【Python进阶笔记】md文档笔记第6篇:Python进程和多线程使用(图文和代码)

本文从14大模块展示了python高级用的应用。分别有Linux命令,多任务编程、网络编程、Http协议和静态Web编程、html+css、JavaScript、jQuery、MySql数据库的各种用法、python的闭包和装饰器、mini-web框架、正则表达式等相关文章的详细讲述。
全套md格式笔记和代码自取: 请移步这里
共 14 章,157 子模块,总计 85313 字

进程的注意点
学习目标
- 能够说出进程的注意点
1. 进程的注意点介绍
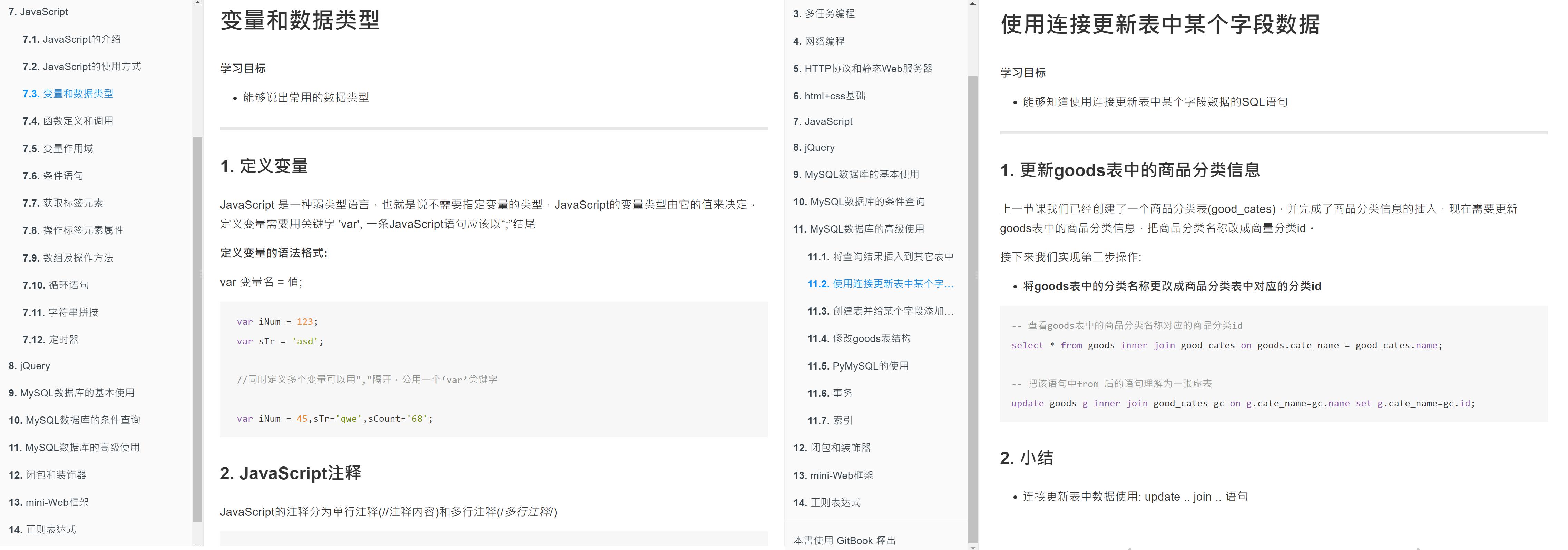
- 进程之间不共享全局变量
- 主进程会等待所有的子进程执行结束再结束
2. 进程之间不共享全局变量
import multiprocessing
import time# 定义全局变量g_list = list()# 添加数据的任务def add_data():for i in range(5):g_list.append(i)print("add:", i)time.sleep(0.2)# 代码执行到此,说明数据添加完成print("add_data:", g_list)def read_data():print("read_data", g_list)if __name__ == '__main__':# 创建添加数据的子进程add_data_process = multiprocessing.Process(target=add_data)# 创建读取数据的子进程read_data_process = multiprocessing.Process(target=read_data)# 启动子进程执行对应的任务add_data_process.start()# 主进程等待添加数据的子进程执行完成以后程序再继续往下执行,读取数据add_data_process.join()read_data_process.start()print("main:", g_list)# 总结: 多进程之间不共享全局变量
执行结果:
add: 0
add: 1
add: 2
add: 3
add: 4
add_data: [0, 1, 2, 3, 4]
main: []
read_data []
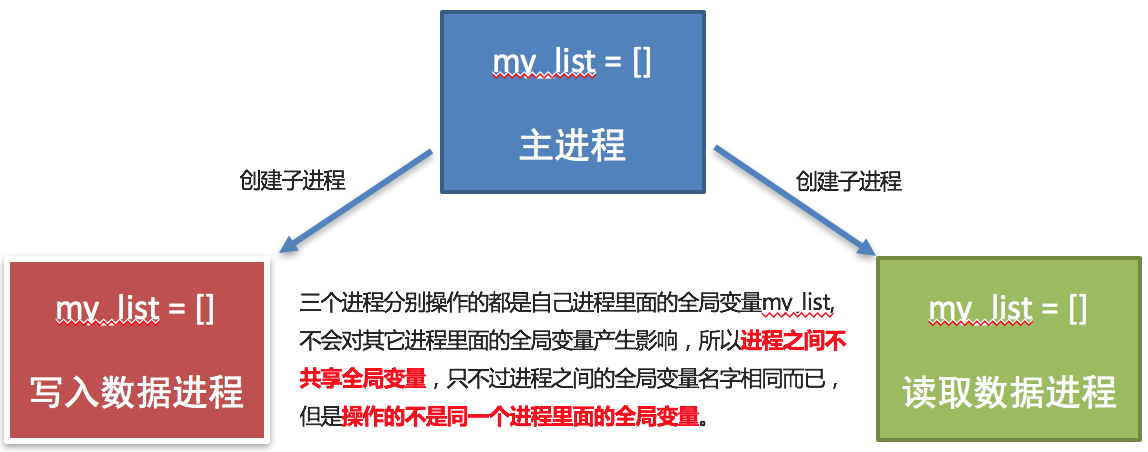
进程之间不共享全局变量的解释效果图:
3. 进程之间不共享全局变量的小结
- 创建子进程会对主进程资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
4. 主进程会等待所有的子进程执行结束再结束
假如我们现在创建一个子进程,这个子进程执行完大概需要2秒钟,现在让主进程执行0.5秒钟就退出程序,查看一下执行结果,示例代码如下:
import multiprocessing
import time# 定义进程所需要执行的任务def task():for i in range(10):print("任务执行中...")time.sleep(0.2)if __name__ == '__main__':# 创建子进程sub_process = multiprocessing.Process(target=task)sub_process.start()# 主进程延时0.5秒钟time.sleep(0.5)print("over")exit()# 总结: 主进程会等待所有的子进程执行完成以后程序再退出
执行结果:
任务执行中...
任务执行中...
任务执行中...
over
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
任务执行中...
说明:
通过上面代码的执行结果,我们可以得知: 主进程会等待所有的子进程执行结束再结束
假如我们就让主进程执行0.5秒钟,子进程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主进程 或者 在主进程退出之前 让子进程销毁
守护主进程:
- 守护主进程就是主进程退出子进程销毁不再执行
子进程销毁:
- 子进程执行结束
保证主进程正常退出的示例代码:
import multiprocessing
import time# 定义进程所需要执行的任务def task():for i in range(10):print("任务执行中...")time.sleep(0.2)if __name__ == '__main__':# 创建子进程sub_process = multiprocessing.Process(target=task)# 设置守护主进程,主进程退出子进程直接销毁,子进程的生命周期依赖与主进程# sub_process.daemon = Truesub_process.start()time.sleep(0.5)print("over")# 让子进程销毁sub_process.terminate()exit()# 总结: 主进程会等待所有的子进程执行完成以后程序再退出# 如果想要主进程退出子进程销毁,可以设置守护主进程或者在主进程退出之前让子进程销毁
执行结果:
任务执行中...
任务执行中...
任务执行中...
over
5. 主进程会等待所有的子进程执行结束再结束的小结
- 为了保证子进程能够正常的运行,主进程会等所有的子进程执行完成以后再销毁,设置守护主进程的目的是主进程退出子进程销毁,不让主进程再等待子进程去执行。
- 设置守护主进程方式: 子进程对象.daemon = True
- 销毁子进程方式: 子进程对象.terminate()
线程
学习目标
能够知道线程的作用
1. 线程的介绍
在Python中,想要实现多任务除了使用进程,还可以使用线程来完成,线程是实现多任务的另外一种方式。
2. 线程的概念
线程是进程中执行代码的一个分支,每个执行分支(线程)要想工作执行代码需要cpu进行调度 ,也就是说线程是cpu调度的基本单位,每个进程至少都有一个线程,而这个线程就是我们通常说的主线程。
3. 线程的作用
多线程可以完成多任务
多线程效果图:

4. 小结
- 线程是Python程序中实现多任务的另外一种方式,线程的执行需要cpu调度来完成。
多线程的使用
学习目标
- 能够使用多线程完成多任务
1. 导入线程模块
#导入线程模块import threading
2. 线程类Thread参数说明
Thread([group [, target [, name [, args [, kwargs]]]]])
- group: 线程组,目前只能使用None
- target: 执行的目标任务名
- args: 以元组的方式给执行任务传参
- kwargs: 以字典方式给执行任务传参
- name: 线程名,一般不用设置
3. 启动线程
启动线程使用start方法
4. 多线程完成多任务的代码
import threading
import time# 唱歌任务def sing():# 扩展: 当前线程# print("sing当前执行的线程为:", threading.current_thread())for i in range(3):print("正在唱歌...%d" % i)time.sleep(1)# 跳舞任务def dance():# 扩展: 当前线程# print("dance当前执行的线程为:", threading.current_thread())for i in range(3):print("正在跳舞...%d" % i)time.sleep(1)if __name__ == '__main__':# 扩展: 当前线程# print("当前执行的线程为:", threading.current_thread())# 创建唱歌的线程# target: 线程执行的函数名sing_thread = threading.Thread(target=sing)# 创建跳舞的线程dance_thread = threading.Thread(target=dance)# 开启线程sing_thread.start()dance_thread.start()
执行结果:
正在唱歌...0
正在跳舞...0
正在唱歌...1
正在跳舞...1
正在唱歌...2
正在跳舞...2
5. 小结
-
导入线程模块
- import threading
-
创建子线程并指定执行的任务
- sub_thread = threading.Thread(target=任务名)
-
启动线程执行任务
- sub_thread.start()
线程执行带有参数的任务
学习目标
- 能够写出线程执行带有参数的任务
1. 线程执行带有参数的任务的介绍
前面我们使用线程执行的任务是没有参数的,假如我们使用线程执行的任务带有参数,如何给函数传参呢?
Thread类执行任务并给任务传参数有两种方式:
- args 表示以元组的方式给执行任务传参
- kwargs 表示以字典方式给执行任务传参
2. args参数的使用
示例代码:
import threading
import time# 带有参数的任务def task(count):for i in range(count):print("任务执行中..")time.sleep(0.2)else:print("任务执行完成")if __name__ == '__main__':# 创建子线程# args: 以元组的方式给任务传入参数sub_thread = threading.Thread(target=task, args=(5,))sub_thread.start()
执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行中..
任务执行中..
任务执行完成
3. kwargs参数的使用
示例代码:
import threading
import time# 带有参数的任务def task(count):for i in range(count):print("任务执行中..")time.sleep(0.2)else:print("任务执行完成")if __name__ == '__main__':# 创建子线程# kwargs: 表示以字典方式传入参数sub_thread = threading.Thread(target=task, kwargs={"count": 3})sub_thread.start()
执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成
4. 小结
-
线程执行任务并传参有两种方式:
- 元组方式传参(args) :元组方式传参一定要和参数的顺序保持一致。
- 字典方式传参(kwargs):字典方式传参字典中的key一定要和参数名保持一致。
线程的注意点
学习目标
- 能够说出线程的注意点
1. 线程的注意点介绍
- 线程之间执行是无序的
- 主线程会等待所有的子线程执行结束再结束
- 线程之间共享全局变量
- 线程之间共享全局变量数据出现错误问题
2. 线程之间执行是无序的
import threading
import timedef task():time.sleep(1)print("当前线程:", threading.current_thread().name)if __name__ == '__main__':for _ in range(5):sub_thread = threading.Thread(target=task)sub_thread.start()
执行结果:
当前线程: Thread-1
当前线程: Thread-2
当前线程: Thread-4
当前线程: Thread-5
当前线程: Thread-3
说明:
- 线程之间执行是无序的,它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
- 进程之间执行也是无序的,它是由操作系统调度决定的,操作系统调度哪个进程,哪个进程就先执行,没有调度的进程不能执行。
3. 主线程会等待所有的子线程执行结束再结束
假如我们现在创建一个子线程,这个子线程执行完大概需要2.5秒钟,现在让主线程执行1秒钟就退出程序,查看一下执行结果,示例代码如下:
import threading
import time# 测试主线程是否会等待子线程执行完成以后程序再退出def show_info():for i in range(5):print("test:", i)time.sleep(0.5)if __name__ == '__main__':sub_thread = threading.Thread(target=show_info)sub_thread.start()# 主线程延时1秒time.sleep(1)print("over")
执行结果:
test: 0
test: 1
over
test: 2
test: 3
test: 4
说明:
通过上面代码的执行结果,我们可以得知: 主线程会等待所有的子线程执行结束再结束
假如我们就让主线程执行1秒钟,子线程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主线程
守护主线程:
- 守护主线程就是主线程退出子线程销毁不再执行
设置守护主线程有两种方式:
- threading.Thread(target=show_info, daemon=True)
- 线程对象.setDaemon(True)
设置守护主线程的示例代码:
import threading
import time# 测试主线程是否会等待子线程执行完成以后程序再退出def show_info():for i in range(5):print("test:", i)time.sleep(0.5)if __name__ == '__main__':# 创建子线程守护主线程 # daemon=True 守护主线程# 守护主线程方式1sub_thread = threading.Thread(target=show_info, daemon=True)# 设置成为守护主线程,主线程退出后子线程直接销毁不再执行子线程的代码# 守护主线程方式2# sub_thread.setDaemon(True)sub_thread.start()# 主线程延时1秒time.sleep(1)print("over")
执行结果:
test: 0
test: 1
over
3. 线程之间共享全局变量
需求:
- 定义一个列表类型的全局变量
- 创建两个子线程分别执行向全局变量添加数据的任务和向全局变量读取数据的任务
- 查看线程之间是否共享全局变量数据
import threading
import time# 定义全局变量my_list = list()# 写入数据任务def write_data():for i in range(5):my_list.append(i)time.sleep(0.1)print("write_data:", my_list)# 读取数据任务def read_data():print("read_data:", my_list)if __name__ == '__main__':# 创建写入数据的线程write_thread = threading.Thread(target=write_data)# 创建读取数据的线程read_thread = threading.Thread(target=read_data)write_thread.start()# 延时# time.sleep(1)# 主线程等待写入线程执行完成以后代码在继续往下执行write_thread.join()print("开始读取数据啦")read_thread.start()
执行结果:
write_data: [0, 1, 2, 3, 4]
开始读取数据啦
read_data: [0, 1, 2, 3, 4]
4. 线程之间共享全局变量数据出现错误问题
需求:
- 定义两个函数,实现循环100万次,每循环一次给全局变量加1
- 创建两个子线程执行对应的两个函数,查看计算后的结果
import threading# 定义全局变量g_num = 0# 循环一次给全局变量加1def sum_num1():for i in range(1000000):global g_numg_num += 1print("sum1:", g_num)# 循环一次给全局变量加1def sum_num2():for i in range(1000000):global g_numg_num += 1print("sum2:", g_num)if __name__ == '__main__':# 创建两个线程first_thread = threading.Thread(target=sum_num1)second_thread = threading.Thread(target=sum_num2)# 启动线程first_thread.start()# 启动线程second_thread.start()
执行结果:
sum1: 1210949
sum2: 1496035
注意点:
多线程同时对全局变量操作数据发生了错误
错误分析:
两个线程first_thread和second_thread都要对全局变量g_num(默认是0)进行加1运算,但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,first_thread取得g_num=0。此时系统把first_thread调度为”sleeping”状态,把second_thread转换为”running”状态,t2也获得g_num=0
- 然后second_thread对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把second_thread调度为”sleeping”,把first_thread转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然first_thread和first_thread都对g_num加1,但结果仍然是g_num=1
全局变量数据错误的解决办法:
线程同步: 保证同一时刻只能有一个线程去操作全局变量 同步: 就是协同步调,按预定的先后次序进行运行。如:你说完,我再说, 好比现实生活中的对讲机
线程同步的方式:
- 线程等待(join)
- 互斥锁
线程等待的示例代码:
import threading# 定义全局变量g_num = 0# 循环1000000次每次给全局变量加1def sum_num1():for i in range(1000000):global g_numg_num += 1print("sum1:", g_num)# 循环1000000次每次给全局变量加1def sum_num2():for i in range(1000000):global g_numg_num += 1print("sum2:", g_num)if __name__ == '__main__':# 创建两个线程first_thread = threading.Thread(target=sum_num1)second_thread = threading.Thread(target=sum_num2)# 启动线程first_thread.start()# 主线程等待第一个线程执行完成以后代码再继续执行,让其执行第二个线程# 线程同步: 一个任务执行完成以后另外一个任务才能执行,同一个时刻只有一个任务在执行first_thread.join()# 启动线程second_thread.start()
执行结果:
sum1: 1000000
sum2: 2000000
5. 小结
-
线程执行执行是无序的
-
主线程默认会等待所有子线程执行结束再结束,设置守护主线程的目的是主线程退出子线程销毁。
-
线程之间共享全局变量,好处是可以对全局变量的数据进行共享。
-
线程之间共享全局变量可能会导致数据出现错误问题,可以使用线程同步方式来解决这个问题。
- 线程等待(join)
互斥锁
学习目标
- 能够知道互斥锁的作用
1.互斥锁的概念
互斥锁: 对共享数据进行锁定,保证同一时刻只能有一个线程去操作。
注意:
- 互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁。
为了更好的理解互斥锁,请看下面的图:

3. 互斥锁的使用
threading模块中定义了Lock变量,这个变量本质上是一个函数,通过调用这个函数可以一把互斥锁。
互斥锁使用步骤:
# 创建锁mutex = threading.Lock()# 上锁mutex.acquire()...这里编写代码能保证同一时刻只能有一个线程去操作, 对共享数据进行锁定...# 释放锁mutex.release()
注意点:
- acquire和release方法之间的代码同一时刻只能有一个线程去操作
- 如果在调用acquire方法的时候 其他线程已经使用了这个互斥锁,那么此时acquire方法会堵塞,直到这个互斥锁释放后才能再次上锁。
4. 使用互斥锁完成2个线程对同一个全局变量各加100万次的操作
import threading# 定义全局变量g_num = 0# 创建全局互斥锁lock = threading.Lock()# 循环一次给全局变量加1def sum_num1():# 上锁lock.acquire()for i in range(1000000):global g_numg_num += 1print("sum1:", g_num)# 释放锁lock.release()# 循环一次给全局变量加1def sum_num2():# 上锁lock.acquire()for i in range(1000000):global g_numg_num += 1print("sum2:", g_num)# 释放锁lock.release()if __name__ == '__main__':# 创建两个线程first_thread = threading.Thread(target=sum_num1)second_thread = threading.Thread(target=sum_num2)# 启动线程first_thread.start()second_thread.start()# 提示:加上互斥锁,那个线程抢到这个锁我们决定不了,那线程抢到锁那个线程先执行,没有抢到的线程需要等待# 加上互斥锁多任务瞬间变成单任务,性能会下降,也就是说同一时刻只能有一个线程去执行
执行结果:
sum1: 1000000
sum2: 2000000
说明:
通过执行结果可以地址互斥锁能够保证多个线程访问共享数据不会出现数据错误问题
5. 小结
- 互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
- 使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
- 使用互斥锁会影响代码的执行效率,多任务改成了单任务执行
- 互斥锁如果没有使用好容易出现死锁的情况
未完待续 下一期下一章
全套笔记直接地址: 请移步这里
reading.Lock()
循环一次给全局变量加1
def sum_num1():
# 上锁
lock.acquire()
for i in range(1000000):
global g_num
g_num += 1
print("sum1:", g_num)
# 释放锁
lock.release()
循环一次给全局变量加1
def sum_num2():
# 上锁
lock.acquire()
for i in range(1000000):
global g_num
g_num += 1
print(“sum2:”, g_num)
# 释放锁
lock.release()
if name == ‘main’:
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动线程
first_thread.start()
second_thread.start()
# 提示:加上互斥锁,那个线程抢到这个锁我们决定不了,那线程抢到锁那个线程先执行,没有抢到的线程需要等待
# 加上互斥锁多任务瞬间变成单任务,性能会下降,也就是说同一时刻只能有一个线程去执行
**执行结果:**```py
sum1: 1000000
sum2: 2000000
说明:
通过执行结果可以地址互斥锁能够保证多个线程访问共享数据不会出现数据错误问题
5. 小结
- 互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
- 使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
- 使用互斥锁会影响代码的执行效率,多任务改成了单任务执行
- 互斥锁如果没有使用好容易出现死锁的情况
未完待续 下一期下一章
全套笔记直接地址: 请移步这里
相关文章:
【Python进阶笔记】md文档笔记第6篇:Python进程和多线程使用(图文和代码)
本文从14大模块展示了python高级用的应用。分别有Linux命令,多任务编程、网络编程、Http协议和静态Web编程、htmlcss、JavaScript、jQuery、MySql数据库的各种用法、python的闭包和装饰器、mini-web框架、正则表达式等相关文章的详细讲述。 全套md格式笔记和代码自…...

基于Vue+SpringBoot的数字化社区网格管理系统
项目编号: S 042 ,文末获取源码。 \color{red}{项目编号:S042,文末获取源码。} 项目编号:S042,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 源码 & 项目录屏 二、功能模块三、开发背景四、系统展示五…...

【数据库设计和SQL基础语法】--数据库设计基础--数据建模与ER图
一、数据建模的基本概念 1.1. 数据模型的概念 数据模型是对现实世界中事物及其之间关系的一种抽象表示。它提供了描述数据结构、数据操作、数据约束等的方式,是数据库设计的基础。数据模型帮助我们理解数据之间的关系,提供了一种规范化的方式来组织和存…...
Vue3 设置点击后滚动条移动到固定的位置
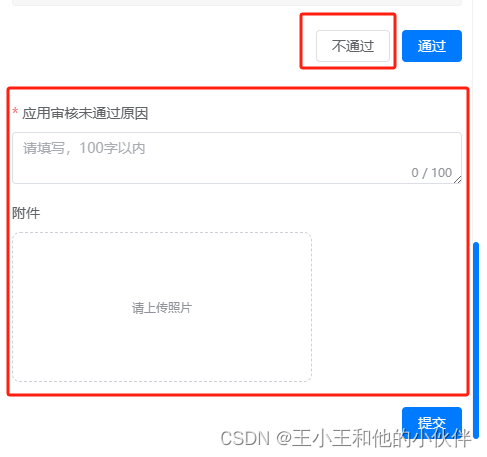
需求: 点击不通过按钮,显示红框中表单,且滚动条滚动到底部 (显示红框中表单默认不显示) <el-button click"onApprovalPass">不通过</el-button> <div class"item" v-if"app…...

外部 prometheus监控k8s集群资源(pod、CPU、service、namespace、deployment等)
prometheus监控k8s集群资源 一,通过CADvisior 监控pod的资源状态1.1 授权外边用户可以访问prometheus接口。1.2 获取token保存1.3 配置prometheus.yml 启动并查看状态1.4 Grafana 导入仪表盘 二,通过kube-state-metrics 监控k8s资源状态2.1 部署 kube-st…...
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
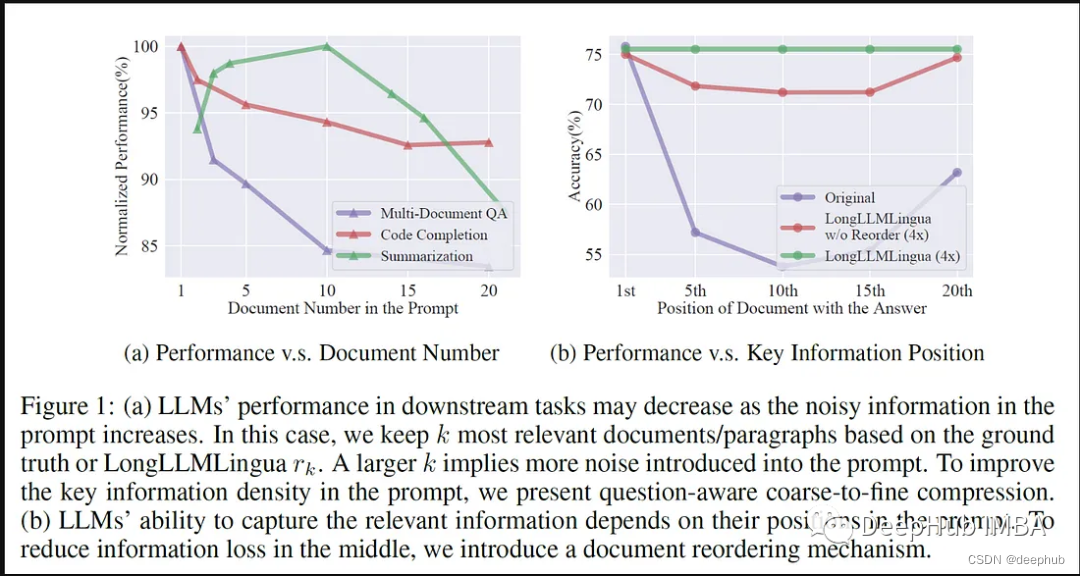
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLM…...

数据资产确权的难点
数据是企业的重要资产之一,但是许多企业对于这项资产在管理上都面临着一些挑战,其中最关键就是数据确权的问题。接下来,将探讨数据资产确权的难点,并提出相应的解决方案,一起来看吧。 首先介绍一下数据资产入表的背景以…...

EMG肌肉电信号处理合集(二)
本文主要展示常见的肌电信号特征的提取说明。使用python 环境下的Pysiology计算库。 目录 1 肌电信号第一次burst的振幅, getAFP 函数 2 肌电信号波长的标准差计算,getDASDV函数 3 肌电信号功率谱频率比例,getFR函数 4 肌电信号直方图…...

2023亚马逊云科技re:Invent引领科技新潮流:云计算与生成式AI共塑未来
2023亚马逊云科技re:Invent引领科技新潮流:云计算与生成式AI共塑未来 历年来,亚马逊云科技re:Invent,不仅是全球云计算从业者的年度狂欢,更是全球云计算领域每年创新发布的关键节点。 2023年亚马逊云科技re:Invent大会在美国拉斯…...
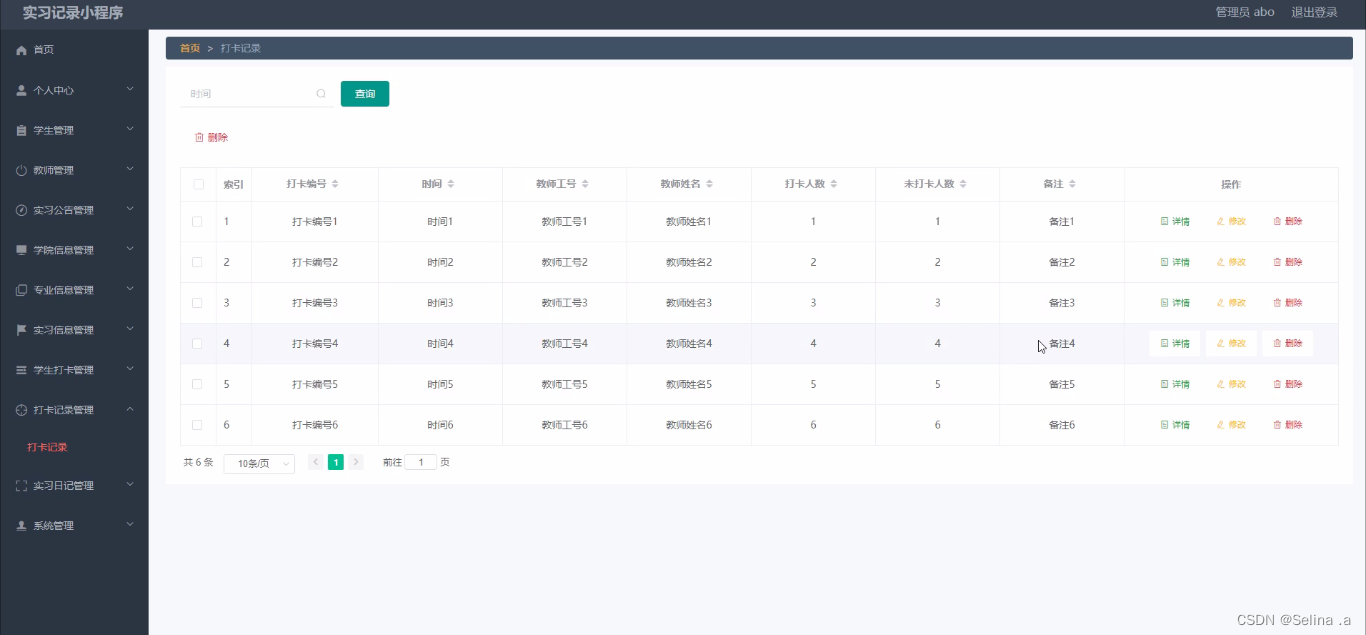
案例018:基于微信小程序的实习记录系统
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...

视频剪辑技巧:如何高效批量转码MP4视频为MOV格式
在视频剪辑的过程中,经常会遇到将MP4视频转码为MOV格式的情况。这不仅可以更好地编辑视频,还可以提升视频的播放质量和兼容性。对于大量视频文件的转码操作,如何高效地完成批量转码呢?现在一起来看看云炫AI智剪如何智能转码&#…...

node.js获取unsplash图片
1. 在Unsplash的开发者页面注册并创建一个应用程序,以便获取一个API访问密钥(即Access Key)。 2. 安装axios: npm install axios3. 使用获取到的API密钥进行请求。 示例代码如下: const axios require(axios);con…...

Git远程库操作(GitHub)
GitHub 网址:https://github.com/ 创建远程仓库 远程仓库操作 命令名称作用git remote -v查看当前所有远程地址别名git remote add 别名 远程地址起别名git push 别名 分支推送本地分支上的内容到远程仓库git clone 远程地址将远程仓库的内容克隆到本地git pull 别…...
java计算下一个整10分钟时间点
最近工作上遇到需要固定在整10分钟一个周期调度某个任务,所以需要这样一个功能,记录下 package org.example;import com.google.gson.Gson; import org.apache.commons.lang3.time.DateUtils;import java.io.InputStream; import java.util.Calendar; i…...
力扣刷题篇之排序算法
系列文章目录 前言 本系列是个人力扣刷题汇总,本文是排序算法。刷题顺序按照[力扣刷题攻略] Re:从零开始的力扣刷题生活 - 力扣(LeetCode) 这个之前写的左神的课程笔记里也有: 左程云算法与数据结构代码汇总之排序&am…...

一键填充字幕——Arctime pro
之前的博客中,我们聊到了PR这款专业的视频制作软件,但是pr有许多的功能需要搭配使用,相信不少小伙伴在剪辑视频时会发现一个致命的问题,就是字幕编写。伴随着人们对字幕需求的逐渐增加,这款软件便应运而生~ 相信应该有…...
)
间隔分区表(DM8:达梦数据库)
DM8:达梦数据库 - 间隔分区表 环境介绍1 按 年 - 间隔分区表2 按 月 - 间隔分区3 按 日 - 间隔分区4 按 数值 - 间隔分区表5 达梦数据库学习使用列表 环境介绍 间隔分区表使用说明: 仅支持一级范围分区创建间隔分区。 只能有一个分区列,且分区列类型为…...
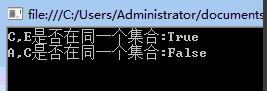
基于C#实现并查集
一、场景 有时候我们会遇到这样的场景,比如:M{1,4,6,8},N{2,4,5,7},我的需求就是判断{1,2}是否属于同一个集合,当然实现方法有很多,一般情况下,普通青年会做出 O(MN)的复杂度,那么有没有更轻量级的复杂度呢…...
opencv-图像轮廓
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。 • 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理或者 Canny 边界检…...
小黑子—Maven高级
Maven高级篇 二 小黑子的Maven高级篇学习1. 分模块开发1.1 分模块开发设计1.2 分模块开发实现1.2.1 抽取domain层1.2.2 抽取dao层 2. 依赖管理2.1 依赖传递2.2 可选依赖2.3 排除依赖 3. 继承与聚合3.1 聚合3.2 继承3.3 总结 4. 属性4.1 配置文件加载属性4.2 版本管理 5. 多环境…...

拆解TMM审稿流程:从Major Revision到Accept,如何高效撰写20页回复信?
学术论文大修回复信撰写全攻略:从意见归类到最终录用 当屏幕上跳出"Major Revision"的邮件通知时,那种既兴奋又忐忑的心情每位研究者都深有体会。兴奋的是论文没有被直接拒稿,忐忑的是面对四位审稿人密密麻麻的修改意见不知从何下手…...
)
ZYNQ实战:手把手教你用LWIP实现UDP文件传输到DDR(附完整代码)
ZYNQ LWIP UDP文件传输实战:从协议栈配置到DDR存储的完整实现 在嵌入式系统开发中,网络通信功能已成为现代SoC设计的标配能力。Xilinx ZYNQ系列凭借其ARM处理器与可编程逻辑的完美结合,为开发者提供了灵活高效的网络通信解决方案。本文将深入…...

Windows平台Hadoop 3.3.6环境搭建与IDEA集成开发:从零实现HDFS文件操作
1. Windows平台Hadoop 3.3.6环境搭建全攻略 在Windows上搭建Hadoop环境对于大数据初学者来说是个不小的挑战。我刚开始接触Hadoop时,光是解决Windows兼容性问题就折腾了好几天。不过别担心,跟着我的步骤走,你可以在30分钟内完成Hadoop 3.3.6的…...

终极免费激活方案:5分钟搞定Windows与Office永久激活的完整指南
终极免费激活方案:5分钟搞定Windows与Office永久激活的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?KMS_VL_ALL_AIO智能激活脚本为您提…...

GB15084-2027实施在即,手把手教你解读CMS电子后视镜的法规合规要点
GB15084-2027法规深度解析:CMS电子后视镜合规实战指南 当传统光学镜片遇上数字成像技术,汽车间接视野系统正经历着自后视镜发明以来最彻底的变革。GB15084-2027(注:应为GB15084-2022,原文标题有误)的实施不…...
)
前端工程师的AutoJS实战:用JavaScript给女朋友的抖音号自动“三连”(附完整源码)
前端工程师跨界实战:用AutoJS打造抖音自动化互动工具 每次女友发布新视频,我的手机总会准时响起——"快给我点赞评论转发三连!"作为前端工程师,我盯着熟悉的JavaScript代码,突然想到:既然能用JS操…...
 仿真环境)
避坑指南:Ubuntu20.04 高效部署 XTDrone 与 PX4 (v1.13) 仿真环境
1. 环境准备:系统与基础依赖 在Ubuntu 20.04上部署XTDrone与PX4仿真环境前,首先要确保系统环境干净。我遇到过不少因为残留旧版本组件导致的诡异问题,最稳妥的方式是使用新安装的系统。如果必须复用现有环境,建议先执行sudo apt a…...

3步掌握Office文档快速预览:高效办公的终极解决方案
3步掌握Office文档快速预览:高效办公的终极解决方案 【免费下载链接】QuickLook.Plugin.OfficeViewer-Native View Word, Excel, and PowerPoint files with MS Office and WPS Office components. 项目地址: https://gitcode.com/gh_mirrors/qu/QuickLook.Plugin…...
3步搞定!TranslucentTB中文界面终极设置指南:让你的Windows任务栏完美透明化
3步搞定!TranslucentTB中文界面终极设置指南:让你的Windows任务栏完美透明化 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/Transluc…...

ESXi内存使用率100%?别慌!这不是故障是正常现象
很多运维小伙伴在管理ESXi主机时,打开监控面板会瞬间慌神:ESXi内存使用率直接拉满100%,甚至持续居高不下,担心是不是主机出了故障、虚拟机要卡顿崩溃。其实大家完全不用紧张,ESXi的设计理念就是“充分利用每一份内存资…...