基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】
本文是关于基于YOLOv4开发构建目标检测模型的超详细实战教程,超详细实战教程相关的博文在前文有相应的系列,感兴趣的话可以自行移步阅读即可:
《基于yolov7开发实践实例分割模型超详细教程》
《YOLOv7基于自己的数据集从零构建模型完整训练、推理计算超详细教程》
《DETR (DEtection TRansformer)基于自建数据集开发构建目标检测模型超详细教程》
《基于yolov5-v7.0开发实践实例分割模型超详细教程》
《轻量级模型YOLOv5-Lite基于自己的数据集【焊接质量检测】从零构建模型超详细教程》
《轻量级模型NanoDet基于自己的数据集【接打电话检测】从零构建模型超详细教程》
《基于YOLOv5-v6.2全新版本模型构建自己的图像识别模型超详细教程》
《基于自建数据集【海底生物检测】使用YOLOv5-v6.1/2版本构建目标检测模型超详细教程》
《超轻量级目标检测模型Yolo-FastestV2基于自建数据集【手写汉字检测】构建模型训练、推理完整流程超详细教程》
《基于YOLOv8开发构建目标检测模型超详细教程【以焊缝质量检测数据场景为例】》
最早期接触v3和v4的时候印象中模型的训练方式都是基于Darknet框架开发构建的,模型都是通过cfg文件进行配置的,从v5开始才全面转向了PyTorch形式的项目,延续到了现在。
yolov4.cfg如下:
[net]
batch=64
subdivisions=8
# Training
#width=512
#height=512
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1learning_rate=0.0013
burn_in=1000
max_batches = 500500
policy=steps
steps=400000,450000
scales=.1,.1#cutmix=1
mosaic=1#:104x104 54:52x52 85:26x26 104:13x13 for 416[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-7[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-10[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-28[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-28[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish# Downsample[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[route]
layers = -2[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish[shortcut]
from=-3
activation=linear[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish[route]
layers = -1,-16[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=1
activation=mish##########################[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky### SPP ###
[maxpool]
stride=1
size=5[route]
layers=-2[maxpool]
stride=1
size=9[route]
layers=-4[maxpool]
stride=1
size=13[route]
layers=-1,-3,-5,-6
### End SPP ###[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = 85[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[route]
layers = -1, -3[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = 54[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[route]
layers = -1, -3[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky##########################[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5[route]
layers = -4[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=256
activation=leaky[route]
layers = -1, -16[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 3,4,5
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5[route]
layers = -4[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=512
activation=leaky[route]
layers = -1, -37[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5yolov4-tiny.cfg如下:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=1
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1learning_rate=0.00261
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1[convolutional]
batch_normalize=1
filters=32
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[route]
layers=-1
groups=2
group_id=1[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky[route]
layers = -1,-2[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[route]
layers = -6,-1[maxpool]
size=2
stride=2[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky##################################[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=80
num=6
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=0
resize=1.5
nms_kind=greedynms
beta_nms=0.6[route]
layers = -4[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky[upsample]
stride=2[route]
layers = -1, 23[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear[yolo]
mask = 1,2,3
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=80
num=6
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=0
resize=1.5
nms_kind=greedynms
beta_nms=0.6最开始的时候还是蛮喜欢这种形式的,非常的简洁,直接使用Darknet框架训练也很方便,到后面随着模型改进各种组件的替换,Darknet变得越发不适用了。YOLOv4的话感觉定位相比于v3和v5来说比较尴尬一些,git里面搜索yolov4,结果如下所示:

排名第一的项目是pytorch-YOLOv4,地址在这里,如下所示:
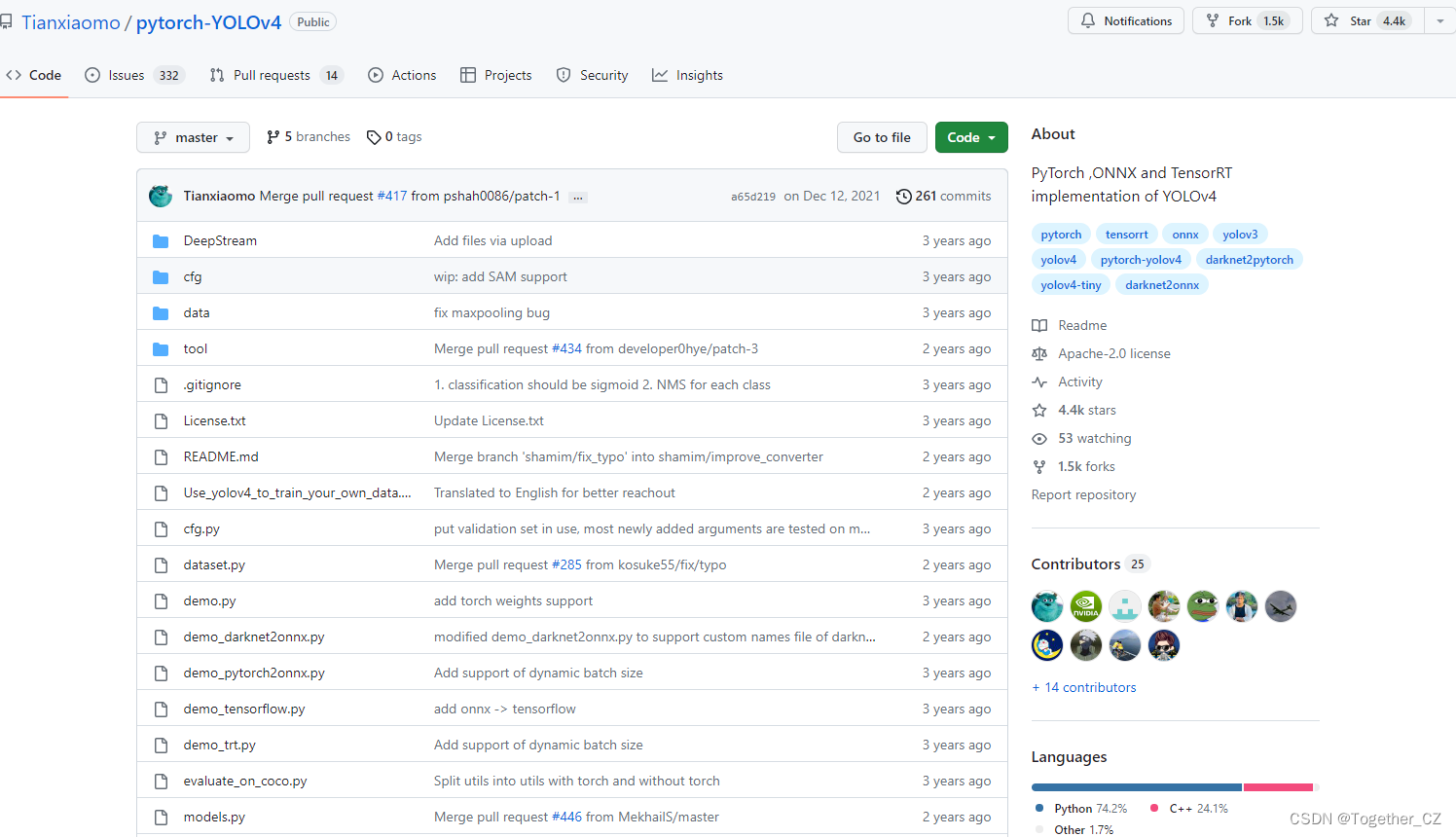
从说明里面来看,这个只是一个minimal的实现:
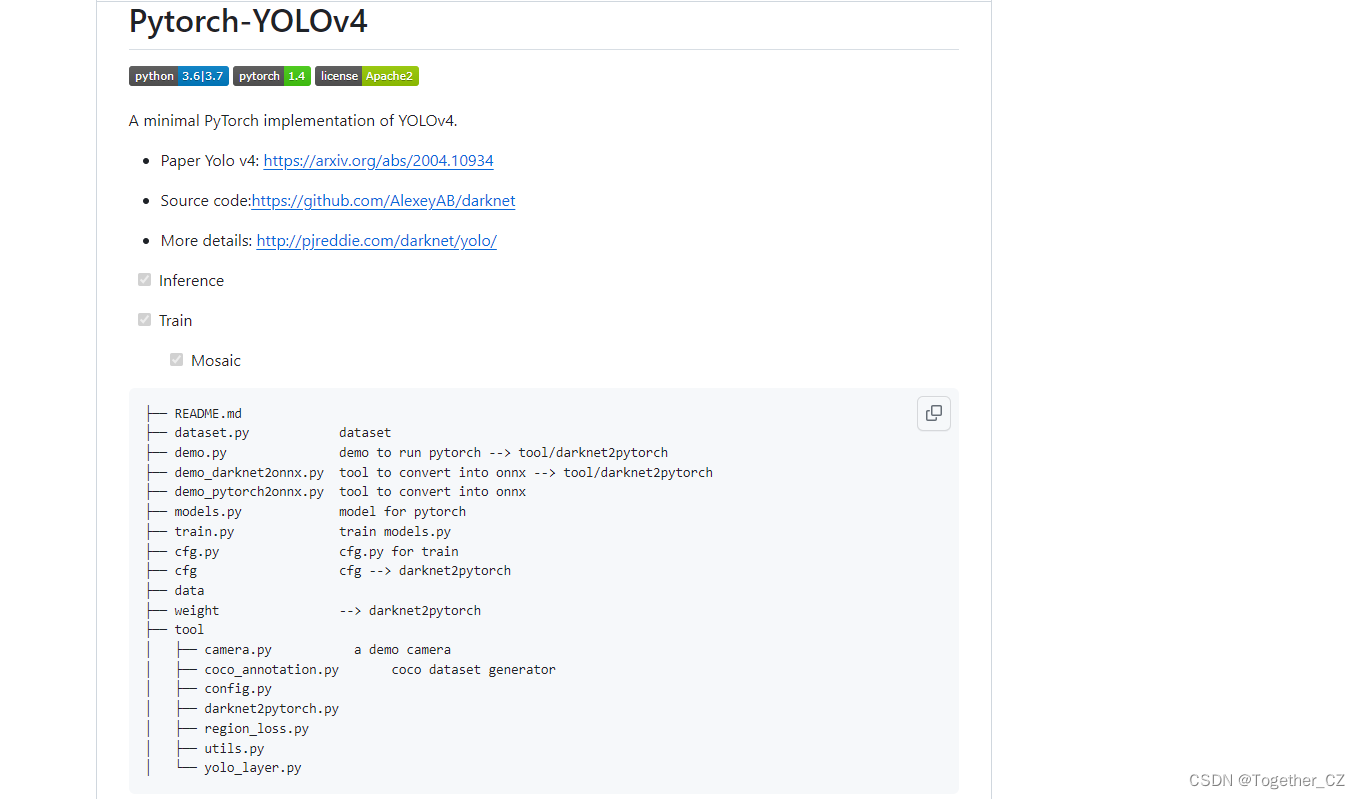
官方的实现应该是:
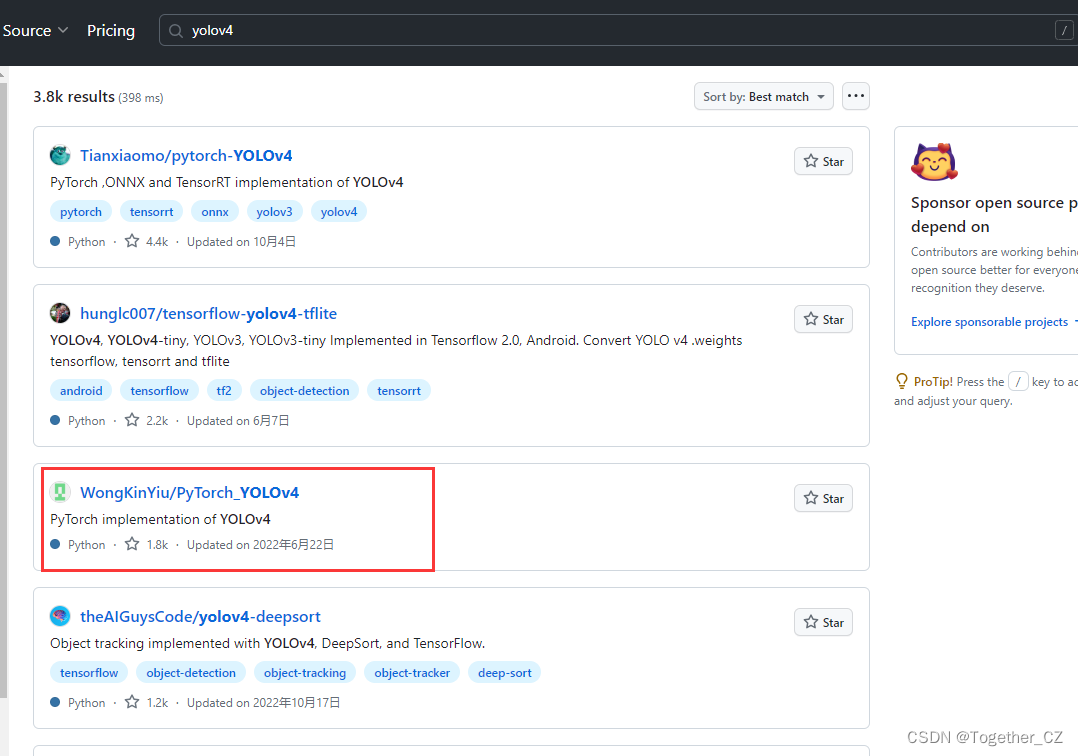
仔细看的话会发现,官方这里提供了YOLOv3风格的实现项目以及YOLOv5风格的实现项目,本文主要是以YOLOv3风格的YOLOv4项目为基准来讲解完整的实践流程,项目地址在这里,如下所示:

首先下载所需要的项目,如下:
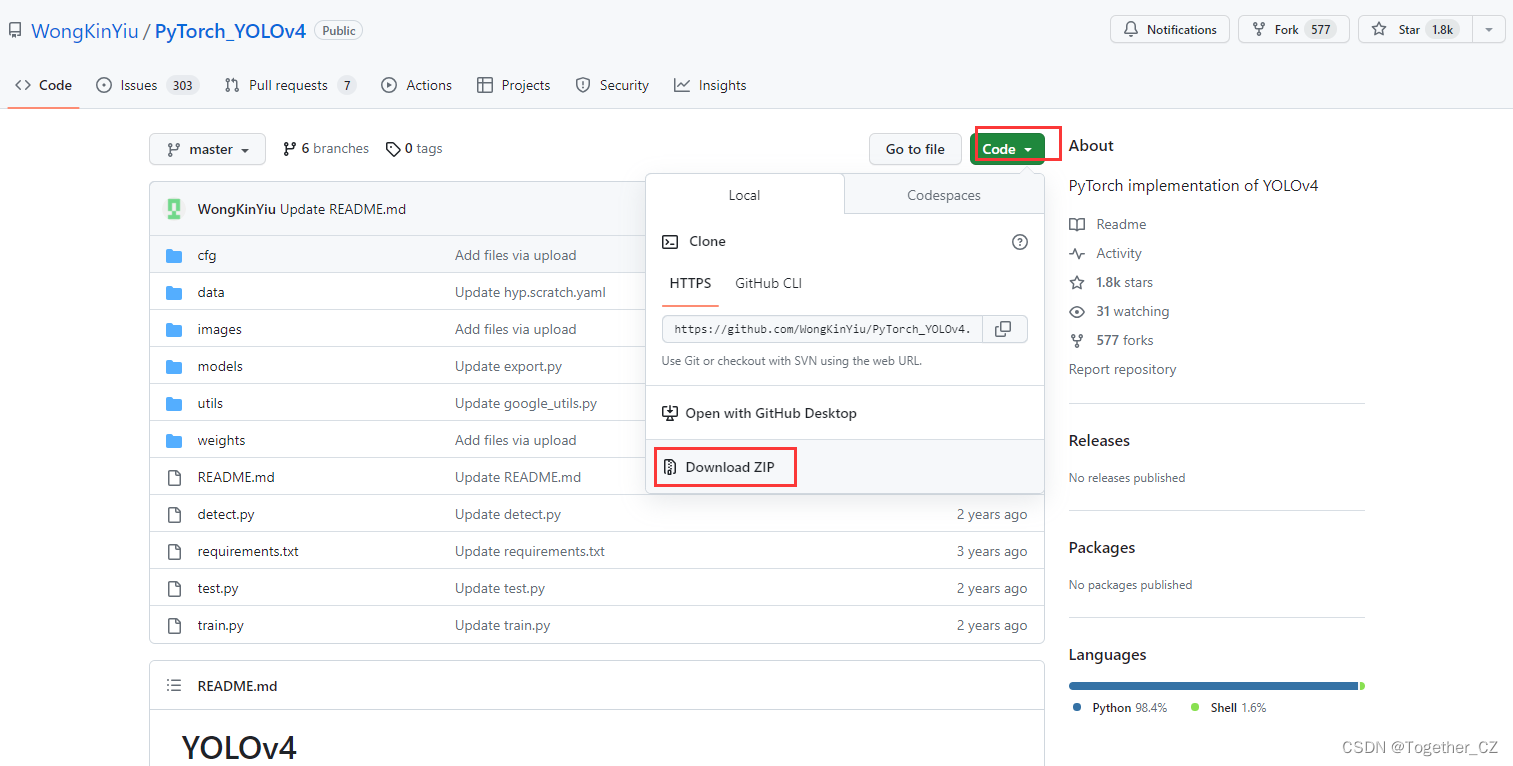
下载到本地解压缩后,如下所示:
网上直接百度下载这两个weights文件放在weights目录下,如下所示:
然后随便复制过来一个自己之前yolov5项目的数据集放在当前项目目录下,我是前面刚好基于yolov5做了钢铁缺陷检测项目,数据集可以直接拿来用,如果没有现成的数据集的话可以看我签名yolov5的超详细教程里面可以按照步骤自己创建数据集即可。如下所示:

这里我选择的是基于yolov4-tiny版本的模型来进行开发训练,为的就是计算速度能够更快一些。
修改train.py里面的内容,如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov4-tiny.weights', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/yolov4-tiny.cfg', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/self.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()终端直接执行:
python train.py即可。
当然也可以选择基于参数指定的形式启动,如下:
python train.py --device 0 --batch-size 16 --img 640 640 --data self.yaml --cfg cfg/yolov4-tiny.cfg --weights 'weights/yolov4-tiny.weights' --name yolov4-tiny根据个人喜好来选择即可。
启动训练终端输出如下所示:
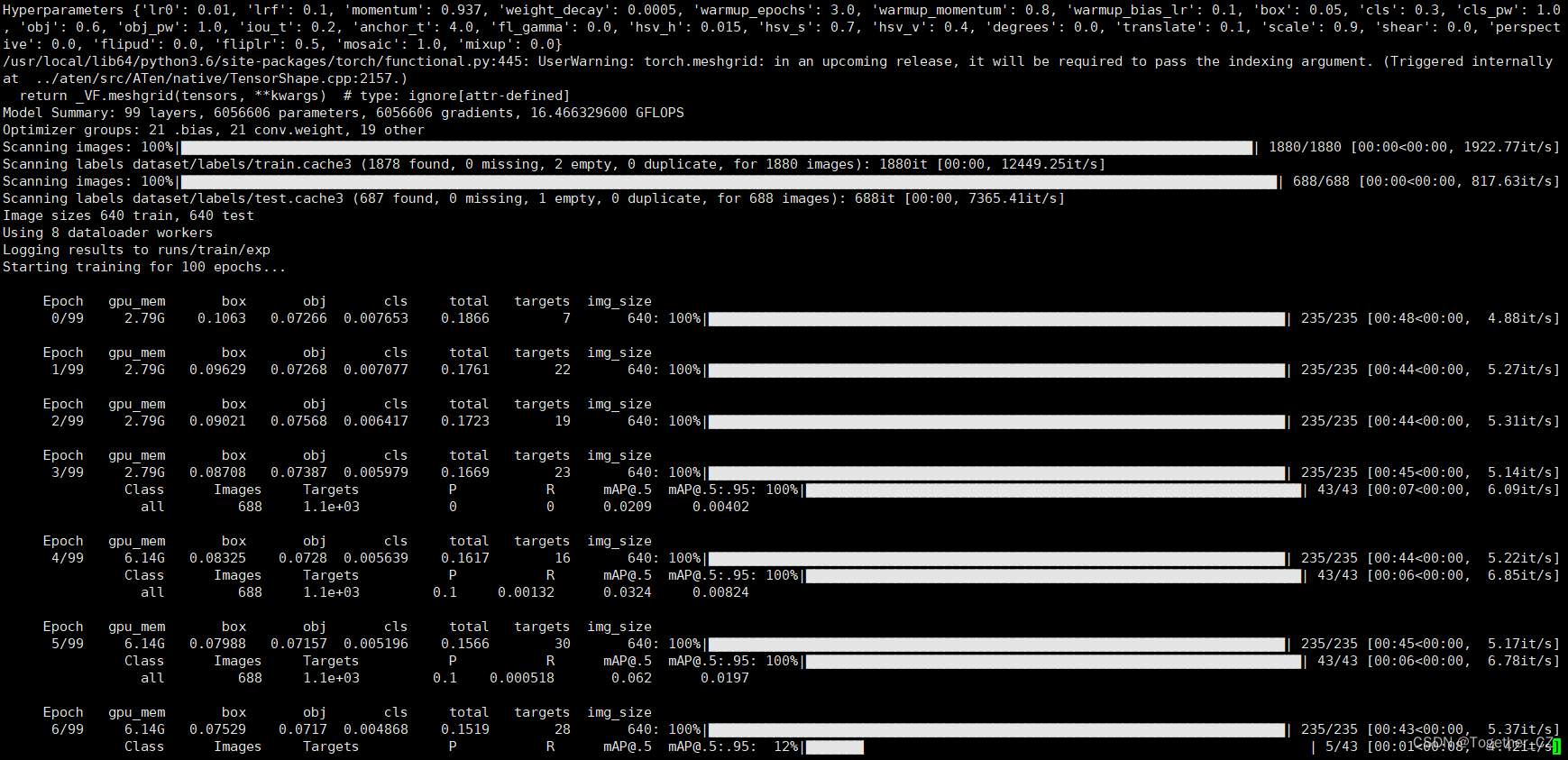
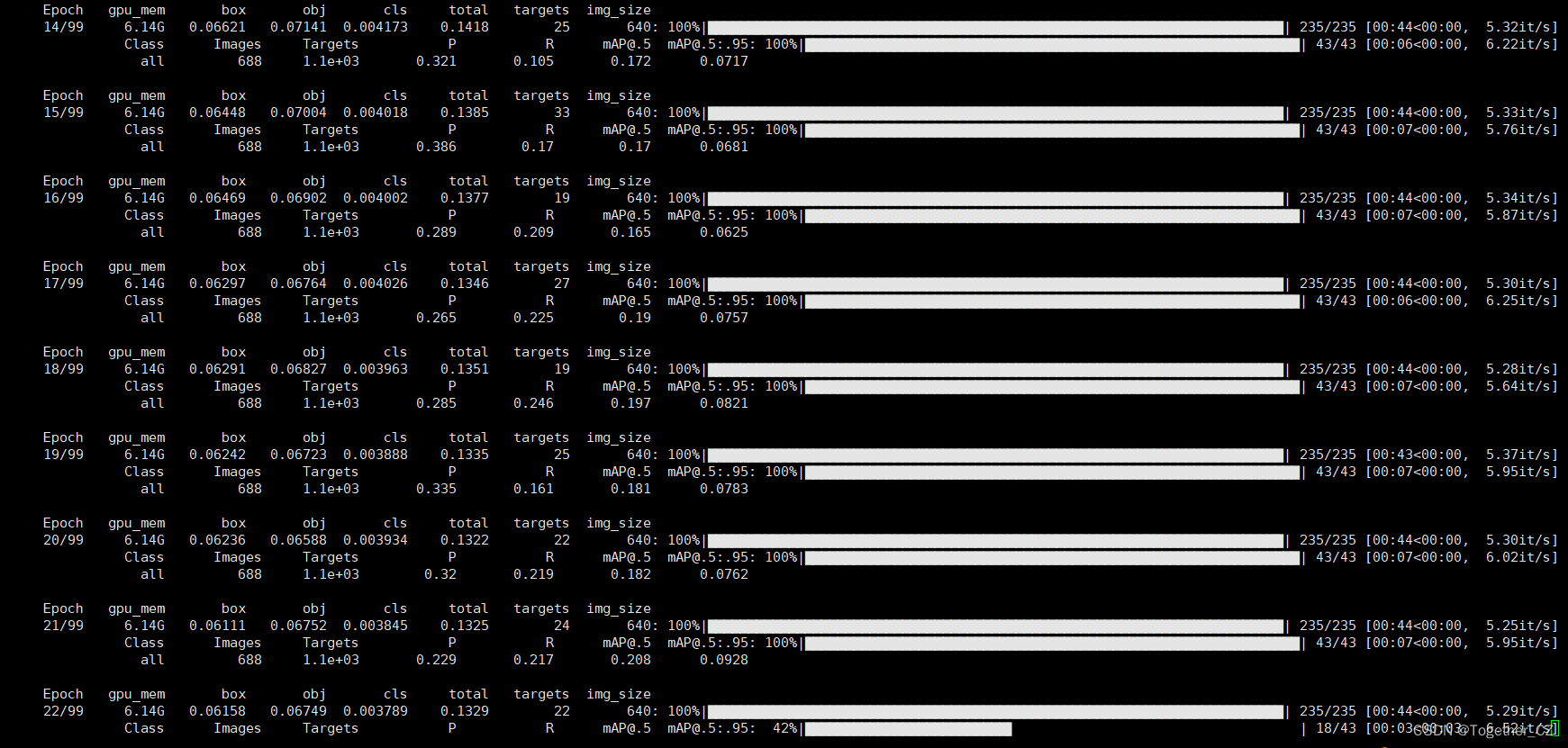

训练完成截图如下所示:
训练完成我们来看下结果文件,如下所示:
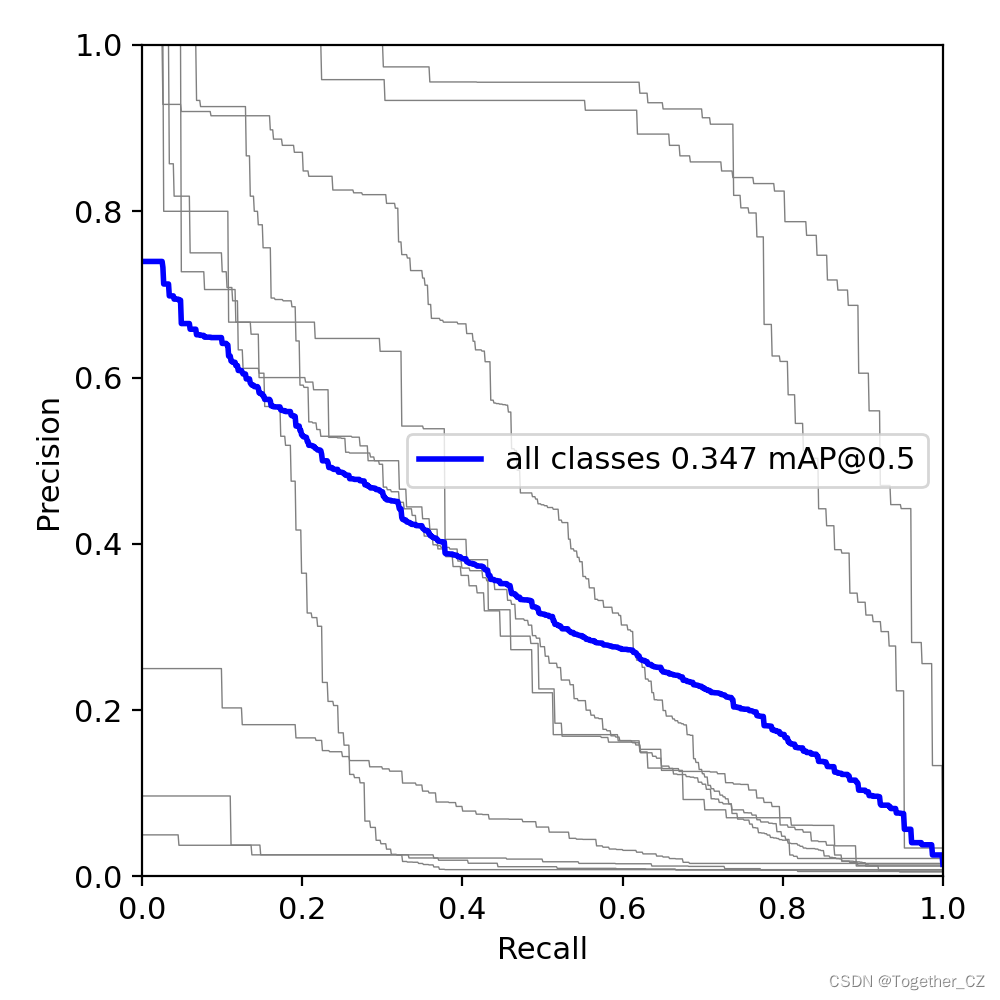
可以看到:结果文件直观来看跟yolov5项目差距还是很大的,评估指标只有一个PR图,所以如果是做论文的话最好还是使用yolov5来做会好点。
PR曲线如下所示:
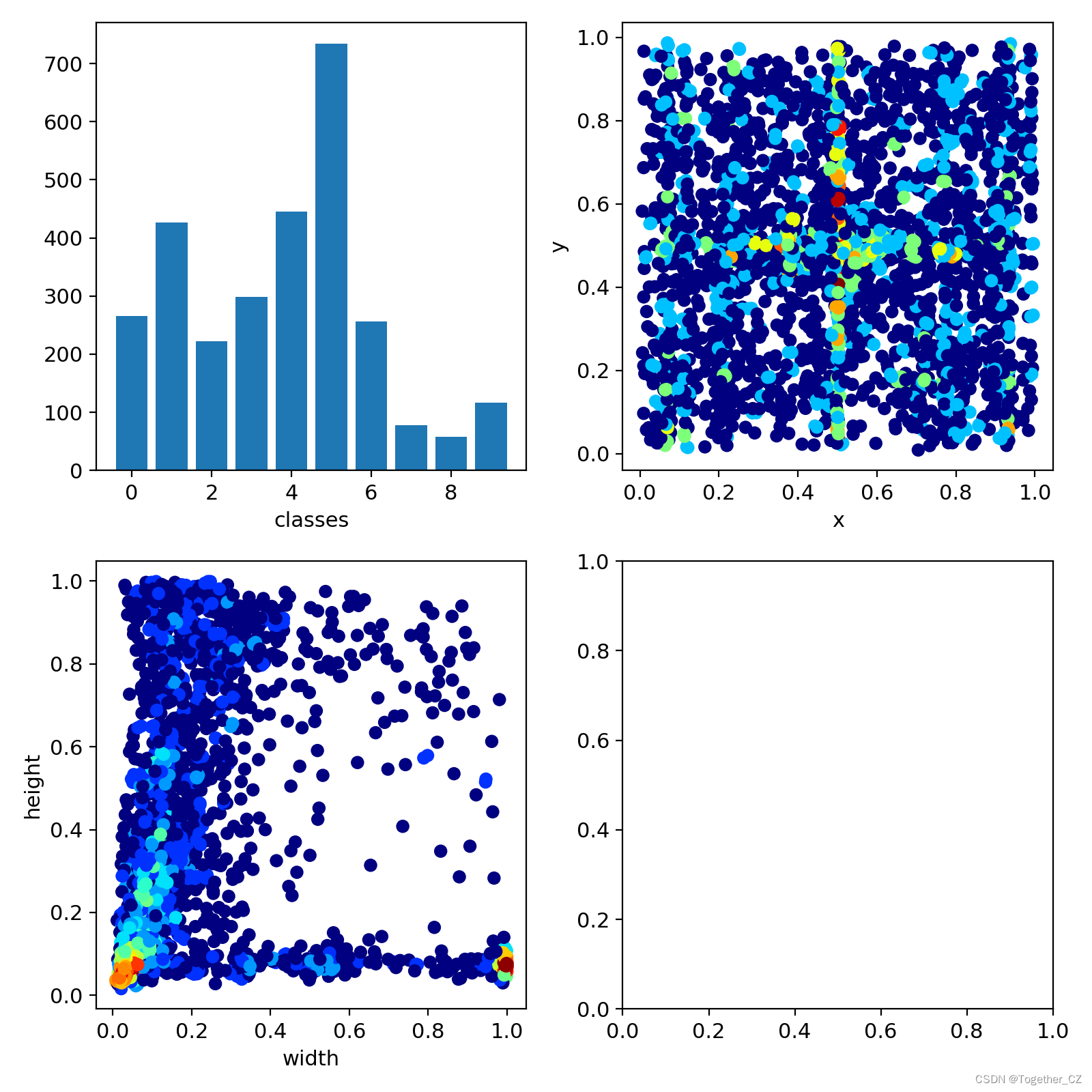
训练可视化如下所示:

LABEL数据可视化如下所示:
weights目录如下所示:
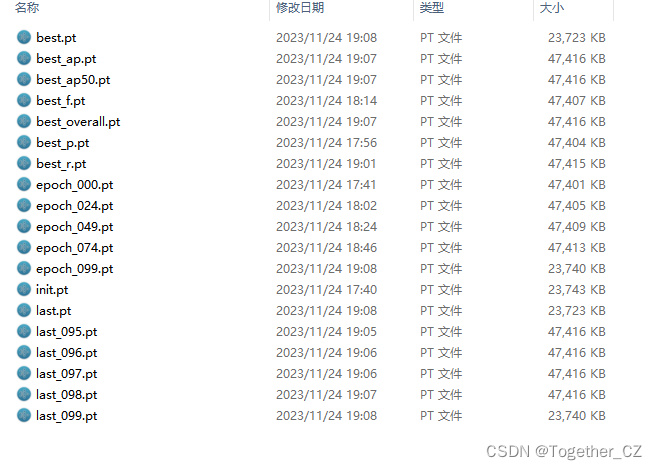
这个跟yolov5项目差异也是很大的,yolov5项目只有两个pt文件,一个是最优的一个是最新的,但是yolov4项目居然产生了19个文件,保存的可以说是非常详细了有点像yolov7,但是比v7维度更多一些。
感兴趣的话都可以按照我上面的教程步骤开发构建自己的目标检测模型。
相关文章:
基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】
本文是关于基于YOLOv4开发构建目标检测模型的超详细实战教程,超详细实战教程相关的博文在前文有相应的系列,感兴趣的话可以自行移步阅读即可:《基于yolov7开发实践实例分割模型超详细教程》 《YOLOv7基于自己的数据集从零构建模型完整训练、…...

1、Docker概述与安装
相关资源网站: ● docker官网:http://www.docker.com ● Docker Hub仓库官网: https://hub.docker.com/ 注意,如果只是想看Docker的安装,可以直接往下拉跳转到Docker架构与安装章节下的Docker具体安装步骤,一步步带你安…...

论文笔记——FasterNet
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。 为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由…...

计算机组成原理-固态硬盘SSD
文章目录 总览机械硬盘vs固态硬盘固态硬盘的结构固态硬盘与机械硬盘相比的特点磨损均衡技术例题 总览 机械硬盘vs固态硬盘 固态硬盘采用闪存技术,是电可擦除ROM 下图右边黑色的块块就是一块一块的闪存芯片 固态硬盘的结构 块大小16KB~512KB 页大小512B~4KB 对固…...
Electron+VUE3开发简版的编辑器【文件预览】
简版编辑器的功能主要是: 打开对话框,选择文件后台读取文件文件前端展示文件内容。主要技术栈是VUE3、Electron和Nodejs,VUE3做页面交互,Electron提供一个可执行Nodejs的环境以及支撑整个应用的环境,nodeJS负责读取文件内容。 环境配置、安装依赖这些步骤就不再叙述了。 …...
docker、elasticsearch8、springboot3集成备忘
目录 一、背景 二、安装docker 三、下载安装elasticsearch 四、下载安装elasticsearch-head 五、springboot集成elasticsearch 一、背景 前两年研究了一段时间elasticsearch,当时也是网上找了很多资料,最后解决个各种问题可以在springboot上运行了…...

【Lombok使用详解】
目录 前言:注解速查1.Lombok概念2.安装Lombok3. 使用Lombok3.1 😊Data3.2 GetterSetter3.3 NonNull3.4 Synchronized3.5 ToString:自动生成toString()方法3.6 Cleanup3.7 EqualsAndHashCode 前言:注解速查 NonNull : 用在成员方法…...

Tars框架 Tars-Go 学习
Tars 框架安装 网上安装教程比较多,官方可以参数这个 TARS官方文档 (tarsyun.com) 本文主要介绍部署应用。 安装完成后Tars 界面 增加应用amc 部署申请 amc.GoTestServer.GoTestObj 名称不知道的可以参考自己创建的app config 点击刷新可以看到自己部署的应用 服…...
基于JAVA+SpringBoot+VUE+微信小程序的前后端分离咖啡小程序
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着社会的快速发展和…...

2015年全国硕士研究生入学统一考试管理类专业学位联考数学试题——解析版
文章目录 2015 级考研管理类联考数学真题一、问题求解(本大题共 15 小题,每小题 3 分,共 45 分)下列每题给出 5 个选项中,只有一个是符合要求的,请在答题卡上将所选择的字母涂黑。真题(2015-01&…...

优秀软件设计特征与原则
1.摘要 一款软件产品好不好用, 除了拥有丰富的功能和人性化的界面设计之外, 还有其深厚的底层基础, 而设计模式和算法是构建这个底层基础的基石。好的设计模式能够让产品开发快速迭代且稳定可靠, 迅速抢占市场先机;而好的算法能够让产品具有核心价值, 例如字节跳动…...

设备管理系统-设备管理软件
一、为什么要使用设备管理系统 1.企业扩张快,设备配置多,管理混乱。 2.设备数量多,存放地点多,查找麻烦。 3.同类设备单独管理, 困难。 4.设备较多时相关信息统计容易出错,错误后修改困难。 二、凡尔码设备管理软件的…...

物联网AI MicroPython学习之语法 I2S音频总线接口
学物联网,来万物简单IoT物联网!! I2S 介绍 模块功能: I2S音频总线驱动模块 接口说明 I2S - 构建I2S对象 函数原型:I2S(id, sck, ws, sd, mode, bits, format, rate, ibuf)参数说明: 参数类型必选参数?…...

Day31| Leetcode 455. 分发饼干 Leetcode 376. 摆动序列 Leetcode 53. 最大子数组和
进入贪心了,我觉得本专题是最烧脑的专题 Leetcode 455. 分发饼干 题目链接 455 分发饼干 让大的饼干去满足需求量大的孩子即是本题的思路: class Solution { public:int findContentChildren(vector<int>& g, vector<int>& s) {…...
基于C#实现赫夫曼树
赫夫曼树又称最优二叉树,也就是带权路径最短的树,对于赫夫曼树,我想大家对它是非常的熟悉,也知道它的应用场景,但是有没有自己亲手写过,这个我就不清楚了,不管以前写没写,这一篇我们…...

Android 13.0 app进程保活白名单功能实现
1.前言 在13.0的系统rom产品开发中,在某些重要的app即使进入后台,产品需求要求也不想被系统杀掉进程,需要app长时间保活,就是app进程保活白名单功能的实现, 所以需要在系统杀进程的时候不杀掉白名单的进程,接下来就看怎么样来实现这些功能 2.app进程保活白名单功能实…...

查找学习笔记
1、静态查找表 以下查找的索引均从1开始 (1)顺序查找(带哨兵) #include<iostream> #include<vector>using namespace std;int search(vector<int> arr, int key) {arr[0] key;int i;for (i arr.size() - 1…...

Qt QIODevice介绍
作者:令狐掌门 技术交流QQ群:675120140 csdn博客:https://mingshiqiang.blog.csdn.net/ 文章目录 主要功能用法示例读取数据写入数据使用数据流基于套接字的读写注意事项QIODevice 是 Qt 中所有输入/输出设备的抽象基类。它为派生类提供了一组标准的接口用于读写数据。这些派…...
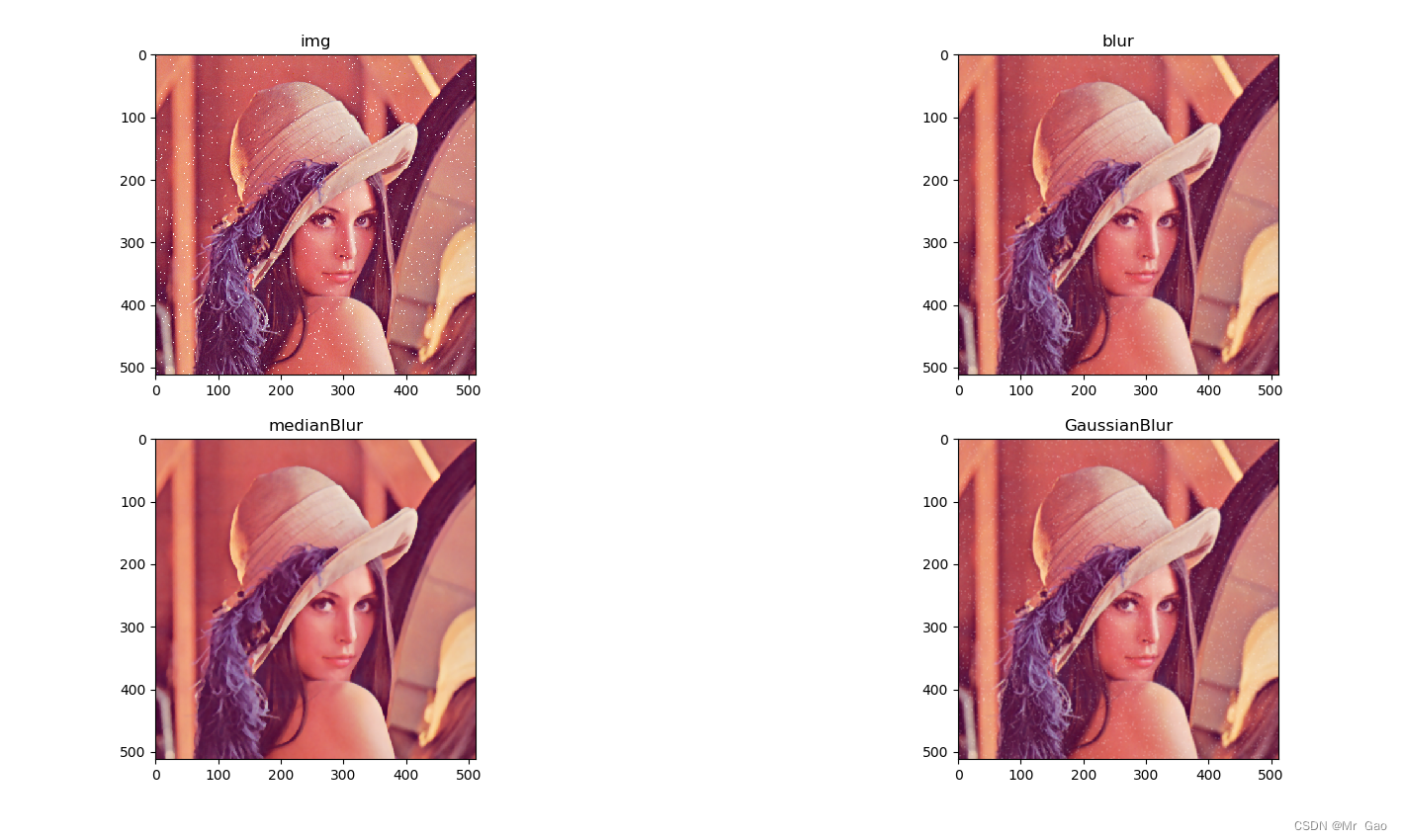
python -opencv 中值滤波 ,均值滤波,高斯滤波实战
python -opencv 中值滤波 ,均值滤波,高斯滤波实战 cv2.blur-均值滤波 cv2.medianBlur-中值滤波 cv2.GaussianBlur-高斯滤波 直接看代码吧,代码很简单: import copy import math import matplotlib.pyplot as plt import matp…...
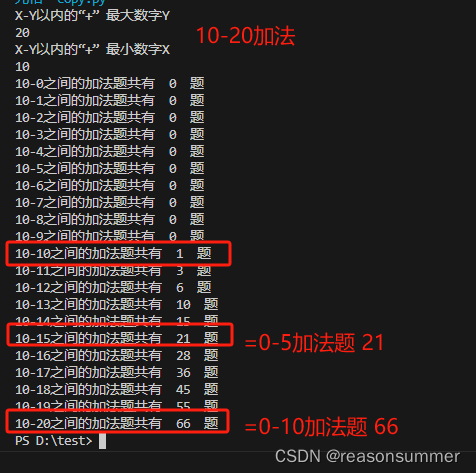
【教学类-06-07】20231124 (55格版)X-X之间的加法、减法、加减混合题
背景需求 在大四班里,预测试55格“5以内、10以内、20以内的加法题、减法题、加减混合题”的“实用性”。 由于只打印一份20以内加法减法混合题。 “这套20以内的加减法最难”,我询问谁会做(摸底幼儿的水平) 有两位男孩举手想挑…...

G-Helper终极指南:3步实现华硕笔记本性能优化与电池保护
G-Helper终极指南:3步实现华硕笔记本性能优化与电池保护 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...

STM32 RTC掉电后时间不准?手把手教你排查VBAT供电和LSE晶振问题
STM32 RTC掉电后时间不准?手把手教你排查VBAT供电和LSE晶振问题 当产品需要持续计时功能时,STM32的RTC模块往往是首选方案。但在实际项目中,工程师们常会遇到一个棘手问题:设备断电重启后,RTC时间出现明显偏差甚至完全…...
)
FPGA实战:手把手教你用Verilog实现有符号数的四舍五入(附完整代码与仿真)
FPGA实战:手把手教你用Verilog实现有符号数的四舍五入(附完整代码与仿真) 在数字信号处理领域,有符号数的四舍五入是一个看似简单却暗藏玄机的操作。许多初学者在处理负数时常常会遇到意想不到的结果,这是因为负数的四…...

OkHttp3实战:除了GET和POST,你还能用它轻松搞定文件上传和Session保持
OkHttp3实战:解锁文件上传与Session保持的高级技巧 在移动应用开发中,网络请求是几乎所有功能的基础支撑。OkHttp3作为Android平台上最受欢迎的HTTP客户端库之一,其简洁的API设计和强大的功能让开发者能够轻松处理各种网络请求场景。但很多开…...

如何在浏览器中直接查看SQLite文件:免费在线SQLite查看器终极指南
如何在浏览器中直接查看SQLite文件:免费在线SQLite查看器终极指南 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 在数据驱动的时代,SQLite数据库已成为移动应用、Web项目和…...
融合轻量级网络Ghostnet(幽灵卷积or幻影卷积),实测参数量降低!轻量化水文小神器!)
YOLO26最新创新改进系列:(粉丝反馈涨点模型TOP3)融合轻量级网络Ghostnet(幽灵卷积or幻影卷积),实测参数量降低!轻量化水文小神器!
YOLO26最新创新改进系列:(粉丝反馈涨点模型TOP3)融合轻量级网络Ghostnet(幽灵卷积or幻影卷积),实测参数量降低!轻量化水文小神器! 购买相关资料后畅享一对一答疑! 畅享超多免费持续更新且可大…...

C语言学习笔记 - 5.C概述 - C的应用领域
本笔记基于郝斌-C语言自学入门教程整理,配套参考教材为谭浩强《C程序设计(第五版)》,适配VSCode C/C开发环境,核心梳理C语言的核心应用场景,明确C语言的适用边界与不可替代的优势领域。一、C语言应用领域总览C语言的核心应用场景&…...

集成学习方法解析:Bagging与Boosting原理与实践
1. 集成学习方法概述:为什么需要模型组合?在机器学习实践中,我们常常面临一个关键矛盾:单一模型往往难以同时满足高准确性和强泛化能力的需求。这就好比医疗诊断中,单个专家的意见可能受限于其专业背景,而多…...

python terraform-cdk
# 当Python遇见基础设施:聊聊Terraform CDK for Python 最近在云原生和基础设施即代码的圈子里,有个工具逐渐引起了Python开发者的注意——Terraform CDK for Python。如果你熟悉Terraform,但总觉得HCL语言写起来不够顺手,或者你…...
)
保姆级教程:用PyQtGraph和Python打造你的专属股票分析桌面应用(附完整源码)
从零构建专业级股票分析桌面应用:PyQtGraph实战指南 在金融科技快速发展的今天,拥有一个定制化的本地股票分析工具已成为许多开发者和量化交易爱好者的刚需。与在线平台相比,本地应用不仅能保护数据隐私,还能根据个人交易策略灵活…...