部分使用不同的日志记录器,同时确保日志消息能够在整个应用程序中传递。
'propagate' 设置为 True时,如果在记录器中记录了一条日志消息,它将传递给其父记录器(如果有的话),以便在整个日志体系中处理。
如果你希望某个特定记录器的日志消息不传递给其父记录器,可以将 'propagate' 设置为 False。这通常在配置多个记录器时用于避免重复记录相同的日志消息。
06-如何按大小或时间分割日志
这个问题已经在本篇本文第05点的第03句代码中说得很清楚了,这里不再赘述。
07-修改代码给每一条日志添加时间戳
Python 的 logging 模块可以自动在每一条日志消息的前面加上时间。这是通过在日志记录器(logger)的格式化字符串中添加时间信息来实现的。
在配置日志处理器时,你可以指定一个格式化字符串,该字符串中可以包含各种信息,包括时间。常用的时间格式占位符包括:
%asctime: 人类可读的时间,其具体格式由formatter参数指定。%created: 创建日志记录的时间戳。%msecs: 毫秒部分。%relativeCreated: 日志记录创建时的时间戳,以毫秒为单位,相对于日志系统启动时间。%thread: 线程ID。%levelname: 日志级别的文本表示。
接下来我们把本文中的例子加上时间戳。
其实就是把setting.py中对日志记录器的配置改成下面这段代码:
# 设置日志记录器
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'file01': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile888.log', # 指定日志文件的路径'formatter': 'verbose', # 将格式化器设置为 'verbose'},},'loggers': {'index_log': {'handlers': ['file01'],'level': 'DEBUG','propagate': False,},},'formatters': {'verbose': {'format': '%(asctime)s - %(message)s','datefmt': '%Y-%m-%d %H:%M:%S', # 人类可读的时间格式},},
}
在上面这段代码中:
我添加了 'formatters' 部分,定义了一个名为 'verbose' 的格式化器,其中包含人类可读时间的占位符 %asctime,并通过'datefmt'指定了具体的人类可读的时间格式。
然后,我在 'handlers' 部分的 'file01' 处将格式化器设置为 'verbose'。
这样,便可以实现在每条日志的前面加上时间戳了。
值得注意的是:如果不通过'datefmt'指定具体的格式,那么默认情况下,%asctime 使用的是计算机友好的时间格式,即包含日期和时间的完整字符串。这种格式对于机器解析是方便的,但对人类来说不够友好。
修改完成后,我们再访问:
http://127.0.0.1:8010/index/
就产生了日志文件:logfile888.log
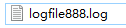
其内容如下:

可见,我们成功实现了在日志前面加上时间戳的需求。
08-一个既包含有时间输出也包含无时间输出的logging模块配置
在下面的代码中:
logger_time是有时间戳输出的logger,对应绑定的handler为handler01;
logger_no_time是无时间输出的looger,对应绑定的handler为handler02;
# 设置日志记录器
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'handler01': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile-time-2013-11-23-05.log', # 指定日志文件的路径,注意,在Centos服务器中要用绝对路径'formatter': 'verbose1', # 将格式化器设置为 'verbose1'},'handler02': {'level': 'DEBUG','class': 'logging.FileHandler','filename': 'log/logfile-no-time-2023-11-23-05.log', # 指定日志文件的路径,注意,在Centos服务器中要用绝对路径},},'loggers': {'logger_time': {'handlers': ['handler01'],'level': 'DEBUG','propagate': False,},'logger_no_time': {'handlers': ['handler02'],'level': 'DEBUG','propagate': False,},},'formatters': {'verbose1': {'format': '%(asctime)s - %(message)s','datefmt': '%Y-%m-%d %H:%M:%S', # 人类可读的时间格式},},
}
在上面的代码中:
logger_time是有时间戳输出的logger,对应绑定的handler为handler01;
logger_no_time是无时间输出的looger,对应绑定的handler为handler02;
相关文章:
Python-Django的“日志功能-日志模块(logging模块)-日志输出”的功能详解
01-综述 可以使用Python内置的logging模块来实现Django项目的日志记录。 所以与其说这篇文章在讲Django的“日志功能-日志模块-日志输出”,不如说是在讲Pthon的“日志功能-日志模块-日志输出”,即Python的logging模块。 下面用一个实例来进行讲解。 …...
笔记——库对数值和字符数据的支持)
C现代方法(第23章)笔记——库对数值和字符数据的支持
文章目录 第23章 库对数值和字符数据的支持23.1 <float.h>: 浮点类型的特性23.2 <limits.h>: 整数类型的大小23.3 <math.h>: 数学计算(C89)23.3.1 错误23.3.2 三角函数23.3.3 双曲函数23.3.4 指数函数和对数函数23.3.5 幂函数23.3.6 就近舍入、绝对值函数和取…...
NSGA-II求解微电网多目标优化调度(MATLAB)
一、NSGA-II简介 NSGA-Ⅱ算法是Kalyanmoy Deb等人于 2002年在 NSGA 的基础上提出的,它比 NSGA算法更加优越:它采用了快速非支配排序算法,计算复杂度比 NSGA 大大的降低;采用了拥挤度和拥挤度比较算子,代替了需要指定的…...

7-9 jmu-python-班级人员信息统计
7-9 jmu-python-班级人员信息统计 分数 15 作者 郑如滨 单位 集美大学 输入a,b班的名单,并进行如下统计。 输入格式: 第1行::a班名单,一串字符串,每个字符代表一个学生,无空格,可能有重复字符。 第2行:&am…...
)
Doris分区与分桶(八)
接上篇----------Doris 建表示例 Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。 也可以仅使用一层分区。使用一层分区时,只支持…...
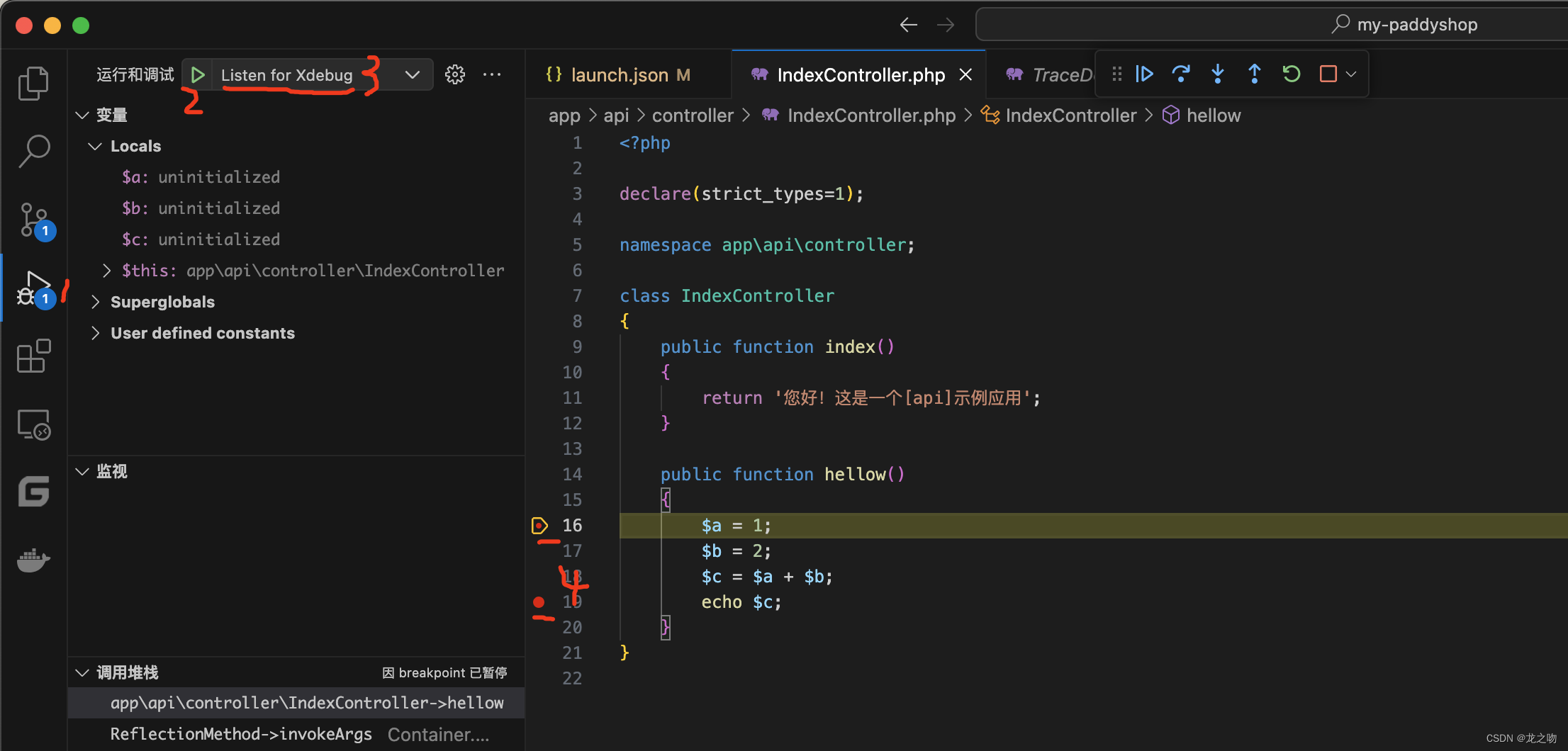
mac VScode 添加PHP debug
在VScode里面添加PHP Debug 插件,根据debug描述内容操作 1: 随意在index里面写个方法,然后用浏览器访问你的hello 方法,正常会进入下边的内容 class IndexController {public function index(){return 您好!这是一个[api]示例应用;}public function hello() {phpin…...

53.最大子数组和
原题链接:53.最大子数组和 思路: 只需要判断当前和小于负数 如果小于则舍弃掉子序列即可, 子序列开头从下一个下标位置开始。 全代码: class Solution { public:int maxSubArray(vector<int>& nums) {int max_len I…...

455.分发饼干
原题链接:455.分发饼干 思路: 先使用大饼干喂饱大胃口的,再到剩余的里面用大饼干喂剩下大胃口的 ,直到全部满足或者喂不了了为止。 全代码: class Solution { public:int findContentChildren(vector<int>&am…...
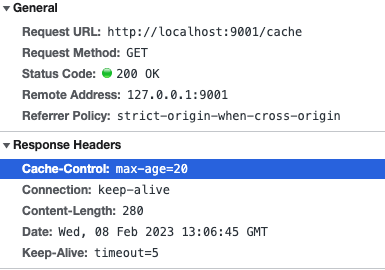
浏览器缓存控制讲解
缓存的作用 在你访问互联网中的任何资源其所产生的任何链路中的每一个节点几乎都会进行缓存,整个缓存体系和细节十分复杂。比如浏览器缓存,服务器缓存,代理服务器缓存,CDN缓存等。 但是缓存又十分重要,不可缺少&…...

批量插入SQL 错误 [933] [42000]: ORA-00933: SQL 命令未正确结束
使用DBeaver向【oracle数据库】插入大量数据 INSERT INTO Student(name,sex,age,address,birthday) VALUES(Nike,男,18,北京,2000-01-01) ,(Nike,男,18,北京,2000-01-01) ,(Nike,女,18,北京,2000-01-01) ,(Nike,女,18,北京,2000-01-01) ,(Nike,男,18,北京,2000-01-01) ,(Nike…...

北京数字孪生赋能工业制造,加速推进制造业数字化转型
随着新一代信息技术与实体经济深度融合进程的加快,企业数字化转型需求的提升,政策的持续支持,数字孪生将为工业制造、未来生活带来无限的可能。在制造业数字化大变革时代,以5G、大数据、物联网、人工智能等为代表的工业4.0&#x…...

【NLP】GPT 模型如何工作
介绍 2021 年,我使用 GPT 模型编写了最初的几行代码,那时我意识到文本生成已经达到了拐点。我要求 GPT-3 总结一份很长的文档,并尝试了几次提示。我可以看到结果比以前的模型先进得多,这让我对这项技术感到兴奋,并渴望…...

Linux下安装Foldseek并从蛋白质的PDB结构中获取 3Di Token 和 3Di Embedding
0. 说明: Foldseek 是由韩国国立首尔大学 (Seoul National University) 的 Martin Steinegger (MMseqs2 和 Linclust 的作者) 开发的一款用于快速地从大型蛋白质结构数据库中检索相似结构蛋白质的工具,可以用于计算两个蛋白之间的结构相似性,…...

单元测试-java.lang.NullPointerException
报错信息 java.lang.NullPointerException 空指针异常 空对象引用 来源 对Controller层进行单元测试,解决完Spring上下文报错后继续报错。 解决 在测试方法执行前要为字段完成对象的注入,否则就报空指针异常。 测试例子 不完整启动Spring框架 pub…...

机器学习数据集整理:图像、表格
前言 如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 表格数据 Sklearn 提供了 13 个表格型数据,且数据处理接口统一;LIBSVM 提供了 131 个表格型数据&a…...

Vue: Cannot find module @/xx/xx/xx.vue or its corresponding type declarations.
编辑器:Webstorm项目技术栈:vitevuets解决 1.vite.config.js设置别名resolve: {alias: {: path.resolve(__dirname, ./src),}, }, 2.src下创建globals.d.ts//通用声明 // Vue declare module *.vue {import { DefineComponent } from vue;const componen…...
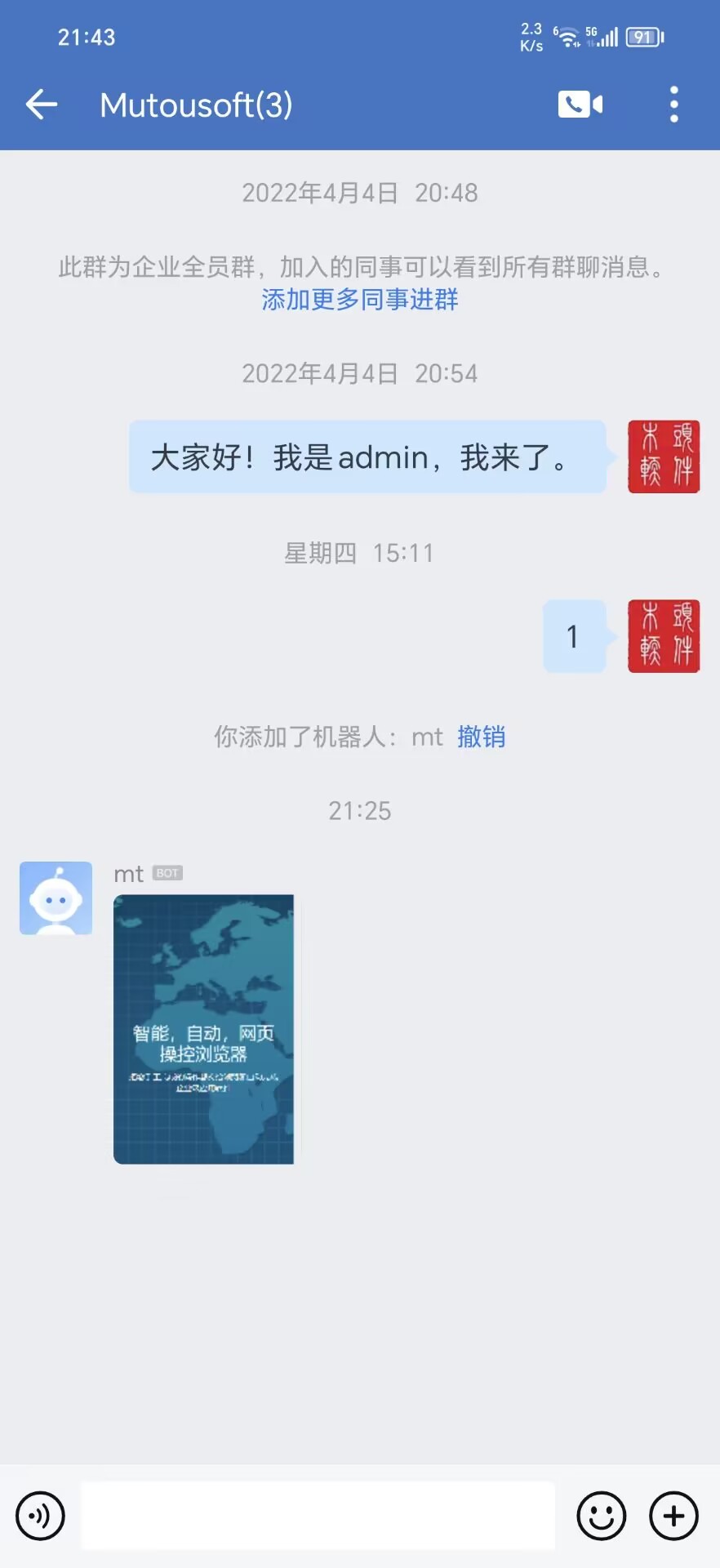
怎样自动把网页截图发到微信群里
现在很多公司都在使用企业微信了,不但方便公司内部交流和客户交流,还能组建各种小组群,业务群。企业微信群提供一个机器人的功能,方便我们把公司业务信息,或来自外部的信息自动发布到群里。 这里研究一下如何向微信群…...
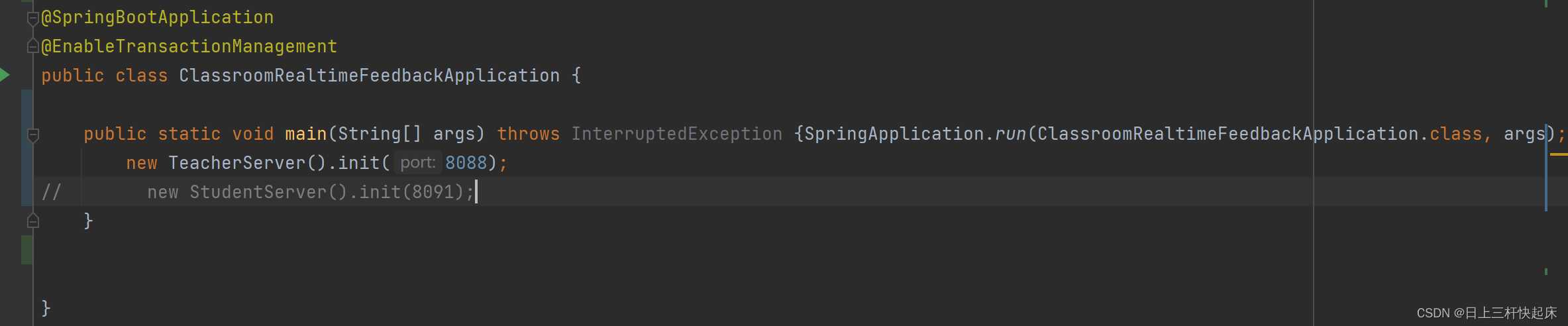
Netty实现websocket且实现url传参的两种方式(源码分析)
1、先构建基本的netty框架 再下面的代码中我构建了一个最基本的netty实现websocket的框架,其他个性化部分再自行添加。 Slf4j public class TeacherServer {public void teacherStart(int port) throws InterruptedException {NioEventLoopGroup boss new NioEve…...

深入理解C语言指针:基础概念、语法和实际应用
导言: 在C语言编程中,指针是一个强大而灵活的概念,它直接涉及到内存的操作,为程序员提供了更多的控制权。本文将深入探讨C语言指针的基础概念、语法规则以及实际应用,帮助读者更好地理解和运用这一重要的编程工具。 1…...

百度云加速免费版下线,推荐几款目前仍旧免费的CDN
近日,百度云加速实施了新政策,将不再支持免费套餐服务。现在免费的CDN也越来越少了,推荐几款目前仍旧免费的CDN,大家且用且珍惜! 1、雨云【点此直达】 源站为雨云产品可以免费使用CDN,源站非雨云产品流量包…...

数字人视频生成利器:Sonic工作流功能体验与效果测评
数字人视频生成利器:Sonic工作流功能体验与效果测评 1. 引言:数字人视频制作的新选择 在内容创作领域,数字人视频正变得越来越流行。无论是电商直播、在线教育还是企业宣传,都需要大量高质量的视频内容。传统视频制作需要专业设…...

给嵌入式开发者的RISC-V vs ARM实战选型指南:从开源生态到芯片采购的5个关键考量
RISC-V与ARM嵌入式开发实战选型指南:5个关键决策维度深度解析 当你在设计下一代智能门锁时,是选择RISC-V的灵活定制还是ARM的成熟稳定?这个看似简单的技术选型问题,实际上关乎产品未来三年的维护成本和市场竞争力。去年某家电厂商…...

iOS开发者必看:深度解析.plist文件,从蒲公英/Fir平台安全提取IPA的底层原理
iOS应用分发技术解析:深入理解.plist文件与安全获取IPA的底层逻辑 在企业签名和TestFlight之外,第三方应用分发平台为开发者提供了另一种灵活的应用测试与分发途径。这些平台通过精心设计的机制保护应用资源,而理解其背后的技术原理不仅能满足…...

智能状态员中的行为变化与条件转移
智能状态机中的行为变化与条件转移 在人工智能与自动化系统领域,智能状态机(Intelligent State Machine)是一种关键模型,用于描述系统在不同状态下的行为变化以及触发状态转移的条件。通过精确控制状态间的转换逻辑,智…...
)
考研复习 Day 18 | 数据结构与算法--图(上)
一、图的基本概念1.1 图的定义图G由顶点集V和边集E组成,记为G(V,E)要素说明V(G)顶点的有限非空集E(G)顶点之间关系的集合重要:线性表可以是空表,树可以是空树,但图不可以是空图。顶点集V必须非空,但边集E可以为空。1.2…...
)
告别三极管!用CH340X/C直连搞定CH32/STM32一键下载(附完整电路图与驱动版本避坑)
极简主义嵌入式开发:CH340直连实现CH32/STM32一键下载全攻略 当你在深夜调试一个嵌入式项目,反复插拔USB线、手动切换BOOT跳线、按复位按钮时,是否想过——这些繁琐操作真的有必要吗?传统的一键下载电路通常需要两个三极管构成的逻…...

Qt桌面应用界面进阶:我把Ribbon菜单和AdvancedDocking拖拽停靠‘焊’在了一起
Qt桌面应用界面进阶:Ribbon菜单与AdvancedDocking无缝整合实战 在开发复杂桌面应用时,如何平衡功能密度与界面灵活性一直是UI设计的核心挑战。想象一下,你正在构建一款专业级CAD软件——用户既需要快速访问数百个工具命令,又要求自…...
把本地Win/Linux服务器暴露到公网)
从虚拟机到“云主机”:教你用内网穿透(frp/花生壳)把本地Win/Linux服务器暴露到公网
从本地开发到公网访问:内网穿透技术实战指南 你是否遇到过这样的困境?在本地虚拟机中精心搭建的Web服务或API接口,却因为缺乏公网IP而无法让同事或客户实时查看。传统的云服务器方案不仅成本高昂,配置过程也相当繁琐。本文将带你探…...

DeepPCB:1500对高质量PCB缺陷检测数据集快速入门指南
DeepPCB:1500对高质量PCB缺陷检测数据集快速入门指南 【免费下载链接】DeepPCB A PCB defect dataset. 项目地址: https://gitcode.com/gh_mirrors/de/DeepPCB 还在为找不到高质量的PCB缺陷检测数据集而烦恼吗?DeepPCB为您提供了一个工业级的深度…...

Hermes Agent/OpenClaw怎么安装?2026年搭建及Coding Plan配置教程
Hermes Agent/OpenClaw怎么安装?2026年搭建及Coding Plan配置教程。还在为部署OpenClaw到处找教程踩坑吗?别再瞎折腾了!OpenClaw一键部署攻略来了,无需代码、只需两步,新手小白也能轻松拥有专属AI助理! …...